哈希算法
哈希算法简介
1. 常见的哈希算法
2. 碰撞与溢出问题的处理
3. 哈希表的动态扩容
哈希算法简介
哈希算法又称为散列法,任何通过哈希查找的数据都不需要经过事先的排序,也就是说这种查找可以直接且快速地找到键值(Key,访问数据)所存放的地址。
通常判断一个查找算法的好坏主要由其比较次数及查找所需时间来判断,一般的查找技巧主要是通过各种不同的比较方法来查找所要的数据,反观哈希算法则是直接通过数学函数来获取对应的存放地址,因此可以快速地找到所要的数据。
哈希算法还具有保密性高的特点,因为不事先知道哈希函数就无法查找到数据。信息技术上有许多哈希法的应用,特别是在数据压缩与加解密方面。
常见的哈希算法有除留余数法、平方取中法、折叠法、数字分析法以及链地址法。哈希算法并没有一定的规则可循,可能是其中的某一种方法,也可能同时使用好几种方法。
原理
- 哈希算法使用哈希函数(散列函数)来计算一个键值(访问数据)所对应的地址(哈希值),进而建立哈希表(也叫散列表,是通过键值直接访问数据的一种数据结构)。
- 之后每次通过键值和哈希函数,就可以直接获得访问数据的地址,实现 O(1) 的数据访问效率。
哈希算法的查找速度与数据多少无关,在没有碰撞和溢出的情况下,一次读取即可完成。

设计原则
选择哈希函数时,要特别注意不宜过于复杂,设计原则上至少必须符合计算速度快与碰撞频率尽量低的两个特点。
1. 常见的哈希算法
1.1 除留余数法
最简单的哈希函数是将数据值(key)除以某一个常数后,取余数来当索引(哈希值)。可以用以下式子来表示:
h(key) = key mod B
一般而言,B(即常数)最好是质数。
例如,在一个有 13 个位置的数组中,只使用到 7 个地址,值分别是 12、65、70、99、33、67、48。我们可以把数据内的值除以 13,并以其余数来当数组的下标(作为索引)。在这个例子中,我们所使用的 B 即为 13,则 h(12) = 12、h(65) = 0、...,其所建立出来的哈希表为:
| 索引 | 数据 |
| 0 | 65 |
| 1 | |
| 2 | 67 |
| 3 | |
| 4 | |
| 5 | 70 |
| 6 | |
| 7 | 44 |
| 8 | 99 |
| 9 | 48 |
| 10 | |
| 11 | |
| 12 | 12 |
1.2 平方取中法
平方取中法和除留余数法相当类似,就是先计算数据的平方,之后再取中间的某段数字作为索引。
如下例所示,我们用平方取中法,并将数据存放在 100 个地址空间中,其操作步骤如下:
1)将 12、65、70、99、33、67、51 平方后如下:
144、4225、4900、9801、1089、4489、2601
2)再取百位数和十位数作为索引,分别为:
14、22、90、80、08、48、60
上述这7个数字的数列就对应于原先的 7 个数 12、65、70、99、33、67、51 存放在 100 个地址空间的索引值,即:
f(14) = 12 f(22) = 65 f(90) = 70 f(80) = 99 f(08) = 33 f(40) = 67 f(60) = 51
若实际空间介于 0~9(10 个空间),但取百位数和十位数的值介于 0~99(共 100 个空间),则必须将平方取中法第一次所求得的索引值再压缩 1/10 才可以将 100 个可能产生的索引值对应到 10 个空间,即将每一个索引值除以 10 取整数(下例我们以 DIV 运算符作为取整数的除法),我们可以得到下列的对应关系:
f(14 DIV 10) = 12 f(1) = 12 f(22 DIV 10) = 65 f(2) = 65 f(90 DIV 10) = 70 f(9) = 70 f(80 DIV 10) = 99 ——> f(8) = 99 f(08 DIV 10) = 33 f(0) = 33 f(40 DIV 10) = 67 f(4) = 67 f(60 DIV 10) = 51 f(6) = 51
