
第十二章 Ganglia监控Hadoop及Hbase集群性能(安装配置)
1 Ganglia简介
Ganglia 是 UC Berkeley 发起的一个开源监视项目,设计用于测量数以千计的节点。每台计算机都运行一个收集和发送度量数据(如处理器速度、内存使用量等)的名为 gmond 的守护进程。它将从操作系统和指定主机中收集。接收所有度量数据的主机可以显示这些数据并且可以将这些数据的精简表单传递到层次结构中。正因为有这种层次结构模式,才使得 Ganglia 可以实现良好的扩展。gmond 带来的系统负载非常少,这使得它成为在集群中各台计算机上运行的一段代码,而不会影响用户性能。
1.1 Ganglia组件
Ganglia 监控套件包括三个主要部分:gmond,gmetad,和网页接口,通常被称为ganglia-web。
Gmond :是一个守护进程,他运行在每一个需要监测的节点上,收集监测统计,发送和接受在同一个组播或单播通道上的统计信息 如果他是一个发送者(mute=no)他会收集基本指标,比如系统负载(load_one),CPU利用率。他同时也会发送用户通过添加C/Python模块来自定义的指标。 如果他是一个接收者(deaf=no)他会聚合所有从别的主机上发来的指标,并把它们都保存在内存缓冲区中。
Gmetad:也是一个守护进程,他定期检查gmonds,从那里拉取数据,并将他们的指标存储在RRD存储引擎中。他可以查询多个集群并聚合指标。他也被用于生成用户界面的web前端。
Ganglia-web :顾名思义,他应该安装在有gmetad运行的机器上,以便读取RRD文件。 集群是主机和度量数据的逻辑分组,比如数据库服务器,网页服务器,生产,测试,QA等,他们都是完全分开的,你需要为每个集群运行单独的gmond实例。
一般来说每个集群需要一个接收的gmond,每个网站需要一个gmetad。
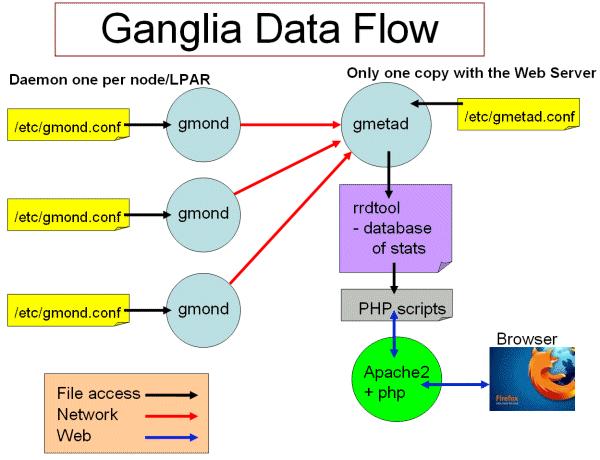
图1 ganglia工作流
Ganglia工作流如图1所示:
左边是运行在各个节点上的gmond进程,这个进程的配置只由节点上/etc/gmond.conf的文件决定。所以,在各个监视节点上都需要安装和配置该文件。
右上角是更加负责的中心机(通常是这个集群中的一台,也可以不是)。在这个台机器上运行这着gmetad进程,收集来自各个节点上的信息并存储在RRDtool上,该进程的配置只由/etc/gmetad.conf决定。
右下角显示了关于网页方面的一些信息。我们的浏览网站时调用php脚本,从RRDTool数据库中抓取信息,动态的生成各类图表。
1.2 Ganglia运行模式(单播与多播)
Ganglia的收集数据工作可以工作在单播(unicast)或多播(multicast)模式下,默认为多播模式。
单播:发送自己收集到的监控数据到特定的一台或几台机器上,可以跨网段。
多播:发送自己收集到的监控数据到同一网段内所有的机器上,同时收集同一网段内的所有机器发送过来的监控数据。因为是以广播包的形式发送,因此需要同一网段内。但同一网段内,又可以定义不同的发送通道。
2 环境
平台:ubuntu12.04
Hadoop: hadoop-2.2.0
Hbase: hbase-0.98
软件安装:apt-get
3 安装部署(单播)
3.1 部署方式
监测节点(gmond):192.168.0.27 192.168.0.28
主节点(gmetad、ganglia-web):192.168.0.26
3.2 安装
