
Python 垃圾回收
1. 对象池
2. 垃圾回收(GC)原理
3. GC 模块
1. 对象池
总结
- 小整数 [-5,257) 共用对象,常驻内存;大整数不共用内存,引用计数为0,销毁。
- 单个字符共用对象,常驻内存。
- 单个单词默认开启 intern 机制,共用对象,引用计数为0时销毁;字符串含有空格、换行符等时,没开启 intern 机制,不共用对象,引用计数为0时则销毁。
- 数值类型和字符串类型在 Python 中都是不可变的,这意味着你无法修改这个对象的值,每次对变量的修改,实际上是创建一个新的对象。
小整数对象池
整数在程序中的使用非常广泛,Python为了优化速度,使用了小整数对象池, 避免为整数频繁申请和销毁内存空间。
Python 对小整数的定义是 [-5, 257) 这些整数对象是提前建立好的,不会被垃圾回收。在一个 Python 的程序中,所有位于这个范围内的整数使用的都是同一个对象.。同理,单个字母也是这样的。
大整数对象池
每一个大整数,均创建一个新的对象。
1 >>> a = 256 2 >>> b = 256 3 >>> id(a) 4 1533081504 5 >>> id(b) 6 1533081504 7 >>> a = 1000 8 >>> b = 1000 9 >>> id(a) 10 11353968 11 >>> id(b) 12 19992672 13 >>> a = 257 14 >>> b = 257 15 >>> id(a) 16 19993056 17 >>> id(b) 18 11353968
intern 机制
1 a1 = "HelloWorld" 2 a2 = "HelloWorld" 3 a3 = "HelloWorld" 4 a4 = "HelloWorld" 5 a5 = "HelloWorld" 6 a6 = "HelloWorld" 7 a7 = "HelloWorld" 8 a8 = "HelloWorld" 9 a9 = "HelloWorld"
Python会不会创建9个对象呢?在内存中会不会开辟9个”HelloWorld”的内存空间呢? 想一下,如果是这样的话,我们写10000个对象,比如a1 = "HelloWorld", ….., a1000 = "HelloWorld", 那岂不是开辟了1000个”HelloWorld”所占的内存空间了呢?如果真这样,内存不就爆了吗?所以python中有这样一个机制——intern 机制,让他只占用一个”HelloWorld”所占的内存空间,靠引用计数去维护何时释放。
1 >>> a = "abcd" 2 >>> b = "abcd" 3 >>> id(a) 4 20034624 5 >>> id(b) 6 20034624 7 >>> del a 8 >>> del b 9 >>> c = "abcd" 10 >>> id(c) 11 20034560 12 >>> # 注意,当字符串中含空格、换行等特殊字符时,即使内容完全相同也会创建新的对象 13 >>> a = "hello world" 14 >>> b = "hello world" 15 >>> id(a) 16 19988672 17 >>> id(b) 18 19988712
2. 垃圾回收(GC)原理
现在的高级语言如 java、c# 等,都采用了垃圾回收(Garbage collection)机制,而不再是 c、c++ 里用户自己管理维护内存的方式。自己管理内存虽然极其自由,可以任意申请内存,但如同一把双刃剑,为内存泄露,悬空指针等 bug 埋下隐患。
对于一个字符串、列表、类甚至数值都是对象,且定位简单易用的语言,自然不会让用户去处理如何分配回收内存的问题。 python 里也同 java 一样采用了垃圾收集机制,不过不一样的是:python 采用的是以引用计数机制为主,以分代回收机制为辅的策略。
GC系统
GC系统所承担的工作远比"垃圾回收"多得多。实际上,它们负责三个重要任务:
- 为新生成的对象分配内存
- 识别垃圾对象
- 从垃圾对象那回收内存
Python 的对象分配
