

由一道我喜欢的题引出的思考,parser?
题目LeetCode 736 hard
给你一个类似 Lisp 语句的字符串表达式 expression,求出其计算结果。
表达式语法如下所示:
表达式可以为整数,let 表达式,add 表达式,mult 表达式,或赋值的变量。表达式的结果总是一个整数。
(整数可以是正整数、负整数、0)
let 表达式采用 "(let v1 e1 v2 e2 ... vn en expr)" 的形式,其中 let 总是以字符串 "let"来表示,接下来会跟随一对或多对交替的变量和表达式,也就是说,第一个变量 v1被分配为表达式 e1 的值,第二个变量 v2 被分配为表达式 e2 的值,依次类推;最终 let 表达式的值为 expr表达式的值。
add 表达式表示为 "(add e1 e2)" ,其中 add 总是以字符串 "add" 来表示,该表达式总是包含两个表达式 e1、e2 ,最终结果是 e1 表达式的值与 e2 表达式的值之 和 。
mult 表达式表示为 "(mult e1 e2)" ,其中 mult 总是以字符串 "mult" 表示,该表达式总是包含两个表达式 e1、e2,最终结果是 e1 表达式的值与 e2 表达式的值之 积 。
在该题目中,变量名以小写字符开始,之后跟随 0 个或多个小写字符或数字。为了方便,"add" ,"let" ,"mult" 会被定义为 "关键字" ,不会用作变量名。
最后,要说一下作用域的概念。计算变量名所对应的表达式时,在计算上下文中,首先检查最内层作用域(按括号计),然后按顺序依次检查外部作用域。测试用例中每一个表达式都是合法的。有关作用域的更多详细信息,请参阅示例。
示例 1:
输入:expression = "(let x 2 (mult x (let x 3 y 4 (add x y))))"
输出:14
解释:
计算表达式 (add x y), 在检查变量 x 值时,
在变量的上下文中由最内层作用域依次向外检查。
首先找到 x = 3, 所以此处的 x 值是 3 。
示例 2:
输入:expression = "(let x 3 x 2 x)"
输出:2
解释:let 语句中的赋值运算按顺序处理即可。
示例 3:
输入:expression = "(let x 1 y 2 x (add x y) (add x y))"
输出:5
解释:
第一个 (add x y) 计算结果是 3,并且将此值赋给了 x 。
第二个 (add x y) 计算结果是 3 + 2 = 5 。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/parse-lisp-expression
思考过程:
对于不清楚lisp,不清楚编译原理parser的同学也不影响,我们只要看题目定义就行,现在定义了这门语言的部分语法,你所要做的就是用你擅长的语言去解析它的三种表达式,add,mult,let,我们一步一步来
首先,加入让你设计一个加法计算器你会怎么做呢例如 1+1=?
你肯定会想这多么简单呀,直接提取'1' '+' '1' 这三个字符,然后将数字部分加起来就可以了,没错就是这样.
那 多个数相加呢 如1 + 1 +1 呢,你得想法应该是没变的,只是解析的过程你会发现有一个'+'其实是多余的,只需要 + 1 1 1 就可以了,这个其实就是前缀表达式,更重要的是可以方便计算
然后你再看看题目中的几个表达式(add e1 e2)不就是(+ 1 1)吗,好了我们继续,提升点难度,并且用add 来替代+
(add (add 1 1) 2) 就是先计算前面的+ 1 1 再将结果和后面的2进行相加,聪明的你可能会想到用栈,或者递归的方式,递归的规律你会发现这个(+ 1 1)本质也是个数,也是个加法计算式,
栈实现则就更加简单了,从左到右入栈,遇到"(add" 记录一下,当遇到对应的")"时,便进行一次计算
我们先写一个转换器,将元素按照我们想要的样式存起来,如也可以不用这步,直接取元素的时候入栈出栈,但是这样虽然会增加一次遍历但是待会方便复用且明朗一点:
先定义关键字,包含后面会用到的:
static final String ADD = "(add"; static final String MULT = "(mult"; static final String LET = "let"; static final String END = ")"; static final String SPACE = " ";
/** * 如将(add 1 (add 1 1)) 等抽离出来 (add , 1 ,(add,1,1,),),为了明朗,部分api的复杂度较高,lexer处理 */ static List<String> convert(String exp) { List<String> list = new ArrayList<>(); while (!exp.isEmpty()) { String e = null; if (exp.startsWith(ADD)) { e = ADD; } else if (exp.startsWith(END)) { e = END; } else { // 为数字 // 非最后参数,那么就是空格结尾 int endSpace = exp.indexOf(SPACE); // 后面都没有空格了说明快结尾了 if (endSpace < 1) { endSpace = Integer.MAX_VALUE; } // 最后参数就是括号")"结尾 int endBrackets = exp.indexOf(END); e = exp.substring(0, Math.min(endSpace, endBrackets)); } list.add(e); exp = exp.substring(e.length()).trim(); } return list; }
测试一下这个方法,我们可以弄个复杂的"(add (add (add 1 1) (add (add 1 1) 1)) (add 2 1))",输出如下就没问题了,注意空格处理,这边都是按照题目正确的显示要求来的
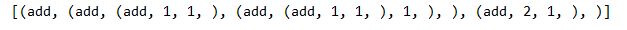
然后开始我们核心的parse的流程,采用我们上面所说的迭代(采用栈),和递归来别实现,这边我们将解析和先计算放在一块,注意注释:
static int parseAndEvaluate(String exp){ Deque<String> stack = new ArrayDeque<>(); // 将exp整理好元素 List<String> tokenList = convert(exp); for(String e : tokenList) { if (e.equals(END)) { // 取出元素进行计算,取到"(add"为止 int a = 0; String b = stack.pop(); while (!b.equals(ADD)) { int c = Integer.parseInt(b); // 计算 a+=c; // 继续取数据元素 b = stack.pop(); } stack.push(String.valueOf(a)); } else { // 添加元素 stack.push(e); } } // exp数据正确的话,栈里面只会有一个元素就是最终的结果 return Integer.parseInt(stack.pop()); }
