SQL(DCL、DDL、DML、DQL)
0. SQL 基础
- SQL 分类
- SQL 语法规则
1. DCL
- 1.1 查看权限
- 1.2 创建用户并赋予权限
- 1.3 回收权限
- 1.4 修改密码
- 1.5 删除账号
- 1.6 权限信息与生效规则
2. DDL
- 2.1 库对象
- 2.2 表对象
3. DML
- 3.1 插入数据:INSERT
- 3.2 修改数据:UPDATE
- 3.3 删除数据:DELETE/TRUNCATE
4. DQL
-
4.1 基础
- 字段控制
- 模糊查询
- 条件查询
- 排序
- LIMIT
- 聚合函数
-
4.2 条件判断查询
-
4.3 多表查询
- 合并结果集(UNION)
- 连接查询(JOIN ... ON)
- 子查询
- 自连接
-
4.4 函数
- 时间日期相关
- 字符串相关
- 数学计算相关
- 流程控制相关
0. SQL 基础
SQL 分类
DCL(Data Control Language):数据控制语句,主要做权限控制,比如创建账号、授权、修改密码。常用关键字有 grant、revoke、create user 等。
DDL (Data Definition Language):数据定义语句,主要针对数据库、表、字段等的定义操作。常用关键字有 create、drop、alter 等。
DML (Data Manipulation Language):数据操纵语句,主要做表数据的增删改操作。常用关键字有 insert、delete、update 等。
DQL (Data Query Language):数据查询语言,主要做表数据的查询操作。常用关键字有 select 等。
SQL 语法规则
- SQL 关键字不区分大小写(Oracle 区分)
- SQL 以 ;(分号)结尾,也可以以 \G 结尾(表示结构化输出结果)
- 使用 ' '(单引号)或 " "(双引号)来表示字符串(Oracle 只支持单引号)
- 使用 ` `(反引号)来表示数据库、数据表、字段(也可以不使用)
- 注释一行: -- 或 #
- 注解多行: /* */
1. DCL
DCL(Data Control Language):数据控制语句,主要做权限控制,比如创建账号、授权、修改密码。常用关键字有 grant,revoke,create user 等。
1.1 查看权限
创建完账号后,时间场了可能就会忘记分配的权限而需要查看账号权限,也有可能经过一段时间后需要更改以前的的账号权限。
查看用户
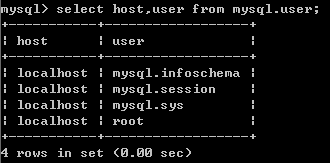
- host:允许用户登录所使用的 IP。
补充:mysql 用户表中多个 host 时的匹配规则
Mysql 数据库中 user 表的 host 字段,是用来控制用户访问数据库“权限”的。
- 可以使用“%”、""(空字符串)、“*”,表示所有的网段(但不包括 localhost);
- 也可以使用具体的 IP 地址,表示只有该 IP 的客户端才可以登录到 Mysql 服务器;
- 也可以使用“_”进行模糊匹配,表示匹配成功的客户端可以登录到 Mysql 服务器。
如果在 user 表中存在一个用户两条不同 host 值的记录,那么 Mysql 服务器该如何匹配该用户的权限呢?
Mysql 采用的策略是:当服务器读取 user 表时,它首先以最具体的 host 值排序(主机名和 IP 是最具体的) 。当有相同 host 值的条目时,首先以最具体的 user 匹配。
如下,有两条 root 用户数据,那么只有 localhost 的 root 客户端可以登录到 Mysql 服务器。
| root | localhost | *81F5E21E35407D884A6CD4A731AEBFB6AF209E1B | | root | % | *81F5E21E35407D884A6CD4A731AEBFB6AF209E1B |
查看权限
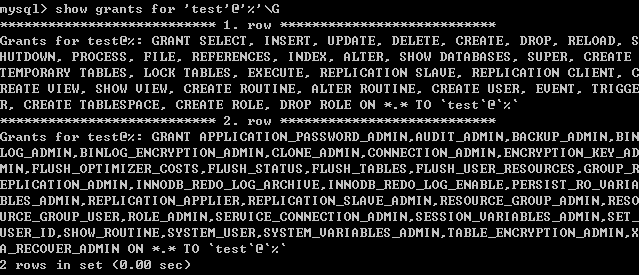
可以通过如下命令进行查看权限:
show grants for 'user'@'host'; -- 可以不加引号,但加了可以避免歧义 show grants for user; --@host 也可以不写,默认为%(模糊匹配) show grants; --查看当前账号的权限
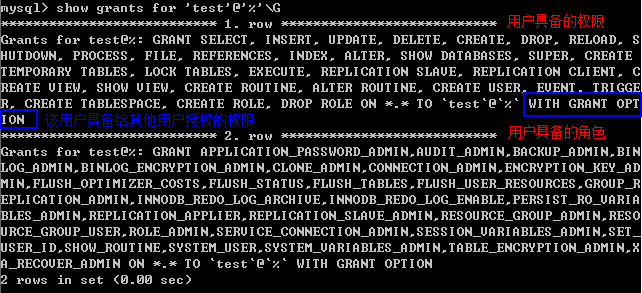
1.2 创建用户并赋予权限
Mysql 8.0 以前的版本可以使用 grant 在授权的时候隐式的创建用户,8.0 以后已经不支持,所以必须先创建用户,然后再授权。
示例 1:创建用户 test,权限为可以在所有数据库上执行所有权限,可以从任意 IP 进行连接。
--创建用户 create user 'test'@'%' identified [with mysql_native_password] by '123456'; --加密方式默认为caching_sha2_password --授权 grant all privileges on *.* to 'test'@'%';
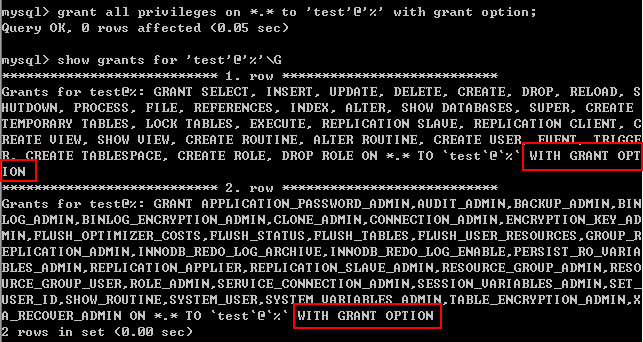
示例 2:在示例 1 的基础上为用户增加 grant 权限。
grant all privileges on *.* to 'test'@'%' with grant option;
示例 3:创建用户 test2,只能从服务器本地进行连接,权限为对 test1 数据库里的所有表进行 select、update、insert 和 delete 操作,初始密码为“123”。
--创建用户 create user 'test2'@'localhost' identified by '123456'; --加密方式默认为caching_sha2_password --授权 grant select, insert, update, delete on test1.* to 'test2'@'localhost';
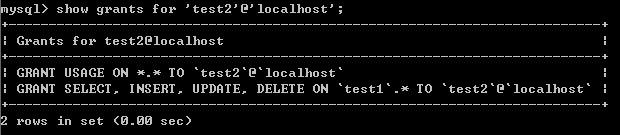
示例 4:只授予登录权限。
grant usage on *.* to 'test2'@'localhost';
示例 5:如果要让一个非 root 账号可以创建用户并授权,需要两步。
grant create user on *.* to 'test'@'%'; -- 授予 create user 权限 grant create user ON *.* TO 'test'@'%' with grant option; -- 授予 grant 权限
