Python 正则表达式
1. 正则表达式介绍
2. re 模块
3. 匹配单个字符
4. 匹配多个字符
5. 匹配边界
6. 匹配分组
7. re 模块的高级用法
8. 贪婪和非贪婪
9. 修饰符
10. 前/后向断言
1. 正则表达式介绍
正则表达式(英语:Regular Expression,在代码中常简写为 regex、regexp 或 RE),是计算机科学的一个概念,Regular Expression 即“描述某种规则的表达式”之意。
正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。
在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。
2. re 模块
在 Python 中需要通过正则表达式对字符串进行匹配的时候,可以使用一个模块,名字为 re。
基本用法
import re # 使用match方法进行匹配操作 result = re.match(正则表达式, 要匹配的字符串) # 如果上一步匹配到数据的话,可以使用group方法来提取数据 result.group()
-
match():是用来进行正则匹配检查的方法,若字符串匹配正则表达式,则 match 方法返回匹配对象(Match Object),否则返回 None。
-
group():匹配对象 Macth Object 具有 group 方法,用来返回字符串的匹配部分。
示例:
1 >>> import re 2 >>> result = re.match("hello", "hello world") # match() 能够匹配出以xxx开头的字符串 3 >>> result.group() 4 'hello'
原生字符串
-
Python 中字符串前面加上 r 表示原生字符串。
-
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
- Python 里的原生字符串很好地解决了这个问题,有了原始字符串,再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
示例:
1 >>> import re 2 >>> re.match("\\\\home", "\home").group() 3 '\\home' 4 >>> re.match(r"\\home", "\home").group() 5 '\\home'
原理:
- 在原生字符串中,反斜杠依然会对引号进行转义。
- 通过下述的 repr 函数可以清楚地看到,原生字符串中的 \ 是经过自动转义的,因此先还原成 \\,又在输出函数中再次转义成 \
。
1 >>> "\w" 2 '\\w' 3 >>> r"\w" 4 '\\w' 5 >>> "\\w" 6 '\\w' 7 >>> r"\\w" 8 '\\\\w' 9 >>> print("\w") 10 \w 11 >>> print(r"\w") 12 \w 13 >>> print("\\w") 14 \w 15 >>> print(r"\\w") 16 \\w 17 >>> 18 >>> print(repr(r"\'")) 19 "\\'" 20 >>> print(r"\'") 21 \' 22 >>> print(r"\") # 转义后的"是作为字符串的内容,不能作为标识字符串结束的边界 23 File "<stdin>", line 1 24 print(r"\") 25 ^ 26 SyntaxError: EOL while scanning string literal
3. 匹配单个字符
正则表达式的单字符匹配如下:
| 字符 | 功能 |
|---|---|
| . | 匹配任意1个字符(除了\n) |
| [ ] | 匹配[ ]中列举的字符;[^]中的^代表非 |
| \d | 匹配数字,即0-9 |
| \D | 匹配非数字,即不是数字 |
| \s | 匹配空白,即 空格,tab键 |
| \S | 匹配非空白 |
| \w | 匹配单词字符,即a-z、A-Z、0-9、_、中文 |
| \W | 匹配非单词字符 |
示例:
1 >>> import re 2 >>> result = re.match("嫦娥\d号", "嫦娥1号") 3 >>> result.group() 4 '嫦娥1号' 5 >>> result = re.match("嫦娥\d号", "嫦娥2号") 6 >>> result.group() 7 '嫦娥2号' 8 >>> result = re.match("[a-zA-Z]", "Hello World") 9 >>> result.group() 10 'H'
注意:\w 匹配的是能组成单词的字符,在 python3 中 re 默认支持的是 unicode 字符集,因此也支持汉字。
如果要让 \w 仅支持英文,加个 re.A 就不会匹配汉字了。
1 >>> import re 2 >>> s = "I am a 男孩!" 3 >>> re.findall("\w+", s, re.A) 4 ['I', 'am', 'a']
4. 匹配多个字符
匹配多个字符的相关格式:
| 字符 | 功能 |
|---|---|
| * | 匹配前一个字符出现0次或者无限次,即可有可无 |
| + | 匹配前一个字符出现1次或者无限次,即至少有1次 |
| ? | 匹配前一个字符出现1次或者0次,即要么有1次,要么没有 |
| {m} | 匹配前一个字符出现m次 |
| {m,} | 匹配前一个字符至少出现m次 |
| {m,n} | 匹配前一个字符出现从m到n次 |
示例1:*
匹配出,一个字符串第一个字母为大小字符,后面都是小写字母并且这些小写字母可有可无:
1 >>> re.match("[A-Z][a-z]*", "Faaa").group() 2 'Faaa' 3 >>> re.match("[A-Z][a-z]*", "F").group() 4 'F'
示例2:+
匹配出,变量命名是否有效:
1 >>> re.match("[a-zA-Z_]+", "Name").group() 2 'Name' 3 >>> re.match("[a-zA-Z_]+", "_Name").group() 4 '_Name' 5 >>> re.match("[a-zA-Z_]+", "1_Name").group() 6 Traceback (most recent call last): 7 File "<stdin>", line 1, in <module> 8 AttributeError: 'NoneType' object has no attribute 'group'
示例3:?
