NoSQL & Redis 介绍、下载、配置
NoSQL 介绍
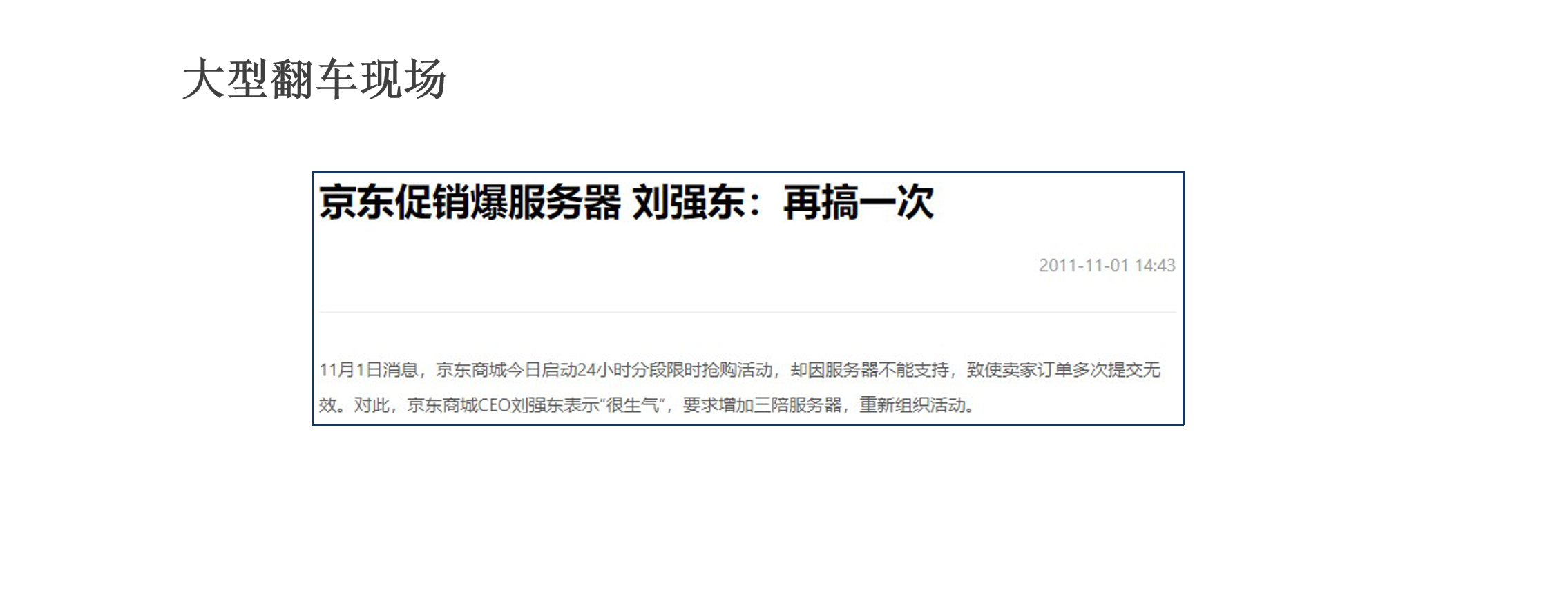
问题现象
在讲解 NoSQL 的概念之前呢,我们先来看一个现象:
每年到了过年期间,大家都会自觉自发的组织一场活动,叫做春运!以前我们买票都是到火车站排队,后来呢,有了 12306,有了它以后就更方便了,我们可以在网上买票,但是带来的问题,大家也很清楚,春节期间买票进不去,进去了刷不着票。什么原因呢,人太多了!

除了这种做铁路的,它系统做的不专业以外,还有马爸爸做的淘宝,它面临一样的问题。淘宝也崩,也是用户量太大!作为我们整个电商界的东哥来说,他第一次做图书促销的时候,也遇到了服务器崩掉的这样一个现象,原因同样是因为用户量太大!
现象特征
再来看这几个现象,有两个非常相似的特征:
-
用户比较多,海量用户
-
高并发
这两个现象出现以后,对应的就会造成我们的服务器瘫痪。核心本质是什么呢?其实并不是我们的应用服务器,而是我们的关系型数据库。关系型数据库才是最终的罪魁祸首!
