
一 前言
截止到目前为止,虽然并不完美,但是JDFS已经初步具备了完整的分布式文件管理功能了,包括:文件的冗余存储、文件元信息的查询、文件的下载、文件的删除等。本文将对JDFS做一个总体的介绍,主要是介绍JDFS的整体架构,流程图等,另外还会介绍如何安装部署运行JDFS.当然正如前面几篇博客里笔者提到的,JDFS并不完美,有一些潜在的难以发现的bug偶尔会出现,这个有赖于后续的不断测试、调试来解决。如果你是第一次阅读JDFS系列博客,笔者建议先读一下该系列的另外几篇博客,其链接如下:
- JDFS:一款分布式文件管理实用程序第一篇(线程池、epoll、上传、下载) 点击我
- JDFS:一款分布式文件管理实用程序第二篇(更新升级、解决一些bug) 点击我
- JDFS:一款分布式文件管理系统,第三篇(流式云存储) 点击我
- JDFS:一款分布式文件管理系统,第四篇(流式云存储续篇) 点击我
JDFS代码已经上传到github,地址请点击我
PS: 本篇博客是博客园用户“cs小学生”的原创作品,转载请注明原作者和原文链接,谢谢。
二 JDFS 架构概览
在前四篇博客中,笔者以文字、代码片段的方式叙述了JDFS的技术细节,每一篇都是针对某个特定功能的。而现在JDFS已经作为一个整体初步完成了,所以在这里我们将从总体上看一下JDFS长什么样,由哪些component组成,从客户端提交任务到任务完成走了一个怎样的路径。接下来将用3个小节来分别介绍一下:JDFS服务端的架构、文件流式冗余存储的流程图、文件下载的执行流。
1 JDFS服务端的架构
我们先来看一张JDFS server端的架构示意图:
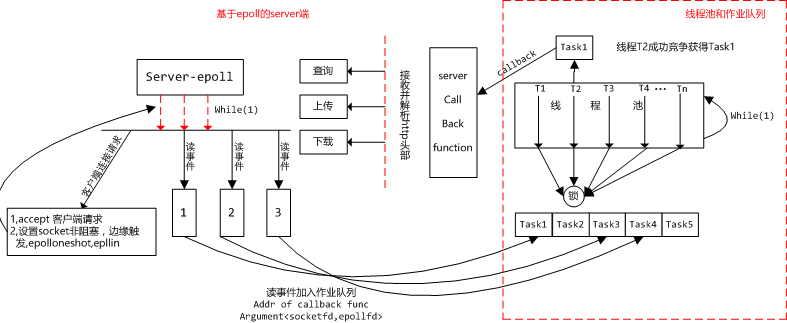
如上图所示,即为Server端的架构示意图,在JDFS中,name node和data node上面跑的server均是采用的图中的架构。从图中可以看出,server端主要包括两个大的部分:监听客户端事件的模块(图左),线程池&作业队列(图右)。监听模块监听客户端的事件,如果是连接事件,则服务端接受之,不需要线程池的参与,而如果epoll监听到读事件(也即客户端发送数据过来),则把该事件打包成一个task,加入到作业队列中,线程池中的线程会时时刻刻盯着作业队列,有task则试图从队列中取出task来执行。在这里不管是server端把task加入到作业队列还是线程池里的线程从task队列中取出task都需要在同步锁的保护下互斥地执行,以保证数据的正确访问。
上一段描述了server端执行的大致过程,现在我们分别介绍下server-epoll端、线程池都有哪些函数来支撑的,然后结合着图中的执行流以及实现的函数,详细描述一下服务端的执行细节。
server-epoll端实现的函数如下:
1 int Http_server_bind_and_listen(char *ip, int port, int *server_listen_fd); 2 int Http_server_body(char *ip, int port, int *server_listen_fd, threadpool *pool); 3 void *Http_server_callback(void *arg);
线程池&作业队列端实现的函数如下:
1 int threadpool_create(threadpool *pool, int num_of_thread, int max_num_of_jobs_of_one_task_queue); 2 int threadpool_add_jobs_to_taskqueue(threadpool *pool, void * (*call_back_func)(void *arg), void *arg); 3 int threadpool_fetch_jobs_from_taskqueue(threadpool *pool, job **job_fetched); 4 void *thread_func(void *arg); 5 int destory_threadpool(threadpool *pool);
其中threadpool_add_jobs_to_taskqueue()是线程池暴露给server-epoll端的接口,用来向作业队列加入task用的。下面我们结合函数接口来详细介绍一下服务端启动的过程。
在c语言里,显然我们需要写一个main()函数来启动server,我们需要先创建线程池,然后启动服务端,可能的启动代码如下:
