NodeJS的url信息截取模块url-extract
2013-09-12 22:49 Justany_WhiteSnow 阅读(3288) 评论(10) 收藏 举报上一篇文章,介绍了怎么利用NodeJS + PhantomJS进行截图,但由于对每次截图操作,都启用了一个PhantomJS进程,所以并发量上去后,效率堪忧,所以我们重写了所有代码,并将其独立成为一个模块,方便调用。
如何改进?
- 控制线程数,以及单线程处理url数量。
- 使用Standard Output & WebSocket 进行通讯。
- 添加缓存机制,目前使用Javascript Object进行。
- 对外提供简易的接口。
设计图
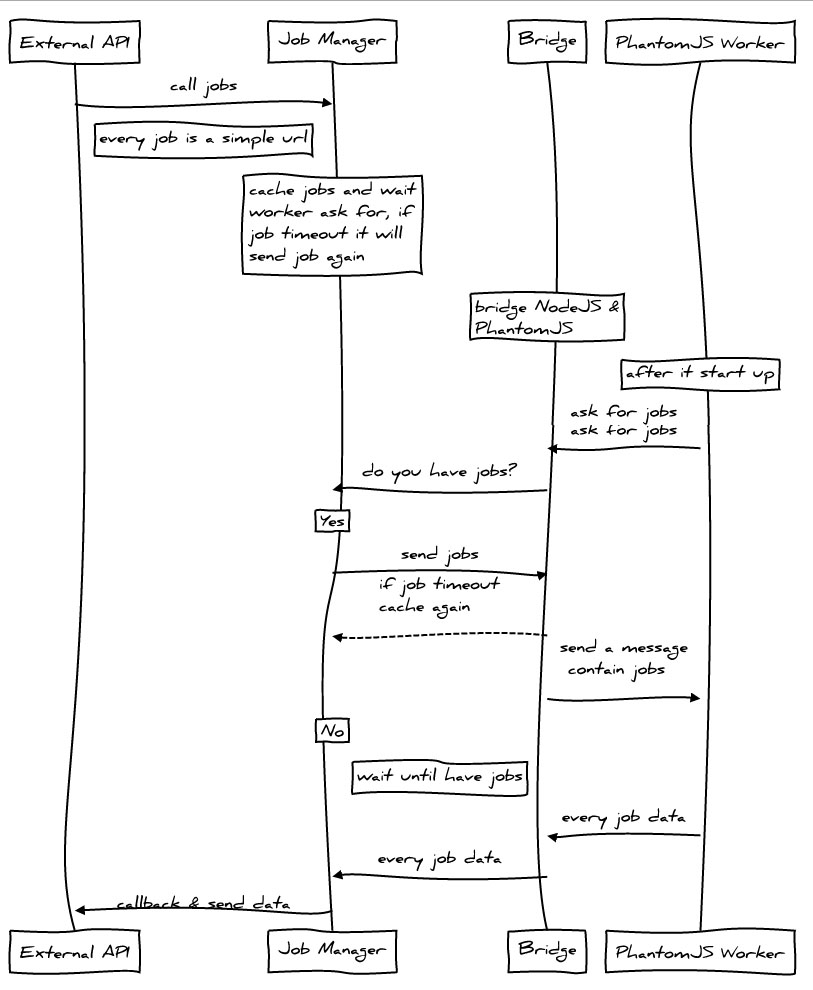
依赖 & 安装
由于PhantomJS 1.9.0+才开始支持Websocket,所以我们先要确定在PATH中的PhantomJS是为1.9.0以上版本。在命令行键入:
$ phantomjs -v
如果能返回版本号1.9.x,则可以继续操作。如果版本过低,或者出现错误,请到PhantomJS官网下载最新版本。
如果你已经安装了Git,或者拥有Git Shell,那么在命令行键入:
$ npm install url-extract
进行安装。
如果没有,那么请在下面的连接下载整个项目:
http://pan.baidu.com/share/link?shareid=1055562065&uk=855675565
一个简单的例子
比如我们要截取百度首页,那么可以这样:
module.exports = (function () { "use strict" var urlExtract = require('url-extract'); urlExtract.snapshot('http://www.baidu.com', function (job) { console.log('This is a snapshot example.'); console.log(job); process.exit(); }); })();
下面是打印:
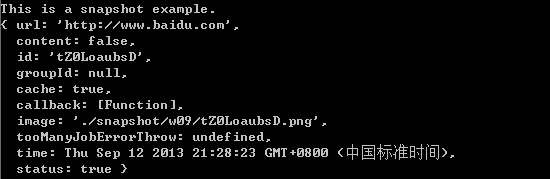
其中,image属性就是截图相对于工作路径的地址。我们可以使用Job的getData接口来得到更清楚的数据,例如:
module.exports = (function () { "use strict" var urlExtract = require('url-extract'); urlExtract.snapshot('http://www.baidu.com', function (job) { console.log('This is a snapshot example.'); console.log(job.getData()); process.exit(); }); })();
打印就变成了这样了:

image表示截图相对于工作路径的地址,status表示状态是否正常,true代表正常,false代表截图失败。
更多例子请参见:https://github.com/miniflycn/url-extract/tree/master/examples
主要API
.snapshot
url快照
- .snapshot(url, [callback])
- .snapshot(urls, [callback])
- .snapshot(url, [option])
- .snapshot(urls, [option])
url {String} 要截取的地址
urls {Array} 要截取的地址数组
callback {Function} 回调函数
