
kaggle之数据分析从业者用户画像分析
数据为kaggle社区发布的数据分析从业者问卷调查分析报告,其中涵盖了关于该行业不同维度的问题及调查结果。本文的目的为提取有用的数据,进行描述性展示。帮助新从业的人员更全方位地了解这个行业。
参考学习视频:http://www.tianshansoft.com/
数据集:https://pan.baidu.com/s/1o7BFzFO
变量说明
数据中包含228个变量,提取其中的一些较有价值的变量进行描述性分析
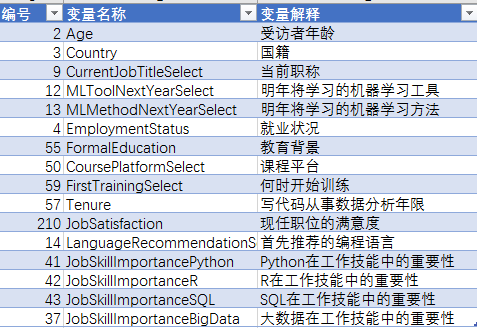
-
数据处理
survey <-read.csv(stringsAsFactors = F,file = 'F:\\R/数据科学社区调查/multipleChoiceResponses.csv',header=T,sep=',') class(survey) table(survey$Country) #统计每个国家参与人数
查看国家时,发现国家中中国被切分成共和国,民国,台湾,此处自行统一为中国
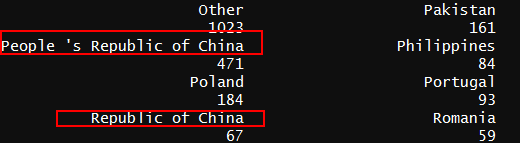
#将大陆,中华民国,台湾统一为中国 survey$Country <- ifelse(survey$Country=="People 's Republic of China" | survey$Country=='Republic of China' | survey$Country=='Taiwan' ,'China',survey$Country)
数据描述性展示
-
探索数据从业者中年龄最小(中位数)的十个国家
#将数据按国家分类,并求年龄的中位数 Country_age <- survey %>% group_by(Country) %>% summarise(Age_median=median(Age,na.rm = T)) %>% arrange(Age_median) head(Country_age)
#绘图,探索数据科学从业者年龄中位数最小的十个国家 p1 <-ggplot(data = head(Country_age,10),aes(reorder(Country,Age_median),Age_median,fill=Country))+ geom_bar(stat='identity')+coord_flip()+ labs(x='年龄',y='国家',title='探索不同国家数据从业者的平均年龄')+ geom_text(aes(label=round(Age_median,0)),hjust=1.5)+ theme(legend.position = 'none',plot.title=element_text(hjust = 0.3))
