
Apache Openwhisk学习(一)
一、背景
最近中途参与的一个项目是和Serverless、Faas相关的,项目的整体架构和实现都参考了开源项目openwhisk,因此,同事们在编码时都会参考openwhisk的源码。因为以前从没有接触过这方面的知识,因此想学习下。关于Serverless和Faas的概念场景等,可以参考下,这两篇博客,Serverless 架构:用服务代替服务器和Serverless应用场景。因为我也是刚刚接触,很多地方不是很了解。
二、Openwhisk简介
OpenWhisk 是属于 Apache 基金会的开源 FaaS 计算平台官网链接, 由 IBM 在2016年公布并贡献给开源社区(github页面),IBM Cloud 本身也提供完全托管的 OpenWhisk FaaS服务 IBM Cloud Function。从业务逻辑上看,OpenWhisk 同 AWS Lambda 一样,为用户提供基于事件驱动的无状态的计算模型,并直接支持多种编程语言(理论上可以将任何语言的 runtime 打包上传,间接调用)。
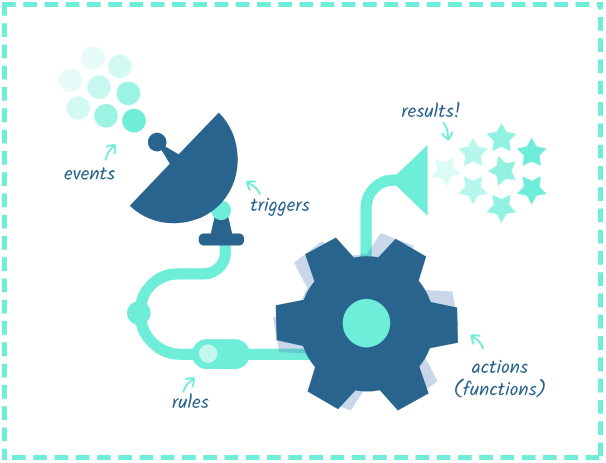
Openwhisk的特点:
(1)高性能、高扩展性的分布式Faas计算平台
(2)函数的代码及运行是全部在Docker容器中进行,利用Docker引擎实现Faas函数运行的管理、负载均衡和扩展
(3)同时,Openwhisk架构中的所有其他组件(API网关、控制器、触发器)也全部运行在Docker容器中,这使得其全栈可以比较容易的部署在IAAS/PAAS平台上 。
(4)更重要的是,相比其他Faas实现,Openwhisk更像是一套完整Serverless解决方案,除了容易调用和函数管理,Openwhisk还包括了身份验证/鉴权、函数异步触发等功能。
三、系统概览
Openwhisk是一个事件驱动的计算平台,它运行代码以响应事件或直接调用,下图显示了其 体系结构:

在上述架构中,代码时基于事件(Event)触发的。事件产生于事件源(feed),而可以用于触发函数的事件源可以是多种多样的,例如数据库的更改,超过特定温度的IoT传感器读数,新提交代码到Github存储库等。事件与对应的函数代码,通过规则(Rule)绑定。通过匹配事件对应的规则,Openswhisk会触发对应的行为(Action)。值得注意的是,多个Action可以串联,完成复杂的操作。
四、Openwhisk的工作原理
作为一个开源项目,openwhisk集成了很多其他组件Nginx,Kafka,Docker,CouchDB等,为了更加详细的解释所有组件,我们可以使用下面这个例子,来追踪整个系统的调用过程。
假设我们有包含以下代码块的文件action.js:
function main() {
console.log('Hello World');
return { hello: 'world' };
}使用下面命令创建动作
wsk action create myAction action.js现在,我们可以使用以下命令调用该操作:
wsk action create myAction action.js那么我现在来看看在Openwhisk中具体发生了什么,整个过程如下图所示:
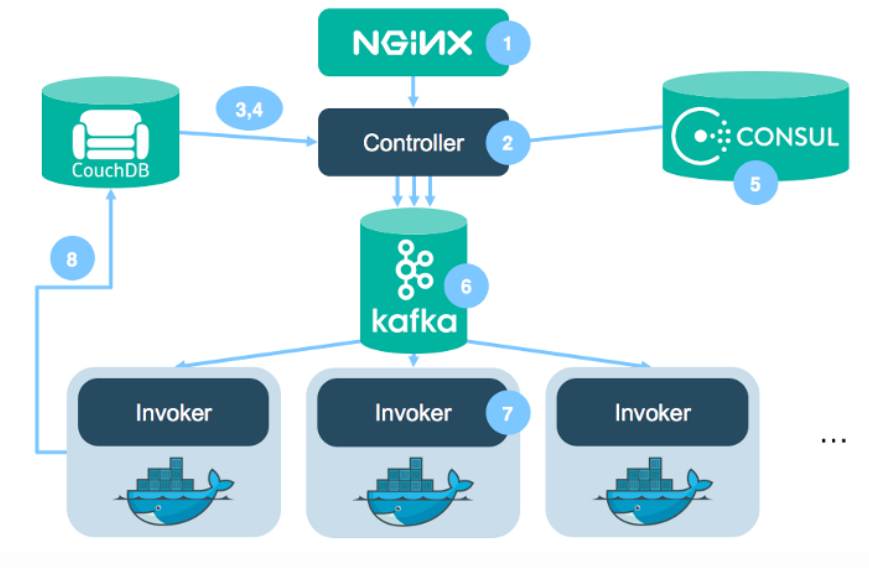
(1)Nginx
Openwhisk面向用户的API完全基于HTTP,遵循Restful设计,因此,通过wsk-cli发送的命令本质上是向其发送HTTP请求,上面的命令大致可以翻译为:
POST /api/v1/namespaces/$userNamespace/actions/myAction
Host: $openwhiskEndpoint此处的Nginx主要用于接受Http请求,并将处理后的Http请求直接转发给controller
