一 前言
本文是上一篇博客JWebFileTrans:一款可以从网络上下载文件的小程序(一)的续集。此篇博客主要在上一篇的基础上加入了断点续传的功能,用户在下载中途停止下载后,下次可以读取断点文件,接着上次已经下载的部分文件继续下载。另外将程序名从JWebFileTrans更改为JDownload,并从github的utility repository中独立出来专门维护,后续会添加多线程、ftp下载等功能。JDownload的github链接请点击JDownload源代码 。
另外时隔三个月后,我按照上一篇博客里面的四个下载链接再次测试的时候发现失败了,原因在于其中有的http链接已经发生变化,比如stable目录下的hbase从1.2.4升级成1.2.5了。然后我把其中有个链接中的1.2.4改成1.2.5结果也无法下载,后来发现是改成1.2.5后的链接是对的,但是服务器会把这个链接重定向到真正的下载链接。由于JDownload在设计过程中并没有考虑到可能出现的重定向问题,所以对于此类链接暂时无法下载,但是在未来可能会考虑增加此类功能。所以大家在测试的时候选择好正确的http链接,确保此链接当前存在,并且是真正的下载链接而不是重定向的链接,这样才会测试成功。
PS: 本文是github用户junhuster,以及微博用户http://weibo.com/junhuster 的原创作品,转载请注明原作者和博客出处,谢谢。
二 断点续传功能展示
测试链接 http://www.flashget.com/apps/flashget3.7.0.1222cn.exe ,这是快车下载软件的官网下载链接,注意,如果读者也用快车链接来做实验的话,请先到快车官网检查下最新的下载链接,因为诸如软件升级改版本号等问题,就会导致本文给出的链接失效。在实验的过程中,作者在虚拟机Ubuntu linux的终端shell里面先提交一个脚本从快车官网下载,等下载到1M左右的时候,终端输入crtl-z中断程序的执行。然后再次运行另外一个脚本,这个脚本会告诉JDownload 去读取断点文件,然后接着上次未完成的下载点继续下载。下载成功后,把快车拷贝到windows 10操作系统里,然后点击测试证明下载的文件可以正确执行。实验过程的截图如下:
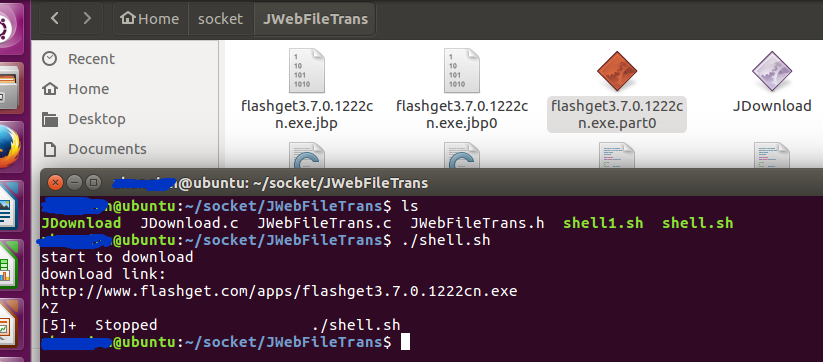
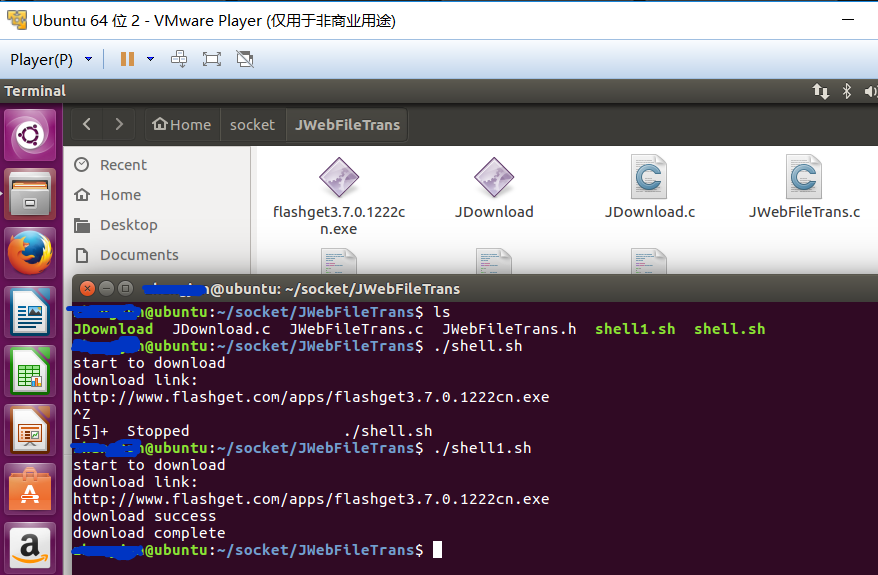
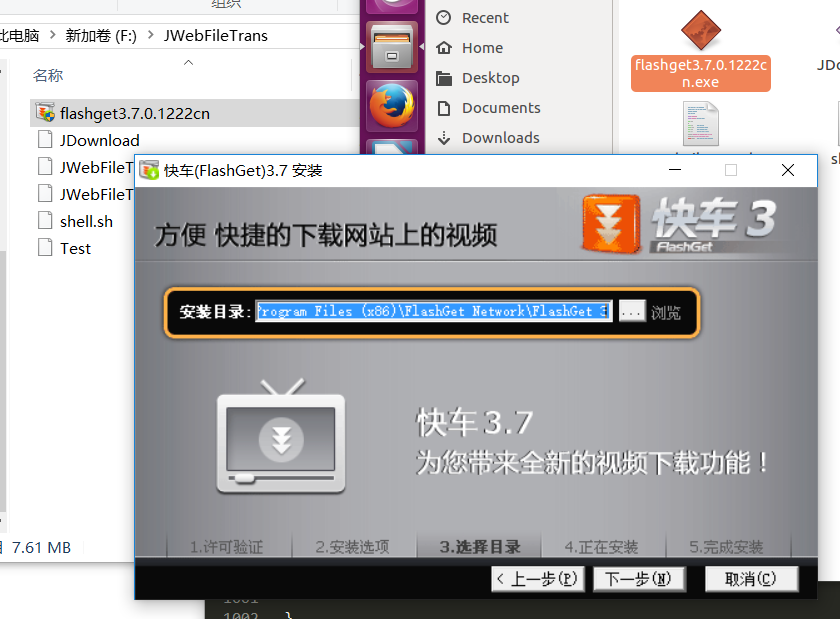
如上图,从第一张图中的终端可以看出,中途笔者执行了crtl-z中断了执行,图中后缀.jbp .jbp0是断点文件,断点续传依赖这些断点数据来继续下载,.part0是未下载完成的快车软件。在第二张图中读者可以看到作者在中断了上一次的执行后,再一次执行另外一个脚本shell1.sh,(这两个脚本请参加作者的github JDownload的test目录),开始继续上次的下载,直到完成。最后一张图是把在ubuntu中下载的快车软件复制的windows里面执行的画面,以确保下载的软件没有出现错误。显然从图中可以看出安装程序可以正常执行。
三 基本思路
关于下载的功能设计部分请读者参考作者的上一篇博客,或者直接参考github代码,链接在前言中。本文主要描述如何在上一篇博客的基础上加入断点续传的功能。
其实断点续传的功能挺简单的,无非就是记录一下上次下载的位置,然后再次下载的时候从那个位置开始就行了。从上一篇博客可以了解到,在下载一个文件的时候,我们会按照一定的规则把这个文件划分为N等分,每一次向服务器请求1/N的数据。所以显然为了支持断点续传,我们需要记录该文件被等分的数目N, 因为是续传我们还要记录上一次已经下载了多少个等分。中断下载后再一次链接时需要知道服务器的链接(或者ip),因此这些信息也是需要记录的。因此在单线程下载的时候只需要用一个文件记录这些信息就行了。然而未来要假如多线程的支持,那个时候一个文件会同时由M个线程同时下载,每一个线程下载这个文件的第i到第j个等分,对于每一个线程来说,都有可能下载中断重新续传的可能性,所以每一个线程所下载的那部分文件都需要记录一份断点信息。而且应该还有一份单独的信息记录总共文件被分成了几份来下载(例如4个线程就相当于把文件分成了四份来下载),这样下载中断后,下载就可以挨个读取所有的断点文件来续传。
由以上描述我们可以设计出如下的数据结构:
下面这个描述的是总体断点的信息情况
1 typedef struct break_point{ 2 3 long file_size; 4 long num_of_part_file; 5 long size_of_one_piece; 6 long total_num_of_piece_of_whole_file; 7 char server_ip[128+1]; 8 int server_port; 9 10 }break_point;
各个字段的含义是:
