
Python 多进程
1. 多进程简介
2. 进程的创建-multiprocessing.Process
3. 进程的创建-Process子类
4. 进程池-Pool
5. 进程间通信-Queue
6. 异步
7. 进程锁
1. 多进程简介
1.1 进程的概念
我们编写的代码只是一个存储在硬盘的静态文件,通过编译后就会生成二进制可执行文件,当我们运行这个可执行文件后,它会被装载到内存中,接着 CPU 会执行程序中的每一条指令,那么这个运行中的程序,就被称为「进程」。进程除了包含代码以外,还有需要运行的环境等,所以和程序是有区别的。
现在我们考虑有一个会读取硬盘文件数据的程序被执行了,那么当运行到读取文件的指令时,就会去从硬盘读取数据,但是硬盘的读写速度是非常慢的,那么在这个时候,如果 CPU 傻傻的等硬盘返回数据的话,那 CPU 的利用率是非常低的。
做个类比,你去煮开水时,你会傻傻的等水壶烧开吗?很明显,小孩也不会傻等。我们可以在水壶烧开之前去做其他事情。当水壶烧开了,我们自然就会听到“嘀嘀嘀”的声音,于是再把烧开的水倒入到水杯里就好了。
所以,当进程要从硬盘读取数据时,CPU 不需要阻塞等待数据的返回,而是去执行另外的进程。当硬盘数据返回时,CPU 会收到个中断,于是 CPU 再继续运行这个进程。
进程是一个内核级的实体,进程结构的所有成分都在内核空间中,一个用户程序不能直接访问这些数据。
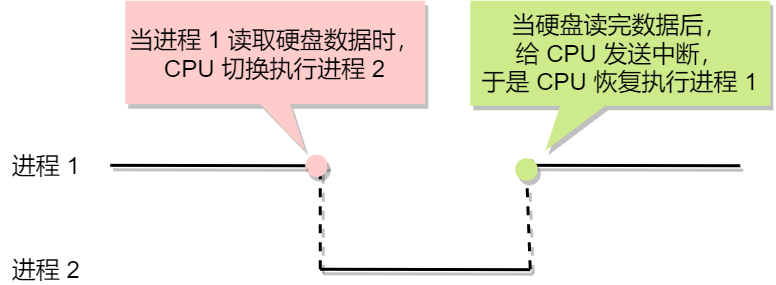
这种多个程序、交替执行的思想,就有 CPU 管理多个进程的初步想法。
对于一个支持多进程的系统,CPU 会从一个进程快速切换至另一个进程,其间每个进程各运行几十或几百个毫秒。
虽然单核的 CPU 在某一个瞬间,只能运行一个进程。但在 1 秒钟期间,它可能会运行多个进程,这样就产生并行的错觉,实际上这是并发。真正的并行执行多任务只能在多核CPU上实现。但是,由于任务数量远远多于 CPU 的核心数量,所以,操作系统也会自动把很多任务轮流调度到每个核心上执行。
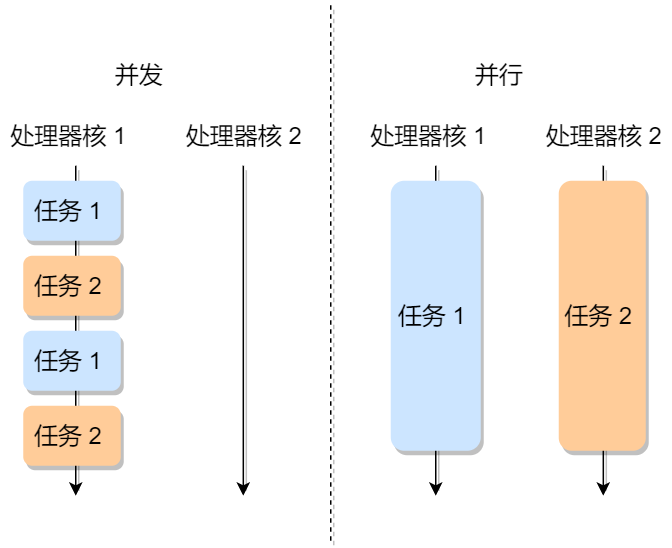
1.2 进程的特征
- 动态性:进程的实质是程序在多任务系统中的一次执行过程,进程是动态产生,动态消亡的。
- 并发性 :任何进程都可以同其他进程一起并发执行。
- 独立性:进程是一个能独立运行的基本单位,同时也是系统分配资源和调度的独立单位。
- 异步性:由于进程间的相互制约,使进程具有执行的间断性,即进程按各自独立的、不可预知的速度执行。
- 结构特征:进程由程序、数据和进程控制块三部分组成。
- 多个不同的进程可以包含相同的程序:一个程序在不同的数据集里就构成不同的进程,能得到不同的结果;但是执行过程中,程序不能发生改变。
1.3 进程的上下文切换
到了晚饭时间,一对小情侣肚子都咕咕叫了,于是男生见机行事,就想给女生做晚饭,所以他就在网上找了辣子鸡的菜谱,接着买了一些鸡肉、辣椒、香料等材料,然后边看边学边做这道菜。
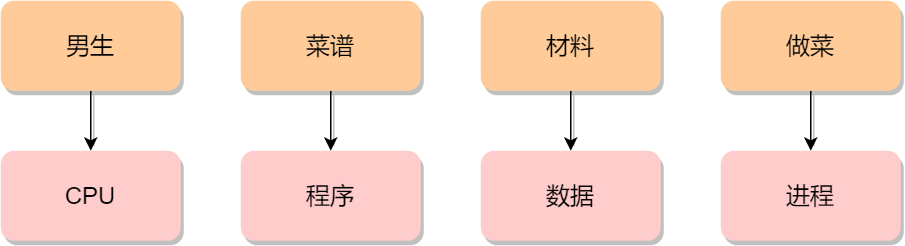
突然,女生说她想喝可乐,那么男生只好把做菜的事情暂停一下,并在手机菜谱标记做到哪一个步骤,把状态信息记录了下来。
然后男生听从女生的指令,跑去下楼买了一瓶冰可乐后,又回到厨房继续做菜。
这体现了,CPU 可以从一个进程(做菜)切换到另外一个进程(买可乐),在切换前必须要记录当前进程中运行的状态信息,以备下次切换回来的时候可以恢复执行。
所以,可以发现进程有着「运行 - 暂停 - 运行」的活动规律。
首先来了解什么是内核
计算机是由各种外部硬件设备组成的,比如内存、CPU、硬盘等,如果每个应用都要和这些硬件设备对接通信协议,那这样太累了。
所以,这个中间人就由内核来负责,让内核作为应用连接硬件设备的桥梁,应用程序只需关心与内核交互,不用关心硬件的细节。
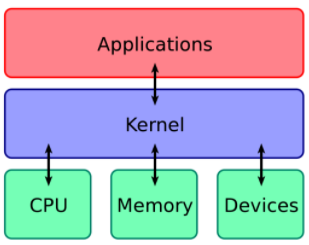
内核有哪些能力呢?
