

MySQL 慢 SQL & 优化方案
1. 慢 SQL 的危害
2. 数据库架构 & SQL 执行过程
3. 存储引擎和索引的那些事儿
4. 慢 SQL 解决之道
- 4.1 优化分析流程
- 4.2 执行计划(explain)详解
- 4.3 索引设计策略
- 4.4 SQL 优化
- 4.5 表结构优化
- 4.6 事务和锁优化
- 4.7 MySQL 服务端参数优化
- 4.8 硬件优化
- 4.9 架构优化
1. 慢 SQL 的危害
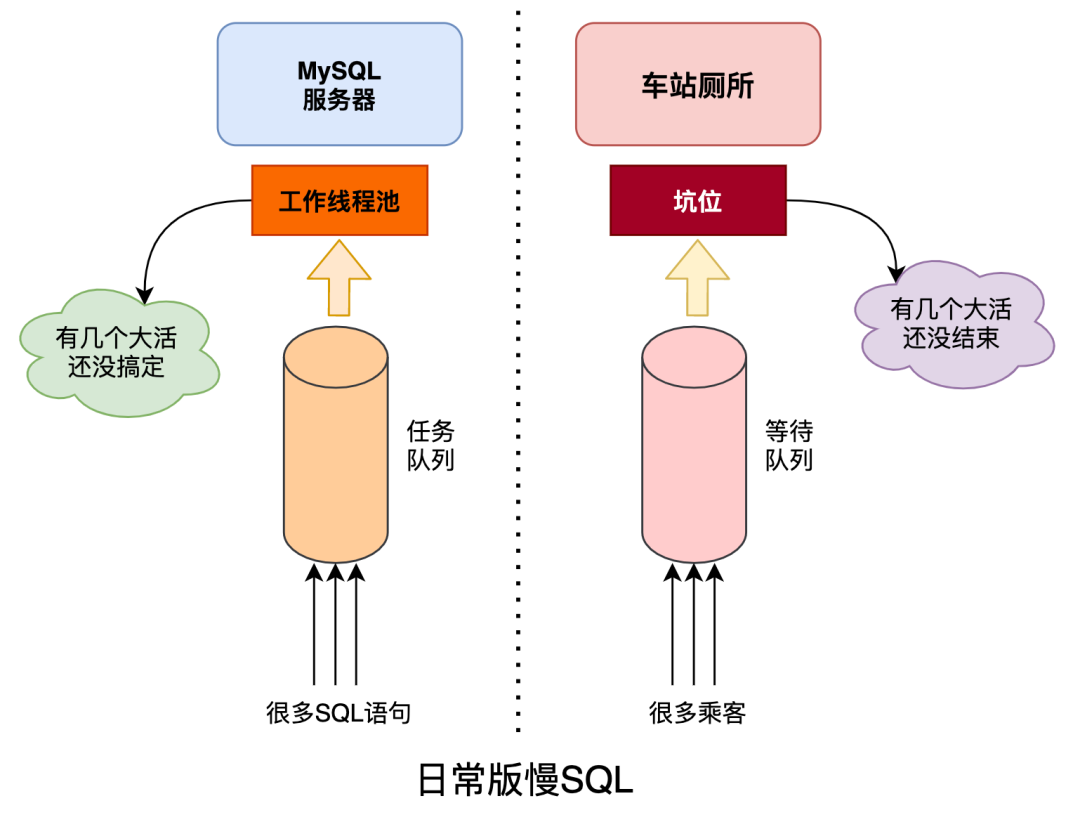
慢 SQL,就是跑得很慢的 SQL 语句,你可能会问慢 SQL 会有啥问题吗?
试想一个场景:
大白和小黑端午出去玩,机票太贵于是买了高铁,火车站的人真是乌央乌央的。
马上检票了,大白和小黑准备去厕所清理下库存,坑位不多,排队的人还真不少。
小黑发现其中有 3 个坑的乘客贼慢,其他 2 个坑位换了好几波人,这 3 位坑主就是不出来。
等在外面的大伙,心里很是不爽,长期占用公共资源,后面的人没法用。
小黑苦笑道:这不就是厕所版的慢 SQL 嘛!
