矩阵论补充知识点
 只是关于矩阵论的零散的一些知识点补充和整理
只是关于矩阵论的零散的一些知识点补充和整理
|
知识点1: 当$\boldsymbol A$和$\boldsymbol B$都是$n$阶方阵时,$\boldsymbol{AB}$行列式的计算满足:
\[\left| \boldsymbol{AB} \right| = \left| \boldsymbol{A} \right| \left| \boldsymbol{B} \right| = \left| \boldsymbol{B} \right| \left| \boldsymbol{A} \right|= \left| \boldsymbol{BA} \right|
\] 🐹 推广:三个矩阵都是方阵的时候,三个矩阵相乘的行列式等于各个矩阵的行列式相乘。 |
|
知识点2: 分块矩阵的行列式:
① 若\(\boldsymbol A\)和\(\boldsymbol D\)是方阵: \[\left|\begin{array}{cc}
\boldsymbol A & \boldsymbol O \\
\boldsymbol O & \boldsymbol D
\end{array}\right| = \left|\begin{array}{cc}
\boldsymbol A & \boldsymbol * \\
\boldsymbol O & \boldsymbol D
\end{array}\right| = \left|\begin{array}{cc}
\boldsymbol A & \boldsymbol O \\
\boldsymbol * & \boldsymbol D
\end{array}\right| = \left| \boldsymbol{A} \right| \left| \boldsymbol{D} \right|
\] 参考2.1:分块矩阵行列式公式 - 趣趣的文章 - 知乎 |
|
知识点3: 分块矩阵($\boldsymbol A$、$\boldsymbol B$、$\boldsymbol C$和$\boldsymbol D$均是方阵)求逆:
① 准对角矩阵 \[\left[\begin{array}{cc}
\boldsymbol A & \boldsymbol O \\
\boldsymbol O & \boldsymbol D
\end{array}\right]^{-1} = \left[\begin{array}{cc}
\boldsymbol A^{-1} & \boldsymbol O \\
\boldsymbol O & \boldsymbol D^{-1}
\end{array}\right] \qquad \qquad \qquad
\left[\begin{array}{cc}
\boldsymbol O & \boldsymbol B \\
\boldsymbol C & \boldsymbol O
\end{array}\right]^{-1} = \left[\begin{array}{cc}
\boldsymbol O & \boldsymbol C^{-1} \\
\boldsymbol B^{-1} & \boldsymbol O
\end{array}\right]
\] ② 分块上三角矩阵/分块下三角 \[\left[\begin{array}{cc}
\boldsymbol A & \boldsymbol B \\
\boldsymbol O & \boldsymbol D
\end{array}\right]^{-1} = \left[\begin{array}{cc}
\boldsymbol A^{-1} & -\boldsymbol{A}^{-1}\boldsymbol{B}\boldsymbol{D}^{-1} \\
\boldsymbol O & \boldsymbol D^{-1}
\end{array}\right] \qquad \qquad
\left[\begin{array}{cc}
\boldsymbol A & \boldsymbol O \\
\boldsymbol C & \boldsymbol D
\end{array}\right]^{-1} = \left[\begin{array}{cc}
\boldsymbol A^{-1} & \boldsymbol O \\
\boldsymbol -\boldsymbol{D}^{-1}\boldsymbol{C}\boldsymbol{A}^{-1} & \boldsymbol D^{-1}
\end{array}\right]
\] 参考3.1:分块矩阵怎么求逆? - 知乎 |
|
知识点4: 方阵$\boldsymbol A$的多项式对应的特征值:
① 若\(\lambda\)是\(\boldsymbol A\)的特征值,如果\(\boldsymbol A\)可逆.则\(\dfrac{1}{\lambda}\)是\(\boldsymbol A^{-1}\)的特征值。 ② 若\(\lambda\)是\(\boldsymbol A\)的特征值,\(f(x)\)是一个多项式,则\(f(\lambda)\)是\(f(\boldsymbol A)\)的特征值。 |
|
知识点5: 代数重数与几何重数的理解
\[\boldsymbol{几何重数} = \dim \left\{ \boldsymbol v \in \boldsymbol V^n \mid \left( \lambda \boldsymbol I - \boldsymbol T \right) \boldsymbol v = \boldsymbol 0 \right\}
\] \[\boldsymbol{代数重数} = \dim \left\{ \boldsymbol v \in \boldsymbol V^n \mid \exists k \in \mathbb{N}(\mathbb{N}是自然数集), 使得 \left( \lambda \boldsymbol I - \boldsymbol T \right)^k \boldsymbol v = \boldsymbol 0 \right\}
\] (PS:我暂时认为上面的说法是正确的,想要深入研究并验证上述说法,可能需要彻底把下面的知识点6-Jordan标准型搞明白。) 从上面的几何和代数重数的计算可知,几何重数和代数重数其计算的公式就不一样,只不过是几何重数(一个特征值对应的特征空间)一定是包含在代数重数对应的特征空间中(因为代数重数中\(k\)可取$k = 1, 2, 3, \cdots $),并且可以得到结论:代数重数 \(\geq\) 几何重数。 或者我可以以一种不正确的表述方法描述我的理解: \[\boldsymbol{几何重数} \Rightarrow \boldsymbol{代数重数} \qquad \qquad \boldsymbol{几何重数} \nLeftarrow \boldsymbol{代数重数}
\] 也即:几何重数是代数重数的充分不必要条件,代数重数是几何重数的必要不充分条件。 参考5.1:如何理解几何重数和代数重数? - 知乎 |
|
知识点6: Jordan标准型的理解:
(😥 PS:Jordan标准型整体知识十分复杂,暂时无法整理出概述本质的简要表述,因此这里先给出如下8个参考链接,日后如果有时间进行详细学习之后,再做回来补充,或者直接另写一个博客文章链接过去。) 参考6.1:【线性代数】包看包会的若当标准形证明(1)-引言 - bilibili |
|
知识点7: 矩阵二次型:
矩阵的二次型是指一个关于向量\(\boldsymbol x \in \mathbb{R}^n\)的二次多项式,可以表示为: \[q(\boldsymbol x) = \boldsymbol x^{\mathrm T} \boldsymbol A \boldsymbol x = \sum_{i=1}^n \sum_{j=1}^n a_{ij} x_i x_j
