
PyTorch:基础实战
通过真实的实战案例(本文将介绍两个图片多分类问题),我们可以高效地将 PyTorch 入门知识串起来,有助于加深理解、为后续的进阶学习打好基础。
1. FashionMNIST时装分类
FashionMNIST数据集 包含已经预先划分好的训练集和测试集,其中训练集共60,000张图像,测试集共10,000张图像。每张图像均为单通道黑白图像,大小为28*28pixel,分属10个类别。我们的任务是对10个类别的“时装”图像进行分类。

1.1 导入必要的包和设置超参数
这一步是标准操作,几乎不用怎么变动,适用于很多深度学习任务。超参数部分可能需要根据具体情况做一些调整。
import os
import numpy as np
import pandas as pd # 用来读取实验数据,若不读取则用不到;一些内置数据集可以直接通过API获取
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
# 配置GPU, 使用“device”,后续对要使用GPU的变量用.to(device)即可
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu") # 作者只使用了CPU
# 配置超参数,如batch_size, num_workers, learning rate, 以及总的epochs
batch_size = 256
num_workers = 4
lr = 1e-4
epochs = 20
1.2 数据读入和加载
第一种方式:下载并使用PyTorch提供的内置数据集。只适用于常见的数据集,如MNIST,CIFAR10等,PyTorch官方提供了数据下载。这种方式往往适用于快速测试方法(比如测试下某个idea在MNIST数据集上是否有效)
第二种方式:从网站下载以csv格式存储的数据,读入并转成预期的格式。需要自己构建Dataset,这对于PyTorch应用于自己的工作中十分重要。
同时,还需要对数据进行必要的变换,比如说需要将图片统一为一致的大小,以便后续能够输入网络训练;需要将数据格式转为Tensor类,等等。
1.2.1 设置数据变换
# 首先设置数据变换
from torchvision import transforms
image_size = 28
data_transform = transforms.Compose([
transforms.ToPILImage(), # 将shape为(C,H,W)的Tensor或shape为(H,W,C)的numpy.ndarray转换成PIL.Image,值不变; 这一步取决于后续的数据读取方式,如果使用内置数据集则不需要(本来就是PIL.Image,若加入的话,会出现错误)
transforms.Resize(image_size),
transforms.ToTensor() # Converts a PIL Image or numpy.ndarray (H x W x C) in the range [0, 255] to a torch.FloatTensor of shape (C x H x W) in the range [0.0, 1.0]
])
transforms.Resize(Resize the input image to the given size.)
- 参数 size (sequence or int) – Desired output size. If size is a sequence like (h, w), output size will be matched to this. If size is an int, smaller edge of the image will be matched to this number. i.e, if height > width, then image will be rescaled to (size * height / width, size).
1.2.2 内置数据集读入方式
## 读取方式一:使用torchvision自带数据集,下载可能需要一段时间(国内较慢,挂上外网会快一些;若下载过程停止,可以多运行几次,接力完成下载任务)
from torchvision import datasets
train_data = datasets.FashionMNIST(root='./', train=True, download=True, transform=data_transform)
test_data = datasets.FashionMNIST(root='./', train=False, download=True, transform=data_transform)
下载到的文件如下所示:
1.2.3 外部数据集读入方式
csv数据下载链接:https://www.kaggle.com/zalando-research/fashionmnist
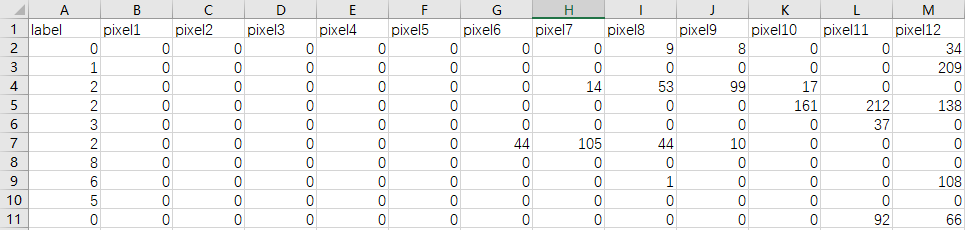
下图是 csv 的内容(每一行代表一个样本,包括图像和标签,其中图像用 28*28 个数值来表示)
class FMDataset(Dataset):
def __init__(self, df, transform=None):
self.df = df
self.transform = transform
self.images = df.iloc[:,1:].values.astype(np.uint8) # astype(np.uint8) 转换为 0-255 的数据格式
self.labels = df.iloc[:, 0].values
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
image = self.images[idx].reshape(28,28,1)
label = int(self.labels[idx])
if self.transform is not None:
image = self.transform(image)
else:
image = torch.tensor(image/255., dtype=torch.float) # 转换为 0-1 的值
label = torch.tensor(label, dtype=torch.long)
return image, label
train_df = pd.read_csv("./FashionMNIST/fashion-mnist_train.csv")
test_df = pd.read_csv("./FashionMNIST/fashion-mnist_test.csv")
train_data = FMDataset(train_df, data_transform)
test_data = FMDataset(test_df, data_transform)
1.2.4 数据载入
在构建训练和测试数据集完成后,需要定义DataLoader类,以便在训练和测试时加载数据
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False, num_workers=num_workers)
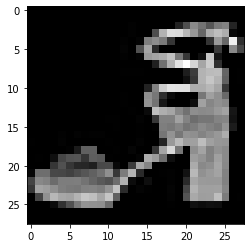
读入后,我们可以做一些数据可视化操作,主要是验证我们读入的数据是否正确
import matplotlib.pyplot as plt
image, label = next(iter(train_loader)) # next() 返回迭代器的下一个项目。next() 函数要和生成迭代器的 iter() 函数一起使用。
print(image.shape, label.shape) # torch.Size([256, 1, 28, 28]) torch.Size([256])
plt.imshow(image[0][0], cmap="gray") # iamge[0][0] 是取值 0-1 的矩阵
1.3 模型设计
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(1, 32, 5),
nn.ReLU(),
nn.MaxPool2d(2, stride=2),
nn.Dropout(0.3),
nn.Conv2d(32, 64, 5),
nn.ReLU(),
nn.MaxPool2d(2, stride=2),
nn.Dropout(0.3)
)
self.fc = nn.Sequential(
nn.Linear(64*4*4, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.conv(x)
x = x.view(-1, 64*4*4)
x = self.fc(x)
# x = nn.functional.normalize(x)
return x
model = Net()
# model = model.cuda() # 作者未使用 GPU,所以不运行这行代码;若有 GPU 的话,则可以运行
# model = nn.DataParallel(model).cuda() # 多卡训练时的写法
1.4 设置损失函数和优化器
criterion = nn.CrossEntropyLoss() # PyTorch会自动把整数型的label转为one-hot型,用于计算CE loss 这里需要确保label是从0开始的,同时模型不加softmax层(使用logits计算)
# criterion = nn.CrossEntropyLoss(weight=[1,1,1,1,3,1,1,1,1,1])
optimizer = optim.Adam(model.parameters(), lr=lr)
1.5 训练和测试
各自封装成函数,方便后续调用
def train(epoch):
model.train()
train_loss = 0
for data, label in train_loader:
data, label = data.to(device), label.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, label)
loss.backward()
optimizer.step()
train_loss += loss.item()*data.size(0)
train_loss = train_loss/len(train_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))
def val(epoch):
model.eval()
val_loss = 0
gt_labels = []
pred_labels = []
with torch.no_grad():
for data, label in test_loader:
data, label = data.to(device), label.to(device)
output = model(data)
preds = torch.argmax(output, 1)
gt_labels.append(label.cpu().data.numpy())
pred_labels.append(preds.cpu().data.numpy())
loss = criterion(output, label)
val_loss += loss.item()*data.size(0)
val_loss = val_loss/len(test_loader.dataset)
gt_labels, pred_labels = np.concatenate(gt_labels), np.concatenate(pred_labels)
acc = np.sum(gt_labels==pred_labels)/len(pred_labels)
print('Epoch: {} \tValidation Loss: {:.6f}, Accuracy: {:6f}'.format(epoch, val_loss, acc))
执行训练和验证代码
for epoch in range(1, epochs+1):
train(epoch)
val(epoch)
