MySQL 存储过程、函数、触发器
1. 存储过程和函数
2. 触发器
1. 存储过程和函数
什么是存储过程?
存储过程和函数是事先经过编译并存储在数据库中的一组 SQL 语句集,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它(无需再编译,直接走执行计划)。
存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象。其思想上很简单,就是数据库 SQL 语言层面的代码封装与重用。
优势
- 可以回传值,并可以接受参数。
- 可以减少程序在调用 DB 时候的信息传输量(其实减少的只有 Request)。
- 存储过程是预先优化和预编译的,节省每次运行编译的时间,所以一般情况下认为存储过程的性能是优于 SQL 语句的。
- 对调用者来说,可以隐藏数据库的复杂性,因为将数据组装的过程进行了封装。
- 参数化的存储过程可以防止 SQL 注入;而且可以将 Grant、Deny 以及 Revoke 权限应用于存储过程。
- 如果在业务开发中,数据人员和业务代码人员是分离的,那么业务人员可以不用关心数据,直接调用存储过程,更加面向分层开发设计理念。
劣势
- 存储过程这种“一次优化,多次使用”的策略节省了每次执行时候编译的时间,但也是该策略导致了一个致命的缺点:随着数据量的增加或数据结构的变化,原来存储过程选择的执行计划也许并不是最优的。
- 存储过程难以调试,受限于各种数据库系统。虽然有些 DB 提供了调试功能,但是一般的账号根本就没有那种权限,更何况线上的数据库不可能会给你调试权限的。再进一步讲,就算能调试效果也比程序的调试要差很多。
- 可移植性差,当碰到切换数据库类型时,存储过程基本就会歇菜。
- 如果业务数据模型有变动,则存储过程必须跟着业务代码一起更改,如果是大型项目,这种改动是空前的,是要命的。
为什么不推荐使用存储过程
以上存储过程的优缺点,你随便一下网络就可能查到,表面看来存储过程的优势还是不少的,这也说明为什么老一辈程序员有很多喜欢写存储过程。但是随着软件行业业务日益复杂化,存储过程现在在复杂业务的面前其实有点有心无力。
在业务中并不推荐使用存储过程
采用存储过程操作数据在网络数据量传输上确实比直接使用 SQL 语句要少很多,但这通常并不是操作数据系统性能的瓶颈,在一次操作数据的过程中,假设用时 100 毫秒,就算采用存储过程可以节省数据传输时间 0.5 毫秒(即使是 5 毫秒),这点时间也基本可以忽略。
存储过程是只优化一次的,这有时候恰恰是个缺陷。有的时候随着数据量的增加或者数据结构的变化,原来存储过程选择的执行计划也许并不是最优的了,所以这个时候需要手动干预或者重新编译了,而什么时候执行计划不是最优的了这个平衡点,预先无法知晓,这就导致了有些应用突然会变慢,程序员处于懵逼的状态。
存储过程确实可以对调用方隐藏数据库的细节,但是这种业务代码人员和数据库设计人员是两个团队的情况又有多少呢,如果真是两个团队,那业务就需要两个团队来理解和沟通,我想沟通的成本也一定很高,而且分歧更容易产生。
数据库就应该做它最擅长的事情:存储相关。一个业务系统的设计往往需要你从数据库的层面抽离出来,把主要精力放在业务模型的设计上,在程序层面体现业务逻辑,而不是把业务逻辑都交给数据层面的管理者。而头疼的还不是业务,而是看着好几千行的存储过程熟悉业务,关键还没有调试的权限(线上更不能调试)。
举例常见的一种“Bug”:存储过程是输入参数是一个主键 id 的列表字符串,长度居然是 nvarchar(max),主要功能是根据 id 列表查询数据。我想说的是就算你是 max 的长度,也有超长的可能性发生,因为业务方传输什么参数,参数什么长度是你 DB 无法控制的,所以这类的业务一定要放在程序中做处理,而不是怀着侥幸心里丢给 DB。
如果是抱着存储过程性能高的心态的话,倒可能是误入歧途,因为存储过程从来都不是提高性能的关键,反而系统的架构、缓存的设计、数据一致性更是系统关键问题。
从面向对象的角度考虑,针对业务应该尽量少用存储过程,而可以用存储过程来做一些日常维护,如数据历史迁移等等。
存储过程通常是一种解决方案,但是通常情况下不是唯一的解决方案,在选择存储过程作为方案前,请确保他们是正确的选择。
其他看法
除了上述观点之外,下面还给大家整理了一下其它关于是否要使用从存储过程的观点。
观点一:

