彻底搞懂Unicode字符集和UTF-8编码方案
计算机的存储本质是二进制的0和1。信息传输也是0和1的排列组合。那么如何让二进制的0和1变成人们能看懂的文字呢?或者说世界上那么多语言,那么多字符怎么用二进制的0和1进行表示呢?这就需要一张超级大的map表或者叫做字典来让人们认识的字符和二进制表示的数字能够一一对应。比如汉字的“中国”两个字,我们假设分别用二进制的00000000和00000001进行表示。当用户在电脑输入中国两个字的时候,那么存储在电脑中的就是二进制的00000000和00000001。通过网络传输到别人电脑上,也能解析成中国两个字。这就需要我们的电脑都使用同一本字典也就是Unicode字符集(所有的计算机或者终端都会内置一套字符集,如果两台电脑用的不是同一套字符集,就可能造成乱码。)和相同的编码规范(因为Unicode字符集并不是二进制的,是十六进制的),例如:UTF-8。
好了,Unicode字符集就是一本字典,用的时候查就是了。那UTF-8又是什么呢?前面我们说到Unicode字符集是十六进制的,而且它并没有规定字符对应的二进制码如何存储。以我们的汉字为例,通常需要占用三个字节,英文只需要占用一个字节,计算机读取汉字字节的时候,并不知道要读取一个字节两个字节还是三个字节。假如我们把中英文都按三个字节存储,不够的全部补0,这又会造成极大的浪费。如果是一篇纯英文的文章,那么存储的体积中的三分之二都是无谓的补0,肯定是大大的不合算。UTF-8的惊艳之处就是它是一种可变长的编码方式。很好的向后兼容了之前的编码规则,例如ASCII。
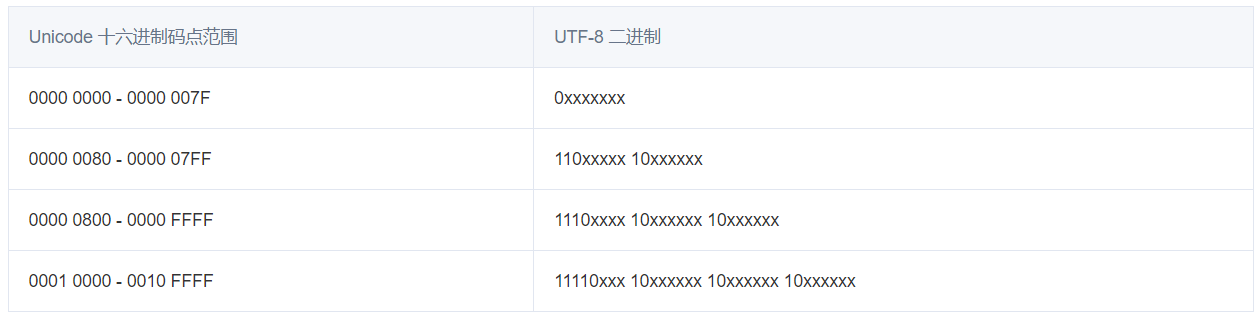
具体的编码规则如下:
1、对于单个字节的字符,第一位设为0,后面的7位对应这个字符的Unicode码点。
2、对应需要使用N个字节表示的字符(N>1),第一个字节的前N位都设为1,第N+1位设为0,剩余的N-1个字节的前两位都设为10,剩下的二进制则使用这个字符的Unicode码点来填充。
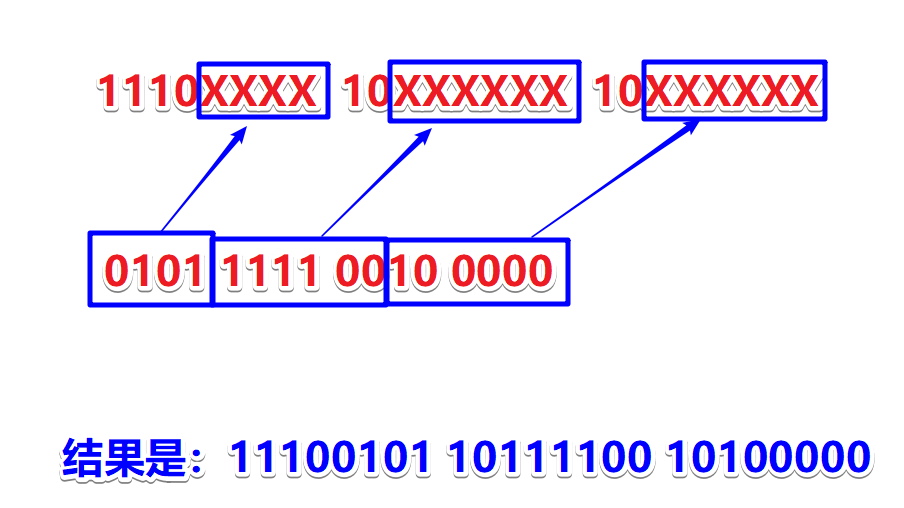
下面就举个栗子,例如我的姓“张”对应的Unicode的码点是 0x5F20,对应第三行。先将十六进制转换成二进制为:0101 1111 0010 0000,然后从张的二进制的最后一位开始,从后向前依次填充对应格式中的X,多出的X用0补上,这就得到了张的UTF-8编码为11100101 10111100 10100000。
posted on 2024-04-12 17:21 hanguahannibk 阅读(196) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号