现代操作系统的内核一般会提供 4 个基本能力:
-
管理进程、线程,决定哪个进程、线程使用 CPU,也就是进程调度的能力。
-
管理内存,决定内存的分配和回收,也就是内存管理的能力。
-
管理硬件设备,为进程与硬件设备之间提供通信能力,也就是硬件通信能力。
-
提供系统调用,如果应用程序要运行更高权限运行的服务,那么就需要有系统调用,它是用户程序与操作系统之间的接口。
内核是怎么工作的?
内核具有很高的权限,可以控制 CPU、内存、硬盘等硬件,而应用程序具有的权限很小,因此大多数操作系统,把内存分成了两个区域:
-
内核空间,这个内存空间只有内核程序可以访问。
-
用户空间,这个内存空间专门给应用程序使用。
用户空间的代码只能访问一个局部的内存空间,而内核空间的代码可以访问所有内存空间。
因此,当程序使用用户空间时,我们常说该程序在用户态执行,而当程序使内核空间时,程序则在内核态执行。
应用程序如果需要进入内核空间,就需要通过「系统调用」,下面来看看系统调用的过程:
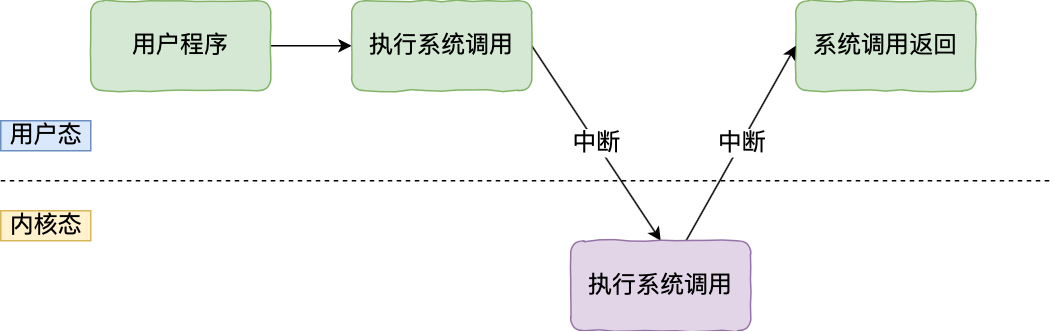
内核程序执行在内核态,用户程序执行在用户态。当应用程序使用系统调用时,会产生一个中断。发生中断后, CPU 会中断当前在执行的用户程序,转而跳转到中断处理程序,也就是开始执行内核程序。内核处理完后,主动触发中断,把 CPU 执行权限交回给用户程序,回到用户态继续工作。
在详细说进程上下文切换前,我们先来看看 CPU 上下文切换
大多数操作系统都是多任务,通常支持大于 CPU 数量的任务同时运行。实际上,这些任务并不是同时运行的,只是因为系统在很短的时间内,让各个任务分别在 CPU 运行,于是就造成同时运行的错觉。
任务是交给 CPU 运行的,那么在每个任务运行前,CPU 需要知道任务从哪里加载,又从哪里开始运行。
所以,操作系统需要事先帮 CPU 设置好 CPU 寄存器和程序计数器。
- CPU 寄存器:是 CPU 内部一个容量小,但是速度极快的内存(缓存)。举个例子,寄存器像是你的口袋,内存像你的书包,硬盘则是你家里的柜子,如果你的东西存放到口袋,那肯定是比你从书包或家里柜子取出来要快的多。
- 程序计数器:则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。
所以说,CPU 寄存器和程序计数器是 CPU 在运行任何任务前,所必须依赖的环境,这些环境就叫做 CPU 上下文。
既然知道了什么是 CPU 上下文,那理解 CPU 上下文切换就不难了。
CPU 上下文切换就是先把前一个任务的 CPU 上下文(CPU 寄存器和程序计数器中的中间数据)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
系统内核会存储保存下来的上下文信息,当此任务再次被分配给 CPU 运行时,CPU 会重新加载这些上下文,这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
上面说到所谓的「任务」,主要包含进程、线程和中断。所以,可以根据任务的不同,把 CPU 上下文切换分成:进程上下文切换、线程上下文切换和中断上下文切换。
什么是进程的上下文切换?
