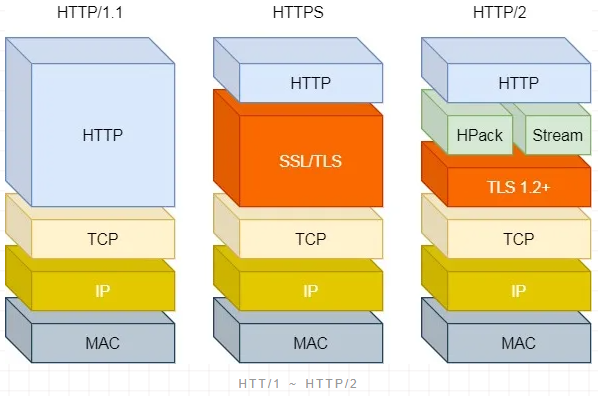
HTTP/1.1、HTTP/2、HTTP/3 演变
HTTP/1.1 相比 HTTP/1.0 提高了什么性能?
针对 HTTP/1.1 的性能瓶颈,HTTP/2 做了什么优化?
HTTP/2 有哪些缺陷?HTTP/3 做了哪些优化?
HTTP/1.1 相比 HTTP/1.0 提高了什么性能?
性能上的改进
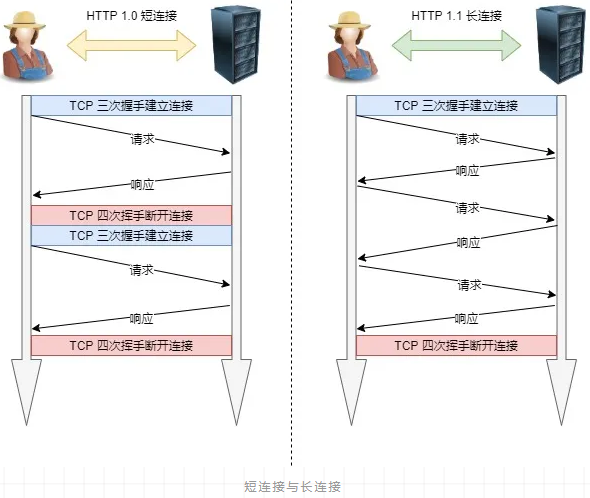
1. 长连接
为了解决上述 TCP 连接问题,HTTP/1.1 提出了长连接的通信方式,也叫持久连接。这种方式的好处在于减少了 TCP 连接的重复建立和断开所造成的额外开销,减轻了服务器端的负载。
持久连接的特点是,只要任意一端没有明确提出断开连接,则保持 TCP 连接状态。
优/缺点
- 长连接可以省去较多的 TCP 建立和关闭的操作,减少浪费,节约时间。对于频繁请求资源的客户来说,较适用长连接。但 Client 与 Server 之间的连接如果一直不关闭的话,会存在一个问题,随着客户端连接数越来越多,Server 早晚有扛不住的时候,这时候 Server 端需要采取一些策略,如关闭一些长时间没有读写事件发生的连接,这样可以避免一些恶意连接导致 server 端服务受损;如果条件再允许就可以以客户端机器为颗粒度,限制每个客户端的最大长连接数,这样可以完全避免某个蛋疼的客户端连累后端服务。
- 短连接对于服务器来说管理较为简单,存在的连接都是有用的连接,不需要额外的控制手段。但如果客户请求频繁,将在 TCP 的建立和关闭操作上浪费时间和带宽。
应用场景
- 长连接多用于操作频繁,且连接数不能太多的情况。每个 TCP 连接都需要三次握手,这需要时间,如果每个操作都是先连接,再操作的话那么处理速度会降低很多,所以每个操作完后都不断开,再次处理时直接发送数据包就 OK 了,不用建立 TCP 连接。例如:数据库的连接用长连接,如果用短连接频繁的通信会造成 socket 错误,而且频繁的 socket 创建也是对资源的浪费。
- 而像 WEB 网站的 HTTP 服务一般都用短链接,因为长连接对于服务端来说会耗费一定的资源,像 WEB 网站这么频繁的成千上万甚至上亿客户端的连接用短连接会更省一些资源,如果用长连接,而且同时有成千上万的用户,如果每个用户都占用一个连接的话,那可想而知。所以短连接多用于并发量大,但每个用户无需频繁操作的情况。
2. 管道(pipeline)网络传输
即可在同一个 TCP 连接里面,客户端可以发起多个请求,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间。
举例来说,客户端需要请求两个资源。以前的做法是,在同一个 TCP 连接里面,先发送 A 请求,然后等待服务器做出回应,收到后再发出 B 请求。管道机制则是允许浏览器同时发出 A 请求和 B 请求。
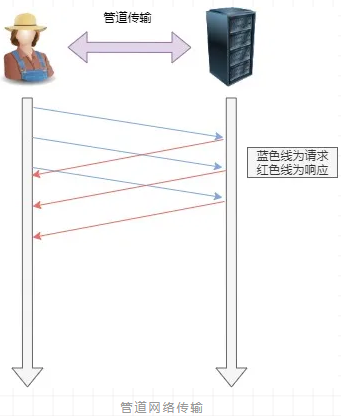
但是服务器还是按照顺序,先回应 A 请求,完成后再回应 B 请求。要是前面的回应特别慢,后面就会有许多请求排队等着。这称为「队头堵塞」。
