
Redis 集群
1. Redis Cluster 简介
2. Redis Cluster 架构
3. 故障转移
1. Redis Cluster 简介
Redis Cluster 是 Redis 官方提供的 Redis 集群功能。
为什么要实现 Redis Cluster?
- Redis 是单线程的(从网络 I/O 处理到实际的读写命令处理),无论单核 CPU 下内存多大,如果需要大量计算能力,还是需要采用分布式以增加 CPU 资源。
- 随着公司发展,用户数量增多,并发越来越多,业务需要更高的 QPS,而主从复制中单机的 QPS(10W)可能无法满足业务需求。
- 数据量的考虑:现有服务器内存不能满足业务数据的需要时,单纯向服务器添加内存不能达到要求,此时需要考虑分布式需求,把数据分布到不同服务器上。
- 网络流量需求:业务的流量已经超过服务器的网卡的上限值,可以考虑使用分布式来进行分流。
- 离线计算,需要中间环节缓冲等别的需求。
Redis Cluster 缺点
当节点数量很多时,性能不会很高。
解决方案:使用 smart 智能客户端操作集群达到通信效率最大化。客户端内部负责计算维护键,槽以及节点的映射,用于快速定位到目标节点。智能客户端知道由哪个节点负责管理哪个槽,而且当节点与槽的映射关系发生改变时,客户端也会知道这个改变,这是一种非常高效的方式。
集群的限制
key 批量操作支持有限:例如 mget、mset 必须在一个 slot。
key 事务和 Lua 支持有限:操作的 key 必须在一个节点。
key 是数据分区的最小粒度:不支持 bigkey 分区。
不支持多个数据库:集群模式下只有一个 db0。
复制只支持一层:不支持树形复制结构。
Redis Cluster 满足容量和性能的扩展性,很多业务“不需要”。
大多数时客户端性能会“降低”。 命令无法跨节点使用:mget、keys、scan、flush、sinter 等。 Lua 和事务无法跨节点使用。
客户端维护更复杂:SDK 和应用本身消耗(例如更多的连接池)。
数据分布
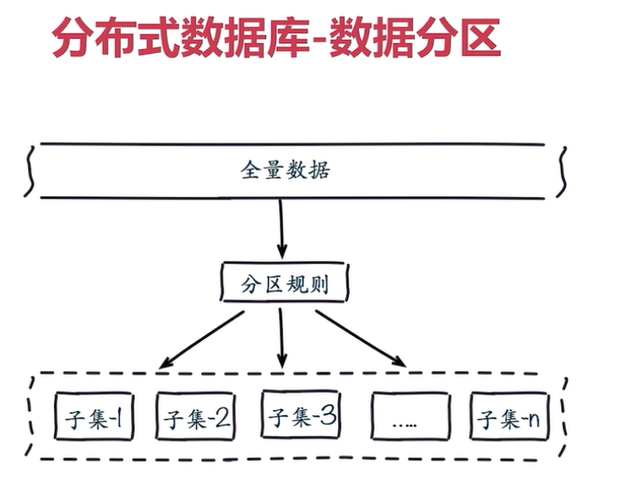
为什么要做数据分布?
