Python 函数
1. 函数介绍
2. 局部/全局变量
3. 函数的参数
4. 递归函数
5. 匿名函数
1. 函数介绍
什么是函数?
函数是组织好的,可重复使用的,用来实现特定功能的代码段。
函数能提高应用的模块性和代码的重复利用率,以提高编写效率。Python 提供了许多内建函数,比如 print()。我们也可以自己创建函数,这被叫做用户自定义函数。
自定义函数
语法:
# 定义函数 def 函数名(形参1, 形参2, ...): # 引号中可添加函数的文档说明 """ :param 形参1: :param 形参2: :return: """ 函数体(即需要实现特定功能的代码块) return 返回值 # 调用函数 函数名(实参1, 实参2, ...)
- 定义时小括号中的参数,用来接收参数用的,称为 “形参”;调用时小括号中的参数,用来传递给函数用的,称为 “实参”。
- 函数可以根据有没有参数,有没有返回值来自由组合。
示例:
1 >>> def cal(a, b): 2 ... result1 = a + b 3 ... result2 = a - b 4 ... return result1, result2 # 多个返回值,利用了元组 5 ... 6 >>> cal(1, 2) 7 (3, -1) 8 >>> result = cal(3, 4) # 保存函数的返回值 9 >>> print(result) 10 (7, -1)
2. 局部/全局变量
局部变量
- 局部变量,就是在函数内部定义的变量。
- 局部变量的作用,是为了临时保存数据而需要在函数中定义变量来进行存储,这就是它的作用。
- 不同的函数,可以定义相同的名字的局部变量,各用各的不会产生影响。
全局变量
- 在函数外边定义的变量叫做全局变量,全局变量能够在所有的函数中进行访问。
- 如果全局变量名和局部变量名相同,那么将使用局部变量。
- 全局变量的位置必须在函数调用之前,但可在函数定义之后。
- 如果在函数中修改全局变量,那么就需要使用 global 进行声明,否则会报错。
示例:修改全局变量
1 # 定义全局变量 2 num = 100 3 4 def test1(): 5 global num # 声明全局变量 6 num = 200 # 修改全局变量 7 print(num) 8 9 def test2(): 10 print(num) 11 12 test1() # 200 13 test2() # 200
可变类型的全局变量
- 不可变类型的全局变量,不使用 global 则无法修改全局变量;
- 可变类型的全局变量,不使用 global 也可修改全局变量。
>>> # 当全局变量为不可变类型时 >>> a = 1 >>> def f1(): ... a += 1 # 未声明全局变量则会报错 ... print(a) ... >>> f1() Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 2, in f1 UnboundLocalError: local variable 'a' referenced before assignment >>> >>> # 当全局变量为可变类型时 >>> li = [1] >>> def f2(): ... li.append(2) # 未声明全局变量也可直接引用 ... print(li) ... >>> f2() [1, 2]
3. 函数的参数
3.1 参数顺序
1 >>> def test(a, b): 2 ... print(a, b) 3 ... 4 >>> test(1, 2) # 默认按传入的顺序 5 1 2 6 >>> test(b=2, a=1) # 指定关键字来传参 7 1 2 8 >>> test(b=2, 1) # 指定关键字需要放在默认传参之后,否则会报错 9 File "<stdin>", line 1 10 SyntaxError: positional argument follows keyword argument 11 >>> test(1, b=2) 12 1 2
3.2 默认参数
- 调用函数时,若默认参数的值没有传入,则会使用默认值。
- 默认参数需要放在形参列表的最后面,否则会报错。
1 >>> def test(name, age=18): 2 ... print(name, age) 3 ... 4 >>> test("xiaoming") 5 xiaoming 18 6 >>> test("xiaoming", 19) 7 xiaoming 19 8 >>> 9 >>> def test(age=18, name): 10 ... print(name, age) 11 ... 12 File "<stdin>", line 1 13 SyntaxError: non-default argument follows default argument
注意:应尽量避免将默认参数定义为可变类型,否则容易出现程序逻辑问题
1)问题示例
在下面的例子中,函数 buggy() 在每次调用时,添加参数 arg 到一个空的列表 result ,然后打印输出一个单值列表。
但是存在一个问题:只有在第一次调用时列表是空的,第二次调用时就会存在之前调用的返回值。
1 def buggy(arg, result=[]): 2 result.append(arg) 3 print(result) 4 5 print('--------1--------') 6 buggy('a') 7 print('--------2--------') 8 buggy('b') # 期望得到 ['b']
执行结果:
--------1-------- ['a'] --------2-------- ['a', 'b']
2)问题解释
- 默认参数值在函数被定义时已经计算出来,而不是在程序运行时。
- 只要函数调用时没有传递新的列表来覆盖默认参数列表,函数就会使用定义时的那个列表,并且操作依次叠加。
- 上面两次调用中,都没有传递新的列表,程序会调用定义函数时保存的默认参数,并在上一次的基础上进行操作叠加,即列表在 append 的时候会在 result 原来的基础上 append 追加值,所以会产生以上结果。
我们通过打印列表的 id 进行辨识来看看:
1 def buggy(arg, result=[]): 2 print(id(result)) 3 result.append(arg) 4 print(result) 5 6 print('--------1--------') 7 buggy('a') 8 print('--------2--------') 9 buggy('b') # expect ['b']