各个进程之间是共享 CPU 资源的,在不同的时候进程之间需要切换,让不同的进程可以在 CPU 执行,那么一个进程切换到另一个进程运行,称为进程的上下文切换。
进程是由内核管理和调度的,所以进程的切换只能发生在内核态。所以,进程的上下文切换不仅包含了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的资源。
通常,会把交换的信息保存在进程的 PCB,当要运行另外一个进程的时候,我们需要从这个进程的 PCB 取出上下文,然后恢复到 CPU 中,这使得这个进程可以继续执行,如下图所示:
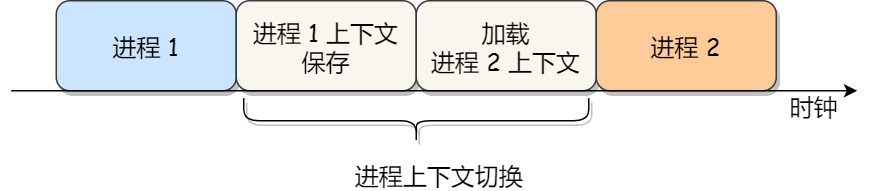
进程的上下文切换就是从正在运行的进程中收回 CPU,然后再使待运行进程来占用 CPU。这里所说的从某个进程收回处理器,实质上就是把进程存放在 CPU 寄存器中的中间数据找个地方存起来,从而把 CPU 的寄存器腾出来让其他进程使用。那么被中止运行进程的中间数据存在何处好呢?当然这个地方应该是进程的私有堆栈。
让进程来占用处理器,实质上是把某个进程存放在私有堆栈中的寄存器的数据(前一次本进程被中止时的中间数据)再恢复到处理器的寄存器中去,并把待运行进程的断点送入处理器的程序指针,于是待运行进程就开始被处理器运行了,也就是这个进程已经占有处理器的使用权了。
这就像多个同学要分时使用同一张课桌一样,所谓要收回正在使用课桌同学的课桌使用权,实质上就是让他把属于他的东西拿走;而赋予某个同学课桌使用权,只不过就是让他把他的东西放到课桌上罢了。
在切换时,一个进程存储在处理器各寄存器中的中间数据叫做进程的上下文,所以进程的切换实质上就是被中止运行进程与待运行进程上下文的切换。在进程未占用处理器时,进程的上下文是存储在进程的私有堆栈中的。
需要注意的是,进程的上下文开销是很关键的,我们希望它的开销越小越好,这样可以使得进程可以把更多时间花费在执行程序上,而不是耗费在上下文切换。
发生进程上下文切换的常见场景
- 为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待 CPU 的进程运行。
- 进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行。
- 当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度。
- 当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
- 发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。
1.4 进程的状态
我们知道了进程有着「运行 - 暂停 - 运行」的活动规律。一般说来,一个进程并不是自始至终连续不停地运行的,它与并发执行中的其他进程的执行是相互制约的。
它有时处于运行状态,有时又由于某种原因而暂停运行处于等待状态,当使它暂停的原因消失后,它又进入准备运行状态。
所以,在一个进程的活动期间至少具备三种基本状态,即运行状态、就绪状态、阻塞状态。
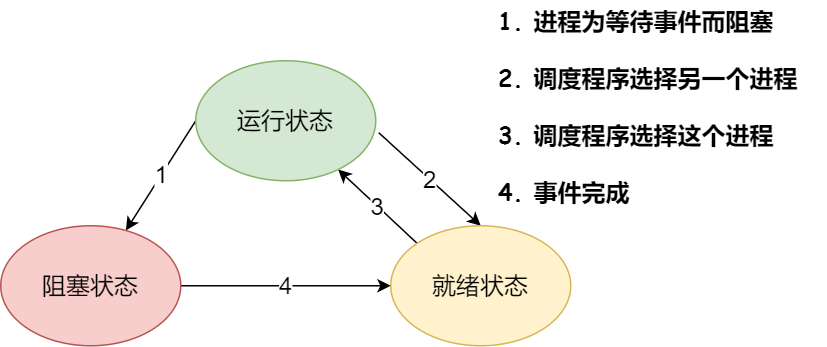
上图中各个状态的意义:
- 运行状态(Runing):进程占用处理器资源;处于此状态的进程的数目小于等于处理器的数目。在没有其他进程可以执行时(如所有进程都在阻塞状态),通常会自动执行系统的空闲进程。
