PyTorch:张量计算和自动求导
张量(Tensor)
几何代数中定义的张量是基于向量和矩阵的推广:0维张量是一个数字,1维张量称为“向量”,2维张量称为矩阵,3维张量可以是彩色图片(RGB)等。张量是现代机器学习的基础。
(width, height, channel) = 3D; (sample_size, width, height, channel) = 4D
在PyTorch中, torch.Tensor 是存储和变换数据的主要工具。Tensor 和 NumPy 的多维数组非常类似。然而,Tensor 提供GPU计算和自动求梯度等更多功能,更加适合深度学习。
张量创建
torch.eye(n, m=None, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor

torch.rand(*size, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor 0-1 均匀分布
torch.randn(*size, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor 0-1 正态分布

torch.normal(mean, std, size, *, out=None) → Tensor

torch.ones(*size, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor #torch.zeros类似

torch.arange(start=0, end, step=1, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) → Tensor

torch.tensor(data, *, dtype=None, device=None, requires_grad=False, pin_memory=False) → Tensor

张量的结构操作
reshape/view: 改变tensor的shape
区别:view 接受的必须是 data 底层存储连续的tensor,且数据还是原来的数据。reshape()没那么可控,执行结果可能是源数据的一个copy,也可能不是。因此,如果需要copy,用clone();如果需要源数据,用view();reshape() 最好少用。
t = torch.tensor([[
[1,1,1,1],
[2,2,2,2],
[3,3,3,3]
], dtype=torch.float32])
t.reshape(1,-1).shape # (1,12),-1表示按元素个数自动推理 t.numel() = 3*4 = 1*x
t.view(1,-1).size() # (1,12)
t.view(t.numel())
t.flatten()
t.reshape(-1) # 以上操作结果相同
squeeze 和 unsqueeze
print(t.reshape([1,12]))
print(t.reshape([1,12]).shape)
# tensor([[1., 1., 1., 1., 2., 2., 2., 2., 3., 3., 3., 3.]])
# torch.Size([1, 12])
t.reshape([1,12]).suqueeze() #无法指定压缩维度的位置,只能在第0维
t.reshape([1,12]).squeeze().shape
# tensor([1., 1., 1., 1., 2., 2., 2., 2., 3., 3., 3., 3.])
# torch.Size([12])
t.reshape([1,12]).squeeze().unsqueeze(dim=0) #可以指定升维的位置
t.reshape([1,12]).squeeze().unsqueeze(dim=0).shape
# tensor([[1., 1., 1., 1., 2., 2., 2., 2., 3., 3., 3., 3.]])
# torch.Size([1, 12])
cat: 张量的拼接
t1 = torch.tensor([
[1,2],
[3,4]])
t2 = torch.tensor([
[5,6],
[7,8]])
t = torch.cat((t1,t2),dim = 0) #在第0轴拼接
# tensor([
[1,2],
[3,4],
[5,6],
[7,8]
])
t = torch.cat((t1,t2),dim = 1) #在第1轴拼接
# tensor([[1, 2, 5, 6],
[3, 4, 7, 8]])
stack: 张量的堆叠
#stack堆叠会在指定位置增加新的一维,不指定位置的话默认是 0 轴。而cat只会改变现有维度的大小,不会增加新的维度
a=torch.randn((1,3,4,4)) #[N,c,w,h]
b=torch.stack((a,a))
b.shape
# (2, 1, 3, 4, 4)
c=torch.stack((a,a),1)
c.shape
# (1, 2, 3, 4, 4)
d=torch.stack((a,a),2)
d.shape
# (1, 3, 2, 4, 4)
张量的算术操作
即逐元素操作 element-wise ops, 也称 point-wise。张量的所有代数操作都是逐元素的。
t1 = torch.tensor([
[1,2],
[3,4]
], dtype=torch.float32)
t2 = torch.tensor([
[9,8],
[7,6]
], dtype=torch.float32)
t1+t2
t1+2
t1 * 2