\] 其中\(\boldsymbol A\)是\(n\times n\)的实对称矩阵,\(\boldsymbol x = (x_1,x_2,\dots,x_n)^{\mathrm T}\)是\(n\)维列向量。\(a_{ij}\)是矩阵\(\boldsymbol A\)的元素。矩阵\(\boldsymbol A\)是二次型的系数矩阵。 💠 矩阵二次型在数学和工程领域有许多应用。以下是其中的一些: 🌂 正定二次型: 正定二次型是指二次型函数的取值恒为正数,即对于二次型函数 \(Q(\boldsymbol x) = \boldsymbol x^\mathrm{T} \boldsymbol A \boldsymbol x\),对于任意的非零向量\(\boldsymbol x \in \mathbb{R}^n\),都有\(Q(\boldsymbol x) > 0\)成立的情况。其中\(\boldsymbol A\)是\(n\times n\)的实对称正定矩阵。 👂 研究正定二次型的意义在于它在数学和应用中具有广泛的应用。以下是一些重要的应用: 🎁 正定二次型在几何上有以下理解: 如果二次型\(Q(\boldsymbol{x})\)是正定的,那么它在\(\boldsymbol{x}\)取遍所有的非零向量时所得到的值都大于零,即\(Q(\boldsymbol{x})>0\)。这意味着对于所有的非零向量\(\boldsymbol{x}\),它在\(Q(\boldsymbol{x})\)作用下的结果都是正数,也就是说,向量\(\boldsymbol{x}\)的长度的平方都大于零,即\(|\boldsymbol{x}|^2>0\),即向量\(\boldsymbol{x}\)的长度都大于零。因此,正定二次型可以被视为一种将向量长度映射到正实数上的函数,它在几何上对应着一个内积,即\(Q(\boldsymbol{x})=\boldsymbol{x}^T\boldsymbol{A}\boldsymbol{x}\),其中\(\boldsymbol{A}\)是一个对称正定矩阵,\(\boldsymbol{x}^T\)表示向量\(\boldsymbol{x}\)的转置。 因此,正定二次型在几何上的意义就是它定义了一个向量空间上的内积,它可以被用来描述向量的长度、角度、投影等几何性质,以及向量之间的正交性等性质。在实际应用中,正定二次型经常被用来表示优化问题的目标函数,因为它具有良好的数学性质,例如可以使用梯度下降等优化算法来求解极小值。 在几何上,正定二次型可以理解为一个椭圆或者一个超曲面,在每个点的函数值都是正数。具体来说,对于一个\(n\)元正定二次型\(Q(x_1,x_2,\dots,x_n)=\sum_{i=1}^{n}\sum_{j=1}^{n}a_{ij}x_ix_j\),可以将它写成向量形式,即\(Q(\boldsymbol{x})=\boldsymbol{x}^T A\boldsymbol{x}\),其中\(\boldsymbol{x}\)是一个\(n\)维列向量,\(A\)是一个\(n\times n\)的对称矩阵,\(A=(a_{ij})\)。 因为\(A\)是对称矩阵,所以它可以通过正交对角化变成一个对角矩阵\(D\),即\(A=P^TDP\),其中\(P\)是一个正交矩阵,即\(P^TP=PP^T=I\),\(D\)是一个对角矩阵,对角线上的元素为\(A\)的特征值。因此,原来的二次型可以写成: Q(x)=x T Ax=xT PT DPx=(Px)T D(Px) 令\(\boldsymbol{y}=P\boldsymbol{x}\),则原来的二次型可以写成\(\boldsymbol{y}^T D\boldsymbol{y}\)的形式,其中\(\boldsymbol{y}\)的每个分量是\(\boldsymbol{x}\)在正交基\(P\)下的坐标,\(D\)是一个对角矩阵,它的对角线上的元素是原二次型的特征值。因为原来的二次型是正定的,所以\(D\)的每个特征值都大于零,因此\(\boldsymbol{y}^T D\boldsymbol{y}\)在每个点的函数值都是正数。 从几何角度来看,\(\boldsymbol{y}^T D\boldsymbol{y}\)对应的是一个椭圆或者一个超曲面,而且在每个点的函数值都是正数。这个椭圆或超曲面的形状和大小与矩阵\(A\)的特征值有关。具体地,如果\(A\)的所有特征值都很大,则对应的椭圆或超曲面就很扁,而且长轴和短轴的比例比较大;如果\(A\)的某些特征值很小,那么对应的椭圆或超曲面就很圆。这种几何意义有助于理解正定二次型的性质,以及在优化问题中的应用。 参考链接7.1:二次型的意义是什么?有什么应用? - 知乎 |
知识点8: 正交矩阵/对称矩阵/酉矩阵:
正交变换不会改变向量间的正交性,如果\(\boldsymbol u\)和\(\boldsymbol v\)正交,则\(\mathrm{T}(\boldsymbol u)\)和\(\mathrm{T}(\boldsymbol v)\)仍然是正交的。 | |||||||||||||||||||||||||||
|
知识点9: 欧氏空间与酉空间一些结论小结:
⓪ 过渡矩阵(我个人又称为基变换矩阵):旧基到新基的转换矩阵;度量矩阵:欧式空间的一组基之间的内积作为元素构成的矩阵。 ① 欧式空间两个不同基对应的度量矩阵\(\boldsymbol A\)和\(\boldsymbol B\)是合同的,即\(\boldsymbol A ≃ \boldsymbol B\); ② 一个基为标准正交基的充要条件是它的度量矩阵为单位矩阵; ③ 一个矩阵\(\boldsymbol Q\)为正交矩阵的充要条件为它的列向量是两两相互正交的单位向量。 ④ 正交矩阵非奇异、其逆矩阵仍是正交矩阵、两个正交阵相乘仍是正交阵; ⑤ 欧氏空间一个变换\(\mathrm{T}\)为正交变换的充要条件是\(\mathrm{T}\)对应于标准正交基下的矩阵是正交矩阵; ⑥ 正交变换在标准正交基下的矩阵才是正交矩阵,在别的基下不一定是正交矩阵; ⑦ 两个标准正交基之间的过渡矩阵是正交矩阵。 ⑧ 欧式空间一个变换\(\mathrm{T}\)为实对称变换的充要条件是\(\mathrm{T}\)对于标准正交基的矩阵是实对称矩阵; ⑨ 实对称矩阵的特征值均为实数、实对称矩阵不同特征值对应的特征向量正交; ⑩ 酉空间的正交变换被称为“酉变换”,酉变换在酉空间的标准正交基下的矩阵\(\boldsymbol A\)是酉矩阵,即满足\(\boldsymbol A^{\mathrm H} \boldsymbol A = \boldsymbol{AA}^{\mathrm H} = \boldsymbol I\); ⑪ 酉矩阵的逆矩阵是酉矩阵、两个酉矩阵乘积是酉矩阵; ⑫ 酉空间的对称变换被称为“Hermite变换/酉对称变换”,Hermite变换在酉空间的标准正交基下的矩阵\(\boldsymbol A\)是Hermite矩阵,即满足\(\boldsymbol A^{\mathrm H} = \boldsymbol A\); ⑬ Hermite矩阵的特征值均为实数、Hermite矩阵不同特征值对应的特征向量正交; ⑭ Schur定理:任意\(n\)阶方阵一定(酉)相似于上/下三角矩阵
\[\boldsymbol Q^{-1} \boldsymbol A \boldsymbol Q = \boldsymbol Q^{\mathrm T} \boldsymbol A \boldsymbol Q = \left[
\begin{array}{cccc}
\lambda_1 & * & \cdots & * \\
&\lambda_2 & \cdots & * \\
& & \ddots & \vdots \\
&
& & \lambda_n
\end{array}\right]
\]
\[\boldsymbol P^{-1} \boldsymbol A \boldsymbol P = \boldsymbol P^{\mathrm H} \boldsymbol A \boldsymbol P = \left[
\begin{array}{cccc}
\lambda_1 & * & \cdots & * \\
&\lambda_2 & \cdots & * \\
& & \ddots & \vdots \\
&
& & \lambda_n
\end{array}\right]
\] ⑮ \(n\)阶方阵(酉)相似于对角矩阵的充要条件:\(\boldsymbol A\)为正规矩阵,即\(\boldsymbol A^{\mathrm H} \boldsymbol A = \boldsymbol{AA}^{\mathrm H}\)
⑯ 实对称矩阵一定能正交相似于对角矩阵。 ⑰ \(\mathrm T\)为欧式空间的对称变换,则一定能找到一组基使\(\mathrm T\)在该基下的矩阵为对角矩阵。 ⑱ 复对称矩阵与实对称矩阵的显著区别之一是不一定能对角化。 ⑲ 任何\(n\)阶方阵都可以相似于一个Jordan标准形矩阵。 ⑳ 实矩阵的复特征值一定是成对共轭出现的。 |
知识点10: 常见向量范数和矩阵范数
|
|
知识点11: 级数的收敛性
🍺 正项级数及其判敛法(重点部分) 在级数理论中,正项级数是非常重要的一种,对一般级数的研究有时可以通过对正项级数的研究来获得结果,就像非负函数广义积分和一般广义积分的关系一样。
🎨 幂级数的收敛半径和收敛域 ② 幂级数及其收敛性 在实际应用中,常常用\(R = \lim\limits_{n \to \infty} \dfrac{|a_n|}{|a_{n+1}|}\)直接计算幂级数\(\sum\limits_{n=0}^{\infty}a_n x^n\)的收敛半径。另一方面,利用正项级数的根值判别法,收敛半径\(\rho\)也可以用极限\(\lim\limits_{n \to \infty} \sqrt[n]{|a_n|}\)来计算 🍭 绝对收敛级数与条件收敛级数: 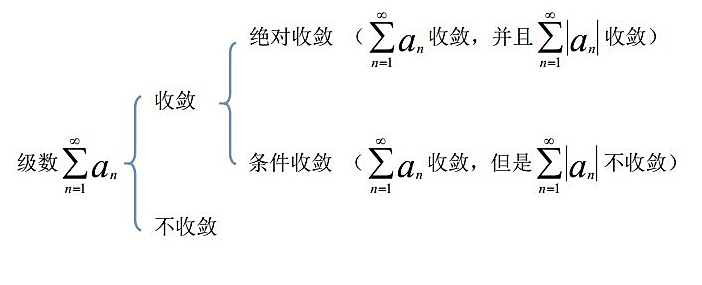 绝对收敛和条件收敛的本质区别在于:是否满足“黎曼重排定理”。
此定理说明,我们不能随意排列一个级数,并且在级数求和时候尽量不能随机排列更不能轻易加括号(一个例子就是\((-1)^n\)这个不收敛级数,如果在计算该级数和时加括号,则可能会导致得到一个收敛级数和)。 收敛半径。。。。。。。。。 转载11.1:绝对收敛级数与条件收敛级数有何本质区别? - 达瓦里希也喝脉动的回答 - 知乎 |