当创建对象时,Python 会立即向操作系统请求内存。当我们创建第二个对象的时候,再次向 OS 请求内存。看起来够简单吧,在我们创建对象的时候,Python 会花些时间为我们找到并分配内存。
实际上 Python 实现了一套自己的内存分配系统,在操作系统堆之上提供了一个抽象层。
2.1 引用计数机制
python里每一个东西都是对象,它们的核心就是一个结构体:PyObject
typedef struct_object { int ob_refcnt; struct_typeobject *ob_type; } PyObject;
PyObject 是每个对象必有的内容,其中 ob_refcnt 就是做为引用计数。当一个对象有新的引用时,它的 ob_refcnt 就会增加,当引用它的对象被删除,它的 ob_refcnt 就会减少。当引用计数为 0 时,该对象生命就结束了。
#define Py_INCREF(op) ((op)->ob_refcnt++) //增加计数 #define Py_DECREF(op) \ //减少计数 if (--(op)->ob_refcnt != 0) \ ; \ else \ __Py_Dealloc((PyObject *)(op))
引用计数机制的优点
- 简单。
- 实时性:一旦没有引用,内存就直接释放了,不用像其他机制等到特定时机。实时性的另一个好处是把处理回收内存的时间分摊到了平时。
引用计数机制的缺点
- 维护引用计数需要消耗资源。
- 出现循环引用时则无法进行回收。
引用计数并不像第一眼看上去那样简单,有许多原因使得许多语言不像 Python 这样使用引用计数 GC 算法:
- 它不好实现。Python 不得不在每个对象内部留一些空间来处理引用数。这样付出了一小点儿空间上的代价。但更糟糕的是,每个简单的操作(像修改变量或引用)都会变成一个更复杂的操作,因为 Python 需要增加一个计数,减少另一个,还可能释放对象。
- 它相对较慢。虽然 Python 随着程序执行 GC 很稳健,但这并不一定更快。Python 不停地更新着众多引用数值。特别是当你不再使用一个大数据结构时,比如一个包含很多元素的列表,Python 可能必须一次性释放大量对象。减少引用数就成了一项复杂的递归过程了。
- 它并不总是奏效的。引用计数不能处理环形数据结构——即含有循环引用的数据结构。
循环引用的示例:
1 list1 = [] 2 list2 = [] 3 list1.append(list2) 4 list2.append(list1)
list1与 list2 相互引用,如果不存在其他对象对它们的引用,list1 与 list2 的引用计数也仍然为 1,所占用的内存永远无法被回收,这将是致命的。 对于如今的强大硬件,资源消耗的缺点尚可接受,但是循环引用导致的内存泄露问题,注定 python 还将引入新的回收机制——分代回收。
2.2 分代回收机制
在Python中的零代(Generation Zero)
我们以一个不是很常见的情况结尾:我们有一个“孤岛”或是一组未使用的、互相指向的对象,但是谁都没有外部引用。换句话说,我们的程序不再使用这些节点对象了,所以我们希望Python的垃圾回收机制能够足够智能去释放这些对象并回收它们占用的内存空间。但是这不可能,因为所有的引用计数都是1而不是0。Python的引用计数算法不能够处理互相指向自己的对象。
这就是为什么Python要引入Generational GC算法的原因!正如Ruby使用一个链表(free list)来持续追踪未使用的、自由的对象一样,Python使用一种不同的链表来持续追踪活跃的对象,Python的内部C代码将其称为零代(Generation Zero)。每次当你创建一个对象或其他什么值的时候,Python会将其加入零代链表:
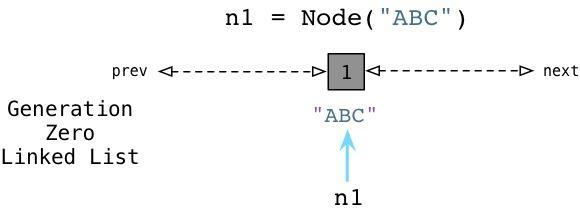
从上边可以看到当我们创建ABC节点的时候,Python将其加入零代链表。请注意到这并不是一个真正的列表,并不能直接在你的代码中访问,事实上这个链表是一个完全内部的Python运行时。 相似的,当我们创建DEF节点的时候,Python将其加入同样的链表:
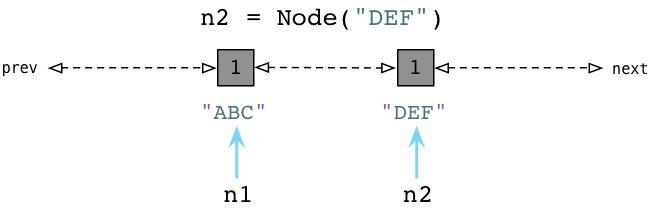
