测试用例设计方法
功能测试设计策略
等价类划分法
边界值分析法
因果图分析法
正交实验法
错误推测法
白盒测试方法
功能测试设计策略
-
在任何情况下都应使用边界值分析法(对输入和输出边界进行的分析)。
-
应为输入和输出确定有效和无效等价类。
-
如果规格说明包含输入条件组合的情况,应首先使用因果图分析法。
-
使用错误推测技术增加更多的测试用例。
-
针对上述测试用例集检查程序的逻辑结构。
等价类划分法
设计原则
-
若输入条件为取值范围(如1至99):应确定1个有效等价类(1<x<99)和两个无效等价类(x<1、x>99)。
-
若为取值的个数(如1至6名):应确定1个有效等价类(1<x<6)和两个无效等价类(没有个数,或多于6名)。
-
若为输入值的集合:应为每个输入值确定一个有效等价类(在集合内)和1个无效等价类(在集合外)。
-
若规定“必须是”的情况:应确定1个有效(是)和1个无效(不是)。
设计步骤
-
为每个等价类设置不同的编号。
-
生成新的测试用例,尽可能多地覆盖那些尚未被涵盖的有效等价类,直到所有的有效等价都被测试用例所覆盖。
-
生成新的测试用例,覆盖1个且仅1个未被涵盖的无效等价类,直到所有的无效等价都被测试用例所覆盖。
案例
案例 1
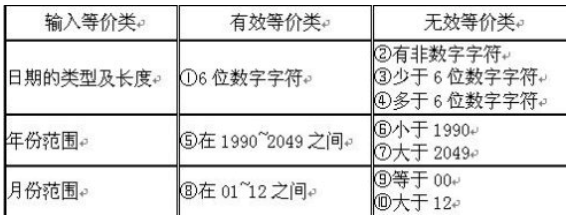
设有一个档案管理系统,要求用户输入以年月表示的日期。假设日期限定在1990年1月 ~ 2049年12月,并规定日期由6位数字字符组成,前4位表示年,后2位表示月。现用等价类划分法设计测试用例,来测试程序的“日期检查功能”(不考虑2月的问题)。
案例 2
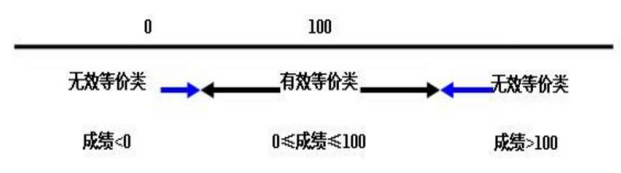
一个有效等价类和两个无效等价类。如:输入值是学生成绩,范围是0~100:
案例 3
输入条件说明学历可为:专科、本科、硕士、博士四种之一,则分别取这四种这四个值作为四个有效等价类,另外把四种学历之外的任何学历作为无效等价类。
边界值分析法
设计原则
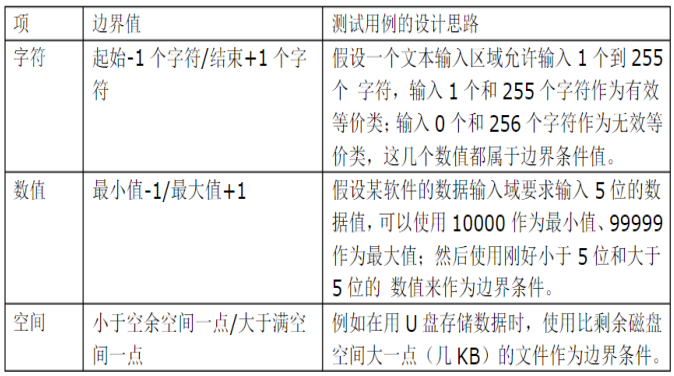
若输入条件规定了取值范围,则选择恰好落在边界上,以及处在边界内、外边上的测试值。
-
若规定了输入数据的个数,则选择最小个数、 最大个数、比最小个数多1和少1、 比最大个数多1和少1 这几种情况为测试时输入数据的个数。
-
若输入数据为有序集合结构,则应特别注意选取有序集合中的第一个和最后一个元素以及越界输入作为测试用例。
-
数值的大小有一个固定的范围,那么边界上的数值和边界外的数值输入都要作为测试用例。
-
注意:不能光考虑了边界值,反而忽略了测试正常的取值范围。
案例
因果图分析法
等价类划分方法和边界值分析方法,都是着重考虑单个输入条件,但未考虑输入条件之间的联系,相互组合等。考虑输入条件之间的相互组合,可能会产生一些新的测试用例。
因果图方法最终生成的就是判定表,它适合于检查程序输入条件的各种组合情况。
注意:因果图或判定表法适合测试组合数量较少的情况。如果组合数量多则使用正交实验法。
