python xpath 获取指定页面中指定区域的html代码
最近一个朋友问我怎么把一个指定区域的内容转成pdf,网上查了一下python里面有个wkhtmltopdf模块可以将str、file、url转成pdf,我们今天不聊怎么转PDF,聊聊怎么获取页面中指定区域的html源码。用到的模块是lxml和requests这两个模块,没有装的小伙伴可以装一下 pip install lxml requests
主要思想是利用xpath获取到指定区域的Element对象,然后再将Element对象传给etree.tostring(),即可得到指定区域的html代码,看一下需求:
1、我们要得到 http://www.w3school.com.cn/ w3c首页中的这个位置的html代码:

看一下页面源码是这样的

2、下面开始编码:
1 from lxml import etree 2 import requests 3 4 res=requests.get('http://www.w3school.com.cn/') 5 tree=etree.HTML(res.content) 6 div=tree.xpath('//div[@id="d1"]')[0] 7 div_str=etree.tostring(div,encoding='utf-8') 8 print div_str
3、结果如下:
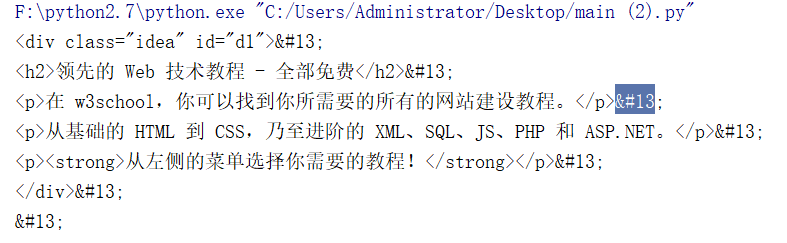
4、成功获取到了指定区域的html代码。
作者:Just-Like
出处:https://www.cnblogs.com/just-do/p/9778941.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
标签:
Python xpath 爬虫



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux glibc自带哈希表的用例及性能测试
· 深入理解 Mybatis 分库分表执行原理
· 如何打造一个高并发系统?
· .NET Core GC压缩(compact_phase)底层原理浅谈
· 现代计算机视觉入门之:什么是图片特征编码
· 手把手教你在本地部署DeepSeek R1,搭建web-ui ,建议收藏!
· Spring AI + Ollama 实现 deepseek-r1 的API服务和调用
· 数据库服务器 SQL Server 版本升级公告
· 程序员常用高效实用工具推荐,办公效率提升利器!
· C#/.NET/.NET Core技术前沿周刊 | 第 23 期(2025年1.20-1.26)