
一 前言
本篇博客是JDFS系列博客的第四篇,从最初简单的上传、下载,到后来加入分布式功能,背后经历了大量的调试,尤其当实验的虚拟计算结点数目增加后,一些潜在的隐藏很深的bug就陆续爆发。在此之前笔者并没有网络编程的经验,大约半年之前读到unix环境高级编程的socket章节,然后就突然对网络编程产生了兴趣,于是后来就想着写一款http远程下载小工具(是笔者另外一篇博客,链接请点击我)。再到后来,由于笔者之前读研期间接触过map-reduce,知道HDFS这个东西,于是突发奇想,不如自己动手写一款类似于HDFS的小巧的分布式文件管理系统,这便是JDFS诞生的来历。笔者开发JDFS的目的,其一是想体验、巩固一下网络编程的知识;其二是想培养实现一个功能上较为完善有一定复杂性的系统;其三也许将来笔者会着手写一个小巧的map-reduce引擎,引擎就可以使用JDFS作为中间计算结果的存储。
上一篇博客主要介绍了客户端如何把本地文件分片后流式、冗余地存储到虚拟集群里的结点里,本篇将会接着上一篇博客介绍如下几个话题:客户端向name node查询文件的元信息,并且显示在终端界面上;客户端查询完文件元信息后,向不同的data node请求下载原始文件的不同分片到本地,并且在本地合并所有分片,恢复原始文件的面貌;客户端向name node请求删除虚拟集群里面的某个文件。在前三篇博客提到的一些点,本文不会再重复赘述,因此如果读者朋友是第一次阅读本文,笔者建议最好先阅读前三篇博客,链接在下面。
- JDFS:一款分布式文件管理实用程序第一篇(线程池、epoll、上传、下载) 点击我
- JDFS:一款分布式文件管理实用程序第二篇(更新升级、解决一些bug) 点击我
- JDFS:一款分布式文件管理系统,第三篇(流式云存储) 点击我
代码已经更新到github上面,请点击我
PS: 本篇博客是博客园用户“cs小学生”的原创作品,转载请注明原作者和原文链接,谢谢。
二 实验结果展示
按照管理,先展示几张实验过程的截图
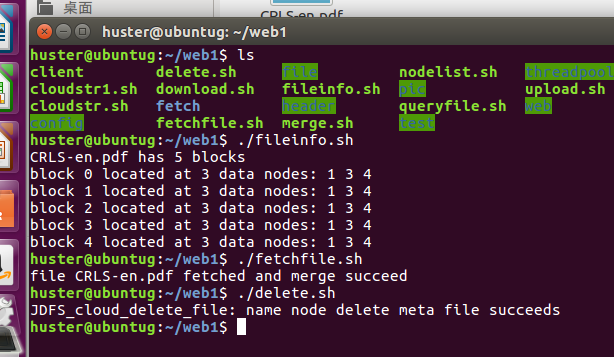

如上图所示,左边是命令行,fileinfo.sh 是向name node查询文件元信息并显示出来,从图上可以看出,CRLS-en.pdf由5个block组成,每一个block分别被冗余地存储在data node 1,3,4上面(目前代码实现的时候简单地把每一个block存储于相同的几个结点上,后续会专门实现一个为每一个block挑选结点的函数)。接着./fetchfile.sh 是把存储在虚拟集群结点上的CRLS-en.pdf的各个block下载到本地并合并还原,还原后的截图如右边那种图显示。双击打开CRLS-en.pdf的截图如下:
三 获取并显示文件元信息
在上一篇博客里,我们说过,文件的正文存储在data node上面,而描述文件元信息的文件存储在name node上。在JDFS的设计里,name node对每个将要存储到虚拟集群里的文件会在name node端创建一个同名的文件,文件里存储对应的元信息,按照存储的顺序包括如下信息:
- 文件名。元信息文件的开头100个字节用来存储文件的名字
- 文件的状态。一个int型的数据,值如果是0表示该文件还没有存储成功,1表示文件已经存储成功,2表示文件等待被删除(每一个data node删除自己的block后,name node才能最后删除元信息文件)
- block数目。一个int型的数据,表示该文件由多少个block组成,比如在本文的实验中,CRLS-en.pdf由5个block组成
- 每一个block的信息,加入block的数目是N,name接下来会有连续的N*max_num_of_nodes*sizeof(int)的存储空,其中max_num_of_nodes表示数据结点的最大数目,假设block 2 打算存储在第m个数据结点上,那么初始情况下(2-1)*max_num_of_nodes*sizeof(int)+(m-1)处的初始值应当被name node设置为1,表示期待存储在该结点上,如果后续data node成功接收到block 2后会告诉name node,然后name node会把该位置的值从1更新为2表示已经ok了。对于其他空闲的结点就初始化为0,表示block2不会存储在该node上。
那么现在客户端想在终端上显示文件的元信息,就必须首先向name node请求上述的文件元信息,获取后解析出来,然后打印在终端上面,客户端实现了下面两个函数来支持该功能:
1 int JDFS_cloud_query_file(char *file_name, JDFS_file_info *jfi,int flag);//flag, 0: query for reading ,1 :query for deleting 2 int JDFS_cloud_display_file_info(char *file_name);
函数JDFS_cloud_query_file()便是用来具体向name node请求文件元信息用的,该函数还可以被删除功能调用,因此需要加一个参数flag来区分,不同的flag, name node做的事情不同。JDFS_cloud_display_file_info()调用前者来获取文件元信息,然后解析打印之,具体的代码逻辑也比较直接,请参考前言里给出的github代码链接。
对应的name node端响应这个请求的函数如下,对应的http request_kind是13
1 void *Http_server_callback_query_file_meta_info(void *arg);
四 从虚拟结点里下载文件到本地
截止到目前我们已经实现了把文件存储到虚拟集群里的结点上,也实现了查询特定文件元信息的功能,现在我们需要把文件下载到本地。