设计原则
如下图所示,需对输入条件的组合进行分析。
-
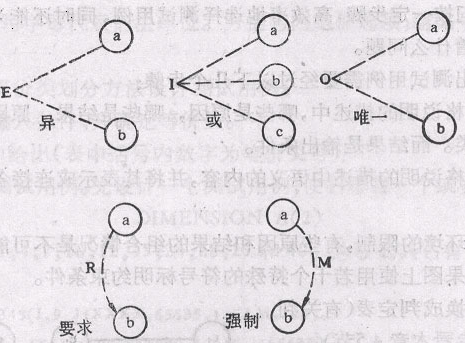
输入条件的约束有以下4类:
-
E 约束(异):a和b中至多有一个可能为1,即a和b不能同时为1。
-
I 约束(或):a、b和c中至少有一个必须是1,即 a、b和c不能同时为0。
-
O 约束(唯一);a和b必须有一个,且仅有1个为1。
-
R 约束(要求):a是1时,b必须是1,即不可能a是1时b是0。
-
输出条件约束类型:
-
输出条件的约束只有M约束(强制):若结果a是1,则结果b强制为0。
设计步骤
-
分析软件规格说明描述中, 哪些是原因(即输入条件或输入条件的等价类),哪些是结果(即输出条件),并给每个原因和结果赋予一个标识符。
-
分析软件规格说明描述中的语义。找出原因与结果之间,原因与原因之间对应的关系。根据这些关系,画出因果图。
-
由于语法或环境限制,有些原因与原因之间,原因与结果之间的组合情况不可能出现。为表明这些特殊情况,在因果图上用一些记号表明约束或限制条件。
-
把因果图转换为判定表。
-
把判定表的每一列拿出来作为依据,设计测试用例。
案例
案例 1
|
条件 |
结果 |
|
如果觉得疲倦并且对书的内容感兴趣,但糊涂的话 |
请停止阅读,休息 |
|
如果觉得疲倦并且对书的内容感兴趣,不糊涂的话 |
请停止阅读,休息 |
|
如果觉得疲倦并且对书的内容不感兴趣,但不糊涂的话 |
请停止阅读,休息 |
|
如果觉得疲倦并且对书的内容不感兴趣,但糊涂的话 |
请停止阅读,休息 |
|
如果不觉得疲倦并且对书的内容感兴趣,但糊涂的话 |
回到本章重读 |
|
如果不觉得疲倦并且对书的内容感兴趣,但不糊涂的话 |
继续读下去 |
|
如果不觉得疲倦并且对书的内容不感兴趣,但糊涂的话 |
跳到下一章去读 |
|
如果不觉得疲倦并且对书的内容不感兴趣,但不糊涂的话 |
跳到下一章去读 |
转换成判定表(不同的组合都会产生唯一的结果):
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
||
|
条件桩 |
是否疲倦 |
Y |
Y |
Y |
Y |
N |
N |
N |
N |
|
是否感兴趣 |
Y |
Y |
N |
N |
Y |
Y |
N |
N |
|
|
是否糊涂 |
Y |
N |
Y |
N |
Y |
N |
Y |
N |
|
|
结果桩 |
重读 |
Y |
|||||||
|
继续读 |
Y |
||||||||
|
跳到下一章 |
Y |
Y |
|||||||
|
休息 |
Y |
Y |
Y |
Y |
|||||
对判定表的对应关系组合进行合并优化:
|
1 |
2 |
3 |
4 |
5 |
||
|
条件桩 |
是否疲倦 |
Y |
N |
N |
N |
N |
|
是否感兴趣 |
N |
Y |
Y |
N |
N |
|
|
是否糊涂 |
Y |
Y |
N |
Y |
N |
|
|
结果桩 |
重读 |