- 就绪状态(Ready):进程已获得除处理器外的所需资源,等待分配处理器资源,只要分配了处理器进程就可执行。就绪进程可以按多个优先级来划分队列。例如,当一个进程由于时间片用完而进入就绪状态时,排入低优先级队列;当进程由I/O操作完成而进入就绪状态时,排入高优先级队列。
- 阻塞状态(Blocked):由于进程等待某种条件(如I/O操作或进程同步),在条件满足之前,即使给它CPU控制权,它也无法运行。
当然,进程另外两个基本状态:
- 创建状态(new):进程正在被创建时的状态。
- 结束状态(Exit):进程正在从系统中消失时的状态。
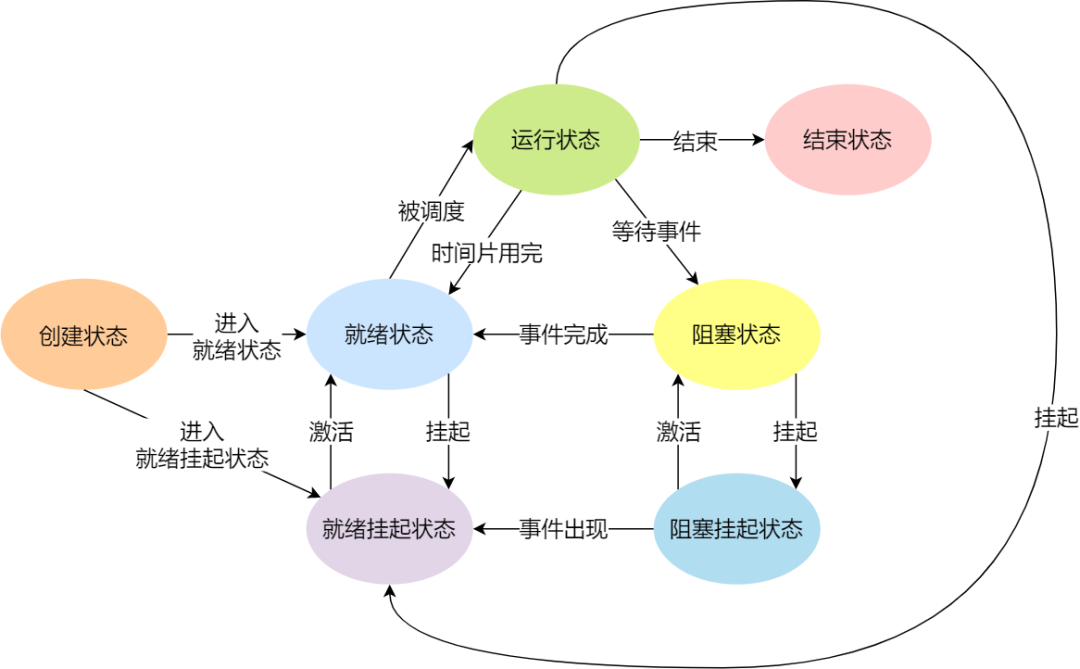
于是,一个完整的进程状态的变迁如下图:
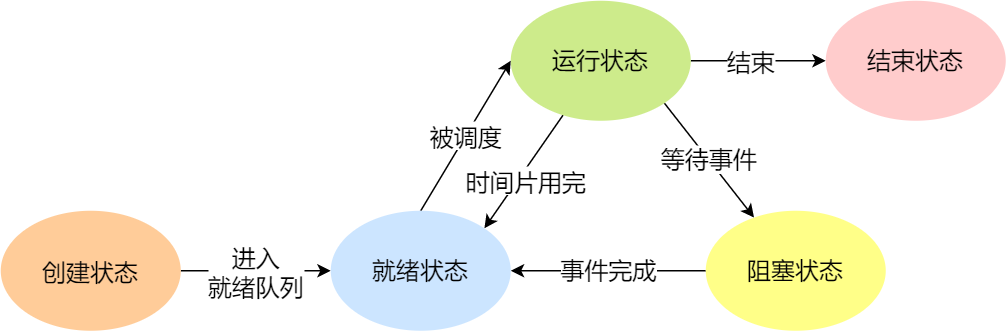
再来详细说明一下进程的状态变迁:
- NULL -> 创建状态:一个新进程被创建时的第一个状态;
- 创建状态 -> 就绪状态:当进程被创建完成并初始化后,一切就绪准备运行时,变为就绪状态,这个过程是很快的;
- 就绪态 -> 运行状态:处于就绪状态的进程被操作系统的进程调度器选中后,就分配给 CPU 正式运行该进程;
- 运行状态 -> 结束状态:当进程已经运行完成或出错时,会被操作系统作结束状态处理;
- 运行状态 -> 就绪状态:处于运行状态的进程在运行过程中,由于分配给它的运行时间片用完,操作系统会把该进程变为就绪态,接着从就绪态选中另外一个进程运行;
- 运行状态 -> 阻塞状态:当进程请求某个事件且必须等待时,例如请求 I/O 事件;
- 阻塞状态 -> 就绪状态:当进程要等待的事件完成时,它从阻塞状态变到就绪状态;
另外,还有一个状态叫挂起状态,它表示进程没有占有物理内存空间,在操作系统中可以定义为暂时被淘汰出内存的进程。这跟阻塞状态是不一样,阻塞状态是等待某个事件的返回。机器的资源是有限的,在资源不足的情况下,操作系统对在内存中的程序进行合理的安排,其中有的进程被暂时调离出内存,当条件允许的时候,会被操作系统再次调回内存,重新进入等待被执行的状态即就绪态。
由于虚拟内存管理原因,进程的所使用的空间可能并没有映射到物理内存,而是在硬盘上,这时进程就会出现挂起状态,另外,调用 sleep 也会被挂起。
挂起状态可以分为两种:
- 阻塞挂起状态:进程在外存(硬盘)并等待某个事件的出现。
- 就绪挂起状态:进程在外存(硬盘),但只要进入内存,即刻立刻运行。
这两种挂起状态加上前面的五种状态,就变成了七种状态变迁,见如下图:
1.5 进程控制块
在操作系统中,是用进程控制块(process control block,PCB)数据结构来描述进程的。
PCB 是进程存在的唯一标识,这意味着一个进程的存在,必然会有一个 PCB,如果进程消失了,那么 PCB 也会随之消失。
PCB 具体包含什么信息呢?
进程描述信息:
- 进程标识符:标识各个进程,每个进程都有一个并且唯一的标识符;
- 用户标识符:进程归属的用户,用户标识符主要为共享和保护服务;
进程控制和管理信息:
- 进程当前状态,如 new、ready、running、waiting 或 blocked 等;
- 进程优先级:进程抢占 CPU 时的优先级;
资源分配清单:
- 有关内存地址空间或虚拟地址空间的信息,所打开文件的列表和所使用的 I/O 设备信息。
CPU 相关信息:
- CPU 中各个寄存器的值,当进程被切换时,CPU 的状态信息都会被保存在相应的 PCB 中,以便进程重新执行时,能从断点处继续执行。
可见,PCB 包含信息还是比较多的。
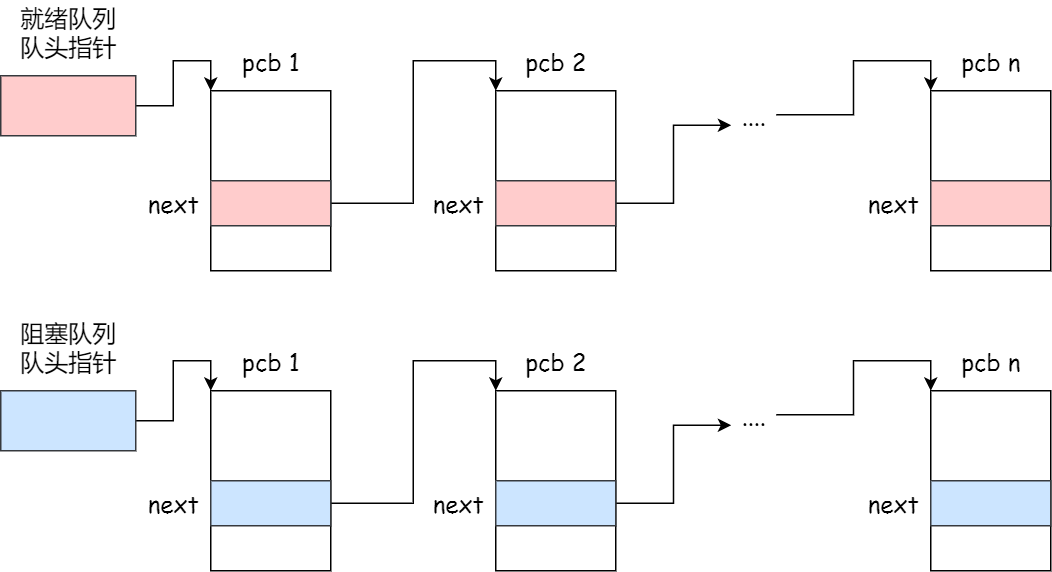
每个 PCB 是如何组织的呢?