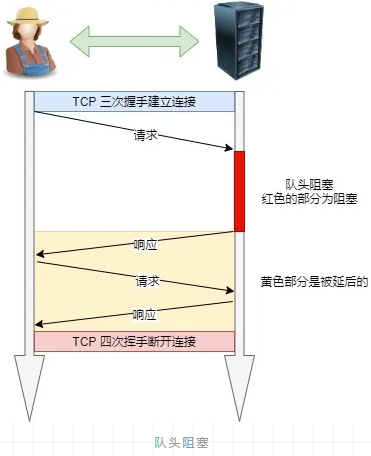
HTTP/1.1 的性能瓶颈
-
请求 / 响应头部未经压缩就发送,首部信息越多延迟越大。只能压缩 Body 的部分。
-
发送冗长的首部。每次互相发送相同的首部造成的浪费较多。
-
服务器是按请求的顺序响应的,当顺序发送的请求序列中的一个请求因为某种原因被阻塞时,在后面排队的所有请求也一同被阻塞了,会招致客户端一直请求不到数据,这也就是「队头阻塞」。好比上班的路上塞车。
-
没有请求优先级控制。
-
请求只能从客户端开始,服务器只能被动响应。
针对 HTTP/1.1 的性能瓶颈,HTTP/2 做了什么优化?
那 HTTP/2 相比 HTTP/1.1 性能上的改进:
1. 头部压缩
HTTP/2 会压缩头部(Header),如果你同时发出多个请求,他们的头是一样的或是相似的,那么,协议会帮你消除重复的部分。
这就是所谓的 HPACK 算法:在客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就提高速度了。
2. 二进制格式
HTTP/2 不再像 HTTP/1.1 里的纯文本形式的报文,而是全面采用了二进制格式。
头信息和数据体都是二进制,并且统称为帧(frame):头信息帧和数据帧。
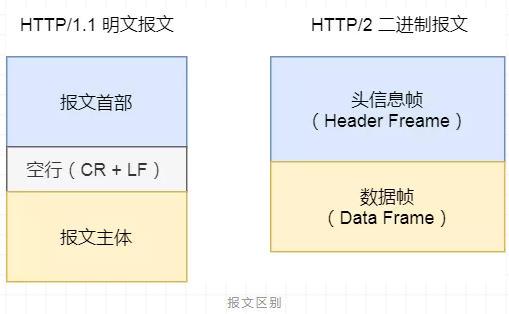
这样虽然对人不友好,但是对计算机非常友好,因为计算机只懂二进制,那么收到报文后,无需再将明文的报文转成二进制,而是直接解析二进制报文,这增加了数据传输的效率。
3. 数据流
HTTP/2 的数据包不是按顺序发送的,同一个连接里面连续的数据包,可能属于不同的回应。因此,必须要对数据包做标记,指出它属于哪个回应。
每个请求或回应的所有数据包,称为一个数据流(Stream)。
每个数据流都标记着一个独一无二的编号,其中规定客户端发出的数据流编号为奇数, 服务器发出的数据流编号为偶数。
客户端还可以指定数据流的优先级。优先级高的请求,服务器就先响应该请求。
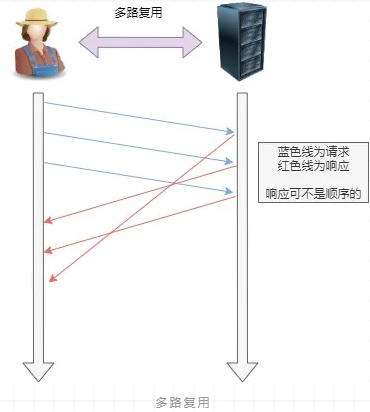
4. 多路复用
HTTP/2 是可以在一个连接中并发多个请求或回应,而不用按照顺序一一对应。
移除了 HTTP/1.1 中的串行响应,不需要排队等待,也就不会再出现「队头阻塞」问题,降低了延迟,大幅度提高了连接的利用率。
举例来说,在一个 TCP 连接里,服务器收到了客户端 A 和 B 的两个请求,如果发现 A 处理过程非常耗时,于是就先回应 A 请求已经处理好的部分,接着回应 B 请求,完成后再回应 A 请求剩下的部分。
5. 服务器推送
HTTP/2 还在一定程度上改善了传统的「请求 - 应答」工作模式,服务器不再是被动地响应,也可以主动向客户端发送消息。
举例来说,在浏览器刚请求 HTML 的时候,就提前把可能会用到的 JS、CSS 文件等静态资源主动发给客户端,减少延时的等待,也就是服务器推送(Server Push,也叫 Cache Push)。
HTTP/2 有哪些缺陷?HTTP/3 做了哪些优化?
