

DSSM 和 YoutubuDNN 召回模型及 Torch-RecHub 代码实战
召回是工业级推荐系统的第一个阶段,负责从大规模物料库中快速筛选出小规模的候选项目,这时候运行速度和召回率指标更加重要,精确率指标次要。目前,使用基于深度学习的双塔模型来做召回是主流方法。
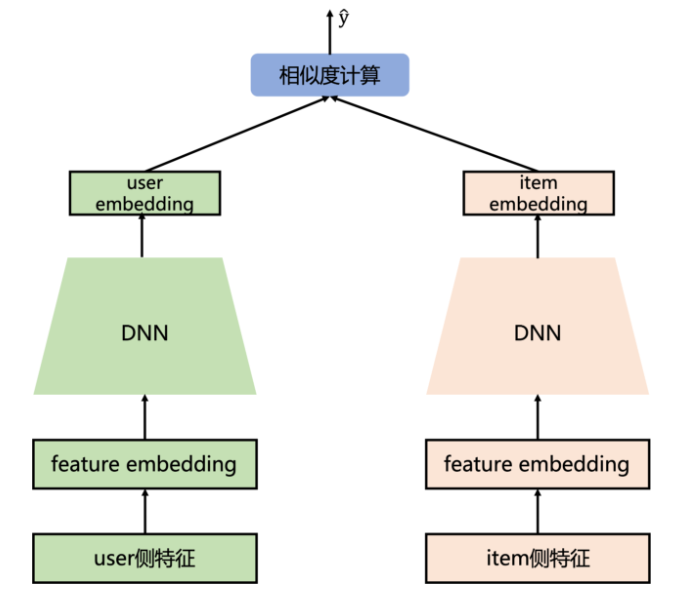
本文将介绍两种双塔模型,经典双塔模性 DSSM 和 YouTubeDNN。
1. Deep Structured Semantic Model (DSSM)
DSSM 模型最早被提出是用来解决网页检索问题(Query → Documents)而不是用于推荐。本文将首先基于原始论文介绍 DSSM,然后讲解 DSSM 用于推荐任务时的实战案例。
1.1 场景和过往研究
搜索引擎的主要任务是,接收用户输入的查询(Query),输出相关的文档(Documents),也称作信息检索(Information retrieval)。性能的评价主要依赖输出结果与用户实际点击行为的相关性,也可以使用 Precision、Recall 等指标来度量。
为了提升输出文档的相关性,需要解决的关键问题是:如何有效计算 Query 和候选 Documents 的相关性。
最经典也是最常用的方法是 keyword-based,根据 Query 和 Documents 中出现过的重复词汇数量来判断相关性,常见的模型有 Bag of Words,TF-IDF 等。然而,这种方法忽略了同一概念会有不同词汇来表示的事实,也就是近义词。比如,“IPhone” 和 “苹果手机” 是相关的,但是因为是不同的词汇。
词汇(lexical)水平的建模失败后,学者们提出了语义(semantic)水平的文本建模方法,比如 LSA、PLSA 和 LDA 等模型。这些方法会根据上下文来找到有相似语义的词汇并将其聚在一起(比如 LDA 的多个主题),解决相同概念不同词汇的问题。这种方法可以将 Query 和 Documents 的原始文本用低维的向量来表征,每一个维度可以被视为某种概念或主题,然后基于这些低维向量计算两者之间的相似性。然而,这种方法是无监督的(聚类),损失函数与网页检索的目标并不完全一致,因此性能并不是很好。
之后,学者们虽然也提出了一些考虑网页检索目标的模型,但是存在着模型复杂、计算量太大等问题,不适合用于具有大规模候选文档的网页检索任务。
1.2 DSSM 模型的原理
DSSM 是由微软研究院于 CIKM 在 2013 年提出的一篇工作,该模型主要用来解决 NLP 领域语义相似度任务,利用深度神经网络将文本表示为低维度的向量,用来提升搜索场景下文档和 query 匹配的问题。
因为模型分为 Query 和 Documents 两部分,在推荐场景中也可对应 user 和 item 部分,被人形象地成为 “双塔”。DSSM 是经典的双塔模型。
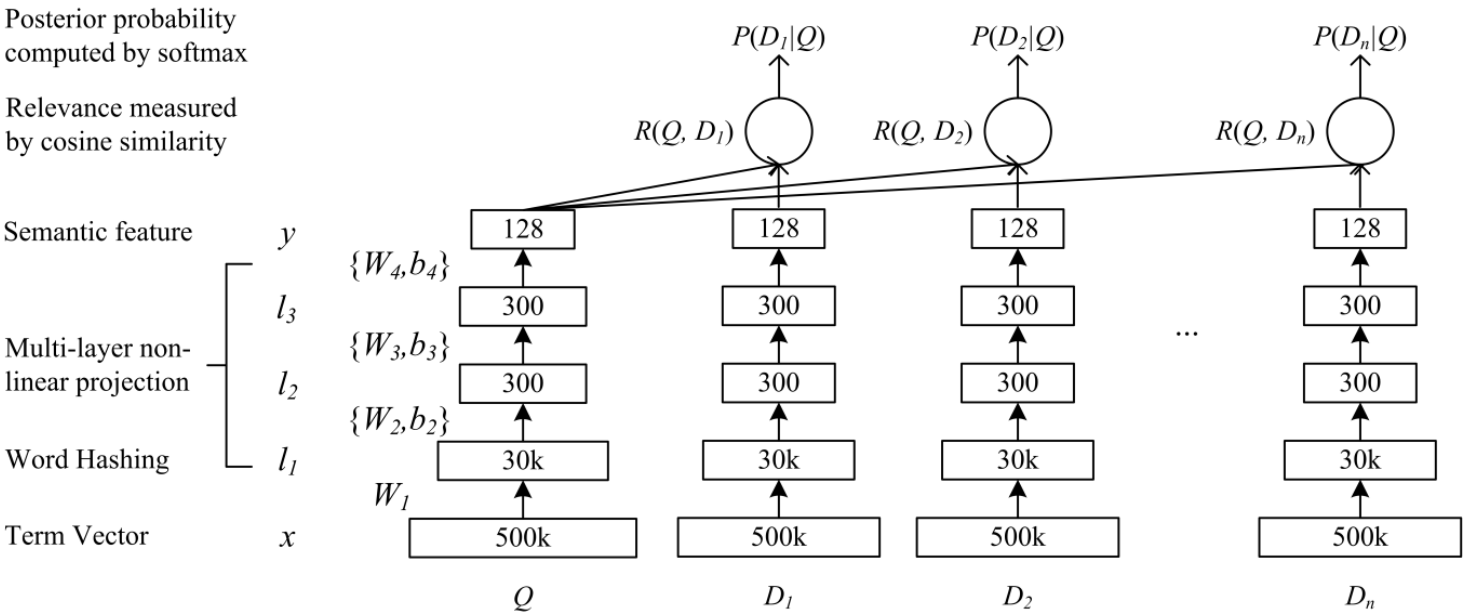
其中,原始输入 x 是初始文本,使用词袋模型或 TF-IDF 模型来表示。毫无疑问,x 的维度会很大,因为要囊括所有可能的词汇。
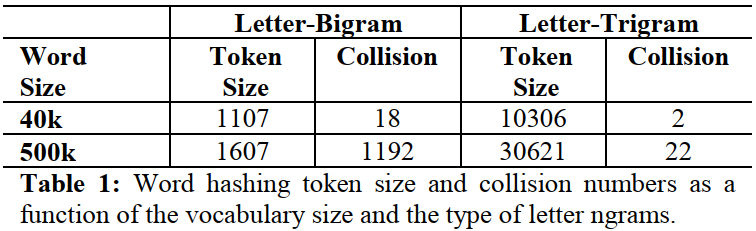
为了降维以降低模型复杂度和计算量,论文提出了 Word hashing 方法,也就是图中的第一层。该方法实际上是将基于 Word 的表征转换为基于 letter n-grams 的表征,比如将单词 "good" 转换为 letter trigrams: #go, goo, ood, od#。对英文来说,word 几乎是无限的,可能不断增长,但是 letter n-grams 是有限的,能够很好地降维、并且对那些 unseen words 或者拼写错误的单词有很好的应对能力。存在的缺点是,有可能两个不同的单词会有相同的 letter n-grams 分布。但是实验证明,这种缺点带来的负面影响可以忽略不计,如下表所示。
这种方法也可以用在中文场景,将基于词汇(word)的文本模型转换为基于字(char)的文本模型。
另外值得强调的是,DSSM 模型优化过程中的损失函数设置和负样本生成。
模型的训练数据来自 clickthrough 日志,它由查询列表及其用户点击过的文档组成。我们假设一个查询与随后用户点击过的文档相关,至少部分相关。模型使用有监督的方法来训练,最大化给定查询下点击文档的条件可能性。
给定查询下,候选文档被点击的概率如下所示:
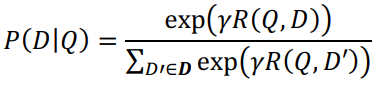
其中, 是 softmax 函数中的平滑因子,该因子是在我们的实验中根据经验在 held-out 数据集上设置的。
我们希望在训练模型后,真实被点击的文档得到的分数高,未被点击的文档得到的分数低。因此,我们需要正负样本来帮助训练。理想情况下,未被点击的文档都应该算作负样本,但这在计算上是不现实的。实际的做法是随机选择指定数量的未被点击文档作为负样本(论文中设定为4)。模型的训练目标(最小化)如下所示:
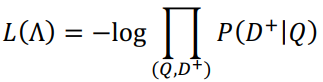
1.3 DSSM 模型的优势
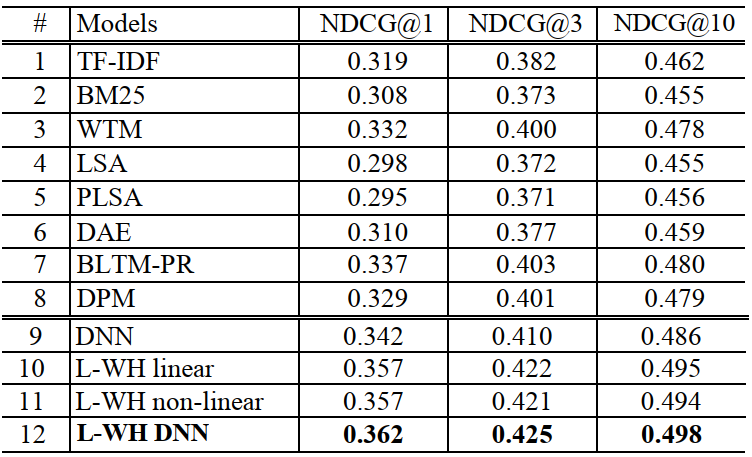
其中,9~12 行 DSSM 不同设置的结果。DNN 是不使用 word hashing 的 DSSM。L-WH DNN 是最好的模型设置。
1.4 MovieLens 实战案例
1.4.1 任务和数据介绍
实战使用的数据集是 MovieLens 1M,使用其中 5 个 user 特征 'user_id', 'gender', 'age', 'occupation', 'zip',2个 item 特征 "movie_id", "cate_id",一共 7 个sparse特征。可以从以下链接 https://cowtransfer.com/s/5a3ab69ebd314e 下载已经预处理的全量 CSV 文件。
该数据集包括用户信息、电影信息和用户对电影的评分信息(本案例将评论近似于观看行为,因为只有观看才能评论),但要注意很多观看电影的用户并不一定会评论。鉴于难以获取真正的观看行为数据,很多研究包括本文只能使用这种公开数据集进行模拟,测试模型。