观点二:

观点三:

观点四:

观点五:

MySQL 存储过程的使用示例
创建语法
CREATE [DEFINER = { user | CURRENT_USER }] PROCEDURE sp_name ([proc_parameter[,...]]) [characteristic ...] routine_body proc_parameter: [ IN | OUT | INOUT ] param_name type characteristic: COMMENT 'string' | LANGUAGE SQL | [NOT] DETERMINISTIC | { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA } | SQL SECURITY { DEFINER | INVOKER } routine_body: Valid SQL routine statement [begin_label:] BEGIN [statement_list] …… END [end_label]
关键语法
声明语句结束符,可以自定义:
DELIMITER $$ 或 DELIMITER //
声明存储过程:
CREATE PROCEDURE demo_in_parameter(IN p_in int)
存储过程开始和结束符号:
BEGIN .... END
变量赋值:
SET @p_in=1
变量定义:
DECLARE l_int int unsigned default 4000000;
创建 MySQL 存储过程、存储函数:
create procedure 存储过程名(参数)
存储过程体:
create function 存储函数名(参数)
- 存储过程体包含了在过程调用时必须执行的语句,例如:dml、ddl 语句,if-then-else 和 while-do 语句、声明变量的 declare 语句等。
- 过程体格式:以 begin 开始,以 end 结束(可嵌套)。
BEGIN BEGIN BEGIN statements; END END END
注意:每个嵌套块及其中的每条语句,必须以分号结束,表示过程体结束的 begin-end 块(又叫做复合语句 compound statement)则不需要分号。
为语句块贴标签:
- 增强代码的可读性。
- 在某些语句(例如 leave 和 iterate 语句),需要用到标签。
[begin_label:] BEGIN [statement_list] END [end_label]
例如:
label1: BEGIN label2: BEGIN label3: BEGIN statements; END label3 ; END label2; END label1
存储过程的参数
MySQL 存储过程的参数用在存储过程的定义,共有三种参数类型 IN, OUT, INOUT, 形式如:
CREATEPROCEDURE 存储过程名([[IN |OUT |INOUT ] 参数名 数据类形...])
- IN 输入参数:表示调用者向过程传入值(传入值可以是字面量或变量)。
- OUT 输出参数:表示过程向调用者传出值(可以返回多个值)(传出值只能是变量)。
- INOUT 输入输出参数:既表示调用者向过程传入值,又表示过程向调用者传出值(值只能是变量)。
调用存储过程
call sp_name[(传参)];
查看存储过程列表
show procedure status;
查看存储过程明细
show create procedure 存储过程名;
示例
-- 创建存储过程 delimiter // create procedure emp_proc1(IN no int, out deptcount int) Begin select count(*) into deptcount from emp where deptno=no; end// delimiter ; -- 调用存储过程 call emp_proc1(1, @deptcount); -- 查看输出参数 select @deptcount; -- 创建函数 create function hello(s CHAR(20)) RETURNS CHAR(50) DETERMINISTIC RETURN CONCAT('Hello ',s,'!'); -- 调用函数 select hello('Liming');
