MySQL 主从复制&读写分离&分库分表
1. 主从复制&读写分离 简介
- 主从同步延迟
- 分配机制
- 解决单点故障
- 总结
2. 主从复制&读写分离 搭建
- 搭建主从复制(双主)
- 搭建读写分离
3. 分库分表 简介
1. 主从复制&读写分离 简介
读写分离顾名思义就是读和写分离,对应到数据库集群一般都是一主一从(一个主库,一个从库)或者一主多从(一个主库,多个从库),业务服务器把需要写的操作都写到主数据库中,读的操作都去从库查询。主库会同步数据到从库保证数据的一致性。
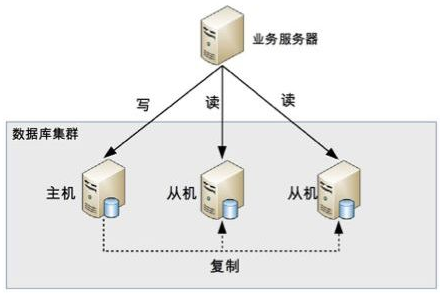
这种集群方式的本质是把访问的压力从主库转移到从库,也就是在单机数据库无法支撑并发读写,并且读的请求很多的情况下适合这种读写分离的数据库集群。如果写的操作很多的话不适合这种集群方式,因为你的数据库压力还是在写操作上,即使主从了之后压力还是在主库上,这样和单机的区别就不大了。
在单机的情况下,一般我们做数据库优化都会加索引,但是加了索引对查询有优化,但会影响写入,因为写入数据会更新索引。所以做了主从之后,我们可以单独地针对从库(读库)做索引上的优化,而主库(写库)可以减少索引而提高写的效率。
实现原理
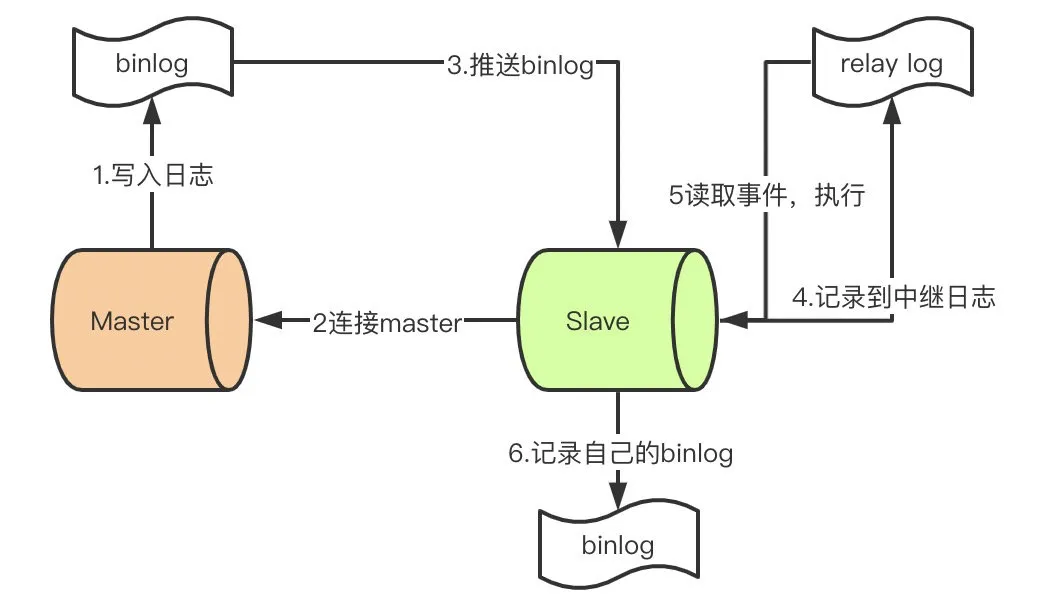
初始状态时,master 和 slave 的数据要保持一致。
- master 提交完事务后,写入 binlog。
- slave 连接到 master,获取 binlog。
- master创建 dump 线程,推送 binlog 到 slave。
- slave 启动一个 I/O 线程读取同步过来的 master 的 binlog,记录到 relay log(中继日志)中。
- slave 再开启一个 SQL 线程从 relay log 中读取内容并在 slave 执行(从 Exec_Master_Log_Pos 位置开始执行读取到的更新事件),完成同步。
- slave 记录自己的 binlog。
由于 MySQL 默认的复制方式是异步的,主库把日志发送给从库后不关心从库是否已经处理。这样会产生一个问题,假设主库挂了,从库处理失败了,这时从库升为主库后,日志就丢失了。由此产生以下两个概念:
全同步复制
主库写入 binlog 后,强制同步日志到从库,等所有的从库都执行完成后,才返回结果给客户端,显然这个方式的性能会受到严重影响。
半同步复制
从库写入日志成功后返回 ACK(确认)给主库,主库收到至少一个从库的确认就可以认为写操作完成,返回结果给客户端。
主从同步延迟
主库有数据写入之后,同时也写入在 binlog(二进制日志文件)中,从库是通过 binlog 文件来同步数据的,这期间会有一定时间的延迟,可能是 1 秒,如果同时有大量数据写入的话,时间可能更长。