1.3 折叠法
折叠法是将数据转换成一串数字后,先将这串数字拆成几个部分,再把它们加起来,就可以计算出这个键值的 Bucket Address(桶地址)。
例如,有一个数据,转换成数字后为 2365479125443,若以每 4 个数为一个部分则可拆为 2365、4791、2544、3。将这 4 组数字加起来后(9703)即为索引值。
在折叠法中有两种做法,如上例直接将每一部分相加所得的值作为其 Bucket Address,被称为“移动折叠法”。
哈希算法的设计原则之一就是降低碰撞,如果希望降低碰撞的机会,就可以将上述每一部分数字中的奇数或偶数翻转,再相加取得其 Bucket Address,这种改进做法被称为“边界折叠法”(folding at the boundaries)。
- 情况一:将偶数反转
2365(第一组数据为奇数,故不反转) + 4791(奇数) + 4452(偶数,故反转) + 3(奇数) = 11611(Bucket Address)
- 情况二:将奇数反转
5631(第一组数据为奇数,故反转) + 1974(奇数) + 2544(偶数,故不反转) + 3(奇数) = 10153(Bucket Address)
1.4 数字分析法
数字分析法适用于数据不会更改,且为数字类型的静态表。在决定哈希函数时先逐一检查数据的相对位置和分布情况,将重复性高的部分删除。
例如,下面这个电话号码表时相当有规则性的,除了区号全部是 080 外,中间三个数字的变化也不大:
080-772-2234 080-772-4525 080-774-2604 080-772-4651 080-774-2285 080-772-2101 080-774-2699 080-772-2694
假设地址空间的大小为 999,那么我们必须从下列数字提取适当的数字,即数字不要太集中,分布范围较为平均(或称随机度高),最后决定提取最后三个数字作为键值,故可得哈希表:
| 索引 | 电话 |
| 234 | 080-772-2234 |
| 525 | 080-772-4525 |
| 604 | 080-774-2604 |
| 651 | 080-772-4651 |
| 285 | 080-774-2285 |
| 101 | 080-772-2101 |
| 699 | 080-774-2699 |
| 694 | 080-772-2694 |
2. 碰撞与溢出问题的处理
在哈希法中,当标识符要放入某个桶(Bucket,哈希表中存储数据的位置)时,若该桶已经满了,就会发生溢出(Overflow);另一方面哈希法的理想情况是所有数据经过哈希函数运算后都得到不同的值,但现实情况是即使所有关键字段的值都不相同,还是可能得到相同的地址,于是就发生了碰撞(Collsion)问题。因此,如何在碰撞发生后处理溢出的问题就显得相当重要。
常见的处理算法有线性探测法、平方探测法、再哈希法、链地址法等。
2.1 线性探测法
线性探测法是当发生碰撞情况时,若该索引对应的存储位置已有数据,则以线性的方式往后寻找空的存储位置,一旦找到位置就把数据放进去。
线性探测法通常把哈希的位置视为环形结构,如此一来若后面的位置已被填满而前面还有位置时,可以将数据放到前面。
Python 线性探测算法
1 def create_table(num, index): 2 """ 3 :param num: 需要存放的数据 4 :param index: 哈希表 5 :return: None 6 """ 7 # 哈希函数:数据 % 哈希表最大元素(索引) 8 tmp = num % INDEXBOX 9 while True: 10 # 如果数据对应的位置是空的,则直接存入数据 11 if index[tmp] == -1: 12 index[tmp] = num 13 break 14 # 否则往后找位置存放 15 else: 16 # 递增取余是为了将哈希表视为环形结构,后面的位置都被填满时再从头位置往后遍历 17 tmp = (tmp+1) % INDEXBOX