|
知识点12: 矩阵相关多项式的定义:
① 方阵\(\boldsymbol A\)的多项式\(f(\boldsymbol A)\): \[f(t) = \sum_{i=0}^n a_i t^i \quad \Longleftrightarrow \quad f(\boldsymbol A) = a_0 \boldsymbol I + a_1 \boldsymbol A + \cdots + a_n \boldsymbol A^n = \sum_{i=0}^{n} a_i \boldsymbol A^i
\] ② 方阵\(\boldsymbol A\)的特征矩阵: \[\boldsymbol A(\lambda) = \lambda \boldsymbol I - \boldsymbol A
\] ③ 方阵\(\boldsymbol A\)的特征多项式\(\varphi (\lambda)\): \[\varphi (\lambda) = \det(\lambda \boldsymbol I - \boldsymbol A) = \left| \lambda \boldsymbol I - \boldsymbol A \right|
\] ④ 方阵\(\boldsymbol A\)的特征方程:特征多项式\(\varphi (\lambda) = 0\) \[\varphi (\lambda) = \det(\lambda \boldsymbol I - \boldsymbol A) = \left| \lambda \boldsymbol I - \boldsymbol A \right| = 0
\] ⑤ 方阵\(\boldsymbol A\)的零化多项式\(\psi(\lambda)\): \[\psi(\lambda) = a_0 + a_1 \lambda + \cdots + a_m \lambda^m
\] 使得 \[\psi(\boldsymbol A) = a_0 \boldsymbol I + a_1 \boldsymbol A + \cdots + a_m \boldsymbol A^m =\boldsymbol O
\] 则\(\psi(\lambda)\)就是\(\boldsymbol A\)的一个零化多项式。 📢 注意:凯莱-哈密顿(Cayley-Hamilton)定理:可以利用多项式长除法用于方阵幂次的计算\(\boldsymbol A^n = ?\),其中\(n\)是一个很大的数。 方阵\(\boldsymbol A\)特征多项式\(\varphi(\lambda)\)是一个零化多项式,因为\(\varphi(\boldsymbol A) = \boldsymbol O\)。 ⑥ 方阵\(\boldsymbol A\)的最小多项式\(m(\lambda)\): 参考12.1:多项式矩阵 - 维基百科 |
|
知识点13: 方阵$\boldsymbol A$的最小多项式
对于一个矩阵\(\boldsymbol A\),我们称它首项系数为1的次数最低的零化多项式是\(\boldsymbol A\)的最小多项式,记作\(m(\lambda)\),显然有\(m(\boldsymbol A) = \boldsymbol O\)。 🚩 \(m(\lambda)\)的几个性质: ⭕ 最小多项式\(m(\lambda)\)的求法: \[m(\lambda) = (\lambda - \lambda_1)^{t_1} \times (\lambda - \lambda_2)^{t_2} \times \cdots \times (\lambda - \lambda_k)^{t_k}
\] ② 第二种方法:判断\(\boldsymbol A\)是否可以被\(\boldsymbol I\)线性表示,如果不能,判断\(\boldsymbol A^2\)是否可以被\(\boldsymbol A\)和\(\boldsymbol I\)线性表示,如果不能,判断\(\boldsymbol A^3\)是否可以被\(\boldsymbol A^2\)、\(\boldsymbol A\)、\(\boldsymbol I\)先行表示。以此类推,直到出现某个\(k\),使得\(\boldsymbol A^k\)可以被\(\boldsymbol A^{k-1}\)、···、\(\boldsymbol A\)、\(\boldsymbol I\)线性表示,不妨设: \[\boldsymbol A^k = a_{k-1} \boldsymbol A^{k-1} + \cdots + a_1 \boldsymbol A + a_0 \boldsymbol I
\] 那么其最小多项式\(m(\lambda)\)为: \[m(\lambda) = \lambda^k - a_{k-1} \lambda^{k-1} - \cdots - a_1 \lambda + a_0
\] 例如:如果\(\boldsymbol A^2 = 2\boldsymbol A-\boldsymbol I\),那么A的最小多项式为\(m(\lambda) = \lambda^2 - 2\lambda + 1\) ③ 第三种方法:矩阵\(\boldsymbol A\)的最小多项式就是\(\boldsymbol A\)的特征矩阵的第\(n\)个不变因子\(d_n(\lambda)\),这是求解一个矩阵的最小多项式的有效通法。 ④ 第四种方法:矩阵的最小多项式为最后一个不变因子。由Smith标准型(不变因子)的定义,最后一个不变因子是所有初等因子的最小公倍式,而最小多项式是所有初等因子的最小公倍式,则最小多项式是最后一个不变因子。最小多项式最高次幂是一次,由前一个不变因子整除后一个不变因子,前面的所有不变因子是一次因式的乘积,即不变因子相乘得到的特征多项式都是一次因式的乘积 r级Jordan块的最小多项式是初等因子,所以在大范围内,Jordan标准型的最小多项式是所有初等因子的乘积。 参考13.1:最小多项式 - 中文数学Wiki |
|
知识点14: 几种特殊子空间:
① 不变子空间:\(\mathrm{T}\)是\(V^n\)上一个线性变换,\(V_1\)是\(V^n\)的一个子空间,若\(\boldsymbol x \in V_1\),有\(\mathrm{T}\boldsymbol x \in V_1\),则\(V_1\)是线性变换\(\mathrm T\)的一个不变子空间。 ② 特征子空间:\(V^n\)上一个线性变换\(\mathrm{T}\)的属于特征值\(\lambda_i\)的所有特征向量+加零向量构成的子空间,即: \[V_{\lambda_i} = \left\{\boldsymbol x \mid \mathrm{T}\boldsymbol x = \lambda_i\boldsymbol x, \boldsymbol x \in V^n \right\}
\] 特征子空间的一些性质: 参考14.1:不变子空间 - 中文数学Wiki |
|
知识点15: 线性方程组有解:
一个线性方程组仅有零解的充分必要条件是该线性方程组的系数矩阵的行向量(或列向量)线性无关,即矩阵的秩等于未知量的个数。 具体来说,设线性方程组为\(\boldsymbol{Ax} = \boldsymbol b\),其中\(\boldsymbol A\)是一\(m \times n\)的矩阵,\(\boldsymbol x\)和\(\boldsymbol b\)是\(n\)维和\(m\)维列向量。则该线性方程组仅有零解的充要条件为\(\text{rank}(\boldsymbol A) = n\),即\(A\)的列向量线性无关。 |
|
知识点16: 谱半径的理解
📜 请问矩阵的谱半径该如何理解,谱半径有没有几何意义? 矩阵的谱半径可以理解为矩阵的所有特征值的绝对值的最大值。具体地,设\(\boldsymbol A\)是一个\(n\times n\)的矩阵,它的特征值为\(\lambda_1,\lambda_2,\cdots,\lambda_n\),则\(\boldsymbol A\)的谱半径定义为: \[\rho(\boldsymbol A) = \max\limits_{i}|\lambda_i| \quad (i = 1, 2, \cdots, n)