注意:账号只能授予自己本身拥有的权限。
1.3 回收权限
GRANT INSERT ON 'test'.* TO 'test1'@'%'; -- 授予INSERT权限 REVOKE INSERT ON 'test'.* FROM 'test1'@'%'; -- 回收INSERT权限
1.4 修改密码
-- 方式1:SET
set password for 'test'@'%'='123456';
-- 方式2:ALTER
alter user 'test'@'%' identified by '123456';
1.5 删除账号
--方式1:DROP drop user 'test'@'localhost'; drop user 'test'@'localhost', 'test2'@'localhost'; -- 删除多个用户 --方式2:修改user表 delete from mysql.user where user='test' and host='localhost'; flush privileges; -- 修改权限表后需要刷新权限才能及时生效(载入内存)
1.6 权限信息与生效规则
权限信息都存在哪里?
所有权限信息都存在 Mysql 库里的 user、db、tables_priv、columns_priv 这四张表中。
权限是如何生效?
一般 Mysql 登录有两个步骤:
- 连接数据库(网络可达);
- 验证密码、权限。
而 Mysql 服务器中的权限信息都会加载到内存中,以此保证验证速度。
GRANT、ALTER 等 DCL 操作修改权限信息时,会直接加载到内存中,即时生效。
当修改权限表信息时,则需要使用 flush privileges 重新加载权限信息到内存中。
2. DDL
DDL (Data Definition Language):数据定义语句,主要针对数据库、表、字段等的定义操作。常用关键字有 create、drop、alter 等。
2.1 库对象
1)创建数据库
create database mydb1; -- 如果 mydb1 存在则会报错 create database IF NOT EXISTS mydb2; -- 如果 mydb2 不存在才创建数据库(避免冲突报错) create database mydb3 character set gbk; create database mydb4 character set gbk COLLATE gbk_chinese_ci;
use mydb1; -- 进入 mydb1 数据库
COLLATE 代表的是数据库校对规则:
- utf8_bin:将字符串中的每一个字符用二进制数据存储,区分大小写。
- utf8_genera_ci:不区分大小写(ci 为 case insensitive 的缩写,即大小写不敏感)。
- utf8_general_cs:区分大小写(cs 为 case sensitive 的缩写,即大小写敏感)。
2)查询数据库信息
-- 查看所有数据库 show databases; -- 查看当前使用的数据库 select database(); -- 查看mydb2数据库的定义信息 show create database mydb2;
3)修改数据库信息
-- 把 mydb2 库的字符集修改为 utf8 alter database mydb2 character set utf8;
4)删除数据库
drop database mydb3;
2.2 表对象
1)创建表
create table [if not exists] 表名( 字段名 字段类型, 字段名 字段类型, ... 字段名 字段类型 ); -- 使用like创建表 create table new_table like old_table; -- 创建与 old_table 表结构一致的 new_table 表 insert into new_table SELECT * from old_table; -- 导入 old_table 的数据到 new_table 表
增加默认值、注释信息、主键、自增值、备注:
create table student( id int comment '学号ID' auto_increment primary key, -- 自增值无需指定默认值(因为已默认从1开始递增),且必须指定为主键 name varchar(30) not null default '' comment '学生姓名', age tinyint not null default 0 comment '学生年龄', phoneNo char(11) not null comment '学生手机号', addr varchar(100) not null comment '学生家庭住址' );
- not null:因为 null 是一个特殊的值,无法被索引,所以建议创建表的时候指定字段为 not null。
- 默认值:建议创建表时为字段指定默认值。
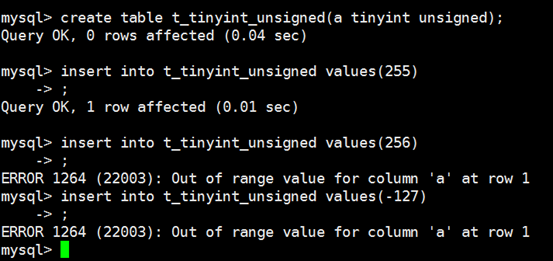
指定无符号的数值类型:
指定存储引擎、字符集、数据库校对规则:
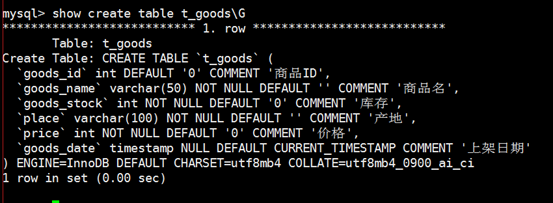
COLLATE 代表的是数据库校对规则:
- utf8_bin:将字符串中的每一个字符用二进制数据存储,区分大小写。
- utf8_genera_ci:不区分大小写(ci 为 case insensitive 的缩写,即大小写不敏感)。
- utf8_general_cs:区分大小写(cs 为 case sensitive 的缩写,即大小写敏感)。
2)查看表信息
-- 当前数据库中的所有表 SHOW TABLES; -- 查看 student 的表结构 DESC student; -- 查看 student 表的创建语句 SHOW CREATE TABLE student;
3)修改表信息