匹配出,0到99之间的数字:
1 >>> re.match("[1-9]?[0-9]", "09").group() 2 '0' 3 >>> re.match("[1-9]?\d", "12").group() 4 '12' 5 >>> re.match("[1-9]?[0-9]", "100").group() 6 '10'
示例4:{m}
匹配出,8到20位的密码,可以是大小写英文字母、数字、下划线:
1 >>> re.match("[\w]{8,20}", "1234567").group() 2 Traceback (most recent call last): 3 File "<stdin>", line 1, in <module> 4 AttributeError: 'NoneType' object has no attribute 'group' 5 >>> re.match("[\w]{8,20}", "1234567a").group() 6 '1234567a' 7 >>> re.match("[\w]{8,20}", "1234567aA_").group() 8 '1234567aA_' 9 >>> re.match("[\w]{8,20}", "1234567aA_000000000000000000").group() 10 '1234567aA_0000000000'
5. 匹配边界
| 字符 | 功能 |
|---|---|
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 |
| \b | 匹配一个单词的边界 |
| \B | 匹配非单词边界 |
示例1:$
匹配 163.com 的邮箱地址:
1 >>> re.match("[\w]{4,20}@163\.com", "123aa_A@163.com").group() 2 '123aa_A@163.com' 3 >>> re.match("[\w]{4,20}@163\.com", "123aa_A@163.com_sada").group() 4 '123aa_A@163.com' 5 >>> re.match("[\w]{4,20}@163\.com$", "123aa_A@163.com_sada").group() 6 Traceback (most recent call last): 7 File "<stdin>", line 1, in <module> 8 AttributeError: 'NoneType' object has no attribute 'group' 9 >>> re.match("[\w]{4,20}@163\.com$", "123aa_A@163.com").group() 10 '123aa_A@163.com'
1 >>> re.match(r"[1-9]?\d$", "12").group() 2 '12' 3 >>> re.match(r"[1-9]?\d$", "0").group() 4 '0' 5 >>> re.match(r"[1-9]?\d$", "01").group() 6 Traceback (most recent call last): 7 File "<stdin>", line 1, in <module> 8 AttributeError: 'NoneType' object has no attribute 'group'
示例2: \b
注意,\b 在正则中表示单词间隔,但 \b 在字符串里本身是个转义,代表退格。因此需要加 r 表示正则中的单词间隔。
而相比于\b, 像 \w、\d 只有一种解释,并没有对应的转义字符,所以不加 r,也不会出错。
1 >>> re.match(r".*\bhello\b", "soda hello ver").group() 2 'soda hello' 3 >>> re.match(r".*\bhello\b", "soda hellover").group() 4 Traceback (most recent call last): 5 File "<stdin>", line 1, in <module> 6 AttributeError: 'NoneType' object has no attribute 'group' 7 >>> re.match(r".*\bhello\b", "hello ver").group() 8 'hello'
示例3:\B
1 >>> re.match(r".*\Bhello\B", "hellover").group() 2 Traceback (most recent call last): 3 File "<stdin>", line 1, in <module> 4 AttributeError: 'NoneType' object has no attribute 'group' 5 >>> re.match(r".*\Bhello\B", "_hellover").group() 6 '_hello' 7 >>> re.match(r".*\Bhello\B", "hello").group() 8 Traceback (most recent call last): 9 File "<stdin>", line 1, in <module> 10 AttributeError: 'NoneType' object has no attribute 'group'
6. 匹配分组
| 字符 | 功能 |
|---|---|