这会导致什么问题呢?比如有一个付款操作,你付款了,主库是已经写入数据,但是查询是到从库查,从库里还没有你的付款记录,所以页面上查询的时候你还没付款。那可不急眼了啊,吞钱了这还了得!打电话给客服投诉!
所以为了解决主从同步延迟的问题有以下几个方法:
1)二次读取
二次读取的意思就是读从库没读到之后再去主库读一下,只要通过对数据库访问的 API 进行封装就能实现这个功能。很简单,并且和业务之间没有耦合。但是有个问题,如果有很多二次读取相当于压力还是回到了主库身上,等于读写分离白分了。而且如有人恶意攻击,就一直访问没有的数据,那主库就可能爆了。
2)写之后的马上的读操作访问主库
也就是写操作之后,立马的读操作指定为访问主库,之后的读操作则访问从库。这就等于写死了,和业务强耦合了。
3)关键业务读写都由主库承担,非关键业务读写分离
类似付钱的这种业务,读写都到主库,避免延迟的问题,但是例如改个头像啊,个人签名这种比较不重要的就读写分离,查询都去从库查,毕竟延迟一下影响也不大,不会立马打客服电话投诉。
分配机制
分配机制的考虑也就是怎么制定写操作是去主库写,读操作是去从库读。
一般有两种方式:代码封装、数据库中间件。
1)代码封装
代码封装的实现很简单,就是抽出一个中间层,让这个中间层来实现读写分离和数据库连接。讲白点就是搞个 provider 封装了 save、select 等通常数据库操作,内部 save 操作的 dataSource 是主库的,select 操作的 dataSource 是从库的。
优点:
- 实现简单。
- 可以根据业务定制化变化,随心所欲。
缺点:
- 如果哪个数据库宕机了,发生主从切换了之后,就得修改配置重启。
- 如果系统很大,一个业务可能包含多个子系统,一个子系统是 java 写的,一个子系统用 go 写的,这样的话得分别为不同语言实现一套中间层,重复开发。
2)数据库中间件
就是有一个独立的系统,专门来实现读写分离和数据库连接管理,业务服务器和数据库中间件之间是通过标准的 SQL 协议交流的,所以在业务服务器看来数据库中间件其实就是个数据库。
优点:
- 因为是通过 SQL 协议的所以可以兼容不同的语言不需要单独写一套。
- 由中间件来实现主从切换,业务服务器不需要关心这点。
缺点:
- 多了一个系统其实就等于多了一个关心,比如数据库中间件挂了。
- 多了一个系统就等于多了一个瓶颈,所以对中间件的性能要求也高,因为所有的数据库操作都要先经过它。
- 中间件实现较为复杂,难度比代码封装高多了。
常用的开源数据库中间件有 Mysql Proxy、Atlas、LVS 等。
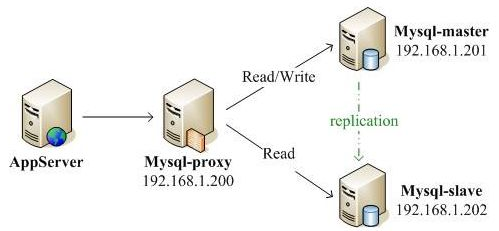
为什么使用 MySQL-Proxy 而不是 LVS?
