Scrapy 爬虫项目框架
1. Scrapy 简介
2. Scrapy 项目开发介绍
3. Scrapy 项目代码示例
3.3 spider目录下的sohu.py:编写提取数据的Spider
3.4 pipelines.py:将爬取后的item数据进行存储
1. Scrapy 简介
什么是 Scrapy?
Scrapy架构
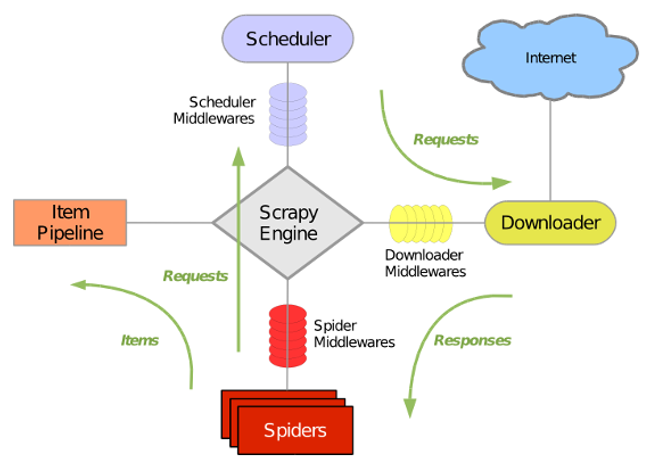
- Scrapy Engine(引擎):Scrapy框架的核心部分,负责在Spider和ItemPipeline、Downloader、Scheduler之间通信、传递数据等。
- Spider(爬虫):发送需要爬取的链接给引擎,最后引擎把其他模块请求回来的数据再发送给爬虫,爬虫就去解析想要的数据。这个部分是我们开发者自己写的,因为要爬取哪些链接,页面中的哪些数据是我们需要的,都是由程序员自己决定。
- Scheduler(调度器):负责接收引擎发送过来的请求,并按照一定的方式进行排列和整理,负责调度请求的顺序等。
- Downloader(下载器):负责接收引擎传过来的下载请求,然后去网络上下载对应的数据再交还给引擎。
- Item Pipeline(管道):负责将Spider(爬虫)传递过来的数据进行保存。具体保存在哪里,应该看开发者自己的需求。
- Downloader Middlewares(下载中间件):可以扩展下载器和引擎之间通信功能的中间件。
- Spider Middlewares(Spider中间件):可以扩展引擎和爬虫之间通信功能的中间件。
Scrapy执行流程
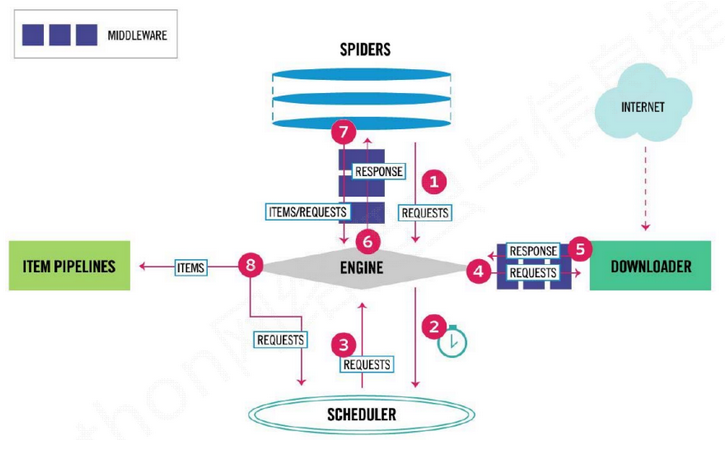
Scrapy 框架的执行顺序:
- Spiders 的 yeild 将 request 发送给 Engine;
- Engine 对request 不做任何处理发送给 Scheduler;
- Scheduler 生成 request交给 Engine;
- Engine 拿到 request,通过 Middleware 进行层层过滤发送给 Downloader;
- Downloader 在网上获取到 response 数据之后,又经过 Middleware 进行层层过滤发送给 Engine;
- Engine 获取到 response 数据之后,返回给 Spiders,Spiders 的 parse() 方法对获取到的 response 数据进行处理,解析出 items 或者 requests;
- 将解析出来的 items 或者 requests 发送给 Engine;
- Engine 获取到 items 或者 requests,将 items 发送给Iitem Pipelines,将 requests 发送给Scheduler。
注意!只有当 Scheduler 中不存在任何 request 了,整个程序才会停止(也就是说,对于下载失败的 url,scrapy 也会重新下载)。
示例:
- 引擎:Hi!Spider, 你要处理哪一个网站?