执行结果:
--------1-------- 12205768 ['a'] --------2-------- 12205768 ['a', 'b']
我们会发现 id 值是相同的,说明两次执行时使用的都是开始定义函数时的默认参数,进行了操作叠加。
下面我们传递新的列表看看
示例 1:
1 def buggy(arg, result=[]): 2 print(id(result)) 3 result.append(arg) 4 print(result) 5 6 print('--------1--------') 7 buggy('a') 8 print('--------2--------') 9 buggy('b', []) # 传递了新的列表
执行结果:
--------1-------- 18497224 ['a'] --------2-------- 18504648 ['b']
发现,列表 id 不同,并且得到了我们期望的值。
示例 2:
1 def add_end(L=[]): 2 print(id(L)) 3 L.append('END') 4 return L 5 6 # 未传递列表,会对默认列表对象进行累加 7 print(add_end()) 8 print(add_end()) 9 print("*"*30) 10 # 传递有变量引用的列表(引用传递),会对新列表对象进行累加 11 li = [1, 2, 3] 12 print(add_end()) 13 print(add_end(li)) 14 print(add_end(li)) 15 print("*"*30) 16 # 传递没有变量引用的列表(值传递),每次返回的都是新列表 17 print(add_end([1, 2, 3])) 18 print(add_end(["x", "y", "z"]))
执行结果:
2385843760264 ['END'] 2385843760264 ['END', 'END'] ****************************** 2385843760264 ['END', 'END', 'END'] 2385843760584 [1, 2, 3, 'END'] 2385843760584 [1, 2, 3, 'END', 'END'] ****************************** 2385843760520 [1, 2, 3, 'END'] 2385843760520 ['x', 'y', 'z', 'END']
注意,在上述例子中,传递没有变量引用的列表时两次调用函数的 id(L) 结果一致,是因为 Python 的内存地址分配特性:对于没有变量引用的相同数据类型的对象,对其所分配的内存地址都是相同的。
1 >>> id([1, 2, 3]) 2 1619966208264 3 >>> id(["z", "y", "z"]) 4 1619966208264 5 >>> 6 >>> id((1, 2 ,3)) 7 1619966178000 8 >>> id(("x", "y", "z")) 9 1619966178000 10 >>> 11 >>> id(1000) 12 1619963916016 13 >>> id(2000) 14 1619963916016
3)解决方法
方法1:
1 def works(arg): 2 result = [] 3 result.append(arg) 4 print(result) 5 6 works('a') 7 works('b')
执行结果:
['a'] ['b']
方法2:
1 def nonbuggy(arg, result=None): 2 if result is None: 3 result = [] 4 result.append(arg) 5 print(result) 6 7 nonbuggy('a') 8 nonbuggy('b')
执行结果:
['a'] ['b']
3.3 不定长参数
当需要一个函数能处理比当初声明时更多的参数时,这些参数就叫做不定长参数,声明时无需命名。
def 函数名(普通参数, *args, **kwargs): 函数体
- 加了 * 的变量 args 会存放所有未命名的变量参数,args 为元组。
- 加了 ** 的变量 kwargs 会存放命名参数,即形如 key=value 的参数,kwargs 为字典。
- 同时使用 *args 和 **kwargs 时,*args 参数必须要在 **kwargs 前,否则会报错。
1 >>> def func(a, b, *args, **kwargs): 2 ... print(a) 3 ... print(b) 4 ... print(args) 5 ... print(kwargs) 6 ... 7 8 # 直接传入元组和字典时,都传给了args 9 >>> func(1, 2, 3, 4, m=5, n=6) 10 1 11 2 12 (3, 4) 13 {'m': 5, 'n': 6} 14 15 # 直接传入元组和字典时,都传给了args 16 >>> c = (3, 4, 5) 17 >>> d = {"m":6, "n":7} 18 >>> func(1, 2, c, d) 19 1 20 2 21 ((3, 4, 5), {'m': 6, 'n': 7}) 22 {} 23 24 # 注意加了星号时为“拆包”:将传入的元组和字典分别对应上args和kwargs 25 # 解包时的传入顺序也需*在前,**在后 26 >>> func(1, 2, *c, **d) 27 1 28 2 29 (3, 4, 5) 30 {'m': 6, 'n': 7} 31 32 33 # 关键字需是字母 34 >>> func(1, 2, a=1, 1=1) 35 File "<stdin>", line 1 36 SyntaxError: keyword can't be an expression 37 # 解包的键也需是字符串 38 >>> d = {"a": 1, 2: 1} 39 >>> func(1, 2, **d) 40 Traceback (most recent call last): 41 File "<stdin>", line 1, in <module> 42 TypeError: func() keywords must be strings
3.4 引用参数
当可变类型与不可变类型的变量分别作为函数参数时,会有什么不同吗?
