PhpSpider PHP爬虫
1、官网地址
https://doc.phpspider.org/
2、包下载地址
https://github.com/owner888/phpspider
也可以通过composer 进行下载 (两者引用类时有区别)
3、通过命令行去运行(必须)
4、不要删除此注释 否则需要进行其他操作
/* Do NOT delete this comment */ /* 不要删除这段注释 */
5.示例
<?php require_once __DIR__ . '/../autoloader.php'; use phpspider\core\phpspider; /* Do NOT delete this comment */ /* 不要删除这段注释 */ $configs =array( 'name'=>'爬虫',//定义当前爬虫名称 'log_show'=>true,//显示日志调试信息 'input_encoding'=>'UTF-8',//输入编码 //定义数据库 'db_config'=>array( 'host'=>'127.0.0.1', 'port'=>'3306', 'user'=>'root', 'pass'=>'root', 'name'=>'test' ), //定义爬虫爬取哪些域名下的网页, 非域名下的url会被忽略以提高爬取速度 'domains'=>array( 'www.pyxww.com', 'pyxww.com' ), //定义爬虫的入口链接, 爬虫从这些链接开始爬取,同时这些链接也是监控爬虫所要监控的链接 'scan_urls'=>array( 'https://www.pyxww.com/news/yaowen/index.html', ), 'content_url_regexes' => array( "https://www.pyxww.com/news/yaowen/index_\d+.html" ), 'client_ip' => array( '192.168.0.2', '192.168.0.3', '192.168.0.4', ), 'user_agent' => array( "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36", "Mozilla/5.0 (iPhone; CPU iPhone OS 9_3_3 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) Version/9.0 Mobile/13G34 Safari/601.1", "Mozilla/5.0 (Linux; U; Android 6.0.1;zh_cn; Le X820 Build/FEXCNFN5801507014S) AppleWebKit/537.36 (KHTML, like Gecko)Version/4.0 Chrome/49.0.0.0 Mobile Safari/537.36 EUI Browser/5.8.015S", ), //爬虫爬取数据导出 // //'export'=>array( // //'type'=>'csv',//type:导出类型 csv、sql、db // //'file'=>'../data/abc.csv',//file:导出 csv、sql 文件地址,如果不存在文件自动创建 // //), //定义内容页的抽取规则 'fields'=>array( array( 'name'=>"title", //'selector'=>"//div[@class='photolst_photo']//a//img",//豆瓣 'selector'=>"//div[@class='xwt_a']//a", //'selector'=>"//div[@class='content2_left']//div[@class='xwt']//div[@class='xwt_a']//a", 'required' => true,//是否必须 如果是必须而且是空 则此条记录不抓取 'repeated' => true//写上是数组(抓取整个列表页) ,不写是字符串(只抓取第一个) ), array( 'name'=>"content", //'selector'=>"//div[@class='photolst_photo']//a//img",//豆瓣 'selector'=>"//div[@class='xwt_b']", //'selector'=>"//div[@class='content2_left']//div[@class='xwt']//div[@class='xwt_a']//a", 'required' => true, 'repeated' => true//写上是数组(抓取整个列表页) ,不写是字符串(只抓取第一个) ) ), 'export' => [ 'type' => 'db', 'table' => 'test', ] ); $spider =new phpspider($configs); $spider->start();
6、补坑
'repeated' => true//写上是数组(抓取整个列表页) ,不写是字符串(只抓取第一个)
设置参数为true 抓取到的值为:
core/db.php中有修改 305行左右(数据库插入)
$a=[ 'title'=>[ "阳张姓拜祖大典举行", "朱良才调研公安和应急管理工作", "万正峰调研我市安全生产工作" ], 'content'=>[ "aaaaaaa", "bbbbbbb", "ccccccccc" ], 'text'=>[ "11", "22", "33" ], 'tmp'=>[ "ppp", "qqq", "vvv" ], ]; $items_sql=$values_sql=""; foreach ($a as $k=>$ArrValue){ $items_sql .= "`$k`,"; $m= count($ArrValue); } for($i=0;$i<$m;$i++){ $tmp =array_column($a,$i); foreach ($tmp as $v){ $values_sql .= "\"$v\","; } $mmm="),("; $values_sql=substr($values_sql,0,-1).$mmm; } $values_sql = "(".$values_sql; $values_sql = substr($values_sql,0,-2); $items_sql=substr($items_sql,0,-1); $sql="Insert Ignore Into `test` ($items_sql) Values $values_sql"; var_dump($sql);
7、修改过的phpspider
phpspider.exe https://www.aliyundrive.com/s/piL1uHfUYqb 提取码: 75pq
8、结果很成功
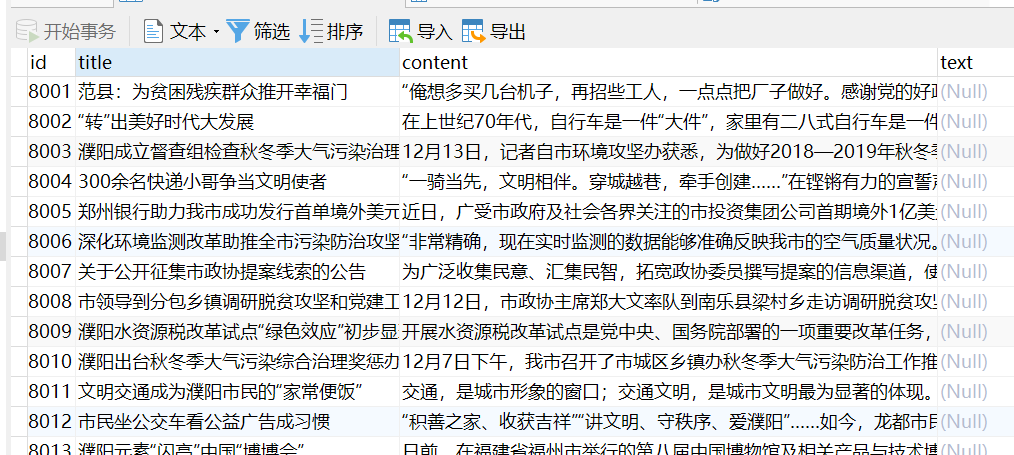
9.测试过程 疯狂抓取豆瓣信息ip被封

10、结果很陈成功。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号