# Epoch: 1 Training Loss: 0.673025
# Epoch: 1 Validation Loss: 0.446441, Accuracy: 0.837000
# Epoch: 2 Training Loss: 0.423221
# Epoch: 2 Validation Loss: 0.369954, Accuracy: 0.865500
# ...
# Epoch: 19 Training Loss: 0.185280
# Epoch: 19 Validation Loss: 0.224482, Accuracy: 0.918800
# Epoch: 20 Training Loss: 0.176032
# Epoch: 20 Validation Loss: 0.224660, Accuracy: 0.917700
1.6 模型保存
训练完成后,可以使用torch.save保存模型参数或者整个模型,也可以在训练过程中保存模型
save_path = "./FahionModel.pkl"
torch.save(model, save_path)
2. kaggle 果蔬分类
数据集地址:kaggle 果蔬分类数据集

这个任务相对更难,图像要分成 36 类,而且不再是单通道黑白图像,而是三通道 RGB 图像。数据集更大,原始图片的大小(长和宽)不一致。为了更好地解决这个问题,我们将使用 预训练模型 + 自有数据集 的方式训练最终的模型。本任务的代码与上一个任务大体类似,在不同的部分本文会详细说明。
2.1 导入必要的包和设置超参数
import os
import torch
import timm # PyTorch Image Models (timm)是一个图像模型(models)、层(layers)、实用程序(utilities)、优化器(optimizers)、调度器(schedulers)、数据加载/增强(data-loaders / augmentations)和参考训练/验证脚本(reference training / validation scripts)的集合,目的是将各种SOTA模型组合在一起,从而能够重现ImageNet的训练结果。
from torchvision import transforms
import numpy as np
import torch.nn as nn
import warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
%matplotlib inline # 表示将图表嵌入到Notebook中
# 设置随机种子,确保结果可以复现
def set_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
random.seed(seed)
np.random.seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
# 设置超参数
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")
batch_size = 32
num_workers = 4
lr = 3e-4
epochs = 10
2.2 数据读入和加载
数据下载后,要声明一下对应的文件路径,便于调用
# 设置文件路径
train_path = './train/'
val_path = './validation/'
test_path = './test/'
# 输出类别
categories = os.listdir(train_path)
print(f"Categories: {len(categories)}") # 36
2.2.1 数据预处理(transformer)
在机器学习或者深度学习的问题中,因为受制于图像采集的方式,投入的精力和图像标注的难度等,用于训练的图像数量可能非常有限。这种情况下,可能出现模型过拟合,训练后的模型泛化能力差等问题,降低模型的实际使用能力,这种现象在医学图像的深度学习中尤其常见。为了在有限的数据下得到更好的分类,检测和分割的结果,往往需要使用数据增强的方式,通过对图像的旋转,加入噪声,仿射变换等方式增加数据量。
# 使用imgaug对图像进行数据增强
import imageio
import imgaug as ia # 可参考官方教程 https://github.com/aleju/imgaug
from imgaug import augmenters as iaa
class ImgAugTransform:
def __init__(self):
self.aug = iaa.Sequential([ # 定义增强方法,用于增强
iaa.Scale((224, 224)), # 缩放图像的大小为 224*224(数据集中的图像长宽不一致)
iaa.Sometimes(0.25, iaa.GaussianBlur(sigma=(0, 3.0))), # 对 25% 的图像随机选择 0-3(sigma = 0 表示没有高斯模糊,sigma = 3.0 表示很强的模糊) 强度的高斯模糊
iaa.Fliplr(0.5), # 对 50% 的图像进行做左右翻转
iaa.Affine(rotate=(-20, 20), mode='symmetric'), # 在-20到20的范围内随机旋转图像的角度
iaa.Sometimes(0.25,
iaa.OneOf([iaa.Dropout(p=(0, 0.1)),
iaa.CoarseDropout(0.1, size_percent=0.5)])), # 随机丢弃一些像素,并将那些像素设置为 0(黑色)
iaa.AddToHueAndSaturation(value=(-10, 10), per_channel=True) # 通过随机值增加或减少色调和饱和度。
])
def __call__(self, img):
img = np.array(img)
return self.aug.augment_image(img).transpose(2,1,0) # 应用数据增强,转置
tfs = ImgAugTransform()
2.2.2 数据读取和载入
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from PIL import Image
# 自定义数据集
train_dataset = ImageFolder(train_path,transform=tfs)
val_dataset = ImageFolder(val_path,transform=tfs)
test_dataset = ImageFolder(test_path,transform=tfs)
train_loader = DataLoader(train_dataset,batch_size=batch_size,worker_init_fn=worker_init_fn,shuffle=True)
val_loader = DataLoader(val_dataset,batch_size=batch_size,worker_init_fn=worker_init_fn,shuffle=False)
test_loader = DataLoader(test_dataset,batch_size=batch_size,worker_init_fn=worker_init_fn,shuffle=False)
# 可视化图片
images, labels = next(iter(train_loader))
print(images.shape) # torch.Size([32, 3, 224, 224])
