Linux 用户操作常用命令
人和系统交互的指令集合,构成了 Shell。Shell 面向于用户并内嵌于操作系统,用户通过 Shell 命令指挥操作系统,进而利用硬件资源完成一系列任务。
Shell 分为很多种类,常见的有 csh、ksh 和 bash。CentOS 默认使用 bash。所谓的常用命令,其实就是 shell 中使用率较高的一组命令。
帮助
ls:显示文件目录列表
pwd:显示当前所在目录
cd:切换当前所在路径
mkdir:创建目录
cp:拷贝文件/目录
rm:删除文件/目录
通配符
关机、重启
显示文件内容
|:管道符
wc:查看文件行数、字数
sort:排序
grep:抓取特定字符
find:查找文件/目录
解压缩
date:查看、修改时间
帮助
以下两种方式可以查看指定命令的使用详解:
help <command>
man <command>
ls:显示文件目录列表
ls [-option] <path or filename>
参数:
- -l:长列表,相当于详细列表。
- -a:列出所有文件,包括隐藏文件。
- -t:按照修改时间排列。
- --full-time:显示全时间格式。
- -r:倒序。
- -s:显示文件及文件夹大小。
- -h:以人类能够理解的方式显示。
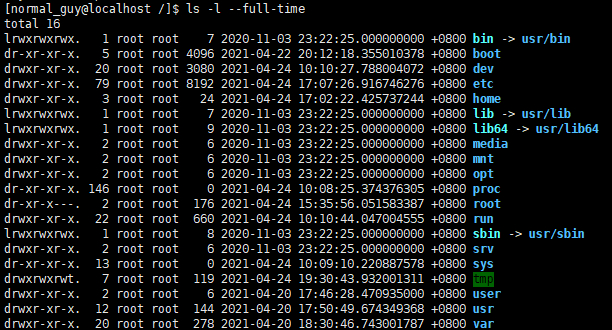
ls -l 详解
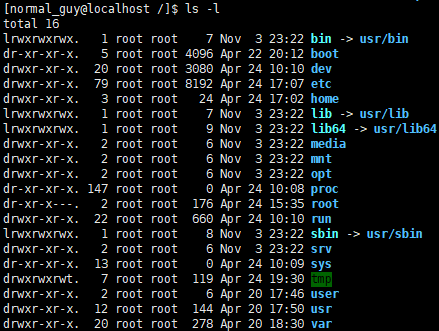
如果使用 ls -lh,就是看起来比较友好的显示。-h 参数在 linux 很多命令里面,都是以“人类能够读懂”的方式显示的意思,主要针对磁盘大小。
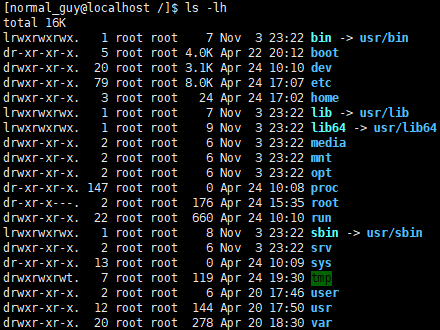
第 1 行:total(总计)
total 后面的数字是指当前目录下所有文件所占用的空间总和。
第 1 字段:文件属性字段
文件属性字段总共有10个字母组成;第一个字符表示文件类型。
- -:表示该文件是一个普通文件。
- d:表示该文件是一个目录,是 dirtectory(目录)的缩写。注意:目录是特殊文件,这个特殊文件存放了其他文件或目录的相关信息。
- l:表示该文件是一个软链接文件。字母"l"是 link(链接)的缩写,类似于 windows下的快捷方式。
- b:表示块设备文件(block),一般置于 /dev 目录下,设备文件是普通文件和程序访问硬件设备的入口,是很特殊的文件。没有文件大小,只有一个主设备号和一个辅设备号。一次传输数据为一整块的被称为块设备,如硬盘、光盘等,最小数据传输单位为一个数据块(通常一个数据块的大小为 512 字节)。
- c:表示该文件是一个字符设备文件(character),一般置于 /dev 目录下,一次传输一个字节的设备被称为字符设备,如键盘、字符终端等,传输数据的最小单位为一个字节。
- p:表示该文件为命令管道文件。与 shell 编程有关的文件。
- s:表示该文件为 sock 文件。与 shell 编程有关的文件。
链接文件分为硬链接或软链接两种。
- 硬链接:多个指向同一文件(硬链接不可以对目录)。硬链接文件大小完全相同,如有多个硬链接,所链接的文件只是一个文件大小。
- 软连接(符号链接):建立一个独立的文件,这个文件会让数据的读取指向它链接的文件内容。类似 windows 快捷方式。
第 1 字段的后 9 个字母表示该文件或目录的权限位。
- r 表示读 (Read)
- w 表示写 (Write)
- x 表示执行 (eXecute)
- - 表明没有该权限。
- 除了 rwx 三种标示,还有 s 标示,称为 SUID 和 GUID,这属于权限的高级应用。
9 个字母中:
- 前三个表示文件拥有者的权限。