这是实际生活中的例子,换到 MySQL 服务器也是一样的,毕竟科技源自生活嘛。
MySQL 服务器的资源(CPU、IO、内存等)是有限的,尤其在高并发场景下需要快速处理掉请求,否则一旦出现慢 SQL 就会阻塞掉很多正常的请求,造成大面积的失败/超时等。
2. 数据库架构 & SQL 执行过程
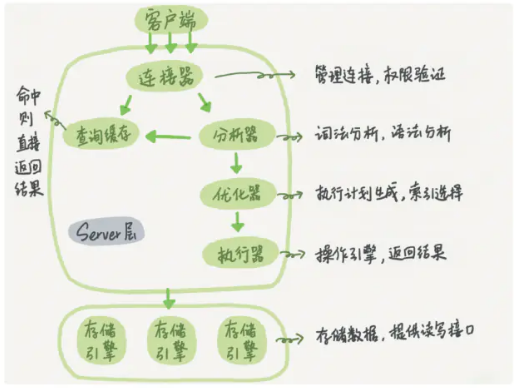
如上图所示,MySQL 逻辑架构图主要分三层:
- 第一层负责连接处理、授权认证等。
- 第二层负责编译并优化 SQL。
- 第三层是存储引擎。
SQL 执行过程:
- 客户端发送一条 SQL 语句给服务端,服务端的连接器先进行账号/密码、权限等验证,若有异常则直接拒绝请求。
- 服务端先查询缓存(MySQL8.0 已取消查询缓存),如果 SQL 语句命中了缓存,则返回缓存中的结果,否则继续处理。
- 服务端对 SQL 语句进行词法和语法分析,提取 SQL 中 select 等关键字,来检查 SQL 语句的合法性。
- 服务端通过优化器对之前生成的解析树进行优化处理,生成最优的物理执行计划。
- 将生成的物理执行计划调用存储引擎的相关接口,进行数据查询和处理。
- 处理完成后将结果返回客户端。
俗话说“条条大路通罗马”,优化器的作用就是找到这么多路中最优的那一条。
存储引擎更是决定 SQL 执行的核心组件,适当了解其中原理十分有益。
3. 存储引擎和索引的那些事儿
3.1 存储引擎
InnoDB 存储引擎(Storage Engine)是 MySQL 默认之选,所以非常典型。
存储引擎的主要作用是进行数据的存取和检索,也是真正执行 SQL 语句的组件。
InnoDB 的整体架构分为两个部分:内存架构和磁盘架构,如图:
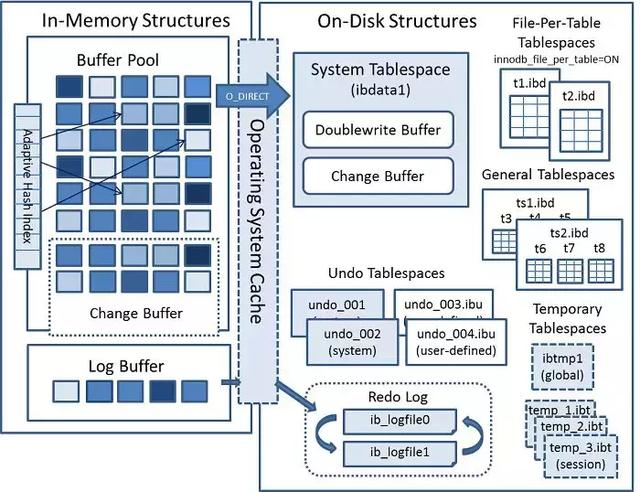
存储引擎的内容非常多,并不是一篇文章能说清楚的,本文不过多展开,我们在此只需要了解内存架构和磁盘架构的大致组成即可。
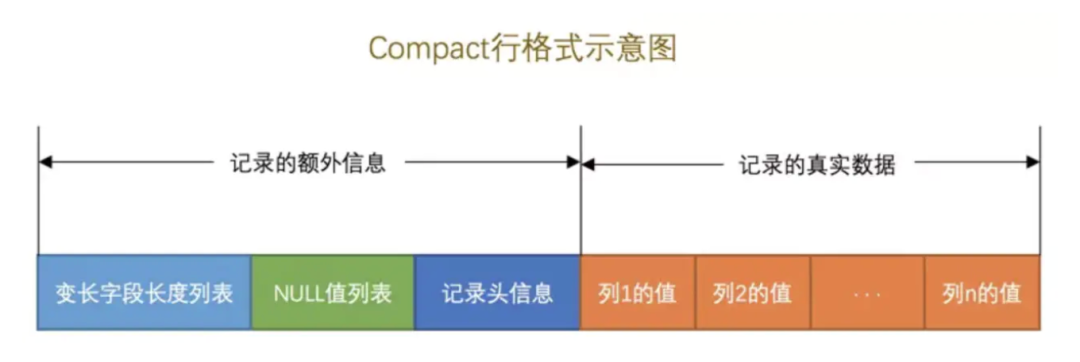
InnoDB 引擎是面向行存储的,数据都是存储在磁盘的数据页中,数据页里面按照固定的行格式存储着每一行数据。
行格式主要分为四种类型:Compact、Redundant、Dynamic 和 Compressed,默认为 Compact 格式。
操作系统
1)局部性原理
- 时间局部性:之前被访问过的数据很有可能被再次访问。
- 空间局部性:数据和程序都有聚集成群的倾向。
2)磁盘预读机制
当计算机访问一个数据时,不仅会加载当前数据所在的数据页,还会将当前数据页相邻的数据页一同加载到内存,磁盘预读的长度一般为页的整倍数,从而有效降低磁盘 I/O 的次数(如果要读取的数据量超过一页的大小,就会触发多次磁盘 I/O 操作)。
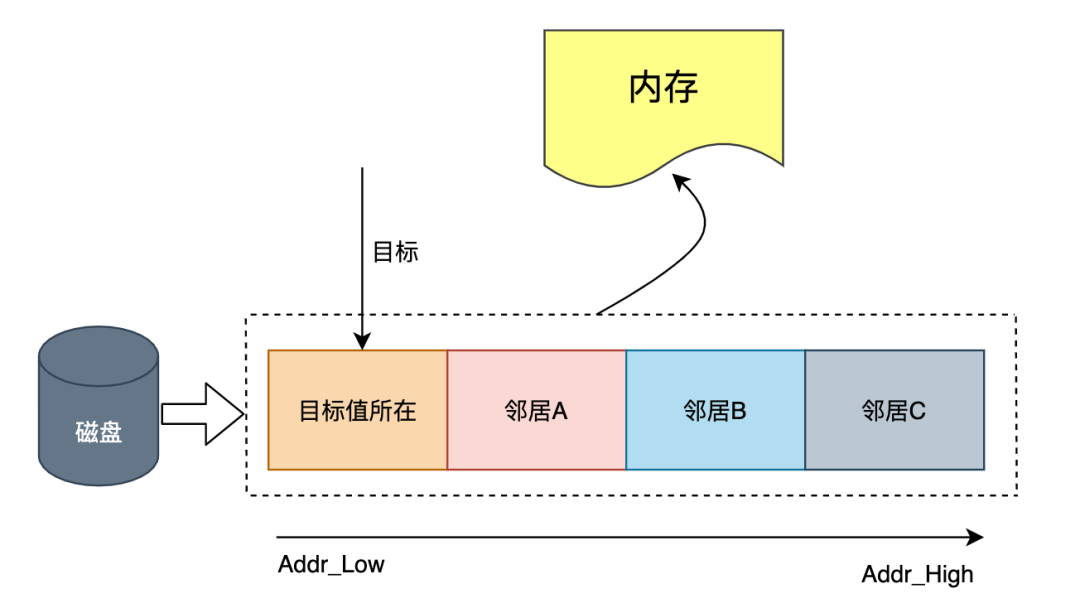
磁盘和内存的交互
MySQL 中磁盘的数据需要被交换到内存,才能完成一次 SQL 交互,大致如图:
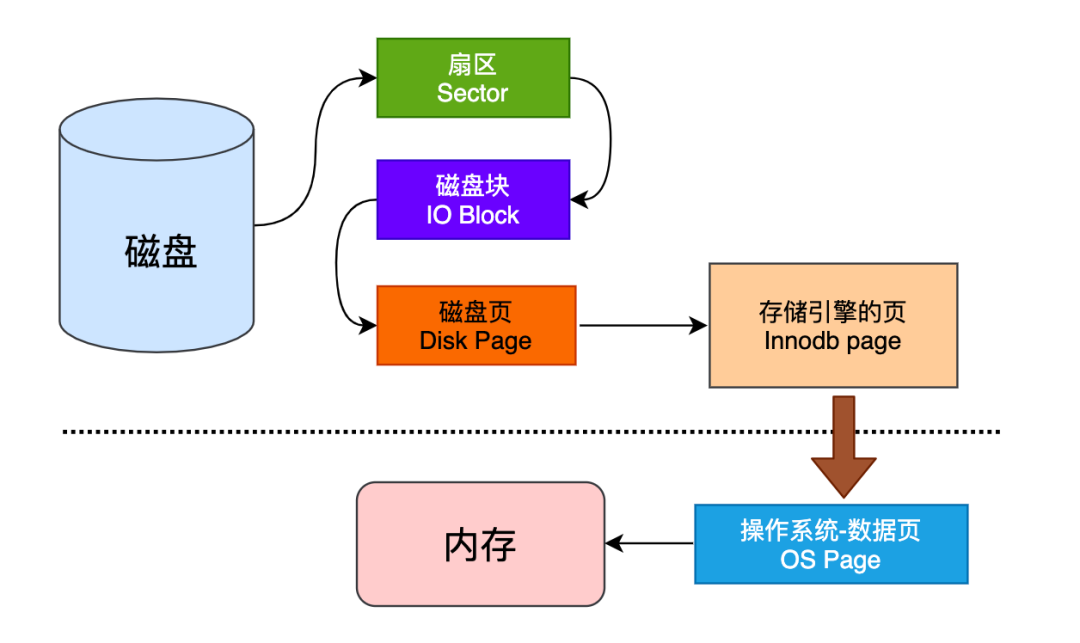
- 扇区是硬盘读写的基本单位,通常情况下每个扇区的大小是 512B。
- 磁盘块是操作系统(文件系统)读写数据的最小单位,相邻的扇区组合在一起形成一个块,一般是 4KB。
- 页是内存的最小存储单位,页的大小通常为磁盘块大小的 2n 倍。
- InnoDB 的页的默认大小是 16KB,是数倍个操作系统的页。
随机磁盘 I/O
MySQL 的数据是一行行存储在磁盘上的,并且这些数据并非物理连续地存储,这样的话要查找数据就无法避免随机在磁盘上读取和写入数据。
对于 MySQL 来说,当出现大量磁盘随机 I/O 时,大部分时间都被浪费到寻道上,磁盘呼噜呼噜转,就是传输不了多少数据。
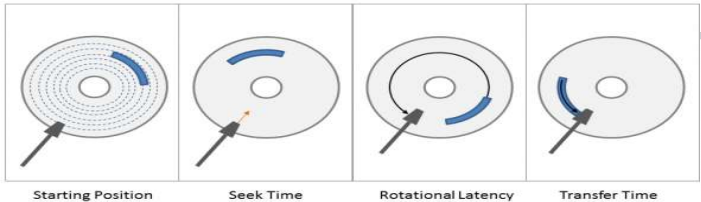
一次磁盘访问由三个动作组成:
- 寻道(Seek Time):磁头移动定位到指定磁道。