| | | 匹配左右任意一个表达式 |
| (ab) | 将括号中的字符作为一个分组 |
\num |
引用分组num匹配到的字符串 |
(?P<name>) |
给分组起别名 |
| (?P=name) | 引用别名为name分组匹配到的字符串 |
示例1:|
匹配出0-100之间的数字:
1 >>> re.match("[1-9]?\d$|100|0", "8").group() # 满足3组规则中的一组即可 2 '8' 3 >>> re.match("[1-9]?\d$|100", "78").group() 4 '78' 5 >>> re.match("[1-9]?\d$|100", "100").group() 6 '100'
示例2:( )
匹配出163、126、qq邮箱之间的数字:
1 >>> re.match("(\w+)@(163|126|qq)\.com$", "123a@qq.com").group() 2 '123a@qq.com' 3 >>> re.match("(\w+)@(163|126|qq)\.com$", "123a@163.com").group() 4 '123a@163.com' 5 >>> re.match("(\w+)@(163|126|qq)\.com$", "123a@163.coma").group() 6 Traceback (most recent call last): 7 File "<stdin>", line 1, in <module> 8 AttributeError: 'NoneType' object has no attribute 'group'
取出分组部分:
1)match/search 的分组示例:两者用法一致
1 # match 2 >>> ret = re.match("([^-]*)-(\d+)", "010-1321331") 3 >>> ret.group() 4 '010-1321331' 5 >>> ret.group(1) # 取出第一个分组 6 '010' 7 >>> ret.group(2) # 取出第二个分组 8 '1321331' 9 # search 10 >>> re.search(r"((a)\d+)(c)", "a123c").group(0) # 取出整个表达式的匹配项,即传0等同于不传参 11 'a123c' 12 >>> re.search(r"((a)\d+)(c)", "a123c").group(1) # 取出第1个分组(外层括号的取数顺序优先于里层括号) 13 'a123' 14 >>> re.search(r"((a)\d+)(c)", "a123c").group(2) # 取出第2个分组 15 'a' 16 >>> re.search(r"((a)\d+)(c)", "a123c").group(3) 17 'c' 18 >>> re.search(r"(a)(\d+(c))", "a123c").group(1) 19 'a' 20 >>> re.search(r"(a)(\d+(c))", "a123c").group(2) # 外层括号的取数顺序优先于里层括号 21 '123c'
2)findall 的分组示例:findall 只会取分组内容
1 >>> re.findall(r"(ab|cd)11","ab11") 2 ['ab'] 3 >>> re.findall(r"abc\d+","abc1,abc2,abc3") 4 ['abc1', 'abc2', 'abc3'] 5 >>> re.findall(r"abc(\d+)","abc1,abc2,abc3") 6 ['1', '2', '3'] 7 >>> re.findall(r"(abc)(\d+)","abc1,abc2,abc3") # 返回两个分组内容 8 [('abc', '1'), ('abc', '2'), ('abc', '3')] 9 >>> re.findall(r"((abc)(\d+))","abc1,abc2,abc3") # 返回三个分组内容 10 [('abc1', 'abc', '1'), ('abc2', 'abc', '2'), ('abc3', 'abc', '3')]
示例3:\number
匹配出<html><h1>www.itcast.cn</h1></html>:
1 >>> re.match(r"<(\w*)><(\w*)>.*</\2></\1>", "<html><h1>www.itcast.cn</h1></html>").group() 2 '<html><h1>www.itcast.cn</h1></html>'
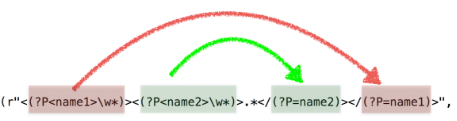
示例4:(?P<name>) (?P=name)
匹配出<html><h1>www.itcast.cn</h1></html>:
1 >>> re.match(r"<(?P<key1>\w*)><(?P<key2>\w*)>.*</(?P=key2)></(?P=key1)>", "<html><h1>www.itcast.cn</h1></html>").group() 2 '<html><h1>www.itcast.cn</h1></html>'
7. re 模块的高级用法
- search:匹配第一处符合规则的部分。
- findall:匹配所有符合规则的部分,并组成列表返回。
- sub:将匹配到的所有符合规则的数据进行替换。
- split:根据匹配进行切割字符串,并返回一个列表。
用法示例:
1 >>> re.search(r"\d+","预习次数为:2,复习次数为:6").group() # search 2 '2' 3 >>> re.findall(r"\d+","预习次数为:2,复习次数为:6") # findall 4 ['2', '6'] 5 >>> re.sub("\d+", "998", "python = 997") # sub 6 'python = 998' 7 >>> re.split(":| ", "info:xiaoZhang 22 shandong") # split,分隔符为冒号或空格 8 ['info', 'xiaoZhang', '22', 'shandong']
示例2:找出单词
1 >>> s = "hello world ha ha" 2 >>> re.split(" ", s) # 方法一 3 ['hello', 'world', 'ha', 'ha'] 4 >>> re.findall("\w+", s) # 方法二 5 ['hello', 'world', 'ha', 'ha']
示例3:sub 的第二种用法,传递函数作为参数
1 import re 2 3 def add_one(ret): 4 str_num = ret.group() 5 return str(int(str_num)+1) 6 7 ret = re.sub("\d+", add_one, "python = 997") 8 print(ret) # python = 998
示例4:用 sub 匹配网址
有一批网址:
http://www.interoem.com/messageinfo.asp?id=35
http://3995503.com/class/class09/news_show.asp?id=14
http://lib.wzmc.edu.cn/news/onews.asp?id=769
http://www.zy-ls.com/alfx.asp?newsid=377&id=6
http://www.fincm.com/newslist.asp?id=415
需要正则后为:
http://www.interoem.com/
http://3995503.com/
http://lib.wzmc.edu.cn/
http://www.zy-ls.com/
http://www.fincm.com/
解:
1 # 方法一 2 re.match(r"http://.*?/", s).group() 3 4 # 方法二:使用替换,仅返回需要的部分 5 re.sub(r"(http://.*?/).*", lambda x: x.group(1), s)
8. 贪婪和非贪婪
Python 中正则表达式的数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),当它在从左到右的顺序求值时,总是尝试匹配尽可能多的字符。非贪婪则相反,总是尝试匹配尽可能少的字符。
在 "*"、"?"、"+"、"{m,n}" 后面加上?,可使贪婪变成非贪婪。
示例1:
1 >>> s = "This is a number 234-235-22-423" 2 >>> re.match(".+(\d+-\d+-\d+-\d+)", s).group(1) 3 '4-235-22-423' 4 >>> re.match(".+?(\d+-\d+-\d+-\d+)", s).group(1) 5 '234-235-22-423'
在上面的例子中,“.+”会从字符串的启始处抓取满足模式的最长字符,其中包括我们想得到的第一个整型字段的中的大部分,“\d+”只需一位字符就可以匹配,所以它匹配了数字“4”,而“.+”则匹配了从字符串起始到这个第一位数字4之前的所有字符。
因此解决方式为使用非贪婪操作符“?”,要求正则匹配的越少越好。
示例2:
1 >>> re.match("aa(\d+)", "aa1232ddd").group(1) 2 '1232' 3 >>> re.match("aa(\d+?)", "aa1232ddd").group(1) 4 '1' 5 >>> re.match("aa(\d+)ddd", "aa1232ddd").group(1) 6 '1232' 7 >>> re.match("aa(\d+?)ddd", "aa1232ddd").group(1) 8 '1232'
示例4:从下面的字符串中取出文本
<div>
<p>岗位职责:</p>
<p>完成推荐算法、数据统计、接口、后台等服务器端相关工作</p>
<p><br></p>
<p>必备要求:</p>
<p>良好的自我驱动力和职业素养,工作积极主动、结果导向</p>
<p> <br></p>
<p>技术要求:</p>
<p>1、一年以上 Python 开发经验,掌握面向对象分析和设计,了解设计模式</p>
<p>2、掌握HTTP协议,熟悉MVC、MVVM等概念以及相关WEB开发框架</p>
<p>3、掌握关系数据库开发设计,掌握 SQL,熟练使用 MySQL/PostgreSQL 中的一种<br></p>
<p>4、掌握NoSQL、MQ,熟练使用对应技术解决方案</p>
<p>5、熟悉 Javascript/CSS/HTML5,JQuery、React、Vue.js</p>
<p> <br></p>
<p>加分项:</p>
<p>大数据,数理统计,机器学习,sklearn,高性能,大并发。</p>
</div>
解:
1 # 方法一:精确匹配 2 re.sub("</?\w*>", "", raw_str) 3 4 # 方法二:使用非贪婪模式 5 re.sub("<.+?>", "", raw_str)