- 中间三个表示文件所属组拥有的权限。
- 最后三个表示其他用户拥有的权限。
第 2 字段:分若干种情况
普通文件:第 2 字段表示文件硬链接数。
- 硬链接文件同指向一个文件,无论是修改哪一个文件,另一个里也做相应的变化,即同一文件的不同文件名。
- 互为硬链接的文件具有相同的文件节点。
软连接文件:表示链接占用的节点。
目录:表示子目录个数。
- 如果是目录,则第 2 字段表示该目录所含子目录的个数。
- 新建空目录,此目录的第二字段就是 2,表示该目录下有两个子目录。因为每一个目录都有一个指向它本身的子目录“.”和指向它上级目录的子目录“..”,此默认子目录是隐藏的。每次在目录下新建一个子目录,该目录第 2 字段的值就增 1,但是新建一个普通文件该字段值不增加。
第 3 字段:文件(目录)拥有者
该字段表示该文件拥有者是谁。只有文件的拥有者才具有改动文件属性的权利。root 具有改动任何文件属性的权利。
对于目录,只有拥有该目录的用户,或者具有写权限的用户才有在目录下创建文件的权利。
第 4 字段:文件(目录)拥有者所在的组
一个用户可以加入很多个组,但是其中有一个是主组,就是显示在第 4 字段的名称。
第 5 字段:文件所占用的空间
第 5 字段表示文件大小。如果是目录,表示该目录大小。注意是目录本身大小,而非目录及其下面的文件的总大小。因为目录也是文件,所以目录本身也占空间。由于目录要记录一系列内容,所以空目录的初始大小也为 4096 字节。如果一个目录下的文件及其多,目录大小会超过 4096 字节。
第 6 字段:文件最近访问(修改)时间
ls 默认查看文件的修改(modify)时间。
Linux 系统的文件和目录的时间属性有三种:访问时间(access)、修改时间(modify)和改变属性时间(change)。在 ls 中分别对应 -u、默认、-c。
- access:只看不写的操作,比如cat,headtail、more、vi 等的不保存退出。
- modify:写入操作,比如 vi 修改内容,重定向到文件。
- change:修改文件属性,比如chown,chmod,chgrp 等。
第 7 字段:文件名
如果是符号链接,会有"->"符号,跟着它指向的文件名。
ls -l --full-time 详解
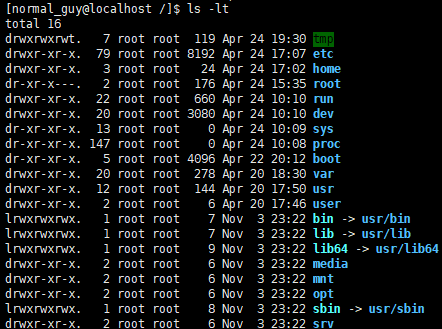
ls -lt:按时间升序排序。如下图所示:
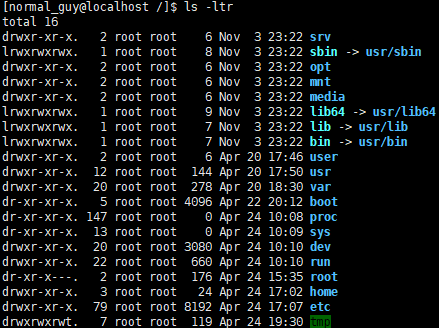
ls -ltr:按时间倒序排序。如下图所示:
问题:时间显示默认是不完整的,如果是本年度的,就会显示月份、日期和时间,如果是往年的,就会显示月份、日期和年份。这样是满足不了特定需求的。
如果加上时间参数,就可以完整的进行对比:
pwd:显示当前所在目录

注意:使用 rm mv chmod chown 这些命令或在对通配符“*”操作时,一定要先 pwd 确认一下路径。
cd:切换当前所在路径
cd [path]
- 绝对路径用法:绝对路径的“绝对”,指的是“/”目录,即从“/”目录开始书写 cd 的参数。比如要进入 /home/training/cd_test 目录,无论在什么目录下,只要如下操作即可。
- 相对路径用法:相对路径的“相对”,指的是当前目录。即:从当前目录跳转到目标目录。
在使用 cd 命令前,往往希望知道自己在什么位置。比如,当前已经在 /home/training/cd_test/dir11/ 这个目录下,那前往 /home/trainng/cd_test/dir12/dir21/ 这个目录用相对路径就很方便;另一种情况,当前在 /root/ 下,还是同一个目标,那当然还是绝对路径来的快一些。
- 从当前目录到上一级目录:cd ..