- file_size: 文件大小,以字节为单位
- num_of_part_file: 文件被分为多少份来下载,比如四个线程来下载就是四份
- size_of_one_piece: 前文说过,一个大文件被分为很多小的等分,这个字段就表示每一个等分的大小,也是以字节为单位
- total_num_of_piece_of_whole_file: 文件总共有多少等分
- server_ip: 服务器ip地址
- server_port: 服务器端口号
下面这个是描述的是每一个线程下载的那部分文件对应的断点信息,当前实际上只有一个线程,未来会加入多线程的支持
1 typedef struct break_point_part 2 { 3 long start_num_of_piece_of_this_part_file; 4 long end_num_of_piece_of_this_part_file; 5 long size_of_last_incomplete_piece; 6 long alread_download_num_of_piece; 7 }break_point_of_part;
各个字段的含义是:
- start_num_of_piece_of_this_part_file: 该部分文件对应的起始等分数,也即前文提到的第i个等分
- end_num_of_piece_of_this_part_file: 分到的结束等分数,也即前文提到的第j个等分
- size_of_last_incomplete_piece: 文件不一定能够完全均分,最后一份取余数
- alread_download_num_of_piece:已经下载了的等分数目
假如,我们一开始启用了四个线程来下载,那么就会生成一份break_point信息,四份break_point_of_part信息。
在一开始的时候我们向服务器查询要下载的文件的大小,然后根据自己代码中每一次下载分片的大小,将文件记为N等分,这N等分将分给M个线程,每一个线程下载其中的N/M个等分。根据这些信息就可以创建出相应的断点文件。然后每一个线程在每一次下载成功后就更新一下对应的断点文件,主要是更新已经下载的等分数目。在中断下载后,再一次下载的时候,程序首先会读取break_point断点文件,得到总共有多少个break_point_of_part断点文件,然后挨个读取break_point_of_part断点文件,解析之,然后继续上次未完成的地方继续下载。
由上所述,我们可以设计出如下几个函数:
1 int Http_create_breakpoint_file(char *file_name, FILE **fp_breakpoint, long file_size, long num_of_part_file, long size_of_one_piece, 2 long total_num_of_piece_of_whole_file, 3 char *server_ip, int server_port); 4 int Http_create_breakpoint_part_file(char *file_name, FILE **fp_breakpoint_part, int part_num, long start_num_of_piece_of_this_part_file, 5 long end_num_of_piece_of_this_part_file, 6 long size_of_last_incompelet_piece, 7 long alread_download_num_of_piece); 8 int Update_breakpoint_part_file(FILE *fp_breakpoint_part, int num_of_piece_tobe_added); 9 int Delete_breakpoint_file(char *file_name, FILE *fp);
四 代码实现
下载部分的代码请参考上一篇博客或者github源代码。这里主要描述断点相关函数。
首先是Http_create_breakpoint_file:
1 int Http_create_breakpoint_file(char *file_name, FILE **fp_breakpoint, long file_size, long num_of_part_file, long size_of_one_piece, 2 long total_num_of_piece_of_whole_file, 3 char *server_ip, int server_port){ 4 /** 5 ** check argument error 6 */ 7 if(file_name==NULL || fp_breakpoint==NULL){ 8 9 printf("Http_create_breakpoint_file: argument error\n"); 10 exit(0); 11 } 12 13 char *break_point_file_name=(char *)malloc((strlen(file_name)+4+1)*sizeof(char)); 14 if(NULL==break_point_file_name){ 15 16 printf("Http_create_breakpoint_file: malloc failed\n"); 17 exit(0); 18 19 } 20 strcpy(break_point_file_name,file_name); 21 strcat(break_point_file_name,".jbp"); 22 23 if(access(break_point_file_name,F_OK)==0){ 24 int ret=remove(break_point_file_name); 25 if(ret!=0){ 26 perror("Http_create_breakpoint_file,remove,\n"); 27 exit(0); 28 } 29 } 30 31 *fp_breakpoint=fopen(break_point_file_name,"w+"); 32 if(NULL==*fp_breakpoint){ 33 printf("Http_create_breakpoint_file: fopen failed\n"); 34 exit(0); 35 } 36 37 unsigned char *break_point_buffer=(unsigned char *)malloc(sizeof(break_point)+1000); 38 if(NULL==break_point_buffer){ 39 printf("Http_create_breakpoint_file: malloc failed\n"); 40 exit(0); 41 } 42 43 ((break_point *)break_point_buffer)->file_size=file_size; 44 ((break_point *)break_point_buffer)->num_of_part_file=number_of_part_file; 45 ((break_point *)break_point_buffer)->size_of_one_piece=size_of_one_piece; 46 ((break_point *)break_point_buffer)->total_num_of_piece_of_whole_file=total_num_of_piece_of_whole_file; 47 ((break_point *)break_point_buffer)->server_port=server_port; 48 49 memcpy(((break_point *)break_point_buffer)->server_ip, server_ip, strlen(server_ip)); 50 ((break_point *)break_point_buffer)->server_ip[strlen(server_ip)]='\0'; 51 52 53 int ret_fwrite=fwrite(break_point_buffer,sizeof(break_point),1,*fp_breakpoint); 54 fflush(*fp_breakpoint); 55 56 if(ret_fwrite!=1){ 57 printf("Http_create_breakpoint_file: fwrite failed \n"); 58 exit(0); 59 } 60 61 if(break_point_file_name!=NULL){ 62 free(break_point_file_name); 63 } 64 65 return 1; 66 }
然后是Http_create_breakpoint_part_file:
1 int Http_create_breakpoint_part_file(char *file_name, FILE **fp_breakpoint_part, int part_num, long start_num_of_piece_of_this_part_file, 2 long end_num_of_piece_of_this_part_file, 3 long size_of_last_incomplete_piece, 4 long alread_download_num_of_piece){ 5 if(file_name==NULL || fp_breakpoint_part==NULL || part_num<0){ 6 printf("Http_create_breakpoint_part_file, argument