- LVS:分不清读还是写;不支持事务。
- MySQL-Proxy:自动区分读操作和写操作;支持事务(注意在 MySQL-Proxy 中不要使用嵌套查询,否则会造成读和写的混乱)。
解决单点故障
解决 Proxy 单点故障问题
MySQL-Proxy 实际上非常不稳定,在高并发或有错误连接的情况下,进程很容易自动关闭,因此打开 --keepalive 参数让进程自动恢复是个比较好的办法,但还是不能从根本上解决问题,通常最稳妥的做法是在每个应用服务器(如 Tomcat)上安装一个 MySQL-Proxy 供自身使用(解决 Proxy 单点故障问题),虽然比较低效但却能保证稳定性。
双(多)主机制
Proxy 之后搭 LVS,LVS 为两台主数据库做负载均衡,从数据库从两台主数据库同步。此方案旨在解决:
- 主数据库的单点故障问题(服务不可用、备份问题)
- 分担写操作的访问压力。
不过多主需要考虑自增长 ID 问题,这个需要特别设置配置文件,比如双主可以使用奇偶。总之,主之间设置自增长 ID 相互不冲突就能解决自增长 ID 冲突问题。
总结
读写分离相对而言是比较简单的,比分表分库简单,但是它只能分担访问的压力,分担不了存储的压力,也就是你的数据库表的数据逐渐增多,但是面对一张表海量的数据,查询还是很慢的,所以如果业务发展的快数据暴增,到一定时间还是得分库分表。
正常情况下,只有当单机真的顶不住压力了才会集群,不要一上来就集群,没这个必要。有关于软件的东西都是越简单越好,复杂都是形势所迫。
一般我们是先优化单机,如优化一些慢查询,优化业务逻辑的调用或者加入缓存等。如果真的优化到没东西优化了,然后才上集群。先读写分离,读写分离之后顶不住就再分库分表。
2. 主从复制&读写分离 搭建
主从同步的方式也分很多种,一主多从、链式主从、多主多从,根据你的需要来进行设置。
搭建主从复制(双主)
1)服务器二台:分别安装 MySQL 数据库
- 安装命令:yum -y install mysql-server
- 配置登录用户的密码:mysqladmin -u root password '密码'
- 配置允许第三方机器访问本机 MySQL:
delete from user where password = ''; update user set host='%'; flush privileges;
2)分别修改 MySQL 配置
配置 masterA:
[root@adailinux ~]# vim /etc/my.cnf [mysqld] datadir = /data/mysql socket = /tmp/mysql.sock server_id = 1 # 指定server-id,必须保证主从服务器的server-id不同 auto_increment_increment = 2 # 设置主键单次增量 auto_increment_offset = 1 # 设置单次增量中主键的偏移量:奇数 log_bin = mysql-bin # 创建主从需要开启log-bin日志文件 log-slave-updates # 把更新的日志写到二进制文件(binlog)中,台服务器既做主库又做从库此选项必须要开启
配置 masterB:
[root@adailinux ~]# vim /etc/my.cnf [mysqld] datadir = /data/mysql socket = /tmp/mysql.sock server_id = 2 # 指定server-id,必须保证主从服务器的server-id不同 auto_increment_increment = 2 # 设置主键单次增量 auto_increment_offset = 2 # 设置单次增量中主键的偏移量:偶数 log_bin = mysql-bin # 创建主从需要开启log-bin日志文件 log-slave-updates = True # 把更新的日志写到二进制文件(binlog)中
以上为同步配置的核心参数。
server_id 有两个用途:
- 用来标记 binlog event 的源产地,就是 SQL 语句最开始源自于哪里。
- 用于 IO_thread 对主库 binlog 的过滤。如果没有设置 replicate-same-server-id=1 ,那么当从库的 IO_thread 发现 event 的源与自己的 server-id 相同时,就会跳过该 event,不把该 event 写入到 relay log 中。从库的 sql_thread 自然就不会执行该 event。这在链式或双主结构中可以避免 sql 语句的无限循环。