- 从当前目录到下一级目录:先 ls 查看,或者使用“tab”键。
- “/”和”//”效果是一样的。有时候不小心多敲了一个“/”没有关系。
- 在 cd 命令中,末尾的”/”可有可无。一般按“tab”键会把末尾的”/”补全。
”tab”键是 bash shell 的补全键、自动填充键,在任何涉及路径和文件名的地方都可以使用“tab”键。单击“tab”键为补全,在单击未能补全目录名称(没有列出到/结束)或者文件名称(显示出完整的文件名,并且空一格)的时候,双击“tab”键可以列出分支选择(前半部路径或名称相同、后半部不同的情况)。
回到家目录:
cd ~
或
cd
回到上一次停留的目录:
cd -
mkdir:创建目录
mkdir [-option] <directory>
- -p:如果父目录不存在,不报错,直接建立父目录。
cp:拷贝文件/目录
cp [-option] <source destination>
- -i:交互模式。
- -r:递归拷贝。
- -p:保持文件读写属性、拥有者属性。注意执行 -p 的用户要有足够的权限,否则无法保持文件夹的所有者属性。此命令一般是 root 用户操作。
- -u:增量拷贝。
危险命令 cp
cp 命令在执行的时候有一定的风险。如果目标目录中和源目录中有同名的文件存在,而在执行前没有确认的话,目标目录的文件会被覆盖,从而丢失。
鉴于此,redhat 各个发行版本在 cp 命令上做了小小的手脚。使用 alias,使”/bin/cp -i”命令代替“/bin/cp”命令。所以在系统中执行 cp 命令,实际上默认带有 -i 参数。
[root@localhost cp_test]# cp dir1/a.txt dir2/ cp: overwrite `dir2/a.txt'? no
注意:例如 cp dir1/a.txt dir2/ 结尾处的“/”是好习惯,虽然结尾处有没有“/”都不影响结果,但是在实际操作中,有这个“/”,尤其是 tab 键自动填充的,可以让人更加确认此次 cp 的准确性。
cp -u 参数
1)执行不带 -u 参数的 cp 命令:
[root@localhost cp_test]# cp dir1/* dir2/ cp: overwrite `dir2/a'? yes cp: overwrite `dir2/b'? yes cp: overwrite `dir2/c'? yes
可以看到提示三次是否覆盖。即:文件即使相同,也会执行覆盖操作。这在大量文件重复的情况下会耗费机器资源。
2)执行带 -u 参数的 cp 命令:
首先在源目录中的文件(如文件 c)中添加一些内容,然后执行 cp -u 命令:
[root@localhost cp_test]# echo "c" > dir1/c [root@localhost cp_test]# cp -u dir1/* dir2/ cp: overwrite `dir2/c'? yes
可以看到,只有 c 文件被覆盖,其它两个文件由于内容一致,没有执行覆盖操作。
3)如果目标目录中的文件被修改,然后执行该命令会如何?
[root@localhost cp_test]# echo "a" >dir2/a [root@localhost cp_test]# cp -u dir1/* dir2/ [root@localhost cp_test]#
可以看到,无任何反应,因为-u参数意味着update,只有源文件比目标文件新,才会覆盖目标文件。
注意:考虑在同一目录下,连续两次执行“cp 源文件 目标文件”,和连续两次执行“cp 源目录 目标目录”有什么区别?
