

Improving Multi-hop Question Answering over Knowledge Graphs using Knowledge Base Embeddings
论文地址ACL2022:Improving Multi-hop Question Answering over Knowledge Graphs using Knowledge Base Embeddings
1.Abstract
知识图谱问答(KGQA)任务是通过图谱来回答自然语言形式的问题。多跳的KGQA需要在图谱上的多条边才能够到达答案实体。最近在多跳问题上的研究尝试着使用外部相关的文本来解决图谱的稀疏性,但是这种特定问题领域的文本并不容易得到。解决这种稀疏性还有一种方法就是通过图谱的嵌入来补全或者预测图谱中实体的连接,这种方法至今并没用用于多跳知识图谱问答,本篇paper就是将这种技术作为进入多跳领域,模型称作EmbedKGQA。在先前的多跳问答解决方案中,从图中选择与问题实体相关的子图/子空间是重要的技术手段,但是使用EmbedKGQA能够放宽这种约束。
即本文的亮点是:(1)放宽参数限制。(2)融合知识图谱的嵌入技术。
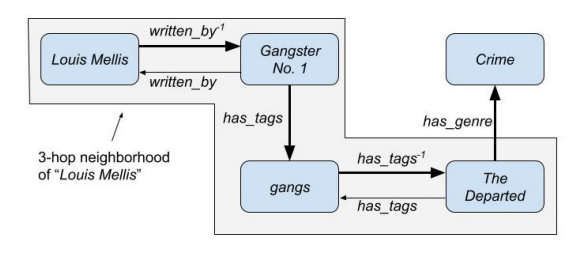
上图是知识图谱问答的例子,如果Louis Mellis和Crime有一条直接的连线,那我们可以很快地就得到问题的答案。但是作为答案实体的Crime在Louis Mellis实体的3跳范围之外,如果推理模型只有3跳则搜索不到答案实体。
EmbedKGQA 使用知识图嵌入而不是本地化子图来回答问题。 它使用头嵌入和问题嵌入,隐式捕获头节点周围所有观察到和未观察到的链接的知识。
因此,与其他 QA 系统不同,即使头部和答案实体之间没有路径,如果 KG 中有足够的信息能够预测该路径,我们的模型也应该能够回答问题。
2.相关工作
KG 嵌入方法学习 KG 中实体和关系的高维嵌入,然后用于链接预测。
KGQA:之前的工作中,TransE嵌入往往用于问题问答,但TransE需要对每个问题进行relation的ground truth标注,并且也无法应用于多跳问题回答。而在其他工作也有通过抽取子图来回答问题的,比如将头结点生成的子图投影到高维空间来生成回答等等,或者使用记忆网络来学习图谱中事实的嵌入等等。
KG补全:链接预测(link prediction)是指使用KG嵌入进行图谱的补全。总体框架是先定义一个关于三元组的得分函数,三元组正确时得分高,反之得分低。RESCAL和DistMlt方法学习的得分函数是关于头尾节点向量与关系矩阵的双线性乘积。ComplEx把实体向量和关系矩阵嵌入到了一个复数空间内。SimplE和TuckER则是基于张量分解的CP(Canonical Polyadic)分解和Tucker分解。而TransE则是将实体嵌入到高维实向量空间,把关系当成头节点和尾节点之间的变换,RotatE则是把节点嵌入到复数空间,把关系表示成复平面上的旋转操作。ConvE使用CNN来学习关于三元组的得分函数,InteractE通过增强特征互相作用提升了ConvE的效果。
连接预测:在链接预测中,给定一个不完整的知识图,任务是预测哪些未知链接是有效的。KG Embedding 模型通过一个评分函数 ![]() 来实现这一点,该函数分配一个分数 ,它指示一个三元组是否为真,目标是能够正确地对所有缺失的三元组进行评分。
来实现这一点,该函数分配一个分数 ,它指示一个三元组是否为真,目标是能够正确地对所有缺失的三元组进行评分。
3.1ComplEx Embedding:是一种向量分解方法

4.EmbedKGQA:
KGQA 中的问题涉及给定一个自然语言问题 q 和问题中存在的主题实体 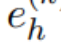 ∈ E,任务是提取一个正确回答问题 q 的实体
∈ E,任务是提取一个正确回答问题 q 的实体 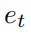 ∈ E。
∈ E。
本文研究的数据集往往没有额外的标注(比如问题类型或推理路径),例如关系“共同演员”是关系“……的演员”^-1和“……的演员”的组合,而本模型则不需要这类标注。
EmbedKGQA分为以下三个部分:

实体嵌入用于学习头部实体、问题和答案实体之间的三者的评分函数。
这个模块把问题也嵌入到了一个固定维度向量 中,先使用前馈神经网络,通过RoBERTa把问题表示成768维的向量,再通过4层全连接层和ReLU函数投影到复数空间
中。
给定问题 、主题实体(头结点)
和答案实体的集合
,通过下面的方式学习问题嵌入:
是前面学习的实体嵌入。这里的
使用的也是ComplEx的得分函数形式:
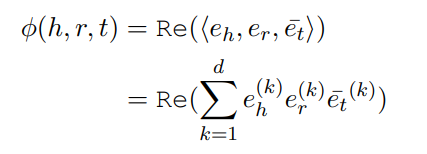
对每个问题,得分函数是使用所有候选答案实体 计算的,模型通过最小化sigmoid(得分)和标签(正1负0)的二元交叉熵损失函数来学习,在实体总数很多时,模型也进行了标签平滑。
4.4答案选择模块:
在推断阶段,模型针对所有可能的答案 计算(头节点,问题)的得分,在像MetaQA这种相对较小的图谱中,作者直接选择了得分最高的实体:
。但如果KG比较大,修剪候选实体(见下文)可以显著地提高EmbedKGQA表现。
4.4.1关系匹配:
和PullNet类似,模型学习了一个得分函数: 来针对给定问题
来对每个关系r进行排序,记
为关系
的嵌入,
为问题输入到RoBERTa的单词序列。得分函数定义为RoBERTa(
)最后一层输出和关系嵌入
点积的sigmoid值:
在所有的relation中,作者选择了得分大于0.5的relation记做集合 。对4.4中得到的每个候选实体
,模型会寻找头节点
和
之间的最短路径,记做集合
,得到每个候选实体的relation集合与总集合的交集得分:
。再结合ComplEx得分选择最终答案实体:
其中 为可调的超参数。
5 实验
三个问题:嵌入的必要性?无直接连接?answer selection?
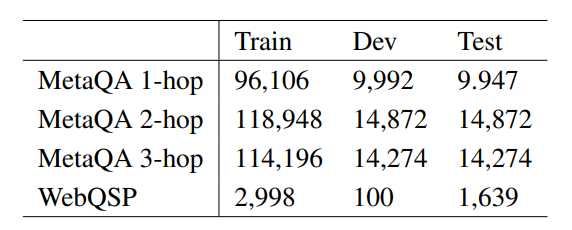
5.1 数据集
MetaQA:一个包括400k的电影领域的多跳KGQA数据集,包括1到3跳的问题。同时也提供了一个135k三元组,43k实体,9个关系的KG。
WebQuestionsSP:包括4737问题的小型QA数据集,数据集中的问题是1跳和2跳的,通过FreebaseKG进行回答。为了简化实验,作者只选取了Freebase中,WebQSP涉及到的实体的2跳距离内的实体以及WebQSP提到的relation,这个自己包括1.8m的实体和5.7m的三元组。
验证没有直接路径时的KG通过KGEmbedding能够获得头实体周围无连接路径的实体关系:
为了证明这一点,作者也设计了一个验证集问题。比如对“what language is [PK] in”,作者移除了([PK], in_language, Hindi)的三元组。同时,数据集也包括一些同一问题的paraphrase,作者移除了所有的paraphrase。
在这样的设置下,基于抽取子图的模型预计会得到0@1的结果,但该模型达到了29.9@1的准确率。另外,如果知道了每个问题对应的relation,这一任务也等价于根据三元组的头实体和relation预测尾实体,ComplEx达到了20.1@1,少的一部分可以归结于ComplEx嵌入只使用了KG没有用QA。

消融实验:
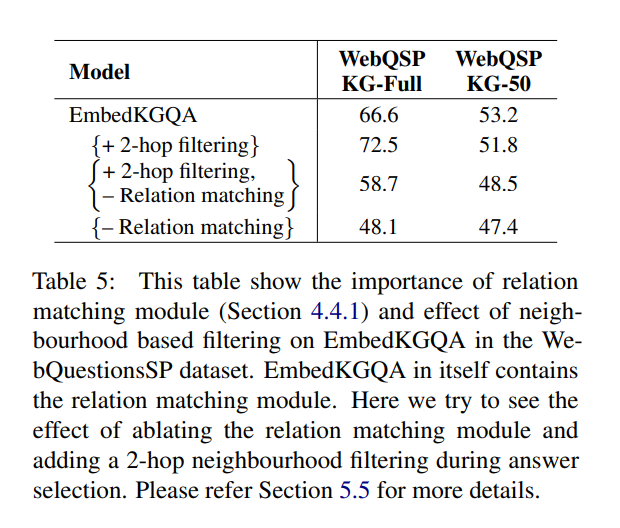
此外,如前所述,WebQSP KG(Freebase 子集)的实体数量比 MetaQA 多一个数量级(1.8M 对 MetaQA 中的 134k),并且可能的答案数量很大。 因此,在 WebQSP KG-Full 的情况下,减少头部实体的 2 跳邻域的答案集显示了改进的性能。但是,这会导致 WebQSP KG-50 的性能下降。 这是因为将答案限制在不完整 KG 上的 2 跳邻域可能会导致答案不存在于候选者中(请参见图 1)。 综上所述,我们发现关系匹配是 EmbedKGQA 的重要组成部分。 此外,我们建议可以在 EmbedKGQA 之上包含答案选择过程中的 n-hop 过滤,以用于相当完整的 KG。
(疑问,这里的限定2-hop代码中如何操作,具体意义又是什么?)
结论:
在本文中,我们提出了一种用于多跳 KGQA 的新方法 EmbedKGQA。 KG 通常不完整且稀疏,这对多跳 KGQA 方法提出了额外的挑战。最近这个问题试图通过利用额外的文本语料库来解决不完整性问题。然而,相关文本语料库的可用性通常是有限的,从而降低了此类方法的广泛覆盖适用性。在另一项研究中,已经提出了 KG 嵌入方法来通过执行缺失链接预测来减少 KG 稀疏性。 EmbedKGQA 利用 KG 嵌入的链接预测特性来缓解 KG 不完整性问题,而无需使用任何额外的数据。它训练 KG 实体嵌入并使用它来学习问题嵌入,并在评估过程中对所有实体进行评分(头部实体、问题),并选择得分最高的实体作为答案。 EmbedKGQA 还克服了现有多跳 KGQA 方法所施加的有限邻域大小约束的缺点。 EmbedKGQA 在多个 KGQA 设置中实现了最先进的性能,这表明 KG 嵌入的链接预测属性可用于缓解 Multi-hop KGQA 中的 KG 不完整性问题