全量数据,单机 Redis 节点无法满足要求,按照分区规则把数据分到若干个子集当中。
常用数据分布之顺序分布
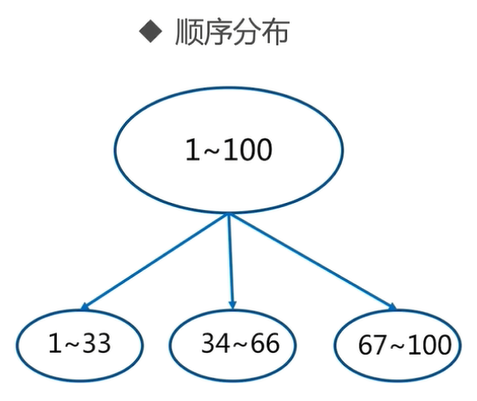
顺序分区常用在关系型数据库的设计。
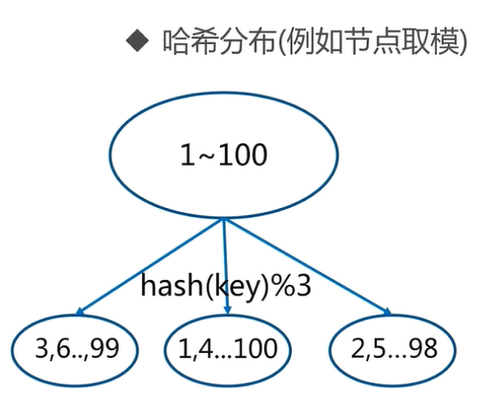
常用数据分布之哈希分布
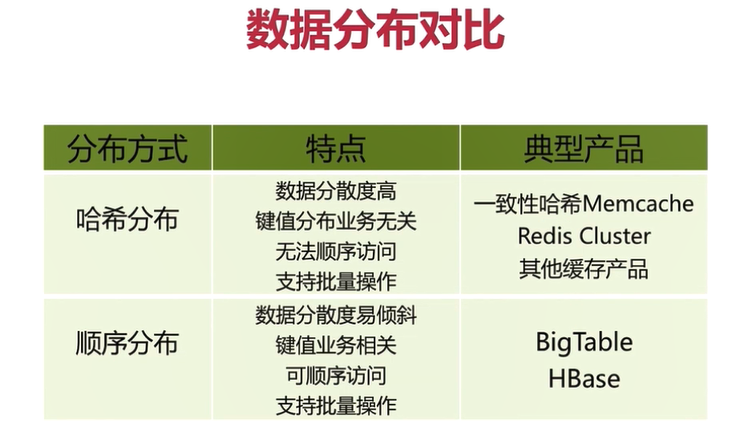
虚拟槽分区
虚拟槽分区是 Redis Cluster 采用的分区方式。
预设虚拟槽,每个槽就相当于一个数字,有一定范围。每个槽映射一个数据子集,一般比节点数大。
Redis Cluster 中预设虚拟槽的范围为 0 到 16383
每个 key 通过 CRC16 校验后对 16384 取模来决定这个 key 存放在哪个槽(slot)。
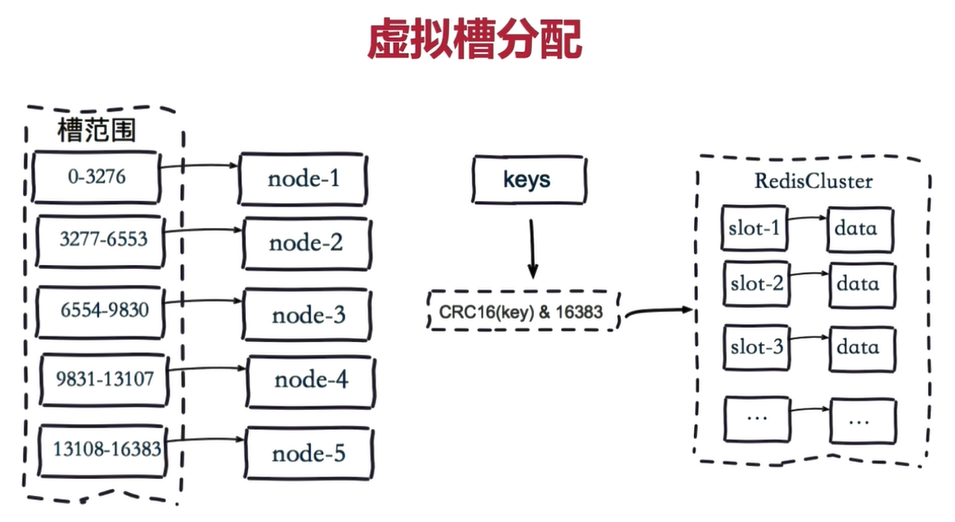
步骤:
- 把 16384 个槽按照节点数量进行平均分配,由节点进行管理。
- 对每个 key 按照 CRC16 规则进行 hash 运算。
- 把 hash 结果对 16383 进行取余。
- 把余数发送给 Redis 节点。
- 节点接收到数据,验证是否在自己管理的槽编号的范围。
- 如果在自己管理的槽编号范围内,则把数据保存到数据槽中,然后返回执行结果。
- 如果在自己管理的槽编号范围外,则会把数据发送给正确的节点,由正确的节点来把数据保存在对应的槽中。
需要注意的是:Redis Cluster 的节点之间会共享消息,每个节点都会知道是哪个节点负责哪个范围内的数据槽。
虚拟槽分布方式中,由于每个节点管理一部分数据槽,数据保存到数据槽中。当节点扩容或者缩容时,对数据槽进行重新分配迁移即可,数据不会丢失。