注意:如果设置多个从服务器,每个从服务器必须有一个唯一的 server-id 值,且与主服务器的以及其它从服务器的都不相同。
分别重启 masterA 和 masterB 并查看主库状态:
[root@adailinux ~]# /etc/init.d/mysqld restart Shutting down MySQL.. SUCCESS! Starting MySQL. SUCCESS! masterA: [root@adailinux ~]# mysql -uroot mysql> show master status; +------------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------+ | mysql-bin.000001 | 419 | TSC | mysql | | +------------------+----------+--------------+------------------+-------------------+ 1 row in set (0.00 sec) masterB: [root@adailinux ~]# mysql -uroot mysql> show master status -> ; +------------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------+ | mysql-bin.000001 | 419 | TSC | mysql | | +------------------+----------+--------------+------------------+-------------------+ 1 row in set (0.00 sec)
3)配置同步信息
masterA:
[root@adailinux ~]# mysql -uroot mysql> change master to master_host='192.168.8.132',master_port=3306,master_user='repl',master_password='123456',master_log_file='mysql-bin.000001',master_log_pos=419; #注:IP为masterB的IP(即,从服务器的IP) mysql> start slave; Query OK, 0 rows affected (0.05 sec) mysql> show slave status\G; 在此查看有如下状态说明配置成功: Slave_IO_Running: Yes Slave_SQL_Running: Yes
masterB:
[root@adailinux ~]# mysql -uroot mysql>change master to master_host='192.168.8.131',master_port=3306,master_user='repl',master_password='123456',master_log_file='mysql-bin.000001',master_log_pos=419; Query OK, 0 rows affected, 2 warnings (0.06 sec) mysql> start slave; Query OK, 0 rows affected (0.04 sec) mysql> show slave status\G 在此查看有如下状态说明配置成功: Slave_IO_Running: Yes Slave_SQL_Running: Yes
4)测试主从同步
在 masterA 上创建一个库,验证 masterB 是否同步创建了该库。
搭建读写分离
场景描述:
- 数据库 Master 主服务器
- 数据库 Slave 从服务器
- MySQL-Proxy 调度服务器
以下操作,均是在 MySQL-Proxy 调度服务器上进行的。
1)MySQL 服务器安装
2)检查/安装系统所需软件包
yum -y install gcc* gcc-c++* autoconf* automake* zlib* libxml* ncurses-devel* libmcrypt* libtool* flex* pkgconfig* libevent* glib* readline*
3)编译安装 lua