通常是通过链表的方式进行组织,把具有相同状态的进程链在一起,组成各种队列。比如:
- 将所有处于就绪状态的进程链在一起,称为就绪队列;
- 把所有因等待某事件而处于等待状态的进程链在一起就组成各种阻塞队列;
- 另外,对于运行队列,在单核 CPU 系统中则只有一个运行指针了,因为单核 CPU 在某个时间,只能运行一个程序。
那么,就绪队列和阻塞队列链表的组织形式如下图:
除了链接的组织方式,还有索引方式,它的工作原理:将同一状态的进程组织在一个索引表中,索引表项指向相应的 PCB,不同状态对应不同的索引表。
一般会选择链表,因为可能面临进程创建,销毁等调度导致进程状态发生变化,所以链表能够更加灵活的插入和删除。
1.6 进程的控制
我们熟知了进程的状态变迁和进程的数据结构 PCB 后,再来看看进程的创建、终止、阻塞、唤醒的过程,这些过程也就是进程的控制。
01 创建进程
操作系统允许一个进程创建另一个进程,而且允许子进程继承父进程所拥有的资源,当子进程被终止时,其在父进程处继承的资源应当还给父进程。同时,终止父进程时同时也会终止其所有的子进程。
创建进程的过程如下:
- 为新进程分配一个唯一的进程标识号,并申请一个空白的 PCB。PCB 是有限的,若申请失败则创建失败;
- 为进程分配资源。为新进程的程序和数据以及用户栈分配必要的内存空间。显然,此时操作系统必须知道新进程所需要的内存大小。此处如果资源不足,进程就会进入等待状态,以等待资源;
- 初始化 PCB,包括:
- 初始化标识信息, 将系统分配的标识符和父进程标识符, 填入新的 PCB 中;
- 初始化处理机状态信息, 使程序计数器指向程序的入口地址, 使栈指针指向栈顶;
- 初始化处理机控制信息, 将进程的状态设置为就绪状态或静止就绪状态, 对于优先级, 通常是将它设置为最低优先级, 除非用户以显式的方式提出高优先级要求。
- 如果进程的调度队列能够接纳新进程,那就将进程插入到就绪队列,等待被调度运行。
02 终止进程
进程可以有 3 种终止方式:正常结束、异常结束以及外界干预:
- 正常结束:在任何计算机系统中,都应该有一个表示进程已经运行完成的指示。例如,在批处理系统中,通常在程序的最后安排一条 Hold 指令或终止的系统调用。当程序运行到 Hold 指令时,将产生一个中断,去通知 OS 本进程已经完成。
- 异常结束:在进程运行期间,由于出现某些错误和故障而迫使进程终止。这类异常事件很多,常见的有:越界错误,保护错,非法指令,特权指令错,运行超时,等待超时,算术运算错,I/O故障。
- 外界干预:外界干预并非指在本进程运行中出现了异常事件,而是指进程应外界的请求而终止运行。这些干预有:操作员或操作系统干预(如信号 kill 掉),父进程请求,父进程终止。
终止进程的过程如下:
- 查找需要终止的进程的 PCB;
- 如果处于执行状态,则立即终止该进程的执行,然后将 CPU 资源分配给其他进程;
- 如果其还有子孙进程,则应将其所有子孙进程终止,以防他们成为不可控的进程;
- 将该进程所拥有的全部资源都归还给父进程或操作系统;
- 将其从 PCB 所在队列中删除。
03 阻塞进程
引起进程阻塞和唤醒的事件:
- 请求系统服务:当正在执行的进程请求操作系统提供服务时,由于某种原因,操作系统并不立即满足该进程的要求时,该进程只能转变为阻塞状态来等待,一旦要求得到满足后,进程被唤醒。
- 启动某种操作:当进程启动某种操作后,如果该进程必须在该操作完成之后才能继续执行,则必须先使该进程阻塞,以等待该操作完成,该操作完成后,将该进程唤醒。
- 新数据尚未到达:对于相互合作的进程,如果其中一个进程需要先获得另一(合作)进程提供的数据才能运行以对数据进行处理,则是要其所需数据尚未到达,该进程只有(等待)阻塞,等到数据到达后,该进程被唤醒。
- 无新工作可做:系统往往设置一些具有某特定功能的系统进程,每当这种进程完成任务后,便把自己阻塞起来以等待新任务到来,新任务到达后,该进程被唤醒。
正在执行的进程,当发现上述某事件后,由于无法继续执行,于是进程便通过调用阻塞原语block把自己阻塞。可见,进程的阻塞是进程自身的一种主动行为。进入block过程后,由于此时该进程还处于执行状态,所以应先立即停止执行,把进程控制块中的现行状态由执行改为阻塞,并将PCB插入阻塞队列。如果系统中设置了因不同事件而阻塞的多个阻塞队列,则应将本进程插入到具有相同事件的阻塞(等待)队列。最后,调度程序进行重新调度,将处理机分配给另一就绪进程,并进行切换。一旦被阻塞等待,它只能由另一个进程唤醒。
阻塞进程的过程如下:
- 找到将要被阻塞进程标识号对应的 PCB;
- 如果该进程为运行状态,则保护其现场,将其状态转为阻塞状态,停止运行;
- 将该 PCB 插入的阻塞队列中去。
04 唤醒进程
进程由「运行」转变为「阻塞」状态是由于进程必须等待某一事件的完成,所以处于阻塞状态的进程是绝对不可能叫醒自己的。
如果某进程正在等待 I/O 事件,需由别的进程发消息给它,则只有当该进程所期待的事件出现时,才由发现者进程用唤醒语句叫醒它。
唤醒进程的过程如下:
- 在该事件的阻塞队列中找到相应进程的 PCB;
- 将其从阻塞队列中移出,并置其状态为就绪状态;
- 把该 PCB 插入到就绪队列中,等待调度程序调度。
进程的阻塞和唤醒是一对功能相反的语句,如果某个进程调用了阻塞语句,则必有一个与之对应的唤醒语句。
2. 进程的创建-multiprocessing.Process
multiprocessing 模块是跨平台版本的多进程管理包,支持子进程、通信和共享数据、执行不同形式的同步。
这个模块表示像线程一样管理进程,这个是 multiprocessing 的核心,它与 threading 很相似,对多核 CPU 的利用率会比 threading 好的多。
multiprocessing 模块提供了一个 Process 类来代表一个进程对象,下面的例子演示了启动一个子进程并等待其结束:
1 from multiprocessing import Process 2 import os 3 4 5 # 子进程要执行的代码 6 def run_proc(name): 7 print("子进程{}运行中,pid={};父进程:ppid={}".format(name, os.getpid(), os.getppid())) 8 9 if __name__=="__main__": 10 print("父进程:{}".format(os.getpid())) 11 p = Process(target=run_proc, args=("test",)) 12 print("子进程将要执行") 13 p.start() # 让子进程开始执行run_proc函数的代码,函数执行完后即子进程也结束 14 p.join() # 堵塞:等待该子进程执行完后,才会继续往下执行 15 print("子进程已结束") 16 17 # 主进程等Process创建的所有子进程执行完后,才会结束
执行结果:
父进程:1420 子进程将要执行 子进程test运行中,pid=6080;父进程:ppid=1420 子进程已结束
Process([group [, target [, name [, args [, kwargs]]]]]) 类
- target:表示这个进程实例所调用对象,一般为函数
- args:表示调用对象的位置参数元组
- kwargs:表示调用对象的关键字参数字典
- name:为当前进程实例的别名
- group:进程所属组,大多数情况下用不到
Process类常用方法
- is_alive():判断进程实例是否还在执行
- join([timeout]):是否等待进程实例执行结束,或等待多少秒
- start():启动进程实例(创建子进程)
- run():如果没有给定target参数,对这个对象调用start()方法时,就将执行对象中的run()方法
- terminate():不管任务是否完成,立即终止
Process类常用属性
- name:当前进程实例别名,默认为Process-N,N为从1开始递增的整数
- pid:当前进程实例的PID值
示例:传入字典
1 from multiprocessing import Process 2 import os 3 import time 4 5 6 # 子进程要执行的代码 7 def run_proc(name, age, **kwargs): 8 # 让子进程执行足够多的时间 9 for i in range(10): 10 print("子进程运行中:name={}, age={}, pid={}".format(name, age, os.getpid())) 11 print(kwargs) 12 13 if __name__=="__main__": 14 print("父进程:{}".format(os.getpid())) 15 p = Process(target=run_proc, args=("test", 18), kwargs={"m":20}) 16 print("子进程将要执行") 17 p.start() 18 time.sleep(0.3) 19 p.terminate() 20 print("子进程已结束")