- 旋转(Rotational Latency):等待指定扇区从磁头下旋转经过。
- 数据传输(Transfer Time):数据在磁盘与内存之间的实际传输。
对于存储引擎来说,如何有效降低随机 I/O 是个非常重要的问题。
3.2 索引
详见《MySQL 索引》。
4. 慢 SQL 解决之道
在遇到慢 SQL 时,不能简单的把原因归结为 SQL 编写问题(虽然这是最常见的因素),实际上导致慢 SQL 有很多因素,大致如下:
- 索引设计问题
- SQL 编写问题
- 表结构(类型、长度等)设计问题
- 锁
- 并发对 IO/CPU 资源争用
- 服务器硬件
- MySQL 本身的 Bug
接下来将从以下几个方面分析慢 SQL 的解决之道:
4.1 优化分析流程
1)了解各种 SQL 的执行效率
show status like 'Com_%'; -- 了解各种SQL的执行频率
- Com_select | 1 执行 select 操作的次数,一次查询只累加 1。
- Com_insert | 0 执行 insert 操作的次数,对于批量插入的 insert,只累加一次。
- Com_update | 0 执行 update 操作的次数。
- Com_delete | 0 执行 delete 操作的次数。
上述参数对 所有存储引擎 的表操作都会进行累计。
下面这几个参数只是针对 InnoDB 存储引擎的,累加的算法也略有不同。
show status like 'Innodb_rows_%';
- Innodb_rows_deleted | 1 | 执行 delete 操作删除的行数。
- Innodb_rows_inserted | 50 | 执行 insert 操作插入的行数。
- Innodb_rows_read | 168 | 执行 select 查询返回的行数。
- Innodb_rows_updated | 0 | 执行 updat 操作更新的行数。
通过以上几个参数,我们可以了解当前数据库的应用是以插入更新为主还是以查询操作为主,以及各种类型的 SQL 大致的执行比例是多少。
对事务型的应用,通过 Com_commit 和 Com_rollback 可以了解事务提交和回滚的情况,对于回滚操作非常频繁的数据库,可能意味着应用编写存在问题。
2)定位慢查询
可以通过以下两种方式定位执行效率较低的 SQL 语句(慢查询的统计通常由运维定期统计):
- 通过慢查询日志定位那些执行效率较低的 SQL 语句,具体可参见《MySQL 日志》的慢查询日志部分。
- 慢查询日志在查询结束以后才纪录,所以在应用反映执行效率出现问题时,查询慢查询日志并不能定位问题。这时可以使用 show processlist 命令查看当前 MySQL 在进行的线程,包括线程的状态、是否锁表等,可以实时地查看 SQL 的执行情况,同时对一些锁表操作进行优化。
show processlist 命令详解
show processlist 命令只列出前 100 条正在运行的线程信息,如果想全列出需要使用 show full processlist。也可以使用 mysqladmin processlist 语句得到此信息。
除非有 SUPER 权限,可以看到所有线程。否则,只能看到自己的线程(也就是,与您正在使用的 MySQL 账户相关的线程)。
本语句会报告 TCP/IP 连接的主机名称(采用 host_name:client_port 格式),以方便地判定哪个客户端正在做什么。
如果得到了“too many connections”错误信息,并且想要了解正在发生的情况,本语句是非常有用的。MySQL保留一个额外的连接,让拥有 SUPER 权限的账户使用,以确保管理员能够随时连接和检查系统(假设没有把此权限给予所有的用户)。
id # ID标识,要kill一个语句的时候很有用
use # 当前连接用户
host # 显示这个连接从哪个ip的哪个端口上发出