error\n"); 7 exit(0); 8 } 9 10 char buffer_for_part_num[6]; 11 sprintf(buffer_for_part_num, "%d",part_num); 12 int part_num_str_len=strlen(buffer_for_part_num); 13 char *break_point_part_file_name=(char *)malloc((strlen(file_name)+4+part_num_str_len+1)*sizeof(char)); 14 if(break_point_part_file_name==NULL){ 15 printf("Http_create_breakpoint_part_file,malloc failed\n"); 16 exit(0); 17 } 18 19 strcpy(break_point_part_file_name,file_name); 20 strcat(break_point_part_file_name,".jbp"); 21 strcat(break_point_part_file_name,buffer_for_part_num); 22 23 if(access(break_point_part_file_name,F_OK)==0){ 24 int ret=remove(break_point_part_file_name); 25 if(ret!=0){ 26 perror("Http_create_breakpoint_part_file,remove"); 27 exit(0); 28 } 29 } 30 31 *fp_breakpoint_part=fopen(break_point_part_file_name, "w+"); 32 if(*fp_breakpoint_part==NULL){ 33 printf("Http_create_breakpoint_part_file,fopen failed\n"); 34 exit(0); 35 } 36 37 break_point_of_part bpt; 38 bpt.start_num_of_piece_of_this_part_file=start_num_of_piece_of_this_part_file; 39 bpt.end_num_of_piece_of_this_part_file=end_num_of_piece_of_this_part_file; 40 bpt.size_of_last_incomplete_piece=size_of_last_incomplete_piece; 41 bpt.alread_download_num_of_piece=alread_download_num_of_piece; 42 43 44 int ret=fwrite(&bpt, sizeof(break_point_of_part), 1, *fp_breakpoint_part); 45 if(ret!=1){ 46 printf("Http_create_breakpoint_part_file,fwrite, break_point_of_part,error\n"); 47 exit(0); 48 } 49 50 51 fflush(*fp_breakpoint_part); 52 53 54 if(break_point_part_file_name!=NULL){ 55 free(break_point_part_file_name); 56 } 57 58 return 0; 59 60 }
接下来是int Update_breakpoint_part_file:
1 int Update_breakpoint_part_file(FILE *fp_breakpoint_part, int num_of_piece_tobe_added){ 2 3 if(fp_breakpoint_part==NULL || num_of_piece_tobe_added<1){ 4 printf("Update_breakpoint_part_file,argument error\n"); 5 exit(0); 6 } 7 8 break_point_of_part *bpt=(break_point_of_part *)malloc(sizeof(break_point_of_part)); 9 if(bpt==NULL){ 10 printf("Update_breakpoint_part_file,malloc failed\n"); 11 exit(0); 12 } 13 fseek(fp_breakpoint_part, 0, SEEK_SET); 14 int