
ES doc values讲解
列式存储——Doc Values
Doc values的存在是因为倒排索引只对某些操作是高效的。 倒排索引的优势在于查找包含某个项的文档,而对于从另外一个方向的相反操作并不高效,即:确定哪些项是否存在单个文档里,聚合需要这种次级的访问模式。
以排序来举例——虽然倒排索引的检索性能非常快,但是在字段值排序时却不是理想的结构。
在搜索的时候,我们能通过搜索关键词快速得到结果集。
当排序的时候,我们需要倒排索引里面某个字段值的集合。换句话说,我们需要转置倒排索引。
转置 结构经常被称作 列式存储 。它将所有单字段的值存储在单数据列中,这使得对其进行操作是十分高效的,例如排序、聚合等操作。
在Elasticsearch中,Doc Values就是一种列式存储结构,在索引时与倒排索引同时生成。也就是说Doc Values和倒排索引一样,基于 Segement生成并且是不可变的。同时Doc Values和倒排索引一样序列化到磁盘。
Doc Values常被应用到以下场景:
对一个字段进行排序
对一个字段进行聚合
某些过滤,比如地理位置过滤
某些与字段相关的脚本计算
下面举一个例子,来讲讲它是如何运作的
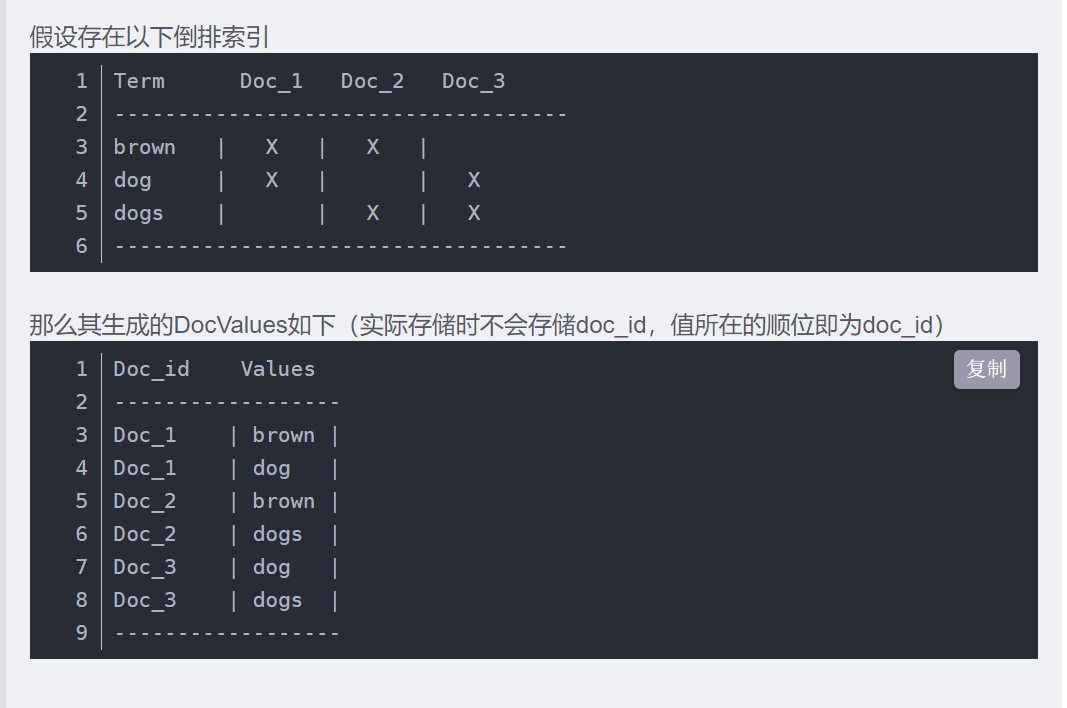
假设我们需要计算出brown出现的次数
GET /my_index/_search { "query":{ "match":{ "body":"brown" } }, "aggs":{ "popular_terms":{ "terms":{ "field":"body" } } }, "size" : 0 }
下面来分析上述请求在ES中是如何来进行查询的:
- 定位数据范围。通过倒排索引,来找到所有包含brown的doc_id。
- 进行聚合计算。借助doc_id在doc_values中定位到为brown的字段,此时进行聚合累加得到计算结果。browm的count=2。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号