这个是 shell 的特性,无论是在 cp、mv 还是在 scp、rsync 等有复制、挪动操作的命令中:
- 如果 destination(也就是后一个参数)并不存在,那么认为把 source 拷贝或者改名到 destination;
- 如果 destination 存在并且是一个文件,那么 source 也必须是文件,并且 destination 会被 source 覆盖;
- 如果 destination 存在并且是一个目录,那么 source 可以是文件也可以是目录,但是 destination 不会被 source 覆盖,只会出现 source 被拷贝到 destination 目录下的情况。
rm:删除文件/目录
rm [-option] <path or file_name>
- -I:交互参数。
- -r:递归。rm 命令默认不允许删除目录,所以如果需要删除目录,则要加上递归参数 -r。
- -f:强制删除。
rm 命令也是危险命令,所以 linux 使用 alias 使其执行时,默认使用 -i 参数,这样在删除时总会有询问。
删除大量文件时或者目录时,不可能每个文件都敲击 yes,所以要使用 -f 参数,这样可以避免询问。很经典也很危险的用法:rm –rf *(切记在使用前先确认目录)。
通配符
通配符不是命令,只是用来匹配文件名和目录的。通配符在 ls、cp、mv、scp、rsync、chown、chmod 等命令中都有强大的作用。
通配符的作用可以用一句话来形容:没有做不到,只有想不到。灵活的运用通配符,可以使很多工作立刻简单。
强大的“*”
“*”在通配符中是最常用的一种,其代表 0 个、一个或多个字符。在使用中有三种情况,表示三种不同的含义。
单独的“*”
这里指的是只有“*”出现的情况,默认为单独的一个,当然连续敲两个以上的“*”效果是一样的。具体点儿说就是“*”没有和其它字符联合起来(表示目录的“/”除外)。这种情况,通配的是该目录下的所有非隐藏内容,包括非隐藏的目录和非隐藏的文件。
看以下三条命令产生的效果:
温习一下 ls 命令,ls 命令在没有跟目录或者文件的时候,默认的操作就是“ls .”,即对当前目录做 list 命令。
当操作 ls * 的时候,相当于 ls 当前目录下的所有内容,ls 会自动的先列出文件,然后按照顺序显示每个目录下的内容。
可以看到,ls *和ls dir1 dir2 file1 file2效果是一样的。
[normal_guy@localhost ~]$ ls a b [normal_guy@localhost ~]$ ls * a b [normal_guy@localhost ~]$ ls a b a b
注意:“*”单独出现匹配目录下所有内容的用途十分广泛,用起来也很方便。但是这是个危险操作,操作时一定要“pwd”确认当前目录,或者使用绝对路径,再或者使用至少一级的可以确定目录路径的相对路径(比如 rm –rf training/* 就很安全,因为知道 training 是自己建立的;但是 rm –rf conf/* 就很危险,系统中有很多 conf 目录)。
rm –rf *、mv *、chmod *、chown * 这些命令,如果执行路径不对,而且执行者是 root,那么都可以造成系统崩溃。
“.*”的使用
单独的“*”表示该目录下所有内容,而“.*”表示的是该目录下所有的隐藏文件和目录以及”.”和”..”。可以尝试执行 ls ~/.*

各种字符和“*”配合使用
一旦出现“*”和字符在一起的情况,“*”就代表这匹配 0 个、一个和多个任意字符的意思,字符和“*”在一起代表 0 个、一个或者多个文件或目录。
比如,在一个日志目录中,目录类型有 access 和 error 两种,所有日志都以日期-时间命名,形如:
access.20120804-6.log access.20120805-19.log error.20120804-0.log error.20120804-22.log error.20120805-13.log
现在需要列出 2012 年 8 月 4 日的 access 日志,则可使用命令如下:
[root@localhost date_dir]# ls -al access.20120804*log -rw-r--r-- 1 root root 0 Aug 9 23:16 access.20120804-0.log -rw-r--r-- 1 root root 0 Aug 9 23:16 access.20120804-10.log -rw-r--r-- 1 root root 0 Aug 9 23:16 access.20120804-11.log -rw-r--r-- 1 root root 0 Aug 9 23:16 access.20120804-12.log -rw-r--r-- 1 root root 0 Aug 9 23:16 access.20120804-13.log -rw-r--r-- 1 root root 0 Aug 9 23:16 access.20120804-14.log -rw-r--r-- 1 root root 0 Aug 9 23:16 access.20120804-15.log -rw-r--r-- 1 root root 0 Aug 9 23:16 access.20120804-16.log -rw-r--r-- 1 root root 0 Aug 9 23:16 access.20120804-17.log -rw-r--r-- 1 root root 0 Aug 9 23:16 access.20120804-18.log -rw-r--r-- 1 root root 0 Aug 9 23:16 access.20120804-19.log ……
也可以拷贝所有2012年的日志:“cp *2012* /destination”。
或者把所有年份月份 14 日当天的日志列出。这个就稍微复杂,需要分析文件名称,由于小时的位置也会出现 14,所以这里的通配不能简单地使用“*14*”,会列出来类似于 access.20120815-14.log 这样的日志。应该使用这样的匹配方法“*14-*”,以避免日期和小时上的混淆,这里使用了日期后面带有“-”的特点。
神奇的“[ ]”
“*”通配不是在所有的时候都好用的,比如需要 8 月 4 日 10-16 点的日志,如果用“*”来通配,总会少一些或者多一些文件,这个时候就用到“[ ]”。