MySQL-Proxy 的读写分离主要是通过 rw-splitting.lua 脚本实现的,因此需要安装 lua。
方式 1:一般系统自带。

方式 2:手工安装。
这里我们建议采用源码包进行安装:
- cd /opt/install
- wget http://www.lua.org/ftp/lua-5.1.4.tar.gz
- tar zvfxlua-5.2.3.tar.gz
- cd lua-5.1.4
- vi src/Makefile
- 在CFLAGS= -O2 -Wall $(MYCFLAGS) 这一行记录里加上-fPIC,更改为 CFLAGS= -O2 -Wall -fPIC$(MYCFLAGS) 来避免编译过程中出现错误。
- make linux(编译到内存)
- make install
4)安装 Mysql-Proxy
MySQL-Proxy 可通过此网址获得:http://mysql.cdpa.nsysu.edu.tw/Downloads/MySQL-Proxy/
推荐采用已经编译好的二进制版本,因为采用源码包进行编译时,最新版的 MySQL-Proxy 对 automake、glib 以及 libevent 的版本都有很高的要求,而这些软件包都是系统的基础套件,不建议强行进行更新。
并且这些已经编译好的二进制版本在解压后都在统一的目录内,因此建议选择以下版本:
- 32 位 RHEL5 平台:http://mysql.cdpa.nsysu.edu.tw/Downloads/MySQL-Proxy/mysql-proxy-0.8.4-linux-rhel5-x86-32bit.tar.gz
- 64 位 RHEL5 平台:http://mysql.cdpa.nsysu.edu.tw/Downloads/MySQL-Proxy/mysql-proxy-0.8.4-linux-rhel5-x86-64bit.tar.gz
tar -xzvf mysql-proxy-0.8.3-linux-rhel5-x86-64bit.tar.gz
mv mysql-proxy-0.8.3-linux-rhel5-x86-64bit /opt/mysql-proxy
创建 Mysql-Proxy 服务管理脚本:
cd /opt/mysql-proxy mkdir scripts cp share/doc/mysql-proxy/rw-splitting.lua scripts/ chmod +x /opt/mysql-proxy/scripts mkdir /opt/mysql-proxy/run mkdir /opt/mysql-proxy/log mkdir /opt/mysql-proxy/scripts
5)修改读写分离脚本 rw-splitting.lua
修改默认连接,进行快速测试,不修改的话要达到连接数为 4 时才启用读写分离
vi /opt/mysql-proxy/scripts/rw-splitting.lua
-- connection pool if not proxy.global.config.rwsplitthen proxy.global.config.rwsplit = { min_idle_connections = 1, //默认为4 max_idle_connections = 1, //默认为8 is_debug = false } end
proxy.conf:
[mysql-proxy] admin-username=root admin-password=admin proxy-read-only-backend-addresses=192.168.188.143,192.168.188.139 proxy-backend-addresses=192.168.188.142 proxy-lua-script=/opt/mysql-proxy/bin/rw-splitting.lua admin-lua-script=/opt/mysql-proxy/lib/mysql-proxy/lua/admin.lua
bin 目录下执行:
./mysql-proxy --defaults-file=/opt/mysql-proxy/proxy.conf
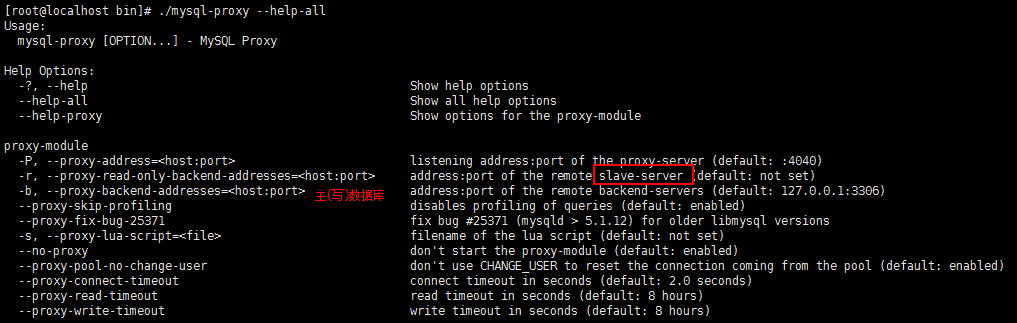
mysql-proxy 脚本参数详解:
- --proxy_path=/opt/mysql-proxy/bin:定义 mysql-proxy 服务二进制文件路径。