- Python中函数参数是引用传递(注意不是值传递),即形参指向了实参的地址。
- 对于不可变类型,因为变量不能修改,所以运算不会影响到变量自身;而对于可变类型来说,函数体中的运算有可能会更改传入的参数变量。
1 >>> # 自定义函数 2 >>> def selfAdd(a): 3 ... "自增" 4 ... a += a 5 ... 6 >>> # 传入不可变类型的参数时 7 >>> a_int = 1 8 >>> selfAdd(a_int) 9 >>> a_int 10 1 11 >>> # 传入可变类型的参数时 12 >>> a_list = [1, 2] 13 >>> selfAdd(a_list) 14 >>> a_list 15 [1, 2, 1, 2]
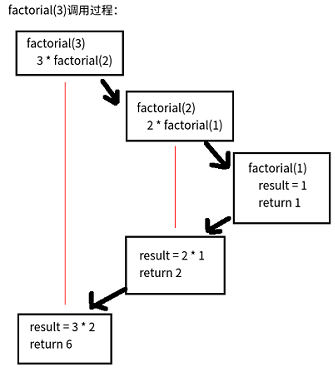
4. 递归函数
如果一个函数在内部调用了自身的话,这个函数就是递归函数(recursive function)。
以阶乘为例子,首先观察其规律:
1! = 1 2! = 2 × 1 = 2 × 1! 3! = 3 × 2 × 1 = 3 × 2! 4! = 4 × 3 × 2 × 1 = 4 × 3! ... n! = n × (n-1)!
实现:
1 def factorial(num): 2 if num > 1: 3 return num * factorial(num-1) 4 else: 5 return 1 6 7 print(factorial(3)) # 结果为6
5. 匿名函数
用 lambda 关键词能创建小型匿名函数,这种函数得名于省略了用def声明函数的标准步骤。
lambda 函数的语法只包含一个语句,如下:
lambda [arg1 [, arg2, .....argn]]: expression
Lambda 函数能接收任何数量的参数,但只能返回一个表达式的值。
示例:
1 >>> sum = lambda a, b: a + b 2 >>> print(sum(2, 3)) 3 5
匿名函数的应用场景
1. 匿名函数作为函数参数进行传递
1 >>> def sum(a, b, opt): 2 ... print(a, b) 3 ... print("result=", opt(a, b)) 4 ... 5 >>> sum(2, 3, lambda a,b: a+b) 6 2 3 7 result= 5
2. 列表中字典(或多维列表、元组)的排序规则
1 >>> stus = [ {"name": "zhangsan", "age": 18}, {"name": "lisi", "age": 19}, {"name": "wangwu", "age": 17} ] 2 >>> 3 >>> stus.sort(key=lambda item:item["age"]) # 按 age 排序 4 >>> stus 5 [{'name': 'wangwu', 'age': 17}, {'name': 'zhangsan', 'age': 18}, {'name': 'lisi', 'age': 19}] 6 >>> stus.sort(key=lambda item:item["name"]) # 按 name 排序 7 >>> stus 8 [{'name': 'lisi', 'age': 19}, {'name': 'wangwu', 'age': 17}, {'name': 'zhangsan', 'age': 18}]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号