匹配特定的多个字符
[acm] 表示匹配“a”、“c”、“m”中的任意一个,也可以写做 [a,c,m],比如挑出以字母 a,c,m 开头的文件:
[root@localhost letter_dir]# ls
a.txt c.txt e.txt g.txt i.txt k.txt m.txt o.txt q.txt s.txt u.txt w.txt y.txt
b.txt d.txt f.txt h.txt j.txt l.txt n.txt p.txt r.txt t.txt v.txt x.txt z.txt
[root@localhost letter_dir]# ls [a,c,m].txt
a.txt c.txt m.txt
[root@localhost letter_dir]# ls [acm].txt
a.txt c.txt m.txt
[035] 表示匹配“0”、“3”、“5”中的任意一个,也可以写作 [0,3,5],比如,挑出 0 时、3 时、5 时的日志:
[root@localhost date_dir]# ls *-[0,3,5].log access.20120804-0.log access.20120805-0.log access.20120814-0.log access.20120815-0.log error.20120804-0.log error.20120805-0.log access.20120804-3.log access.20120805-3.log access.20120814-3.log access.20120815-3.log error.20120804-3.log error.20120805-3.log access.20120804-5.log access.20120805-5.log access.20120814-5.log access.20120815-5.log error.20120804-5.log error.20120805-5.log
注意:这里 [ ] 中不能出现双位以上的数字,比如 [0,15]。这种情况下shell会认为需要匹配 [0,1,5]。如果需要 0 点和 15 点的数据,只能分开执行或者使用特殊方法利用正则表达式。
匹配连续数字或字母的用法
连续的数字或者字母,用 [2-9] 和 [a-z] 这样的方式表示,其含义是匹配 2 到 9 中的任意一个数字和 a 到 z 中的任意一个字母。
注意:和上面提到的情况类似,这里“-”两边只能是一个字符,比如 0、3、9、a 等,不能是 10、13 这样的双位或者更多位数字。如果写成 [10-23],shell会认为需要匹配“1,0-2,3”这四个数字。
像本节开头所描述那样,需要 8 月 4 日 10-16 点的日志:
[root@localhost date_dir]# ls *0804-1[0-6].log access.20120804-10.log access.20120804-12.log access.20120804-14.log access.20120804-16.log error.20120804-11.log error.20120804-13.log error.20120804-15.log access.20120804-11.log access.20120804-13.log access.20120804-15.log error.20120804-10.log error.20120804-12.log error.20120804-14.log error.20120804-16.log
很少使用的“?”
虽然“?”匹配任意一个字符的功能很强大,但是在实际使用中很少见。
某个目录中有以数字命名的文件,其名字位数不同,找出由两位数字组成的文件:
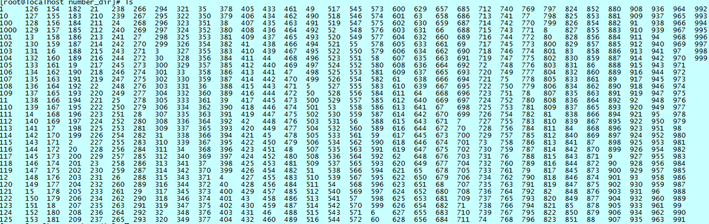
[root@localhost number_dir]# ls ?? 10 13 16 19 22 25 28 31 34 37 40 43 46 49 52 55 58 61 64 67 70 73 76 79 82 85 88 91 94 97 11 14 17 20 23 26 29 32 35 38 41 44 47 50 53 56 59 62 65 68 71 74 77 80 83 86 89 92 95 98 12 15 18 21 24 27 30 33 36 39 42 45 48 51 54 57 60 63 66 69 72 75 78 81 84 87 90 93 96 99
关机、重启
关机:
shutdown [option]
- shutdown –k now:在所有终端屏幕上显示马上要关机,但是实际上不关机。-k 参数不真正关机。
- shutdown –h now:在所有终端上显示马上要关机,实际上也立即关机。
- shutdown –h 5:在所有终端上显示 5 分钟后关机,实际上 5 分钟后关机。
重启:
reboot
立即执行重启操作。
显示文件内容
cat:查看文件内容
cat [-option] <filename>
- -n:显示行号
该一次全部显示整个文件,对于大文件不推荐使用(可能会出现太吃内存而导致死机、崩溃)。
more:分页显示文件内容
more filename
分页显示文件内容,空格翻页。more 有很强大的功能,但是一般情况,使用这些功能远不如 vi 舒服。经常在管道符后面使用 more,用来分页显示管道传递的数据。
head:显示头部命令
head [-option] <filename>
- head -1 filename:显示第一行。
- head -2 filename:显示前两行。
- head -n -10 filename:查询日志文件除了最后 10 行的其他所有日志。
tail:显示尾部命令
tail [-option] <filename>
- -f 实时显示文件内容。
示例:
- tail -1 filename:显示最后一行。
- tail -2 filename:显示后两行内容。
- tail -n 10 filename:查询日志尾部最后 10 行的日志。
- tail -n +10 filename:查询 10 行之后的所有日志。
- tail -f filename:实时显示文件最后内容,常用于查看日志。