- --proxy-backend-addresses=192.168.10.130:3306:定义后端主服务器地址。
- --proxy-lua-script=/opt/mysql-proxy/scripts/rw-splitting.lua:定义 lua 读写分离脚本路径。
- --proxy-id=/opt/mysql-proxy/run/mysql-proxy.pid:定义 mysql-proxy PID 文件路径。
- --daemon:定义以守护进程模式启动。
- --keepalive:使进程在异常关闭后能够自动恢复。
- --pid-file=$PROXY_PID:定义 mysql-proxy PID 文件路径。
- --user=mysql:以 mysql 用户身份启动服务。
- --log-level=warning:定义 log 日志级别,由高到低分别有(error|warning|info|message|debug)。
- --log-file=/opt/mysql-proxy/log/mysql-proxy.log:定义 log 日志文件路径。
6)测试读写分离
- 登录 Proxy:mysql -u -p -h<proxy_ip> -P4040
- stop slave
- 在 Proxy 上插数据后,验证主数据库新增数据,而从没有新增数据。
3. 分库分表 简介
当访问用户越来越多,写请求暴涨,对于上面的单 Master 节点肯定扛不住,那么该怎么办呢?多加几个 Master?不行,这样会带来更多的数据不一致的问题,且增加系统的复杂度。那该怎么办?就只能对库表进行拆分了。

常见的拆分类型有垂直拆分和水平拆分,一般来说我们拆分的顺序是先垂直后水平。
垂直分库
以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。
基于现在微服务的拆分来说,都是已经做到了垂直分库了:

垂直分表
以字段为依据,按照字段的活跃性、数据长度等,将表中字段拆到不同的表(主表和扩展表)中。

水平分库/分表
以字段为依据,按照一定策略(hash、range 等),将一个库/表中的数据拆分到多个库/表中。
首先结合业务场景来决定使用什么字段作为分库/分表字段(sharding_key),比如我们现在日订单 1000 万,我们大部分的场景来源于 C 端,那么我们可以用 user_id 作为 sharding_key,数据查询支持到最近 3 个月的订单,超过 3 个月的做归档处理,那么 3 个月的数据量就是 9 亿,可以分 1024 张表,每张表的数据大概就在 100 万左右。
比如用户 id 为 100,那我们都经过 hash(100),然后对 1024 取模,就可以落到对应的表上了。
示例
以拼夕夕电商系统为例,一般有订单表、用户表、支付表、商品表、商家表等,最初这些表都在一个数据库里。后来随着砍一刀带来的海量用户,拼夕夕后台扛不住了!于是紧急从阿狸粑粑那里挖来了几个 P8、P9 大佬对系统进行重构。
- P9 大佬第一步先对数据库进行垂直分库,根据业务关联性强弱,将它们分到不同的数据库,比如订单库,商家库、支付库、用户库。
- 第二步是对一些大表进行垂直分表,将一个表按照字段分成多表,每个表存储其中一部分字段。比如商品详情表可能最初包含了几十个字段,但是往往最多访问的是商品名称、价格、产地、图片、介绍等信息,所以我们将不常访问的字段单独拆成一个表。
由于垂直分库已经按照业务关联切分到了最小粒度,但数据量仍然非常大,于是 P9 大佬开始水平分库,比如可以把订单库分为订单 1 库、订单 2 库、订单 3 库……那么如何决定某个订单放在哪个订单库呢?可以考虑对主键通过哈希算法计算放在哪个库。
分完库,单表数据量任然很大,查询起来非常慢,P9 大佬决定按日或者按月将订单分表,叫做日表、月表。
分库分表同时会带来一些问题,比如平时单库单表使用的主键自增特性将作废,因为某个分区库表生成的主键无法保证全局唯一。
经过一番大刀阔斧的重构,拼夕夕恢复了往日的活力,大家又可以愉快的在上面互相砍一刀了。
常用的分库分表中间件
- sharding-jdbc
- Mycat
分库分表可能遇到的问题
- 事务问题:使用分布式事务。
- 跨节点 Join 的问题:可以分两次查询实现。
- 跨节点的 order by、group by 聚合函数、排序等问题:分别在各个节点上得到结果后在应用程序端进行合并。
- 数据迁移,容量规划,扩容等问题。
- ID 唯一性问题:数据库被切分后,不能再依赖数据库自身的主键生成机制。
- ……
分表后的 ID 怎么保证唯一性?