现在零代包含了两个节点对象。(他还将包含Python创建的每个其他值,与一些Python自己使用的内部值。)
检测循环引用
随后,Python会循环遍历零代列表上的每个对象,检查列表中每个互相引用的对象,根据规则减掉其引用计数。在这个过程中,Python会一个接一个的统计内部引用的数量以防过早地释放对象。
为了便于理解,来看一个例子:

从上面可以看到 ABC 和 DEF 节点包含的引用数为1,有三个其他的对象同时存在于零代链表中,蓝色的箭头指示了有一些对象正在被零代链表之外的其他对象所引用。(接下来我们会看到,Python中同时存在另外两个分别被称为一代和二代的链表)。这些对象有着更高的引用计数,因为它们正在被其他指针所指向着。
接下来你会看到Python的GC是如何处理零代链表的:
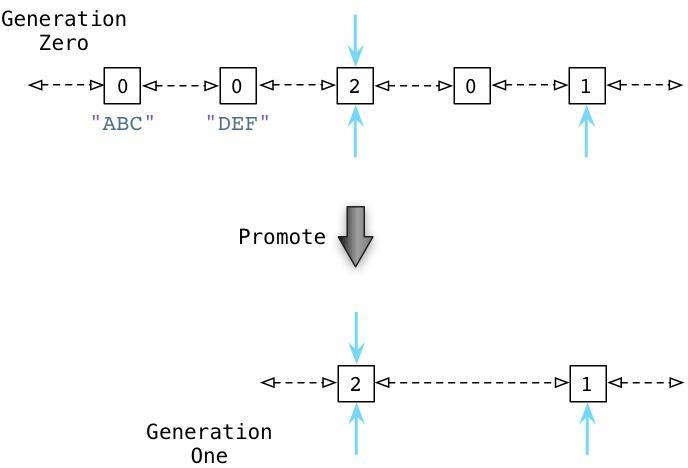
通过识别内部引用,Python能够减少许多零代链表对象的引用计数。在上图的第一行中你能够看见ABC和DEF的引用计数已经变为零了,这意味着收集器可以释放它们并回收内存空间了。剩下的活跃的对象则被移动到一个新的链表:一代链表。即若循环引用的对象的引用计数未减到0时,继续留在零代,而没有循环引用的对象则移动到新一代。
从某种意义上说,Python的GC算法类似于Ruby所用的标记回收算法。周期性地从一个对象到另一个对象追踪引用以确定对象是否还是活跃的、正在被程序所使用的,这正类似于Ruby的标记过程。
Python中的GC阈值
Python什么时候会进行这个标记过程?随着你的程序运行,Python解释器保持对新创建的对象,以及因为引用计数为零而被释放掉的对象的追踪。从理论上说,这两个值应该保持一致,因为程序新建的每个对象都应该最终被释放掉。
当然,事实并非如此。因为循环引用的原因,并且因为你的程序使用了一些比其他对象的存在时间更长的对象,从而被分配对象的计数值与被释放对象的计数值之间的差异在逐渐增长。一旦这个差异累计超过某个阈值,则Python的回收机制就启动了,并且触发上边所说到的零代算法,释放“浮动的垃圾”,并且将剩下的对象移动到一代列表。
随着时间的推移,程序所使用的对象逐渐从零代列表移动到一代列表。而Python对于一代列表中对象的处理遵循同样的方法,一旦被分配计数值与被释放计数值累计到达一定阈值,Python会将剩下的活跃对象移动到二代列表。
通过这种方法,你的代码所长期使用的对象,那些你的代码持续访问的活跃对象,会从零代链表转移到一代再转移到二代。通过不同的阈值设置,Python可以在不同的时间间隔处理这些对象。Python处理零代最为频繁,其次是一代然后才是二代。
弱代假说
来看看代垃圾回收算法的核心行为:垃圾回收器会更频繁的处理新对象。一个新的对象即是你的程序刚刚创建的,而一个老的对象则是经过了几个时间周期之后仍然存在的对象。Python会在当一个对象从零代移动到一代,或是从一代移动到二代的过程中提升(promote)这个对象。
为什么要这么做?这种算法的根源来自于弱代假说(weak generational hypothesis)。这个假说由两个观点构成:首先是年轻的对象通常死得也快,而老的对象则很有可能存活更长的时间。
假定现在用Python或是Ruby创建一个新对象:
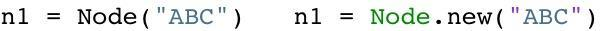
根据假说,我的代码很可能仅仅会使用ABC很短的时间。这个对象也许仅仅只是一个方法中的中间结果,并且随着方法的返回这个对象就将变成垃圾了。大部分的新对象都是如此般地很快变成垃圾。然而,偶尔程序会创建一些很重要的,存活时间比较长的对象(例如web应用中的session变量或是配置项)。
通过频繁的处理零代链表中的新对象,Python的垃圾收集器将把时间花在更有意义的地方:它处理那些很快就可能变成垃圾的新对象。同时只在很少的时候,当满足阈值的条件,收集器才回去处理那些老变量。
3. GC 模块
垃圾回收 = 垃圾检查 + 垃圾回收。这个机制的主要作用就是发现并处理不可达的垃圾对象。
可以通过 import gc 模块,并且 is_enable()=True 启动自动垃圾回收。
Python中的垃圾回收是以引用计数为主,分代回收为辅。