- tail -f 10 filename:实时显示文件最后10 行 内容。
|:管道符
管道可以把一组命令按照数据流向的方式进行操作。简单地说,第一个命令执行后,不回显结果,而把结果通过管道传递给第二个命令。第二个命令处理以后传递给第三个……直到没有管道符后才中止命令,并回显最终结果。
比如:ls -alt 按照时间对目录内容排序,但是文件很多,现在只需要关心最新的 5 个文件:
[root@localhost date_dir]# ls -lt |head -6 total 16 -rw-r--r-- 1 root root 0 Aug 9 23:27 access.20120815-0.log -rw-r--r-- 1 root root 0 Aug 9 23:27 access.20120815-10.log -rw-r--r-- 1 root root 0 Aug 9 23:27 access.20120815-11.log -rw-r--r-- 1 root root 0 Aug 9 23:27 access.20120815-12.log -rw-r--r-- 1 root root 0 Aug 9 23:27 access.20120815-13.log
这里因为 ls -lt 会显示一行 total,所以要查看前 6 行,才能看到 5 行数据。
管道命令很强大,可以使用不同的命令组合成强大的指令集合。比如对文件夹下所有以 txt 结尾的文件重命名,就需要三个管道符号,四个命令完成。
wc:查看文件行数、字数
wc [-option] filename
- wc -l filename:查看文本文件行数。
- wc -w filename:查看文本文件单词数。
- wc -c filename:查看文本文件字符数。
注意:实际上 wc -l 常用于管道传来的数据,用来统计行数。比如统计一下日志目录中 access 日志有几条:
[root@localhost date_dir]# ls -l access*|wc -l 96
sort:排序
sort [-option] <filename>
参数:
- -n:以数字顺序排序。
- -r:倒序。
- -u:剔除重复。
- -k:指定排序的列,默认为第一列。
- -t:指定列间的分隔符,默认为空格(不支持复杂分隔符,比如“::”)。
以数字顺序排序的意义在于,sort 默认的只是考察第一位字符,这样会出现以下情况:
[root@localhost sort_test]# cat test.txt 1 a 3 j 6 j 9 l 10 oi 14 asd 6 j [root@localhost sort_test]# sort test.txt 10 oi 14 asd 1 a 3 j 6 j 6 j 9 l
可以看到,虽然是正序的,但是 10 却在 1 的前面。因此需要 -n 参数,-n 参数也是最常用的 sort 参数:
[root@localhost sort_test]# sort -n test.txt 1 a 3 j 6 j 6 j 9 l 10 oi 14 asd
-r 参数为倒序,-u 参数为剔重:
[root@localhost sort_test]# sort -nru test.txt 14 asd 10 oi 9 l 6 j 3 j 1 a
可以看到整个排序从大到小了,而且 6 j 只剩下一行了。
-t 参数可以指定分隔符,虽然不支持复杂的分隔符,但是可以处理复杂分割符为简单分割符。而且也可以想办法使复杂分隔符不影响排序。
-k 参数指定需要排序的列,经常和 -t 参数配合。原因在于,如果是对第一列排序,那无所谓什么样的分隔符,都可以正确排序。
[root@localhost sort_test]# cat test2.txt 1::a 3::j 6::j 9::l 10::oi 14::asd 6::j [root@localhost sort_test]# sort -t ':' -k 2 test2.txt 1::a 14::asd 3::j 6::j 6::j 9::l 10::oi [root@localhost sort_test]# sort -t ':' -k 3 test2.txt 1::a 14::asd 3::j 6::j 6::j 9::l 10::oi
如上述结果,不难发现,-k 2 和 -k 3 都起到了同样的效果,都对第二列进行了排序。因为以“:”分隔,实际上字母在第三个位置。但是第二个位置都是相同的空字符,排序自然以第三列进行。
在实际使用中,sort 也经常接到来自于管道的数据。比如,du 计算文件和目录大小的命令(du 计算目录和其下文件的总大小),就可以用 sort 排序。
[root@localhost dir_size]# du -sk *|sort -nr 6740 b4.txt 580 b3.txt 48 b1.txt 4 c2 4 c1 4 b2.txt
grep:抓取特定字符
grep [-option] <string> <filename>
- -E:扩展的 grep,支持复杂正则。
- -F:完全关闭正则。
- -v:显示不匹配的项。
- -i:不区分大小写。
- -o:只显示匹配内容。
- -r:递归参数。在遇到目录的时候会自动的进入目录并查找该目录下的所有文件和目录。
grep 命令可以把注意力集中在想要的结果上,是强大的工具,尤其是开启 -E 参数以后,利用正则更是可以代替很多 shell script、sed、awk 的功能,会是日常工作出现率很高的命令。
如下所示,我们只想看到 test.txt 文件中有 shell 那一行:
[root@localhost grep_test]# cat test.txt
linux training
shell study
awk study
sed study
apache training
rpm make
trainer zhangzhe
[root@localhost grep_test]# grep shell test.txt
shell study
grep 和通配符“*”使用,再配合上 -r -i 参数,是查找利器。如下所示,我们要在 apache 的配置文件中查找 Listen(监听的端口)。