1 threadpool *pool=(threadpool *)malloc(sizeof(threadpool)); 2 threadpool_create(pool, 6, 20); 3 Http_server_body(ip_str,port,&server_listen_fd,pool); 4 destory_threadpool(pool);
首先我们用threadpool_create()函数创建了一个线程池,该线程池中有6个线程,作业队列中最大容纳20个task,在图中我们可以看到,矩形框代表着线程池,框的右边有一个while(1),意为线程池是一个无限循环,循环里不断从task队列中取task,执行之,执行完毕后,继续在while循环里互斥地取下一个task.当然截止目前,作业队列里面还没有任何task,此时线程池里面所有的线程都卡在pthread_cond_t类型的变量上,后续一旦有task被加入队列中,被卡住的线程会被唤醒并同时竞争队列里的task.
现在让我们把目光从线程池移到server-epoll端。上图左边最上边带“server-epoll”字样的矩形框标志着Http_server_body()被调用,服务端已经启动了。Http_server_body()会先调用Http_server_bind_and_listen()来监听server端的<ip,port>,后续客户端的请求都发送到这个ip-端口所代表的服务端上。监听端口搞定后,接下来我们需要创建一个epoll,并且把监听的socket fd加入到epoll中,接下来我们就需要在一个无限循环中while(1)来不断调用epoll_wait()检测是否有事件发生。上图中server-epoll矩形框下面有三条红色虚线箭头,旁边有一个while(1)也即代表了我们所说的:在无限循环中监测事件的发生。从图中红虚线箭头所指向的逻辑可以看出来,客户端发过来的请求有两种:其一是客户端的连接请求,其二是某个socket fd上监测到读事件(客户端发送数据过来)。
对于客户端的连接请求,将由服务端“亲自”处理,从图中我们可以看出:服务端主线程需要首先调用accept()函数接受客户端的连接请求,接受成功则会得到一个socket-fd代表着某个客户端与服务端的socket连接。紧接着我们会把该socket-fd设置为非阻塞、边缘触发、epolloneshot、epollin. 其中之所以会用到边缘触发和epolloneshot的原因在之前的博客里面有详细介绍,读者可以到前言里面找到这些连接自行阅读,此处不再赘述,epollin的意思是监听该socket-fd上的读事件。这些属性都设置好后,需要把该socket-fd再次加入到之前创建的epoll中,使用接口epoll_ctl()可以达到这个目的。这些都做完后,如果客户端发送数据过来,epoll就会监测并报告,正如图中我们画了三个小矩形框代表着监测到的3个读事件,这个时候server端主线程需要把读事件包装成一个task,并调用线程池提供的接口threadpool_add_jobs_to_taskqueue()把该作业加入到task队列中,当然该函数在此处的实现是线程安全的。我们说了task,task包括回调函数的地址、对应读事件的socket-fd、epollfd,所谓回调函数以本文为例,是这样的:回调函数逻辑上是和server-epoll端是一体的,但是调用回调函数的caller并不是server端,而是线程池端通过指针来调用的,简言之,A处的函数,B处通过函数指针来调用。
现在让我们把目光再次转移到线程池里,前文说过线程池刚创建的时候所有的线程都卡在pthread_cond_t类型的变量上,如图所示,运行一段时间后,server端主线程已经将5个task加入到作业队列里面了,再加入task的过程中,如果当前task队列为空,则作业加入后会使用pthread_cond_broadcast()来唤醒所有卡住的线程,此时如图所示,我们假设线程T2成功竞争获得task1,于是线程T2从task1中拿到回调函数的地址,和参数,然后调用之。此刻回调函数开始执行,图中带“server call back function”字样的矩形框代表了这一执行过程,callback函数会首先使用recv()函数接收一个头部(代码里自定义的头部,长度是已知的),接收完头部后,callback()函数会解析头部看看是哪种类型的请求,并调用具体的接口函数来执行该请求,如图所示对于data node来说有查询、上传、下载等不同的功能接口函数。