\] 从几何意义上来看,矩阵的谱半径可以描述线性变换的“最大拉伸率”。设 \(\boldsymbol A\) 是一个 \(n\) 维线性变换,如果对于所有向量 \(x\in\mathbb{R}^n\),有 \(|\boldsymbol{Ax}| \le K|\boldsymbol{x}|\),其中\(K\)是一个常数,则称\(K\)是\(\boldsymbol A\)的一个上界。而\(\boldsymbol A\)的谱半径\(\rho(\boldsymbol A)\)就是所有上界中最小的一个。也就是说,矩阵的谱半径描述了\(\boldsymbol A\)的最大拉伸率,即所有向量长度的最大变化率。 需要注意的是,矩阵的谱半径并不一定等于矩阵的模长的最大值。矩阵的模长定义为\(|\boldsymbol A| = \max_{|\boldsymbol x|=1}|\boldsymbol{Ax}|\),它表示在所有长度为\(1\)的向量上,\(\boldsymbol A\)的最大拉伸率。而矩阵的谱半径是所有特征值的绝对值的最大值,因此它只和\(\boldsymbol A\)的特征值有关,而不是和\(\boldsymbol A\)的模长有关。 📚 矩阵谱半径有什么应用呢? 矩阵谱半径在控制理论、信号处理、网络分析、优化等领域都有广泛的应用。 ① 在控制理论中,矩阵谱半径可以用于判断系统的稳定性。当矩阵的谱半径小于1时,系统是稳定的,否则是不稳定的。 ② 在信号处理中,矩阵谱半径可以用于信号去噪。通常情况下,信号是由一个稳定的矩阵变换得到的,因此矩阵的谱半径可以用于判断信号的稳定性。如果信号的谱半径较小,可以通过对信号进行矩阵变换,使得信号的谱半径变小,从而实现信号去噪的目的。 ③ 在网络分析中,矩阵谱半径可以用于衡量网络的中心性。一些重要的网络指标,如中心性和影响力等,可以通过矩阵谱半径来计算。 ④ 在优化中,矩阵谱半径可以用于判断优化算法的收敛性。如果优化算法收敛,那么矩阵的谱半径应该小于1,否则算法不收敛。因此,可以根据矩阵谱半径的大小来选择合适的优化算法。 📀 谱半径的一些性质: ① 矩阵\(\boldsymbol A\)的2范数又可表示为谱半径的形式: \[\| \boldsymbol A \|_2 = \sqrt{\lambda_{\max}},\lambda_{\max}是矩阵\boldsymbol A^{\mathrm H} \boldsymbol A的最大特征值 \quad \Longleftrightarrow \quad \| \boldsymbol A \|_2 = \sqrt{\rho(\boldsymbol A^{\mathrm H}\boldsymbol A)} = \sqrt{\rho(\boldsymbol A \boldsymbol A^{\mathrm H})}
\] 特别的,若\(\boldsymbol A\)是正规矩阵,则有\(\| \boldsymbol A \|_2 = \rho(\boldsymbol A) = \max\limits_{i}|\lambda_i|\)。 ② 设\(\boldsymbol A \in \mathbb C^{n \times n}\),则对\(\mathbb C^{n \times n}\)上的任意矩阵范数\(\| \cdot \|\)都有: \[\rho(\boldsymbol A) \leq \| \boldsymbol A \|
\] 并且\(\rho(\boldsymbol A)\)是\(\boldsymbol A\)的所有范数的下确界。 ③ 若对\(\mathbb C^{n \times n}\)上的某一矩阵范数\(\| \cdot \|_M\)有\(\| \boldsymbol A\|_M < 1 \Longleftrightarrow \rho(\boldsymbol A) < 1\),则\(\boldsymbol{I-A}\)就是可逆的。 ④ 对于任意的\(n\)阶矩阵\(\boldsymbol A\),其谱半径\(\rho(\boldsymbol A)\)不超过其所有元素的模的最大值,即\(|\rho(A)| \leq |A|_{\infty}\)。 ⑤ 如果矩阵\(\boldsymbol A\)是幂零矩阵,即存在正整数\(k\),使得\(\boldsymbol A^k = \boldsymbol O\),那么\(\rho(\boldsymbol A) = 0\)。 ⑥ 对于任意两个\(n\)阶矩阵\(\boldsymbol A\)和\(\boldsymbol B\),有\(\rho(\boldsymbol {AB}) \leq \rho(\boldsymbol A) \rho(\boldsymbol B)\)。 ⑦ 对于任意\(n\)阶方阵\(\boldsymbol A\),其谱半径等于\(\boldsymbol A\)的转置矩阵\(\boldsymbol A^{\mathrm T}\)的谱半径,即\(\rho(\boldsymbol A) = \rho(\boldsymbol A^{\mathrm T})\)。 ⑧ 如果\(\boldsymbol A\)是一个实对称矩阵,那么\(\rho(\boldsymbol A)\)等于\(\boldsymbol A\)的模最大的特征值的模,即\(\rho(\boldsymbol A) = |\lambda_{\max}(\boldsymbol A)|\)。 ⑨ 对于任意\(n\)阶矩阵\(\boldsymbol A\),都有\(\rho(\boldsymbol A) \geq \frac{\sum_{i=1}^n|a_{i,i}|}{n}\),其中\(a_{i,i}\)是矩阵\(\boldsymbol A\)的第\(i\)个对角元素。 参考16.1:对范数、矩阵谱半径的通俗化理解 - CSDN |
知识点17: 矩阵的常见分解:
参考17.1:矩阵分解算法 - 博客园 |
|
知识点18: 齐次/非齐次微分方程组的解:
① 齐次微分方程组的解 对于如下形式的齐次微分方程组: \[\dfrac{\mathrm{d}}{\mathrm{d}t} \boldsymbol{x}(t) = \boldsymbol{Ax}(t)
\] 其中,\(\boldsymbol{A} = (a_{ij})_{n \times n}\),\(\boldsymbol{x}(t) = \left(\xi_1(t), \xi_2(t), \cdots, \xi_n(t)\right)^{\mathrm T}\)。 其解空间为: \[S = \begin{Bmatrix}\boldsymbol{x}(t) \mid \dfrac{\mathrm{d}}{\mathrm{d}t} \boldsymbol{x}(t) = \boldsymbol{Ax}(t)\end{Bmatrix}
\] 有以下2个结论:
\[\boldsymbol{x}(t) = e^{t \boldsymbol{A}} \boldsymbol{c} = \gamma_1 \boldsymbol{x}_1(t)+\gamma_2 \boldsymbol{x}_2(t)+\cdots+\gamma_n \boldsymbol{x}_n(t)
\] ② 非齐次微分方程组的解 对于如下形式的非齐次微分方程组: \[\dfrac{\mathrm{d}}{\mathrm{d}t} \boldsymbol{x}(t) = \boldsymbol{Ax}(t) + \boldsymbol{b}(t)
\] 其中,\(\boldsymbol{b}(t) = \left(\beta_1(t), \beta_2(t), \cdots, \beta_n(n) \right)^{\mathrm T}\)。 设\(\boldsymbol{x}(t)\)是方程一般解/通解,\(\widetilde{\boldsymbol{x}}(t)\)是方程的一个特解。 特解\(\widetilde{\boldsymbol{x}}(t)\)的求解一般是通过常数变异法:\(\widetilde{\boldsymbol{x}}(t) = e^{t \boldsymbol A} \boldsymbol{c}(t)\)。最终可求得非齐次微分方程组的一个特解为: \[\widetilde{\boldsymbol{x}}(t) = e^{t \boldsymbol A} \int_{t_0}^t e^{-s \boldsymbol A}\boldsymbol{b}(s)\text{ d}s
\] 综上,可得下面2条结论:
\[\boldsymbol{x}(t) = e^{t \boldsymbol A}\boldsymbol{k} + \widetilde{\boldsymbol{x}}(t) = e^{t \boldsymbol A}\boldsymbol{k} + e^{t \boldsymbol A} \int_{t_0}^t e^{-s \boldsymbol A}\boldsymbol{b}(s)\text{ d}s
\]
\[\boldsymbol{x}(t) = e^{t \boldsymbol A}\left(e^{-t_0 \boldsymbol A}\boldsymbol{x}_0 + \int_{t_0}^t e^{-s \boldsymbol A}\boldsymbol{b}(s)\text{ d}s\right)
\] 其中,\(\boldsymbol{k} = (\kappa_1, \kappa_2, \cdots, \kappa_n)^{\mathrm T}\)为任意常数向量。 |
|
知识点19: 投影:
① 矢量向矢量投影:把矢量\(\boldsymbol x\)投影到矢量\(\boldsymbol a\)上 \[\text{Proj}_{\boldsymbol a} \boldsymbol x = \boldsymbol a \frac{(\boldsymbol a, \boldsymbol x)}{\| \boldsymbol a \|^2} = \boldsymbol a \frac{(\boldsymbol a, \boldsymbol x)}{(\boldsymbol a, \boldsymbol a)} = \boldsymbol a (\boldsymbol a, \boldsymbol a)^{-1} (\boldsymbol a, \boldsymbol x) = \boldsymbol a (\boldsymbol a^{\mathrm H} \boldsymbol a)^{-1} \boldsymbol a^{\mathrm H} \boldsymbol x
\] ② 矢量向矩阵投影:把矢量\(\boldsymbol x\)投影到矩阵\(\boldsymbol A\)的列构成的空间中 \[\text{Proj}_{\boldsymbol A} \boldsymbol x = \boldsymbol A (\boldsymbol A^{\mathrm{H}} \boldsymbol A)^{-1} \boldsymbol A^{\mathrm{H}} \cdot \boldsymbol x
\] ③ 矩阵向矩阵投影:把矩阵\(\boldsymbol X\)向\(\boldsymbol A\)的列向量张成的子空间投影 \[\text{Proj}_{\boldsymbol A} \boldsymbol X = \boldsymbol A (\boldsymbol A^{\mathrm{H}} \boldsymbol A)^{-1} \boldsymbol A^{\mathrm{H}} \cdot \boldsymbol X
\] ④ 矩阵向矩阵补空间投影:把矩阵\(\boldsymbol X\)向\(\boldsymbol A\)的列向量张成的子空间的正交补空间投影 \[\text{Proj}_{\boldsymbol A^{\perp}} \text{ }\boldsymbol X = \boldsymbol I - \boldsymbol A (\boldsymbol A^{\mathrm{H}} \boldsymbol A)^{-1} \boldsymbol A^{\mathrm{H}} \cdot \boldsymbol X
\] |
|
知识点20: 特征值与秩:
设方阵\(\boldsymbol A\)阶数为\(n\),特征值个数为\(k\),其中有\(i\)重特征值\(\lambda_i\),单个\(\lambda\)对应的无关特征向量个数为\(t\),方阵的秩为\(r\)。
① 特征值个数\(k\)(包括重根和复根)与方阵的阶数\(n\)相等; ② 特征值个数\(k\) \(\geq\) 所有无关特征向量数之和(因为\(i\)重特征值\(λ_i\)最多有\(i\)个线性无关的特征向量); ③ 特征值个数\(k\)与方阵的秩无关。
① 单个\(λ\)对应的无关特征向量个数\(t\)与方阵的秩\(r\)没有什么直接的关系,它们都小于等于方阵阶数\(n\)。
① 当方阵\(\boldsymbol A\)可以相似对角化时(这里自然是包括了方阵\(\boldsymbol A\)为实对称矩阵的情况),\(i=n-r\)。 因为\(\boldsymbol A \sim \boldsymbol \Lambda\), 所以\(\text{rank}(\boldsymbol A) = \text{rank}(\boldsymbol \Lambda)\)。此时若\(\text{rank}(\boldsymbol A) = \text{rank}(\boldsymbol \Lambda) = r\),意味着对角阵有\(r\)个不为零的特征值,即\(\boldsymbol A\)也有\(r\)个不为零的特征值,进而得到\(\boldsymbol A\)有\(n-r\)重特征值:\(λ_i = 0\) ② 当方阵\(\boldsymbol A\)不可相似对角化时,\(i \geq n-r\)。 首先,对于\(i\)重特征值\(λ_i\)最多有\(i\)个线性无关的特征向量,反过来说,同一特征值\(λ_i\)对应的线性无关的特征向量个数(设为t)\(t <= i\)。对于\(λ_i = 0\),有\(r(0\boldsymbol E - \boldsymbol A) = \text{rank}(-\boldsymbol A) = \text{rank}(\boldsymbol A) = r\),所以,\(λ_i\)的线性无关特征向量个数\(t = n-r\),根据上一行的说法就有,\(λ_i=0\)的重数\(t \leq i\) ,即\(i \geq n-r\)。 🧺 正交变换(正交矩阵)不改变秩、特征值、行列式、迹,另外它不改变向量的长度(保模长性质)。 |
|
知识点21: 范德蒙(Vandermonde)矩阵和范德蒙行列式:
🎫 Vandermonde 矩阵具有以下形式: \[\boldsymbol A=\left[\begin{array}{ccccc}
1 & x_1 & x_1^2 & \cdots & x_1^{m-1} \\
1 & x_2 & x_2^2 & \cdots & x_2^{m-1} \\
\vdots & \vdots & \vdots & \ddots & \vdots \\
1 & x_n & x_n^2 & \cdots & x_n^{m-1}
\end{array}\right]_{n \times m} \qquad \quad
\boldsymbol A^{\mathrm T}=\left[\begin{array}{cccc}
1 & 1 & \cdots & 1 \\
x_1 & x_2 & \cdots & x_n \\
x_1^2 & x_2^2 & \cdots & x_n^2 \\
\vdots & \vdots & \ddots & \vdots \\
x_1^{m-1} & x_2^{m-1} & \cdots & x_n^{m-1}
\end{array}\right]_{m \times n}
\] 具有如上\(\boldsymbol A\)或者\(\boldsymbol A^{\mathrm T}\)形式的矩阵称为范德蒙(Vandermonde)矩阵。 🏓 \(n\)阶Vandermonde矩阵的行列式计算 \[\operatorname{det} \boldsymbol A_n = \prod_{1 \leq j,i \leq n}(x_i - x_j)
\] 例如: \[\operatorname{det} \boldsymbol A_3=\left|\begin{array}{lll}
1 & x_1 & x_1^2 \\
1 & x_2 & x_2^2 \\
1 & x_3 & x_3^2
\end{array}\right| = (x_2 - x_1)(x_3 - x_2)(x_3 - x_1)
\] 🍰 范德蒙矩阵的秩
🏳🌈 范德蒙矩阵的应用 可应用于多项式最小二乘法拟合以及多项式插值。 参考资料21.1:范德蒙矩阵、范德蒙行列式 - 小时百科 |
|
知识点22: 秩1矩阵
秩为1的矩阵一定能分解成一个行矩阵和列矩阵的乘积: \[\boldsymbol A = \boldsymbol{uv}^{\mathrm T}
\] \(n\)阶矩阵\(\boldsymbol A\),\(\text{rank}(\boldsymbol A) = 1\),则\(\boldsymbol A\)的特征值一个是\(\boldsymbol A\)的迹,其余都是0,即: \[\lambda_1 = \text{tr}(\boldsymbol A) = \sum_{i=1}^n a_{ii}, \qquad \lambda_2 = \lambda_3 = \cdots = \lambda_n = 0
\] 秩1矩阵可对角化的条件:
参考22.1:关于秩为1矩阵的重要结论 - 小海考研人的文章 - 知乎 |
知识点23: 奇异值分解(SVD)
矩阵对角化有很多应用:简化计算、解方程等等,但不是所有矩阵都可以对角化的,矩阵可对角化的条件参考本文知识点17_特征值分解和矩阵可对角化的充要条件 - 我思故我在的文章 - 知乎。可对角化矩阵例:对称矩阵。 对于一般的\(m \times n\)矩阵\(\boldsymbol A\),有没有类似的操作? ① 回忆线性代数的知识:方程\(\boldsymbol{Ax = b}\)不一定有解,但是\(\boldsymbol{A}^{\mathrm T} \boldsymbol{Ax} = \boldsymbol{A}^{\mathrm T} \boldsymbol b\)一定有解。 ② 考虑方阵\(\boldsymbol{A}^{\mathrm T}\boldsymbol A\)和\(\boldsymbol{A}\boldsymbol{A}^{\mathrm T}\),它们都是半正定矩阵,所以可以对角化而且特征值大于等于0。 方阵\(\boldsymbol{A}^{\mathrm T}\boldsymbol A\)和\(\boldsymbol{A}\boldsymbol{A}^{\mathrm T}\)可进行对角化:\(\boldsymbol{A}^{\mathrm T}\boldsymbol A = \boldsymbol{V}\boldsymbol{\Lambda}_1 \boldsymbol{V}^{\mathrm T} \quad \boldsymbol{A}\boldsymbol{A}^{\mathrm T} = \boldsymbol{U}\boldsymbol{\Lambda}_2 \boldsymbol{U}^{\mathrm T}\),也就有: \[\begin{aligned}