任务描述:已知用户过去的电影观看(评论)行为,预测该用户观看(评论)另外一种电影的可能性(在本文中,用 0/1 的标签表示预测和真实结果,即经典的二分类问题)。
1.4.2 数据载入和预处理
首先,要载入相关的库,并固定随机数种子便于复现
import torch
import pandas as pd
import numpy as np
import os
pd.set_option('display.max_rows',500)
pd.set_option('display.max_columns',50)
pd.set_option('display.width',1000)
torch.manual_seed(2022)
然后,载入全量的实验数据。要注意,下面的 file_path 要根据自己的数据文件位置设置,而不是照抄。
file_path = '../examples/matching/data/ml-1m/ml-1m.csv'
data = pd.read_csv(file_path) # 全量数据有100万个样本,如果设备运行速度较慢,可以抽取较少数量的样本来实验
# data = data.iloc[:10000,]
print(data.head())
其中,time 的值越大,说明时间越晚,不同 time 之间的差值单位是 秒。
1.4.3 特征工程
我们使用两种类别的特征,分别是稀疏特征(SparseFeature)和序列特征(SequenceFeature)。
- 对于稀疏特征,是一个离散的、有限的值(例如用户ID,一般会先进行 LabelEncoding 操作转化为连续整数值),模型将其输入到 Embedding 层,输出一个 Embedding 向量。
- 对于序列特征,每一个样本是一个List[SparseFeature](一般是观看历史、搜索历史等),对于这种特征,默认对于每一个元素取 Embedding 后平均,输出一个 Embedding 向量。此外,除了平均,还有拼接,最值等方式,可以在pooling参数中指定。
Label Encoding
在本案例中,Emebedding 是模型训练出来的,而不是通过预训练模型直接载入的。
# 处理genres特征,取出其第一个作为标签
data["cate_id"] = data["genres"].apply(lambda x: x.split("|")[0])
# 指定用户列和物品列的名字、离散和稠密特征,适配框架的接口
user_col, item_col = "user_id", "movie_id"
sparse_features = ['user_id', 'movie_id', 'gender', 'age', 'occupation', 'zip', "cate_id"]
dense_features = []
save_dir = '../examples/ranking/data/ml-1m/saved/'
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 对SparseFeature进行LabelEncoding
from sklearn.preprocessing import LabelEncoder
print(data[sparse_features].head())
feature_max_idx = {}
for feature in sparse_features:
lbe = LabelEncoder()
data[feature] = lbe.fit_transform(data[feature]) + 1 # 删除 0 值
feature_max_idx[feature] = data[feature].max() + 1 # 多出来的 1 应该是为了 unseen 类别做保留,比如新商品、新用户
if feature == user_col: # lbe.classes_的值会随着 lbe.fit_transform 处理的数据而变化,有对应关系;leb.classes_是类属性
user_map = {encode_id + 1: raw_id for encode_id, raw_id in enumerate(lbe.classes_)} #encode user id: raw user id
if feature == item_col:
item_map = {encode_id + 1: raw_id for encode_id, raw_id in enumerate(lbe.classes_)} #encode item id: raw item id
np.save(save_dir+"raw_id_maps.npy", (user_map, item_map)) # evaluation时会用到
print('LabelEncoding后:')
print(data[sparse_features].head())
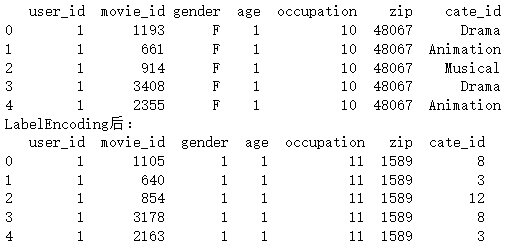
可以看到,特征被转换为了连续的数值,比如 gender,cate_id。
user/item tower seting
在 DSSM 中,分为用户塔和物品塔,每一个塔的输出是用户/物品的特征拼接后经过 MLP(多层感知机)得到的。我们需要定义用户塔和物品塔都有哪些特征:
# 定义两个塔对应哪些特征
user_cols = ["user_id", "gender", "age", "occupation", "zip"]
item_cols = ['movie_id', "cate_id"]
# 从data中取出相应的数据
user_profile = data[user_cols].drop_duplicates('user_id') # 去重
item_profile = data[item_cols].drop_duplicates('movie_id')
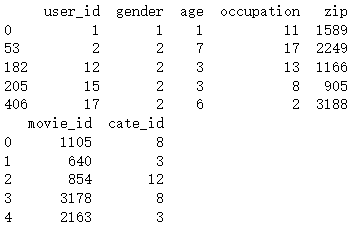
print(user_profile.head())
print(item_profile.head())
sequence feature 生成
