Java爬虫框架WebMagic入门——爬取列表类网站文章
初学爬虫,WebMagic作为一个Java开发的爬虫框架很容易上手,下面就通过一个简单的小例子来看一下。
WebMagic框架简介
WebMagic框架包含四个组件,PageProcessor、Scheduler、Downloader和Pipeline。
这四大组件对应爬虫生命周期中的处理、管理、下载和持久化等功能。
这四个组件都是Spider中的属性,爬虫框架通过Spider启动和管理。
WebMagic总体架构图如下:
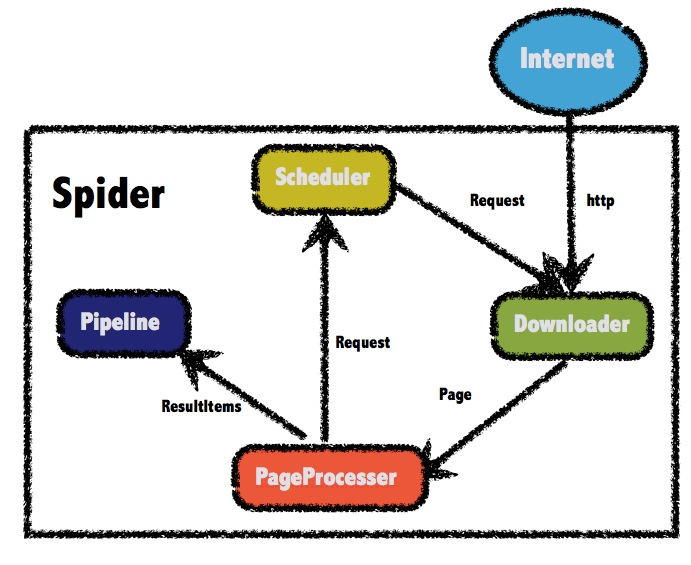
四大组件
PageProcessor 负责解析页面,抽取有用信息,以及发现新的链接。需要自己定义。
Scheduler 负责管理待抓取的URL,以及一些去重的工作。一般无需自己定制Scheduler。
Pipeline 负责抽取结果的处理,包括计算、持久化到文件、数据库等。
Downloader 负责从互联网上下载页面,以便后续处理。一般无需自己实现。
用于数据流转的对象
Request 是对URL地址的一层封装,一个Request对应一个URL地址。
Page 代表了从Downloader下载到的一个页面——可能是HTML,也可能是JSON或者其他文本格式的内容。
ResultItems 相当于一个Map,它保存PageProcessor处理的结果,供Pipeline使用。
环境配置
使用Maven来添加依赖的jar包。
<dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-core</artifactId> <version>0.7.3</version> </dependency>
<dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-extension</artifactId> <version>0.7.3</version> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> </exclusions> </dependency>
或者直接摸我下载。
添加完jar包就完成了所有准备工作,是不是很简单。
下面来测试一下。
package edu.heu.spider; import us.codecraft.webmagic.Page; import us.codecraft.webmagic.Site; import us.codecraft.webmagic.Spider; import us.codecraft.webmagic.pipeline.ConsolePipeline; import us.codecraft.webmagic.processor.PageProcessor; /** * @ClassName: MyCnblogsSpider * @author LJH * @date 2017年11月26日 下午4:41:40 */ public class MyCnblogsSpider implements PageProcessor { private Site site = Site.me().setRetryTimes(3).setSleepTime(100); public Site getSite() { return site; } public void process(Page page) { if (!page.getUrl().regex("http://www.cnblogs.com/[a-z 0-9 -]+/p/[0-9]{7}.html").match()) { page.addTargetRequests( page.getHtml().xpath("//*[@id=\"mainContent\"]/div/div/div[@class=\"postTitle\"]/a/@href").all()); } else { page.putField(page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/text()").toString(), page.getHtml().xpath("//*[@id=\"cb_post_title_url\"]/@href").toString()); } }
public static void main(String[] args) { Spider.create(new MyCnblogsSpider()).addUrl("http://www.cnblogs.com/justcooooode/") .addPipeline(new ConsolePipeline()).run(); } }
输出结果:
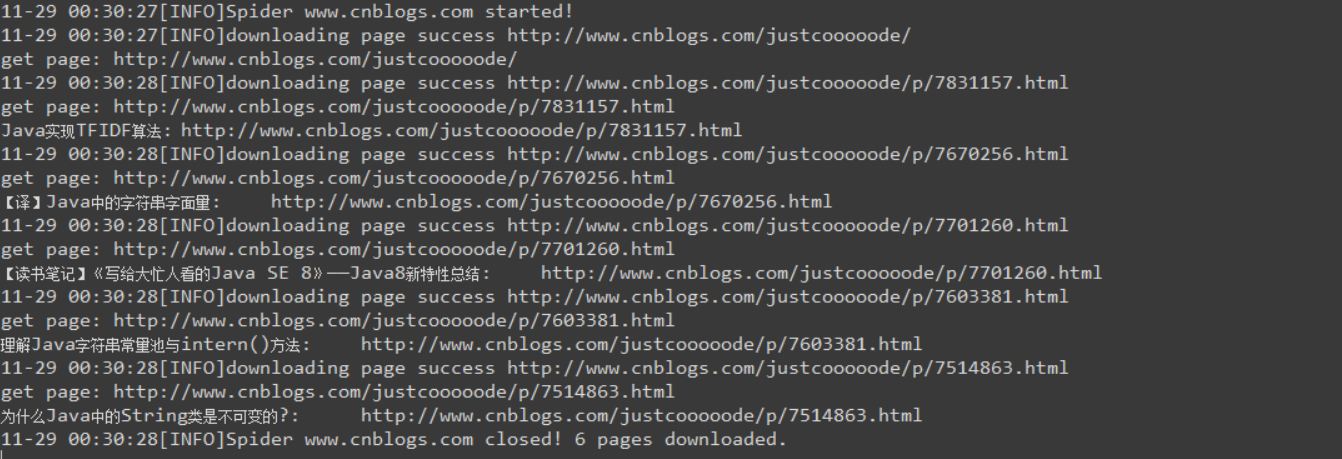
如果你和我一样之前没有用过log4j,可能会出现下面的警告:

这是因为少了配置文件,在resource目录下新建log4j.properties文件,将下面配置信息粘贴进去即可。
目录可以定义成你自己的文件夹。
# 全局日志级别设定 ,file log4j.rootLogger=INFO, stdout, file # 自定义包路径LOG级别 log4j.logger.org.quartz=WARN, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d{MM-dd HH:mm:ss}[%p]%m%n # Output to the File log4j.appender.file=org.apache.log4j.FileAppender log4j.appender.file.File=D:\\MyEclipse2017Workspaces\\webmagic\\webmagic.log log4j.appender.file.layout=org.apache.log4j.PatternLayout log4j.appender.file.layout.ConversionPattern=%n%-d{MM-dd HH:mm:ss}-%C.%M()%n[%p]%m%n
现在试一下,没有警告了吧😊。
爬取列表类网站例子
列表爬取的思想都很类似,首先判定是否为列表页,若是的话将文章url加入爬取队列,不是的话就代表此时为文章页,直接爬取你要的内容就可以。
选择一个列表类文章的网站:https://voice.hupu.com/nba
首先判断是文章还是列表,查看几个页面后可以找到规律,利用正则表达式区分。
page.getUrl().regex("https://voice\\.hupu\\.com/nba/[0-9]{7}\\.html").match()
如果满足上面的正则表达式,则该url对应的是一个文章页面。
接下来要对需要爬取的内容进行抽取,我选择了xPath(浏览器自带直接粘贴就可以)。

WebMagic框架支持多种抽取方式,包括xPath、css选择器、正则表达式,还可以通过links()方法选择所有链接。
记住抽取之前要获得通过getHtml()来获取html对象,通过html对象来使用抽取方法。
ps:WebMagic好像不支持xPath中的last()方法,如果用到的话可以想其他方法代替。
然后利用page.putFiled(String key, Object field)方法来将你想要的内容放到一个键值对中。
page.putField("Title", page.getHtml().xpath("/html/body/div[4]/div[1]/div[1]/h1/text()").toString());
page.putField("Content", page.getHtml().xpath("/html/body/div[4]/div[1]/div[2]/div/div[2]/p/text()").all().toString());
如果不满足文章页的正则,就说明这是一个列表页,此时要通过xPath来定位页面中文章的url。

page.getHtml().xpath("/html/body/div[3]/div[1]/div[2]/ul/li/div[1]/h4/a/@href").all();
这时,你已经得到要爬取url的list,把他们通过addTargetRequests方法加入到队列中即可。
最后实现翻页,同理,WebMagic会自动添加到爬取队列中。

