HanLP 关键词提取。入门篇
前段时间,领导要求出一个关键字提取的微服务,要求轻量级。
对于没写过微服务的一个小白来讲。硬着头皮上也不能说不会啊。
首先了解下公司目前的架构体系,发现并不是分布式开发,只能算是分模块部署。然后我需要写个Boot的服务,对外提供一个接口就行。
在上网浏览了下分词概念后,然后我选择了Gradle & HanLP & SpringBoot & JDK1.8 & tomcat8 & IDEA工具来实现。
Gradle 我也是第一次听说,和Maven一样,可以很快捷的管理项目需要的jar。下载,解压,配置环境变量,验证等。不再赘述,可以去这里了解下https://www.w3cschool.cn/gradle/ctgm1htw.html
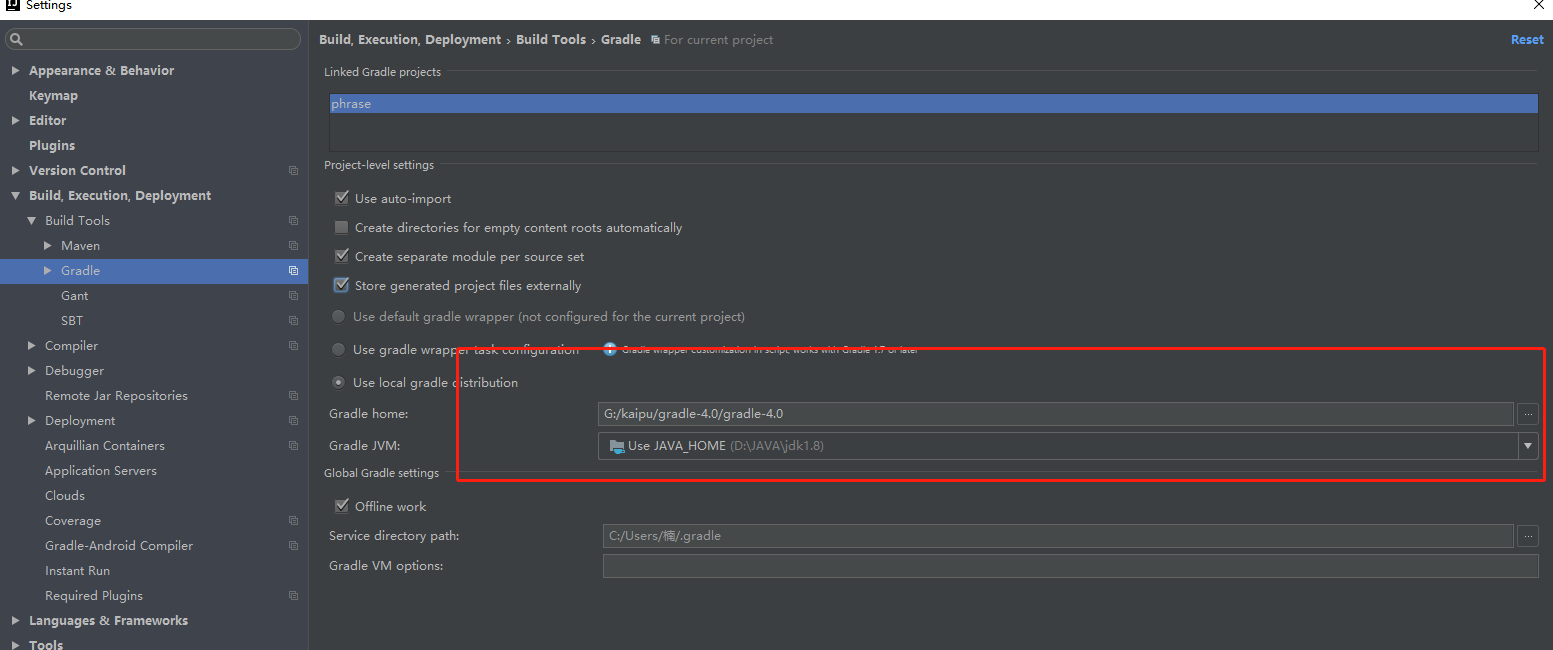
然后准备就绪后,在idea里配置一下Gradle路径
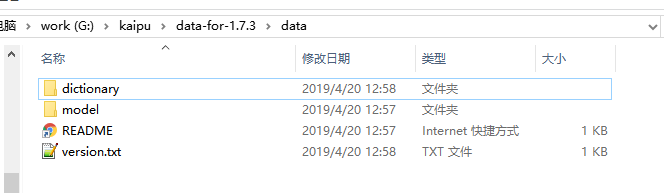
HanLP呢,老规矩,先下载,解压,https://github.com/hankcs/HanLP/releases 。简单看下目录结构
HanLP分为词典 和模型,其中词典(dictionary)是词法分析必备,模型(model)是句法分析必需。解压好准备data的上级目录 的绝对路径 下面会提到用途。
这里为G:/kaipu/data-for-1.7.3
tomcat8 去官网自行下载,选择自己操作系统对应的。 jdk1.8 下载安装,环境变量配置不再描述。
一切准备就绪,开始创建项目
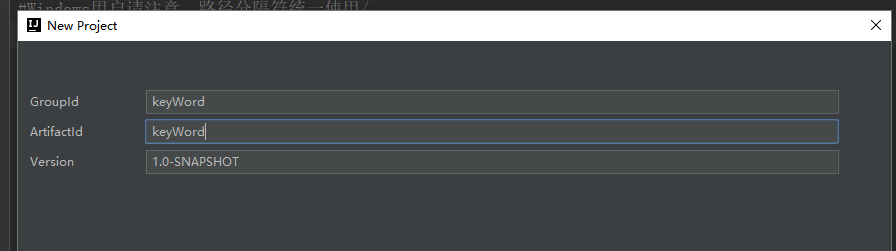
输入项目ID:keyWord,NEXT
选择本地的gradle
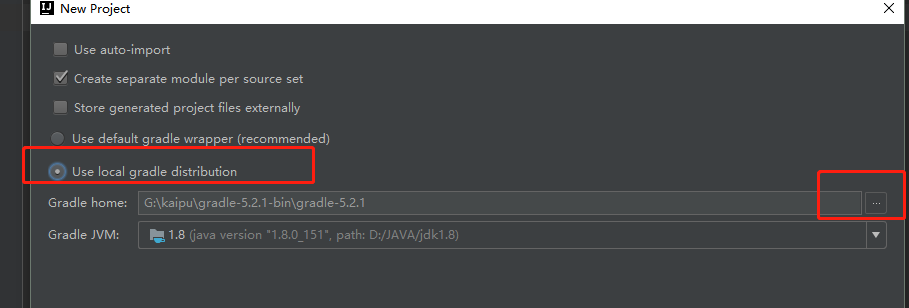
Next ,Finish
此刻项目就创建好了。
打开根目录下的
1 2 3 4 5 6 | dependencies { compile 'org.springframework.boot:spring-boot:2.0.5.RELEASE' compile 'org.springframework.boot:spring-boot-starter-web:2.0.5.RELEASE' providedRuntime 'org.springframework.boot:spring-boot-starter-tomcat:2.0.5.RELEASE' testCompile group: 'junit', name: 'junit', version: '4.11' compile 'com.hankcs:hanlp:portable-1.7.3'<br>} |
前三个jar 是集成springboot外部tomcat用的,第四个是junit单元测试依赖,第五个就是我们要用的hanlp依赖。
PS:这里我着重说下打包的事情,因为我没用过Gradle打包,项目时间紧,我就延用了war包格式,这里先记录下过程,这个项目后,再回头来研究Gradle打JAR包。
1 2 3 4 5 6 7 | group 'keyword'version '1.0-SNAPSHOT'apply plugin: 'java'apply plugin: 'war'war { archiveName 'key-word.war'} |
等待idea自动导包完成后,我们来加载hanlp
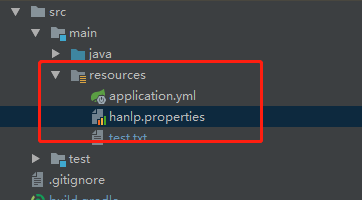
在resources下,出现一个hanlp.properties,打开编辑这个文件,更改root路径。这个路径就是上面我们提到的 data上级目录的绝对路径。

创建第一个测试类
1 2 3 | @Test public void test0(){ String text = "中国是世界上的经济大国,社会主义强国!"; <br> List<Term> keyWords = HanLP.segment(text);<br> System.out.println(keyWords.toString()); <br> } |
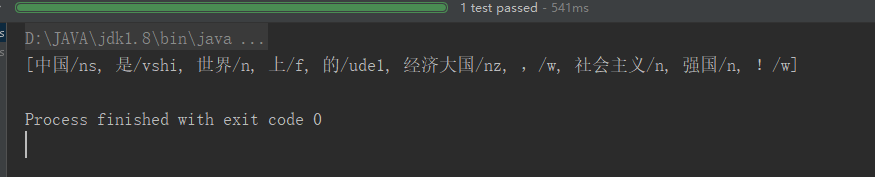
说明词库引入成功。
