正则表达式、编辑器(vi、sed、awk)
1. vi
2. 正则表达式
3. sed
- 1)打印命令:p
- 2)删除命令:d
- 3)替换命令:s
4. awk
- 1)awk 基本用途
- 2)匹配打印
- 3)判断打印
- 4)数组
1. vi
vi 是 Linux 中的标准文本编辑器。所有的 unix 和类 unix 都会提供 vi 编辑器。在 linux 中还可以使用 vim(vi improved)。
vi 提供两种模式:
- 命令模式
- 用于浏览、删除、剪贴、查找等。
- 可以用各种命令进入插入模式。
- 插入模式
- 用于键入内容。
- 用 <ESC> 退出插入模式后回到命令模式。
vi 将命令模式和插入模式区分开来,这经常被认为是 vi 的一个大问题,但往往这也被认为是 vi 的优势所在。理解其中的区别是掌握 vi 的关键。
- vi 启动时处于命令模式。在这种模式下,我们可以在文件中到处移动,改变文本的某个特定区域、剪切、复制和粘贴文本。
- 插入模式是指用户可以真正在文件中输入内容。
进入 vi 的命令
- vi <filename>:打开或新建文件,并将光标置于第一行首。
- vi +n <filename>:打开文件,并将光标置于第 n 行首。
- vi + <filename>:打开文件,并将光标置于最后一行首。
- vi +/pattern <filename>:打开文件,并将光标置于第一个与 pattern 匹配的串处。
- vi -r <filename>:在上次正用 vi 编辑时发生系统崩溃,恢复 filename。
移动操作
移动操作命令繁多,熟练使用以下几个就够应付大部分情况。
- [PgDn]:向下翻一页。
- [PgUp]:向上翻一页。
- gg:回到首行。
- G:到尾行。
- nG:到第 n 行。
- $:到行尾。
- ^:到行首。
- fx:向右到第一个字符 x 处,x 为任意字符。
- Fx:向左到第一个字符 x 处。
删除
- x/<del>:删除一个字符。
- nx:删除下 n 个字符。
- dd:删除当前行。
- dw:删至词尾(并不是删掉该词,因为光标可能不在单词第一个字符)。
- ndw:删除后 n 个词(分割符并不是默认的空格)。
- d$:删除至行尾。
- ndd:删除下 n 行。
复制粘贴
- yy:将光标所在行进行复制。
- nyy:将光标下 n 行进行复制。
- yw:将光标所在词进行复制(可能不是整个词,视光标位置定)。
- y$:将光标所在位置至行尾的部分进行复制。
- p:贴在光标所在行的下一行。
- P:贴在光标所在行的上一行。
从命令模式进入插入模式
- i:光标在当前位置进入插入模式。
- I:光标跳到行首并进入插入模式。
- a: 光标后退一个并进入插入模式。
- A:光变推到行尾并进入插入模式。
- o:在光标所在行下新起一行并进入插入模式。
- O:在光标所在行上新起一行并进入插入模式。
- s:删除光标所在字符并进入插入模式。
- S:删除光标所在行并进入插入模式。
取消操作
- u:取消上一个更改。
- U:取消一行内的所有更改。
- :e!:放弃所有更改,重新编辑(:e! 代表先按:进入命令输入行再按 e 和 !)
查找文本
- /string:向下查找 string。
- ?string:向上超找 string。
- n:继续查找下一个。
命令模式下的输入选项
:r [filepath]:把 filepath 文件的内容插入到光标处。
:r! [command]:把 command 命令的结果插入到光标处。
:! [command]:退出 vi 编辑器执行 command 命令,然后返回 vi 编辑器。
退出、保存
:w:保存当前文件。
:q:如果上次保存后没有修改,退出文件。
:wq:保存退出。
:q!:放弃保存退出。
2. 正则表达式
一个正式表达式是一个字符串。字符串里的字符被称为元字符,它们可能表示了比它们字面上看起来的意思更丰富的含义。例如,一个引用符号可能表示引用一个人演讲中的话,或者表示下面将要讲到的引申表示的意思。正则表达式是一个字符或和元字符组合成的字符集,它们匹配(或指定)一个模式。
正则表达是的主要作用是用来文本搜索和字串操作。一个正则表达式匹配一个字符或是一串字符。
一个正则表达式包含下面一个或多个项:
- 一个字符集:这里的字符集里的字符表示的就是它们字面上的意思。正则表达式最简单的情况就是仅仅由字符集组成,而没有其他的元字符。
- 锚:一个锚指明了正则表达式在一行文本中要匹配的位置,例如 ^ 和 $ 就是锚。
- 修饰符:它们用于展开或缩小(即是修改了)正则表达式匹配文本行的范围。修饰符包括了星号。括号和反斜杠符号。
*(星号)
*:星号表示匹配前一个字符的任意多次(包括零次)。
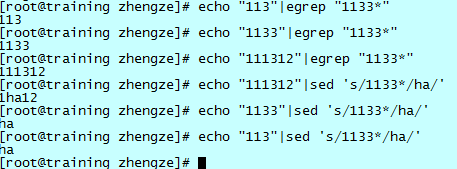
如上图所示,"1133*" 表示匹配:“11”+“一个或更多的 3”+“可能的其他字符”。
注意,“匹配”和“等于”的概念并不相同:
- 匹配(egrep):相当于可以搜索到。
- 等于(sed):相当于可替换。
直接匹配 "*" 没有实际意义,可以理解为匹配任意字符,在实际工作中从来不使用。在很多时候,直接匹配一个字符加上*号也是没有意义的,因为很多时候只会匹配一次“0个该字符”。

