XPath 与 CSS 定位方式
XPath
XPath 简介
什么是 XPath?
-
XPath 是一门
在 XML 文档中查找信息的语言。 -
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集,这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
-
XPath 含有超过 100 个内建的函数。这些函数用于字符串值、数值、日期和时间比较、节点和 QName 处理、序列处理、逻辑值等等。
XPath 术语
-
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。
-
XML 文档是被作为节点树来对待的。
-
树的根被称为文档节点或者根节点。
XPath 表达式
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 作为起始符时,表示从根节点开始选取; 作为中间符时,表示从子节点中选取 |
| // | 作为起始符时,表示相对路径; 作为中间符时,表示从子孙节点中选取 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
XPath 运算符
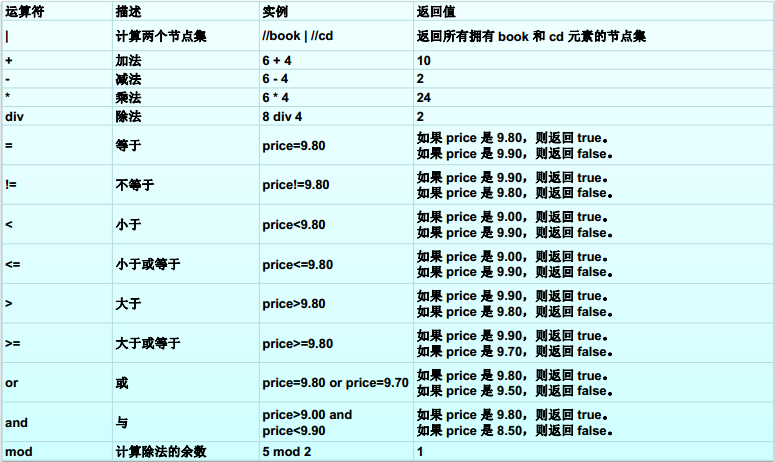
亲属关系匹配
| 表达式 | 结果 |
|---|---|
parent::* |
表示当前节点的父节点元素 |
ancestor::* |
表示当前节点的祖先节点元素 |
child::* |
表示当前节点的子元素 |
descendant::* |
表示当前节点的所有后代元素 |
self::* |
表示当前节点的自身元素 |
ancestor-or-self::* |
表示当前节点的及它的祖先节点元素 |
descendant-or-self::* |
表示当前节点的及它们的后代元素 |
following-sibling::* |
表示当前节点的后序所有兄弟节点元素 |
preceding-sibling::* |
表示当前节点的前面所有兄弟节点元素 |
following::* |
表示当前节点的后序所有元素 |
preceding::* |
表示当前节点的所有元素 |
综合示例
http://www.w3school.com.cn/example/xmle/books.xml
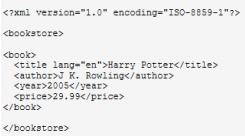
| 路径表达式 | 结果 |
|---|---|
/bookstore |
选取根元素 bookstore |
//book |
选取所有 book 子元素,而不管它们在文档中的位置 |
//* |
选取文档中的所有元素 |
/bookstore/* |
选取 bookstore 元素的所有子元素 |
/bookstore//book |
选取属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置 |
/bookstore/book[1] |
选取属于 bookstore 子元素的第一个 book 元素 |
/bookstore/book[last()] |
选取属于 bookstore 子元素的最后一个 book 元素 |
/bookstore/book[last()-1] |
选取属于 bookstore 子元素的倒数第二个 book 元素 |
/bookstore/book[position()<3] |
选取最前面的两个属于 bookstore 元素的子元素的 book 元素 |
//*[@lang] |
选取包含 lang 属性的所有元素 |
//title[@lang='eng'] |
选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性 |
/bookstore/book[price>35.00] |
选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00 |
/bookstore/book[price>35.00]/title |
选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00 |
//book[@category='web' and @cover='paperback'] |
使用多个属性构成唯一的属性组合 |
//*[.='Everyday Italian'] |
精确匹配文本 |
//*[text()='Everyday Italian'] |
精确匹配文本 |
//title[contains(., 'Everyday')] |
模糊匹配文本 |
//title[contains(text(), 'Everyday')]/.. |
模糊匹配文本 |
//title[starts-with(text(), 'Every')]/.. |
匹配文本开头 |
//title[ends-with(text(), 'day')]/.. |
匹配文本结尾 |
//book[2]/child::title |
定位到下一级的 title 节点 |
//book[2]/child::* |
定位到下一级的所有子节点 |
//book[2]/title/.. |
定位父节点 |
//book[2]/title/parent::book |
定位父节点 |
CSS Selector(选择器)
| 选择器 | 例子 | 例子描述 |
|---|---|---|
| .class | .introl | 选择 class="intro" 的所有元素 |
| #id | #firstname | 选择 id="firstname" 的所有元素 |
| * | * | 选择所有元素 |
| element | p | 选择所有 <p> 元素 |
| element,element | div,p | 选择所有 <div> 元素和所有 <p> 元素 |
| element element | div p | 选择所有 <div> 元素内部的所有 <p> 元素 |
| element>element | div>p | 选择父元素为 <div> 元素的所有 <p> 元素 |
| element+element | div+p | 选择紧接在 <div> 元素之后的所有 <p> 元素 |
| [attribute] | [target] | 选择带有 target 属性的所有元素 |
| [attribute=value] | [target=_blank] | 选择 target="_blank" 的所有元素 |
| :nth-child(n) | p:nth-child(2) | 选择属于其父元素的第二个子元素的每个 <p> 元素 |
| element1~element2 | p~ul | 选择前面有 <p> 元素的每个 <ul> 元素 |
XPath 与 CSS Selector 区别
1)CSS Selector 比 XPath 速度快,特别是在 IE 下面(IE 没有自己的XPath 解析器)。
2)对于文本的处理,xpath 的使用更强大。
需要注意的是,Xpath 的 text() 获取的是当前元素的文本,而不包括其子元素的文本。
- 示例元素:
<div id="id1">
<span>Memo<span>
Please click here
</div>
- XPath 的 text() 得到的结果是 "Please click here" 。
- CSS 的 $("#id1").text() 获取的则是 "Memo Please click here" 。
- 使用 selenium 获取元素 text 也是 "Memo Please click here" 。
3)对于 class 属性,CSS 能直接模糊匹配;而 Xpath 对于 class 属性跟普通属性一致,需要使用 contains() 函数才能匹配部分字符串。
- 示例元素:
<div class="class1 popup js-dragable alert-msg">
<div class ="class2 submit-box ">
<input class ="class3"/>
</div>
</div>
- 表达式:
String locatorXpath1 = "//div[@class='class1 popup js-dragable alert-msg']//input[@class='class3']";
String locatorXpath2 = "//div[contains(@class,'popup js-dragable alert-msg')]//input[@class='class3']";
String locatorCss = ".class1.js-dragable .class3"
4)使用祖先元素属性与当前元素属性组合处理时。
- 示例元素:
<div class="111">
<div>
<div>
<input class = "222"/>
</div>
</div>
</div>
- 表达式:
String locatorXpath1 = "//div[@class='111'/*/*/*[@class='222']]";
String locatorXpath2 = "//div[@class='111'//[@class='222']]";
String locatorCss = ".111 .222";
5)模糊匹配。
模糊匹配属性值中的部分文本:
| XPath | Css |
|---|---|
| //span[contains(@class,'popup-btn js-dragable')] | span[title*='456'] |
| //input[starts-with(@name,'name1')] | input[name^='name1'] |
| //input[ends-with(@name,'name1')] | input[name$='name1'] |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号