接下来可以正常开发,按照需求,需要提取正文里的关键词,摘要。
分析如下:
关键词抽取工具:
思路:输入标题,正文文本,综合考虑词频、位置、词性、组合性短语长度等因素,计算权重得分;返回topN个关键词。在此基础上进行抽取式摘要,按句子包含的关键词数量和权重进行处理。
原理:分词后,将命名实体单独拿到,再找合适的名词短语。依托HanLP的核心词典,根据TF*IDF算法计算每个命名实体和名词性短语的得分score,按score倒排返回前面若干关键词。
首先定义一个关键词类。可以是个单词,也可以是几个单词组成的短语。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | public class Phrase implements Comparable<Phrase>{ private String word; //候选关键词 private boolean inDictionary; //是否在HanLP词典中 private String suffixWord; //中心词。对单词,中心词就是word。如果是短语,则是短语中最后一词 private String suffixWordPos; //中心词的词性 private String prefixWordPos; //首词的词性 private int freqOfDict = 1; //在词典中该词的词频 private boolean single; //true表示单词,false表示短语 private Location location; //该候选关键词出现的位置 private int offset; //该候选词在正文中位置 private boolean isCandidate; //是否候选关键词 * * * /**<br> *这会在比较score时用到<br> */ @Override public int compareTo(Phrase o) { return this.getWord().compareTo(o.getWord()); }} |
以下是核心算法的一部分,寻找候选关键词
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | /**全局逻辑先找出关键词,再计算分数<br>一、 * 从分词Term中解析 候选的关键词, * 因为要计算每个句子的分数值需要句子里的所有词累加计算score,所以这里都需要打标分数。 * @param terms 分词列表 * @param title 文章标题 * @param firstParagraphEnd 对于正文处理,表示正文第一段结尾位置 * @param lastParagraphBegin 对于正文处理,表示正文最后一段开始位置 */<br><br><br>int index= 0;while (index < terms.size()) {<br> //当前词<br> Term current = terms.get(index);<br> //首先判断是否是命名实体 人名开头 包含 地名 动名词 其他专名,或者团体名开头if (current.nature.startsWith("nr") || current.nature.equals(Nature.ns) || current.nature.equals(Nature.nz) || current.nature.equals(Nature.vn) || current.nature.startsWith("nt")) { Phrase phrase = new Phrase(current.word, CoreDictionary.contains(current.word), current.word, current.nature.toString(), current.nature.toString(), CoreDictionary.get(current.word) == null ? 