爬虫简介、requests 基础用法、urlretrieve()
1. 爬虫简介
2. requests 基础用法
3. urlretrieve()
1. 爬虫简介
爬虫的定义
网络爬虫(又被称为网页蜘蛛、网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
爬虫有什么用
- 市场分析:电商分析、商圈分析、一二级市场分析等
- 市场监控:电商、新闻、房源监控等
- 商机发现:招投标情报发现、客户资料发掘、企业客户发现等
认识网址的构成
一个网站的网址一般由域名 + 自己编写的页面所构成。我们在访问同一网站的网页时,域名一般是不会改变的,因此我们爬虫所需要解析的就是网站自己所编写的不同页面的入口 url,只有解析出来各个页面的入口,才能开始我们的爬虫。
了解网页的两种加载方法
只有同步加载的数据才能直接在网页源代码中直接查看到,异步加载的数据直接查看网页源代码是看不到的。
- 同步加载:改变网址上的某些参数会导致网页发生改变,例如:www.itjuzi.com/company?page=1(改变 page= 后面的数字,网页会发生改变)。
- 异步加载:改变网址上的参数不会使网页发生改变,例如:www.lagou.com/gongsi/(翻页后网址不会发生变化)。
- 同步任务:在主线程上排队执行的任务,只有前一个任务执行完毕,才能执行后一个任务。
- 异步任务:不进入主线程,而进入"任务队列"(task queue)的任务。有等主线程任务执行完毕,"任务队列"开始通知主线程,请求执行任务,该任务才会进入主线程执行(如回调函数)。
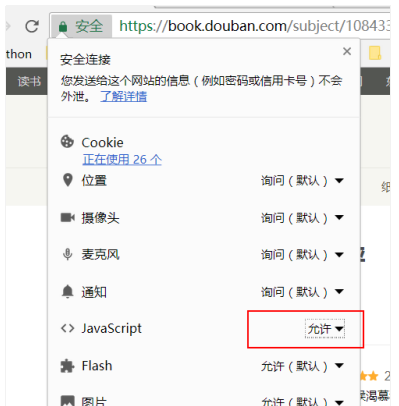
验证网页是同步还是异步加载的方法:把 JavaScript 由“允许”改为“阻止”,重新刷新页面。若网页正常加载,说明该网页的加载方式是同步加载;若网页没有正常加载,说明该网页的加载方式是异步加载。
认识网页源码的构成
在网页中右键点击查看网页源码,可以查看到网页的源代码信息。
源代码一般由三个部分组成,分别是:
-
html:描述网页的内容结构。
-
css:描述网页的样式排版布局。
-
JavaScript:描述网页的事件处理,即鼠标或键盘在网页元素上的动作后的程序。
查看网页请求
以 chrome 浏览器为例,在网页上点击鼠标右键,选择“检查”(或者直接 F12),选择“network”,刷新页面,选择 ALL 下面的第一个链接,这样就可以看到网页的各种请求信息。
请求头(Request Headers):
- Accept: text/html,image/* (浏览器可以接收的类型)
- Accept-Charset: ISO-8859-1 (浏览器可以接收的编码类型)
- Accept-Encoding: gzip,compress (浏览器可以接收压缩编码类型)
- Accept-Language: en-us,zh-cn (浏览器可以接收的语言和国家类型)
- Host: www.it315.org:80 (浏览器请求的主机和端口)
- If-Modified-Since: Tue, 11 Jul 2000 18:23:51 GMT (某个页面缓存时间)
- Referer: http://www.it315.org/index.jsp (请求来自于哪个页面)
- User-Agent: Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0) (浏览器相关信息)
- Cookie: (浏览器暂存服务器发送的信息)
- Connection: close(1.0)/Keep-Alive(1.1) (HTTP请求的版本的特点)
- Date: Tue, 11 Jul 2000 18:23:51 GMT (请求网站的时间)
响应头(Response Headers):
- Location: http://www.it315.org/index.jsp (控制浏览器显示哪个页面)
- Server: apache tomcat (服务器的类型)
- Content-Encoding: gzip (服务器发送的压缩编码方式)
- Content-Length: 80 (服务器发送显示的字节码长度)
- Content-Language: zh-cn (服务器发送内容的语言和国家名)
- Content-Type: image/jpeg; charset=UTF-8 (服务器发送内容的类型和编码类型)
- Last-Modified: Tue, 11 Jul 2000 18:23:51 GMT (服务器最后一次修改的时间)
- Refresh: 1;url=http://www.it315.org (控制浏览器1秒钟后转发URL所指向的页面)
- Content-Disposition: attachment; filename=aaa.jpg (服务器控制浏览器下载方式打开文件)
- Transfer-Encoding: chunked (服务器分块传递数据到客户端)
- Set-Cookie: SS=Q0=5Lb_nQ; path=/search (服务器发送Cookie相关的信息)
- Expires: -1 (服务器控制浏览器不要缓存网页,默认是缓存)
- Cache-Control: no-cache (服务器控制浏览器不要缓存网页)
- Pragma: no-cache (服务器控制浏览器不要缓存网页)
- Connection: close/Keep-Alive (HTTP请求的版本的特点)
- Date: Tue, 11 Jul 2000 18:23:51 GMT (响应网站的时间)
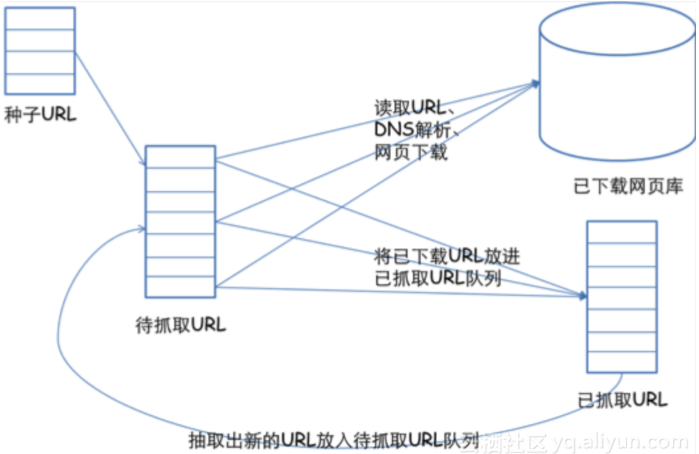
通用的网络爬虫框架
-
挑选种子 URL;
-
将这些 URL 放入待抓取的 URL 队列;
-
取出待抓取的 URL,下载并存储进已下载网页库中。此外,将这些 URL 放入已抓取 URL 队列;
-
分析已抓取队列中的 URL,并且将 URL 放入待抓取 URL 队列,从而进入下一循环。
2. requests 基础用法
详解:requests 库
Requests 库的主要方法
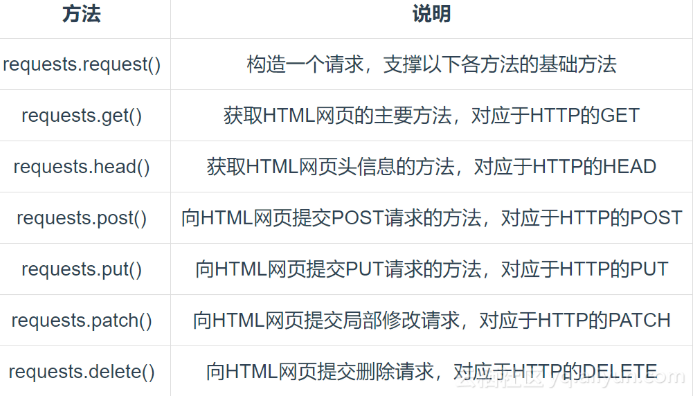
requests.get 方法
1 # 使用get方法发送请求,返回包含网页数据的Response并存储到Response对象r中 2 r = requests.get(url)
Response 对象的属性
- r.status_code:http 请求的返回状态,200 表示连接成功(HTTP 状态码)
- r.text:返回对象的文本内容
- r.content:猜测返回对象的二进制形式
- r.encoding:分析返回对象的编码方式
- r.apparent_encoding:响应内容编码方式(备选编码方式)
示例:分析豆瓣短评网页
1 import requests 2 3 url = ' https://book.douban.com/subject/27147922/?icn=index-editionrecommend' 4 r = requests.get(url, timeout=20) # 设置超时时间为20秒 5 # #print(r.text) # 打印返回文本 6 # 抛出异常 7 print(r.raise_for_status()) # None
3. urlretrieve()
用于直接将远程数据下载到本地。
urlretrieve(url, filename=None, reporthook=None, data=None)
-
filename:指定了保存本地路径(如果参数未指定,urllib 会生成一个临时文件保存数据)。
-
reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度。
-
data:指post导服务器的数据,该方法返回一个包含两个元素的(filename, headers)元组,filename 表示保存到本地的路径,header 表示服务器的响应头。
示例 1:下载图片
使用 urlretrieve():
1 from urllib.request import urlretrieve 2 3 urlretrieve("http://pic1.win4000.com/pic/b/20/b42b4ca4c5_250_350.jpg", "e:\\1.jpg")
使用 requests:
1 import requests 2 3 url = "http://pic1.win4000.com/pic/b/20/b42b4ca4c5_250_350.jpg" 4 r = requests.get(url) 5 with open("e:\\1.jpg", "wb") as fp: 6 fp.write(r.content)
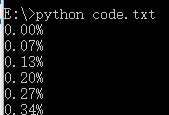
示例 2:下载文件并显示下载进度
1 import os 2 from urllib.request import urlretrieve 3 4 def cbk(a, b, c): 5 '''回调函数 6 @a:已经下载的数据块 7 @b:数据块的大小 8 @c:远程文件的大小 9 ''' 10 per = 100*a*b/c 11 if per > 100: 12 per = 100 13 print('%.2f%%' % per) 14 15 url = 'http://www.python.org/ftp/python/2.7.5/Python-2.7.5.tar.bz2' 16 dir = os.path.abspath('.') 17 work_path = os.path.join(dir, 'Python-2.7.5.tar.bz2') 18 urlretrieve(url, work_path, cbk)
执行效果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号