db # 数据库名
command # 连接状态,一般是休眠(sleep),查询(query),连接(connect),初始化(init)
time # 连接持续时间,单位是秒
state # 显示当前sql语句的状态
info # 显示这个sql语句
该命令中最关键的就是 state 列,MySQL 列出的状态主要有以下几种:
- Checking table:正在检查数据表(这是自动的)。
- Closing tables:正在将表中修改的数据刷新到磁盘中,同时正在关闭已经用完的表。这是一个很快的操作,如果不是这样的话,就应该确认磁盘空间是否已经满了或者磁盘是否正处于重负中。
- Connect out:复制从服务器正在连接主服务器。
- Copying to tmp table on disk:由于临时结果集大于 tmp_table_size,正在将临时表从内存存储转为磁盘存储以此节省内存。
- Creating tmp table:正在创建临时表以存放部分查询结果。
- deleting from main table:服务器正在执行多表删除中的第一部分,刚删除第一个表。
- deleting from reference tables:服务器正在执行多表删除中的第二部分,正在删除其他表的记录。
- Flushing tables:正在执行FLUSH TABLES,等待其他线程关闭数据表。
- Killed:发送了一个 kill 请求给某线程,那么这个线程将会检查 kill 标志位,同时会放弃下一个 kill 请求。MySQL 会在每次的主循环中检查 kill 标志位,不过有些情况下该线程可能会过一小段才能死掉。如果该线程程被其他线程锁住了,那么 kill 请求会在锁释放时马上生效。
- Locked:被其他查询锁住了。
- Sending data:正在处理 SELECT 查询的记录,同时正在把结果发送给客户端。
- Sorting for group:正在为 GROUP BY 做排序。
- Sorting for order:正在为 ORDER BY 做排序。
- Opening tables:这个过程应该会很快,除非受到其他因素的干扰。例如,在执 ALTER TABLE 或 LOCK TABLE 语句行完以前,数据表无法被其他线程打开。正尝试打开一个表。
- Removing duplicates:正在执行一个 SELECT DISTINCT 方式的查询,但是 MySQL 无法在前一个阶段优化掉那些重复的记录。因此,MySQL 需要再次去掉重复的记录,然后再把结果发送给客户端。
- Reopen table:获得了对一个表的锁,但是必须在表结构修改之后才能获得这个锁。已经释放锁,关闭数据表,正尝试重新打开数据表。
- Repair by sorting:修复指令正在排序以创建索引。
- Repair with keycache:修复指令正在利用索引缓存一个一个地创建新索引。它会比 Repair by sorting 慢些。
- Searching rows for update:正在讲符合条件的记录找出来以备更新。它必须在 UPDATE 要修改相关的记录之前就完成了。
- Sleeping:正在等待客户端发送新请求.:
- System lock:正在等待取得一个外部的系统锁。如果当前没有运行多个 mysqld 服务器同时请求同一个表,那么可以通过增加 --skip-external-locking 参数来禁止外部系统锁。
- Upgrading lock:正在尝试取得一个锁表以插入新记录。
- Updating:正在搜索匹配的记录,并且修改它们。
- User Lock:正在等待 GET_LOCK()。
- Waiting for tables:该线程得到通知,数据表结构已经被修改了,需要重新打开数据表以取得新的结构。然后,为了能的重新打开数据表,必须等到所有其他线程关闭这个表。以下几种情况下会产生这个通知:FLUSH TABLES tbl_name, ALTER TABLE, RENAME TABLE, REPAIR TABLE, ANALYZE TABLE 或 OPTIMIZE TABLE。