所以一旦发生了丢包现象,就会触发 TCP 的重传机制,这样在一个 TCP 连接中的所有的 HTTP 请求都必须等待这个丢了的包被重传回来。
-
HTTP/1.1 中的管道( pipeline)传输中如果有一个请求阻塞了,那么队列后请求也统统被阻塞住了。
-
HTTP/2 多请求复用一个 TCP 连接,一旦发生丢包,就会阻塞住所有的 HTTP 请求。
这都是基于 TCP 传输层的问题,所以 HTTP/3 把 HTTP 下层的 TCP 协议改成了 UDP!
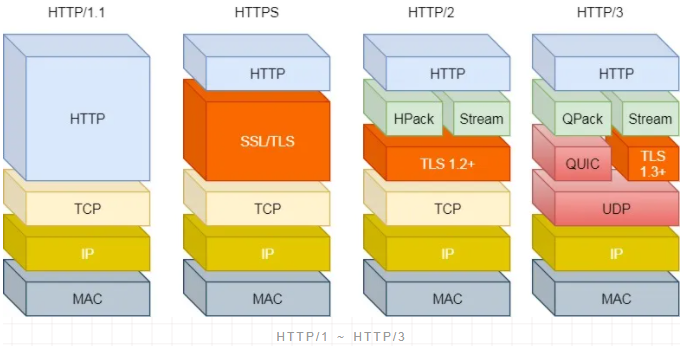
大家都知道 UDP 是不可靠传输的,但基于 UDP 的 QUIC 协议 可以实现类似 TCP 的可靠性传输。
-
QUIC 有自己的一套机制可以保证传输的可靠性的。当某个流发生丢包时,只会阻塞这个流,其他流不会受到影响。
-
TLS 升级成了最新的 1.3 版本,头部压缩算法也升级成了 QPack。
-
HTTPS 建立一个连接,要花费 6 次交互,先是建立三次握手,然后是 TLS/1.3 的三次握手。QUIC 直接把以往的 TCP 和 TLS/1.3 的 6 次交互合并成了 3 次,减少了交互次数。
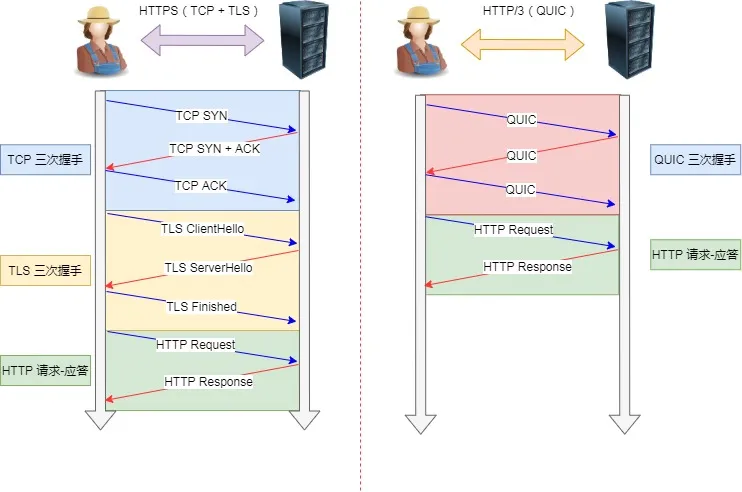
QUIC 是新协议,对于很多网络设备,根本不知道什么是 QUIC,只会当做 UDP,这样会出现新的问题。所以 HTTP/3 现在普及的进度非常的缓慢,不知道未来 UDP 是否能够逆袭 TCP。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号