这里必须说明一个问题,我是在ubuntu下直接安装的。因为涉及到版本问题,hadoop-2.2.0和hbase-0.98均支持ganglia3.0和ganglia3.1版本,但是在配置时加载的模块是不一样的。所以,我们需要知道安装的ganglia是什么版本。
#sudo apt-cache show ganglia-webfrontend ganglia-monitor
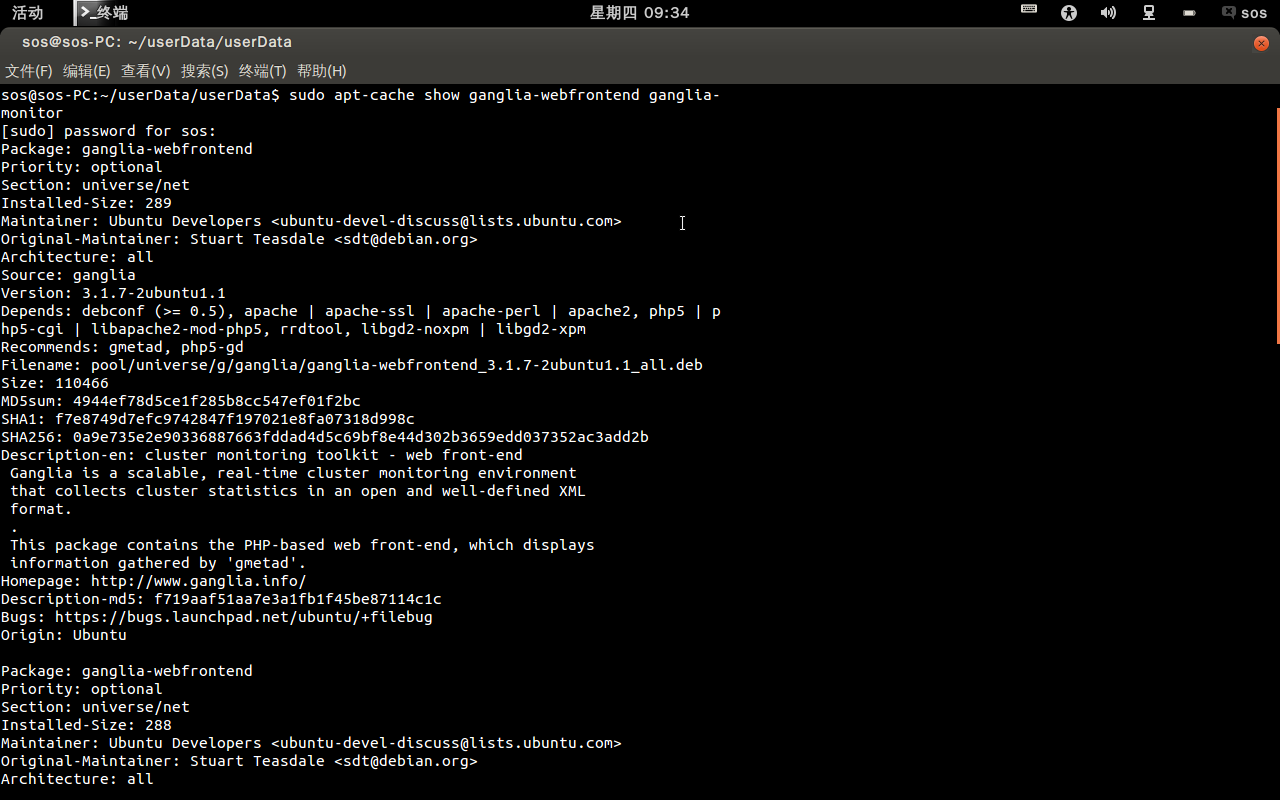
图3 安装版本信息
我们可以发现,安装的版本是ganglia3.1.7,所以是支持的。所以在26这台主机上安装ganglia-webfrontend和ganglia-monitor。在其他监视节点上,只需要安装ganglia-monitor即可。
在192.168.0.26上:
#sudo apt-get install ganglia-webfrontend ganglia-monitor
在192.168.0.27和192.168.0.28上:
#sudo apt-get install ganglia-monitor
将ganglia的文件链接到apache的默认目录下,只需要在26机子上运行
#sudo ln -s /usr/share/ganglia-webfront /var/www/ganglia
Ganglia-webfrontend等同与上面所说的gmetad及ganglia-web,同时还会自动帮你安装apache2和rrdtool,非常方便。
3.3 Ganglia配置
在各个节点上,都需要配置/etc/gmond.conf,配置相同如下所示:每个机器都是这样的配置,红色是修改部分
请注意send_metadata_interval被设置为10秒。Ganglia的度量指标从他的元数据间隔发送得到的。元数据包含诸如度量分组,类型等等。假如你重启了接收的gmond主机,那么元数据就会丢失,gmond就不知道如何处理度量数据,因此会把他们抛弃。这会导致生成空白的图表。在组播模式下,gmonds可以和其他任意一台主机通信,在元数据丢失情况请求重新获取。但这在单播模式下是不可能的,因此你需要命令gmond定期的发送元数据。
globals { daemonize = yes #以后台的方式运行 setuid = yes user = hadoop #运行gmond的用户 debug_level = 0 #调试级别 max_udp_msg_len = 1472 mute = no #哑巴,本节点将不会再广播任何自己收集到的数据在网络上 deaf = no #聋子,本节点不会再接收任何其他节点广播的数据包 host_dmax = 0 /*secs */ cleanup_threshold = 300 /*secs */ gexec = no #是否使用gexec send_metadata_interval = 10 #节点发送间隔/*secs*/ } /* If a cluster attribute is specified, then all gmond hosts are wrapped inside * of a <CLUSTER> tag. If you do not specify a cluster tag, then all <HOSTS> will * NOT be wrapped inside of a <CLUSTER> tag. */ cluster { name = "namenode2" #本节点属于哪个cluster