什么样的原因导致的整个系统崩掉的呢:
1)性能瓶颈:磁盘 I/O 性能低下
关系型数据库菜存取数据的时候和读取数据的时候他要走磁盘 I/O。磁盘这个性能本身是比较低的。
2)扩展瓶颈:数据关系复杂,扩展性差,不便于大规模集群
我们说关系型数据库,它里面表与表之间的关系非常复杂,不知道大家能不能想象一点,就是一张表,通过它的外键关联了七八张表,这七八张表又通过她的外件,每张又关联了四五张表。你想想,查询一下,你要想拿到数据,你就要从 A 到 B、B 到 C、C 到 D 的一直这么关联下去,最终非常影响查询的效率。同时,你想扩展下,也很难!
解决思路:
面对这样的现象,我们要想解决怎么版呢。两方面:
-
降低磁盘 I/O 次数,越低越好。
-
去除数据间关系,越简单越好。
降低磁盘 I/O 次数,越低越好,怎么搞?我不用你磁盘不就行了吗?于是,内存存储的思想就提出来了,我数据不放到你磁盘里边,放内存里,这样是不是效率就高了。
第二,你的数据关系很复杂,那怎么办呢?干脆简单点,我断开你的关系,我不存关系了,我只存数据,这样不就没这事了吗?
把这两个特征一合并一起,就出来了一个新的概念:NoSQL 。
NoSQL 定义
定义
NoSQL:即 Not-Only SQL( 泛指非关系型的数据库),作为关系型数据库的补充,常用于超大规模数据的存储(例如 google 或 facebook 每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的(表结构)模式,且更容易横向扩展。
什么意思呢?就是我们数据存储要用 SQL,但是可以不仅仅用 SQL,还可以用别的东西,那别的东西叫什么呢?于是他定义了一句话叫做 NoSQL。这个意思就是说我们存储数据,可以不光使用 SQL,还可以使用非 SQL 的这种存储方案,这就是所谓的 NoSQL 。
优势
-
可扩容,可伸缩
SQL 数据关系过于复杂,你扩容一下难度很高,但我们 Nosql 这种的不存关系,所以它的扩容就简单一些。 -
大数据量下的高性能
当数据非常多的时候,它的性能高,因为你不走磁盘 I/O,你走的是内存,性能肯定要比磁盘 I/O 的性能快一些。 -
灵活的数据模型、高可用
NoSQL 数据存储结构比关系型数据库的更丰富,传统关系型数据库都是结构化的表,而 NoSQL 可以是列式存储、Key-Value、文档存储、图存储等。 -
高可用
多数 NoSQL 都支持分布式、集群部署。 -
授权费用低
NoSQL 授权费用也比较低,相比较 Oracle 这种企业级授权费用是低了不少。
劣势
- 没有标准化:不支持 SQL 这样的工业标准查询,所以学习成本就比较高。
- 大多数 NoSQL 都不支持事务(Redis 支持,MongoDB 不支持)。
- NoSQL 只能保证数据相对一致性,尤其是在数据同步的时候,主从服务器的状态是不一致的。
- 大多都是初创产品,不够成熟,和传统数据库几十年的完善不可同日而语。
常见 Nosql 数据库