-- 增加一个 lesson 列,其字段类型为 blob ALTER TABLE student ADD lesson blob not null default ''; -- 一次增加多个列 ALTER TABLE student ADD nick_name char(10) not null default '', ADD teacher char(10) not null default ''; -- 修改 addr 列,使其长度为 60 ALTER TABLE student MODIFY addr varchar(60); -- 列名 addr 修改为 address,并修改其字段属性 ALTER TABLE student CHANGE addr address varchar(100) not null default ''; -- 删除 lesson 列 ALTER TABLE student DROP image; -- 一次删除多列 ALTER TABLE student DROP phoneNo, DROP addr; -- 表名改为 new_student RENAME TABLE student TO new_student; -- 修改表的字符集为 utf8 ALTER TABLE new_student CHARACTER SET utf8;
自增字段达到了最大值,导致插入数据报错:

这时就需要把自增字段修改为存储范围更大的数值类型(如 bigint)。
4)删除表
DROP TABLE student; -- 删除 student 表
3. DML
DML (Data Manipulation Language):数据操纵语句,主要做表数据的增删改操作。常用关键字有 insert、delete、update 等。
3.1 插入数据:INSERT
语法:
INSERT INTO 表名(列名1,列名2 ...)VALUES(列值1,列值2...);
- 列名与列值的类型、个数、顺序要一一对应。
- 如果要插入空值,可使用 "" 或 null。
- 其它未提供的字段,采用 default(默认值)或自增值。
示例:
-- 创建表 create table tmp( id int, name varchar(100), gender varchar(10), birthday date, salary float(10, 2), entry_date date, resume text ); -- 插入单条数据 INSERT INTO tmp(id, name, gender, birthday, salary, entry_date, resume) VALUES(1, 'zhangsan', 'female', '1990-5-10', 10000, '2015-5-5', 'good girl'); -- 插入多条数据 INSERT INTO tmp(id, name, gender, birthday, salary, entry_date, resume) VALUES(2, 'lisi', 'male', '1995-5-10', 10000, '2015-5-5', 'good boy'), (3, '你好', 'male', '1995-5-10', 10000, '2015-5-5', 'good boy');
3.2 修改数据:UPDATE
语法:
UPDATE 表名 SET 列名1=列值1, 列名2=列值2, ... WHERE 列名=值
示例:
-- 全量修改:将所有员工薪水修改为5000元 UPDATE emp SET salary=5000; -- 带条件修改:将姓名为'zs'的员工薪水修改为3000元 UPDATE emp SET salary=3000 WHERE name='zhangsan'; -- 修改多个字段:将姓名为'aaa'的员工薪水修改为4000元,job改为ccc UPDATE emp SET salary=4000, gender='female' WHERE name='lisi'; -- 使用运算:将wu的薪水在原有基础上增加1000元 UPDATE emp SET salary=salary+1000 WHERE gender='male';
3.3 删除数据:DELETE/TRUNCATE
语法:
DELETE 表名 WHERE 列名=值; -- 删除指定数据 TRUNCATE TABLE 表名; -- 清空整个表数据(等于重新建表)
示例:
-- 删除表中名称为'zs'的记录 DELETE FROM tmp WHERE name='zs'; -- 删除表中所有记录 DELETE FROM tmp; -- 使用truncate删除表中记录 TRUNCATE TABLE tmp; -- 根据id值删除重复数据:每个分组保留最小的id值并删除其余数据 delete from student where id not in (select minid from (select min(id) as minid from student group by name) b);
DELETE 与 TRUNCATE 区别:
- DELETE:删除表中的数据,表结构还在;删除后的数据可以找回。
- TRUNCATE:等于把表直接 DROP 掉,然后再创建一个同样的新表。删除的数据不能找回,自增值重置为从 1 开始。执行速度比 DELETE 快。
4. DQL
DQL (Data Query Language):数据查询语言,主要做表数据的查询操作。常用关键字有 select 等。
数据库执行DQL语句不会对数据进行改变,而是让服务端发送结果集给客户端,即查询返回的结果集是一张虚拟表。

查询语句的书写顺序如上;而执行顺序如下:
from —> where —> group by —> having —> select —> order by —> limit
4.1 基础
字段控制
1)两列的类型都是数值类型,可以做加运算。如果其中有一个字段不是数值类型,那么会报错。
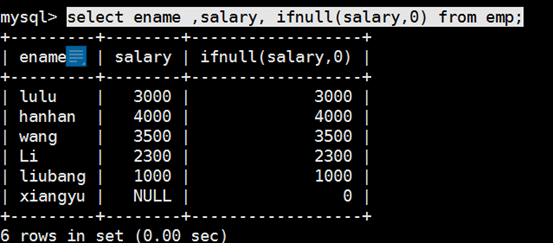
2)假如某列有很多记录的值为 NULL,因为任何东西与 NULL 相加结果还是 NULL ,所以结算结果可能会出现 NULL。下面使用了把 NULL 转换成数值 0 的函数 IFNULL():
SELECT *, sal+IFNULL(comm, 0) FROM emp;
3)可以给列名添加别名,并且给列起别名时,是可以省略 AS 关键字的。
模糊查询
当想查询姓名中包含 a 字母的学生时就需要使用模糊查询了。模糊查询需要使用关键字 LIKE。
通配符如下:
- _:任意一个字母。
- %:任意 0~n 个字母。
select * from student where name like '%a%';
条件查询
条件查询就是在查询时给出 WHERE 子句,在 WHERE 子句中可以使用如下运算符及关键字:
- =、!=、<>、<、<=、>、>=
- BETWEEN…AND
- IN
- IS NULL
- AND
- OR
- NOT
排序
-- 查询所有学生记录,按年龄升序排序 SELECT * FROM stu ORDER BY sage ASC; -- 默认升序 SELECT * FROM stu ORDER BY sage; -- 查询所有学生记录,按年龄降序排序 SELECT * FROM stu ORDER BY age DESC; -- 查询所有雇员,按月薪降序排序;如果月薪相同时,按编号升序排序 SELECT * FROM emp ORDER BY sal DESC, empno ASC;
LIMIT
LIMIT 用来限定查询结果的起始行以及总行数。
-- 起始行, 需要的行数 SELECT * FROM emp LIMIT 0, 5; -- 也可以只写行数 SELECT * FROM emp LIMIT 5; -- 起始行默认为0
聚合函数

- count
- count(*) :输出的是所有记录行数,包括全为 null 的行。
- count(列名) :会统计空字符,而不会统计 null。
- sum
- 均不统计空字符与 null。
- avg
- avg(value) = sum(value) / count(value)
- 对某列使用 avg 时,其处理空值和空字符时方式和 count 一样,会统计空字符而不会统计 null。
having 与 where 的区别
| WHERE | HAVING | |
| 出现位置 | GROUP BY 前 | GROUP BY 后 |
| 作用对象 |
数据源 (是对分组前记录的筛选条件,如果某行记录没有满足 WHERE 子句的条件,那么这行记录不会参加分组) |
分组后的结果 (对分组后的数据进行过滤,是对分组后数据的约束) |
| 语句后能否使用聚合函数 | WHERE 后面不可以使用聚合函数 | HAVING 后面可以使用聚合函数 |
示例:
SELECT deptno, SUM(sal) FROM emp GROUP BY deptno HAVING SUM(sal) > 9000; -- 查询总薪资大于9000的部门编号
4.2 条件判断查询

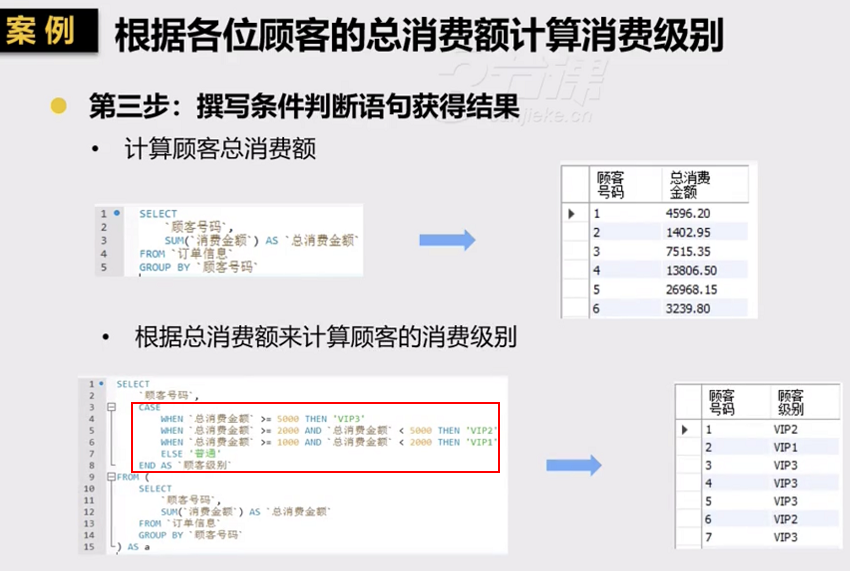
4.3 多表查询
多表查询有如下几种:
- 合并结果集:UNION、UNION ALL
- 连接查询:JOIN ... ON
- 内连接:[INNER] JOIN ... ON
- 外连接:[OUTER] JOIN ... ON
- 左(外)连接:LEFT [OUTER] JOIN
- 右(外)连接:RIGHT [OUTER] JOIN
- 全外连接:(MySQL 不支持)FULL JOIN
- 自然连接:NATURAL JOIN
- 子查询
- 自连接
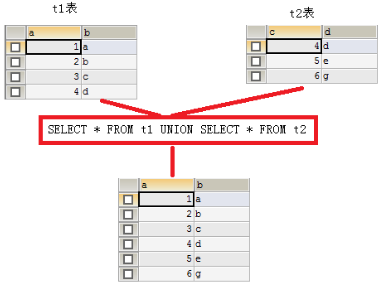
1)合并结果集(UNION)
作用:合并结果集就是把两个 select 语句的查询结果合并到一起。
要求:被合并的两张表的列数、列类型必须相同。
-- UNION:去除重复记录 SELECT * FROM t1 UNION SELECT * FROM t2;
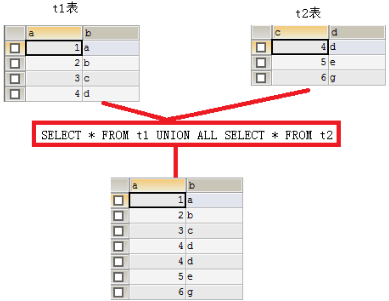
-- UNION ALL:不去除重复记录 SELECT * FROM t1 UNION ALL SELECT * FROM t2;
2)连接查询(JOIN ... ON)
连接查询就是求出多个表的乘积,例如 t1 连接 t2,那么查询出的结果就是 t1*t2。
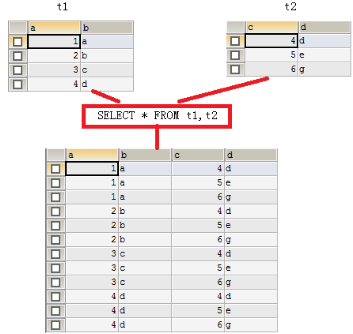
连接查询会产生笛卡尔积,假设集合 A={a,b},集合 B={0,1,2},则两个集合的笛卡尔积为 {(a,0),(a,1),(a,2),(b,0),(b,1),(b,2)}。可以扩展到多个集合的情况。
多表查询产生这样的结果并不是我们想要的,那么怎样去除重复的、不想要的记录呢?当然是通过条件过滤。通常要查询的多个表之间都存在关联关系(主键),那么就可以通过关联关系(主键)去除笛卡尔积。
SELECT * FROM emp,dept WHERE emp.deptno=dept.deptno; -- emp表和dept表 通过deptno主键字段 进行关联
内连接
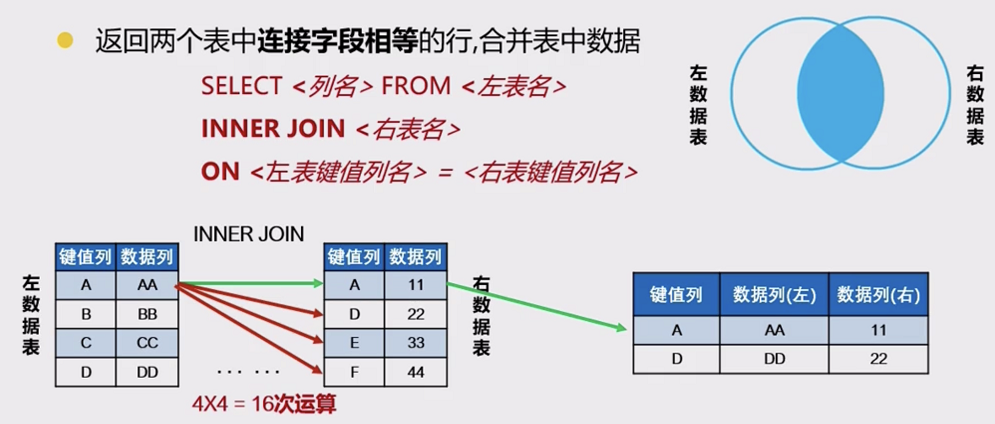
INNER 可以省略,MySQL 默认的连接方式就是内连接。
内连接的特点:查询结果必须满足条件,即查询出同时满足左表和右表的条件的结果。
外连接(左/右连接)
外连接的特点:查询出的结果存在不满足条件的可能。
- 左连接是先查询出左表(即以左表为主),然后查询右表,右表中满足条件的显示出来,不满足条件的显示 NULL。
- 右连接就是先把右表中所有记录都查询出来,然后左表满足条件的显示,不满足显示 NULL。


连接查询总结
连接不限于两张表,连接查询也可以是三张、四张,甚至 N 张表的连接查询。通常连接查询不需要整个笛卡尔积,而只是需要其中一部分,那么这时就需要使用条件来去除不需要的记录。这个条件大多数情况下都是使用主外键关系去除。
两张表的连接查询一定有一个主外键关系,三张表的连接查询就一定有两个主外键关系,所以在大家不是很熟悉连接查询时,首先要学会去除无用笛卡尔积,那么就是用主外键关系作为条件来处理。如果是两张表的查询,那么至少得有一个主外键条件,三张表连接则至少得有两个主外键条件。
自然连接(NATURAL JOIN)
连接查询会产生无用笛卡尔积,我们通常使用主外键关系等式来去除它。而自然连接无需你去给出主外键等式,它会自动找到这一等式。
两张连接的表中名称和类型完全一致的列作为条件,例如 emp 和 dept 表都存在 deptno 列,并且类型一致,所以会被自然连接找到。
当然自然连接还有其他的查找条件的方式,但其他方式都可能存在问题。
SELECT * FROM emp NATURAL JOIN dept; --内连接 SELECT * FROM emp NATURAL LEFT JOIN dept; --左连接 SELECT * FROM emp NATURAL RIGHT JOIN dept; --右连接
3)子查询
子查询就是嵌套查询,即 SELECT 中包含 SELECT,如果一条语句中存在两个,或两个以上 SELECT,那么就是子查询语句。
子查询出现的位置:
- where 后:作为被查询的条件的一部分