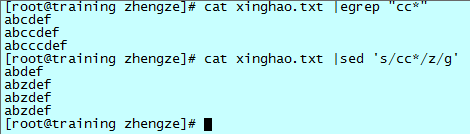
一般需要匹配一个连续的字符串的时候,需要用这样的模式 "cc*",代表匹配了一个 c 和这个 c 之后的任意几个(或 0 个)c。
.(点)
表示匹配除了新行符之外的任意一个字符。
- "13.":表示匹配“13”+“至少一个任意字符(包括空格)”,如匹配 1133、11333,但不匹配 13。
^(脱字符)
表示匹配一行的开头,但依赖于上下文环境,可能在方括号中表示否定。
$(美元符)
表示在正则表达式中匹配行尾。
- "^$":表示匹配空行。
[...](方括号)
表示在正则表达式中表示匹配括号中的一个字符。
- "[xyz]":匹配字符 x、y 或 z。
- "[c-n]":匹配从字符 c 到 n 之间的任意一个字符。
- "[B-Pk-y]":匹配从 B 到 P 或从 k 到 y 的任意一个字符。
- "[a-z0-9]":匹配任意小写字母或数字。
- "[^b-d]":匹配除了从 b 到 d 范围内所有的字符。这是正则表达式中反转意思或取否的一个例子(就好像在别的情形中 ! 字符所扮演的角色)。
- 多个方括号字符集组合使用可以匹配一般的单词和数字模式。如 "[Yy][Ee][Ss]" 表示匹配 yes、Yes、YES、yEs 等。
\(反斜杠)
表示转义(escapes)一个特殊的字符,使这个字符等于原来字面上的意思。
- 如 "\$" 表示了原来的字面意思 "$",而不是在正则表达式中表达的匹配行尾的意思。
- 如 "\\" 也被解释成了字面上的意思 "\"。
转义符用途广泛,不仅仅用于正则上的匹配。在脚本中,有些时候不想让特殊字符立即生效,也需要使用转义符。
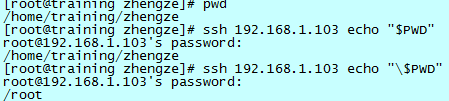
如上图所示,ssh 到 1.103 机器执行 echo “$PWD” 的命令:
- 如果没有转义 $ 符号,该命令在 linux 中执行实际就会是:ssh 192.168.1.103 echo /home/training/zhengze
- 转义之后,该命令在 linux 中执行会是:ssh 192.168.1.103 echo $PWD
\<...\>(转义"尖括号")
表示匹配单词的边界。尖括号必须被转义,因为不这样做的话它们就表示单纯的字面意思。
- 如 "\<the\>" 匹配单词 "the",但不匹配 "them"、"there"、"other" 等。
扩展
以下正则元素是扩展,并不是在所有地方都可以使用。
扩展的正则表达式增加了一些元字符到上面提到的基本的元字符集合里,它们可以在 egrep、awk 和 Perl 中使用。
?(问号)
表示匹配零或一个前面的字符。它一般用于匹配单个字符。
+(加号)
表示匹配一个或多个前面的字符。它的作用和 * 很相似,但唯一的区别是它不匹配零个字符的情况。
\{ \}(转义大括号)
表示匹配前面正则表达式匹配的次数。
如果不转义的话,大括号只是表示他们字面上的意思。这个用法只是技巧上的而不是基本正则表达式的内容。
- "[0-9]\{5\}":精确匹配 5 个数字 (从 0 到 9 的数字)。
注意:大括号不能在“经典”(不是 POSIX 兼容)的正则表达式版本的 awk 中使用。然而,gawk 有一个选项 --re-interval 来允许使用大括号(不必转义)。
bash$ echo 2222 | gawk --re-interval '/2{3}/' 2222
Perl 和一些 egrep 版本也不要求转义大括号。
(...)(圆括号)
括起一组正则表达式. 它和下面要讲的 "|" 操作符或在用 expr 进行子字符串提取(substring extraction)一起使用时很有用。
|(竖线)
类似于编程语言中的"或",用于匹配一组可选的字符。
bash$ egrep 're(a|e)d' misc.txt People who read seem to be better informed than those who do not. The clarinet produces sound by the vibration of its reed.
注意:一些 sed、ed 和 ex 的版本像 GNU 的软件版本一样支持上面描述的扩展正则表达式的版本。
3. sed
sed 是流线型、非交互式编辑器。它允许你执行与 vi 和 ex 编辑器一样的编辑任务。sed 程序不是与编辑器交互式工作的,而是让你在命令行里敲入编辑的命令,然后在屏幕上查看命令输出的结果。
sed 编辑器按一次处理一行的方式来处理文件,并把结果输出到屏幕。
下面介绍 sed 最常用的几种功能,这几种功能可以满足日常 linux 运维需求,但只涵盖了 sed 功能的冰山一角。
1)打印命令:p
按照行号打印
sed <-n> '1<,3>p' file 或者使用管道传递数据 cat file | sed <-n> '1<,3>p'
打印第一行:sed '1p' file.name
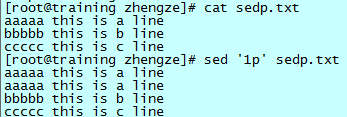
可以看到,sed 把每一行都打印了,但是第一行打印了两遍。p 命令有这个特性,但是这个特性一般是不需要的,所以有 sed -n 这样的用法(-n 参数告诉 sed 只显示出操作的行,一般配合打印命令使用)。