- waiting for handler insert:已经处理完了所有待处理的插入操作,正在等待新的请求。
大部分状态对应很快的操作,只要有一个线程保持同一个状态好几秒钟,那么可能是有问题发生了,需要检查一下。
还有其他的状态没在上面中列出来,不过它们大部分只是在查看服务器是否有存在错误是才用得着。
3)连接数
当数据库连接池被占满时,如果有新的 SQL 语句要执行,只能排队等待,等待连接池中的连接被释放(等待之前的 SQL 语句执行完成)。
如果监控发现数据库连接池的使用率过高,甚至是经常出现排队的情况,则需要进行调优。
查看/设置最大连接数
-- 查看最大连接数 mysql> show variables like '%max_connection%'; +-----------------------+-------+ | Variable_name | Value | +-----------------------+-------+ | extra_max_connections | | | max_connections | 2512 | +-----------------------+-------+ 2 rows in set (0.00 sec) -- 重新设置最大连接数 set global max_connections=1000;
在 /etc/my.cnf 里面设置数据库的最大连接数:
[mysqld] max_connections = 1000
查看当前连接数
mysql> show status like 'Threads%'; +-------------------+-------+ | Variable_name | Value | +-------------------+-------+ | Threads_cached | 32 | | Threads_connected | 10 | | Threads_created | 50 | | Threads_rejected | 0 | | Threads_running | 1 | +-------------------+-------+ 5 rows in set (0.00 sec)
- Threads_connected:表示当前连接数。跟 show processlist 结果相同。准确的来说,Threads_running 代表的是当前并发数。
- Threads_running:表示激活的连接数。一般远低于 connected 数值。
- Threads_created:表示创建过的线程数。
- 如果我们在 MySQL 服务器配置文件中设置了 thread_cache_size,那么当客户端断开之后,服务器处理此客户的线程将会缓存起来以响应下一个客户而不是销毁(前提是缓存数未达上限)。
- 如果发现 Threads_created 值过大的话,表明 MySQL 服务器一直在创建线程,这也是比较耗资源,因此可以适当增加配置文件中 thread_cache_size 值。
查询服务器 thread_cache_size 的值
mysql> show variables like 'thread_cache_size'; +-------------------+-------+ | Variable_name | Value | +-------------------+-------+ | thread_cache_size | 100 | +-------------------+-------+ 1 row in set (0.00 sec)
4.2 执行计划(explain)详解
EXPLAIN 命令可以获取 MySQL 如何执行 SELECT 语句的信息。因此平时在进行 SQL 开发时,都要养成用 explain 分析的习惯。