page.getHtml().xpath("/html/body/div[3]/div[1]/div[3]/a[@class='page-btn-prev']/@href").all()
下面是完整代码,自己实现了一个MysqlPipeline类,用到了Mybatis,可以将爬下来的数据直接持久化到数据库中。
也可以用自带的ConsolePipeline或者FilePipeline等。
package edu.heu.spider; import java.io.IOException; import java.io.InputStream; import java.util.Iterator; import java.util.Map; import java.util.Map.Entry; import org.apache.ibatis.io.Resources; import org.apache.ibatis.session.SqlSession; import org.apache.ibatis.session.SqlSessionFactory; import org.apache.ibatis.session.SqlSessionFactoryBuilder; import edu.heu.domain.News; import us.codecraft.webmagic.Page; import us.codecraft.webmagic.ResultItems; import us.codecraft.webmagic.Site; import us.codecraft.webmagic.Spider; import us.codecraft.webmagic.Task; import us.codecraft.webmagic.pipeline.Pipeline; import us.codecraft.webmagic.processor.PageProcessor; /** * @ClassName: HupuNewsSpider * @author LJH * @date 2017年11月27日 下午4:54:48 */ public class HupuNewsSpider implements PageProcessor { // 抓取网站的相关配置,包括编码、抓取间隔、重试次数等 private Site site = Site.me().setRetryTimes(3).setSleepTime(100); public Site getSite() { return site; } public void process(Page page) { // 文章页,匹配 https://voice.hupu.com/nba/七位数字.html if (page.getUrl().regex("https://voice\\.hupu\\.com/nba/[0-9]{7}\\.html").match()) { page.putField("Title", page.getHtml().xpath("/html/body/div[4]/div[1]/div[1]/h1/text()").toString()); page.putField("Content", page.getHtml().xpath("/html/body/div[4]/div[1]/div[2]/div/div[2]/p/text()").all().toString()); } // 列表页 else { // 文章url page.addTargetRequests( page.getHtml().xpath("/html/body/div[3]/div[1]/div[2]/ul/li/div[1]/h4/a/@href").all()); // 翻页url page.addTargetRequests( page.getHtml().xpath("/html/body/div[3]/div[1]/div[3]/a[@class='page-btn-prev']/@href").all()); } }
public static void main(String[] args) { Spider.create(new HupuNewsSpider()).addUrl("https://voice.hupu.com/nba/1").addPipeline(new MysqlPipeline()) .thread(3).run(); } } // 自定义实现Pipeline接口 class MysqlPipeline implements Pipeline { public MysqlPipeline() { } public void process(ResultItems resultitems, Task task) { Map<String, Object> mapResults = resultitems.getAll(); Iterator<Entry<String, Object>> iter = mapResults.entrySet().iterator(); Map.Entry<String, Object> entry; // 输出到控制台 while (iter.hasNext()) { entry = iter.next(); System.out.println(entry.getKey() + ":" + entry.getValue()); } // 持久化 News news = new News(); if (!mapResults.get("Title").equals("")) { news.setTitle((String) mapResults.get("Title")); news.setContent((String) mapResults.get("Content")); } try { InputStream is = Resources.getResourceAsStream("conf.xml"); SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(is); SqlSession session = sessionFactory.openSession(); session.insert("add", news); session.commit(); session.close(); } catch (IOException e) { e.printStackTrace(); } } }
查看数据库:😊

爬好的数据已经静静地躺在数据库中了。
官方文档中还介绍了通过注解来实现各种功能,非常简便灵活。
使用xPath时要留意,框架作者自定义了几个函数:
| Expression | Description | XPath1.0 |
|---|---|---|
| text(n) | 第n个直接文本子节点,为0表示所有 | text() only |
| allText() | 所有的直接和间接文本子节点 | not support |
| tidyText() | 所有的直接和间接文本子节点,并将一些标签替换为换行,使纯文本显示更整洁 | not support |
| html() | 内部html,不包括标签的html本身 | not support |
| outerHtml() | 内部html,包括标签的html本身 | not support |
| regex(@attr,expr,group) | 这里@attr和group均可选,默认是group0 | not support |
使用起来很方便。
转载请注明原文链接:http://www.cnblogs.com/justcooooode/p/7913365.html
参考资料
官方文档:https://github.com/code4craft/webmagic
http://webmagic.io/docs/zh/
xPath教程:http://www.w3school.com.cn/xpath/index.asp