- from 后:用作表
当子查询出现在 where 后作为条件时,还可以使用如下关键字:
- any
- all
子查询结果集的形式:
- 单行单列(用作条件)
- 单行多列(用作条件)
- 多行单列(用作条件)
- 多行多列(用作表)
示例:
-- 子查询作为条件:查询高于编号30部门所有人工资的员工信息 SELECT * FROM emp WHERE sal > ALL (SELECT sal FROM emp WHERE deptno=30); -- 子查询作为表 SELECT e.ename, e.sal, d.dname, d.loc FROM emp e, (SELECT dname,loc,deptno FROM dept) d WHERE e.deptno=d.deptno AND e.empno=7788;
4)自连接
即表对自身连接,将一张表当成两张或多张表使用,以别名来区分表。
-- 例:求7369员工编号、姓名、经理编号和经理姓名 SELECT e1.empno, e1.ename, e2.mgr, e2.ename FROM emp e1, emp e2 WHERE e1.mgr = e2.empno AND e1.empno = 7369;
4.4 函数
时间日期相关
1)获取当前时间
- CURRENT_DATE():当前日期
- CURRENT_TIME():当前时间
- CURRENT_TIMESTAMP():当前时间戳
- now():当前日期+时间
- sysdate():当前日期+时间
sysdate() 日期时间函数跟 now() 类似,不同之处在于:
- now() 在执行开始时值就得到了。
- sysdate() 在函数执行时动态得到值,一般情况下很少用到。
mysql> select now(), sleep(3), now(); +---------------------+----------+---------------------+ | now() | sleep(3) | now() | +---------------------+----------+---------------------+ | 2021-06-08 14:39:29 | 0 | 2021-06-08 14:39:29 | +---------------------+----------+---------------------+ 1 row in set (3.08 sec) mysql> select sysdate(), sleep(3), sysdate(); +---------------------+----------+---------------------+ | sysdate() | sleep(3) | sysdate() | +---------------------+----------+---------------------+ | 2021-06-08 14:40:03 | 0 | 2021-06-08 14:40:06 | +---------------------+----------+---------------------+ 1 row in set (3.06 sec)
2)INTERVAL
INTERVAL 代表的是时间间隔。
Mysql 中的时间间隔类型有如下几种:
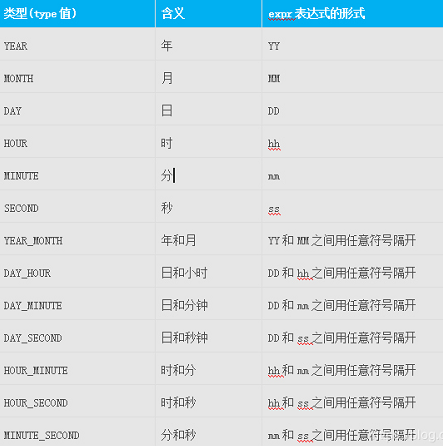
利用 INTERVAL 做时间的加减法:
-- 加法 SELECT DATE '2018-11-01' + INTERVAL '10 11' DAY_HOUR; -- 结果:2018-11-11 11:00:00 -- 减法 select DATE '2018-11-11 11:00:00' - INTERVAL '10 11' DAY_HOUR; -- 结果:2018-11-01 00:00:00
3)时间计算
为日期增加一个时间间隔:date_add()
set @dt = now(); select date_add(@dt, interval 1 day); -- add 1 day select date_add(@dt, interval 1 hour); -- add 1 hour select date_add(@dt, interval 1 minute); select date_add(@dt, interval 1 second); select date_add(@dt, interval 1 microsecond); select date_add(@dt, interval 1 week); select date_add(@dt, interval 1 month); select date_add(@dt, interval 1 quarter); select date_add(@dt, interval 1 year); select date_add(@dt, interval -1 day); -- sub 1 day
adddate()、addtime() 函数,可以用 date_add() 来替代:
set @dt = '2008-08-09 12:12:33'; select date_add(@dt, interval '01:15:30' hour_second); -- 2008-08-09 13:28:03 select date_add(@dt, interval '1 01:15:30' day_second); -- 2008-08-10 13:28:03
为日期减去一个时间间隔:date_sub()
date_sub() 函数 和 date_add() 用法一致,不再赘述。
select date_sub('1998-01-01 00:00:00', interval '1 1:1:1' day_second); -- 1997-12-30 22:58:59
日期、时间相减函数:datediff(date1, date2)、timediff(time1, time2)
-- datediff(date1,date2):两个日期相减 date1 - date2,返回天数 select datediff('2008-08-08', '2008-08-01'); -- 7 select datediff('2008-08-01', '2008-08-08'); -- -7 -- timediff(time1,time2):两个日期相减 time1 - time2,返回 time 差值 select timediff('2008-08-08 08:08:08', '2008-08-08 00:00:00'); -- 08:08:08 select timediff('08:08:08', '00:00:00'); -- 08:08:08