这样,我们仅仅得到了第一行的输出。
打印第 2 行到第 4 行:sed -n '2,4p' file.name
打印匹配行(相当于 egrep)
在引号中的打印命令“p”前,可以放置一对“/”标识符,来代表匹配。形如“/..../”。
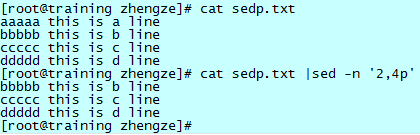
打印 sedp.txt 文件中,含有字母“c”的行:sed -n '/c/p' sedp.txt
打印 sedp.txt 文件中,以“c”开头的行:sed -n '/^c/p' sedp.txt

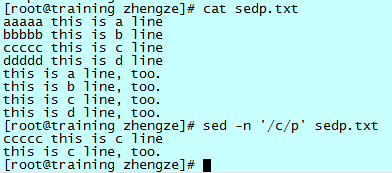
打印 sedp.txt 文件中,含有三个以上连续相同字母的行:
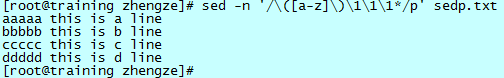
注意:“\(...\)”中的匹配内容将被放置在临时寄存器中,之后对该寄存器的引用为 \1,如果有第二对“\(...\)”,引用则为 \2。这个在替换中经常用到,打印命令一般用不到。
这里,“/.../”中的含义为:匹配任意一个小写字母,并将这个匹配内容放置在寄存器中,然后紧接着匹配和这个字母一样的一个字母、再次匹配一下这个字母,第四次匹配这个字母的时候用了“*”,代表有 0 次或者多次。这样就完成了题干中含有三个以上连续相同字母的匹配。
打印包含“aaaaa”和包含“ccccc”之间的行:
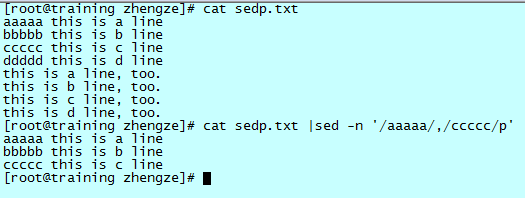
可以看到,“/.../”之间用“,”号分隔,就可以匹配打印从 aaaaa 到 ccccc 的行。
思考:在 sedp.txt 文件中,sed '/a/,/c/p' sedp.txt 会出现什么情况?

匹配都有“贪婪性”,这是操作中应该重点注意的。
- 如果文本中多行出现 a 和 c,贪婪性的动作会把匹配变的不容易预估。整体的原则是,在第一次扫描的 a 后,就向下找 c,找到 c 之前碰到匹配 a 的行并不会从这一行开始,而是仍然从第一次出现 a 的行开始,直到找到 c 的行结束,如果一直未找到 c,那就到尾行结束。
- 如果找到 a 并且找到 c,此时扫描并不结束,会继续向下找 a,重复上述描述过程。所以本例中会打印出除了 ddddd this is d line 以外所有的行。
同样的情况发生在正则中,”^.*c”会匹配到最后一个 c 字母出现的位置,在操作时需要注意。
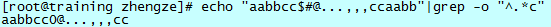
可以看到,匹配在第一个“c”处并没有停止。
2)删除命令:d
在默认情况下,sed 的删除操作并不直接作用于文件本身,而仅仅是在打印的时候不打印匹配的行,有些类似于 grep -v。
如果需要删除操作作用于文件,在有文件写权限的前提下,可以使用 sed -i 参数来使删除操作作用于文件。注意:不是所有的 unix 自带的 sed 工具都有这个功能。
删除指定行
删除第三行:
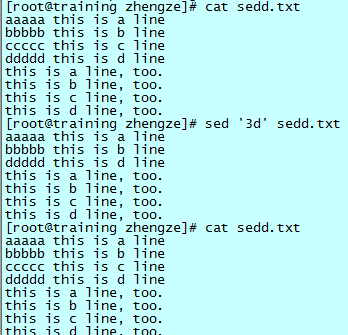
可以看到,sed 命令仅仅是在打印的时候忽略了第三行,实际上并没有删除第三行。
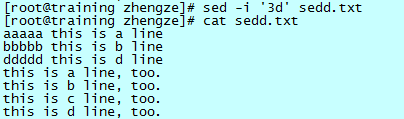
加上 -i 参数后,删除直接作用于文件本身。
注意:
- 在实际操作中,不加 -i 参数反而更加常用。一般的做法是保留原文件,仅仅将 sed 的结果重定向。
- 一般在删除操作中,不加 -n 参数,-n 参数告诉 sed 只显示出操作的行,对于打印命令很有效果,但是对于删除操作,操作的行已经不存在,如果再不显示未操作行,将看不到任何结果。
删除第三到第五行:
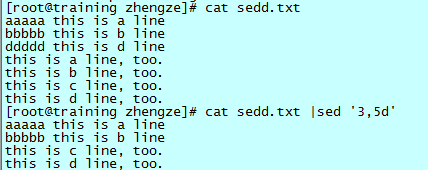
删除匹配行
删除以“this”单词开头的行
文件如下:
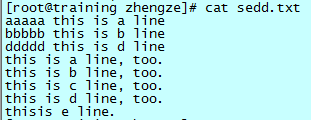
正解如下:(注意看两种方式)
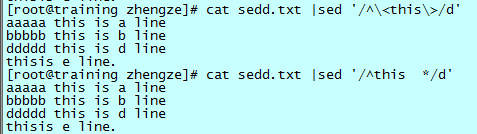
- 第二种写法,首先要在匹配模式中添加开头的锚定符“^”,然后是“this”本身,作为单词,其后要至少有一个空格,于是“ *”。注意空白处为两个空格,就可以表示为一个或者一个以上的空格。一般不要使用“+”,因为不是所有的 sed 都支持扩展的正则表达式。
- 第一种写法,回顾正则中,“\<...\>”表示单词,这个符号将严格的定位一个单词,即 this 这四个字母紧挨在一起,前后都有一个以上空格或者制表符;或者这个单词在一行的开头处,后面跟一个以上空格;或者这个单词在结尾处,前面有一个以上的空格。
在本例中,如果要删除含有 this 单词的行而不使用“\<...\>”的话,正则的写法将要麻烦的多,尤其是在不确定该版本 sed 是否支持扩展正则的情况下,如下所示:

在 sed 中,可以用“;”来分隔若干个命令,这里分隔成三个删除命令,这三个命令依次执行。可以看到,依次匹配了 this 单词开头的情况、中间的情况和结尾的情况。虽然文本中没有 this 结尾的情况,但是如果我们拿到一个特别大的文件,那就无法确认是否有这种的情况。
注意:建议不要使用这种方式,不是特别友好,看起来比较费劲。不如写成 sed '//d'|sed '//d' 的管道形式,虽然多敲了一些字符,但是逻辑更加清晰。并且管道的效率和例子中的写法效率是一样的。
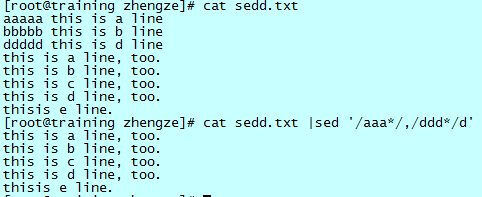
删除连续的 a 和连续的 d 的行以及两者之间的行:
3)替换命令:s
在日常工作中,sed 命令最常用的用途就是替换。其实上面讲到的打印和删除,都可以使用 grep 或者 grep -v 来实现(匹配两行之间的操作不可以)。sed 的其它功能也都可以有替代品,比如删除重复行等;更复杂一些的命令用的很少。虽然 sed 的替换功能可以被 tr 命令代替一部分,但是 tr 命令并不支持正则。于是,sed 在运维人员眼中,甚至仅仅是一个替换命令。
sed的替换可以是字面上的替换,也可以是正则匹配的替换。正则形式出现的替换会更多一些。
下面以一些例子讲解sed的替换用法:
sed 替换的基本格式
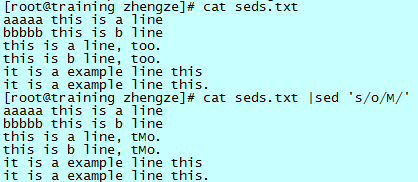
sed 's/old/new/' # 这样就完成了将“old”替换成“new”
如下图,第一个出现的字母 o 替换成了字母 M:
全局替换
如上例所示含有字母 o 的一行,并没有把所有的字母 o 都替换掉。这是因为 sed 默认替换第一个匹配的项,替换一次后结束该行(也可以指定第几个匹配项进行替换)。
如果要把一行内所有的匹配项都替换,需要加全局命令“g”。如下图所示:

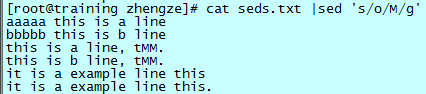
g 是常用命令,大部分替换命令需要用到全局变量。
指定行替换
初步接触替换命令时,觉得和打印命令和删除命令不太一样,无论是“p”或者是“d”都出现在指定的行号后面或者匹配的后面。实际上替换的“s”也是这样的,只不过默认的是对文件全篇进行替换,而不是指定行或者匹配行替换。
指定第三行进行“o”替换成“M”:
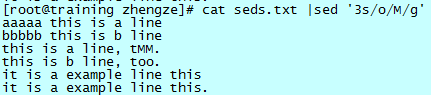
这样看起来熟悉多了,只有第三行的 o 被替换了,注意全局指令的使用。
匹配行替换
仔细观察,发现“a example”是错误的语法,应该是“an example”。这时候用到匹配替换,需要匹配“example”单词,然后将这一行的“example”前的“a”替换成“an”。
请注意,以下几个例子说明了新手容易犯的错误:
先看原文:

错误一:

这个例子中的错误在于:
- 没有考虑到全局命令的使用;
- 没有考虑到 a 的限制。
错误二:

看上去正常工作了,但是实际上因为上下文的偶然关系才正常的。如果这一行中有一句,”it is a cat”,那么,这个“a”也将被替换成“an”。
注意:sed 的匹配模式中支持正则,替换成的目标是不支持正则的。比如“s/.*/.*/”会将把所有内容都换成”.*”。

正确方式:

- 首先匹配 example,因为只有 example 前的 a 出现了问题;
- 然后将“a example”换成“an example”,这样需要匹配”a example”;
- 但是我们并不知道“a”和“example”之间有几个空格,不能想当然的认为是一个,于是匹配变成了“a *example”,这样可以匹配到一个或者多个空格;
- 最后,我们并不想改变修改后的格式,想要和修改前“a”和“example”之间的空格数保持一致,于是我们将“a”后面的匹配内容放到临时的寄存器中,这样在后面的替换目标那一项中,直接使用寄存器中的内容,可以保证“an”和“example”之间的格式与之前一样。
看一个更清楚的例子,保证了最后一行“a”后三个空格没有被改变:
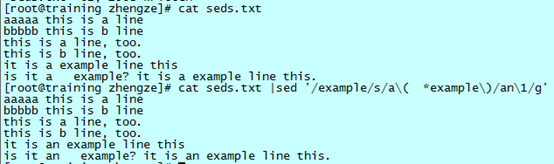
临时寄存器在 sed 的替换功能中经常用到,而且很好用。
匹配行之间的替换
和打印和删除类似,替换也有这样的功能,虽然不常用。
把连续“a”和连续“c”两行以及其之间行的单词“is”换成“was”:
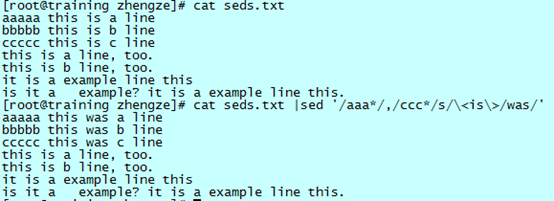
不要忘记了“\< \>”表示锚定一个单词,也不要忘记“s/.../.../”中,第二个代表替换目标的区间不支持正则。
删除某些字符
如删除上述例子中的“too”单词:
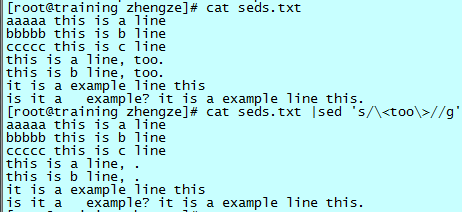
可以看到,替换目标的区域空下来了,也就是把匹配的内容换成“空”。
常用例子
在行首增加“#”

删除行尾的“.”

注意,“.”在匹配的时候需要转义,不然就是正则中的代表任意一个字符。
删除多余的空格

其中,\t 表示一个制表符(tab 键产生),含义是把一个或者多个空格或者制表符换成一个空格。
将连续字母变成一个,并且只显示修改行
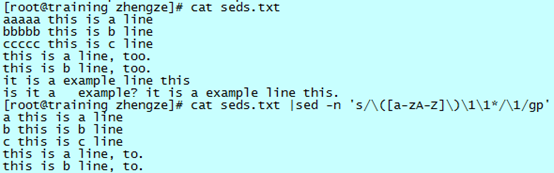
操作流程:
- 替换命令中也是可以禁止输出未改动或者未匹配项的,用 -n 参数,需要再次提醒,使用 -n 参数后,需要加上 p 命令才可以输出匹配或者修改的行;
- 在“s/.../.../”的匹配中,首先锁定某个字母 [a-zA-Z] 就是匹配任意一个字母;
- 然后匹配该字母的连续出现,这个时候使用连续的 [a-zA-Z] 是无法实现的,只能使用临时存储器,将上一个匹配的字母存入,然后使用“\1”再现上一个字母。
使 sed 的修改直接对文件生效
只需增加 -i 参数即可。
注意:在 sed 替换时,不建议直接使用 -i 参数。需要确认结果后再加 -i 参数。
当匹配对象中含有“/”
这在运维工作中经常碰到,一般是需要处理目录路径的时候。
比如,将”/etc”换成”/usr/local/etc”,两种方法:
方法一:通过转义符

这种方法令人费解。
方法二:将”s/.../.../“换成任意字符分割:

实际上,sed 中替换“s”后面可以跟除字母外的任意三个相同字符来做分隔符,甚至数字都可以,但是作为分隔符的符号在匹配和作为替换目标时,必须转移。
sed 博大精深,这里只介绍冰山一角。如果感兴趣,推荐学习 O’REILLY 的《sed & awk》。
4. awk
awk 是用来操作数据和产生报表的一种编程语言。数据可能来自标准输入、一个或者多个文件或者是一个进程的输出。awk 可以用在命令行里用于简单操作,或者可以为了较大的应用而写到程序中。
awk 从第一行到最后一行逐行扫描文件(或输入),并执行选定的操作(封装在花括号里)。比如:
awk <-F string> '<opearate> {print <items>}' filename
最常用的例子:
cat /etc/passwd|awk –F: '/zhangzhe/{print $1}'
含义是查看 /etc/passwd 文件,结果给 awk 处理。首先用“:”代替空格作为分隔符,然后从第一行到最后一行逐行扫描文件,执行匹配“zhangzhe”的操作,如果匹配则执行花括号中的打印第一个域的操作。
awk 的文件是必须存在的,如果没有文件,也可以使用管道传递数据。
awk 是 一门编程语言,作为 unix 工具来使用简化了很多,但是仍然有许多编程语言的特性,可以对目标进行一些列的处理。
可以抽象的理解一下 awk 的处理过程,这个过程和 sed 相当类似。如果抛开 awk 的 BEGIN 和 END(参考《sed & awk》,这两部分是 awk 在读取文件前的操作和完成逐行操作后的操作)。对于文件的每行,awk 分两个阶段处理:
- 读取该行内容,分配临时寄存器,分配域名等操作;
- 对域做各种处理并输出。
也就是说,我们对每一行的操作,实际上有两个部分组成:读入时和读入后。
1)awk 基本用途
awk 的核心概念是“域”,所谓“域”就是把一行字符按照特定的分隔符分成一列列的内容。awk 的操作就是逐行地对每一个域进行操作,以实现类似于二维表格的各种功能。
简单输出
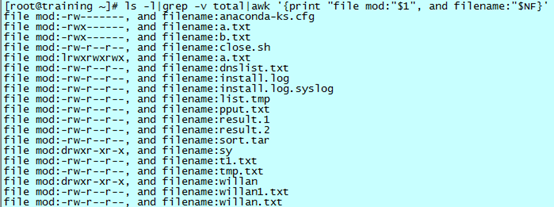
最简单的 awk 操作,就是对每一行都是以空格为分隔符的文件做输出选择。比如 ls -l 的结果,除去第一行后,仅仅想要得到权限情况和文件名。
首先看 ls -l|grep -v 的执行结果:
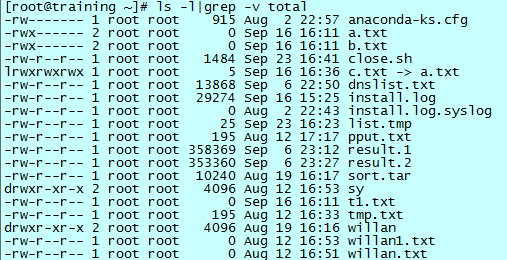
可以看到,每一行被一个或者多个空格(或者制表符)分为 9 部分的内容。每一部分内容就是一个域,awk 中都有一个特定的标识符来表示一个域。
awk 中,默认的分隔符就是一个或者多个空格(或者制表符)。
接下来看执行结果:
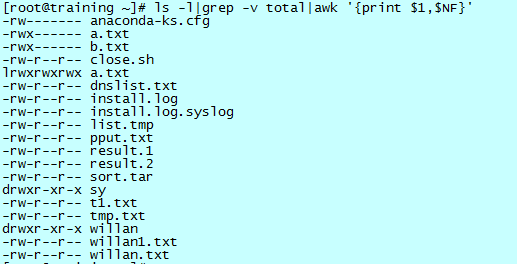
可以看到,结果通过管道被 awk 处理后,只留下了第一列和第九列,语句的具体含义是:
- 花括号前没有任何的语句,说明是默认的对每一行进行操作,而没有任何的限制;
- 花括号中是打印语句,这里打印了 $1 和 $NF。awk 顺序地为每一个域分配域号,$1 代表从左边起第一个域,$2 代表第二个……。也可以从右向左数,$NF 代表最后一个,$NF-1 代表倒数第二个;
- 打印语句中的“,”代表仍然使用默认的分隔符(一个空格)来分隔打印出来的内容。默认的分隔符分为输入和输出两种,输入可以使用“-F”参数来改变,输出的请参考《sed and awk》。
也可以不按照默认的分隔符进行输出,比如:
当然,这并不好看,只是举个例子。print 语句中出现的字符需要引号。字符和数字会被如实打印,域会被打印出实际值。需要注意的是:引号外的空格不会被打印,有没有空格对打印结果没有影响,只是为了程序的可读性而存在。
另外,print 语句中允许出现数学表达式或者一部分函数。简单举例说明,如下图所示:
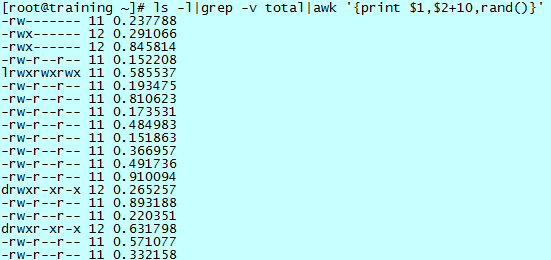
可以看到,除了打印了第一个域,还可以对第二个域做一个简单的运算,awk 会自动识别域中的数字以完成数学运算。
另外,打印语句也可以不针对域,仅仅是一个数学表达式或者函数,比如上图中的随机函数。
实际上,shell 本身不支持浮点运算,因此经常需要使用 awk 的浮点运算,例如:

这里只是给 awk 一个空字符,让其可以顺利执行。
分隔符的艺术
巧妙的改变分隔符,可以完成许多意想不到的任务。
单字符分隔符:打印系统中用户名和其使用的 shell 类型
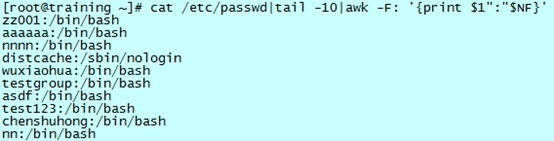
如果使用默认的分隔符,那么 awk 将会把 passwd 这个文件的每一行识别为一个域。修改了分隔符为“:”后,就可以正常的识别每一个域。当然,这时的输出分隔符仍然是空格。
-F 参数后面需要跟内容,有两种写法。当分隔符为单个字符时,可以像例子中那样紧跟着 F 写一个字符;当分隔符为一组字符或者正则表达式或者多个表达式的时候,需要使用引号,并且和 F 之间有个空格。
单字符分隔符:管道连续使用 awk 打印 nginx 日志中的访问目录
在工作中,经常需要取得 nginx 日志中的访问目录情况,例如:

若需要取得“GET”之后,“?”之前的内容,通常做以下操作:

可以看到,连续使用不同分隔符的 awk 操作,很容易实现了这个需求。
分解一下,首先看第一个 awk 完成的工作:

这样一目了然,这个 awk 以“?”为分隔符,直接取得了“?”之前的所有内容。接着第二个 awk 很容易的把目标内容得到。
多字符分隔符:抓取 apache 详细版本
在工作中,会碰到要求检查 apache 版本的情况。不仅仅检查版本号,还要检查安装的版本和当前系统版本是否一致,例如:
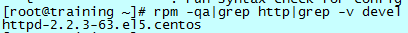
需要取得 2.2.3-63.el5.centos 来做判断,这个时候需要使用多字符的分隔符来完成:

以“httpd-”为分隔符,该分隔符前面有一个空字符串(可以理解为开头”^”),然后需要的结果为第二个域的全部内容。
实际上 awk 自己有匹配功能,可以代替 grep 操作。但是某些时候,grep 操作更方便一些,比如 grep的 -o 参数、-A 参数等。
多字符多个分隔符:截取 ip 地址
在脚本中,获取本机的 ip 地址不是一件容易的事情,尤其是机器使用 dhcp 分配 ip 地址。这个时候只能使用 ifconfig 来确定机器的 ip。

使用 ifconfig 和 grep 语句定位到需要的 ip 地址这一行。当然可以使用多次 awk 来实现,也可以这样做:

可以看到,将“addr:”或“Bcast:”作为分隔符,那么需要的 ip 地址在第二个域中。
注意,需要“|”作为分隔符的时候,需要这样写 -F “\|”。
正则分隔符:截取 ip 地址
如果不仅需要 ip,还需要子网掩码的话,用上例中的方法也可以,不过需要再加上“Mask:”作为第三个分隔符,这样太麻烦。实际上,awk 的分隔符支持正则:

如上图所示,以字母、冒号和空格的组合作为分隔符,可以很容易的数字和点组合的 ip 地址抽取出来。
这里的 [a-zA-Z: ]* 充分的利用了正则的贪婪性,正则会将方括号内的所有元素都尽量多的匹配在一起。对于目标行:

正则会将以下三个内容作为“或关系”的分隔符“ inet addr:”、“ Bcast:”和“ Mask:”,剩余的三个 ip 类型的字串分别占据第二、第三和第四个域。
注意,分隔符的使用原则是:有用的信息外的所有东西,尽量都放进分隔符内。
2)匹配打印
awk 在逐行扫描读入文件时,可以对每一行的内容做出一定的判断和操作。
整行中匹配内容
/etc/passwd 文件中,有系统默认用户和后添加的用户。如果想要查看添加的用户列表,可以根据该行是否有”/home/username”这样的关键字来抓取:

和 sed 一样,awk 的匹配模式也在“/.../”中,这行代码的意思是如果匹配到包含“home”的行,就把该行的第一个域打印出来。
虽然看上去并不是十分准确,比如 sabayon 明显是系统默认的用户,但是基本上可以拿到准确的值。下面会介绍更准确的方法。
可以看到,这个操作实际上代替了 grep home|awk -F: ‘{print $1}’。
反过来,也可以显示系统默认的用户,同样的方法,使用“不匹配”来操作:
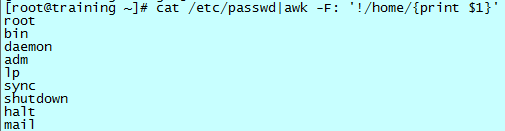
在匹配模式外加一个“!”,为不匹配该模式的行。
注意:awk 和 sed 在这个地方差异很大。sed 的不匹配方式比较特殊,不常用。
sed 的“不匹配”不是在模式前面加”!”,而是在命令前面加”!”。比如:

可以看到,被修改的行是“aa”以外的行。
域匹配内容
除了在正行中搜索匹配内容,也可以对某个域做匹配。在某些时候,很多行都会有目标关键字存在,但是对域进行匹配的话,有可能只有一行可以匹配。比如,想在 /etc/group 文件中找出“zhangzhe”这个组:

“zhangzhe”关键字出现了三回,并没有完全达到预期效果。
注意:awk 中的花括号是可以省略的,省略的话默认打印整行。
这时候需要对域进行匹配:

可以看到,对第一个域进行匹配的话,能找到预期的目标行。
对域进行匹配相当于对一个变量进行匹配操作,需要使用“~”号;上例中花括号省略的内容实际上是 {print $0},$0 代表一整行。
对域的不匹配表达式是:
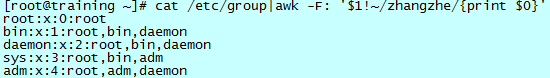
“!”号写在“~”号前面。
3)判断打印
在每一行文件完成读入后,可以对该行内容做一些操作后进行输出。这时候的操作和其它编程语言很类似,尤其是和“c”几乎是一样的。
上一节中域匹配“zhangzhe”的例子仍然可以在此处使用,只是命令写出来不同:

可以看到,匹配操作挪到了“{...}”中,这是读取该行内容后的操作。
在 awk 中,if 语句后紧跟一对“(...)”,其中的语句主要是对域的各种判断,有匹配操作“~”、等于“==”、大于“>”、小于“<”、大于等于”>=”、小于等于“<=”、...。
If 语句后紧跟 print 语句,可以打印满足条件的内容。
如果是想要精确地获得 zhangzhe 这个用户的信息,而不是匹配 zhangzhe 这个用户,需要:

看上去输出没有变化,但是考虑不同点。以下例子为匹配和等于的不同点:

判断的功能主要体现在对数字的处理上:
需要查看 /home 目录中大小超过 10000K 的目录列表
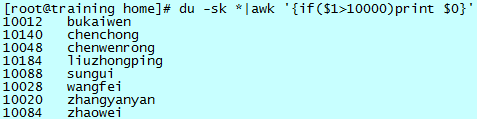
需要准确找到系统后添加的账户名列表
一般系统账户 uid 号从 5000 开始,普通系统用户个数不会超过 50000。