本数据集中的序列特征为观看历史,根据timestamp来生成,具体在generate_seq_feature_match函数中实现。参数含义如下:
- mode表示样本的训练方式(0 - point wise, 1 - pair wise, 2 - list wise)
- neg_ratio表示每个正样本对应的负样本数量
- min_item限制每个用户最少的样本量,小于此值将会被抛弃,当做冷启动用户处理(框架中还未添加冷启动的处理,这里直接抛弃)
- sample_method表示负采样方法
from torch_rechub.utils.match import generate_seq_feature_match, gen_model_input
df_train, df_test = generate_seq_feature_match(data,user_col,item_col,time_col="timestamp",item_attribute_cols=[],sample_method=1, mode=0,neg_ratio=3,min_item=0) # 该函数将在 1.5 中讲解
print(df_train.head())
x_train = gen_model_input(df_train, user_profile, user_col, item_profile, item_col, seq_max_len=50) # 该函数将在 1.5 中讲解
y_train = x_train["label"]
x_test = gen_model_input(df_test, user_profile, user_col, item_profile, item_col, seq_max_len=50)
y_test = x_test["label"]
del x_train["label"] # 删除 y 值
del x_test["label"]
print({k: v[:3] for k, v in x_train.items()})

1.4.4 模型-特征配置
from torch_rechub.basic.features import SparseFeature, SequenceFeature
# embed_dim 是指定 LabelEncoder 的维度,会通过训练来自动学习到合适的 Lookup table
user_features = [
SparseFeature(feature_name, vocab_size=feature_max_idx[feature_name], embed_dim=16) for feature_name in user_cols
]
user_features += [
SequenceFeature("hist_movie_id", vocab_size=feature_max_idx["movie_id"], embed_dim=16, pooling="mean", shared_with="movie_id") # mean pooling,会对历史观影的 embedding 做平均运算
]
item_features = [
SparseFeature(feature_name, vocab_size=feature_max_idx[feature_name], embed_dim=16) for feature_name in item_cols
]
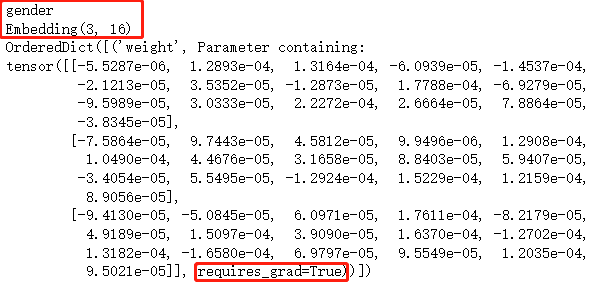
print(user_features[1].name)
print(user_features[1].get_embedding_layer())
print(user_features[1].get_embedding_layer()._parameters)
# 将dataframe转为dict
from torch_rechub.utils.data import df_to_dict
all_item = df_to_dict(item_profile)
test_user = x_test
print({k: v[:3] for k, v in all_item.items()})
print({k: v[0] for k, v in test_user.items()})
将 dataframe 转为 dict 的原因:dict里可以存tensor,df里不好放tensor,方便在model输入。

1.4.5 训练模型
根据之前的x_train字典和y_train等数据生成训练用的Dataloader(train_dl)、测试用的Dataloader(test_dl, item_dl)。
定义一个双塔DSSM模型,user_features表示用户塔有哪些特征,user_params表示用户塔的MLP的各层维度和激活函数。(Note:在这个样例中激活函数的选取对最终结果影响很大)
定义一个召回训练器 MatchTrainer,进行模型的训练。
from torch_rechub.models.matching import DSSM
from torch_rechub.trainers import MatchTrainer
from torch_rechub.utils.data import MatchDataGenerator
# 根据之前处理的数据拿到Dataloader
dg = MatchDataGenerator(x=x_train, y=y_train)
train_dl, test_dl, item_dl = dg.generate_dataloader(test_user, all_item, batch_size=256)
# 定义模型
model = DSSM(user_features, item_features, temperature=0.02, # 在归一化之后的向量计算內积之后,乘一个固定的超参 r ,论文中命名为温度系数。归一化后如果不乘 temperature,模型无法收敛
user_params={
"dims": [256, 128, 64],
"activation": 'prelu', # important!!