9. 修饰符
正则表达式可以包含一些可选标志修饰符来控制匹配模式。修饰符被指定为一个可选的标志,用在正则表达式处理函数中的 flag 参数中。多个标志可以通过使用按位或运算符"|"来指定它们,表示同时生效。如:re.I | re.M 表示被设置成 I 和 M 标志。

示例:
# re.A:使得 \w 不会匹配到中文字符 >>> s = "I am a 男孩!" >>> re.findall("\w+", s) ['I', 'am', 'a', '男孩'] >>> re.findall("\w+", s, re.A) ['I', 'am', 'a'] # re.I:忽略大小写 >>> re.search("abc", "saBcs", re.I) <_sre.SRE_Match object; span=(1, 4), match='aBc'> >>> re.search("[a-z]+", "saBcs", re.I) <_sre.SRE_Match object; span=(0, 5), match='saBcs'> # re.DOTALL:使得"."能够匹配到转义字符 >>> re.match("a.b", "a\nb") >>> re.match("a.b", "a\nb", re.S) <_sre.SRE_Match object; span=(0, 3), match='a\nb'>
10. 前/后向断言
前/后向肯定断言
- 前向肯定断言:(?<=pattern)
前向肯定断言表示你希望匹配的字符串前面是 pattern 匹配的内容时,才匹配。
- 后向肯定断言:(?=pattern)
后向肯定断言表示你希望匹配的字符串的后面是 pattern 匹配的内容时,才匹配。
所以从上面的介绍来看,如果在一次匹配过程中,需要同时用到前向肯定断言和后向肯定断言时,那你必须将前向肯定断言表达式写在要匹配的正则表达式的前面,而后向肯定断言表达式写在你要匹配的字符串的后面,表示后向肯定模式之后,前向肯定模式之前。
前向肯定断言括号中的正则表达式必须是能确定长度的正则表达式,比如 \w{3},而不能写成 \w* 或者 \w+ 或者 \w? 等这种不能确定个数的正则模式符。
示例:
1 >>> import re 2 >>> 3 >>> s = 'aaa111aaa , bbb222 , 333ccc' 4 >>> 5 >>> # 指定前后肯定断言 6 ... print(re.findall( r'(?<=[a-z]{3})\d+(?=[a-z]+)', s) ) 7 ['111'] 8 >>> # 只指定后向肯定断言 9 ... print(re.findall( r'\w+\d+(?=[a-z]+)', s) ) 10 ['aaa111', '333'] 11 >>> # 只指定前向肯定断言 12 ... print(re.findall( r'(?<=[a-z]{3})\d+', s) ) 13 ['111', '222'] 14 >>> # 普通匹配方法 15 ... print(re.findall (r'[a-z]+(\d+)[a-z]+', s)) 16 ['111'] 17 >>> 18 >>> # 下面是一个错误的实例 19 ... try: 20 ... matchResult = re.findall( r'(?<=[a-z]+)\d+(?=[a-z]+)', s) 21 ... except Exception as e: 22 ... print(e) 23 ... else: 24 ... print(matchResult) 25 ... 26 look-behind requires fixed-width pattern 27 >>>
前/后向否定断言
- 前向否定断言:(?<!pattern)
前向否定断言表示你希望匹配的字符串的前面不是 pattern 匹配的内容时,才匹配。
- 后向否定断言:(?!pattern)
后向否定断言表示你希望匹配的字符串后面不是 pattern 匹配的内容时,才匹配。
示例:
1 import re 2 s = 'aaa111aaa , bbb222 , 333ccc' 3 4 # 指定前后否定断言,不满足前三个字母和后三个字母的条件 5 print(re.findall( r'(?<![a-z]{3})\d+(?![a-z]+)', s)) # ['1', '22', '33'] 6 7 # 只指定后向否定断言 8 print(re.findall( r'\w+\d+(?![a-z]+)', s)) # ['aaa11', 'bbb222', '33'] 9 10 # 只指定前向否定断言 11 print(re.findall( r'(?<![a-z]{3})\d+', s) ) # ['11', '22', '333'] 12 13 # 普通匹配方法 14 print(re.findall(r'[a-z]+(\d+)[a-z]+', s)) # ['111'] 15 16 # 下面是一个错误的实 17 try: 18 matchResult = re.findall(r'(?<![a-z]+)\d+(?![a-z]+)', s) 19 except Exception as e: 20 print(e) # look-behind requires fixed-width pattern 21 else: 22 print(matchResult)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号