Y |
||||
|
继续读 |
Y |
|||||
|
跳到下一章 |
Y |
Y |
||||
|
休息 |
Y |
|||||
最后如下图判定表,一列就是一条用例:

案例 2
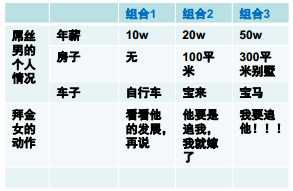
正交实验法
设计原则
正交实验法:依据Galois理论,从大量的(实验)数据(测试例)中挑选适量的、有代表性的点(例),从而合理地安排实验(测试)的一种科学实验设计方法。
这些有代表性的点具备了“均匀分散,齐整可比”的特点。当输入条件很多时,因果图等设计方法设计出来的用例数往往多的惊人,用正交法可有效减少用例数。
关于正交试验表的两个重要概念:
- 所有参与试验、影响试验结果的条件称为因子。
- 影响试验因子的取值或输入叫做因子的水平。
- 考虑因子的个数
- 考虑水平的个数
- 考虑正交表的行数
- 取行数最少的一个
利用正交实验设计方法来设计测试用例时,首先要根据被测试软件的规格说明书找出影响其功能实现的操作对象和外部因素,把他们当作因子,而把各个因子的取值当作状态。
案例
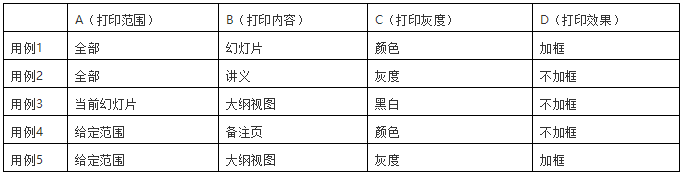
- 打印范围 分为:全部、当前幻灯片、给定范围 共三种情况;
-
打印内容 分为:幻灯片、讲义、备注页、大纲视图 共四种方式;
-
打印颜色/灰度 分为:颜色、灰度、黑白 共三种设置;
-
打印效果 分为:幻灯片加框和幻灯片不加框两种方式。
分析:
PowerPoint 软件打印功能有4个条件,其中:
-
条件1有3个取值;
-
条件2有4个取值;
-
条件3有3个取值;
-
条件4有2个取值。
因此实际组合共有 3*4*3*2=72 种。
但正交表取值使用最大的条件数组合,即4*4*4*4=256,即找正交表 4_4 的组合,但是发现正交表中没有 4_4 的选项,那么就选择最接近的选项 L16_4_5(条件数为4,状态数为5)使用的时候去掉E列。
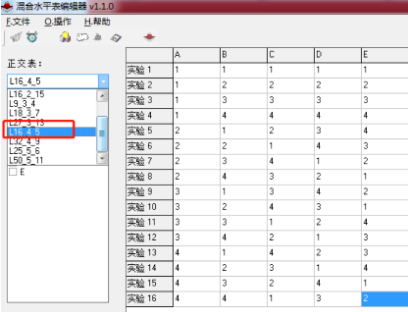
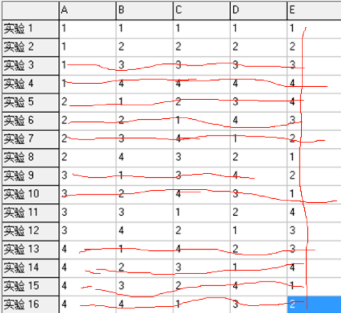
下面来选取有效组合:
-
首先去掉因子5,即E列去掉
-
因子A只有3个条件,那么去掉13、14、15、16 行
-
因子B有4个条件,不用改
-
因子C有3个条件,那么去掉 4、7、10 行
-
因子D有2个条件,那么去掉3、5、6、9行
-
剩下1、2、8、11、12 这5个组合
实际72个组合,挑选5个有效组合来测试,大大节省测试时间。
错误推测法
基于经验和直觉推测程序中所有可能存在的各种错误,从而有针对性的设计测试用例的方法。
-
程序中所有可能有的错误;
-
容易发生错误的特殊情况;
-
以前产品测试中曾经发现的错误。
主要错误类型
-
异常处理不够
-
代码的异常分支覆盖
-
代码未考虑到的异常分支覆盖
-
涉及计算
-
等价类
-
边界值
-
输入输出组合考虑全面
-
场景欠缺
-
需求分析准确
白盒测试方法
白盒测试介绍
什么是白盒测试?