注意:timediff(time1, time2) 函数的两个参数类型必须相同。
时间戳(timestamp)转换、增、减函数
- timestamp(date) -- date to timestamp
- timestamp(dt, time) -- dt + time
- timestampadd(unit, interval, datetime_expr)
- timestampdiff(unit, datetime_expr1, datetime_expr2)
select timestamp('2008-08-08'); -- 2008-08-08 00:00:00 select timestamp('2008-08-08 08:00:00', '01:01:01'); -- 2008-08-08 09:01:01 select timestamp('2008-08-08 08:00:00', '10 01:01:01'); -- 2008-08-18 09:01:01 -- timestampadd() 函数类似于 date_add() select timestampadd(day, 1, '2008-08-08 08:00:00'); -- 2008-08-09 08:00:00 select date_add('2008-08-08 08:00:00', interval 1 day); -- 2008-08-09 08:00:00 -- timestampdiff() 函数就比 datediff() 功能强多了,datediff() 只能计算两个日期(date)之间相差的天数。 select timestampdiff(year, '2002-05-01', '2001-01-01'); -- -1 select timestampdiff(day , '2002-05-01', '2001-01-01'); -- -485 select timestampdiff(hour, '2008-08-08 12:00:00', '2008-08-08 00:00:00'); -- -12 select datediff('2008-08-08 12:00:00', '2008-08-01 00:00:00'); -- 7
4)格式转换
日期/时间转换成时间戳
-
timestamp(date[, time]):date + time,其中 time 部分默认为 00:00:00
select timestamp('2008-08-08'); -- 2008-08-08 00:00:00 select timestamp('2008-08-08 08:00:00', '01:01:01'); -- 2008-08-08 09:01:01 select timestamp('2008-08-08 08:00:00', '10 01:01:01'); -- 2008-08-18 09:01:01
日期/时间转换成字符串
- date_format(date, format)
- time_format(time, format)
select date_format('2008-08-08 22:23:01', '%Y%m%d%H%i%s'); -- 20080808222301
date_format()、time_format() 能够把一个日期/时间转换成各种各样的字符串格式。它是 str_to_date(str, format) 函数的一个逆转换。
字符串转换为日期
- str_to_date(str, format)
select str_to_date('08/09/2008', '%m/%d/%Y'); -- 2008-08-09 select str_to_date('08/09/08' , '%m/%d/%y'); -- 2008-08-09 select str_to_date('08.09.2008', '%m.%d.%Y'); -- 2008-08-09 select str_to_date('08:09:30', '%h:%i:%s'); -- 08:09:30 select str_to_date('08.09.2008 08:09:30', '%m.%d.%Y %h:%i:%s'); -- 2008-08-09 08:09:30
可以看到,str_to_date() 可以把一些杂乱无章的字符串转换为日期格式。另外,它也可以转换为时间。
日期、天数互换
mysql> select to_days('0000-01-01'); +-----------------------+ | to_days('0000-01-01') | +-----------------------+ | 1 | +-----------------------+ 1 row in set (0.00 sec) mysql> select to_days('2020-01-01'); +-----------------------+ | to_days('2020-01-01') | +-----------------------+ | 737790 | +-----------------------+ 1 row in set (0.00 sec) mysql> select from_days(737790); +-------------------+ | from_days(737790) | +-------------------+ | 2020-01-01 | +-------------------+ 1 row in set (0.00 sec)
时间、秒互换
- time_to_sec(time)
- sec_to_time(seconds)
select time_to_sec('01:00:05'); -- 3605 select sec_to_time(3605); -- '01:00:05'
拼接日期、时间
- makdate(year, dayofyear)
- maketime(hour, minute, second)