#绘图,探索数据科学从业者年龄中位数最大的十个国家 p2 <- ggplot(data = tail(Country_age,10),aes(reorder(Country,Age_median),Age_median,fill=Country))+ geom_bar(stat='identity')+coord_flip()+ labs(x='年龄',y='国家')+ geom_text(aes(label=round(Age_median,0)),hjust=1.5)+ theme(legend.position = 'none')
#合并两张图 library(Rmisc) multiplot(p1,p2,cols = 1)
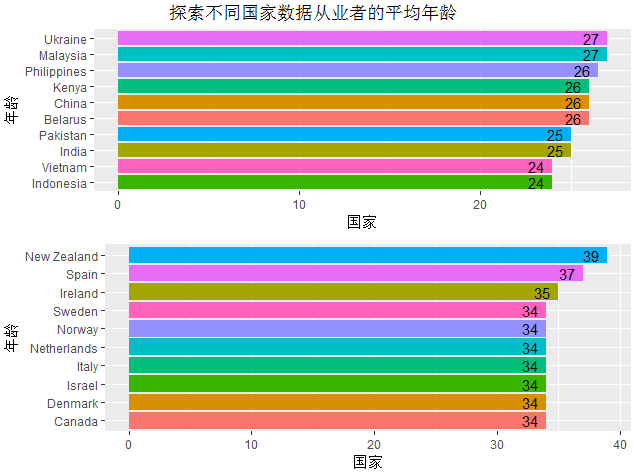
可以看到,按年龄中位数排列的话,亚洲国家在年龄较小的十个国家中占了七席,其中年龄中位数最小的国家为印度尼西亚和越南,只有24岁。中国的数据从业者集中在26岁。而年龄中位数最大的国家中,欧洲国家占了六席,且几乎都为发达国家。可见发达国家在数据科学领域已经有多年的发展。
探索数据从业者的职位名称分类
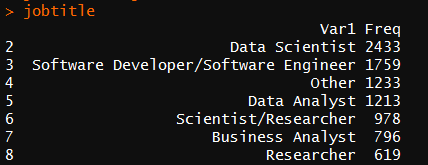
首先对数据整理,得出受访人数最多的前十个职位,且降序排列
#数据科学从业者的职位分类 jobtitle<-table(survey$CurrentJobTitleSelect)%>% #统计频数 as.data.frame()%>% #转化为数据框 arrange(desc(Freq)) #按频数倒序排列(大在前) jobtitle <- jobtitle[-1,] #人数最多的一行为空值,即职业一栏无填写
接下来进行绘图,将数据可视化
ggplot(data=head(jobtitle,10),aes(x=reorder(Var1,Freq),Freq,fill=Var1))+ #选取受访人数最多的前十个职业 geom_bar(stat = 'identity')+ labs(x='职业',y='人数',title='受访人数最多的十个职位')+ coord_flip()+ #翻转坐标轴 geom_text(aes(label=Freq),hjust=1.5)+ #添加数据标签 theme(legend.position = 'none',plot.title = element_text(hjust = 0.2)) #去除图例,调整标题位置

从图中可看出数据科学家参加问卷调查的人数最多,达2433人。排名第十的为程序员,只有462人
探索中美两国受访者的职业分类
-
处理数据
diff_nation <- survey[which(survey$Country=='China'),] #提取出国家为中国的调查者信息 diff_nation1 <- survey[which(survey$Country=='United States'),] #提取出国家为美国的调查者信息 china_jobtitle <- table(diff_nation$CurrentJobTitleSelect)%>%as.data.frame()%>%arrange(desc(Freq)) #探索在中国的受访人数较多职位 usa_jobtitle <- table(diff_nation1$CurrentJobTitleSelect)%>%as.data.frame()%>%arrange(desc(Freq)) #探索在美国的受访人数较多职位