执行结果:
父进程:2636 子进程将要执行 子进程运行中:name=test, age=18, pid=11560 {'m': 20} 子进程运行中:name=test, age=18, pid=11560 {'m': 20} 子进程运行中:name=test, age=18, pid=11560 {'m': 20} 子进程已结束
示例:两个子进程
1 from multiprocessing import Process 2 import time 3 import os 4 5 6 def worker_1(interval): 7 print("worker_1,父进程:{},当前进程:{}".format(os.getppid(), os.getpid())) 8 t_start = time.time() 9 time.sleep(interval) 10 t_end = time.time() 11 print("worker_1 整体执行时间为%.2f秒" % (t_end - t_start)) 12 13 14 def worker_2(interval): 15 print("worker_2,父进程:{},当前进程:{}".format(os.getppid(), os.getpid())) 16 t_start = time.time() 17 time.sleep(interval) 18 t_end = time.time() 19 print("worker_2 整体执行时间为%.2f秒" % (t_end - t_start)) 20 21 if __name__ == "__main__": 22 23 # 输出当前主进程的id 24 print("进程ID:{}".format(os.getpid())) 25 26 p1 = Process(target=worker_1, args=(2,)) 27 p2 = Process(target=worker_2, name="worker2", args=(1,)) 28 29 p1.start() 30 p2.start() 31 32 # 同时主进程仍在往下执行,如果p2进程还在执行,返回True 33 print("p2 is alive = {}".format(p2.is_alive())) 34 35 # 输出p1和p2进程的别名和pid 36 print("p1.name=%s" % p1.name) 37 print("p1.pid=%s" % p1.pid) 38 print("p2.name=%s" % p2.name) 39 print("p2.pid=%s" % p2.pid) 40 41 p1.join() 42 print("p1.is_alive=%s" % p1.is_alive())
执行结果:
进程ID:6572 p2 is alive = True p1.name=Process-1 p1.pid=4716 p2.name=worker2 p2.pid=14936 worker_1,父进程:6572,当前进程:4716 worker_2,父进程:6572,当前进程:14936 worker_2 整体执行时间为1.02秒 worker_1 整体执行时间为2.02秒 p1.is_alive=False
注意:若以上执行代码未在 if __name__ == "__main__:" 中,会出现RuntimeError,错误提示如下:
An attempt has been made to start a new process before the current process has finished its bootstrapping phase. This probably means that you are not using fork to start your child processes and you have forgotten to use the proper idiom in the main module: if __name__ == '__main__': freeze_support() ... The "freeze\_support()" line can be omitted if the program is not going to be frozen to produce an executable.
简单解释
由于Python运行过程中,新创建进程后,进程会导入正在运行的文件,即代码在运行到 Process() 时,新的进程会重新读入该代码,对于没有 if __name__=="__main__" 保护的代码,新进程都认为是要再次运行的代码,这时子进程又一次运行 Process(),但是在 multiprocessing.Process 的源码中是对子进程再次产生子进程是做了限制的,是不允许的,于是出现如上的错误提示。
3. 进程的创建-Process子类
创建新的进程还能够使用类的方式,可以自定义一个类,继承Process类,每次实例化这个类的时候,就等同于实例化一个进程对象。
示例:
1 from multiprocessing import Process 2 import time 3 import os 4 5 6 class ProcessClass(Process): 7 8 def __init__(self, interval): 9 Process.__init__(self) 10 self.interval = interval 11 12 def run(self): 13 print("子进程(%d)开始执行,父进程为%d" % (os.getpid(), os.getppid())) 14 t_start = time.time() 15 time.sleep(self.interval) 16 t_end = time.time() 17 print("子进程(%d)执行结束,执行时间为%.2f秒" % (os.getpid(), t_end-t_start)) 18 19 20 if __name__ == "__main__": 21 print("当前主进程(%d)" % os.getpid()) 22 t_start = time.time() 23 p = ProcessClass(1) 24 # 对一个不包含target属性的Process类执行start()方法,就会运行这个类中的run()方法,所以这里会执行p1.run() 25 p.start() 26 p.join() 27 t_end = time.time() 28 print("当前主进程(%d)执行结束,执行时间为%.2f秒"%(os.getpid(), t_end-t_start))
执行结果:
当前主进程(764) 子进程(10256)开始执行,父进程为764 子进程(10256)执行结束,执行时间为1.02秒 当前主进程(764)执行结束,执行时间为1.37秒
4. 进程池-Pool
当需要创建的子进程数量不多时,可以直接利用 multiprocessing 中的 Process 动态成生多个进程,但如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到 multiprocessing 模块提供的 Pool 方法。
初始化 Pool 时,可以指定一个最大进程数,当有新的请求提交到 Pool 中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来执行。
示例:apply_async 非阻塞型
1 from multiprocessing import Pool 2 import os 3 import time 4 import random 5 6 7 # 定义子进程函数 8 def worker(msg): 9 t_start = time.time() 10 print("进程(%s)开始执行,id=%d" % (msg, os.getpid())) 11 # random.random():随机生成0~1之间的浮点数 12 time.sleep(random.random()*2) 13 t_end = time.time() 14 print("进程(%s)执行完毕,耗时%.2f秒" % (msg, t_end-t_start)) 15 16 17 if __name__ == "__main__": 18 # 创建一个进程池,最大进程数为3 19 po = Pool(3) 20 # 每次循环将会用空闲出来的子进程去调用目标函数 21 for i in range(10): 22 # apply_async(要调用的目标函数, (传递给函数的参数元组,)) 23 po.apply_async(worker, (i,)) 24 25 print("------start------") 26 po.close() # 关闭进程池,关闭后po不再接收新的请求 27 po.join() # 等到po中所有子进程执行完成。必须放在close语句之后 28 print("-------end-------")