以上便是server端的一个完整执行流的过程描述,在JDFS中有两种计算结点,一个是data node一个是name node,上面跑的server均是按照本小节描述的过程来工作的。
2 流式冗余存储执行流
先来看一下对应的执行流程图:
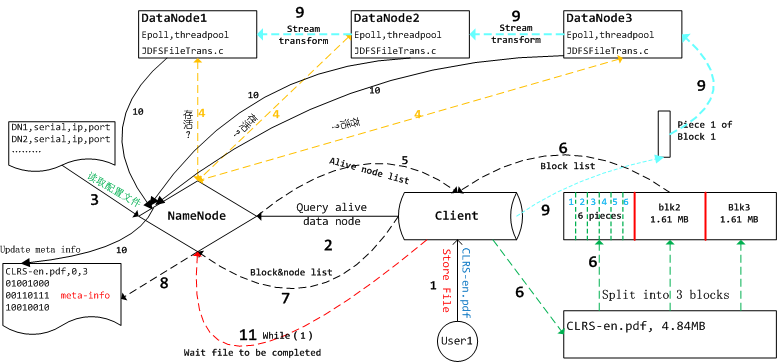
上面这张图描述了我们把算法导论CLRS-en.pdf流式冗余地存储到三个data node的全过程。图中的数字标志了执行的先后顺序,有些线条用同一种特殊的颜色比如黑色虚线,意为这几个步骤逻辑上连接比较紧密。现在我们就顺着数字1,2,3....10来详细看一看具体的过程。在数字1处,用户User1向Client发出存储CLRS-en.pdf的请求,client是提供了若干面向用户的接口,用户可以直接调用该接口来完成相应的功能,从图中我们可以看到用户把CLRS-en.pdf作为参数传递给了Client。然后入数字2标志的箭头所示,Client首先会向Name node发送一个http请求,查询当前虚拟集群里面还活跃着的data node。顺着数字3我们看到name node首先会读取本地的配置文件(里面记录了所有data node的ip地址、监听端口、串号等信息),对于配置文件里面列出的所有<ip,port>对,name node会向<ip,port>标志的服务发送一个查询是否活跃的请求,这个过程用数字4标志的黄色虚线表示,该虚线是个双向箭头,活跃着的data node在接收到name node发过来的查询请求后,会沿着同一个socket-fd(如图中的黄色虚线)发送数据给name node告诉它我目前处于活跃状态,可以提供相应的服务。
接下来的逻辑我们聚焦于数字5,6,7,8标志的黑色虚线,数字5标志的虚线表示name node会把上一步查询到的活跃的data node的ip地址,端口等发送给Client,接着两个数字6标志的绿色虚线表示Client按照一定的策略把CLRS-en.pdf分割为3个block,然后基于<活跃的结点列表、本地文件的分块信息>, Client端会按照一定的策略为每一个block选取若干个data node结点来冗余地存储该block. 然后Client会把这些信息沿着8标志的黑色虚线发送给name node,告诉name node“我打算把CRLS-en.pdf”分成3个block冗余地存储于虚拟集群里。Name node会在本地创建一个同名的文件来存储该文件的元信息。如图所示,元信息记录了如下信息:文件名,文件的状态(0表示打算存储,但是还没有完成),文件的block数目,接下来是每一个block对应的具体信息:该block存储于哪个结点上,标志为0的表示不打算存储在对应的数据结点上,标志为1的表示应该存储到对应的数据结点上但是还没有存储成功。在JDFS的实现当中,10010010表示第3个block应当冗余存储到第1,4,7个结点上面。
接下来如图中9所标志的4条虚线箭头代表了流式冗余存储的过程。如图所示每一个block在传输前又继续被分成了6个pieces(此处简化了,实际代码中被分成了100多片),client会挨个遍历每个block的每一个pieces,并且把它传输给datanode3,这个过程是串行的,也即成功传递一个piece后才会传递下一个piece. datanode3每成功接收一个piece都会给Client发送一个确认信息,这样Client就知道该piece成功传递,否则需要重新传输。
接下来的情况比较复杂,也是潜在bug容易出现的地方:流式传递。所谓流式传递,以上图为例,每一个data node再接收上一个data node传输过来的piece后,需要把这个piece传递给下一个data node,同时继续接收上一个data node发送过来的下一个piece,这个过程就像是字节流一样,所以被称之为流式传递。笔者曾将在网上找到一篇介绍HDFS的博客,里面介绍HDFS就是采用的流式传递的方式来传输数据分片,本文就是借鉴HDFS的这个处理方式来实现的,在此感谢HDFS。刚才说了这个过程是比较复杂的,原因在于此时数据的传递已经不向Client-datanode3之间那样是串行传输,从datanode3--->datanode2--->datanode1的传输过程不再是串行的,对于datanode2来说,很可能第一个block的第2个piece比第1个piece先到达,此时接收顺序已经是乱序、并行的了。所以此时面临的问题是datanodex里的所有线程同时接收block的piece,文件由谁来创建是一个问题,另外在最初笔者经过很多的bug调试后决定使用边缘触发、epolloneshot的,这些问题的原因读者都可以在前几篇博客里面找到,此处不再赘述。