示例程序
以除留余数法的哈希函数取得索引值,再以线性探测法来存储数据。
1 import random 2 3 4 INDEXBOX = 10 # 哈希表最大元素(索引) 5 MAXNUM = 7 # 最大数据个数 6 7 8 # 线性探测算法 9 def create_table(num, index): 10 """ 11 :param num: 需要存放的数据 12 :param index: 哈希表 13 :return: None 14 """ 15 # 哈希函数:数据 % 哈希表最大元素 16 tmp = num % INDEXBOX 17 while True: 18 # 如果数据对应的位置是空的,则直接存入数据 19 if index[tmp] == -1: 20 index[tmp] = num 21 break 22 # 否则往后找位置存放 23 else: 24 # % 递增取余是为了将哈希表视为环形结构,后面的位置都被填满时再从头位置往后遍历 25 tmp = (tmp+1) % INDEXBOX 26 27 28 # 主程序 29 index = [-1] * INDEXBOX # 初始化哈希表 30 data = [random.randint(1, 20) for num in range(MAXNUM)] # 原始数组值 31 print(" 原始数组值:\n%s" % data) 32 33 # 使用哈希算法存入数据 34 print("哈希表内容:") 35 for i in range(MAXNUM): 36 create_table(data[i], index) 37 print(" %d => %s" % (data[i], index)) 38 39 print(" 完成哈希表:\n%s" % index)
执行结果:
原始数组值: [13, 17, 19, 10, 14, 20, 18] 哈希表内容: 13 => [-1, -1, -1, 13, -1, -1, -1, -1, -1, -1] 17 => [-1, -1, -1, 13, -1, -1, -1, 17, -1, -1] 19 => [-1, -1, -1, 13, -1, -1, -1, 17, -1, 19] 10 => [10, -1, -1, 13, -1, -1, -1, 17, -1, 19] 14 => [10, -1, -1, 13, 14, -1, -1, 17, -1, 19] 20 => [10, 20, -1, 13, 14, -1, -1, 17, -1, 19] 18 => [10, 20, -1, 13, 14, -1, -1, 17, 18, 19] 完成哈希表: [10, 20, -1, 13, 14, -1, -1, 17, 18, 19]
2.2 平方探测法
线性探测法有一个缺点,就是相类似的键值经常会聚集在一起,因此可以考虑以平方探测法来加以改进。
在平方探测法中,当发生溢出时,下一次查找的地址是 (f(x)+i2) mob B 或 (f(x)-i2) mob B,即让数据值加或减 i 的平方。
例如数据值 key,哈希函数 h,其查找算法如下:
第一次查找:h(key)
第二次查找:(h(key)+12) % B
第三次查找:(h(key)-12) % B
第四次查找:(h(key)+22) % B
第五次查找:(h(key)-22) % B
...
...