select makedate(2001, 31); -- '2001-01-31' select makedate(2001, 32); -- '2001-02-01' select maketime(12, 15, 30); -- '12:15:30'
Unix 时间戳、日期互换
- unix_timestamp()
- unix_timestamp(date)
- from_unixtime(unix_timestamp)
- from_unixtime(unix_timestamp, format)
select unix_timestamp(); -- 1218290027 select unix_timestamp('2008-08-08'); -- 1218124800 select unix_timestamp('2008-08-08 12:30:00'); -- 1218169800 select from_unixtime(1218290027); -- '2008-08-09 21:53:47' select from_unixtime(1218124800); -- '2008-08-08 00:00:00' select from_unixtime(1218169800); -- '2008-08-08 12:30:00' select from_unixtime(1218169800, '%Y %D %M %h:%i:%s %x'); -- '2008 8th August 12:30:00 2008'
时区(timezone)转换
- convert_tz(dt, from_tz, to_tz)
select convert_tz('2008-08-08 12:00:00', '+08:00', '+00:00'); -- 2008-08-08 04:00:00 -- 时区转换也可以通过 date_add, date_sub, timestampadd 来实现。 select date_add('2008-08-08 12:00:00', interval -8 hour); -- 2008-08-08 04:00:00 select date_sub('2008-08-08 12:00:00', interval 8 hour); -- 2008-08-08 04:00:00 select timestampadd(hour, -8, '2008-08-08 12:00:00'); -- 2008-08-08 04:00:00
5)提取
- date(datetime):返回 datetime 中的日期部分。
- year/month/day(datetime):返回 datime 中的年/月/日部分。
- extract():返回日期/时间的单独部分,比如年、月、日、小时、分钟等。
-- 语法 EXTRACT(unit FROM date) -- 示例 mysql> SELECT -> EXTRACT(YEAR FROM NOW()) AS years , -> EXTRACT(MONTH FROM NOW()) AS months, -> EXTRACT(DAY FROM NOW()) AS days; +-------+--------+------+ | years | months | days | +-------+--------+------+ | 2021 | 6 | 8 | +-------+--------+------+ 1 row in set (0.02 sec) mysql> SELECT NOW(), EXTRACT(DAY_SECOND FROM NOW()); +---------------------+--------------------------------+ | NOW() | EXTRACT(DAY_SECOND FROM NOW()) | +---------------------+--------------------------------+ | 2021-06-08 15:13:58 | 151358 | +---------------------+--------------------------------+ 1 row in set (0.00 sec)
unit 取值表:
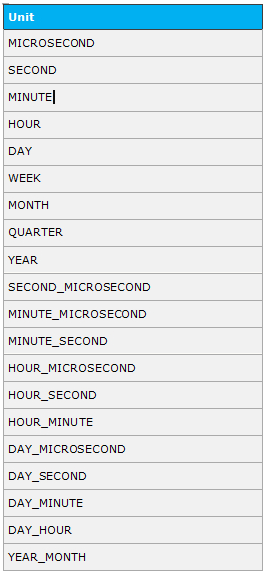
复合函数实现查询上个月月末/月初的日期
-- 上个月月末 -- 1. 首先查询出来这个月过了几天 select EXTRACT(DAY FROM NOW()) AS DAY; -- 2. 用 DATE_SUB 减去这时间间隔 SELECT DATE_SUB(DATE_FORMAT(NOW(), '%y-%m-%d'), INTERVAL EXTRACT(DAY FROM NOW()) AS DAY); -- 上个月月初 -- 1. 算出这个月过了几天 select EXTRACT(DAY FROM NOW()) DAY; -- 假设今天时间为11月7日,这个月过了7天,如果11月7日减去6天的话,就是月初,所以6天就是距离月初的时间间隔 select EXTRACT(DAY FROM NOW()) - 1 DAY; -- 2. 用 date_sub 得到本月月初时间 SELECT DATE_SUB(DATE_FORMAT(NOW(), '%y-%m-%d'), INTERVAL EXTRACT(DAY FROM NOW()) - 1 DAY); -- 3. 继续用 date_sub 将上述结果,减去一个月 SELECT DATE_SUB(DATE_SUB(DATE_FORMAT(NOW(), '%y-%m-%d'), INTERVAL EXTRACT(DAY FROM NOW()) - 1 DAY), INTERVAL 1 MONTH);
字符串相关
| 语法 | 说明 |
| CHARSET(str) | 返回字符串的字符集 |
| CONCAT(str[, str2, str3, ...]) | 拼接字符串 |
| INSTR(str, substr) | 返回 substr 在 str 中出现的位置,没有则返回 0 |
| UCASE(str) / UPPER(STR) | 转换成大写 |
| LCASE(str) / LOWER(STR) | 转换成小写 |
| LEFT(str, len) | 从 str 的左边起取 len 个字符 |
| SUBSTRING(str, position[, length]) | 从 str 的position 索引位开始取 length 个字符 |