测试一下"(add (add (add 1 1) (add (add 1 1 1) 1)) (add 2 1 1))",题目只规定了add有两个参数,我们这直接实现了对更多参数的支持
关于递归的实现,直接处理tokenList也是可以的,但是我们想换个方式,我们尝试去构建一个数据结构,Enode,怎么去构建呢,我们观察(add 1 1) ,这个整个整体就可以看成是一个Enode,主要包括三部分,add 1 1,add 作为操作符,这个"1"可能也是(add 1 1),也就是一个Enode,那么此时我们便可以开始定义这个具体的数据结构:
class Enode { // type 为add 或者 mult时 按照题目设计eNodes 长度为2,但是我们这边直接处理成支持多参数 // type 为let 时,eNodes,按照题目设计长度不定 // type 为 变量 或者 值时,eNodes为空 ,content为变量名或者值 String type; List<Enode> eNodes; // 内容,如 a b c, 1 2 3 String content; // 局部变量,add,mult 时有值,通过let操作来存储 Map<String, Integer> envMap; }
聪明的你会想到这不就是n叉树的数据结构,envMap我们先忽略.
树的节点数据结构设计好了,我们便可以开始构建这个树了,可以调用convert得到的tokenList来帮助我们进行树的构建,或者在convert的时候直接构建:
Enode getType(String e) { Enode node = new Enode(); // 非值类型 if (e.startsWith("(add") || e.startsWith("(mult") || e.startsWith("(let")) { if (e.startsWith("(add")) { node.type = "(add"; } else if (e.startsWith("(mult")) { node.type = "(mult"; } else if (e.startsWith("(let")) { node.type = "(let"; } List<Enode> list = new ArrayList<>(); node.eNodes = list; e = e.substring(node.type.length(), e.length() - 1).trim(); for (int i = 0; i < e.length(); i++) { if (e.charAt(i) == ' ') continue; String ex = "" + e.charAt(i); int c = i; if (ex.charAt(0) == '(') { int left = 1; for (int j = c + 1; j < e.length(); j++) { i++; ex += e.charAt(j); if (e.charAt(j) == '(') { left++; } else if (e.charAt(j) == ')') { left--; if (left == 0) { break; } } } } else { for (int j = c + 1; j < e.length(); j++) { i++; if (e.charAt(j) == ' ') { break; } else { ex += e.charAt(j); } } } list.add(getType(ex)); } return node; } try { // 值类型 Integer.parseInt(e); node.type = "val"; } catch (Exception ex) { // 变量,这边使用了异常处理,不建议,可以使用正则进行类型判断,为了方便 node.type = "par"; } node.content = e; return node; }
关于let,let我们在进行赋值运算时,我们这边是用一个envMap来对变量进行一个kv的维护,当进入到下一个环境时,会将envMap拷贝带过去,若是子环境重新进行了赋值,也不会影响父环境的envMap,下面是计算的过程,就是进行多叉树的遍历,
这边是用递归进行处理:
int evaluateNode(Enode node) { switch (node.type) { case "val": return Integer.parseInt(node.content); case "par": return node.envMap.get(node.content); case "(add": int sum = 0; for (int i = 0; i < node.eNodes.size(); i++) { Enode node2 = node.eNodes.get(i); node2.envMap = node.envMap; sum += evaluateNode(node2); } return sum; case "(mult": int mult = 1; for (int i = 0; i < node.eNodes.size(); i++) { Enode node2 = node.eNodes.get(i); node2.envMap = node.envMap; mult *= evaluateNode(node2); } return mult; case "(let": Map<String, Integer> envMap = new HashMap<>(); if (node.envMap != null) { envMap.putAll(node.envMap); } for (int i = 0; i < node.eNodes.size() - 1; i += 2) { Enode node2 = node.eNodes.get(i + 1); node2.envMap = envMap; envMap.put(node.eNodes.get(i).content, evaluateNode(node2)); } Enode result = node.eNodes.get(node.eNodes.size() - 1); result.envMap = envMap; // System.out.println(envMap); return evaluateNode(result); } return 0; }
最后编写调用函数,进行测试:
public int evaluate(String e) { Enode root = getType(e); return evaluateNode(root); }
,这边我们相较原题目,增加add,mult多参数的支持
谢谢大家,后面写了不算很细致,后面会写一些相关的,进行补充,大家相互学习,新年快乐!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号