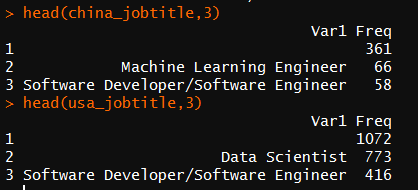
图中可看到,中国的受访者中,有361人没有填写当前职位这一栏。美国也有1072人。在绘图的过程中,需要将这些空值筛选掉
-
绘图
p3<-ggplot(china_jobtitle[c(2:11),],aes(reorder(Var1,Freq),Freq,fill=Var1))+ #数据集中国前十位热门职业 geom_bar(stat = 'identity')+ labs(x='职业',y='受访人数(中国)',title='中美两国受访者的当前职位对比')+ coord_flip()+ #翻转坐标轴 geom_text(aes(label=Freq),hjust=1)+ theme(legend.position = 'none',plot.title = element_text(size = 15,face = 'bold.italic')) #去除图例,设置标题大小,字体 p4<-ggplot(usa_jobtitle[c(2:11),],aes(reorder(Var1,Freq),Freq,fill=Var1))+ #数据集中国前十位热门职业 geom_bar(stat = 'identity')+ labs(x='职业',y='受访人数(美国)')+ coord_flip()+ #翻转坐标轴 geom_text(aes(label=Freq),hjust=1)+ theme(legend.position = 'none') #合并两图 multiplot(p3,p4)
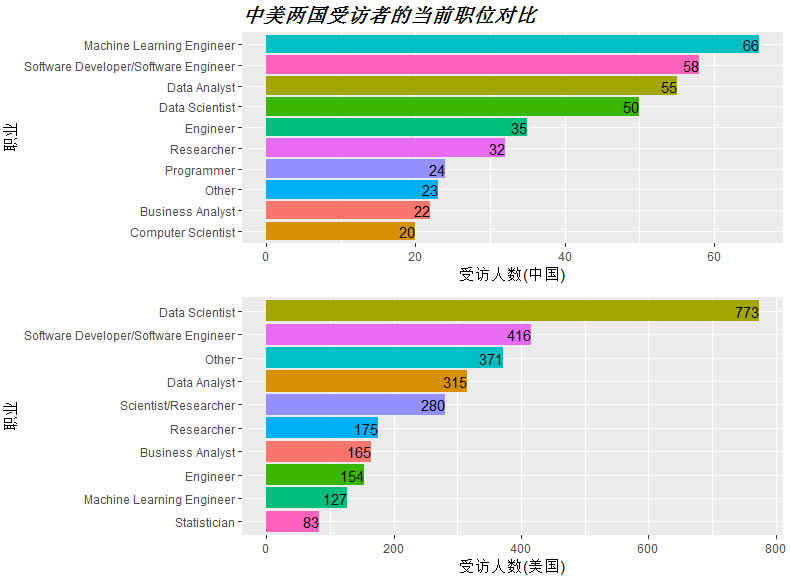
图中可看出,中国的受访者中,人数最多的为数据挖掘工程师,共66人,而美国受访者中最多的为数据科学家,共773人。排在第二位的皆为软件开发工程师。
探索数据科学从业者明年将学习的学习工具
-
数据处理
study_tool <- table(survey$MLToolNextYearSelect) %>% as.data.frame()%>% arrange(desc(Freq))
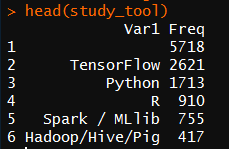
-
绘图
绘图过程与前面大同小异,所以可将绘图函数封装,代入变量即可