第 n 次查找:(h(key)±((B-1)/2)2) % B,其中,B 必须为 4j + 3 型的质数,且 1 ≤ i ≤ (B-1)/2
2.3 再哈希法
再哈希法就是一开始就先设置一系列的哈希函数,如果使用第一种哈希函数出现溢出时就改用第二种,如果第二种也出现溢出则改用第三种,一直到没有发生溢出为止。例如,h1 为 key%11、h2 为 key*key、h3 为 key*key%11、h4....。
示例:使用再哈希法处理下列数据碰撞的问题
681、467、633、511、100、164、472、438、445、366、118
其中哈希函数为(此处的 m=13):
h1(key) = key MOD m h2(key) = (key+2) MOD m h3(key) = (key+4) MOD m
1)使用第一种哈希函数 f(key) = key MOD 13,所得的哈希地址如下:
681 -> 5 467 -> 12 633 -> 9 511 -> 4 100 -> 9 164 -> 8 472 -> 4 438 -> 9 445 -> 3 366 -> 2 118 -> 1
2)其中 100、472、438 都发生碰撞,再使用第二种哈希函数 h2(key) = (key+2) MOD 13,进行数据的地址安排:
100 -> h2(100+2) = 102 mod 13 = 11 472 -> h2(472+2) = 474 mod 13 = 6 438 -> h2(438+2) = 440 mod 13 = 11
3)438 仍发生碰撞问题,故接着使用第三种哈希函数 h3(key+4) = (key+4) MOD 13,重新进行438 的地址安排:
438 -> h3(438+4) = 442 mod 13 = 0
经过三次再哈希后,数据的地址安排如下:
| 位置 | 数据 |
| 0 | 438 |