},
item_params={
"dims": [256, 128, 64],
"activation": 'prelu', # important!!
})
# 模型训练器
trainer = MatchTrainer(model,
mode=0, # 同上面的mode,需保持一致
optimizer_params={
"lr": 1e-4,
"weight_decay": 1e-6
},
n_epoch=10,
device='cpu',
model_path=save_dir)
# 开始训练
trainer.fit(train_dl)

1.4.6 向量化召回-评估
使用trainer获取测试集中每个user的embedding和数据集中所有物品的embedding集合
用annoy构建物品embedding索引,对每个用户向量进行ANN(Approximate Nearest Neighbors)召回K个物品
查看topk评估指标,一般看recall、precision、hit
import collections
import numpy as np
import pandas as pd
from torch_rechub.utils.match import Annoy
from torch_rechub.basic.metric import topk_metrics
def match_evaluation(user_embedding, item_embedding, test_user, all_item, user_col='user_id', item_col='movie_id',
raw_id_maps="./raw_id_maps.npy", topk=10):
print("evaluate embedding matching on test data")
annoy = Annoy(n_trees=10)
annoy.fit(item_embedding)
#for each user of test dataset, get ann search topk result
print("matching for topk")
user_map, item_map = np.load(raw_id_maps, allow_pickle=True)
match_res = collections.defaultdict(dict) # user id -> predicted item ids
for user_id, user_emb in zip(test_user[user_col], user_embedding):
items_idx, items_scores = annoy.query(v=user_emb, n=topk) #the index of topk match items
match_res[user_map[user_id]] = np.vectorize(item_map.get)(all_item[item_col][items_idx])
#get ground truth
print("generate ground truth")
data = pd.DataFrame({user_col: test_user[user_col], item_col: test_user[item_col]})
data[user_col] = data[user_col].map(user_map)
data[item_col] = data[item_col].map(item_map)
user_pos_item = data.groupby(user_col).agg(list).reset_index()
ground_truth = dict(zip(user_pos_item[user_col], user_pos_item[item_col])) # user id -> ground truth
print("compute topk metrics")
out = topk_metrics(y_true=ground_truth, y_pred=match_res, topKs=[topk])
return out
user_embedding = trainer.inference_embedding(model=model, mode="user", data_loader=test_dl, model_path=save_dir)
item_embedding = trainer.inference_embedding(model=model, mode="item", data_loader=item_dl, model_path=save_dir)
match_evaluation(user_embedding, item_embedding, test_user, all_item, topk=10, raw_id_maps=save_dir+"raw_id_maps.npy")
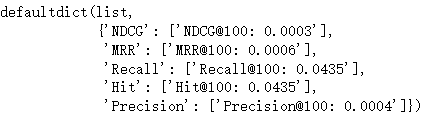
可能是因为未使用全量数据,效果一般。
1.5 重要源码的解析
1.5.1 DSSM
class DSSM(torch.nn.Module):
"""Deep Structured Semantic Model
Args:
user_features (list[Feature Class]): training by the user tower module.
item_features (list[Feature Class]): training by the item tower module.
temperature (float): temperature factor for similarity score, default to 1.0.
user_params (dict): the params of the User Tower module, keys include:`{"dims":list, "activation":str, "dropout":float, "output_layer":bool`}.
item_params (dict): the params of the Item Tower module, keys include:`{"dims":list, "activation":str, "dropout":float, "output_layer":bool`}.
"""
def __init__(self, user_features, item_features, user_params, item_params, temperature=1.0):
super().__init__()
self.user_features = user_features
self.item_features = item_features
self.temperature = temperature
self.user_dims = sum([fea.embed_dim for fea in user_features])
self.item_dims = sum([fea.embed_dim for fea in item_features])
self.embedding = EmbeddingLayer(user_features + item_features)
self.user_mlp = MLP(self.user_dims, output_layer=False, **user_params)
self.item_mlp = MLP(self.item_dims, output_layer=False, **item_params)
self.mode = None
def forward(self, x):
user_embedding = self.user_tower(x)
item_embedding = self.item_tower(x)
if self.mode == "user":
return user_embedding
if self.mode == "item":
return item_embedding
# calculate cosine score
y = torch.mul(user_embedding, item_embedding).sum(dim=1)
# y = y / self.temperature
return torch.sigmoid(y)
def user_tower(self, x):
if self.mode == "item":
return None
input_user = self.embedding(x, self.user_features, squeeze_dim=True) #[batch_size, num_features*deep_dims]
user_embedding = self.user_mlp(input_user) #[batch_size, user_params["dims"][-1]]
user_embedding = F.normalize(user_embedding, p=2, dim=1) # L2 normalize
return user_embedding
def item_tower(self, x):
if self.mode == "user":
return None
input_item = self.embedding(x, self.item_features, squeeze_dim=True) #[batch_size, num_features*embed_dim]
item_embedding = self.item_mlp(input_item) #[batch_size, item_params["dims"][-1]]
item_embedding = F.normalize(item_embedding, p=2, dim=1)
return item_embedding
1.5.2 generate_seq_feature_match
def generate_seq_feature_match(data,
user_col,
item_col,
time_col,
item_attribute_cols=[],
sample_method=0,
mode=0,
neg_ratio=0,
min_item=0):
"""generate sequence feature and negative sample for match.
Args:
data (pd.DataFrame): the raw data.
user_col (str): the col name of user_id
item_col (str): the col name of item_id
time_col (str): the col name of timestamp
item_attribute_cols (list[str], optional): the other attribute cols of item which you want to generate sequence feature. Defaults to `[]`.
sample_method (int, optional): the negative sample method `{
0: "random sampling",
1: "popularity sampling method used in word2vec",
2: "popularity sampling method by `log(count+1)+1e-6`",
3: "tencent RALM sampling"}`.