##############============封装绘图函数========##################### fun1 <-function(data1,xlab1,ylab1,xname1,yname1,titlename1){ ggplot(data = data1,aes(x=xlab1,y=ylab1,fill=xlab1))+ geom_bar(stat = 'identity')+ labs(x=xname1,y=yname1,title=titlename1)+ coord_flip()+ #翻转坐标轴 geom_text(aes(label=ylab1),hjust=1)+ #数据标签 theme(legend.position = 'none',plot.title = element_text(size = 15,face = 'bold.italic')) #去除图例,设置标题大小,字体 } ########################################################################
代入变量
#function(data,xlab1,ylab1,var1,xname1,yname1,titlename1) data <- study_tool[c(2:11),] xname1 <- '明年将学习的学习工具' yname1 <- '人数' titlename1 <- '受访者明年将学习的学习工具调查' fun1(data,reorder(data$Var1,data$Freq),data$Freq,xname1,yname1,titlename1)
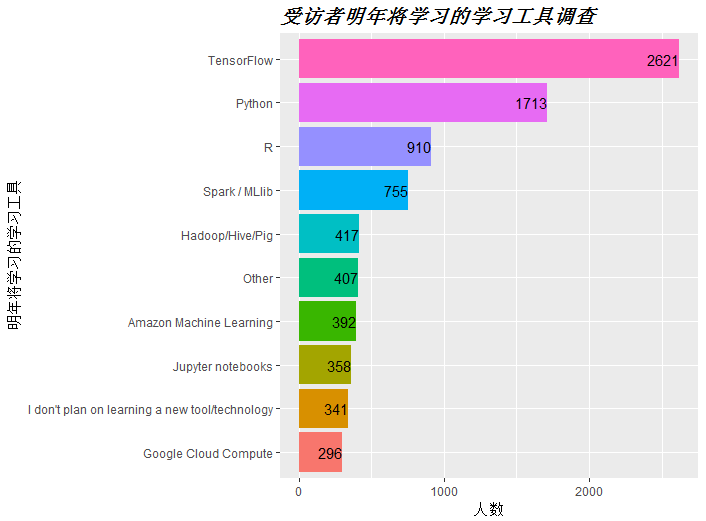
图中可看到,学习TensorFlow将成为明年的趋势,在受访者中,学习的人数达2621人之多。而接下来为python和R。可以预见,这3项将成为以后的主流学习工具。
探索中美两国数据科学从业者明年将学习的学习工具
-
数据提取
china_studytool <- survey %>% filter(survey$MLToolNextYearSelect !=''&Country=='China') %>% group_by(MLToolNextYearSelect) %>% summarise(count=n())%>% #n() 汇总 arrange(desc(count))
以上为提取中国受访者明年将学习的学习工具数据。
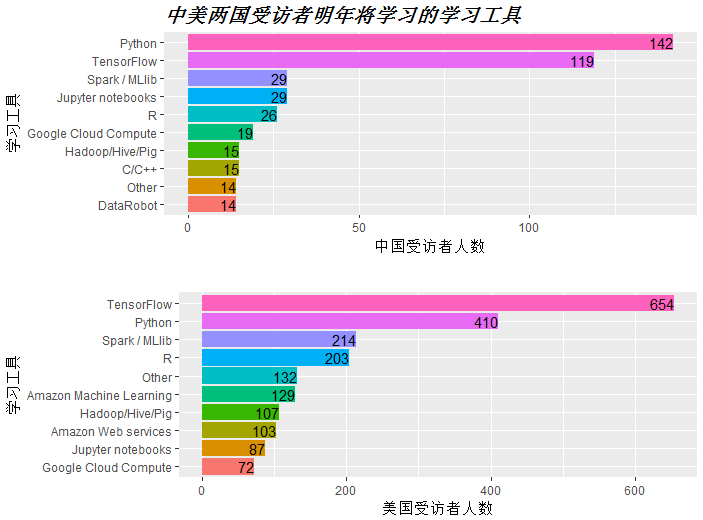
图中可见,中国数据科学从业者明年即将学习的学习工具热度较高的为Python,TensorFlow,Spark,jupyter,R。而美国为TensorFlow,python,sparkR,其他,比较符合国际趋势。
探索数据科学从业者明年将学习的机器学习方法
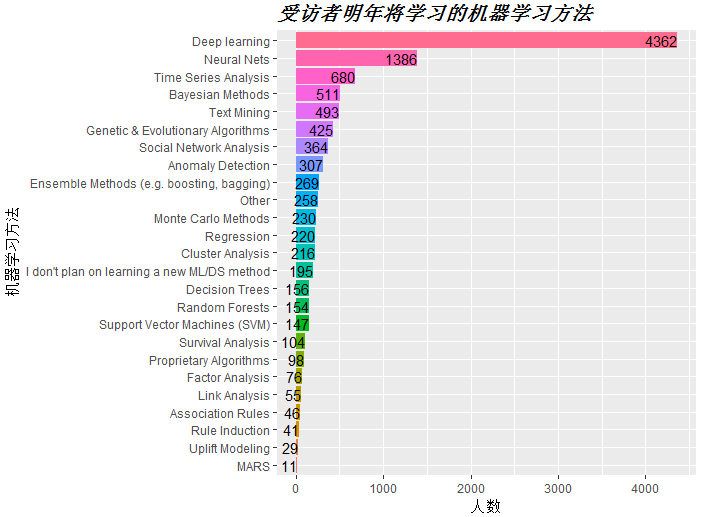
可以看到,当前的机器学习趋势为深度学习,神经网络,时间序列分析,贝叶斯方法,文本挖掘等。对机器学习方法感兴趣的从业者不妨做个参考。
从业者对新手的建议
-
推荐的编程语言
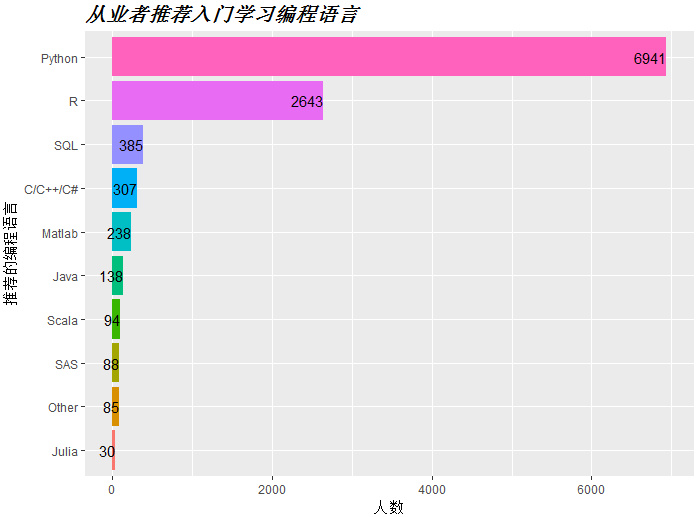
python,R,SQL是入门机器学习的必备技能

