为什么要使用分布式锁(通过redis实现)
如果需要使用到缓存机制,那就存在着这三个问题:
* 1、缓存穿透问题:(全部访问redis中不存在的信息),解决方式:在redis中将数据库中没有的数据暂时赋值为null
* 2、缓存雪崩问题:(redis中的key在同一时间大幅度的过期),解决方式:在redis中存入数据的时候,传入一个随机值作为存活时间
* 3、缓存击穿问题:(在大量请求访问一个高频词汇的时候,这个信息突然过期了),解决方式:通过在数据库查询的时候添加分布式锁可以解决
在这里我们重点谈一下缓存击穿问题,他的解决方案就是使用分布式锁。
再出现缓存击穿问题的时候,redis中存放的缓存突然过期了,如果不使用任何机制的话,就会导致大量请求去访问数据库,从而使得数据库压力骤然增大,甚至导致宕机。
如图所示:
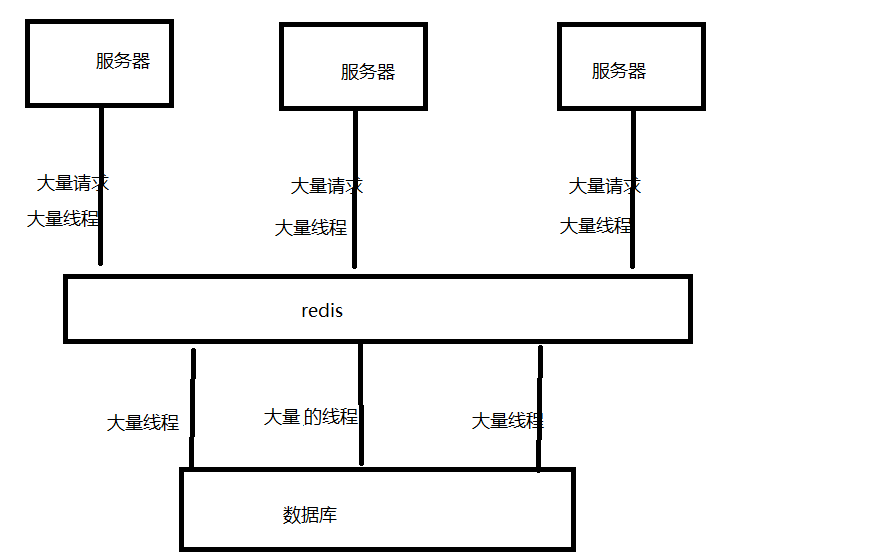
如果我们使用分布式锁,就会形成以下效果:
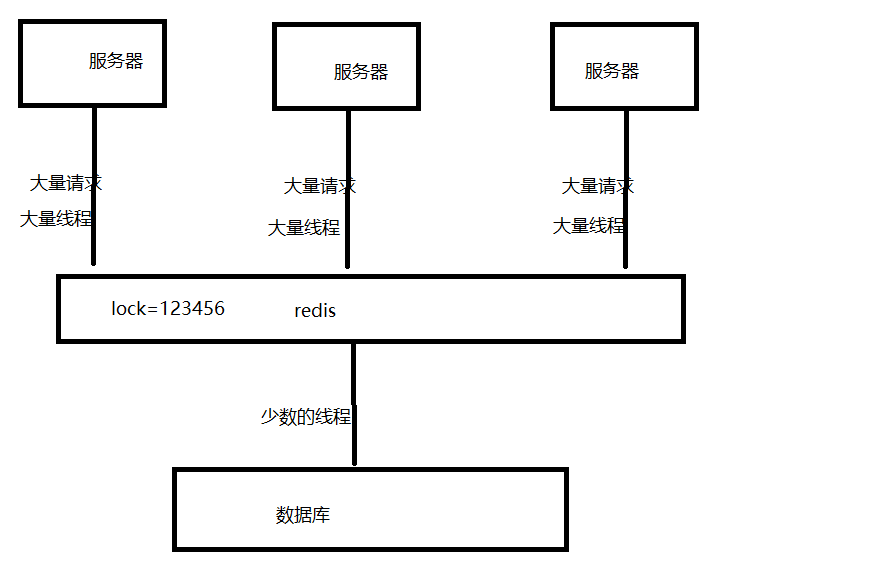
由此可以看出,使用分布式锁可以大量减少访问数据库的次数,降低数据库的压力。
分布式锁的机制:
就是在redis中设置一个锁(一对键值对),只有在当前线程获取到锁的时候才会执行访问数据库的操作,在执行完相应的查询操作之后,需要将锁进行释放,在设置锁和释放锁的时候需要原子性问题,可通过lua脚本进行实现。
通过redisson实现分布式锁:
代码如下:
引入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.15.5</version>
</dependency>
public String test() {
//创建一个锁的对象,锁与锁之间的区分就在于所得名字
RLock lock = redisson.getLock("lockName");
String result="";
try {
//进行一些操作(例如查询数据库中的信息)
//进行加锁操作,这是一个阻塞等待的方式,只有获取到锁之后,才会继续往下执行
lock.lock();//在加完锁之后,会自动自旋去去获取锁,当获取到锁之后,继续往下执行
result = doSomeFromDB();
} finally {
//通过lock进行解锁操作
lock.unlock();
}
return result;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号