option {Object} 可选参数
┝ id {String} 自定义url的id,如果第一个参数是urls,此参数无效
┝ image {String} 自定义截图的保存地址,如果第一个参数是urls,此参数无效
┝ groupId {String} 定义一组url的groupId,用于返回时候辨认是哪一组url
┝ ignoreCache {Boolean} 是否忽略缓存
┗ callback {Function} 回调函数
.extract
url信息抓取,并获取快照
- .extract(url, [callback])
- .extract(urls, [callback])
- .extract(url, [option])
- .extract(urls, [option])
url {String} 要截取的地址
urls {Array} 要截取的地址数组
callback {Function} 回调函数
option {Object} 可选参数
┝ id {String} 自定义url的id,如果第一个参数是urls,此参数无效
┝ image {String} 自定义截图的保存地址,如果第一个参数是urls,此参数无效
┝ groupId {String} 定义一组url的groupId,用于返回时候辨认是哪一组url
┝ ignoreCache {Boolean} 是否忽略缓存
┗ callback {Function} 回调函数
Job(类)
每一个url对应一个job对象,url的相关信息由job对象存储。
Field
- url {String} 链接地址
- content {Boolean} 是否抓取页面的title和description信息
- id {String} job的id
- groupId {String} 一堆job的组id
- cache {Boolean} 是否开启缓存
- callback {Function} 回调函数
- image {String} 图片地址
- status {Boolean} job当前是否正常
Prototype
- getData() 获取job的相关数据
全局配置
url-extract根目录中的config文件可以进行全局配置,默认如下:
module.exports = { wsPort: 3001, maxJob: 100, maxQueueJob: 400, cache: 'object', maxCache: 10000, workerNum: 0 };
- wsPort {Number} websocket占用的端口地址
- maxJob {Number} 每个PhantomJS线程可并发worker数
- maxQueueJob {Number} 最大等待工作数量,0表示不限制,超过该数量,任何工作都直接返回失败(即status = false)
- cache {String} 缓存实现,目前只有object实现
- maxCache {Number} 最大缓存链接数
- workerNum {Number} PhantomJS线程数,0表示和CPU数量相同
一个简单的服务例子
https://github.com/miniflycn/url-extract-server-example
注意,需要安装connect和url-extract:
$ npm install
如果你下载了网盘的文件,那么请安装connect:
$ npm install connect
然后键入:
$ node bin/server
打开:
查看效果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号