导致引用计数 +1 的情况:
- 对象被创建,例如 a=23
- 对象被引用,例如 b=a
- 对象被作为参数,传入到一个函数中,此时形参指向实参,例如 func(a)
- 对象作为一个元素,存储在容器中,例如 list1=[a, a]
导致引用计数 -1 的情况:
- 对象的别名被显式销毁,例如 del a
- 对象的别名被赋予新的对象,例如 a=24
- 一个对象离开它的作用域,例如 func 函数执行完毕时,func 函数中的局部变量(全局变量不会)
- 对象所在的容器被销毁,或从容器中删除对象
gc模块常用功能解析
gc模块提供一个接口给开发者设置垃圾回收的选项。上面说到,采用引用计数的方法管理内存的一个缺陷是循环引用,而gc模块的一个主要功能就是解决循环引用的问题。
常用函数:
- gc.set_debug(flags):设置gc的debug日志,一般设置为gc.DEBUG_LEAK
- gc.collect([generation]):显式进行垃圾回收,可以输入参数,0代表只检查第一代的对象,1代表检查一,二代的对象,2代表检查一,二,三代的对象,如果不传参数,执行一个full collection,也就是等于传2。 返回不可达(unreachable objects)对象的数目
- gc.get_threshold():获取的gc模块中自动执行垃圾回收的频率。
- gc.set_threshold(threshold0[, threshold1[, threshold2]):设置自动执行垃圾回收的频率。
- gc.get_count():获取当前自动执行垃圾回收的计数器,返回一个长度为3的列表。
查看一个对象的引用计数
1 >>> import sys 2 >>> a = "hello" 3 >>> sys.getrefcount(a) 4 2
查看a对象的引用计数,注意结果值会比正常计数大1,因为调用函数的时候传入a,这会让a的引用计数+1。
循环引用导致内存泄露
引用计数的缺陷是无法处理循环引用的问题。
1 import gc # python3默认开启了gc,即无需导入gc模块也正常运行垃圾回收机制 2 3 class ClassA: 4 def __init__(self): 5 print("obejct born, id:{}".format(str(hex(id(self))))) 6 7 def f2(): 8 while 1: 9 c1 = ClassA() 10 c2 = ClassA() 11 c1.t = c2 12 c2.t = c1 13 del c1 14 del c2 15 16 # 把gc关闭 17 gc.disable() 18 19 f2()
执行 f2(),进程占用的内存会不断增大:
- 创建了c1,c2后,这两块内存的引用计数都是1,执行 c1.t=c2 和 c2.t=c1 后,这两块内存的引用计数变成2。
- 在del c1后,内存1的对象的引用计数变为1,由于不是为0,所以内存1的对象不会被销毁,所以内存2的对象的引用数依然是2,在del c2后,同理,内存1的对象、内存2的对象的引用数都是1。
- 虽然它们两个的对象都是可以被销毁的,但是由于循环引用,导致垃圾回收器都不会回收它们,所以就会导致内存泄露。
执行垃圾回收
1 import gc 2 3 class ClassA: 4 def __init__(self): 5 print("obejct born, id:{}".format(str(hex(id(self))))) 6 7 def f3(): 8 print("----0----") 9 c1 = ClassA() 10 c2 = ClassA() 11 c1.t = c2 12 c2.t = c1 13 print("----1----") 14 del c1 15 del c2 16 print("----2----") 17 print(gc.garbage) # 查看垃圾回收后的对象 18 print("----3----") 19 print(gc.collect()) # 显式执行垃圾回收 20 print("----4----") 21 print(gc.garbage) 22 print("----5----") # 程序执行完并退出时,也会进行垃圾回收 23 24 if __name__ == "__main__": 25 gc.set_debug(gc.DEBUG_LEAK) # 设置gc模块的日志级别 26 f3()