&\boldsymbol{V}^{\mathrm T}\boldsymbol{A}^{\mathrm T}\boldsymbol{A} \boldsymbol{V} = (\boldsymbol{A} \boldsymbol{V})^{\mathrm T}(\boldsymbol{A} \boldsymbol{V}) = \boldsymbol{\Lambda}_1\\
&\boldsymbol{U}^{\mathrm T}\boldsymbol{A}\boldsymbol{A}^{\mathrm T} \boldsymbol{U} = (\boldsymbol{U}^{\mathrm T}) \boldsymbol{A}(\boldsymbol{A}^{\mathrm T} \boldsymbol{U}) = \boldsymbol{\Lambda}_2
\end{aligned}
\] 💦 猜测:找到正交矩阵\(\boldsymbol{U}\)和\(\boldsymbol{V}\)使得\(m \times n\)矩阵\(\boldsymbol{U}^{\mathrm T} \boldsymbol{A} \boldsymbol{V}\)可以写成\(\boldsymbol \Sigma\)?其中\(\boldsymbol \Sigma\)是某种意义上的“对角”矩阵。
对于一个\(m \times n\)的实矩阵\(\boldsymbol{A}\),则\(\boldsymbol{A}^{\mathrm T} \boldsymbol{A}\)是一个\(n \times n\)的对称矩阵,\(\{\boldsymbol{q}_1, \boldsymbol{q}_2, \cdots, \boldsymbol{q}_n\}\)是由\(\boldsymbol{A}^{\mathrm T} \boldsymbol{A}\)的特征向量构成的\(\mathbb R^n\)中的正交归一基,对应的实特征值为\(\{\lambda_1, \lambda_2, \cdots, \lambda_n\}\),假设\(\lambda_1 \geq \lambda_2 \geq \cdots \geq \lambda_n \geq 0\),则矩阵\(\boldsymbol A\)的奇异值定义\(\boldsymbol{A}^{\mathrm T} \boldsymbol{A}\)的特征值的平方根: \[\sigma_1 = \sqrt{\lambda_i}
\] 引入如下两个不加证明的定理: 定理1:对于一个\(m \times n\)的矩阵\(\boldsymbol{A}\),其秩满足:\(\mathrm{rank}(\boldsymbol{A}) = \mathrm{rank}(\boldsymbol{A}^{\mathrm T}) = \mathrm{rank}(\boldsymbol{A}\boldsymbol{A}^{\mathrm T}) = \mathrm{rank}(\boldsymbol{A}^{\mathrm T}\boldsymbol{A})\)。 定理2:对于一个\(m \times n\)的实矩阵\(\boldsymbol{A}\),其非0奇异值\(\sigma_1 \geq \sigma_2 \geq \cdots \geq \sigma_r > 0\)的个数\(r\)等于矩阵\(\boldsymbol{A}\)的秩,\(r = \mathrm{rank}(\boldsymbol{A})\)
广义对角矩阵:\(m \times n\)矩阵\(\boldsymbol \Sigma\) \[\boldsymbol \Sigma = \left[\begin{array}{cc}
\boldsymbol D & \boldsymbol 0 \\
\boldsymbol 0 & \boldsymbol 0
\end{array}\right]
\] 其中,\(\boldsymbol D\)是一个\(r \times r\)的对角矩阵,\(\boldsymbol \Sigma\)所有大于\(r\)的行和列的元素均为0。 定理(SVD):\(m \times n\)矩阵\(\boldsymbol{A}\)的秩为\(r\)。则存在一个形状如上的\(m \times n\)矩阵\(\boldsymbol \Sigma\)且\(\boldsymbol D\)的对角元是\(\boldsymbol{A}\)的前\(r\)个(非零)的奇异值,\(m \times m\)的正交矩阵\(\boldsymbol{U}\)和\(n \times n\)的正交矩阵\(\boldsymbol{V}\),而且以上矩阵满足关系: \[\boldsymbol{A} = \boldsymbol{U \Sigma V}^{\mathrm T}
\] 推论1:\(\{\boldsymbol{u}_1, \boldsymbol{u}_2, \cdots, \boldsymbol{u}_m\}\)是矩阵\(\boldsymbol{A}\boldsymbol{A}^{\mathrm T}\)的特征向量,\(\{\boldsymbol{v}_1, \boldsymbol{v}_2, \cdots, \boldsymbol{v}_n\}\)是矩阵\(\boldsymbol{A}^{\mathrm T}\boldsymbol{A}\)的特征向量,即\(\boldsymbol{U}\)和\(\boldsymbol{V}\)分别是将\(\boldsymbol{A}\boldsymbol{A}^{\mathrm T}\)和\(\boldsymbol{A}^{\mathrm T}\boldsymbol{A}\)对角化的正交矩阵。 推论2: 推论3:\(\boldsymbol{A}\boldsymbol{A}^{\mathrm T}\)和\(\boldsymbol{A}^{\mathrm T}\boldsymbol{A}\)的非0特征值都相同。
数据压缩:假设\(rank(\boldsymbol{A}) < \min(m, n)\),则: \[\boldsymbol A=\left(\boldsymbol U_r, \boldsymbol U_{m-r}\right)\left[\begin{array}{cc}
\boldsymbol D & \boldsymbol 0 \\
\boldsymbol 0 & \boldsymbol 0
\end{array}\right]\left[\begin{array}{c}
\boldsymbol V_r^T \\
\boldsymbol V_{n-r}^T
\end{array}\right]=\boldsymbol U_r \boldsymbol D \boldsymbol V_r^T=\sum_{i=1}^r \sigma_i \boldsymbol{u}_i \boldsymbol{v}_i^{\mathrm T}
\] 这意味着可以只用\(\boldsymbol U_r\)、\(\boldsymbol D\)、\(\boldsymbol V_r\)三个子矩阵的总共\(r \times (m+1+n)\)个分量完全决定\(\boldsymbol A\)。 例如:图像压缩 矩阵伪逆:由于\(m \times n\)的矩阵\(\boldsymbol{A} = \boldsymbol{U \Sigma V}^{\mathrm T}\),则其伪逆可直接求得: \[\boldsymbol{A}^+ = \boldsymbol{V \Sigma^+ U}^{\mathrm T} = \boldsymbol{V} \left(\begin{array}{cc} \boldsymbol{D}^{-1} & \boldsymbol{0} \\ \boldsymbol{0} & \boldsymbol{0}\end{array}\right)\boldsymbol{U}^{\mathrm T} = \sum_{k=1}^r \sigma_k^{-1} \boldsymbol v_k \boldsymbol u_k^{\mathrm T}