因为我们的主键默认都是自增的,那么分表之后的主键在不同表就肯定会有冲突了。有几个方案可以考虑:
- 设定步长。比如 1-1024 张表我们可以分别设定 1-1024 的基础步长,这样主键落到不同的表就不会冲突了。
- 分布式 ID。自己实现一套分布式 ID 生成算法,或者使用开源的比如雪花算法这种。
- 分表后不使用主键作为查询依据,而是每张表单独新增一个字段作为唯一主键使用,比如订单表订单号是唯一的,那么不管最终落在哪张表,都可以基于订单号作为查询依据,更新也一样。
分表后非 sharding_key 的查询怎么处理呢?
- 可以做一个 mapping 表,比如这时候商家要查询订单列表怎么办呢?不带 user_id 查询的话总不能扫全表吧?所以我们可以做一个映射关系表,保存商家和用户的关系,查询的时候先通过商家查询到用户列表,再通过 user_id 去查询。
- 打宽表。一般而言,商户端对数据实时性要求并不是很高,比如查询订单列表,可以把订单表同步到离线(实时)数据仓库,再基于数仓去做成一张宽表,再基于其他如 es 提供查询服务。
- 数据量不是很大的话,比如后台的一些查询之类,也可以通过多线程扫表,然后再聚合结果的方式来做,或者异步的形式也是可以的。
架构实现
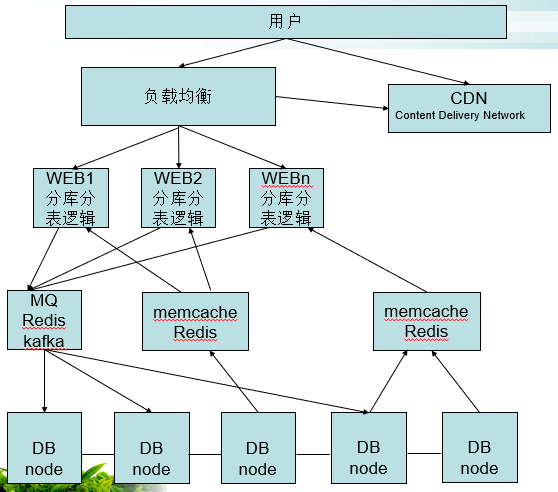
在代码层面实现分库分表逻辑:
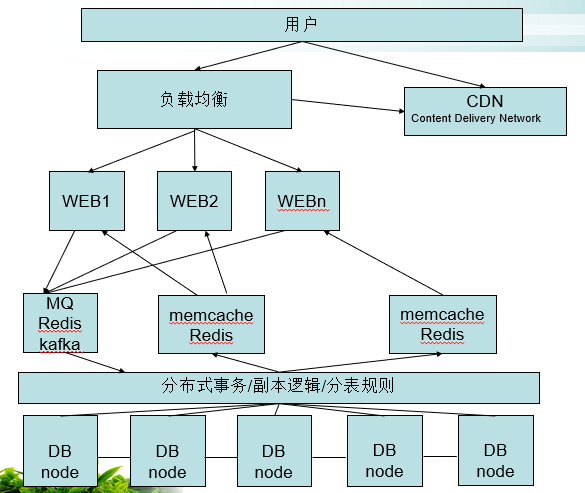
使用分布式/分库分表的中间件:
使用分布式数据库:

分库分表算法简介
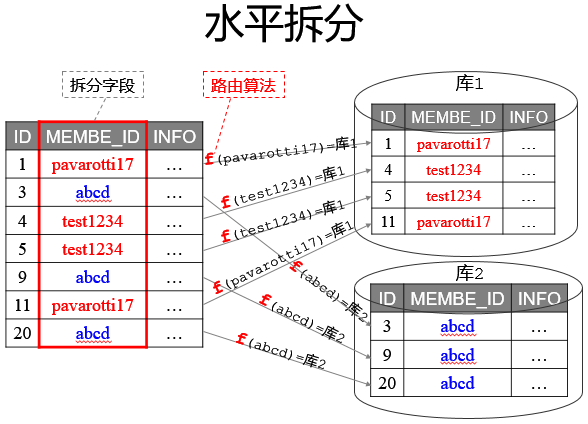
路由算法:

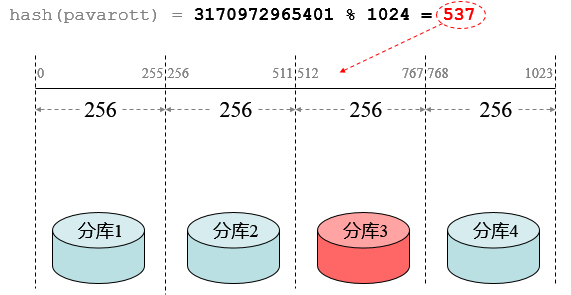
路由算法——扩容:
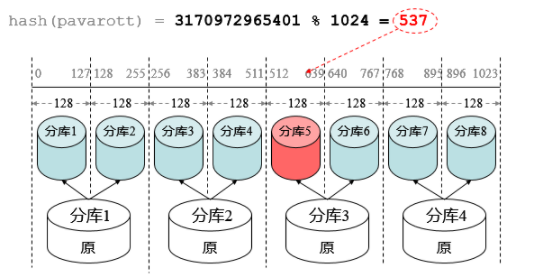
路由算法——非均匀分布:
各库的服务器性能不一定相同,因此可以根据各库的性能情况使用非均匀分布。
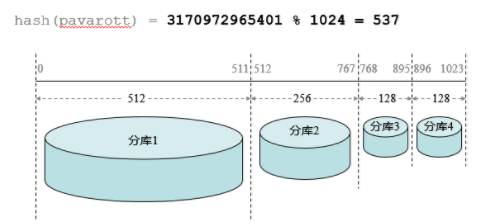
拆分表的数据访问——SQL 转发:

MySQL 集群替代 Oracle 单点:
- 基于表的水平拆分和分布:根据字段值的一致性 Hash 分布。
- 数据查询方式:根据 where 中的拆分字段分发。
后台数据访问逻辑层次:
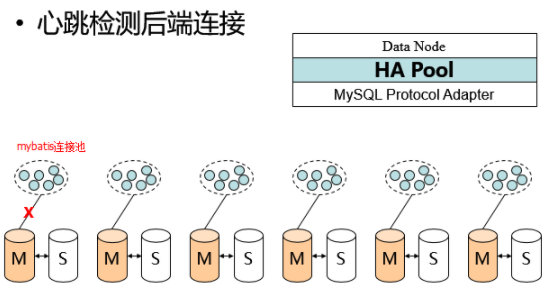
- 一组内的主从数据是同步一致的;
- 每组的数据是不一致的。
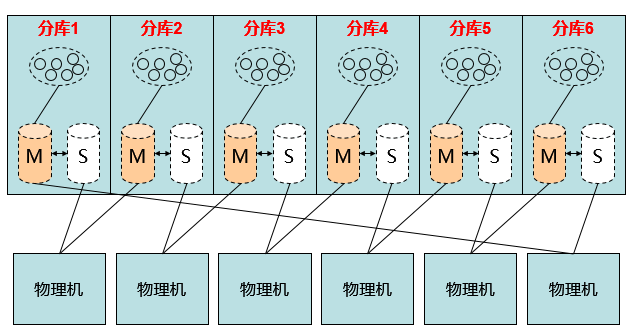
解决备机空闲时浪费机器资源的问题:
如下图所示,可由 12 台机器节省为 6 台。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号