“白盒测试”可以理解为一种专门用于评估代码及程序内部结构的测试技术,也有结构测试这么一说,因为白盒测试会涉及查看代码的结构。对于测试工程师而言,如果你知道软件产品/系统或应用程序的内部结构,就可以尽早展开针对性的测试,以确保程序内部操作是按照规范运行的,并且所有内部结构都能得到充分的测试执行。
作为测试人员,乃至于测试开发人员,我们熟知仅仅依靠黑盒测试不足以达到最大的测试覆盖率,需要黑盒和白盒测试技术的有效结合来覆盖最大范围的缺陷。在软件研发过程中,如能合理有效地实施白盒测试,势必会对软件质量做出客观的贡献。
为什么需要白盒测试?
我们从代码质量保障和潜在BUG挖掘这两层面说明白盒测试的必要性:
确保以下几点:
- 确保模块中所有独立路径至少被执行一次。
- 确保所有合乎逻辑的判断都要验证其真假值。
- 确保所有循环边界值,及其操作范围内的内部数据结构的有效性。
尽可能发现由于以下因素引起的BUG:
- 当我们还未将功能的设计实现及其相关条件控制用代码来实现时,逻辑错误往往会潜入到我们的工作中。
- 程序逻辑与实际实现的差异而导致的设计错误。
- 程序语法语义错误及程序书写不规范引起的错误。
白盒测试能力要求 & 测试范畴
由于我们需要编写测试用例来确保程序逻辑的完整覆盖,对程序的了解和认知是先决条件,我们必须详细理解被测代码及测试需求。对于大型系统进行全面测试是不可能的,毕竟这非常耗时耗力,我们不可能针对程序中循环的每一条路径进行测试,这就意味着测试人员需要通过选择重要的逻辑路径和数据结构进行切实有效且可行的测试。
在企业中进行白盒测试时,开发人员和测试人员往往会协同工作,例如分析哪一行代码被实际执行的,哪一行代码由于逻辑缺失而未被执行,哪些片断的代码存在拼写错误等。因此,白盒测试对代码的能力要求较高,需要对被测试代码使用的语言及代码间的逻辑关系有相当程度的认知及驾驭能力。
案例详解
假设我们有如下伪代码片段:

对于语句覆盖 —— 我们只需一个测试用例来检查代码中所有行。这意味着: 如果我们有测试用例“TestCase_01 (A=40和B=70)”,那么所有代码行都将被执行。
现在问题又来了: 仅仅这个测试用例真的够吗?如果我们将测试用例变为A=33和B=45呢?又会怎么样呢?

