
[大数据学习研究] 错误排查,Hadoop集群部分DataNode不能启动
错误现象
不知道什么原因,今天发现我的hadoop集群启动后datanode只有一台了,我的集群本来有三台的,怎么只剩一台了呢?
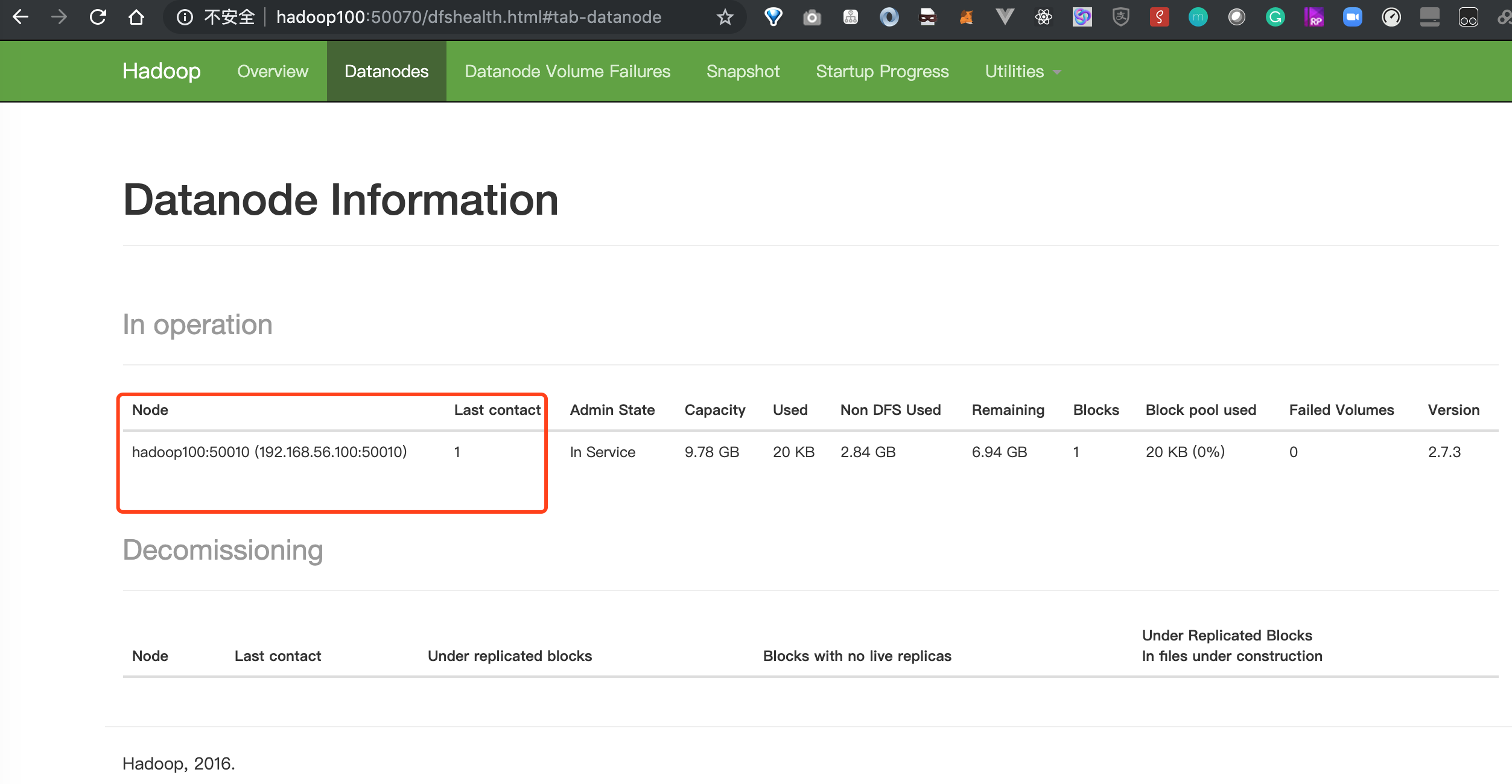
用jps命令检查一下,发现果然有两台机器的DataNode没有启动。

可能原因:
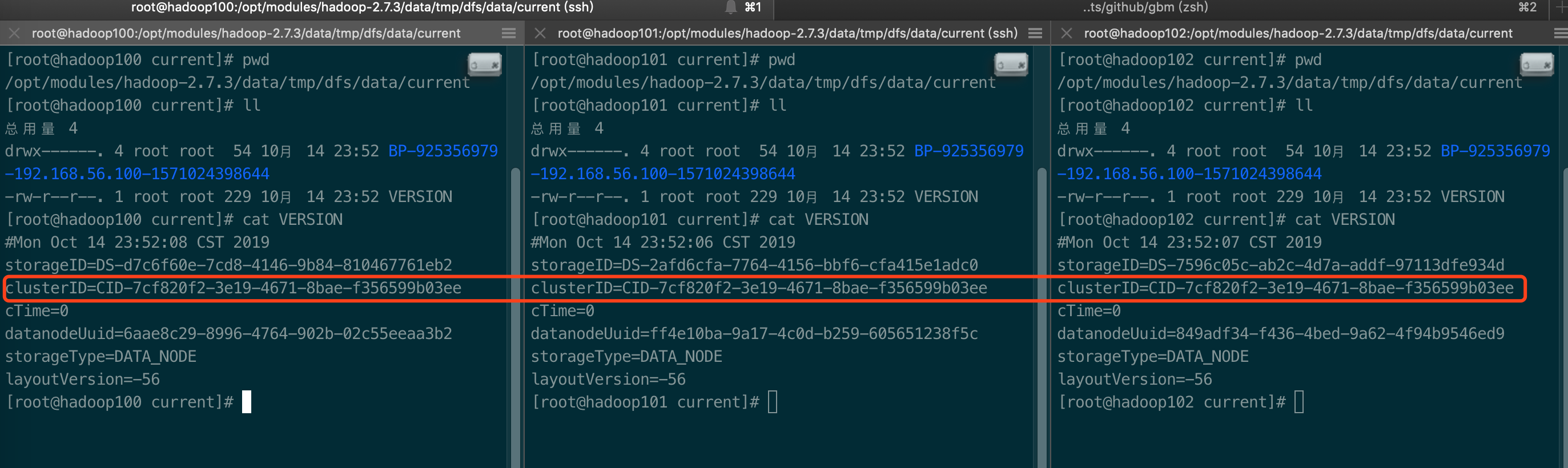
1. 我之前遇到过的问题,由于多次运行hdfs namenode -format, 造成了clusterId不一致,检查一下:进入到/opt/modules/hadoop-2.7.3/data/tmp/dfs/data/current目录下,cat显示一下VERSION文件的内容,检查集群中的几台机器的ClusterID是不是一致。我的机器这三台机器的clusterid是一致的,看起来没问题。如果要是不一致的话,需要改过来,改成一致的,然后用 hadoop-daemon.sh start datanode 就可以启动datanode了,我的不是这个问题引起的,还得继续排查。
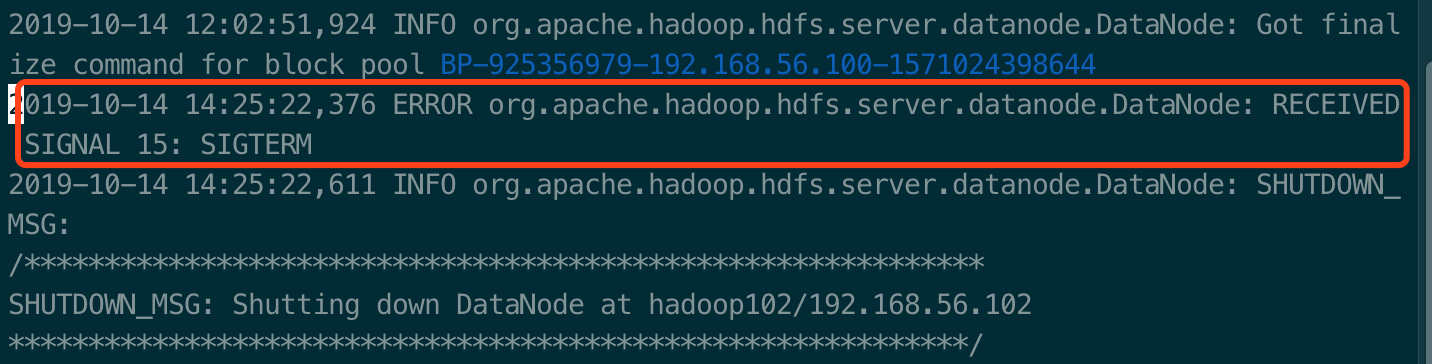
2. 不知道什么原因,还是看看日志,进入的出问题的机器上的logs目录下,打开日志文件,跳到最后,从后面往前看,终于在一堆INFO里面看到一条ERROR:
[root@hadoop101 logs]# pwd
/opt/modules/hadoop-2.7.3/logs
[root@hadoop101 logs]# vi hadoop-root-datanode-hadoop101.log
2019-10-14 14:25:22,376 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: RECEIVED SIGNAL 15: SIGTERM
解决问题
什么原因引起的不清楚,放狗搜了一下,有人说重启服务就好了,当然还是要试一下这个重启大法。关闭服务,再重启一下相关服务,就解决了,好没趣。
stop-all.sh 等带完成 start-dfs.sh start-yarn.sh
另外,这个帖子里说调用一下hadoop dfsadmin -refreshNodes就好了,但我没用上,反正先重启就搞定了,要还有下次的话再试试吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号