[root@localhost httpd]# pwd /etc/httpd [root@localhost httpd]# ls conf conf.d logs modules run [root@localhost httpd]# grep -ri Listen * conf/httpd.conf:# Listen: Allows you to bind Apache to specific IP addresses and/or conf/httpd.conf:# Change this to Listen on specific IP addresses as shown below to conf/httpd.conf:#Listen 12.34.56.78:80 conf/httpd.conf:Listen 80 conf.d/proxy_ajp.conf:# Tomcat is configured to listen on port 8009 for AJP requests Binary file modules/mod_cgid.so matches Binary file modules/mod_proxy_ftp.so matches Binary file modules/mod_info.so matches Binary file modules/libphp5.so matches Binary file modules/libphp5-zts.so matches
上面的 5 个目录中全部是配置文件,在不熟悉 apache 情况下,无从得知 Listen 参数会在哪个目录的哪个文件中,但是我们递归的查找所有目录,就很容易找到。
-v 参数(显示不匹配的项)在某些场合特别有用。如 apache 的主配置文件中的大量注释信息确实不需要看,-v 在这种时候十分必要:
[root@localhost httpd]# cat /etc/httpd/conf/httpd.conf |wc -l 991 [root@localhost httpd]# cat /etc/httpd/conf/httpd.conf |grep -v "#"|wc -l 317 [root@localhost httpd]# cat /etc/httpd/conf/httpd.conf |grep -v "#"|grep -v "^ *$"|wc -l 222
可以看到,如果不剔除注释行和空行,阅读到的内容大部分会是无用的信息。”^ *$”是空行的含义。
-o 参数(只显示匹配内容)在 shell 编程中用途较大。比如在特定的文件中,有一系列特定的字符,想把这个字符传递给某个参数,这时候需要用到 -o 参数:
[root@localhost grep_test]# cat test.txt linux training shell study awk study sed study apache training rpm make trainer zhangzhe [root@localhost grep_test]# cat test.txt |grep training linux training apache training [root@localhost grep_test]# cat test.txt |grep -o training training training [root@localhost grep_test]# cat test.txt |grep -o training|sort -u training
如上述结果,在 test.txt 文件中想要提出 training 字符,仅仅 grep 该字符,会出来两行内容,使用 -o 参数后,就会将想要的字符显示出来。然后再处理一下,就可以成为传递给变量的数值。
-E 参数也可以写成 egrep,表示支持复杂正则。
-F 参数也可以写成 fgrep,表示完全关闭正则。
[root@localhost grep_test]# cat fgrep.txt aaaaa fffff sssss fffff ..... qqqqq [root@localhost grep_test]# cat fgrep.txt |fgrep . ..... qqqqq [root@localhost grep_test]# cat fgrep.txt |grep . aaaaa fffff sssss fffff ..... qqqqq
.在正则中代表任意一个字符,如果没有使用 fgrep,grep 管道传来的数据,所有行都可以显示,使用 fgrep 后,仅仅显示有“.”的行。请看下面的效果:
[root@localhost grep_test]# cat fgrep.txt |grep "\." ..... qqqqq
经过转义后,“.”不再具有特殊含义。
find:查找文件/目录
find <path> [-option] <string>
find 命令功能强大,参数复杂,下面介绍几种固定的用法。
按照文件名查找
[root@localhost training]# find /home/training/ -name "test*" /home/training/sort_test/test2.txt /home/training/sort_test/test.txt /home/training/grep_test/test.txt /home/training/tongpei/test
路径位置可以写绝对路径、也可以使用相对路径。-name 参数可以按照文件或者目录名称查找,名称支持通配。
按照文件类型和时间查找
[root@localhost training]# find /home/training/ -type f -ctime -1 /home/training/sort_test/test2.txt /home/training/sort_test/test.txt /home/training/grep_test/test.txt /home/training/grep_test/fgrep.txt
查找一天以内修改的文件。-tpye f 代表文件,-type d 代表目录,-ctime 代表修改时间(以天为单位),-1 说明是一天以前(计时时间点是当天凌晨,也就是从昨天的凌晨开始计算)。