| LENGTH(str) | 返回 str 的长度 |
| INSERT(str, x, y, instr) | 从字符串 str 的 x 位置开始,取 y 个字符替换为 instr |
| REPLACE(str, search_str, replace_str) | 在 str 中用 replace_str 替换 search_str |
| LTRIM(str)/RTRIM(str)/TRIM(str) | 去除字符串左/右/左右边的空格 |
| LPAD(str, n, pad) | 从 str 左边开始用 pad 字符串进行填充,直到字符串长度为 n |
| RPAD(str, n, pad) | 从 str 右边开始用 pad 字符串进行填充,直到字符串长度为 n |
| REPEAT(str, n) | 将字符串 str 重复 n 次 |
示例:
mysql> select concat("hello", " ", "world"); +-------------------------------+ | concat("hello", " ", "world") | +-------------------------------+ | hello world | +-------------------------------+ 1 row in set (0.06 sec) mysql> select concat("hello", null, "world"); -- 只要含有null,则结果都为null +--------------------------------+ | concat("hello", null, "world") | +--------------------------------+ | NULL | +--------------------------------+ 1 row in set (0.00 sec) mysql> select INSTR("abcde", "bc"); -- 索引从1开始 +----------------------+ | INSTR("abcde", "bc") | +----------------------+ | 2 | +----------------------+ 1 row in set (0.04 sec) mysql> select insert("!!!!!", 2, 3, "world"); -- 索引从1开始 +--------------------------------+ | insert("!!!!!", 2, 3, "world") | +--------------------------------+ | !world! | +--------------------------------+ 1 row in set (0.00 sec) mysql> select lpad("hello", 15, "!"); +------------------------+ | lpad("hello", 15, "!") | +------------------------+ | !!!!!!!!!!hello | +------------------------+ 1 row in set (0.06 sec) mysql> select repeat("hello ", 3); +---------------------+ | repeat("hello ", 3) | +---------------------+ | hello hello hello | +---------------------+ 1 row in set (0.20 sec)
数学计算相关
| 语法 | 说明 |
| ABS(num) | 绝对值 |
| BIN(num) | 十进制转二进制 |
| CEIL(num) / CEILING(num) | 向上取整 |
| FLOOR(num) | 向下取整 |
| CONV(num, from_base, to_base) | 进制转换 |
| FORMAT(num, decimal_places) | 保留小数位数 |
| HEX(num) | 十进制转十六进制 |
| LEAST(num1[, num2, num3, ...]) | 取最小值 |
| GREATEST(num1[, num2, num3, ...]) | 取最大值 |
| MOD(num, denominator) | 取余 |
| RAND([seed]) |
返回 [0, 1) 的随机数 (同样的种子得到同样的随机序列) |
| ROUND(float, n) |
四舍五入,保留 n 位小数 |
| TRUNCATE(float_num, n) |
将浮点数进行截断,保留 n 位小数 |
示例:
mysql> select ROUND(10.4999, 1); +-------------------+ | ROUND(10.4999, 1) | +-------------------+ | 10.5 | +-------------------+ 1 row in set (0.00 sec) mysql> select TRUNCATE(10.4999, 1); +----------------------+ | TRUNCATE(10.4999, 1) | +----------------------+ | 10.4 | +----------------------+ 1 row in set (0.00 sec) mysql> select ROUND(RAND()*100); +-------------------+ | ROUND(RAND()*100) | +-------------------+ | 9 | +-------------------+ 1 row in set (0.00 sec)
流程控制相关
| 语法 | 说明 |
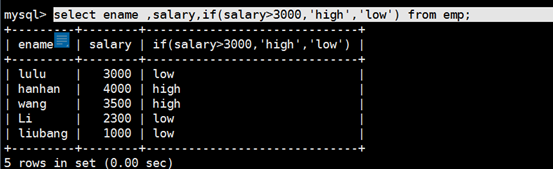
| IF(condition, t, f) | 如果 condition 为真,返回 t,否则返回 f |
| IFNULL(values1, value2) | 如果 value1 不为 null,返回 value1;否则返回 value2 |
示例:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号