虚拟槽分区特点:
- 使用服务端管理节点、槽、数据。例如 Redis Cluster。
- 可以对数据打散,又可以保证数据分布均匀
2. Redis Cluster 架构
1)节点
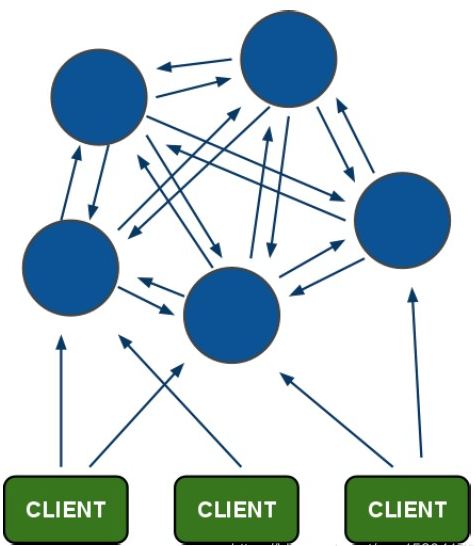
- Redis Cluster 是分布式架构的:即 Redis Cluster 中有多个节点,每个节点都负责进行数据读写操作。
- 每个节点之间会进行通信。
2)meet 操作
- meet 操作是节点之间完成相互通信的基础,meet 操作有一定的频率和规则。
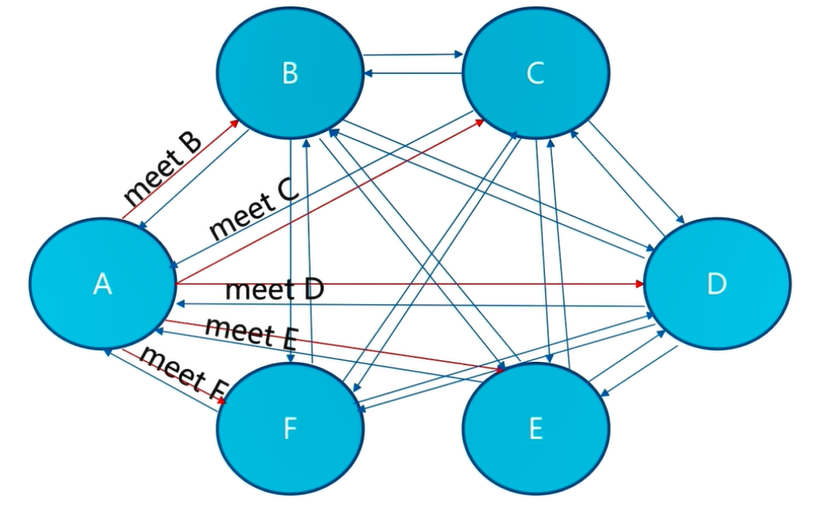
所有的 Redis 节点彼此互连,内部使用二进制协议优化传输速度和带宽。
客户端与 Redis 节点直连,不需要中间 proxy 层。客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
3)分配槽
把 16384 个槽平均分配给节点进行管理,每个节点只能对自己负责的槽进行读写操作。
由于每个节点之间都彼此通信,每个节点都知道其他节点负责管理的槽范围。
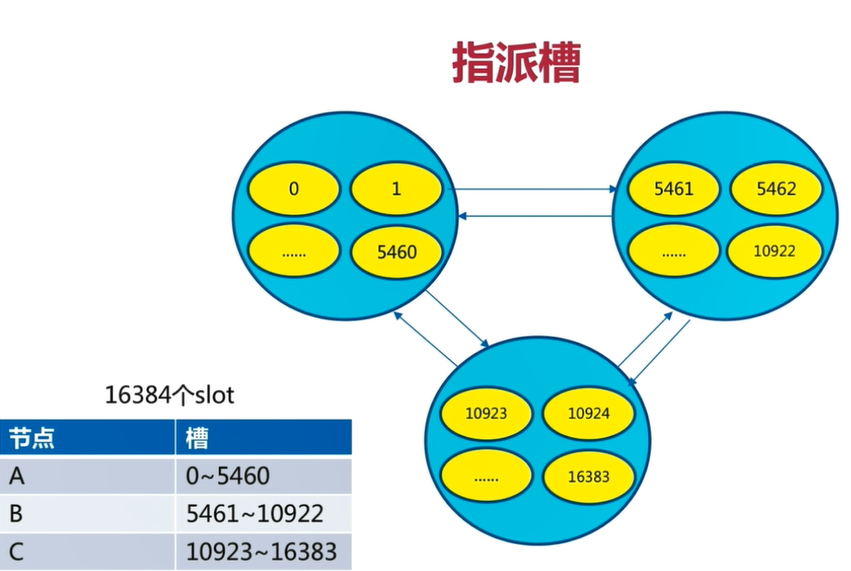
客户端访问任意节点时,对数据 key 按照 CRC16 规则进行 hash 运算,然后将运算结果对 16383 进行取余,如果余数在当前访问的节点管理的槽范围内,则直接返回对应的数据
如果不在当前节点负责管理的槽范围内,则会告诉客户端去哪个节点获取数据,由客户端去正确的节点获取数据。
4)复制