详见《explain 命令详解》。
4.3 索引设计策略
详见《MySQL 索引》。
4.4 SQL 优化
即使数据库表的索引设置已经比较合理,但 SQL 语句书写不当的话,也会造成索引失效,甚至造成全表扫描,从而拉低性能。
开启查询缓存(MySQL 8.0 已废弃该功能)
大多数的 MySQL 服务器都开启了查询缓存。这是提高性最有效的方法之一,而且这是被 MySQL 的数据库引擎处理的。当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存中,这样,后续的相同的查询就不用操作表而直接访问缓存结果了。
这里最主要的问题是,对于程序员来说,这个事情是很容易被忽略的。因为我们的某些查询语句会让 MySQL 不使用缓存。请看下面的示例:
SELECT username FROM user WHERE signup_date >= CURDATE(); -- 不走缓存 SELECT username FROM user WHERE signup_date >= '2014-06-24'; -- 走缓存
上面两条 SQL 语句的差别就是 CURDATE() ,MySQL 的查询缓存对这个函数不起作用。所以,像 NOW() 和 RAND() 或是其它的诸如此类的 SQL 函数都不会开启查询缓存,因为这些函数的返回是不确定的。
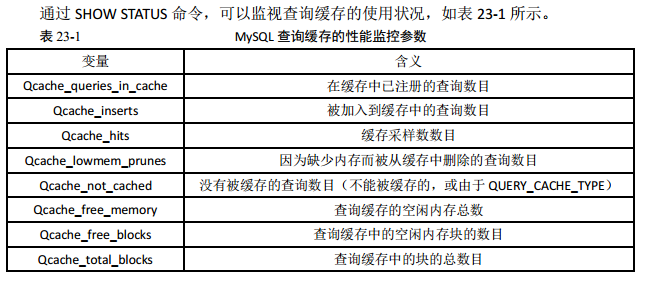
使用连接查询代替子查询
对于数据库来说,在绝大部分情况下,连接会比子查询更快,使用连接的方式,MySQL 优化器一般可以生成更佳的执行计划,更高效地处理查询。
而子查询往往需要运行重复的查询,子查询生成的临时表上也没有索引, 因此效率会更低。
当只要一行数据时使用 LIMIT 1
针对非主键的其他查询,加上 LIMIT 1 可以增加性能。这样 MySQL 数据库引擎会在找到一条数据后停止搜索,而不是继续往后查下一条符合记录的数据(否则即使已经查到一条结果,也会继续查询是否还存在等值结果,再返回结果)。
多表关联查询时,小表在前,大表在后
在 MySQL 中,执行 from 后的表关联查询是从左往右执行的,第一张表会涉及到全表扫描,所以将小表放在前面,先扫小表,扫描快效率较高,在扫描后面的大表,或许只扫描大表的前 100 行就符合返回条件并 return 了。
调整 where 子句中的连接顺序
MySQL 采用从左往右的顺序解析 where 子句,可以将过滤数据多的条件放在前面,最快速度缩小结果集。
不要使用 ORDER BY RAND()
想打乱返回的数据行?随机挑一个数据?但你却不了解这样做有多么可怕的性能问题。
如果你真的想把返回的数据行打乱了,你有 N 种方法可以达到这个目的。而这样使用只让你的数据库的性能呈指数级的下降。这里的问题是:MySQL会不得不去执行 RAND() 函数(很耗 CPU),而且这是为每一行记录去记行(扫全表),然后再对其排序,就算是用了 limit 1 也无济于事(因为要排序)。
优化 GROUP BY
使用 GROUP BY 但要避免排序结果的消耗。
GROUP BY … ORDER BY NULL; -- 禁止排序
JOIN 查询
如果你的应用程序有很多 JOIN 查询,你应该确认两个表中 JOIN 的字段是被建过索引的。这样,MySQL 内部会启动为你优化 JOIN 语句的机制。
而且,这些被用来 JOIN 的字段,应是相同类型的。例如:如果你要把 DECIMAL 字段和一个 INT 字段 JOIN 在一起,MySQL 就无法使用它们的索引。对于 STRING 类型,还需要有相同的字符集才行(两个表的字符集有可能不一样)。
SELECT company_name FROM users LEFT JOIN companies ON users.state = companies.state WHERE users.id = ...