| 1 | 118 |
| 2 | 366 |
| 3 | 445 |
| 4 | 411 |
| 5 | 681 |
| 6 | 472 |
| 7 | null |
| 8 | 164 |
| 9 | 633 |
| 10 | null |
| 11 | 100 |
| 12 | 467 |
2.4 链地址法
链地址法是目前比较常用的冲突解决方法,一般可以通过数组和链表的结合达到冲突数据缓存的目的。
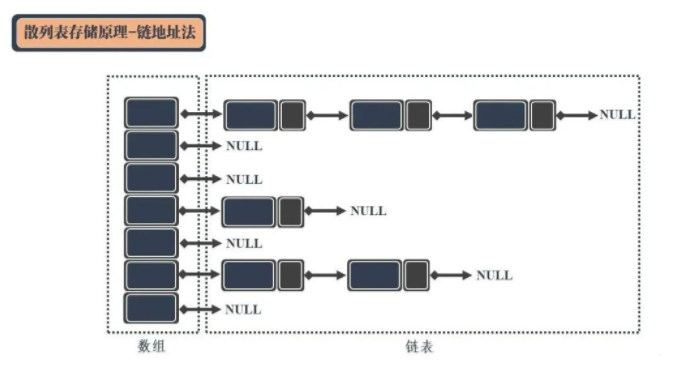
左侧数组的每个成员包括一个指针,指向一个链表的头。每发生一个冲突的数据,就将该数据作为链表的节点链接到链表尾部。这样一来,就可以保证冲突的数据能够区分并顺利访问。
考虑到链表过长造成的问题,还可以使用红黑树替换链表进行冲突数据的处理操作,来提高散列表的查询稳定性。
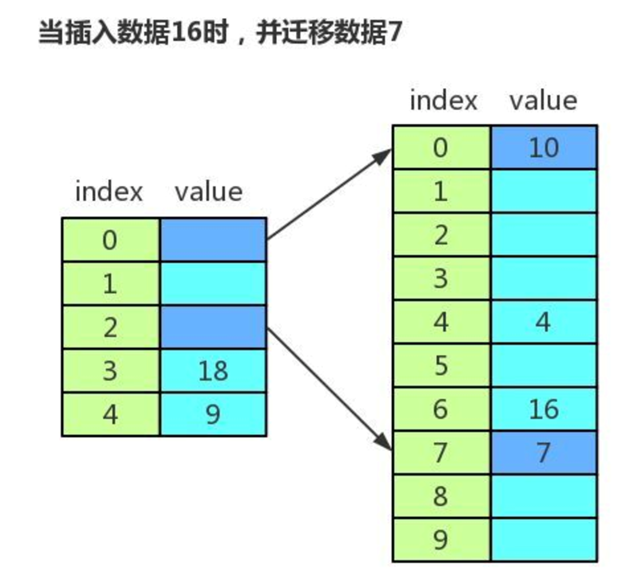
3. 哈希表的动态扩容
重哈希和装载因子
- 装载因子:即关键字个数和哈希表长度之比,用于度量所有关键字填充后哈希表的饱和度。
- 哈希表的装载因子 = 填入表中的元素个数 / 哈希表的长度。
- 重哈希:当装载因子达到指定的阈值时,哈希表进行扩容的过程。
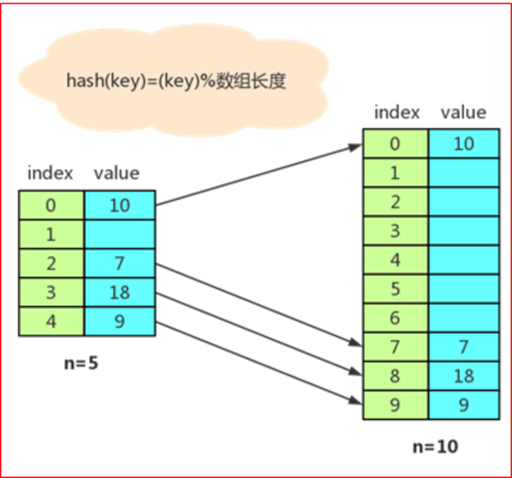
动态扩容过程
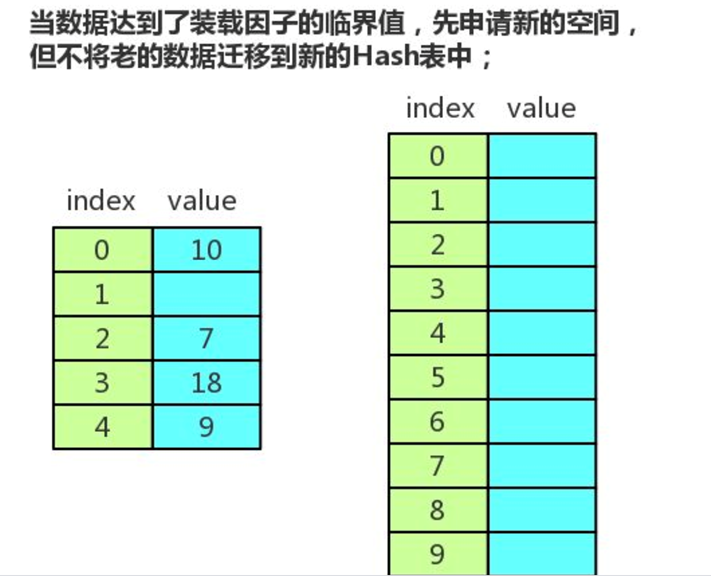
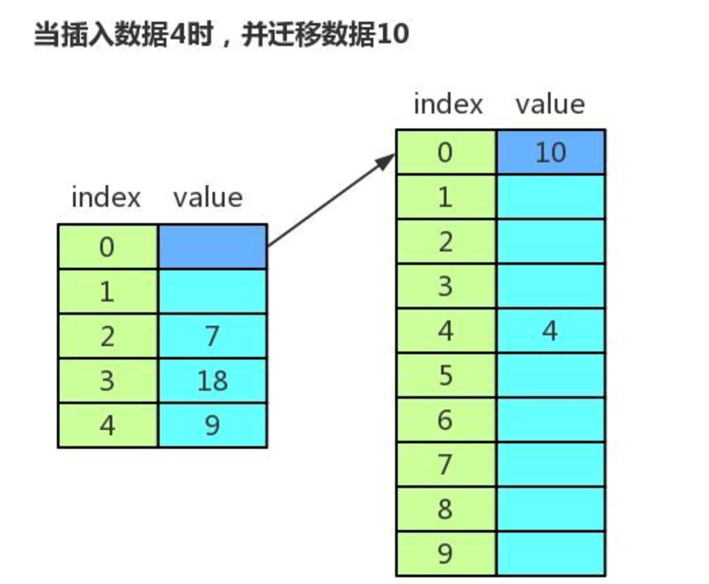
总结
- 每次插入时迁移一个数据,这样不像集中一次性迁移数据那样耗时,不会形成明显的阻塞。
- 由于迁移过程中,有新旧两个哈希表,查找数据时,先在新的哈希表中进行查找,如果没有,再去旧的哈希表中进行查找。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号