ret_fread=fread(bpt, sizeof(break_point_of_part), 1, fp_breakpoint_part); 15 16 int start_num=bpt->start_num_of_piece_of_this_part_file; 17 int end_num=bpt->end_num_of_piece_of_this_part_file; 18 bpt->alread_download_num_of_piece=bpt->alread_download_num_of_piece+num_of_piece_tobe_added; 19 if((bpt->alread_download_num_of_piece)<=(bpt->end_num_of_piece_of_this_part_file-bpt->start_num_of_piece_of_this_part_file+1+1)){ 20 fseek(fp_breakpoint_part, 0, SEEK_SET); 21 int ret=fwrite(bpt, sizeof(break_point_of_part), 1, fp_breakpoint_part); 22 if(ret!=1){ 23 printf("Update_breakpoint_part_file,fwrite failed\n"); 24 exit(0); 25 } 26 fflush(fp_breakpoint_part); 27 }else{ 28 printf("Update_breakpoint_part_file, num_of_piece_tobe_added not correct\n"); 29 exit(0); 30 } 31 32 }
最后是Delete_breakpoint_file,文件下载成功后,这些断点文件应该删除
1 int Delete_breakpoint_file(char *file_name,FILE *fp){ 2 3 if(file_name==NULL || fp==NULL){ 4 printf("Delete_breakpoint_file, argument error\n"); 5 exit(0); 6 } 7 8 break_point *bp=(break_point *)malloc(sizeof(break_point)); 9 fseek(fp, 0, SEEK_SET); 10 int ret=fread(bp, sizeof(break_point), 1, fp); 11 if(ret!=1){ 12 printf("Delete_breakpoint_file,fread failed\n"); 13 exit(0); 14 } 15 int num=bp->num_of_part_file; 16 17 char *buffer=(char *)malloc((strlen(file_name)+4+100)); 18 for(int i=0;i<num;i++){ 19 20 char buffer_part[6]; 21 sprintf(buffer_part, "%d",i); 22 strcpy(buffer,file_name); 23 strcat(buffer,".jbp"); 24 strcat(buffer,buffer_part); 25 26 if(access(buffer, F_OK)==0){ 27 if(remove(buffer)!=0){ 28 perror("Delete_breakpoint_file,remove .jbp_num"); 29 exit(0); 30 } 31 } 32 33 } 34 35 36 37 fclose(fp); 38 strcpy(buffer, file_name); 39 strcat(buffer, ".jbp"); 40 41 if(access(buffer, F_OK)==0){ 42 if(remove(buffer)!=0){ 43 perror("Delete_breakpoint_file,remove .jbp"); 44 exit(0); 45 } 46 } 47 48 if(buffer!=NULL){ 49 free(buffer); 50 } 51 52 return 0; 53 }
注意,每一次重新续传读取断点文件的时候模式不要设错了,笔者之前每次读取断点文件以“w+”模式打开,结果每次下载完后,文件都是错误的,原因是w+模式打开文件,会把文件清零,这样自然就出错了。
五 结束语
自此整篇文章就结束了,更详细的信息请访问笔者的github链接。
联系方式:https://github.com/junhuster/
http://weibo.com/junhuster/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号