Defaults to 0.
mode (int, optional): the training mode, `{0:point-wise, 1:pair-wise, 2:list-wise}`. Defaults to 0.
neg_ratio (int, optional): negative sample ratio, >= 1. Defaults to 0.
min_item (int, optional): the min item each user must have. Defaults to 0.
Returns:
pd.DataFrame: split train and test data with sequence features.
"""
if mode == 2: # list wise learning
assert neg_ratio > 0, 'neg_ratio must be greater than 0 when list-wise learning'
elif mode == 1: # pair wise learning
neg_ratio = 1
print("preprocess data")
data.sort_values(time_col, inplace=True) #sort by time from old to new
train_set, test_set = [], []
n_cold_user = 0
items_cnt = Counter(data[item_col].tolist())
items_cnt_order = OrderedDict(sorted((items_cnt.items()), key=lambda x: x[1], reverse=True)) #item_id:item count
neg_list = negative_sample(items_cnt_order, ratio=data.shape[0] * neg_ratio, method_id=sample_method)
neg_idx = 0
for uid, hist in tqdm.tqdm(data.groupby(user_col), desc='generate sequence features'):
pos_list = hist[item_col].tolist()
if len(pos_list) < min_item: #drop this user when his pos items < min_item
n_cold_user += 1
continue
for i in range(1, len(pos_list)):
hist_item = pos_list[:i]
sample = [uid, pos_list[i], hist_item, len(hist_item)]
if len(item_attribute_cols) > 0:
for attr_col in item_attribute_cols: #the history of item attribute features
sample.append(hist[attr_col].tolist()[:i])
if i != len(pos_list) - 1:
if mode == 0: #point-wise, the last col is label_col, include label 0 and 1
last_col = "label"
train_set.append(sample + [1])
for _ in range(neg_ratio):
sample[1] = neg_list[neg_idx]
neg_idx += 1
train_set.append(sample + [0])
elif mode == 1: #pair-wise, the last col is neg_col, include one negative item
last_col = "neg_items"
for _ in range(neg_ratio):
sample_copy = copy.deepcopy(sample)
sample_copy.append(neg_list[neg_idx])
neg_idx += 1
train_set.append(sample_copy)
elif mode == 2: #list-wise, the last col is neg_col, include neg_ratio negative items
last_col = "neg_items"
sample.append(neg_list[neg_idx: neg_idx + neg_ratio])
neg_idx += neg_ratio
train_set.append(sample)
else:
raise ValueError("mode should in (0,1,2)")
else:
test_set.append(sample + [1]) #Note: if mode=1 or 2, the label col is useless.
random.shuffle(train_set)
random.shuffle(test_set)
print("n_train: %d, n_test: %d" % (len(train_set), len(test_set)))
print("%d cold start user droped " % (n_cold_user))
attr_hist_col = ["hist_" + col for col in item_attribute_cols]
df_train = pd.DataFrame(train_set,
columns=[user_col, item_col, "hist_" + item_col, "histlen_" + item_col] + attr_hist_col + [last_col])
df_test = pd.DataFrame(test_set,
columns=[user_col, item_col, "hist_" + item_col, "histlen_" + item_col] + attr_hist_col + [last_col])
return df_train, df_test
1.5.3 gen_model_input
def gen_model_input(df, user_profile, user_col, item_profile, item_col, seq_max_len, padding='pre', truncating='pre'):
# merge user_profile and item_profile, pad history seuence feature
df = pd.merge(df, user_profile, on=user_col, how='left') # how=left to keep samples order same as the input