很显然因为“语句覆盖”只覆盖了“TRUE”的一面,所以对于上述伪代码片段,只有一个测试用例不足以测试它。
作为一个合格的测试人员,我们必须考虑负面情况。为了获得最大的覆盖率,我们需要引入“分支覆盖”,评估“FALSE”条件。由此可见,通过“语句覆盖”我们发现了伪代码中的逻辑问题,从而需要考虑“分支覆盖”。在现实情况下,我们就可以得出这样的结论:对于被测代码片段,需要为条件失败时添加上适当的语句,于是便有了以下的修复结果(更新后的伪代码片段):

鉴于“语句覆盖”不足以测试整个伪代码,我们需要“分支覆盖”来确保最大的覆盖率。
对于“分支覆盖”,我们需要如下两个测试用例来完成这段伪代码的测试,从而确保每行代码都能被有效执行:

通过以上“语句覆盖” VS “条件覆盖”不难得出结论:
-
分支覆盖对比语句覆盖能够确保更多的覆盖范围;分支覆盖比语句覆盖更强大;
-
100% 分支覆盖率意味着 100% 语句覆盖率;
-
但是 100%语句覆盖率并不能保证 100% 分支覆盖率。
现在让我们转向“路径覆盖”。路径覆盖”于测试复杂的代码片段,这些代码片段基本上包含循环语句,亦或是循环和判断语句的组合。我们来看这样一段伪代码片段:

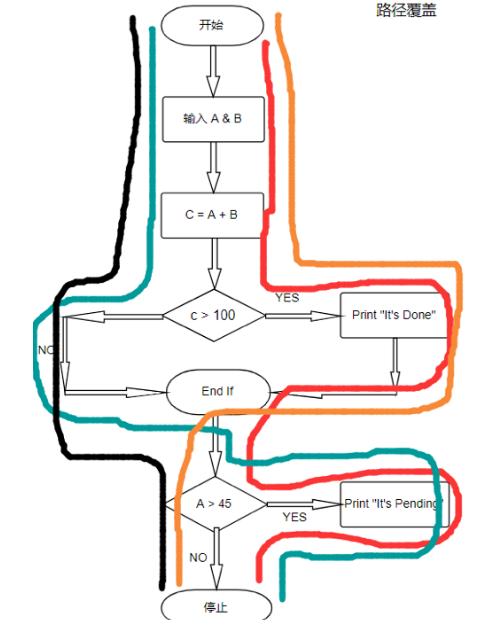
为了确保最大的覆盖率,我们需要 4 个测试用例。通过观察我们发现,代码片段中有两个分支语句, 对于每个分支判断语句,我们需要分别测试两个分支,一个是真,另一个是假。
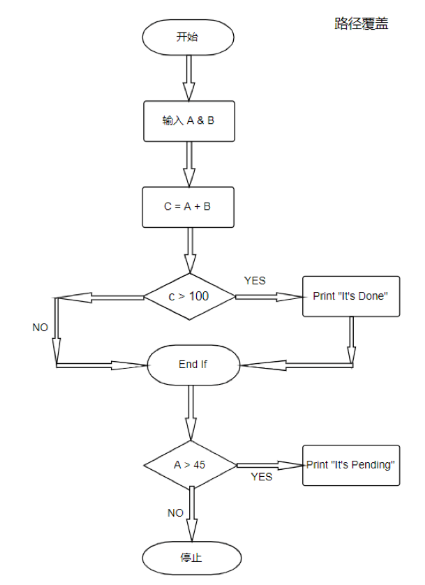
因此,对于2个分支判断语句, 需要2个测试用例来测试“为真”的那一侧分支,2个测试用例来测试“为假”的一侧分支,由此可见共需4个测试用例。为了获得完整的覆盖,我们需要以下测试用例:

白盒测试工具
下面给出几款比较热门的白盒测试工具,感兴趣的话可根据实际需求自行研究使用:
-
[ Veracode ] :一款白盒测试工具,能以较低地成本快速、轻松识别和解决软件缺陷。它支持多种应用程序语言,如.net,c++,JAVA等;
-
[ EclEmma ] :最初是为Eclipse工作台中的测试运行和分析而设计的, 是一个免费的Java代码覆盖工具;
-
[ RCUNIT ] :一款免费的专门用于测试C程序的框架;
-
[ Cfix ] :C/C++单元测试框架之一,唯一目的是使测试套件的开发尽可能简单和容易;
-
[ GoogleTest ] :谷歌的一款C++测试框架。可以实现参数化测试、致命和非致命失败、死亡测试、XML测试报告生成等功能。支持Linux, Windows, Symbian, Mac OS X等平台;
-
[ Emma ] :一款易于使用的免费JAVA代码覆盖工具;
-
[ NUnit ] :一款易于使用的开源单元测试框架,它不需要任何人工干预来判断测试结果。支持所有.net语言,还支持数据驱动测试;
-
[ CppUnit ] :一个用C++编写的单元测试框架,被认为是JUnit的端口。CppUnit的测试输出可以是XML格式或文本格式,通过用自己的类创建单元测试,并在测试套件中运行测试;
-
[ JUnit ] :一个简单的单元测试框架,支持Java编程语言的测试自动化。主要支持测试驱动开发并提供测试覆盖率报告;
-
[ JsUnit ] :被认为是JUnit到javascript的端口,它是一个开源的单元测试框架,支持客户端Javascript。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号