- Spider:老大要我处理xxxx.com。
- 引擎:你把第一个需要处理的URL给我吧。
- Spider:给你,第一个URL是xxxxxxx.com。
- 引擎:Hi!调度器,我这有request请求你帮我排序入队一下。
- 调度器:好的,正在处理你等一下。
- 引擎:Hi!调度器,把你处理好的request请求给我。
- 调度器:给你,这是我处理好的request。
- 引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求。
- 下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)。
- 引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿 responses 默认是交给 parse() 这个函数处理的)。
- Spider:(处理完毕数据之后对于需要跟进的URL)Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
- 引擎:Hi!管道,我这儿有个item你帮我处理一下。Hi!调度器,这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
- 管道&调度器:好的,现在就做!
2. Scrapy 项目开发介绍
Scrapy 安装
- pip install scrapy
- pip install -i https://pypi.douban.com/simple/ scrapy
Scrapy 项目的开发步骤
可以使用命令行来新建一个爬虫工程,这个工程会自动按照scrapy的结构创建一个工程目录。
- 创建项目:scrapy startproject xxx(项目名字,不区分大小写)
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
- 启动程序的py文件(start.py):等同于此命令(scrapy crawl xxx -o xxx.json)
示例:创建项目
1)在e盘下新建一个目录:scrapy_crawler
2)在cmd进入目录:scrapy_crawler,然后执行scrapy startproject tutorial(给工程起名为tutorial),执行后会在scrapy_crawler创建好爬虫的工程,目录名为:tutorial

3)进入 tutorial 目录,执行命令:scrapy genspider sohu www.sohu.com(给爬虫文件起名,并设定种子URL)
以上三步执行完毕,则工程的框架建立完毕。后续需要你自己实现爬虫分析和保存的逻辑。目录结构如下图:

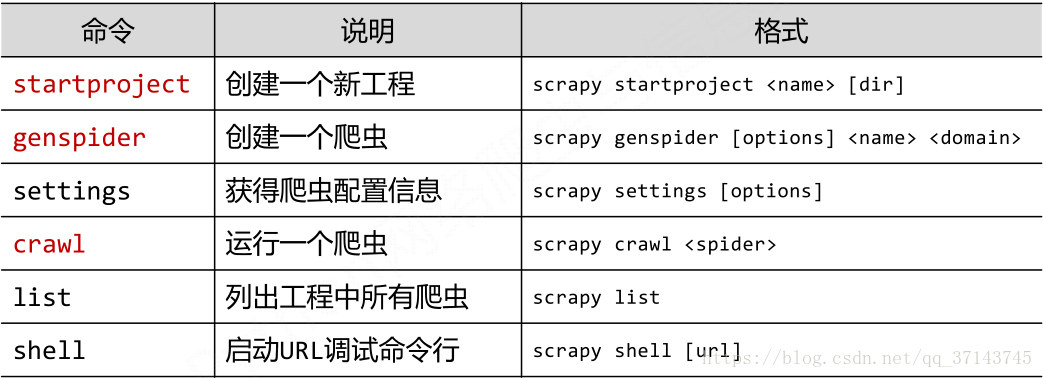
Scrapy 常用命令
Scrapy 保存信息的简单方法
- json格式,默认为Unicode编码:scrapy crawl 项目名 -o 项目名.json
- json lines格式,默认为Unicode编码:scrapy crawl 项目名 -o 项目名.jsonlines
- csv 逗号表达式,可用Excel打开:scrapy crawl 项目名 -o 项目名.csv
- xml格式:scrapy crawl 项目名 -o 项目名.xml
Parse()方法的工作机制
- 因为使用的yield,而不是return。parse函数将会被当做一个生成器使用。scrapy会逐一获取parse方法中生成的结果,并判断该结果是一个什么样的类型;
- 如果是request则加入爬取队列,如果是item类型则使用pipeline处理,其他类型则返回错误信息;
- scrapy取到第一部分的request不会立马就去发送这个request,只是把这个request放到队列里,然后接着从生成器里获取;
- 取尽第一部分的request,然后再获取第二部分的item,取到item了,就会放到对应的pipeline里处理;
- Parse()方法作为回调函数(callback)赋值给了Request,指定parse()方法来处理这些请求 scrapy.Request(url, callback=self.parse);
- Request对象经过调度,执行生成 scrapy.http.response()的响应对象,并送回给parse()方法,直到调度器中没有Request(递归的思路);
- 取尽之后,parse()工作结束,引擎再根据队列和pipelines中的内容去执行相应的操作;
- 程序在取得各个页面的items前,会先处理完之前所有的request队列里的请求,然后再提取items;
- 这一切的一切,Scrapy引擎和调度器将负责到底。
3. Scrapy 项目代码示例
3.1 setting.py:爬虫基本配置
必选配置项
1 BOT_NAME = 'tutorial' 2 3 4 5 SPIDER_MODULES = ['tutorial.spiders'] 6 7 NEWSPIDER_MODULE = 'tutorial.spiders' 8 9 10 11 ROBOTSTXT_OBEY = False # 若抓不到东西,就设置为True 12 13 14 # 取消下述注释行 15 ITEM_PIPELINES = { 16 17 'tutorial.pipelines.TutorialPipeline': 300, 18 19 }
可选配置项
# CONCURRENT_REQUESTS_PER_DOMAIN = 16 # 每个域名,同时并发的请求次数限制
# CONCURRENT_REQUESTS_PER_IP = 16 # 每个IP,同时并发的请求次数限制
# CONCURRENT_REQUESTS = 32 # 框架最大的并发请求数量,针对多个域名和多个ip的一个并发请求上限
3.2 items.py:定义您想抓取的数据