| 类型 | 部分代表 | 特点 |
|---|---|---|
| 列存储 | Hbase、Cassandra、Hypertable | 顾名思义,是按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的 I/O 优势。 |
| 文档存储 | MongoDB、CouchDB | 文档存储一般用类似 Json 的格式存储,这样也就有机会对某些字段建立索引,实现关系数据库的某些功能。 |
| Key-Value 存储 | Redis、Tokyo Cabinet / Tyrant、Berkeley DB、MemcacheDB | 可以通过 Key 快速查询到其 Value。一般来说,存储不管 Value 的格式,照单全收。(Redis 包含了其他功能) |
| 图存储 | Neo4J、FlockDB | 图形关系的最佳存储。使用传统关系数据库来解决的话性能低下,而且设计使用不方便。 |
| 对象存储 | db4o、Versant | 通过类似面向对象语言的语法操作数据库,通过对象的方式存取数据。 |
| XML 数据库 | Berkeley DB XML、BaseX | 高效的存储 XML 数据,并支持 XML 的内部查询语法,比如 XQuery、Xpath。 |
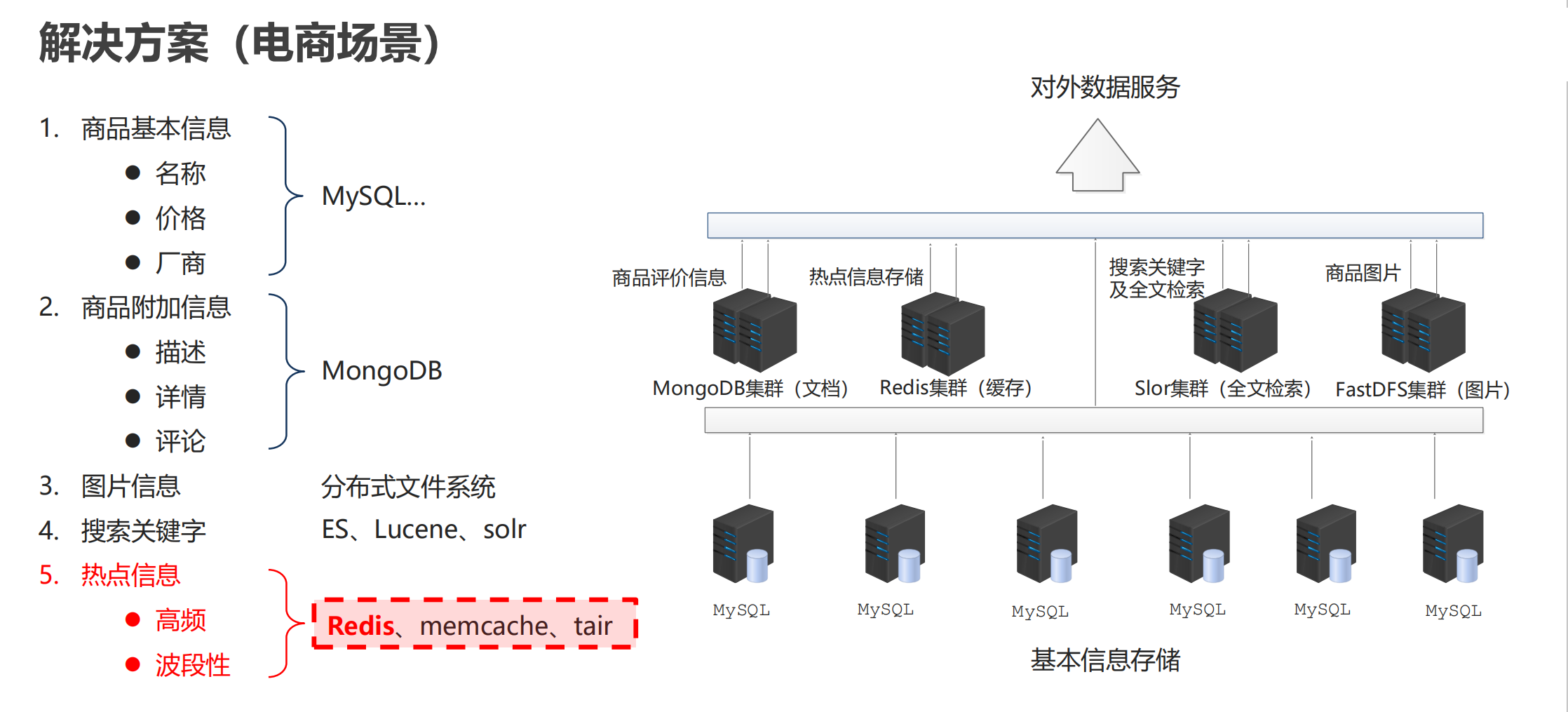
应用场景示例:电商
我们以电商为例,来看一看 NoSQL 在这里边起到的作用。
-
第一类,在电商中我们的基础数据一定要存储起来,比如说商品名称,价格,生产厂商,这些都属于基础数据,这些数据放在MySQL数据库。
-
第二类,商品的附加信息。比如说,你买了一个商品评价了一下,这个评价它不属于商品本身。就像你买一个苹果,“这个苹果很好吃”就是评论,但是你能说很好吃是这个商品的属性嘛?不能这么说,那只是一个人对他的评论而已。这一类数据呢,我们放在另外一个地方,我们放到 MongoDB。它也可以用来加快我们的访问,它也属于 NoSQL 的一种。
-
第三,图片类的信息。注意这种信息相对来说比较固定,他有专用的存储区,我们一般用文件系统来存储。至于是不是分布式,要看你的系统的一个整个瓶颈了?如果说你发现你需要做分布式,那就做,不需要的话,一台主机就搞定了。
-
第四,搜索关键字。为了加快搜索,我们会用到一些技术,有些人可能了解过,像分 ES、Lucene、solr 都属于搜索技术。那说的这么热闹,我们的电商解决方案中还没出现我们的 redis 啊!注意第五类信息。
-
第五,热点信息。访问频度比较高的信息,这种东西的第二特征就是它具有波段性。换句话说他不是稳定的,它具有一个时效性的。那么这类信息放哪儿了,放到我们的 redis 这个解决方案中来进行存储。
CAP 定理 & BASE
CAP:
在计算机科学中, CAP定理(CAP theorem), 又被称作布鲁尔定理(Brewer's theorem), 它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