t1 / 2
当对两个形状不同的 Tensor 按元素运算时,可能会触发广播 (broadcasting) 机制:先适当复制元素使这两个 Tensor 形状相同后再按元素运算。
张量的统计操作
#普通的张量减少(元素)操作
t.sum() #元素求和
t.numel() #元素总数
t.prod() #乘积
t.mean() #均值
t.std() #标准差
#沿轴减少操作
t = torch.tensor([
[1,1,1,1],
[2,2,2,2],
[3,3,3,3]
], dtype=torch.float32)
t.sum(dim = 0) #tensor([6., 6., 6., 6.])
t.sum(dim = 1) #tensor([4., 8., 12.])
#张量最大值的下标索引 argmax
t = torch.tensor([
[1,0,0,2],
[0,3,3,0],
[4,0,0,5]
], dtype=torch.float32)
t.max() #tensor(5.)
#如果不指定轴argmax索引,会默认是从flatten完全展开后得到的索引下标
t.argmax() #tensor(11)
#指定轴argmax索引时
t.max(dim=0)
# tensor([4., 3., 3., 5.])
t.argmax(dim=0)
# tensor([2, 1, 1, 2])
t.max(dim=1)
# tensor([2., 3., 5.])
t.argmax(dim=1)
# tensor([3, 1, 3])
#获取张量内的元素
t = torch.tensor([
[1,2,3],
[4,5,6],
[7,8,9]
], dtype=torch.float32)
t.mean()
# tensor(5.)
t.mean().item() # .item()获取元素作为scalar
# 5.0
t.mean(dim=0).tolist() # .tolist()转变为list
# [4.0, 5.0, 6.0]
t.mean(dim=0).numpy() # tensor--->numpy数组
# array([4., 5., 6.], dtype=float32)
自动求导
PyTorch 中,所有神经网络的核心是 autograd 包。autograd 包为张量上的所有操作提供了自动求导机制。
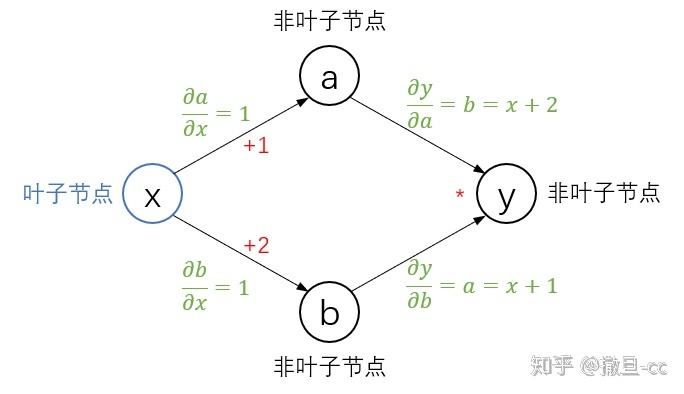
数据可分为 叶子节点(leaf node)和非叶子节点;叶子节点是用户创建的节点(可通过属性 .is_leaf 查看),不依赖其它节点;它们表现出来的区别在于反向传播结束之后,非叶子节点的梯度会被释放掉,只保留叶子节点的梯度,这样就节省了内存。
torch.Tensor 是这个包的核心类。如果设置它的属性 .requires_grad 为 True,那么它将会追踪对于该张量的所有操作。当完成计算后可以通过调用 .backward(),来自动计算所有的梯度。这个张量的所有梯度将会自动累加到.grad属性。
举例:温度计校准
def model(t_u, w, b): # 预测模型,其中 t_u 为输入,w 和 b 为模型的参数
return w * t_u + b
def loss_fn(t_p, t_c): # 损失函数 MSE,其中 t_p 为预测值,t_c 为实际值
squared_diffs = (t_p - t_c)**2
return squared_diffs.mean()
params = torch.tensor([1.0, 0.0], requires_grad=True) # 要估计的参数,w 和 b
使用 grad 属性
张量构造函数的 requires_grad=True,这个参数告诉 PyTorch 跟踪由对 params 张量进行操作后产生的张量的整个系谱树。换句话说,任何将params作为祖先的张量都可以访问从params到那个张量调用的函数链。如果这些函数是可微的(大多数PyTorch张量操作都是可微的),导数的值将自动填充为params张量的grad属性。
通常,所有PyTorch张量都有一个名为grad的属性。通常情况下,该属性值为None。我们所要做的就是从一个 requires_grad 为 True 的张量开始,调用模型并计算损失,然后反向调用损失张量:
loss = loss_fn(model(t_u, *params), t_c)
loss.backward()
params.grad
#tensor([4517.2969, 82.6000])
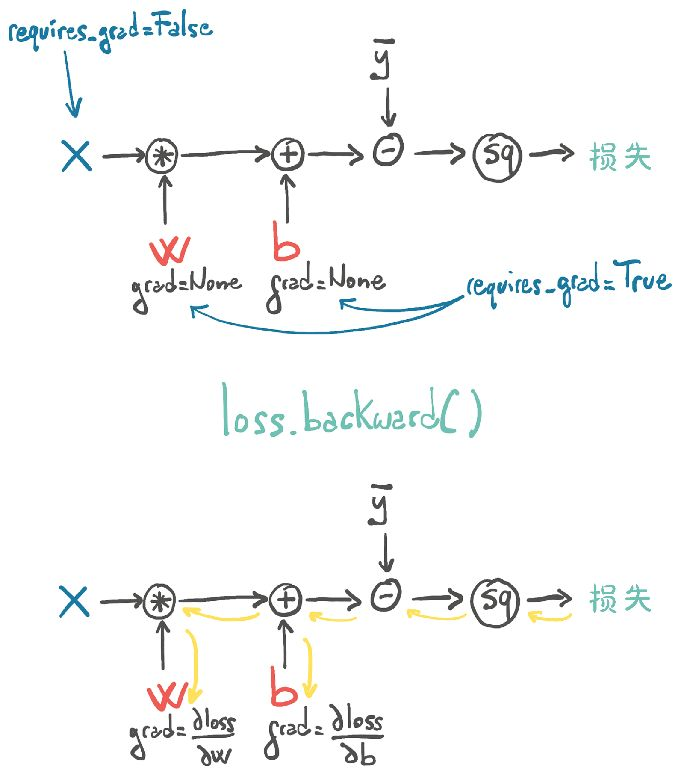
当我们计算损失时,参数w和b需要计算梯度。除了执行实际的计算外,PyTorch还创建了以操作(黑色圆圈)为节点的自动求导图。当我们调用loss.backward()时,PyTorch将反向遍历此图以计算梯度。
累加梯度函数
我们可以有任意数量的requires-grad为True的张量和任意组合的函数。在这种情况下,PyTorch将计算整个函数链(计算图)中损失的导数,并将它们的值累加到这些张量的grad属性中(图的叶节点)。
注意:调用backward()将导致导数在叶节点上累加。使用梯度进行参数更新后,我们需要显式地将梯度归零。
if params.grad is not None:
params.grad.zero_()
注意:你可能会好奇为什么梯度的归零是一个必要的步骤,而不是当我们调用backward()时自动进行归零。这样做为在复杂模型中使用梯度提供了更多的灵活性和控制力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号