2. 触发器
触发器(TRIGGER)是特殊的存储过程,由事件来触发某个操作,事件包括 INSERT、UPDATE 和 DELETE 语句;可以协助应用在数据库端确保数据的完整性。如在定义完触发器后,会在 INSERT、UPDATE 和 DELETE 语句执行前或执行后自动执行触发器中的内容。
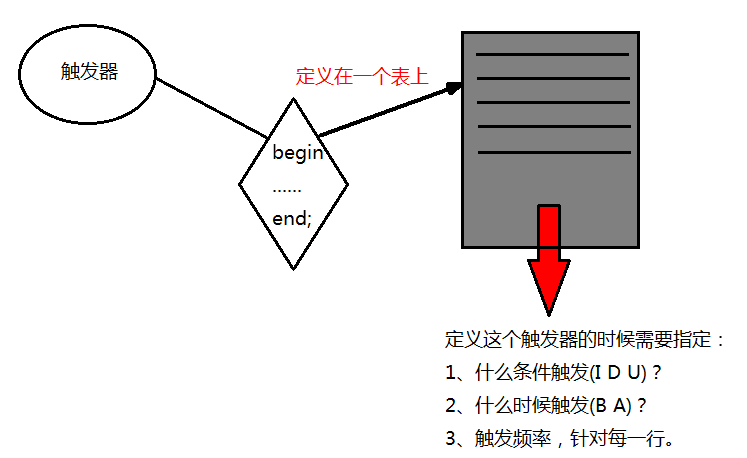
注意:cannot associate a trigger with a TEMPORARY table or a view.
触发器和存储过程的对比
- 存储过程和触发器二者是有很大的联系的,可以把触发器理解为一个隐藏的存储过程,因为它不需要参数,不需要显式调用,往往在你不知情的情况下已经做了很多操作。从这个角度来说,由于是隐式的,无形中增加了系统的复杂性。
- 再有,涉及到复杂逻辑的时候,触发器的嵌套是避免不了的,如果再涉及几个存储过程,再加上事务等等,很容易出现死锁现象,再调试的时候也会经常性地从一个触发器转到另外一个,级联关系的不断追溯,很容易使人头大。其实,从性能上,触发器并没有提升多少性能,只是从代码上来说可能在 coding 的时候很容易实现业务。
- 在编码中存储过程显式调用很容易阅读代码,触发器隐式调用容易被忽略。
综上:尽量少使用触发器,不建议使用。
假设触发器每次执行耗时 1s,insert table 500 条数据,那么就需要触发 500 次触发器,光是触发器执行的时间就花费了 500s。因此我们特别需要注意的一点是触发器的 begin end; 之间的语句的执行效率一定要高,资源消耗要小。
MySQL 触发器使用示例
创建语法
CREATE [DEFINER = { user | CURRENT_USER }] TRIGGER trigger_name trigger_time trigger_event ON tbl_name FOR EACH ROW [trigger_order] trigger_body trigger_time: { BEFORE | AFTER } trigger_event: { INSERT | UPDATE | DELETE } trigger_order: { FOLLOWS | PRECEDES } other_trigger_name
- BEFORE 和 AFTER 参数指定了触发执行的时间,在事件之前或是之后。
- FOR EACH ROW 表示任何一条记录上的操作满足触发事件都会触发该触发器,也就是说触发器的触发频率是针对每一行数据触发一次。
示例:定义一个触发器,一旦有满足条件的删除操作,就会执行 BEGIN 和 END 中的语句
mysql> DELIMITER ||
mysql> CREATE TRIGGER trig2 BEFORE DELETE
-> ON work FOR EACH ROW
-> BEGIN
-> INSERT INTO time VALUES(NOW());
-> INSERT INTO time VALUES(NOW());
-> END||
mysql> DELIMITER ;
查看触发器
1)直接查看触发器信息:
mysql> SHOW TRIGGERS\G; ……
结果显示所有触发器的基本信息;无法查询指定的触发器。
2)在 information_schema.triggers 表中查看触发器信息:
mysql> SELECT * FROM information_schema.triggers\G ……
结果,显示所有触发器的详细信息;同时,该方法可以查询制定触发器的详细信息。
mysql> select * from information_schema.triggers
-> where trigger_name='upd_check'\G;
删除触发器
DROP TRIGGER [IF EXISTS] [schema_name.]trigger_name

 浙公网安备 33010602011771号
浙公网安备 33010602011771号