1 # Define here the models for your scraped items 2 3 # 4 5 # See documentation in: 6 7 # https://docs.scrapy.org/en/latest/topics/items.html 8 9 10 import scrapy 11 12 13 class TutorialItem(scrapy.Item): 14 15 # define the fields for your item here like: 16 17 # name = scrapy.Field() 18 19 URL = scrapy.Field() # 存放当前网页地址 20 21 TITLE = scrapy.Field() # 存放当前网页title,格式类似于:<head><title>百度一下</title></head> 22 23 H1 = scrapy.Field() # 存放一级标题 24 25 TEXT = scrapy.Field() # 存放正文
3.3 spider目录下的sohu.py:编写提取数据的Spider
- 拿到每个网页的页面源码
- 拿到网页源码中的url
- 把网页源码中要的4个数据都存到一个类似字典格式的字符串
- 把抓取的结果发给pipelines做持久化
- 把新获取的url通过递归的方式,进行抓取
1 import scrapy 2 import re,os 3 from tutorial.items import TutorialItem 4 from scrapy import Request 5 6 7 class SohuSpider(scrapy.Spider): 8 9 name = 'sohu' # 项目名称 10 # allowed_domains = ['www.sohu.com'] # 如果指定爬虫作用范围,则作用于首页之后的页面 11 start_urls = ['http://www.sohu.com/'] # 开始url 12 13 def parse(self, response): 14 # response:网页源码对象 15 # 从源码对象中获取/html下的所有标签内容,拿到了所有网页的源码 16 all_urls = re.findall('href="(.*?)"',response.xpath("/html").extract_first()) 17 for url in all_urls: 18 # 每生成这个对象,就可以存储一组4个数据 19 item = TutorialItem() 20 if re.findall("(\.jpg)|(\.jpeg)|(\.gif)|(\.ico)|(\.png)|(\.js)|(\.css)$",url.strip()): 21 pass # 去掉无效链接 22 elif url.strip().startswith("http") or url.strip().startswith("//"): 23 temp_url = url.strip() if url.strip().startswith('http') else 'http:' + url.strip() # 三目运算符获取完整网址 24 item = self.get_all(item,response) 25 # 判断item中存在正文且不为空,页面一级标题不为空 26 if 'TEXT' in item and item['TEXT'] != '' and item['TITLE'] != '': 27 yield item # 发送到管道 28 print('发送<' + temp_url + '>到下载器') # 提示 29 yield Request(temp_url,callback=self.parse) # 递归调用,实现了不断使用新的url进行下载 30 31 # 自定义封装的方法:从网页中提取4个要爬取的内容放到类似字典item的里面 32 def get_all(self,item,response): 33 # 获取当前页面的网址、title、一级标题、正文内容 34 item['URL'] = response.url.strip() 35 item['TITLE'] = response.xpath('/html/head/title/text()').extract()[0].strip() 36 contain_h1 = response.xpath('//h1/text()').extract() # 获取当前网页所有一级标题 37 contain= contain_h1[0] if len(contain_h1) !=0 else "" # 获取第一个一级标题 38 item["H1"] = contain.strip() 39 main_text = [] 40 # 遍历网页中所有p标签和br标签的内容 41 for tag in ['p','br']: 42 sub_text = self.get_content(response,tag) 43 main_text.extend(sub_text) 44 # 对正文内容去重并判断不为空 45 main_text = list(set(main_text)) 46 if len(main_text) != 0: 47 item['TEXT'] = '\n'.join(main_text) 48 return item 49 50 def get_content(self,response,tag): 51 # 判断只有大于100个文字的内容才保留 52 main_text = [] 53 contexts = response.xpath('//'+tag+'/text()').extract() 54 for text in contexts: 55 if len(text.strip()) > 100: 56 main_text.append(text.strip()) 57 return main_text
3.4 pipelines.py:将爬取后的item数据进行存储
1 # Define your item pipelines here 2 3 # 4 5 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 6 7 # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html 8 9 import json 10 11 12 class TutorialPipeline(object): 13 14 def __init__(self): 15 # 存爬取数据的文件句柄 16 self.filename = open("content.txt",'w',encoding="utf-8") 17 # 集合对象,用于去重爬取数据 18 self.contain = set() 19 20 # 数据怎么存 21 def process_item(self, item, spider): 22 # item:爬取来的数据 23 # 抓取后的数据,包含中文的话,可以直接看到正文。等价于text= str(item) 24 text = json.dumps(dict(item),ensure_ascii=False) + '\n' 25 # 把json串转换为字典 26 text_dict = eval(text) 27 # 用字典去取数据 28 if text_dict['URL'] not in self.contain: # 抓取到新网页,并写入文件 29 # 判断url是否被抓取过,如果没有被抓取过,就存到文件里面 30 for _,targetName in text_dict.items(): 31 # 实现存储数据的逻辑 32 # 网页正文包含“人”才会保存, 33 # “人”是我们想抓取页面的核心关键词,可以换成其它关键词 34 if "人" in targetName: 35 # 有的话,把这个字典写到文件里面 36 self.write_to_txt(text_dict) 37 # 避免重复写入 38 break 39 # 每次记录文件后把网页url写入集合,重复的url会自动过滤掉 40 self.contain.add(text_dict['URL']) 41 # 表示item处理完了 42 return item 43 44 45 # 爬虫关掉时,把文件关掉 46 def close_spider(self,spider): 47 self.filename.close() 48 49 # 具体把字典写入到文件的方法 50 def write_to_txt(self,text_dict): 51 52 # 把抓取到的内容写入文件中 53 for key,value in text_dict.items(): 54 self.filename.write(key+"内容:\n"+value+'\n') 55 self.filename.write(50*'='+'\n')
说明
Item 在 Spider 中被收集之后,它将会被传递到 Item Pipeline,一些组件会按照一定的顺序执行对 Item 的处理。
每个 Item Pipeline 组件(有时称之为“Item Pipeline”)是实现了简单方法的 python 类。他们接收到 Item 并通过它执行一些行为,同时也决定此 Item 是否继续通过 Pipeline,或是被丢弃而不再进行处理。
Item Pipeline 的一些典型应用:
- 清理 HTML 数据
- 验证爬取的数据(检查 Item 包含某些字段)
- 查重(并丢弃)
Item Pipeline的内置方法
每个 item pipiline 组件是一个独立的 python 类,同时必须实现以下方法:
process_item(item, spider)
每个item pipeline组件都需要调用该方法,这个方法必须返回一个 Item(或任何继承类)对象, 或是抛出 DropItem 异常,被丢弃的 item 将不会被之后的 pipeline 组件所处理。
- item (Item 对象) – 被爬取的 item
- spider (Spider 对象) – 爬取该 item 的 spider
open_spider(spider)
当 spider 被开启时,这个方法被调用。
- spider (Spider 对象) – 被开启的 spider
close_spider(spider)
当 spider 被关闭时,这个方法被调用。
- spider(Spider 对象)– 被关闭的 spider
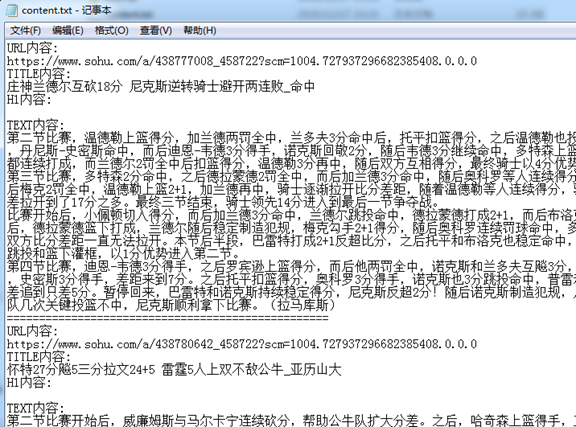
3.5 执行结果:查看爬取数据
在根目录下执行命令:
方式一 指定json文件输出:scrapy crawl sohu -o items.json
方式二 根据pipelines.py定义输出:scrapy crawl sohu
例:E:\tutorial无限制爬取\tutorial>scrapy crawl sohu

 浙公网安备 33010602011771号
浙公网安备 33010602011771号