执行结果:
------start------ 进程(0)开始执行,id=4276 进程(1)开始执行,id=12064 进程(2)开始执行,id=5444 进程(0)执行完毕,耗时0.39秒 进程(3)开始执行,id=4276 进程(3)执行完毕,耗时0.47秒 进程(4)开始执行,id=4276 进程(2)执行完毕,耗时1.05秒 进程(5)开始执行,id=5444 进程(1)执行完毕,耗时1.41秒 进程(6)开始执行,id=12064 进程(6)执行完毕,耗时0.06秒 进程(7)开始执行,id=12064 进程(4)执行完毕,耗时0.66秒 进程(8)开始执行,id=4276 进程(5)执行完毕,耗时0.56秒 进程(9)开始执行,id=5444 进程(7)执行完毕,耗时0.19秒 进程(8)执行完毕,耗时0.80秒 进程(9)执行完毕,耗时1.05秒 -------end-------
multiprocessing.Pool 常用函数解析:
- apply_async(func[, args[, kwds]]) :使用非阻塞方式调用func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args为传递给func的参数列表,kwds为传递给func的关键字参数列表。
- apply(func[, args[, kwds]]):使用阻塞方式调用func。
- close():关闭Pool,使其不再接受新的任务。
- terminate():不管任务是否完成,立即终止。
- join():主进程阻塞,等待子进程的退出, 必须在close或terminate之后使用。
示例:apply 阻塞型
1 from multiprocessing import Pool 2 import os 3 import time 4 import random 5 6 7 # 定义子进程函数 8 def worker(msg): 9 t_start = time.time() 10 print("进程(%s)开始执行,id=%d" % (msg, os.getpid())) 11 # random.random():随机生成0~1之间的浮点数 12 time.sleep(random.random()*2) 13 t_end = time.time() 14 print("进程(%s)执行完毕,耗时%.2f秒" % (msg, t_end-t_start)) 15 16 17 if __name__ == "__main__": 18 # 创建一个进程池,最大进程数为3 19 po = Pool(3) 20 # 每次循环将会用空闲出来的子进程去调用目标函数 21 for i in range(10): 22 po.apply(worker, (i,)) 23 24 print("------start------") 25 po.close() # 关闭进程池,关闭后po不再接收新的请求 26 po.join() # 等到po中所有子进程执行完成。必须放在close语句之后 27 print("-------end-------")
执行结果:
进程(0)开始执行,id=3260 进程(0)执行完毕,耗时1.67秒 进程(1)开始执行,id=8788 进程(1)执行完毕,耗时0.58秒 进程(2)开始执行,id=14492 进程(2)执行完毕,耗时1.67秒 进程(3)开始执行,id=3260 进程(3)执行完毕,耗时1.12秒 进程(4)开始执行,id=8788 进程(4)执行完毕,耗时1.48秒 进程(5)开始执行,id=14492 进程(5)执行完毕,耗时1.55秒 进程(6)开始执行,id=3260 进程(6)执行完毕,耗时0.08秒 进程(7)开始执行,id=8788 进程(7)执行完毕,耗时0.06秒 进程(8)开始执行,id=14492 进程(8)执行完毕,耗时1.41秒 进程(9)开始执行,id=3260 进程(9)执行完毕,耗时1.72秒 ------start------ -------end-------
5. 进程间通信-Queue
每个进程的用户地址空间都是独立的,一般而言是不能互相访问的,但内核空间是每个进程都共享的,所以进程之间要通信必须通过内核。Linux 内核提供了不少进程间通信的机制,如下所示:
- 管道
- 消息队列
- 共享内存
- 信号量
- 信号
- Socket(用得最多)
Queue的使用
可以使用 multiprocessing 模块的 Queue 实现多进程之间的数据传递,Queue 本身是一个消息列队程序。
注意,Queue 本身是进程安全的,它是 Blocking Queue,内部有保护。
Queue()对象
- 初始化Queue()对象时(例如:q=Queue()),若括号中没有指定最大可接收的消息数量,或数量为负值,那么就代表可接受的消息数量没有上限(直到内存的尽头)。
- Queue.qsize():返回当前队列包含的消息数量。
- Queue.empty():如果队列为空,返回True,反之False。
- Queue.full():如果队列满了,返回True,反之False。
- Queue.get([block[, timeout]]):获取队列中的一条消息,然后将其从列队中移除,block默认值为True。
- 如果block使用默认值True,且没有设置timeout(单位秒),消息列队如果为空,此时程序将被阻塞(停在读取状态),直到从消息列队读到消息为止,如果设置了timeout,则会等待timeout秒,若还没读取到任何消息,则抛出"Queue.Empty"异常。
- 如果block值为False,消息列队如果为空,则会立刻抛出"Queue.Empty"异常。
- Queue.get_nowait():相当Queue.get(False)。
- Queue.put(item,[block[, timeout]]):将item消息写入队列,block默认值为True。
- 如果block使用默认值True,且没有设置timeout(单位秒),消息列队如果已经没有空间可写入,此时程序将被阻塞(停在写入状态),直到从消息列队腾出空间为止,如果设置了timeout,则会等待timeout秒,若还没空间,则抛出"Queue.Full"异常。
- 如果block值为False,消息列队如果没有空间可写入,则会立刻抛出"Queue.Full"异常。
- Queue.put_nowait(item):相当Queue.put(item, False)。
示例1:消息的读写
1 from multiprocessing import Queue 2 3 4 # 初始化一个Queue对象,最多可接收3条消息 5 q = Queue(3) 6 q.put("msg1") 7 q.put("msg2") 8 print(q.full()) # 此时消息队列未满,False 9 q.put("msg3") 10 print(q.full()) # True 11 12 13 try: 14 # 堵塞等待2秒,若未能放入新消息,则抛出异常 15 q.put("msg4", True, 2) 16 except: 17 print("消息队列已满,现有消息数量为:%d" % q.qsize()) 18 19 try: 20 q.put_nowait("msg4") 21 except: 22 print("消息队列已满,现有消息数量为:%d" % q.qsize()) 23 24 25 # 推荐方式:写消息时,先判断消息队列是否已满,再写入 26 if not q.full(): 27 q.put_nowait("msg4") 28 29 30 # 读消息时,先判断消息队列是否为空,再读取 31 if not q.empty(): 32 for i in range(q.qsize()): 33 print(q.get_nowait())
执行结果:
False True 消息队列已满,现有消息数量为:3 消息队列已满,现有消息数量为:3 msg1 msg2 msg3
示例2:在父进程中创建两个子进程,一个往 Queue 里写数据,一个从 Queue 里读数据