对于Client来说,在把所有数据分片成功传输给datanode3后,剩下的事情就是数字11标志的“wait file to be completed”的过程,注意此时Client的数据虽然成功发送完毕了,但是datanode3-datanode2-datanode1之间的流式传递很可能还没有完成,所以此处需要等待数据传输完毕。Client会间歇式地给name node发送请求查询文件是否存储完毕,Name node会读取对应文件的元信息,检测每一个block对应的元信息,如果所有先前标志为1的数字都变成了2,则说明该文件已经存完毕,name node会把该文件标志为已经完成存储,然后告诉Client,此时Client收到存储成功的消息后就会返回。
那么这些原先标志为1的数字怎么变成2了呢?让我们把目光移动到图中数字10标志的黑色实线处,每一个data node在成功接收完毕一个完整的block后,就会发送消息给name node,name node此时就会更新该block对应的元信息,也即把相应的1该为2,表示该block成功存储到对应的datanode上了。前面我们说过,对于data node2,3来说,接收到的数据分片是乱序的,很可能接收到某个block的最后一个分片后,实际上该block的其他分片还没有被成功传输,那么这个问题怎么解决呢?在JDFS中我们让接收某个block的最后一个分片的线程负责这件事,该线程会等待其他所有分片到达完毕后,发消息给name node告知该block已经接收完毕。具体的实现可以参见github里面的代码。
以上就是CLRS-en.pdf被分割后,流式冗余存储到虚拟集群里的全过程,下面我们罗列一下name node, data node, client分别实现的函数接口:
name node的实现代码:
1 void *Http_server_callback_query_nodelist(void *arg);3 void *Http_server_callback_query_ip_from_node_serial(void *arg); 4 void *Http_server_callback__cloudstr_meta(void *arg); 5 void *Http_server_callback_update_meta_info(void *arg); 6 void *Http_server_callback_wait_meta_complete(void *arg); 7 void *Http_server_callback_delete_meta_file(void *arg);
data node的实现代码:
1 void *Http_server_callback_query(void *arg); 2 void *Http_server_callback_upload(void *arg); 3 void *Http_server_callback_download(void *arg); 4 void *Http_server_callback_query_node_alive(void *arg); 5 int Http_stream_transform_file(callback_arg_upload *cb_arg_upload, char *namenode_ip, int namenode_port); 6 void *Http_server_callback_delete_file(void *arg);
client端的实现代码,包括了后续将要介绍的下载、删除、显示等功能的代码:
1 int JDFS_cloud_query_node_list( char *server_ip, int server_port, node_list *nli); 2 int JDFS_cloud_store_file(char *file_name, int flag); 3 int JDFS_cloud_store_one_block(char *file_name, int block_num,char nodes_8_bits, node_list *nli, int total_num_of_blocks); 4 int Split_file_into_several_parts(char *file_name, int part_size); 5 int Extract_part_file_and_store(FILE *fp,char *new_file_name,int range_begin,int range_end); 6 int JDFS_wait_file_transform_completed(char *file_name, char *ip_str, int port); 7 int JDFS_cloud_query_file(char *file_name, JDFS_file_info *jfi,int flag);//flag, 0: query for reading ,1 :query for deleting 8 int JDFS_cloud_query_ip_from_node_serial(int serial_num, char *ip_str); 9 int JDFS_cloud_fetch_file(char *file_name); 10 int JDFS_cloud_merge_file(char *file_name, int num_of_blocks); 11 int JDFS_cloud_delete_file(char *file_name); 12 int JDFS_cloud_delete_file_internal(char *file_name, char *ip_str, int port); 13 int JDFS_cloud_delete_meta_file(char *file_name, char *ip_str, int port); 14 int JDFS_cloud_display_file_info(char *file_name); 16 int JDFS_select_optimal_node_for_one_block(each_block_info *ebi);//return the optimal node num 17 int JDFS_cloud_fetch_one_block(char *file_name, int block_num,int node_num, char *destination_file_path);
3 从云端下载文件到本地

如上图所示,CLRS-en.pdf已经被分成若干个block,每一个block冗余地存储在不同的data node里。这里我们要从云端把组成文件的所有block下载到本地,然后合并还原原始文件。在数字1标志的箭头处,用户user1向Client发出fetch file的请求,并且把文件名CLRS-en.pdf传给了Client. 如数字2,3标志的箭头所示,Client先向Name node发出查询文件CLRS-en.pdf元信息的请求,然后name node在本地的配置文件里找到CLRS-en.pdf的元信息文件,读取后把相关信息发送给Client. 在数字5标志的箭头处我们可以看到Client先解析name node发送过来的数据,解析的结果是CLRS-en.pdf有3个block组成,block 1冗余地存储在data node 2,5上,block2 冗余地存储于data node 3,4,6,7,8上,block3 冗余地存储于data node 1,4上。(因为篇幅有限,图中只列出了data node 1,2,3)。为了获得CLRS-en.pdf,客户端需要把组成该文件的3个block都下载下来。客户端通过特定的策略决定从data node 2下载block1, data node 3下载block2, data node 1 下载block3. 此时Client还不知道data node 1,2,3的ip地址,于是数字6,7,处客户端向name node查询data node 1,2,3的ip地址。接下来数字8,9,10处表示客户端分别从不同的data node下载相应的block, 在11处,Client将3个block合并成原始文件,返回给用户。至此文件获取的过程就全部结束了。
另外关于文件的显示、删除等逻辑比较直观,本文将不再对此进行介绍,读者可以自行阅读github上的代码或者参见前言列出的博客。
三 结束语
到此JDFS的整体结束就结束了,原本打算在本篇博客里面介绍下如何安装、部署运行JDFS的,但是写到这里,感觉有点累了,又加上篇幅太长阅读起来容易疲劳,我想还是放在下一篇博客里面介绍吧,在此期间笔者正好可以继续测试JDFS,解决一下潜在的bug之类的。联系方式:https://github.com/junhuster/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号