一致性(Consistency):所有节点在同一时间具有相同的数据。可用性(Availability):保证每个请求不管成功或者失败都有响应。分隔容忍(Partition tolerance):系统中任意信息的丢失或失败不会影响系统的继续运作。
CAP 理论的核心是:一个分布式系统不可能同时很好的满足一致性、可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三大类:
- CA:单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
- CP:满足一致性、分区容忍性的系统,通常性能不是特别高。
- AP:满足可用性、分区容忍性的系统,通常可能对一致性要求低一些。
BASE:
BASE(Basically Available, Soft-state, Eventually Consistent)是 NoSQL 数据库通常对可用性及一致性的弱要求原则:
- Basically Available:基本可用。
- Soft-state:软状态/柔性事务。 "Soft state" 可以理解为"无连接"的, 而 "Hard state" 是"面向连接"的。
- Eventually Consistency:最终一致性, 也是 ACID 的最终目的。
Redis 介绍
定义:
Redis(REmote DIctionary Server)是一款用 C 语言开发的、开源的 NoSQL 数据库,是一个高性能的、数据格式为 Key-Value 的、分布式的、内存数据库,同时也支持数据持久化。
特征:
- 数据间没有必然的关联关系。
- 内部采用单线程机制进行工作。
- 高性能。官方提供测试数据,50 个并发执行 10W 个请求,读的速度是 11W 次/s,写的速度是 8.1W 次/s。
- 多数据类型支持。
- 支持持久化,可以进行数据灾难恢复。
注意:
Redis 虽然是以单线程架构被大家所知,但是这个单线程指的是「从网络 IO 处理到实际的读写命令处理」都是由单个线程完成的,并不是说整个 Redis 里只有一个主线程。
有些命令操作可以用后台子进程执行(比如快照生成、AOF 重写)。
严格意义上说的话,Redis 4.0 之后并不是单线程架构了,除了主线程外,它也有后台线程在处理一些耗时比较长的操作,例如清理脏数据、无用连接的释放、大 Key 的删除等等。
你可能听到 Redis 6.0 版本支持了多线程技术,不过这个并不是指多个线程同时在处理读写命令,而是使用多线程来处理 Socket 的读写,最终执行读写命令的过程还是只在主线程里。
之所以采用多线程 I/O 是因为 Redis 处理请求时,网络处理经常是瓶颈,通过多个 I/O 线程并发处理网络操作,可以提升整体处理性能。
那为什么处理操作命令的过程只在单线程里呢?