df = pd.merge(df, item_profile, on=item_col, how='left')
for col in df.columns.to_list():
if col.startswith("hist_"):
df[col] = pad_sequences(df[col], maxlen=seq_max_len, value=0, padding=padding, truncating=truncating).tolist()
input_dict = df_to_dict(df)
return input_dict
2. Deep Neural Networks for YouTube Recommendations (YoutubeDNN)
YoutubeDNN 是2016年发布的,介绍了 YouTube 推荐系统全方位引入深度学习方法的重大转变(当时采用深度学习做推荐系统的还很少)。虽然时间有些早了,但仍是一篇经典文章,值得学习和思考。
2.1 场景和过往研究
推荐系统的设计要与应用场景紧密结合,根据场景具有的特点和约束条件等改进模型以提升各方位的性能。
YouTube 是全球最大的视频分享和观看平台,服务超过十亿用户,也存在着很严重的信息过载问题。因此,YouTube 的推荐系统是非常重要的。目前,YouTube 视频推荐系统主要面临以下三个挑战:
- Scale(规模): 视频数量非常庞大,大规模数据下需要分布式学习算法以及高效的线上服务系统(此时,很多在小规模数据中工作良好的推荐算法不再适用)。
- Freshness(新鲜度): YouTube上的视频一直在动态变化,每秒钟都有很多用户去上传新视频。用户一般都比较喜欢看比较新的视频,而不管是不是真和用户相关(这个感觉和新闻比较类似)。
- Noise(噪声): 由于数据的稀疏和不可见的其他原因,数据里面的噪声非常之多,很难获取用户对观看过的视频的满意度或隐式反馈。
为了解决以上三个挑战,YouTube 基于深度学习设计了通用目的的解决方案。
2.2 YouTubeDNN 模型的原理
推荐系统的整体架构如下图所示:
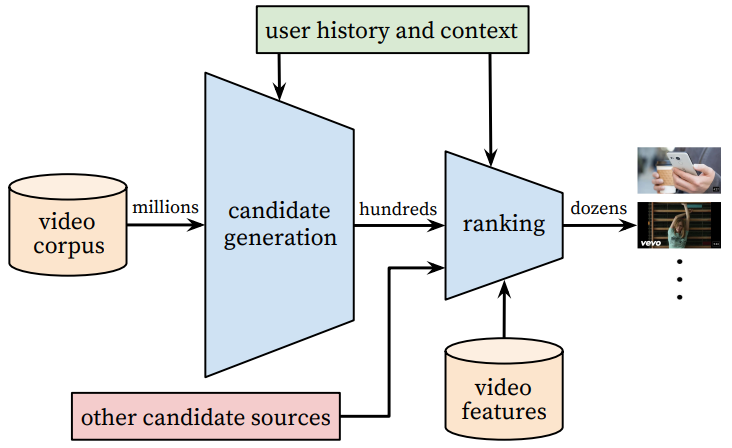
这个系统主要是两大部分组成: 召回(Candidate generation)和精序(Ranking)。召回的目的是根据用户部分特征,从海量物品库,快速找到小部分用户潜在感兴趣的物品交给精排,重点强调快;精排主要是融入更多特征,使用复杂模型,来做个性化推荐,强调准。
2.2.1 召回(Candidate generation)
论文把推荐问题转换为一个多分类问题:根据用户 U 和上下文 C,预测在时刻 t 观看视频 i 的概率。
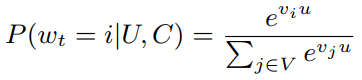
式子中,u 指的是用户 U 和上下文 C 的 Embedding,v 指的是候选视频项目的 Embedding。深度学习的任务是学习一个函数(参数估计),怎么根据用户的历史记录和上下文生成当前的 Embedding。
另外,YouTube 不使用点赞等用户显式反馈作为用户满意度的信号,而是使用用户是否观看完视频的隐式反馈作为用户满意度信号。因为后者有更多的可用数据(很多视频用户感兴趣,看完了,但因为一些原因不愿点赞),前者的数据稀疏性较为严重。
召回阶段的模型架构如下所示(可以理解为一个 DNN):
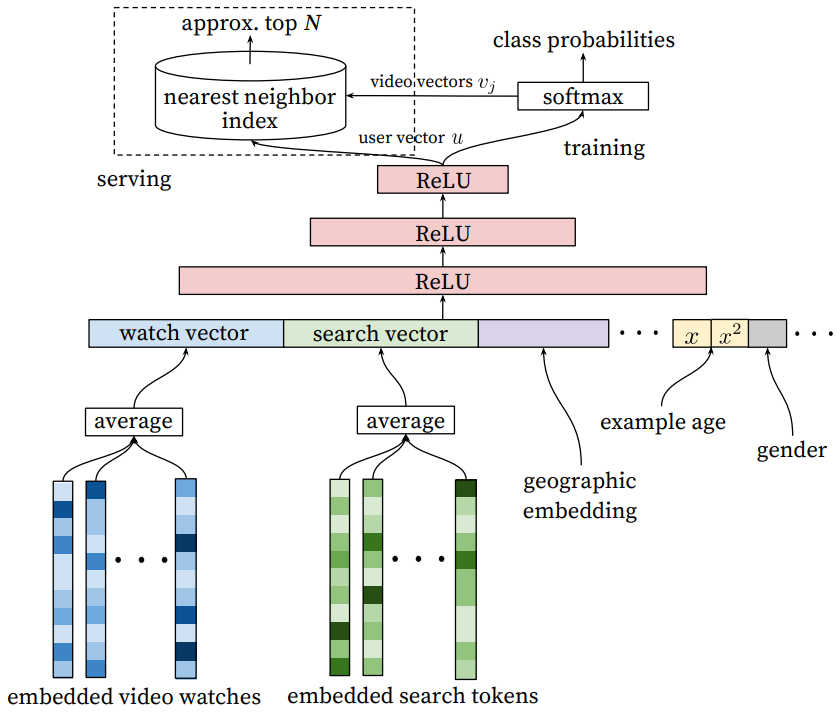
上图中,搜索历史(search history)指用户在搜索中输入的 Query。Query 将被分词为 unigrames 和 bigrams,并且每个词汇都会转变为 Embedding 进行处理(和 watch history 类似)。用户的基本信息,比如年龄、地区、性别等,可使用binary或者嵌入的方式表征,得到的表征与其他的拼接在一起。
“example age” 是和场景比较相关的特征,也是作者的经验传授。 我们知道,视频有明显的生命周期,例如刚上传的视频比之后更受欢迎,也就是用户往往喜欢看最新的东西,而不管它是不是和用户相关,所以视频的流行度随着时间的分布是高度非稳态变化的(下面图中的绿色曲线)。
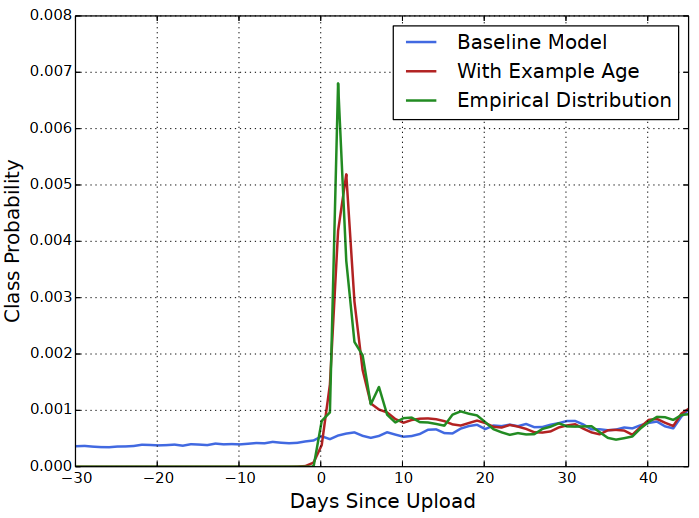
"example age" 定义为 其中 是训练数据中所有样本的时间最大值,而 t 为当前样本的时间。线上预测时, 直接把example age全部设为0或一个小的负值,这样就不依赖于各个视频的上传时间了。
2.2.2 精排(Ranking)
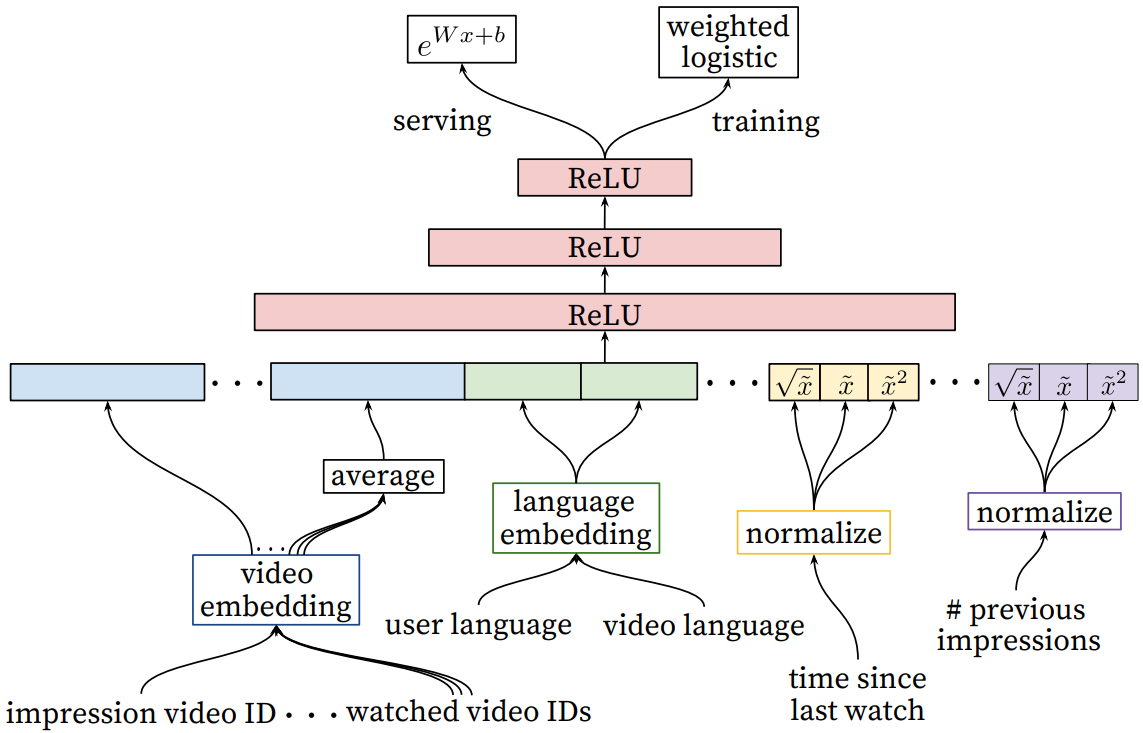
以上的YouTube的精排模型,本文目前重点讲解召回部分,精排部分之后有空再补充。
2.3 MovieLens 实战案例
数据和场景与 1.4 是一致的,不再赘述。很多代码也是一致的,只要部分特征处理和模型使用方面有所不同。
2.3.1 数据载入和特征工程
以下关于数据载入和预处理的代码与之前一致,不再详解。
import os
import numpy as np
import pandas as pd
import torch
from sklearn.preprocessing import LabelEncoder
from torch_rechub.models.matching import YoutubeDNN
from torch_rechub.trainers import MatchTrainer
from torch_rechub.basic.features import SparseFeature, SequenceFeature
from torch_rechub.utils.match import generate_seq_feature_match, gen_model_input
from torch_rechub.utils.data import df_to_dict, MatchDataGenerator
torch.manual_seed(2022)
data = pd.read_csv(file_path)
data["cate_id"] = data["genres"].apply(lambda x: x.split("|")[0])
sparse_features = ['user_id', 'movie_id', 'gender', 'age', 'occupation', 'zip', "cate_id"]
user_col, item_col = "user_id", "movie_id"
save_dir = '../examples/ranking/data/ml-1m/saved/'
if not os.path.exists(save_dir):
os.makedirs(save_dir)
feature_max_idx = {}