通过 uid 的判断,我们准确的取得了列表。
4)数组
awk 的数组是一种关联数组(Associative Arrays),下标可以是数字和字符串。因无需对数组名和元素提前声明,也无需指定元素个数 ,所以 awk 的数组使用非常灵活。
这里仅对最常用的两个场景做讲解,同时也是 awk 数组最简单的两个用法。
场景一:日志分析中,对来源 ip 进行次数统计
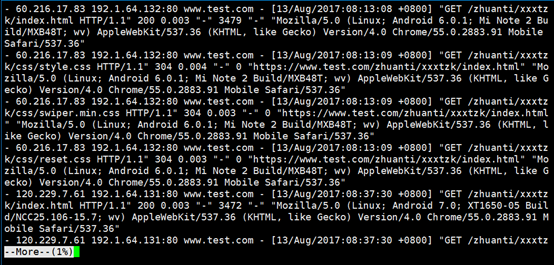
如上图,一段 nginx 访问日志的样例。注意,日志格式根据定义产生,并非所有 nginx 日志都是一样的格式。
根据观察,第二列为来源 IP,现在对来源 IP 访问次数进行统计。
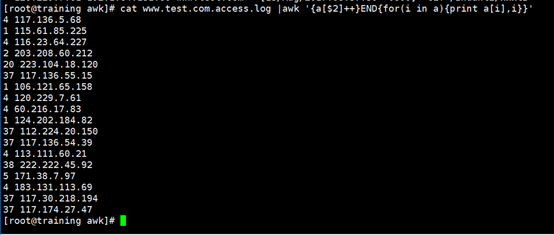
awk 脚本分为三段,命令行格式如下:
awk 'BEGIN{...}{...}END{...}'
在前文中未曾用到 BEGIN 和 END。
BEGIN 中可以更改全局变量、打印一些表头内容;END 中可以打印计算结果、统计等内容。
中间的部分是 awk 逐行扫描计算的过程,如 print、匹配后 print 等都是在这个部分完成打印,因为我们需要知道的就是中间逐行扫描过程中的结果。
数组计算通常是在中间部分进行,但是数组的打印一定是在 END 中。中间部分也可以进行数组的打印,但是打印结果随着不同行的扫描不停的变化,没有实际意义。
cat www.test.com.access.log |awk '{a[$2]++}END{for(i in a){print a[i],i}}'
awk 中数组不需要声明,直接使用。下标可以使数字,可以使字符串。
- 这里我们用第二个域作为下标生成一个数组。
- 以上面图片中出现的 ip 为例,当 awk 扫描第一行的时候,$2=60.216.17.83,同时 a[60.216.17.83] 生成,并执行 a[60.216.17.83]= a[60.216.17.83]+1。数组中的元素,未进行赋值的时候为空,一旦进行数学计算,就直接转化成数字。
- 第一行结束后,a 数组中包含一个元素 a[60.216.17.83]=1
- 第二行扫描,执行 a[60.216.17.83]= a[60.216.17.83]+1,第二行结束后,a 数组中包含一个元素 a[60.216.17.83]= 2
- 第三行、第四行扫描,同上。结束后,a 数组中包含一个元素 a[60.216.17.83]= 4
- 第五行扫描,$2=120.229.7.61,同时 a[120.229.7.61] 生产,并执行 a[120.229.7.61]= a[120.229.7.61]+1。第五行结束后,a 数组中包含两个元素:a[120.229.7.61]=1 和 a[60.216.17.83]= 4
- 依次类推,直到最后一行扫描结束。
- 进入 END 模块打印数组结果:使用 for 循环遍历数组 for(i in a)。此时 i 代表数组中的下标,a[i] 为该下标所代表的数值。使用 print 语句在每一次循环后打印下标(下标为 ip 地址)和数值(数值为访问次数)。
由于统计后数据的行数和长度都已经很精简,可以直接使用 sort 进行排序。awk 本身也可以直接进行排序。两者的效率相仿。
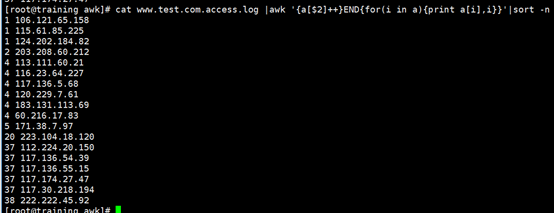
根据上述方法,也可以对访问的 url 次数进行统计,或者浏览器类型出现的次数进行统计,或者是“200”,“404”等状态码出现次数进行统计。甚至可以使用 a[$2$9] 这样的下标,对不同来源 ip 访问 url 的次数进行统计。
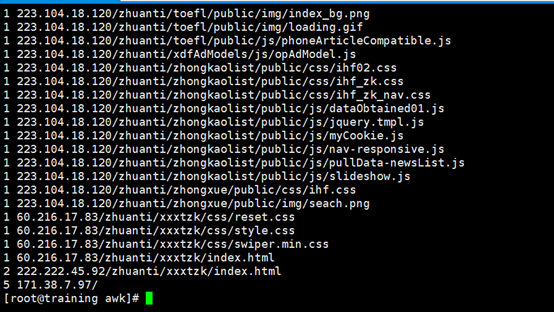
场景二:日志分析中,对某个 ip 访问本网站的流量进行统计
查看日志,我们知道第 14 列是某次访问的流量大小。
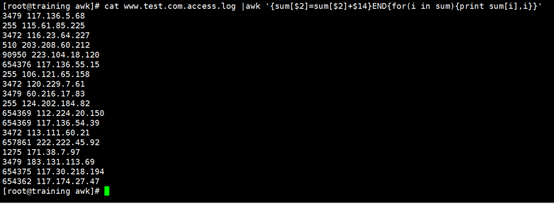
依然使用 $2 为下标,不同的是,这次不再让 a[$2] 自增,而是把 $14 的数字累加上去。整个过程原理和计算 ip 出现次数一样。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号