owner = "hadoop" #谁是该节点的所有者 latlong = "unspecified" #在地球上的坐标 url = "unspecified" } /* The host section describes attributes of the host, like the location */ host { location = "unspecified" } /* Feel free to specify as many udp_send_channels as you like. Gmond used to only support having a single channel */ udp_send_channel {
#udp包的发送通道 # mcast_join = 239.2.11.71
host = 192.168.0.26 #多播,工作在192.168.0.26通道下。单播,则指向主节点,单播模式下也可以配置多个udp_send_channel port = 8649 #监听端口 ttl = 1 } /* You can specify as many udp_recv_channels as you like as well. */ udp_recv_channel { #接受UDP包配置 # mcast_join = 239.2.11.71 port = 8649 # bind = 239.2.11.71 }

在主节点上(192.168.0.26)上还需要配置/etc/gmetad.conf,这里面的名字“namenode2”和上面gmond.conf中应该是一致的。
data_source "namenode2" 192.168.0.26:8649
3.4 Hadoop配置
所有hadoop所在的节点,均需要配置hadoop-metrics.properties,配置如下:这个文件在hadoop-2.2.0/etc/hadoop下面,分别在dfs,mapred,jvm下面加入
# dfs.period=10
# dfs.servers=localhost:8649
dfs.class=org.apache.hadoop.metrics.ganglia.GangliaCOntext31
dfs.period=30
dfs.servers=192.168.0.26:8649
# mapred.period=10
# mapred.servers=localhost:8649
mapred.class=org.apache.hadoop.metrics.ganglia.GangliaCOntext31
mapred.period=30
mapred.servers=192.168.0.26:8649
# jvm.period=10
# jvm.servers=localhost:8649
jvm.class=org.apache.hadoop.metrics.ganglia.GangliaCOntext
jvm.class=org.apache.hadoop.metrics.ganglia.GangliaCOntext31
jvm.period=30
jvm.servers=192.168.0.26:8649
所有hadoop所在的节点,均需要配置hadoop-metrics2.properties,配置如下:
3.5 Hbase配置
所有hadoop所在的节点,均需要配置hadoop-metrics2-hbase.properties,配置如下:
# syntax: [prefix].[source|sink].[instance].[options]
# See javadoc of package-info.java for org.apache.hadoop.metrics2 for details
# *.sink.file*.class=org.apache.hadoop.metrics2.sink.FileSink
# default sampling period
# *.period=10 //这几行要注释掉,否则报错
# Below are some examples of sinks that could be used
# to monitor different hbase daemons.
# hbase.sink.file-all.class=org.apache.hadoop.metrics2.sink.FileSink
# hbase.sink.file-all.filename=all.metrics
# hbase.sink.file0.class=org.apache.hadoop.metrics2.sink.FileSink
# hbase.sink.file0.context=hmaster
# hbase.sink.file0.filename=master.metrics
# hbase.sink.file1.class=org.apache.hadoop.metrics2.sink.FileSink
# hbase.sink.file1.context=thrift-one
# hbase.sink.file1.filename=thrift-one.metrics
# hbase.sink.file2.class=org.apache.hadoop.metrics2.sink.FileSink
# hbase.sink.file2.context=thrift-two
# hbase.sink.file2.filename=thrift-one.metrics
# hbase.sink.file3.class=org.apache.hadoop.metrics2.sink.FileSink
# hbase.sink.file3.context=rest
# hbase.sink.file3.filename=rest.metrics
*.sink.ganglia.class=org.apache.hadoop.metrics2.sink.ganglia.GangliaSink31
*.sink.ganglia.period=10
hbase.sink.ganglia.period=10
hbase.sink,ganglia.servers=192.168.0.26:8649
4 启动与检验
先需要重启hadoop和hbase 。在各个节点上启动gmond服务,主节点还需要启动gmetad服务。
#sudo service ganglia-monitor start //192.168.0.26,192.168.0.27,192.168.0.28都需要启动
#sudo service gmetad start //在192.168.0.26再次启动
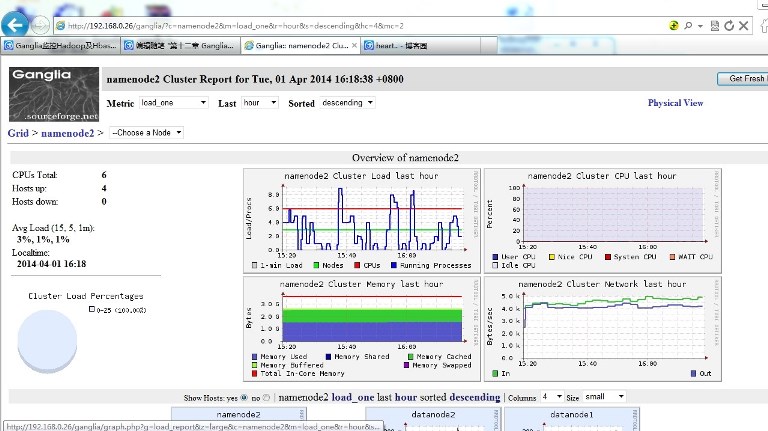
启动完以后,在网页上面输入http://192.168.0.26/ganglia

 浙公网安备 33010602011771号
浙公网安备 33010602011771号