
memcached的slab钙化问题
memcached的slab钙化问题
现象:
服务某些接口成功率波动,经研发查看是数据在memcached查询的偶尔失败。
因为前一晚升级的时候,改了存储在memcahed的数据(图片base64)的大小,改成高清图。
猜测是memcached存储有问题
排查步骤:
查看memcached监控

内存使用率一直都是满的,这个是之前就存在的问题。
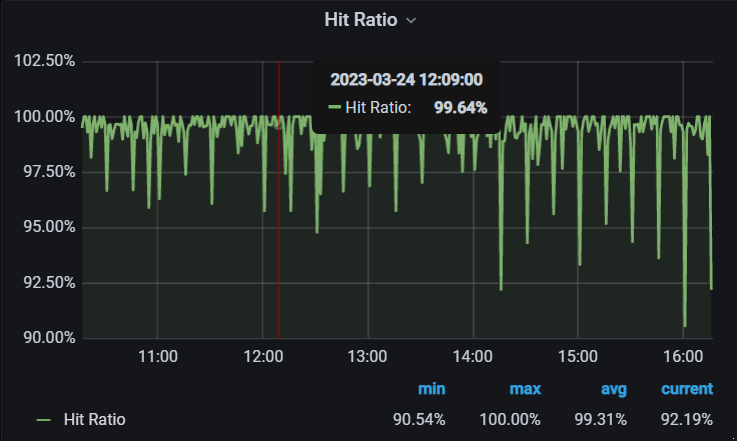
数据命中率波动,是服务接口报错的表面原因。
接着上memcached服务器查看stats状态,看看是那些数据导致命中率下降
使用memcached-tool工具
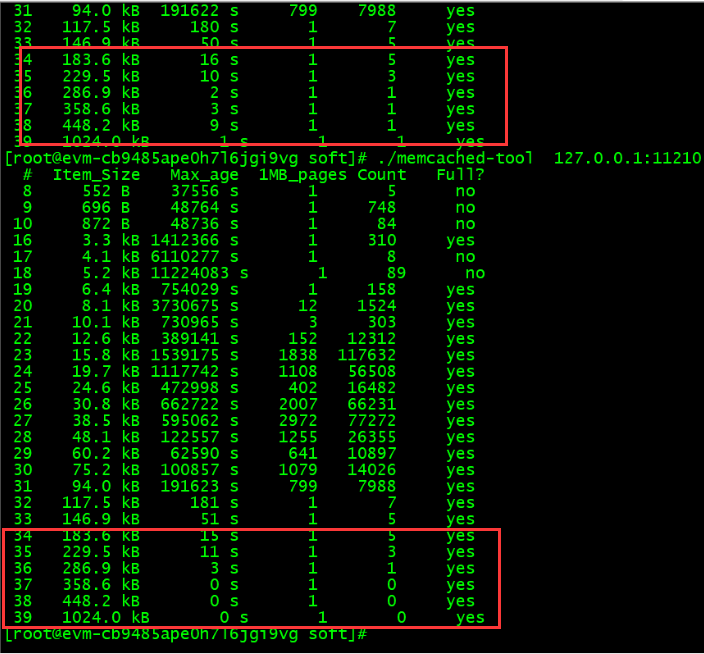
可以看出大item_size的存储数量很少,就1个,而且保留时间都很短,几秒中就被更新了。
推断是这部分数据的查询导致命中率下降。
那为啥明明是刚写入比较新的数据,但被淘汰了?
经百度查询是Slab钙化问题:
memcached内存利用率一直是90%,已经达到growth factor=1.25的期望内存利用率,所以内存已满。
就算flush_all删除所有数据,item仍占用chunk size,MC删除机制是数据不会真正从内存中消失,只要被其他数据覆盖,MC不会主动删除Slab chunk已存在的数据。
Slab钙化降低内存使用率,如果发生Slab钙化,有三种解决方案:
1) 重启Memcached实例,简单粗暴,启动后重新分配Slab class,但是如果是单点可能造成大量请求访问数据库,出现雪崩现象,冲跨数据库。
2) 随机过期:过期淘汰策略也支持淘汰其他slab class的数据,twitter工程师采用随机选择一个Slab,释放该Slab的所有缓存数据,然后重新建立一个合适的Slab。
3) 通过slab_reassign、slab_authmove参数控制。
Memcached 内存分配机制介绍
https://cloud.tencent.com/developer/article/1981648
memcached-tool使用详解
memcached-tool脚本可以方便地获得slab的使用情况 (它将memcached的返回值整理成容易阅读的格式),可以从下面的地址获得脚本:
http://www.netingcn.com/demo/memcached-tool.zip
使用方法也极其简单:
Usage: memcached-tool <host[:port]> [mode]
memcached-tool 10.0.0.5:11211 display # shows slabs
memcached-tool 10.0.0.5:11211 # same. (default is display)
memcached-tool 10.0.0.5:11211 stats # shows general stats
memcached-tool 10.0.0.5:11211 move 7 9 # takes 1MB slab from class #7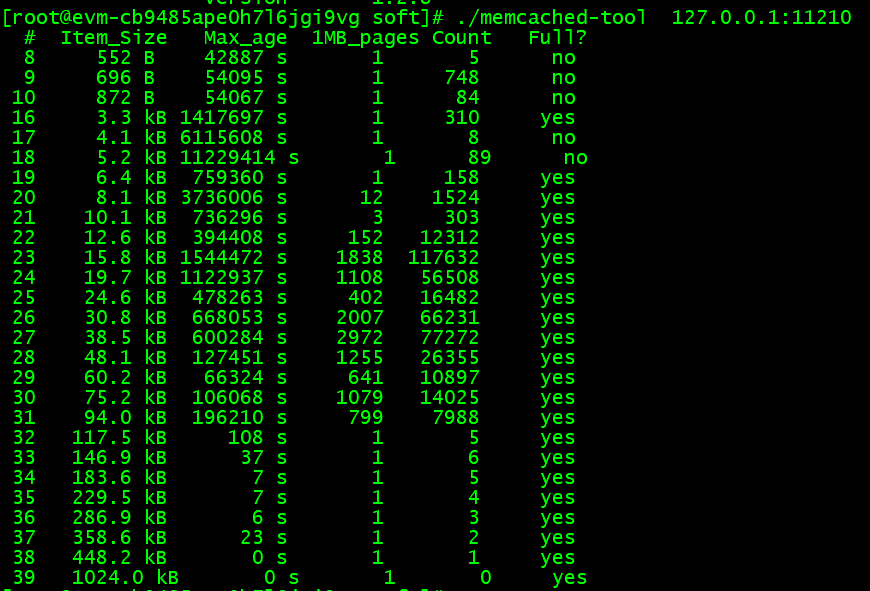
各列的含义:
# slab class编号
Item_Size Chunk大小
Max_age LRU内最旧的记录的生存时间
1MB_pages 分配给Slab的页数
Count Slab内的记录数
Full? Slab内是否含有空闲chunk
memcached使用详解
https://zhuanlan.zhihu.com/p/46364634


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 周边上新:园子的第一款马克杯温暖上架
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?
· 使用C#创建一个MCP客户端