1 from multiprocessing import Process, Queue 2 import time 3 import os 4 import random 5 6 7 # 写数据进程要执行的函数 8 def write(q): 9 for value in "ABC": 10 print("put '%s' to queue..." % value) 11 if not q.full(): 12 q.put(value) 13 time.sleep(random.random()) 14 15 # 读数据进程要执行的函数 16 def read(q): 17 while True: 18 if not q.empty(): 19 value = q.get(True) 20 print("get '%s' from queue..." % value) 21 time.sleep(random.random()) 22 else: 23 break 24 25 26 if __name__ == "__main__": 27 # 父进程创建Queue,并传给各个子进程 28 q = Queue() 29 pw = Process(target=write, args=(q,)) 30 pr = Process(target=read, args=(q,)) 31 pw.start() 32 pw.join() # 等待pw结束 33 pr.start() 34 pr.join() # 等待pr结束 35 print("所有数据都写入并且读完")
执行结果:
put 'A' to queue... put 'B' to queue... put 'C' to queue... get 'A' from queue... get 'B' from queue... get 'C' from queue... 所有数据都写入并且读完
示例3:进程池中的 Queue
如果要使用Pool创建进程并进行进程间通信,就需要使用multiprocessing.Manager()中的Queue(),而不是multiprocessing.Queue(),否则会得到一条如下的错误信息:
RuntimeError: Queue objects should only be shared between processes through inheritance.
1 from multiprocessing import Pool, Manager 2 import time 3 import os 4 import random 5 6 7 # 写数据进程要执行的函数 8 def write(q): 9 print("写进程(%d)启动,父进程为%d" % (os.getpid(), os.getppid())) 10 for value in "ABC": 11 print("put '%s' to queue..." % value) 12 if not q.full(): 13 q.put(value) 14 time.sleep(random.random()) 15 16 # 读数据进程要执行的函数 17 def read(q): 18 print("读进程(%d)启动,父进程为%d" % (os.getpid(), os.getppid())) 19 while True: 20 if not q.empty(): 21 value = q.get(True) 22 print("get '%s' from queue..." % value) 23 time.sleep(random.random()) 24 else: 25 break 26 27 28 if __name__ == "__main__": 29 print("主进程启动:id=%s" % os.getpid()) 30 # 父进程创建Queue,并传给各个子进程 31 q = Manager().Queue() 32 po = Pool() 33 # 使用阻塞模式创建进程,这样就不需要在reader中使用死循环了,可以让writer完全执行完成后,再用reader去读取 34 po.apply(write, (q, )) 35 po.apply(read, (q, )) 36 po.close() 37 po.join() 38 print("主进程结束:id=%s" % os.getpid()) 39
执行结果:
主进程启动:id=10336 写进程(10776)启动,父进程为10336 put 'A' to queue... put 'B' to queue... put 'C' to queue... 读进程(1340)启动,父进程为10336 get 'A' from queue... get 'B' from queue... get 'C' from queue... 主进程结束:id=10336
6. 异步
异步(async)是相对于同步(sync)而言的:
- 同步:一件事一件事地执行。一定要等上一个任务执行完了,得到结果,才能执行下一个任务。
- 异步:即使上一个任务未执行完,也可以先执行下一个任务,再跳回上一个任务继续执行。
1 from multiprocessing import Pool 2 import time 3 import os 4 5 6 def test(): 7 print("---进程池中的进程---pid=%d, ppid=%d"%(os.getpid(), os.getppid())) 8 for i in range(3): 9 print("---%d---" % i) 10 time.sleep(1) 11 return "haha" 12 13 def test2(arg): 14 print("--callback func--pid=%d" % os.getpid()) 15 print("--callback func--arg=%s" % arg) # 注意子进程的返回值传给了主进程的回调函数 16 17 18 if __name__ == "__main__": 19 pool = Pool() 20 pool.apply_async(func=test, callback=test2) # 只要子进程一执行完,主进程就会马上调用test2(回调函数) 21 time.sleep(5) 22 print("----主进程----pid=%d" % os.getpid()) 23 pool.close() # 进程池不再接收任务 24 pool.join() # 主进程堵塞,等待子进程执行完,才会往下执行
执行效果:
---进程池中的进程---pid=9308, ppid=12108
---0---
---1---
---2---
--callback func--pid=12108
--callback func--arg=haha
----主进程----pid=12108
7. 进程锁
- 线程安全:操作一个数据的时候,不会产生竞争;
- 线程不安全:产生竞争,导致数据操作不对。 线程安全的代码执行效率要比线程不安全的效率差。
线程安全和不安全是针对多线程场景来说的,单线程都是安全的。线程安全通常都是加锁来实现同步。
同理,进程也存在安全问题,以及对应的解决方案——进程锁。
进程锁 代码示例:
1 from multiprocessing import Process, Lock 2 import time 3 4 # 第一种进程锁方式 5 def worker_with(lock): 6 with lock: # 使用with上下文的方式来使用锁 7 for i in range(5): 8 time.sleep(0.5) 9 print("task 1") 10 11 12 # 第二种进程锁方式 13 def worker_not_with(lock): 14 lock.acquire() # 加锁 15 try: 16 for i in range(5): 17 time.sleep(0.5) 18 print("task 2") 19 finally: 20 lock.release() # 释放锁 21 22 23 if __name__ == "__main__": 24 lock = Lock() 25 w = Process(target=worker_with, args=(lock,)) 26 nw = Process(target=worker_not_with, args=(lock,)) 27 w.start() 28 nw.start() 29 w.join() 30 nw.join()
执行结果:
task 1 task 1 task 1 task 1 task 1 task 2 task 2 task 2 task 2 task 2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号