100 : CoreDictionary.get(current.word).totalFrequency, true, title.contains(current.word) ? Location.TITLE : whichLocation(terms.get(index).offset, firstParagraphEnd, lastParagraphBegin), terms.get(index).offset, true); phrases.add(phrase); index++; } <br>二、//计算候选关键词的权重TreeMap<Phrase, Double> scoreMap = new TreeMap<>();<br>for (Phrase phrase : phrases) {<br> double score = scoreMap.containsKey(phrase) ? scoreMap.get(phrase) : 0.0;<br> String phraseString = phrase.getWord().toString();<br> int wordLength = phraseString.length();<br> //排除单字符 的关键字,不进行输出<br> if (score == 0.0 && wordLength != 1) {<br> //weight方法:根据词性、词频、位置、词语长度等因素计算权重<br> //这里依赖HanLp核心词典 和自定义词典 实现TF*IDF算法<br><br> if (title.contains(phrase.getWord())) {<br> phrase.setFreqOfDict(phrase.getFreqOfDict() / 2);<br> }<br> if (phrase.getPrefixWordPos().startsWith("v") && phrase.getWord().contains("的")) {<br> phrase.setFreqOfDict(phrase.getFreqOfDict() * 1000);<br> }<br> score += Math.log(weight(phrase, content, title) * freqMap.get(phrase.getWord()) / phrase.getFreqOfDict());<br> scoreMap.put(phrase, score);<br> }<br><br>}三、<br><br>倒排Comparator<Map.Entry<Phrase, Double>> valueComparator = new Comparator<Map.Entry<Phrase, Double>>() {<br> @Override<br> public int compare(Map.Entry<Phrase, Double> o1,<br> Map.Entry<Phrase, Double> o2) {<br> return (o2.getValue().compareTo(o1.getValue()));<br> }<br>};<br>List<Map.Entry<Phrase, Double>> list = new ArrayList<Map.Entry<Phrase, Double>>(scoreMap.entrySet());<br>Collections.sort(list, valueComparator);<br><br>此刻就可利用subList函数 取出tonN的关键词了subList(0, Math.min(topN, 候选关键词数组size()));<br><br>四、<br>在三的基础上,对正文按标点符号 。?!;.!? 等进行分句。<br><br>List<Sentence> sentences = new ArrayList<>();<br>int i = 0;<br>int lastSentenceEnd = 0;<br>while (i <= content.length() - 1) {<br> char c = content.charAt(i);<br> if (SENTENCE_END_TAGS.indexOf(c) >= 0<br> && i > lastSentenceEnd + 1<br> && i > 0<br> && i < content.length()) {<br> Location location = Location.MIDDLE;<br> if (i < firstParagraphEnd) {<br> location = Location.FIRST;<br> } else if (i > lastParagraphBegin) {<br> location = Location.LAST;<br> }<br> int begin = lastSentenceEnd + 1;<br> if (sentences.isEmpty()) begin = 0; // 对第一句,应该从0开始<br> Sentence sentence = new Sentence(begin, i, location);<br> sentences.add(sentence);<br> lastSentenceEnd = i;<br> }<br> i++;<br>}<em>五,分句后,对每句含有的词,在三的基础上,进行分数累加。(有个小逻辑:句子长度对分数比例的影响 || 单个句子包含多个命名实体 人名等对分数比例的影响。|| 。。。)这些需要大量的场景测</em>for (Sentence sentence : sentences) { String line = content.substring(sentence.getBegin(), sentence.getEnd() + 1);<br> double sumScore = wordsWeight.get(wordsWeight.size() - 1).getValue();<br> //注意:要用关键词中最小权重做为基数,避免句子权重计算结果为0<br> int maxSize = Math.min(topN, wordsWeight.size());<br> for (int i = 0; i < maxSize; i++) {<br> Map.Entry<Phrase, Double> weight = wordsWeight.get(i);<br> double weightDouble = weight.getValue();<br> if (line != null && line.indexOf(weight.getKey().getWord()) >= 0){<br> List<Term> terms = NLPTokenizer.segment(line);<br> int index =0;int termCount = 0;<br> sumScore += weightDouble;}<br><em id="__mceDel"> }<br></em><em id="__mceDel"><em id="__mceDel"><em id="__mceDel"> sentence.setScore(sumScore);</em></em></em><em>然后同理,根据subList()取出想要的几个句子。再根据句子所在正文的位置,进行一个先后顺序的排列。<br></em>Comparator<Sentence> valueComparator = new Comparator<Sentence>() {<br><br> @Override<br> public int compare(Sentence o1, Sentence o2) {<br> return o1.getBegin() - o2.getBegin();<br> }<br>};<br>Collections.sort(prefixSentences, valueComparator);<br>StringBuilder sb = new StringBuilder();<br>for (Sentence sentence : prefixSentences) {<br> sb.append(SentenceTool.toString(sentence, content));<br>} |
还有一些可增删的业务逻辑:
去除文章末尾误识别的编辑、记者名称等
判断关键词里的 发言人;|| *** 说:“”。这些权重适当降低
保留句子里的实词词性,去除虚词词性(权重降低),来保证摘要的理性。
等等等等。
调试期间,有很多坑,现在记录下来,以便以后复习查看。
以上内容纯属个人所有,转载请注明出处。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异