-
因为 Redis 不存在 CPU 成为瓶颈的情况,主要受限于内存和网络。
-
而且使用单线程的好处在于,可维护性高、实现简单。
如果采用多线程模型来处理读写命令,虽然能提升并发性能,但是它却引入了程序执行顺序的不确定性,带来了并发读写的一系列问题,增加了系统复杂度、同时可能存在线程切换、甚至加锁解锁、死锁造成的性能损耗。
redis 的应用场景:
为热点数据加速查询(主要场景)。如热点商品、热点新闻、热点资讯、推广类等高访问量信息等。- 即时信息查询。如各位排行榜、各类网站访问统计、公交到站信息、在线人数信息(聊天室、网站)、设备信号等。
- 时效性信息控制。如验证码控制、投票控制等。
- 分布式数据共享。如分布式集群架构中的 session 分离。
- 消息队列。
Redis 安装
1)在线安装:
yum install redis
2)离线安装:打开 redis 官方网站,推荐下载稳定版本(stable)
# 解压:
tar zxvf redis-3.2.5.tar.gz
# 复制:推荐放到 usr/local 目录下:
sudo mv -r redis-3.2.3/* /usr/local/redis/
# 进入 redis 目录,进行编译:
cd /usr/local/redis/
sudo make
# 安装:将 redis 的命令安装到 /usr/bin/ 目录
sudo make install
Redis 启动
Redis 服务端启动
1)默认参数启动:
redis-server
2)参数启动:
redis-server [--port port]
# 示例:redis-server --port 6379
3)配置文件启动:
redis-server config_file_name
# 示例:redis-server redis.conf
客户端启动
1)默认参数启动:
redis-cli
- 默认 ip 为【127.0.0.1】,port 为【6379】
2)参数启动:
redis-cli [-h host] [-p port]
# 示例:redis-cli –h 61.129.65.248 –p 6384
注意:服务器启动指定端口使用的是--port,客户端启动指定端口使用的是-p,“-”的数量不同。
Redis 配置
Redis 基础环境设置约定
# 创建配置文件存储目录
mkdir conf
# 创建服务器文件存储目录(包含日志、数据、临时配置文件等)
mkdir data
# 创建快速访问链接
ln -s redis-5.0.0 redis
配置文件启动与常用配置
服务器端设定
# 设置服务器以守护进程的方式运行,开启后服务器控制台中将打印服务器运行信息(同日志内容相同)
daemonize yes|no
# 绑定主机地址
bind ip
# 设置服务器端口
port port
# 设置服务器文件保存地址
dir path
客户端配置
# 服务器允许客户端连接最大数量,默认0,表示无限制。当客户端连接到达上限后,Redis会拒绝新的连接
maxclients count
# 客户端闲置等待最大时长,达到最大值后关闭对应连接。如需关闭该功能,设置为 0
timeout seconds
日志配置
# 设置服务器以指定日志记录级别
loglevel debug|verbose|notice|warning
# 日志记录文件名
logfile filename
注意:日志级别开发期设置为 verbose 即可,生产环境中配置为 notice,简化日志输出量,降低写日志 I、O 的频度。
Redis 基础操作
选择数据库
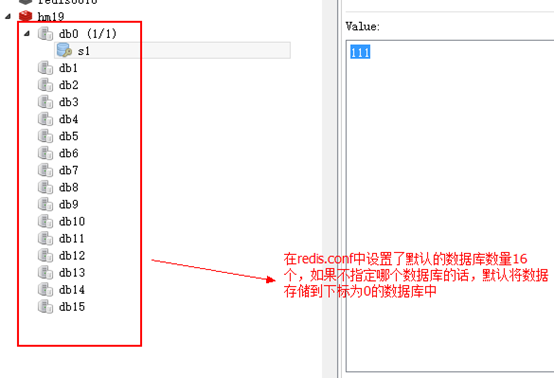
在 redis.conf 中,数据库数量的配置项如下:
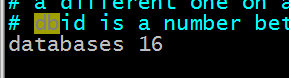
使用 select 加上数据库的下标就可以选择指定的数据库来使用,下标从 0 开始:
127.0.0.1:6379> select 15
OK
127.0.0.1:6379[15]>
信息读写
# 设置 key,value 数据
set key value
# 示例:set name itheima
# 根据 key 查询对应的 value,如果不存在,返回空(nil)
get key
# 示例:get name
帮助信息
# 获取命令帮助文档
help [command]
# 示例:help set
# 获取组中所有命令信息名称
help [@group-name]
# 示例:help @string
退出命令行客户端模式
# 退出客户端
quit
exit
# 快捷键
Ctrl+C

 浙公网安备 33010602011771号
浙公网安备 33010602011771号