想象一下,我们要把“云端”的数据下载到本地要经历哪些过程呢?首先客户端需要向name node查询元信息,元信息里包含了文件的block数目N,对于每个block客户端从元信息里解析出它冗余地存储在哪些结点里,然后挑选一个最优的结点将之下载到本地。在实际的场景中,挑选结点是有讲究的,如果同一个机柜里的结点有这个block,就从这个机柜里下载,否则需要从其他机柜里的某个结点下载。但是在JDFS中暂时把这个挑选的功能简化为直接指定某个结点,未来会细化这一块,目的是使得现在面临的问题不至于太复杂。文件元信息里面存储了包含这个block的结点串号,光是有串号还不行,客户端需要用这个串号向name node查询对应的ip地址和端口号(目前JDFS中简单地设置端口为8888),于是对于每一个block我就得到了<block num, ip, port>这组信息,有了这些信息我们就可以向对应的结点请求传送该block了,所有block传输到客户端后,客户端需要把这N个block合并成一个整体。
在客户端我们实现了下面几个函数来支持该功能:
1 int JDFS_cloud_query_file(char *file_name, JDFS_file_info *jfi,int flag);//flag, 0: query for reading ,1 :query for deleting 2 int JDFS_cloud_query_ip_from_node_serial(int serial_num, char *ip_str); 3 int JDFS_cloud_fetch_file(char *file_name); 4 int JDFS_cloud_merge_file(char *file_name, int num_of_blocks);
如上述代码所示,JDFS_cloud_fetch_file()是该功能的入口,它先调用JDFS_cloud_query_file()来查询文件元信息,解析出存储该block的结点串号serial_num后调用JDFS_cloud_query_ip_from_node_serial()来查询它的ip地址,得到ip地址后紧接着调用JDFS_http_download()从data node上面下载该block,都下载完后调用JDFS_cloud_merge_file()合并block成为一个文件。
name node端响应客户端查询文件元信息的过程请参见上一小节,此处不再赘述。
data node端响应客户端下载请求的逻辑在之前的博客里也详细介绍过,此处也不再赘述,感兴趣的读者可以翻看笔者之前写的博客。
五 从虚拟集群里删除文件
最后我们还需要实现删除文件的功能。想象一下,一个文件被切分成了N份,N份文件正文被冗余地存储在不同的结点上面,我们需要通知所有存储有该文件block的数据结点去删除之,另外文件的元信息也需要删除。具体的流程是客户端向name node查询文件元信息,并通知它该文件要删除了,name node server不仅要把文件元信息发送给客户端,还有把文件元信息里的“文件状态”值改为2,表示等待被删除,以防止其他客户端来读它。客户端得到文件元信息后就会通知各个data node删除相应的数据。等隶属于该文件的所有冗余block都被删除后,客户端再一次请求name node server删除该文件的元信息文件,于是删除动作完成了。
在客户端我们实现了如下几个函数来支持该功能:
1 int JDFS_cloud_delete_file(char *file_name); 2 int JDFS_cloud_delete_file_internal(char *file_name, char *ip_str, int port); 3 int JDFS_cloud_delete_meta_file(char *file_name, char *ip_str, int port); 4 5 int JDFS_cloud_query_file(char *file_name, JDFS_file_info *jfi,int flag);//flag, 0: query for reading ,1 :query for deleting 6 int JDFS_cloud_query_ip_from_node_serial(int serial_num, char *ip_str);
JDFS_cloud_delete_file()是该功能的入口点函数,它会首先调用第5,6行的函数来获得文件元信息、以及结点ip地址,然后对于文件的每一个block,查询所有存储有该block的data node,向该data node server发送删除请求,具体是通过调用JDFS_cloud_delete_file_internal()来做的,等所有的都删除完毕后,再调用JDFS_cloud_delete_meta_file()向name node server发送删除元信息文件的请求。
对于data node端,实现了一下几个函数来支持该功能
1 void *Http_server_callback_delete_file(void *arg);
对于name node server实现了如下函数来支持该功能:
1 void *Http_server_callback_delete_meta_file(void *arg);
六 结束语
到此为止,JDFS的全部功能已经介绍完毕,当前还剩下两件事情要做,其一是继续调试JDFS隐藏很深的潜在bug,使得系统能够稳定的运行,稳定运行之后,需要把data node server和name node server做成守护进程,这样server启动后就不会因为用户关闭终端而终止了,也不会因为用户按下Crtl+C等而终止,诸如此类,关于守护进程请参见《Unix环境高级编程》;其二,在下一篇博客笔者会配以流程图、结构图的方式从总体上勾画出JDFS的架构,工作流程等,还会详细介绍如何在虚拟集群里把JDFS跑起来,也有读者反应能否简化安装,一键部署等,等JDFS稳定运行后,我在来研究一下简化安装,一键部署的问题。
另外因为笔者研究生期间曾接触过一个单机多核平台的map-reduce系统,因此萌生了自己动手写一个模仿hdoop的小巧的map-reduce引擎的想法,如果未来真去做的话,正好可以用JDFS来作为中间结果的存储管理系统。
联系方式:https://github.com/junhuster/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号