for feature in sparse_features:
lbe = LabelEncoder()
data[feature] = lbe.fit_transform(data[feature]) + 1
feature_max_idx[feature] = data[feature].max() + 1
if feature == user_col:
user_map = {encode_id + 1: raw_id for encode_id, raw_id in enumerate(lbe.classes_)} #encode user id: raw user id
if feature == item_col:
item_map = {encode_id + 1: raw_id for encode_id, raw_id in enumerate(lbe.classes_)} #encode item id: raw item id
np.save(save_dir+"raw_id_maps.npy", (user_map, item_map))
print('LabelEncoding后:')
print(data[sparse_features].head())
user_cols = ["user_id", "gender", "age", "occupation", "zip"]
item_cols = ["movie_id", "cate_id"]
user_profile = data[user_cols].drop_duplicates('user_id')
item_profile = data[item_cols].drop_duplicates('movie_id')

2.3.2 训练测试集划分和模型配置
#Note: mode=2 means list-wise negative sample generate, saved in last col "neg_items"
df_train, df_test = generate_seq_feature_match(data, user_col, item_col, time_col="timestamp", item_attribute_cols=[], sample_method=1,
mode=2, # [0]训练方式改为List wise
neg_ratio=3, min_item=0)
x_train = gen_model_input(df_train, user_profile, user_col, item_profile, item_col, seq_max_len=50)
y_train = np.array([0] * df_train.shape[0]) # [1]训练集所有样本的label都取 0。因为一个样本的组成是(pos, neg1, neg2, ...),视为一个多分类任务,正样本的位置永远是0
x_test = gen_model_input(df_test, user_profile, user_col, item_profile, item_col, seq_max_len=50)
user_cols = ['user_id', 'gender', 'age', 'occupation', 'zip']
user_features = [SparseFeature(name, vocab_size=feature_max_idx[name], embed_dim=16) for name in user_cols]
user_features += [SequenceFeature("hist_movie_id", vocab_size=feature_max_idx["movie_id"], embed_dim=16, pooling="mean",]
item_features = [SparseFeature('movie_id', vocab_size=feature_max_idx['movie_id'], embed_dim=16)] # [2]物品的特征只有itemID,即movie_id一个
neg_item_feature = [
SequenceFeature('neg_items', vocab_size=feature_max_idx['movie_id'], embed_dim=16, pooling="concat", shared_with="movie_id")
] # [3] 多了一个neg item feature,会传入到模型中,在item tower中会用到
all_item = df_to_dict(item_profile)
test_user = x_test
dg = MatchDataGenerator(x=x_train, y=y_train)
train_dl, test_dl, item_dl = dg.generate_dataloader(test_user, all_item, batch_size=256)

2.3.3 模型性能评价
model = YoutubeDNN(user_features, item_features, neg_item_feature, user_params={"dims": [128, 64, 16]}, temperature=0.02) # [4] MLP的最后一层需保持与item embedding一致
trainer = MatchTrainer(model, mode=2, optimizer_params={"lr": 1e-4, "weight_decay": 1e-6}, n_epoch=5, device='cpu', model_path=save_dir)
trainer.fit(train_dl)
print("inference embedding")
user_embedding = trainer.inference_embedding(model=model, mode="user", data_loader=test_dl, model_path=save_dir)
item_embedding = trainer.inference_embedding(model=model, mode="item", data_loader=item_dl, model_path=save_dir)

match_evaluation(user_embedding, item_embedding, test_user, all_item, topk=100, raw_id_maps=save_dir+"raw_id_maps.npy")

2.5 重要源码的解析
class YoutubeDNN(torch.nn.Module):
"""The match model mentioned in `Deep Neural Networks for YouTube Recommendations` paper.