例如以上两个 state 字段应该是被建过索引的,而且应是相当类型、相同字符集的。
4.5 表结构优化
永远为每张表创建主键
我们应该为数据库里的每张表都设置一个 id 作为主键,最好还是 INT 类型的(推荐使用 UNSIGNED 即无符号化),并设置上自动增加的 AUTO_INCREMENT 标志。
- 表数据的存储在磁盘中是按照主键顺序存放的,所以使用主键查询数据速度最快。
- INT 类型相比字符串类型,其长度更为固定,查询效率更高。
- 还有一些操作需要用到主键,比如集群、分区等。在这些情况下,主键的性能和设置变得非常重要。
所以建表时一定要带有主键,后续优化效果最好。
固定长度的表会更快
如果表中的所有字段都是“固定长度”的,整个表会被认为是 “static” 或 “fixed-length”。 例如,表中没有如下类型的字段: VARCHAR、TEXT、BLOB。只要你包括了其中一个这些字段,那么这个表就不是“固定长度静态表”了,这样,MySQL 引擎会用另一种方法来处理。
固定长度的表会提高性能,因为 MySQL 搜寻得会更快一些,因为这些固定的长度是很容易计算下一个数据的偏移量,所以读取的自然也会很快。而如果字段不是定长的,那么,每一次要找下一条的话,需要程序找到主键。
并且,固定长度的表也更容易被缓存和重建。不过,唯一的副作用是,固定长度的字段会浪费一些空间,因为定长的字段无论你用不用,他都是要分配那么多的空间。
通过拆分表,提高访问效率
把数据库中的表按列变成几张表的方法,这样可以降低表的复杂度和字段的数目,从而达到优化的目的。
越小的列会越快
对于大多数的数据库引擎来说,硬盘操作可能是最重大的瓶颈。所以,把你的数据变得紧凑会对这种情况非常有帮助,因为这减少了对硬盘的访问。
如果一个表只会有几列罢了(比如说字典表、配置表),那么,我们就没有理由使用 INT 来做主键,使用 MEDIUMINT、SMALLINT 或是更小的 TINYINT 会更经济一些。如果你不需要记录时间,使用 DATE 要比 DATETIME 好得多。
使用 ENUM 而不是 VARCHAR
ENUM 类型是非常快和紧凑的。实际上其保存的是 TINYINT,但其外表上显示为字符串。这样一来,用这个字段来做一些选项列表变得相当的完美。
如果你有一个字段,比如“性别”,“国家”,“民族”,“状态”或“部门”,你知道这些字段的取值是有限而且固定的,那么,你应该使用 ENUM 而不是 VARCHAR。
4.6 事务和锁优化
参见《MySQL 事务和锁》。
4.7 MySQL 服务端参数优化
Innodb_buffer_pool_size
影响性能的最主要参数,一般建议配置为系统总内存的 70-80%,这个参数决定了服务可分配的最大内存。
-- 通过 Buffer Pool 的实时状态信息来确定 InnoDB 的 Buffer Pool 的使用是否高效 mysql> show status like 'Innodb_buffer_pool_%'; +---------------------------------------+-------------+ | Variable_name | Value | +---------------------------------------+-------------+ | Innodb_buffer_pool_dump_status | not started | | Innodb_buffer_pool_load_status | not started | | Innodb_buffer_pool_pages_data | 446 | | Innodb_buffer_pool_bytes_data | 7307264 | | Innodb_buffer_pool_pages_dirty | 0 | | Innodb_buffer_pool_bytes_dirty | 0 | | Innodb_buffer_pool_pages_flushed | 110 | | Innodb_buffer_pool_pages_free | 12864 | | Innodb_buffer_pool_pages_misc | 2 | | Innodb_buffer_pool_pages_total | 13312 | | Innodb_buffer_pool_read_ahead_rnd | 0 | | Innodb_buffer_pool_read_ahead | 0 | | Innodb_buffer_pool_read_ahead_evicted | 0 | | Innodb_buffer_pool_read_requests | 10293 | | Innodb_buffer_pool_reads | 432 | | Innodb_buffer_pool_wait_free | 0 | | Innodb_buffer_pool_write_requests | 380 | +---------------------------------------+-------------+ 17 rows in set (0.00 sec)
Innodb_log_buffer_size
顾名思义,这个参数就是用来设置 Innodb 的 Log Buffer 大小的,系统默认值为 1MB 。 Log Buffer 的主要作用就是缓冲 Log 数据,提高写 Log 的 I/O 性能。
一般来说,如果你的系统不是写负载非常高且以大事务居多的话, 8MB 以内的大小就完全足够了。