执行结果:
----0---- obejct born, id:0x31d8208 obejct born, id:0x31d83a0 ----1---- ----2---- [] ----3---- gc: collectable <ClassA 0x031D8208> gc: collectable <ClassA 0x031D83A0> gc: collectable <dict 0x00F488C0> gc: collectable <dict 0x031DBB90> 4 ----4---- [<__main__.ClassA object at 0x031D8208>, <__main__.ClassA object at 0x031D83A0>, {'t': <__main__.ClassA object at 0x031D83A0>}, {'t': <__main__.ClassA object at 0x031D8208>}] ----5---- gc: collectable <dict 0x00F182D0> gc: collectable <module 0x00F1D0F0> gc: collectable <dict 0x00F1D118> gc: collectable <builtin_function_or_method 0x00F182A8> ……
说明:
- 垃圾回收后的对象会放在 gc.garbage 列表里面。
- gc.collect() 会返回不可达的对象数目,4等于两个对象以及它们对应的dict。
触发垃圾回收的三种情况
- 调用 gc.collect() 时;
- gc模块的计数器达到阀值时;
- 程序退出时。
gc模块的计数器
在Python中采用分代收集的方法,会把对象分为三代。一开始,对象在创建的时候,放在一代中,如果在一次一代的垃圾检查中,该对象存活下来,就会被放到二代中,同理在一次二代的垃圾检查中,该对象存活下来,就会被放到三代中。
gc模块里面会有一个长度为3的列表的计数器,可以通过 gc.get_count() 获取。
例如(488,3,0),其中488是指距离上一次一代垃圾检查,Python分配内存的数目减去释放内存的数目,注意是内存分配,而不是引用计数的增加。例如:
1 >>> gc.get_count() 2 (581, 9, 0) 3 >>> a = A() 4 >>> gc.get_count() 5 (582, 9, 0) 6 >>> del a 7 >>> gc.get_count() 8 (581, 9, 0)
3是指距离上一次二代垃圾检查期间,一代垃圾检查的次数。同理,0是指距离上一次三代垃圾检查期间,二代垃圾检查的次数。
gc模块的阈值
gc模快有一个自动垃圾回收的阀值,即通过 gc.get_threshold() 函数获取到的长度为3的元组,例如(700,10,10)。每一次计数器的增加,gc模块就会检查增加后的计数是否达到阀值的数目,如果是,就会执行对应的代数的垃圾检查,然后重置计数器。
例如,假设阀值是(700,10,10):
- 当计数器从(699,3,0)增加到(700,3,0),gc模块就会执行gc.collect(0),即检查一代对象的垃圾,并重置计数器为(0,4,0)
- 当计数器从(699,9,0)增加到(700,9,0),gc模块就会执行gc.collect(1),即检查一、二代对象的垃圾,并重置计数器为(0,0,1)
- 当计数器从(699,9,9)增加到(700,9,9),gc模块就会执行gc.collect(2),即检查一、二、三代对象的垃圾,并重置计数器为(0,0,0)
注意点
(python2)gc模块唯一处理不了的是循环引用的类都有 __del__ 方法,所以项目中要避免定义 __del__ 方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号