Cluster 自动做 master+slave 的主从复制和读写分离、master+slave 高可用和主备切换、支持多个 master 的 hash slot 即数据分布式存储。
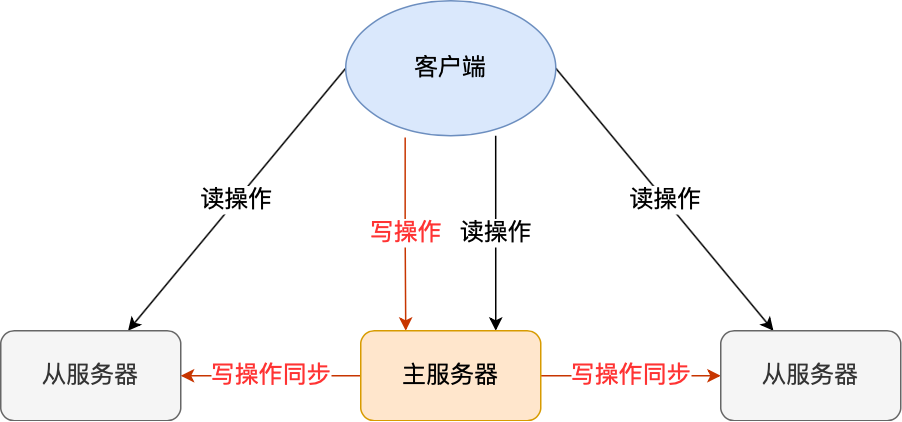
3. 故障转移
集群自动故障转移过程分为故障发现和节点恢复。节点下线分为主观下线和客观下线:
- 当超过半数的主节点(master)认为故障节点为主观下线时,则标记这个节点为客观下线状态。
- 从节点(slave)负责对客观下线的主节点(master)触发故障恢复流程,保证集群的可用性。
节点失效机制:选举
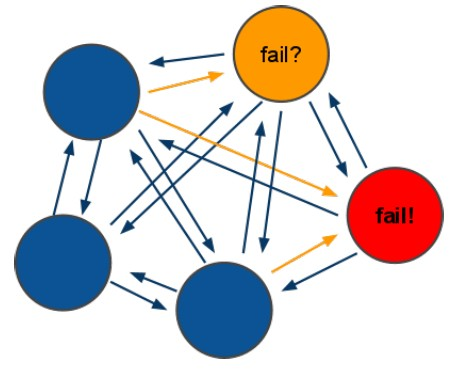
ping/pong 模式
- Redis Cluster 通过 ping/pong 消息实现故障发现。
- ping/pong 不仅能传递节点与槽的对应消息,也能传递其他状态,比如:节点主从状态,节点故障等。
- 故障发现就是通过这种模式来实现,分为主观下线和客观下线。
集群中所有 master 参与投票,如果半数以上 master 节点与其中一个 master 节点通信超时(cluster-node-timeout),则认为该 master 节点挂掉。
什么时候整个集群不可用(cluster_state:fail)?
- 如果集群任意 master 挂掉,且当前 master 没有 slave,则集群进入 fail 状态。也可以理解成集群的 [0-16383] slot 映射不完全时进入 fail 状态。
- 如果集群超过半数以上 master 挂掉,无论是否有 slave,集群进入 fail 状态。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号