-- 查看innodb_log_buffer_size 设置是否合理 mysql> show status like 'innodb_log%'; +---------------------------+-------+ | Variable_name | Value | +---------------------------+-------+ | Innodb_log_waits | 0 | | Innodb_log_write_requests | 61 | | Innodb_log_writes | 25 | +---------------------------+-------+ 3 rows in set (0.00 sec)
刷盘策略
- Sync_binlog:这是控制日志刷盘策略的,基于安全一般设置为 1。
- Innodb_flush_log_at_trx_commit:这个是控制事务日志刷盘策略,基于安全一般设置为 1。
上面两个参数设置为 1 时最安全,但对于磁盘 I/O 消耗更大;0 时为最大性能,但故障切换时容易丢数据。
InnoDB 性能监控
-- 持续获取状态信息的方法 create table innodb_monitor(a int) engine=innodb;
创建一个 innodb_monitor 空表后,InnoDB 会每隔 15 秒输出一次信息并记录到 Error Log 中。通过删除该表可停止监控。
除此之外,我们还可以通过相同的方式打开和关闭 innodb_tablespace_monitor、innodb_lock_monitor、innodb_table_monitor 这三种监控功能。
4.8 硬件优化
不同的应用或者进程,对于硬件资源的要求是不同的。比如有计算密集型、I/O 密集型等。
- 关系型数据库的要求:多 CPU、高内存、高磁盘 I/O 的一种服务。
- Redis 的要求:单 CPU、高内存、对磁盘要求低。
对于 MySQL,硬件如何选择和优化呢:
- CPU:多核高频。
- 内存:高内存。
- 磁盘:选择 SSD;且一般要求做 RAID(磁盘阵列)。
RAID(磁盘阵列)
根据数据分布和冗余方式,RAID 分为许多级别。不同存储厂商提供的 RAID 卡或设备,其支持的 RAID 级别也不尽相同。以下介绍最常见也是最基本的几种,其他 RAID 级别基本上都是在这几种基础上的改进。
|
RAID 级别 |
特性 | 优点 | 缺点 |
| RAID 0 | 也叫条带化(Stripe),按一定的条带大小(Chunk Size)将数据依次分布到各个磁盘,没有数据冗余。 | 数据并发读写速度快,无额外的磁盘空间开销,投资省。 | 数据无冗余保护,可靠性差。 |
| RAID 1 | 也叫磁盘镜像(Mirror),两个磁盘一组,所有数据都同时写入两个磁盘,但读时从任一磁盘读都可以。 |
数据有完全冗余保护,只要不出现两块镜像磁盘同时损坏,就不会影响使用; 可以提高并发读性能。 |
容量一定的话,需要 2 倍的磁盘,投资比较大。 |
| RAID 10 | 是 RAID 1 和 RAID 0 的结合,也叫 RAND 1+0。先对磁盘做镜像,再条带话,使其兼具 RAID 1 的可靠性和 RAID 0 的优良并发读写性能。 | 可靠性高,并发读写性能优良。 | 容量一定的话,需要 2 倍的磁盘,投资比较大。 |
| RAID 4 | 像 RAID 0 一样对磁盘组条带化,不同的是:需要额外增加一个磁盘,用来写各 Stripe 的校验纠错数据。 |
RAID 中的一个磁盘损坏的话,其数据可以通过校验纠错数据计算出来,具有一定容错保护能力; 读数据速度快。 |
每个 Stripe 上数据的修改都要写校验纠错块,写性能受影响; 所有纠错数据都在同一磁盘上,风险大,也会形成一个性能瓶颈; 在出现坏盘时,读性能会下降。 |
| RAID 5 | 是对 RAID4 的改进:将每一个条带(Stripe)的校验纠错数据块也分布写到各个磁盘,而不是写到一个特定的磁盘。 | 基本同 RAID 4,只是其写性能和数据保护能力要更强一 点。 |
写性能不及 RAID 0、 RAID 1 和 RAID 10,容错能力也不及 RAID 1; 在出现坏盘时,读性能会下降。 |
如何选择 RAID 级别
了解各种 RAID 级别的特性后,我们就可以根据数据读写的特点、可靠性要求,以及投资预算等来选择合适的 RAID 级别,比如:
- 数据读写都很频繁,可靠性要求也很高,最好选择 RAID 10。
- 数据读很频繁,写相对较少,对可靠性有一定要求,可以选择 RAID 5。
- 数据读写都很频繁,但可靠性要求不高,可以选择 RAID 0。
虚拟文件卷或软 RAID
最初,RAID 都是由硬件实现的,要使用 RAID,至少需要有一个 RAID 卡。但现在,一些操作系统中提供的软件包,也模拟实现了一些 RAID 的特性,虽然性能上不如硬 RAID,但相比单个磁盘,性能和可靠性都有所改善。比如:
- Linux下的逻辑卷(Logical Volume)系统 lvm2,支持条带化(Stripe)。
- Linux 下的 MD(Multiple Device)驱动,支持 RAID 0、RAID 1、RAID 4、RAID 5、RAID 6 等。
在不具备硬件条件的情况下,可以考虑使用上述虚拟文件卷或软 RAID 技术,具体配置方法可参见 Linux 帮助文档。
4.9 架构优化
- 业务架构优化:合理使用缓存数据库 Redis、消息队列等。
- 数据库架构优化:参见《MySQL 主从复制&读写分离&分库分表》。