[root@localhost training]# find /home/training/ -type d -cmin +1440 -name "dir2*" /home/training/ls_test/dir2 /home/training/cp_test/dir2 /home/training/cd_test/dir11/dir23 /home/training/tongpei/test/dir2
上述示例中,-type d 为目录,-cmin 指修改时间(以分钟为单位),+1440 是 1440 分钟以前的,另外加上 -name 的限制。
find 功能强大,支持各种类型的查找,上面举例了按名字、按时间,也可以按照大小、按照用户等等,而且都可以组合。
执行后续操作
find 除了可以查找外,还可以执行后续操作,比如删除。这个功能提供了很大的便利。
举例说明:日志文件是需要定时删除的,如果保留 30 天的文件,就删除 30 天以前的。假使 find 没有后续操作过程,可能仅仅列出文件仍然让人头疼,数量巨大且目录复杂的文件时无法快速处理的。
[root@localhost training]# find ./ -mtime +30 ./ls_test/dir_time/a10 ./rm_test/find.txt [root@localhost training]# find ./ -mtime +30 -exec rm -rf {} \; [root@localhost training]# find ./ -mtime +30 [root@localhost training]#
-exec 参数说明要执行后续操作;rm –rf 为操作命令;{} 为固定用法,表示将前面 find 的内容作为入参;“\;” 为固定用法,必须有才可以执行。
解压缩
tar
tar 压缩命令常用于包含文件夹的压缩,比如整体项目的挪动。
tar [-options] <new_filename> <file/directory>
- -f:使用文件输入或者输出。
- -v:显示压缩过程。
- -z:加入 zip 压缩。
- -x:解压。
- -c:压缩。
注意:-f 参数必须有,不然会出现错误。
示例:压缩
[root@localhost training]# tar -zcvf ls_test.tar.gz ls_test/ ls_test/ ls_test/slink.txt ls_test/dir_time/ ls_test/dir_time/a54 ls_test/dir_time/a53 ls_test/dir_time/a21 ls_test/dir_time/a45 ls_test/dir_time/a28 ...... [root@localhost training]# ll total 2348 drwxr-xr-x 6 root root 4096 Aug 8 23:58 cd_test drwxr-xr-x 4 root root 4096 Aug 9 21:34 cp_test drwxr-xr-x 2 root root 4096 Aug 11 11:20 grep_test drwxr-xr-x 6 root root 4096 Aug 8 17:57 ls_test
......
压缩命令的参数后面先写将要生成的文件名称,可以带路径。然后跟要压缩的内容,这里可以是文件、目录、或者多个文件和目录的组合。压缩后,压缩文件生成,原有文件或目录不变化。
示例:解压
[root@localhost training]# cp ls_test.tar.gz /tmp/ [root@localhost training]# cd /tmp/ [root@localhost tmp]# tar -zxvf ls_test.tar.gz ls_test/ ls_test/slink.txt ls_test/dir_time/ ls_test/dir_time/a54 ls_test/dir_time/a53 ......
解压后,目录和文件结构和压缩以前一样。也可以在原有目录解压缩,这样会覆盖原有目录。
另外,tar 解压对文件扩展名不敏感,只要文件是 tar 类型(可用 file 命令查看文件类型)即可解压。
gzip
gzip 压缩常用于单个文件的压缩,比如:日志文件的压缩。
gzip <filename> # 压缩
gunzip <filename> # 解压
示例:压缩
[root@localhost zip_test]# ls 10.txt 1.txt 2.txt 3.txt 4.txt 5.txt 6.txt 7.txt 8.txt 9.txt dir
[root@localhost zip_test]# gzip * gzip: dir is a directory -- ignored
[root@localhost zip_test]# ls 10.txt.gz 1.txt.gz 2.txt.gz 3.txt.gz 4.txt.gz 5.txt.gz 6.txt.gz 7.txt.gz 8.txt.gz 9.txt.gz dir
可以看到,gzip 压缩对文件夹没有效果,只对文件生效。而且压缩后重命名文件,源文件不保留。
注意:这种特性对日志压缩很有用,压缩后没有原文件意味着空间的释放。不需要再执行删除原文件的操作。
示例:解压
[root@localhost zip_test]# gunzip * gunzip: dir is a directory -- ignored [root@localhost zip_test]# ls 10.txt 1.txt 2.txt 3.txt 4.txt 5.txt 6.txt 7.txt 8.txt 9.txt dir
gunzip 对文件扩展名敏感,需要是 .gz 的文件才能进行解压。
另外,gzip 可以利用 zcat 文件来直接读取压缩后的文件内容,而不需要解开压缩。这也是 gzip 成为日志备份首选的重要原因。
date:查看、修改时间
[root@localhost log]# date # 查看时间 Sat Aug 18 16:57:51 CST 2012 [root@localhost log]# date -s 20120819 # 修改日期 Sun Aug 19 00:00:00 CST 2012 [root@localhost log]# date -s 16:59 # 修改时间 Sun Aug 19 16:59:00 CST 2012

 浙公网安备 33010602011771号
浙公网安备 33010602011771号