(2)控制器(Controller)
控制器是真正开始处理请求的地方。控制器使用Scala语言实现,并提供了对应的Rest API,接受Nginx转发的请求。Controller分析请求内容,进行下一步处理。下面的很多个步骤都会和其有关系。
(3)身份验证和鉴权:CouchDB
继续用上一步用户发出的Post请求为例,控制器首先需要验证用户的身份和权限。用户的身份信息(credentials)保存在CouchDB的用户身份数据库中,验证无误后,控制器进行下一步处理。
(4)再次CouchDB,得到对应的Action的代码及配置
身份验证通过后,Controller需要从CouchDB中加载此操作(在本例中为myAction)。操作记录主要要执行的代码和要传递给操作的默认参数,并与实际调用请求中包含的参数合并。它还包含执行时对其施加的资源限制,例如允许使用的内存。
(5)Consul和负载均衡
到了这一步,控制器已经有了触发函数所需要的全部信息,在将数据发送给触发器(Invoker)之前,控制器需要和 Consul 确认,从 Consul 获取处于空闲状态的触发器的地址。Consul 是一个开源的服务注册/发现系统,在 OpenWhisk 中 Consul 负责记录跟踪所有触发器的状态信息。当控制器向 Consul 发出请求,Consul 从后台随机选取一个空闲的触发器信息,并返回。值得注意的是:无论是同步还是异步触发模式,控制器都不会直接调用触发器API,所有触发请求都会通过 Kafka 传递。
(6)发送请求进Kafka
考虑使用kafka主要是担心发生以下两种状况:
1、系统崩溃,丢失调用请求
2、系统可能处于繁重的负载之下,调用需要等待其它调用首先完成。
Openwhisk考虑到异步情况的发生,考虑异步触发的情况,当控制器得到 Kafka 收到请求消息的的确认后,会直接向发出请求的用户返回一个 ActivationId,当用户收到确认的 ActivationId,即可认为请求已经成功存入到 Kafka 队列中。用户可以稍后通过 ActivationId 索取函数运行的结果。
(7)Invoker运行用户的代码
Invoker从对应的Kafka topic中接受控制器传来的请求,会生成一个Docker容器,注入动作代码,试用传递给他的参数执行它,获取结果,消灭容器。这也是进行了大量性能优化以减少开销并缩短响应时间的地方。
(8)CouchDB存储请求结果
Invoker的执行结果最终会被保存在CouchDB的whisk数据库中,格式如下所示:
{
"activationId": "31809ddca6f64cfc9de2937ebd44fbb9",
"response": {
"statusCode": 0,
"result": {
"hello": "world"
}
},
"end": 1474459415621,
"logs": [
"2016-09-21T12:03:35.619234386Z stdout: Hello World"
],
"start": 1474459415595,
}保存的结果中包括用户函数的返回值,及日志记录。对异步触发用户,可以通过步骤6中返回的 activationID 取回函数运行结果。同步触发的的结果和异步触发一样保存在 CouchDB 里,控制器在得到触发结束的确认后,从 CouchDB 中取得运行结果,直接返回给用户。
本文主要参考了:
(1)https://github.com/apache/incubator-openwhisk/blob/master/docs/about.md
(2)https://blog.xinkuo.me/post/apache-openwhisk.html#apache-openwhisk%E7%AE%80%E4%BB%8B

 浙公网安备 33010602011771号
浙公网安备 33010602011771号