print(type(images)) # <class 'torch.Tensor'>
print(images[1].shape) # torch.Size([3, 224, 224])
plt.imshow(images[0].permute(1,2,0))
plt.show()

2.3 模型设计
timm(Pytorch Image Models)项目是一个站在大佬肩上的图像分类模型库,通过timm可以轻松的搭建出各种sota模型(目前内置预训练模型592个,包含densenet系列、efficientnet系列、resnet系列、vit系列、vgg系列、inception系列、mobilenet系列、xcit系列等等),并进行迁移学习。
import timm
model = timm.create_model("resnet18",num_classes=36,pretrained=True).to(device)
avail_pretrained_models = timm.list_models(pretrained=True)
len(avail_pretrained_models) # 592
# 使用通配符查找resnet系列
all_resnent_models = timm.list_models("*resnet*")
all_resnent_models
# ['cspresnet50',
# 'cspresnet50d',
# 'cspresnet50w',
# 'eca_resnet33ts',
# 'ecaresnet26t',
# 'ecaresnet50d',
# 'ecaresnet50d_pruned',
# 'ecaresnet50t',
# 'ecaresnet101d', ...
# 查看模型默认的cfg
model.default_cfg
#{'url': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
# 'num_classes': 1000,
# 'input_size': (3, 224, 224),
# 'pool_size': (7, 7),
# 'crop_pct': 0.875,
# 'interpolation': 'bilinear',
# 'mean': (0.485, 0.456, 0.406),
# 'std': (0.229, 0.224, 0.225),
# 'first_conv': 'conv1',
# 'classifier': 'fc',
# 'architecture': 'resnet18'}
2.4 训练验证和测试
from tqdm import tqdm # 一个快速,可扩展的Python进度条,可以在 Python 长循环中添加一个进度提示信息,用户只需要封装任意的迭代器 tqdm(iterator)
from torch.optim import Adam
from torch.optim.lr_scheduler import CosineAnnealingLR
# 设置优化器和损失函数
criterion = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=3e-4, betas=[0.9, 0.99], eps=1e-08, weight_decay=0.0)
scheduler = CosineAnnealingLR(optimizer, T_max=100, eta_min=0)
# 模型训练
def train(epoch,model,train_loader):
model.train()
train_loss = 0
for image, target in tqdm(train_loader):
image = image.float()
image = image.to(device)
target = target.to(device)
predict = model(image)
loss = criterion(predict, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step()
train_loss += loss.item() * image.size(0)
train_loss = train_loss / len(train_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))
# 测试集验证
def val(epoch,model,val_dataloader):
model.eval()
val_loss = 0
gt_labels = []
pred_labels = []
with torch.no_grad():
for data, label in tqdm(val_dataloader):
data, label = data.float().to(device), label.to(device)
output = model(data)
preds = torch.argmax(output, 1)
gt_labels.append(label.cpu().data.numpy())
pred_labels.append(preds.cpu().data.numpy())
loss = criterion(output, label)
val_loss += loss.item() * data.size(0)
val_loss = val_loss / len(val_dataloader)
gt_labels, pred_labels = np.concatenate(gt_labels), np.concatenate(pred_labels)
acc = np.sum(gt_labels == pred_labels) / len(pred_labels)
print('Epoch: {} \tValidation Loss: {:.6f}, Accuracy: {:6f}'.format(epoch, val_loss, acc))
# 验证集验证
def test(epoch,model,test_dataloader):
model.eval()
test_loss = 0
gt_labels = []
pred_labels = []
with torch.no_grad():
for data, label in tqdm(test_dataloader):
data, label = data.float().to(device), label.to(device)
output = model(data)
preds = torch.argmax(output, 1)
gt_labels.append(label.cpu().data.numpy())
pred_labels.append(preds.cpu().data.numpy())
gt_labels, pred_labels = np.concatenate(gt_labels), np.concatenate(pred_labels)
acc = np.sum(gt_labels == pred_labels) / len(pred_labels)
print('Epoch: {} \tTest Accuracy: {:6f}'.format(epoch, acc))
for epoch in range(epochs):
train(epoch,model,train_loader)
val(epoch,model,val_loader)
test(epoch,model,test_loader)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号