It's a DSSM match model trained by global softmax loss on list-wise samples.
Note in origin paper, it's without item dnn tower and train item embedding directly.
Args:
user_features (list[Feature Class]): training by the user tower module.
item_features (list[Feature Class]): training by the embedding table, it's the item id feature.
neg_item_feature (list[Feature Class]): training by the embedding table, it's the negative items id feature.
user_params (dict): the params of the User Tower module, keys include:`{"dims":list, "activation":str, "dropout":float, "output_layer":bool`}.
temperature (float): temperature factor for similarity score, default to 1.0.
"""
def __init__(self, user_features, item_features, neg_item_feature, user_params, temperature=1.0):
super().__init__()
self.user_features = user_features
self.item_features = item_features
self.neg_item_feature = neg_item_feature
self.temperature = temperature
self.user_dims = sum([fea.embed_dim for fea in user_features])
self.embedding = EmbeddingLayer(user_features + item_features)
self.user_mlp = MLP(self.user_dims, output_layer=False, **user_params)
self.mode = None
def forward(self, x):
user_embedding = self.user_tower(x)
item_embedding = self.item_tower(x)
if self.mode == "user":
return user_embedding
if self.mode == "item":
return item_embedding
# calculate cosine score
y = torch.mul(user_embedding, item_embedding).sum(dim=2)
y = y / self.temperature
return y
def user_tower(self, x):
if self.mode == "item":
return None
input_user = self.embedding(x, self.user_features, squeeze_dim=True) #[batch_size, num_features*deep_dims]
user_embedding = self.user_mlp(input_user).unsqueeze(1) #[batch_size, 1, embed_dim]
user_embedding = F.normalize(user_embedding, p=2, dim=2)
if self.mode == "user":
return user_embedding.squeeze(1) #inference embedding mode -> [batch_size, embed_dim]
return user_embedding
def item_tower(self, x):
if self.mode == "user":
return None
pos_embedding = self.embedding(x, self.item_features, squeeze_dim=False) #[batch_size, 1, embed_dim]
pos_embedding = F.normalize(pos_embedding, p=2, dim=2)
if self.mode == "item": #inference embedding mode
return pos_embedding.squeeze(1) #[batch_size, embed_dim]
neg_embeddings = self.embedding(x, self.neg_item_feature,
squeeze_dim=False).squeeze(1) #[batch_size, n_neg_items, embed_dim]
neg_embeddings = F.normalize(neg_embeddings, p=2, dim=2)
return torch.cat((pos_embedding, neg_embeddings), dim=1) #[batch_size, 1+n_neg_items, embed_dim]
3. 补充知识点
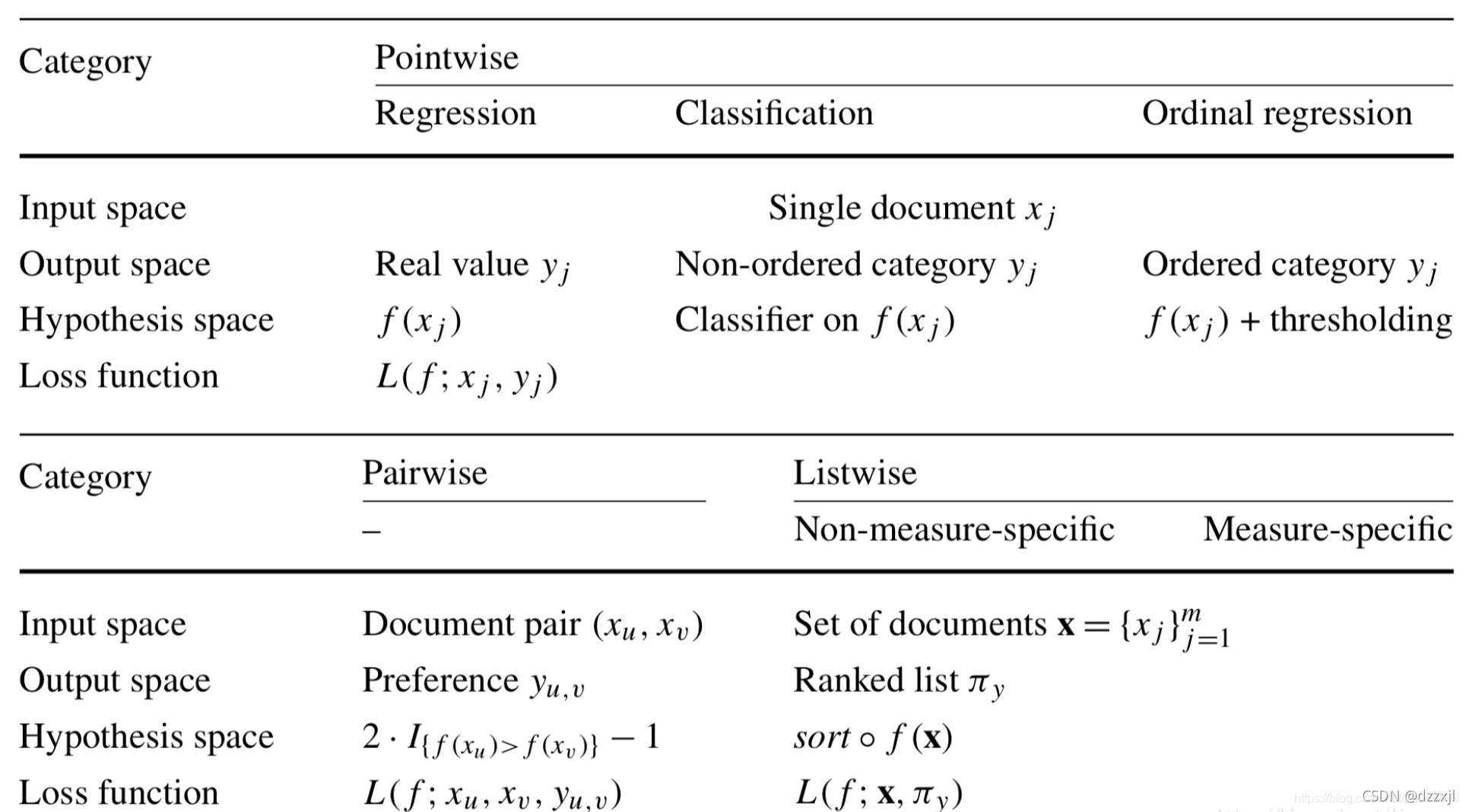
Point-wise、Pair-wise、List-wise分别代表搜索排序中,一个query对应一个truth, 两个truth,多个truth。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY