java学习笔记
定义数组
1. 整形数组,char float double 等和int格式相同
int [] <数组名>=new int [need size];
2.定义字符串数组
String <数组名>;
<数组名>={"little shark!"};
3、continue表示遇到continue之后本次循环结束,在Continue后面的Java语句不再执行,直接进入下一次循环;continue可以指定某个循环体,前提是
,这个循环体要先定义,如:
MyFor:for(int a;a<10;a++)
{
if(a==6){
continue MyFor;
}
}
4、当要表示一个long类型的整数时,应该在数字后面添加L(可以是小写l,但推荐大写L),因为在Java语言中,整数默认识int类型的。
5、计算机存的数据全都是以这个数的补码形式存放在计算机中。
6、java中的方法就是c语言中的函数。
7、方法名的首字母大写其余小写。
8、面向对象和面向过程的区别:
*面向过程:是由大量的因果关系共同构成一个系统,耦合性非常强,拓展力比较弱。(比如集成显卡,是刻在主板上的,与主板不可分割)
*面向对象:只在乎每个对象(结构体)的功能是什么。是由多个对象组合起来构成一个系统,耦合性较弱,拓展力强。(比如独立显卡,可以任意拆卸)
9、构建方法的作用:
1、创建对象
2、初始化对象
10、this里存放的是当前这个对象的地址。
11、构建方法是可以重载的。
12、当要操作的是对象的时候,不能加static。
13、Java.util.Scanner可以重复使用。
14、java中继承就是将一个类里面的东西复制到需要继承的那一个类,被继承的那个类叫做父类、基类、超类、superclass。需要继承的那个类叫做子类、派生类、subclass。
注意:1、在Java语言中,不允许同时继承很多类,一次继承只能继承一个类。
2、在Java语言中,只有私有的(private)和构建方法不能被继承,其它的都能被继承。
3、虽然java语言中只支持单个继承,但可以间接继承,例如:
class A extends B{
}
class B extends C{
}
值得注意的是,有的时候方法会在继承的时候被覆盖。
4、java语言中,假设一个类没有显示继承任何类,则该类默认继承javase库当中提供的Java.lang.object类。
15、创建对象
类名 a=new 类名();<构造方法名()>
16、调用含有static关键字的方法:
类名.方法名
17、调用不含static关键字的方法:
必须要创建一个对象,后引用调用
引用.方法名
18、this关键字是存在对象的时候使用,表示当前对象的地址,(与引用里存放的地址相同),this在用来区分局部变量和实例变量的时候不能省略,当this(参数)(表示调用某个类本身的构造方法)出现在构造方法中的时候,只能放在第一行,否则会报错。
例如:
Public person (int age ,String name ,int Account){
This(age,name); à调用下面这个构造方法
This.Account=Account; à赋值
}
Public person(int age.String name){
This.age=age; à赋值
This.name=name; à赋值
}
19、当出现一个类是,java会自动生成一个不带形参的构造器(无形参的构造方法),可使用它来创建对象,当你写入一个带参数的构造器时,自动生成的不带参数的构造器会消失。
20、构造方法(也叫构造器、构造函数)的作用时创建对象和将对象初始化,(注意:构造方法的方法名必须和类名相同),public static 构造方法名(<可带参数,可不带参数>){
}
21、对于 类名 a=new 类名() 的理解,就是创建一个 类名 类型的对象。
22、在运行时,class文件会存放在方法区中,局部变量存放在栈内存中,成员变量(实例变量)存放在堆内存中,对象会存放在堆内存中。
23、在类体中,方法名外定义的变量叫做实例变量(成员变量),使用时,需要创建对象,使用方法为 引用.实例变量。
24、static级别的变量(静态变量)等同于类级别,当在类加载的时候就会分配内存,不需要创建对象,静态变量存放在方法区当中,使用时为 类名.静态变量名。当每个对象都有一个相同的属性时,且每个对象的这个属性都相同时,使用static(静态变量),当每个对象都有这个属性,但每个对象的这个属性都不相同时,使用成员变量。
25、静态代码块(会在类加载的时候执行且只执行一次,执行在main方法前,这是对于程序员来说比较特别的一个时期)
格式:
static{
java语句
java语句
……}
}
一个类中可以有多个代码块。
26、实例代码块(在执行构造方法(包括系统自动生成的无形参的构造方法)之前执行,当没有new对象时不会执行实例代码块,这也是对于程序员来说比较特殊的一个时期)
格式:
{
Java语句
Java语句
….
}
27、main方法也可以使用方法重载。
28、方法覆盖在什么情况下使用:
当子类继承的父类时,父类中的代码已经不能满足子类的业务需求时,子类有必要将
类的代码进行重新编写,这个重新编写的过程叫做方法覆盖或叫做方法重写;方法覆盖发生在具有父子类关系的类中,而方法重载是发生在同一个类中,须注意区别,在方法重写时需要注意,类型名、返回值、形参表、方法名必须和父类相同,如果和父类不相同就不会被覆盖住,还是执行父类继承的代码,再重写时,访问权限可以更高,不能降低(public不能降为private);在重新编写时抛出异常不能增加,只能减少。
29、输出字符串数组的时候可以定义一个字符串变量进行输出。如:
String[] a={“xiao”,”huang”,”ren”,”ai”,”xiang”,”jiao”};
for(String b : a){
System.out.println(b);
}
这样写就可以达到将a字符串数组分别输出。
30、关于多态:举例:
30.1、:animal和cat、bird的关系:
Cat继承animal
Bird继承animal
Cat和bird没有任何继承关系。
30.2、关于多态中涉及到的几个概念:
*向上转型(upcasting)
子类à父类
又被称为自动转型。
*向下转型(downcasting)
父类à子类
又被称为强制类型装换。【需要添加强制类型转换符】
***注意:无论是向上转型还是向下转型,两个类型之间必须存在有继承关系。(没有继承关系编译器会编译报错)
30.3、java语法中是允许 父类型引用指向子类型对象。
举例:
Cat extends Animal
在创建对象的时候:
Animal a=new Cat();(这种语法:父类型的引用指向子类型的对象)
值得注意的是,java程序永远分为编译阶段和运行阶段,在编译时,在这里的引用时Animal类型的,他只能引用Animal.class文件里的实例方法,不能访问Cat.class文件里的实例方法(编译器只能看表面,比较单纯,编译阶段是静态绑定,编译阶段绑定);但是,他真正创建的对象时Cat类型的对象,所以,在运行时,他执行的还是在Cat.class文件里的跟Animal继承过来的实例方法(运行阶段是动态绑定,运行阶段绑定)。(某个类的对象只能访问这个类里的方法)。
向上转型举例:
Animal a=new Cat();(向上转型)
向上转型只要编译通过,运行就不会有问题。
向下转型举例:
Animal a1=new Cat();
Cat a2= (Cat) a1;(因为a1是属于Animal类型的引用,Animal对于Cat来说是父类,所以,当Animal的引用或对象要转型为Cat类型的时候需要加强制转换符)
注意:在向下转型的时候,多数会发生编译通过,运行不通过的例子。
原因是这两个类之间没有任何的继承关系,会出现著名的异常:
Java.lang.classCastException
为此,在进行向下转型的时候,记得采用instanceof运算符(是运算符,不是方法),返回值是boolean类型。
使用举例:
A instanceof Animal
如果返回值是true
表示a这个引用指向对象是Animal类型
如果返回值是false
表示a这个引用指向对象不是Animal类型
多态在实际开发中的作用:
1、 降低程序的耦合度,提高程序的拓展力
能使用多态就多使用多态
核心:面向抽象编程,不要面向具体编程。
31、 java语言中的final关键字:
1、 final是一个关键字
2、 final修饰的类无法被继承
3、 final修饰的方法无法被覆盖
4、 final修饰的变量一但赋值后,不可重新赋值(只能赋值一次)
5、 final修饰的实例变量(成员变量)(没有加final的实例变量在没有赋值时系统会自动赋值为0,但加了final关键字的实例变量必须由程序员自己赋值,系统不会自动赋值。必须手动赋值。)
6、 final修饰的引用一但指向某一个对象之后,他不能再重新指向另一个对象。被指向的对象无法被垃圾回收器回收。
32、 常量的定义方法:
Public static final 类型 常量名=值 ;
(java语法中要求常量名全部大写,每个单词用下划线连接,垃圾回收器不会释放常量)
33、 package和import:
语法:
package +包名;
包名的命名规范:
公司的域名倒序+项目名+模块名+功能名;
这样重名的机率较低。
包名要求全部小写,包名也是标识符,必须遵守标识符命名规则。
一个包将来对应一个目录(目录之间使用 . 隔开)
使用package机制后,运行时,类名会变化为 包名.原来的类名,还必须将生成的class文件放在指定的文件夹下(文件夹目录看包名)才能运行成功。
另外一种方式 java -d 要放的位置路径 编译文件的路径
(这种方法会在指定存放的位置在生成和java文件中包名相关的文件夹)
Import:
Import语句用来导入其他类,同一个包下的类不需要导入,不在同一个包下的类需要手动导入。
语法格式:
Import +类名;
或者
Import +包名.* (这里的*是通配符,表示导入所有的文件)
Import语句需要编写在package语句之下,class语句之上。
在Java中,java.lang.* 不需要手动导入,这是Java语言的核心类,不需要手动导入;
其他的必须手动导入,如(java.util.Date)这就需要导入。
34、 访问控制符:(控制符可以修饰类、方法、变量等…)
Public :表示公开的,在任何位置都可以访问。
Private :表示私有的,只有在这个类中才能访问。
Protected :同包下可以访问,(继承中)子类(子类可以不是同包)可以访问
(缺省,可直接不写):只能在同包下访问
省略和protected的区别就在于子类能不能访问
访问控制符的范围:
Private < (缺省)< protected < public
类只能是public和(缺省有的叫default)修饰符进行修饰 【内部类除外(在类里面再定义一个类)】
35、 super:
1、 super只能出现在实例方法和构造方法中
2、 super不能用在静态方法中
3、 super大部分情况下是可以省略的
4、 super只能出现在构造方法第一行,通过当前的构造方法去调用父类中的构造方法,目的是为了在创建子类对象的时候,先初始化父类型特征
5、 super()表示通过子类的构造方法去调用父类的构造方法
模拟现实世界中的这种场景:要有儿子,现有父亲
重点:
当一个构造方法的第一行,既没有this()又没有super()的话,系统会自动在构造方法第一行添加super(),表示通过当前子类的构造方法去调用父类的构造方法,所以,在父类中的构造方法必须存在无参数的构造方法。【this()和super()不能共存,他们都只能出现在构造方法的第一行】
在java中,无论你创建什么对象,最后都会调用object类,因为当没有this关键字和super关键字时,系统会自动生成super(),并且,当没有手动继承(extends)时,系统会自动继承object类。(object类中的object无参数构造方法处于栈顶处,最后调用,最先出去)
36、 在Java语法中,允许在子类中出现和父类同名或同属性的变量。
37、 如果父类中和子类中有同名属性,并且希望在子类中访问父类的特征,super.不能省略。
Java语法中,就靠this关键字和super关键字区分父类和子类的同名属性。
This.name à当前对象的name属性
Super.name à当前对象的父类特征的name属性
Super不是引用,他不保存地址,也不指向对象,他只是代表当前对象的父类的属性特征,不能像this关键字那样直接输出他内部保存的值。
使用super.访问父类中的私有属性是访问不了的,可以间接使用super.set或者super.get方法对父类特征进行访问和赋值。
38、 抽象类:
1、定义:抽象类是类和类之间具有共同特征,将这些具有共同特征的类进一步抽象形成了抽象类。
2、抽象类因为组成的部分是类,类在现实世界中不存在,所以不能在抽象类中创建对象(无法实例化)。
3、抽象类和抽象类如果还有相同的特征,还可以继续抽象。
4、抽象类属于引用数据类型。
5、抽象类的语法:
(修饰符列表) abstract class 类名{
类体……;
}
6、 抽象类是用来子类继承的。
7、 Final和abstract不能联合使用。(abstract就是用来继承的)。
8、 抽象类虽然不能创建对象但是抽象类具有构造方法,这个构造方法供子类使用。(因为子类里会存在super())。
9、 抽象类中关联到抽象方法(但是抽象类中不一定要有抽象方法,有抽象方法一定出现在抽象类中),抽象方法表示没有实现的方法,没有方法体的方法
10、 抽象方法的语法:
Public(访问权限关键字) abstract 返回类型 方法名() ;
因为没有方法体(在非抽象的子类中,需要方法重写,如果继承的子类也是抽象类,那么可以不用方法重写,******抽象方法只能出现在抽象类中),所以不能写大括号
抽象方法的特点:
1、 抽象方法没有方法体,以分号结尾(它是一个抽象出来的)
2、 修饰符列表中有abstract关键字
11、 抽象类中可以存在普通方法,需要用子类创建的对象进行引用才可以使用。
12、 抽象类中也可以使用多态语法,但实际创建的类型是普通类的类型。
39、 接口:
1、 接口是一种引用数据类型(接口名.<抽象方法名或者常量名>),接口通常描述的是行为动作。
2、 接口是完全抽象的,也不能创建对象。(抽象类是半抽象的)(interface是一种特殊的抽象类,在生成时,生成的还是class文件)
3、 接口的定义和语法:
定义:
【修饰符列表】 interface 接口名{
}
4、 接口是特殊的类,一个接口可以继承多个接口(,仅限于接口,中间用英文逗号隔开),例如:
Interface A{
}
Interface B{
}
Interface C extends A,B{
}
5、 ****接口中,只有两种东西(没有其他内容):
1、 抽象方法(当没有写abstract时程序也不会报错,因为在接口中,只能存在一种方法———>抽象方法)
2、 常量
6、 接口(interface)中,所有的元素的访问权限都是公开的(public)
7、 接口中的抽象方法中的public abstract可以省略(接口中只存在常量和抽象方法,所以不会冲突),编译时系统会自动加上。
8、 接口中的常量中的public static final 也是可以省略的,后面编译时系统会自动加上。
9、 抽象方法不能有方法体,不能有静态方法。
10、******类与类之间叫做继承(用extends关键字),类(普通类和抽象类)与接口之间叫做实现(用implements关键字)。可以看在定义时,使用的关键字是否相同,如果相同,类如都是class(或者都是interface)来定义的,在这些类之间就使用extends,如果是不同的,举例:一个是用class来定义类的,一个是用interface来定义的,这两个之间就使用implements。
11、当一个非抽象类去实现接口的时候,必须重写接口中的全部抽象方法。
12、使用了接口语法也是可以用多态的(具体看interfaceTest.java)
13、*****一个类(包括抽象类)可以实现多个接口。接口和接口之间是支持多继承的,类和接口之间是支持实现多个的,类和类之间不支持多继承。
14、*********接口与接口之间,在没有继承关系的时候,可以实现强制转型,但是,在当转型的对象的引用与对象的类型不一致时,在运行时,会报错,只有当要转型的引用和对象的类型一致时,才能运行成功(示例见interfaceTest);类与类之间,只有存在继承关系的时候才能强制转型。(在向下转型的时候养成好习惯,要用instanceof运算符进行判断)
15、extends和implements可以共存,当extends和implements同时出现的时候extends写在前面,implements卸载后面。
40、接口在开发中的作用:
1、接口在开发中的作用类似于多态在开发中的作用,常说的面向抽象编程其实就是面向接口编程,有了接口就有了可插拔,可插拔表示拓展力很强,耦合度低。(类似于usb接口),符合ocp原则。
2、接口的使用离不开多态,因为接口没办法创建对象,这两者一起使用,能降低耦合度。
3、任何一个接口都有调用者和实现者,接口的作用就是将调用者和实现者的关系解耦合,调用者面向接口调用,实现者面向接口实现。
41、is… a… has…a… like…a… :
1、is a :
Cat is a animal。
凡是满足is a的关系,表示“继承关系“
A extends B
2、has a:
I has a pen
凡是满足has a关系的表示“关联关系”
关联关系同常以“属性”的形式存在
A{
B b;
}
3、 like a:
Cooker like a Menu。
凡是满足lilke a关系的表示“实现关系”
实现关系通常是让类去事项接口。
A implements B
42、抽象类和接口的区别:
1、抽象类是半抽象的,接口是完全抽象的
2、抽象类中可以含有普通方法、抽象方法和构造方法,接口中只能含有抽象方法。
3、抽象类与类之间只能单继承,接口与接口之间可以多继承
4、一个类可以实现多个接口,一个类只能继承一个抽象类
5、接口中只允许出现常量和抽象方法。
注意:在以后开发中,接口比抽象类用的多,抽象类用的比较少,接口一般是对行为进行抽象。
43、String类中的equals方法和toString已经被重写了,不需要再重写了。
44、当用System.out.println输出引用时(System.out.println(引用)),系统会自动生成.toString
方法,String类中的equals方法和toString方法已经被sum公司重写过了,不需要我们再去重写了,但在其它类中,我们需要重写equals方法和toString方法。
45、java中什么时候用==来判断相等,什么时候用equals方法来判断相等:
Java中,判断基本数据类型的时候用==来判断是否相等
Java中,判断引用数据类型的时候用equals方法来判断是否相等
46、Object类中的finalize方法是不需要程序员调用的,它的访问权限为protected,它的作用是在一个Java对象即将被垃圾回收器回收的时候被垃圾回收器调用的方法,这是Sum公司给程序员提供的一个特殊时间段(对象即将被回收),因为finalize方法体中没有Java语句,所以在没重写finalize之前,对象被回收不会有任何程序运行,但如果重写了finalize方法后,在对象被回收的时候就会先执行finalize方法体中的Java语句。
47、Object类中的hascode方法的返回值类型时int类型,它的作用是将对象的内存地址根据哈希算法得到一个值后输出,可以近似的把输出的值看作对象的地址。
48、匿名内部类(属于局部内部类的一种,没有类名):
1、内部类:在类的内部又定义了一个新的类,被叫做内部类。
2、内部类的分类:
静态内部类:类似于静态变量。
实例内部类:类似于实例变量。
局部内部类:类似于局部变量。
3、匿名类内部类的作用可以是接口的实现,例如:
Interface A{
Int sum(int b ,int c);
}
Class Mymath{
Public int Mysum(A a,int b,int c){
a.sum(int c,int b);
}
}
在创建对象的时候可以这样写:
Main方法中:
Mymath d=new Mymath();
d.Mysum(new A() {
Public int sum(int b ,int c){
Return b+c;
}
})
这样写看似用接口A直接创建了对象,但是,就是因为有匿名内部类,这个类对接口中的抽象方法进行了实现,所以并不是接口可以创建对象了,接口中并没有构造方法,记住,抽象的类不能创建对象。
4、 程序中不建议使用匿名内部类,使用匿名内部类会使程序的可读性变差,因为没有名字所以代码不能循环使用。
49、
1、数组是一种引用数据类型,数组默认继承Object,数组中可以存放基本数据类型,也可以存放引用数据类型,存放引用数据类型的时候储存是对象的地址。
2、数组存放在堆内存中。(引用数据类型存放在堆内存中)
3、数组一旦被创建后,长度不会改改变。
4、数组要求存放的数据类型相同
5、每个数组对象都具有length属性(java自带的),用来获取数组中的元素个数。
6、和C语言一样,数组中的元素的内存地址是连续的。
7、数组名(或第一个数组元素)是数组的内存地址。(数组名的地址==第一个元素的地址)
8、数组中存放100个元素和数组中存放100万个元素,查询或者检索时的效率是一样的,他是通过数学表达式进行计算,计算出所要元素的内存。(同过起始地址、数据类型就可以算出指定元素的内存)。
9、数组中每个元素所占内存相同。
数组的优点:
1、 数组中存放100个元素和数组中存放100万个元素,查询或者检索时的效率是一样的,他是通过数学表达式进行计算,计算出所要元素的内存,可以直接定位。(同过起始地址、数据类型就可以算出指定元素的内存)
数组的缺点:
1、 由于数组元素的内存是有顺序的,这就导致想要在数组中添加或者删除一个元素时,会有让后面或者前面的元素向前或者向后移动的操作(效率较低,除了最后一位元素)。
2、 数组不能存储大数据量,因为很难在内存空间上找到很大一块连续的空的内存空间。
50、
1、java中的main方法是由JVM进行调用,在JVM调用时,会自动传入一个String数组作为参数,JVM传入的数组参数的长度时0(表示数组创建了,但里面没有东西),但不是null,传过来的String数组中没有东西。
2、什么时候main方法中的String[] args中有值呢:
其实,这个数组是留给用户的,用户可以在控制台输入参数,这个参数会自动转换为“String [] args ” ,例如:
在控制台输入 java test1 abc def
这个时候,JVM在调用main方法中时,会将“abc” 、“def” 根据空格的方式进行分离{“abc”,“def”},分离后,会自动放的String[] args 数组中
所以,main方法中的String[] args主要是用来接收用户参入的参数的。
3、 在数组中也是有多态语法的具体看ArrayTest01.java
4、 关于Java中数组的扩容(将长度较小的数组复制到长度较大的数组中):
System.arraycopy()方法可以实现数组的克隆
具体看System.arraycopytest01
5、 当数组中保存的变量是引用的时候,数组中每个元素保存的是该对象的地址。
51、二维数组:
1、二维数组是一个特殊的一维数组,特殊在于,她的每一个元素都是一个一维数组。
2、二维数组的第一个元素是二维数组的起始地址(也就是第一列这个一维数组的起始地址)。
3、二维数组的第一列的第一个元素是该行这个一维数组的起始地址。
52、String:
1、所有用双引号括起来的都存储在 “方法区” 中的 “字符常量池” 中。
目的是提高效率(在开发中,字符串用的太频繁)。
2、 字符串一旦产生就不可更改,例如:
String a=”abc”;
不能将abc更改为abcd,java中不允许。
3、 凡是new的对象都在堆内存中开辟地址(对象都在堆内存中)。
4、 字符串字面值存储在方法区中的字符串常量池中,字符串对象是在堆内存中,他的值是字符串变量池中某个字符串字面值的地址。(局部变量是存储在栈内存中的,实力变量是存储在堆内存中)。
例如:
String s1=”abcdef”;
String s2=”xy”;
String s3=new String(“xy”);
这三个代码的内存图如下:

String s1=”abc”;
其实是s1这个引用中保存的是字符串对象“abc”的内存地址
不是直接保存“abc”
5、比较字符串时不能使用双等号进行比较“==”(这个比较的是内存地址) ,要使用equals进行比较(这个比较的是引用指向的对象的内存地址,也就是String字符串的数据或者叫比较字符串的字面值)。
53、判断数组的长度是属性,判断字符串的长度是方法。(需要注意)
54、StringBuffer相关知识:
1、StringBuffer可以减少字符串拼接中对象的创建,减小方法区中字符串常量池的压力,例如:在字符串常量池中有“a”,想拼接成“ab”,用加法连接的话会产生三个对象:“a” “b” “ab” 比较浪费空间,使用 StringBuffer中的append方法就可以减少对象的创建,主要是减少中间的对象(要添加的字符串),例如这里就只会有两个对象在字符串常量池中:“a” “ab” 以后都建议使用append对字符串进行拼接。
2、StringBuffer在无参数创建时,默认的十六个空间的Byte[ ]数组。
3、值得注意的是是,在使用StringBuffer时,要估计好需要的空间大小,多次扩容会降低效率。具体看StringBufferTest01.java
55、StringBuffer和StringBulider的区别:
1、StringBuffer使用synchronized修饰的,这个表示StringBuffer在多线程使用的时候是安全的;而StringBulider没有使用synchronized修饰,所以StringBulider在多线程使用的时候是不安全的。StringBuffer是线程安全的 StringBulider是非线程安全的
56、8中基本数据类型分别具有八种包装类型,八种包装类型属于引用数据类型,父类是Object。(使用场景:一个方法的参数是一个引用类型,我们想将基本数据类型传进去,这就需要将基本数据类型进行包装),这八种包装类型不需要我们写,Sun已经为我们提供了这八种包装类型。
57、八种基本数据类型对应的包装类型类名:
基本数据类型 包装类型类名
byte java.lang.Byte
short java.lang.Short
int java.lang.Integer
long java.lang.Lang
float java.lang.Float
double java.lang.Double
boolean java.lang.Boolean
char java.lang.Character
具体看
58、方法区中还存在一个常量池,叫做整数型常量池,里面保存了【-128~127】之间的任何整数,目的是为了提高效率,因此,在使用integer时,如果存在integer x=【-128~127】之间的整数时,不需要直接new对象,直接将x赋值为相应变量的内存地址,所以,如果两个在【-128~127】之间的integer变量进行比较的时候,使用==可以直接比较它们对应的数值是否相等,因为integer引用变量里保存的都是【-128~127】之间整数的内存地址。
59、String 和int和Integer之间的转化关系:
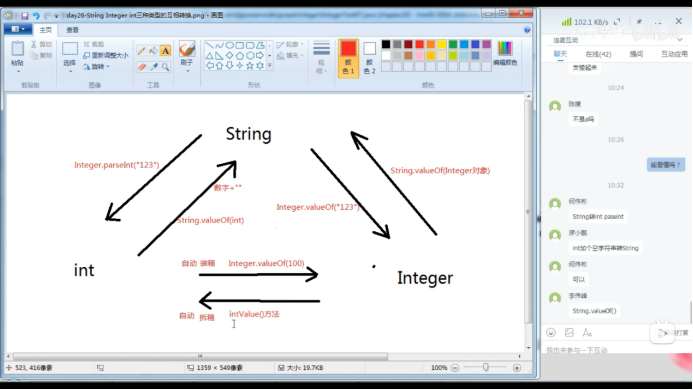
60、异常:
1、异常在java中是以类的形式存在的,每一个异常都可以创建异常对象
2、当运行出现异常的时候,JVM会自动new一个异常对象,并抛出(throw),输出到控制台上。
3、所有的异常的是放生在运行阶段
61、UML:
什么是UML:UML是一种统一的建模语言,一种图标式语言(画图的),只要是面向对象的语言都会有UML。
62、异常的继承结构:
Object下面是Throwable(可抛出的)
Throwable下有Error(不可处理的,直接退出JVM)和Exception(可处理的)
Exception下有两个分支:
Exception的直接子类:编译时异常(受检异常,受控异常)(要求在编译阶段必须将这些异常进行处理,如果不处理,编译器会直接报错)
RuntimeException:运行时异常(未受检异常,非受控异常)(在编译阶段可以处理,可以不处理,原因在于发生的机率较低)
63、编译时异常和运行时异常的区别:
编译时异常相对于运行时异常发生的概率较高。
64、所有的一场都是发生在运行阶段(包括编译时异常和运行时异常)
65、java中对异常的两种处理方式(只有这两种方式):
第一种方式:在方法声明的位置使用throws关键字,抛给上一级。
谁调用就抛给谁,抛给上一级
第二种方式:使用try… catch语句对异常进行捕捉。
如果一个异常一直往上抛,抛给了main方法,main方法继续往上抛,抛个调用者JVM,JVM知道异常后只有一个结果,终止程序。
可以抛出多个异常,并且只能抛出异常本生或者它的父类。
66、try…catch深入:
1、可以有多个catch语句
2、可以是精确的异常类型,也可以是它的父类
3、但使用多个catch语句的时候,需要遵循从小到大的原则(原因在于,父类中已经包含了子类了)
67、throws和try…catch的选择:
如果希望调用者来解决这个异常就采用throws的方法
如果希望直接处理了就采用try…catch的方法进行处理
68、异常在new出来过后,如果没有进行抛出,JVM会把它当作一个普通的Java对象,不会报错,只有当抛出后才会报错。(源代码中new出来的异常对象都是进行抛出了的,所以要对异常进行解决)
69、java中两条重要的语法机制:
1、return语句一定是最后执行的,并且,执行后方法结束
2、方法体中一定是遵循自上而下的顺序进行运行的
70、final finally finalize这三个的区别:
Final是一个关键字,是一个修饰符,表示最终的,被修饰后里面的值不可修改,被修饰类不可被继承,被修饰的方法不可被覆盖。
Finally也是一个关键字,他必须和try连用,不可单独出现,通常用在处理java中的异常
Finalize是一个标识符,他是一个Object中的一个方法,有垃圾回收器GC调用的(作用是在垃圾回收器回收垃圾时留下相应的提示信息,这个提示信息需要手动填写)。
需注意区分
71、自定义异常的方法:
第一步:继承Exception或者RunTimeException
第二部:创建两个构建方法(一个有参数,参数类型为String类型,一个为无参)
72、在以后,都使用异常来处理一些退出等情况。
73、集合
1、集合是一个容器,常见的集合有数组、二叉树、链表、哈希表…
2、集合里面存储的都是地址(集合的元素是引用)
3、集合在java.util.包下(所有的集合类和集合接口都在java.util.包下)
4、不同的集合对应不同的数据结构(数组、二叉树、链表、哈希表…)
5、集合中分为两大类:
第一种是单个方式储存元素:
单个方式储存元素这一类的超级父接口是:java.uitl.Collection
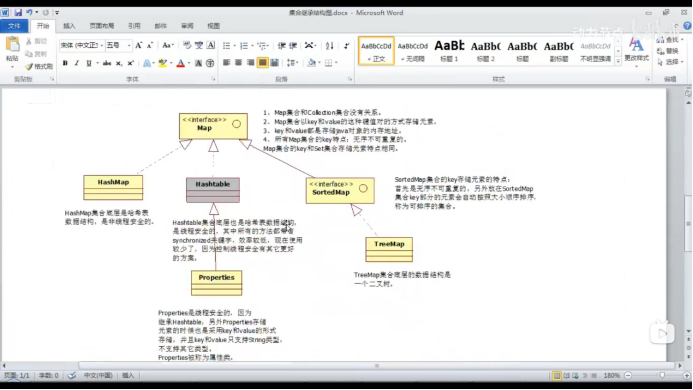
第二种是以键值对的方式储存元素:
以键值对的方式储存元素这一类的超级父接口是:java.uitl.Map
6、集合继承图:
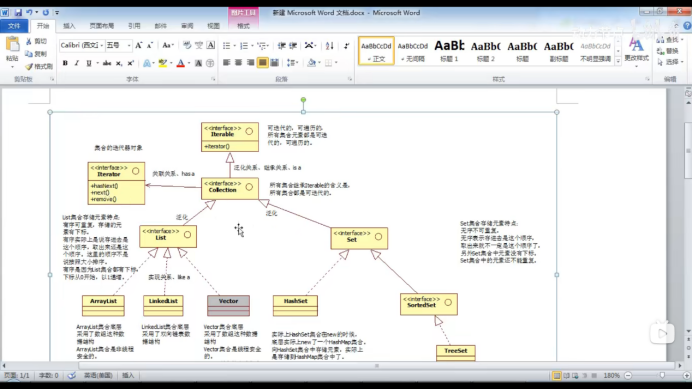
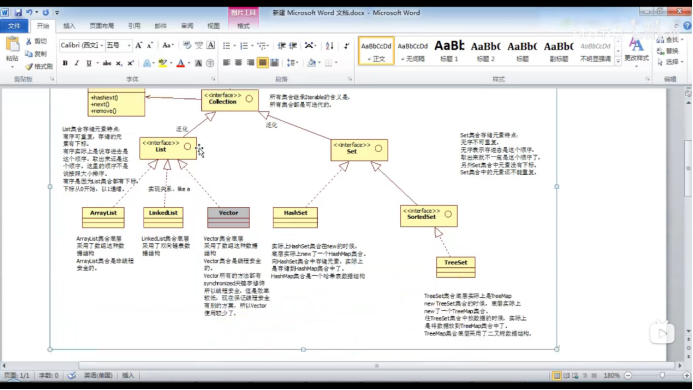
总结:
所有的实现类:
ArrayList:底层是数组(非线程安全)
LinkedList:底层是双向链表。
Vector:底层是数组(线程安全,效率较低,用的较少)。
HashSet:底层是HashMap,放到HashSet集合中的元素等同于放到HashMap集合中的Key部分了。
TreeSet:底层是TreeMap,放到TreeSet集合中的元素等同于放到TreeMap集合中的Key部分了。
HashMap:底层是哈希表
Hashtable:底层是哈希表(是线程安全的,效率较低,用的较少)
Properties(继承Hashtable):是线程安全的,只是Key和Value中只能存储String类型的对象的地址。
TreeMap:底层是二叉树,TreeMap集合中的Key部分因为实现了SortedMap接口,所以可以自动按照大小顺序排序。
集合的特点:
List集合的特点:
有序,可重复
有序:有下标,放进去是什么顺序取出来就是什么顺序。
可重复:放进去了一个1,还可以放进去一个1
Set集合的特点:
无序,不可重复
无序:没有顺序,没有下标,放进去是一个顺序,拿出来就不一定是这个顺序了。
不可重复:放进去一个1就不能再放进去1了。
SortedSet(继承Set)(SortedSet就是SortedMap集合中的Key部分)的特点:
无序,不可重复的,但是可以排序
可排序:可以根据大小顺序进行排序
Map集合中的key部分其实就是一个Set集合
往Set集合中放数据,就是往Map集合中的key部分中放元素。(Set就是半个Map,Set底层就是Map)
74、单链表
1、单链表中的基本单元是节点
2、节点中包含两个属性:
第一属性是 存储的数据
第二属性是 下一个节点的内存地址
75、对Set<Map.Entry<Integer,String>>的理解:
首先,Map.Entry是一个内部类,这个内部类只能存放由<Integer,String>这样成对出现的数据的内存地址;再然后,Set这个类中只允许存储<Map.Entry>类型的数据的内存地址,也就间接的使Set这个类中只能存储<Integer,String>这样成对出现的数据的内存地址。
76、IO:
Input和output都是相对于内存作为参照物
流的分类:
输入流 输出流
字符流(一次读取一个字符,只能读取txt文件) 字节流(一次读取一个字节,可读取任意文档)
凡是以Stream结尾的就是字节流
以reader或者writer结尾的就是字符流(reader字符输入流 writer字符输出流)
77、java语法规定,属性配置文件需要以 .properties结尾
Properties这个类是专门用来存放配置文件内容的一个类。
78、进程和线程:
进程与进程之间是不共享内存的
线程和线程之间堆内存和方法区内存共享,但是栈内存独立,一个线程一个栈。
一个线程一个栈
多个线程(多个栈)共同去完成一个进程,这叫做多线程并发,目的是为了提高效率
多核处理器能够真正做到多线程并发,一个核心处理一个进程
单核处理器不能真正做到多线程并发,但可以给人一种多线程并发的感觉
79、进程的生命周期:
新建状态
就绪状态
运行状态
阻塞状态
死亡状态
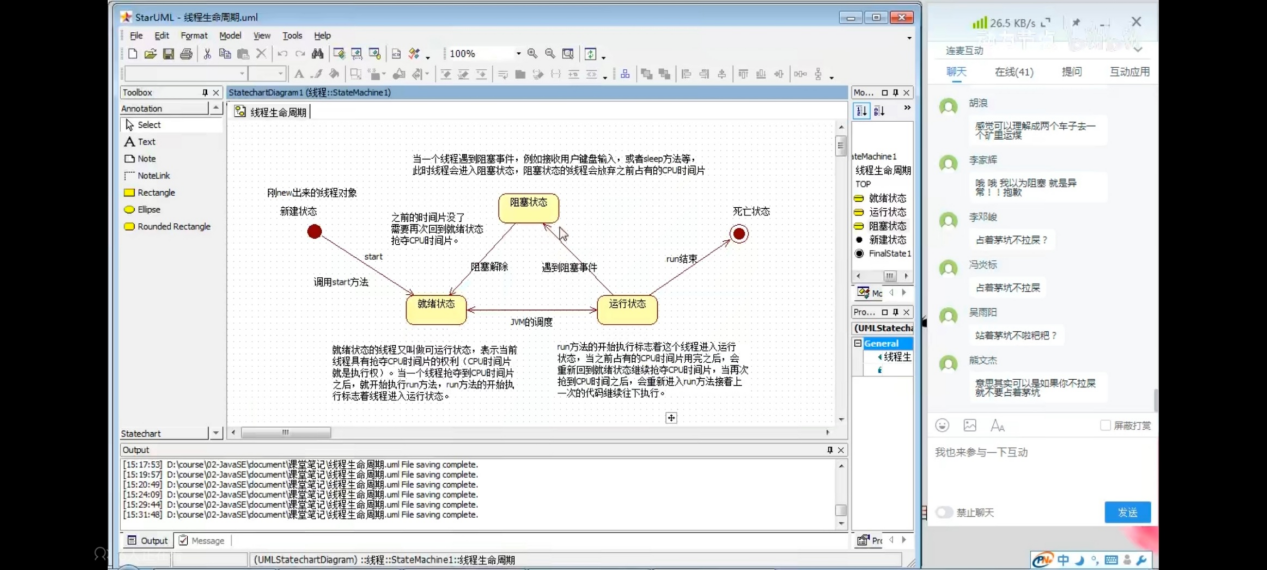
80、多线程什么情况下会出现安全问题:
条件1:多线程并发
条件2:有共享数据
条件三:共享数据有修改的行为
满足这三个条件就会存在线程安全问题
怎样解决线程安全问题?
让线程排队执行,一个执行完了在执行另一个相乘
这种方法叫做线程同步机制
这种方法会降低一定效率,但保证了数据的安全。
什么是异步编程模型:(线程并发)
T1和t2这两个线程各执行各的,谁也不管谁,这样效率较高,但数据的安全得不到保证。
什么是同步编程模型:
T1和t2按照顺序进行执行,第二个必须在第一个执行完了之后再执行,或者在第一个执行之前,第二个线程必须先执行完成,两者发生了等待关系,这样会降低一定的效率,但是数据安全得到了保证。
局部变量不存在线程安全问题,因为每个线程都会有相应的栈内存,栈内存中的数据不共享;静态变量和实例变量存在线程安全问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号