\] ① \(\boldsymbol{A}^+\boldsymbol{A} = \boldsymbol{V \Sigma}^+\boldsymbol{U}^{\mathrm T}\boldsymbol{U \Sigma}\boldsymbol{V}^{\mathrm T} = \boldsymbol{V}\left(\begin{array}{cc} \boldsymbol{I}_{r \times r} & \boldsymbol{0} \\ \boldsymbol{0} & \boldsymbol{0}\end{array}\right) \boldsymbol{V}^{\mathrm T}\)是投影到\(C(\boldsymbol{A}^{\mathrm T})\)的矩阵。 ② \(\boldsymbol{A}\boldsymbol{A}^+ = \boldsymbol{U \Sigma}\boldsymbol{V}^{\mathrm T}\boldsymbol{V \Sigma}^+\boldsymbol{U}^{\mathrm T} = \boldsymbol{U}\left(\begin{array}{cc} \boldsymbol{I}_{r \times r} & \boldsymbol{0} \\ \boldsymbol{0} & \boldsymbol{0}\end{array}\right) \boldsymbol{U}^{\mathrm T}\)是投影到\(C(\boldsymbol{A})\)的矩阵。 矩阵伪逆可以用来求解最小二乘问题:最小二乘\(\boldsymbol{A}^{\mathrm T}\boldsymbol{Ax} = \boldsymbol{A}^{\mathrm T}\boldsymbol{b}\)的解为\(\boldsymbol{x}^+ = \boldsymbol{A}^+ \boldsymbol{b}\)。 矩阵的模:\(\| \boldsymbol{A} \| = \max \dfrac{\| \boldsymbol{Ax} \|}{\| \boldsymbol{x} \|} = \sigma_1\)(关于矩阵模的详细定义和性质请参考链接23.1)。 参考23.1:奇异值分解 - 颜文斌 - 清华大学(在线pdf文件) |
知识点24: 主成分分析(PCA)
假设一组数据来源于\(n\)个样本\(\{\mu_1, \mu_2, \cdots, \mu_n\}\),其平均值\(\bar{\mu} = \dfrac{\sum{i=1}^n \mu_i}{n}\),标准差\(\sigma = \sqrt{\dfrac{\sum{i=1}^n (\mu_i - \bar \mu)}{n-1}}\)。
假设\(n\)个样本,每个样本\(i\)我们得到两个数据\(\mu_i\)和\(\rho_i\)(例所有同学的期中考试成绩\(\mu_i\)和平时作业成绩\(\rho_i\),则协方差可定义为:\(\operatorname{cov}(\mu, \rho)=\frac{\sum_{i=1}^n\left(\mu_i-\bar{\mu}\right)\left(\rho_i-\bar{\rho}\right)}{n-1}\)。
将数据存在一个\(m \times n\)的矩阵\(\boldsymbol A_0\)中,每一行对应一种数据,每一列代表一个样本,将中心化之后的数据记为\(\boldsymbol A\)(由\(\boldsymbol A_0\)的每一个元素减去它所在行的平均值得到): \[\boldsymbol A_{ij} = (\boldsymbol A_0)_{ij} - \dfrac{\sum_{k=1}^n (\boldsymbol A_0)_{ik}}{n}
\] 则协方差矩阵(covariance matrix)可定义为: \[\boldsymbol S = \dfrac{\boldsymbol{AA}^{\mathrm T}}{n-1}
\]
一般来说数据\(i\)和数据\(j\)可能会有相关,也就是说它们之间的协方差\(\boldsymbol S_{ij}\)不等于\(0\),主成分分析就是要找到原有数据的一系列线性组合作为新的数据,新数据之间的协方差为0。 \(\boldsymbol A\)的奇异值分解为\(\boldsymbol A = \boldsymbol{U \Sigma V}^{\mathrm T}\),定义新的数据矩阵\(\boldsymbol B\): \[\boldsymbol B = \boldsymbol{U}^{\mathrm T}\boldsymbol A = \boldsymbol{\Sigma V}^{\mathrm T}
\] 此时,计算可得新的数据矩阵\(\boldsymbol B\)的协方差为: \[\dfrac{\boldsymbol{BB}^{\mathrm T}}{n-1} = \dfrac{\boldsymbol{\Sigma V}^{\mathrm T}\boldsymbol{V \Sigma}^{\mathrm T}}{n-1} = \dfrac{\boldsymbol{\Sigma \Sigma}^{\mathrm T}}{n-1}
\] 因为\(\boldsymbol{\Sigma \Sigma}^{\mathrm T}\)是对角矩阵,因此\(\boldsymbol B\)的数据之间的协方差为0,同时可得“新数据的方差 = \(\boldsymbol A\)的奇异值平方/(n-1)”。
原数据矩阵:\(\boldsymbol{A} = (\boldsymbol a_1, \boldsymbol a_2, \cdots, \boldsymbol a_n)\);
新数据矩阵:\(\boldsymbol{B} = (\boldsymbol b_1, \boldsymbol b_2, \cdots, \boldsymbol b_n) = \boldsymbol{U}^{\mathrm T}\boldsymbol{A} = (\boldsymbol{U}^{\mathrm T}\boldsymbol a_1, \boldsymbol{U}^{\mathrm T}\boldsymbol a_2, \cdots, \boldsymbol{U}^{\mathrm T}\boldsymbol a_n)\)
① \(\boldsymbol{A}\)的非零奇异值的数量是\(\boldsymbol{A}\)的秩\(r\),\(r+1\)到\(m\)的新数据的方差是0; ② 所有的数据都在\(\mathrm R^m\)的\(m-r\)个平面\(\sum\limits_{j=1}^m \boldsymbol{U}_{ji}\boldsymbol{x}_j = 0, i = r+1,⋯,m\)的交集上; ③ 所有数据点分布在一个\(r\)维的空间中,这个空间由\(\{\boldsymbol{u}_1, \boldsymbol{u}_2, \cdots, \boldsymbol{u}_r\}\)张成(是\(C(\boldsymbol{A})\)的正交归一基); ④ 如果第\(i\)个奇异值很接近\(0\),说明数据很靠近平面\(\sum\limits_{j=1}^m \boldsymbol{U}_{ji}\boldsymbol{x}_j = 0, i = r+1,⋯,m\)。 主成分:\(\{\boldsymbol{u}_1, \boldsymbol{u}_2, \cdots, \boldsymbol{u}_r\}\),其中\(\boldsymbol{u}_1\)是所有数据变化最大的方向(对应的方差最大),\(\boldsymbol{u}_3\)次之……主成分是描述整组数据最重要的线性组合,而且互相独立;由于\(r \leq m\),所以虽然每个样本测了\(m\)个数据,里面只有\(r\)个是独立的。 \(\{\boldsymbol{v}_1, \boldsymbol{v}_2, \cdots, \boldsymbol{v}_r\}\)都是\(n\)维向量,每个分量对应一个样本: |
|
知识点25: Toeplitz矩阵的范德蒙德分解:
对于任意的秩满足\(r \leq N\)的半正定Toeplitz矩阵\(\boldsymbol T(u) \in \mathbb{C}^{N \times N}\),则有如下的\(r-\)原子范德蒙德分解: \[\boldsymbol T(u) = \sum_{k=1}^{r} p_k \boldsymbol a(f_k) \boldsymbol a^{\mathrm H}(f_k) = \boldsymbol A(f) \mathrm{diag}(\boldsymbol p) \boldsymbol A^{\mathrm H}(f)
\] 其中,\(\boldsymbol A(f) = [\boldsymbol a(f_1), \boldsymbol a(f_2), \cdots, \boldsymbol a(f_r)]\)。当\(r < N\)时,此分解是唯一的。 参考25.1:压缩感知的尽头: 原子范数最小化 - CSDN |
|
知识点26: Kronecker积和矩阵向量化(拉直)Vec的相关性质:
Kronecker积的相关定理: 定理1:设矩阵\(\boldsymbol A \in \mathbb{C}^{m \times n}, \boldsymbol B \in \mathbb{C}^{p \times q}\),则有\(\mathrm{rank}(\boldsymbol A \otimes \boldsymbol B) = \mathrm{rank}(\boldsymbol A) \mathrm{rank}(\boldsymbol B)\)。 定理2:设矩阵\(\boldsymbol A \in \mathbb{C}^{m \times m}, \boldsymbol B \in \mathbb{C}^{n \times n}\),则有\(\mathrm{Tr}(\boldsymbol A \otimes \boldsymbol B) = \mathrm{Tr}(\boldsymbol A) \mathrm{Tr}(\boldsymbol B)\)。 定理3:设矩阵\(\boldsymbol A \in \mathbb{C}^{m \times m}, \boldsymbol B \in \mathbb{C}^{n \times n}\),则有\(\mathrm{det}(\boldsymbol A \otimes \boldsymbol B) = \mathrm{det}(\boldsymbol A)^n \mathrm{det}(\boldsymbol B)^m\)。 定理4:若\(\boldsymbol A \succeq 0, \boldsymbol B \succeq 0\),则有\(\boldsymbol A \otimes \boldsymbol B \succeq 0\)。 矩阵的向量化Vec: 矩阵的\(\mathrm{Vec}(\boldsymbol A)\),一般是按列拉直(也可按照行拉直,根据具体情况分析),将矩阵\(\boldsymbol A\)表示为排列成一个\(mn \times 1\)的列向量,即: \[\mathrm{Vec}(\boldsymbol A) = [a_{11}, a_{21}, \cdots, a_{m1}, \cdots, a_{1n}, a_{2n}, \cdots, a_{mn}]^{\mathrm T}
\] 定理5:\(\mathrm{Vec}(\boldsymbol{xy}^{\mathrm T}) = \boldsymbol y \otimes \boldsymbol x\),\(\mathrm{Vec}(\boldsymbol{A} \otimes \boldsymbol b) = \mathrm{Vec}(\boldsymbol A) \otimes \boldsymbol b\)。 假定\(\boldsymbol A, \boldsymbol B \in \mathbb R^{m \times n}\),则这两个矩阵乘积的迹具有如下性质: 定理6:\(\mathrm{Tr}(\boldsymbol A^{\mathrm T} \boldsymbol B) = \mathrm{Vec}(\boldsymbol A)^{\mathrm T}\mathrm{Vec}(\boldsymbol B)\),\(\mathrm{Tr}(\boldsymbol{ABC}) = \mathrm{Vec}(\boldsymbol A)^{\mathrm T}(\boldsymbol I_p \otimes \boldsymbol B)\mathrm{Vec}(\boldsymbol C)\),\(\mathrm{Tr}(\boldsymbol{ABCD}) = \mathrm{Vec}(\boldsymbol D^{\mathrm T})^{\mathrm T}(\boldsymbol C^{\mathrm T} \otimes \boldsymbol A)\mathrm{Vec}(\boldsymbol B) = \mathrm{Vec}(\boldsymbol D^{\mathrm T})^{\mathrm T}(\boldsymbol A \otimes \boldsymbol C^{\mathrm T})\mathrm{Vec}(\boldsymbol B^{\mathrm T})\) 定理7:设矩阵\(\boldsymbol A \in \mathbb{C}^{m \times n}, \boldsymbol X \in \mathbb{C}^{n \times p}, \boldsymbol B \in \mathbb{C}^{p \times q}\),则有\(\mathrm{Vec}(\boldsymbol{AXB}) = (\boldsymbol A \otimes \boldsymbol B^{\mathrm T}) \mathrm{Vec}(\boldsymbol X)\)。 推论7:设矩阵\(\boldsymbol A \in \mathbb{C}^{m \times m}, \boldsymbol X \in \mathbb{C}^{m \times n}, \boldsymbol B \in \mathbb{C}^{n \times n}\),则有\(\mathrm{Vec}(\boldsymbol{AX}) = (\boldsymbol A \otimes \boldsymbol I_n) \mathrm{Vec}(\boldsymbol X)\),\(\mathrm{Vec}(\boldsymbol{XB}) = (\boldsymbol I_m \otimes \boldsymbol B^{\mathrm T}) \mathrm{Vec}(\boldsymbol X)\),\(\mathrm{Vec}(\boldsymbol{AX+XB}) = (\boldsymbol A \otimes \boldsymbol I_n + \boldsymbol I_m \otimes \boldsymbol B^{\mathrm T}) \mathrm{Vec}(\boldsymbol X)\)。 参考26.1:矩阵Kronecker乘积性质与应用 - 豆丁 |
|
知识点27: 矩阵的特征值和奇异值:
设矩阵\(\boldsymbol A \in \mathbb{R}^{n \times n}\),其特征值为\((\lambda_1, \lambda_2, \cdots, \lambda_n)\); 矩阵\(\boldsymbol{AA}^{\mathrm T}\)的特征值为\((\mu_1, \mu_2, \cdots, \mu_n)\); 矩阵\(\boldsymbol A\)的奇异值为\((\sigma_1, \sigma_2, \cdots, \sigma_n) = (\sqrt{\mu_1}, \sqrt{\mu_2}, \cdots, \sqrt{\mu_n})\)。 |
知识点28: 矩阵迹的相关定义与性质
矩阵的迹 :就是矩阵的主对角线上所有元素的和,矩阵\(\boldsymbol A_{n \times n}\)的迹和\(\boldsymbol{AB}\)的迹分别为: \[\mathrm{Tr}(\boldsymbol A) = \sum_{i=1}^{n} a_{ii} \qquad\quad \mathrm{Tr}(\boldsymbol{AB}) = \sum_{i=1}^m \sum_{j=1}^n a_{ij}b_{ji}
\] 矩阵的F范数为\(||\boldsymbol A||_F = \sqrt{\sum\limits_{i=1}^m \sum\limits_{j=1}^n |a_{ij}|^2}\),F范数可以用矩阵的迹来表示: \[||\boldsymbol A||_F = \sqrt{\mathrm{Tr}(\boldsymbol{AA}^{\mathrm T})}
\]
参考28.1:机器学习中常用的矩阵公式 - CSDN |
|
知识点29: 矩阵核范数的定义:
矩阵\(\boldsymbol A\)的核范数记为\(||\boldsymbol A||_{\star}\),具体定义为: \[||\boldsymbol A||_{\star} = \sum_{i=1}^n \lambda_i
\] 其中,\(\lambda_i\)为矩阵\(\boldsymbol A\)的奇异值,也即,矩阵\(\boldsymbol A\)的核范数为奇异值之和。 |
线性代数中,向量空间的子空间的“和”与“直和”,这两个概念的区别是什么? - 知乎
https://www.zhihu.com/question/38577398
|
知识点30: 半正定矩阵
半正定矩阵是数学中的一个经典概念,是指对于任意非零向量\(\boldsymbol x\),都有\(\boldsymbol x^{\mathrm T} \boldsymbol{Ax} \geq 0\)。在实际应用中,半正定矩阵经常出现在最优化、高维数据分析、微分方程等领域中。 介绍2种常见的半正定矩阵分解方法,它们分别是Cholesky分解、特征值分解。
参考30.1:半正定矩阵性质研究论文 - 北华大学本科毕设 - 人人文库 |
知识点31: Schur补的性质
给定任意的Hermition矩阵\(\boldsymbol M = \left[\begin{array}{cc} \boldsymbol A & \boldsymbol B \\ \boldsymbol B^{\mathrm H} & \boldsymbol C \end{array}\right]\),则以下三个结论是等价的:
参考31.1:The Schur Complement and Symmetric Positive Semidefinite (and Definite) Matrices |
一些矩阵论的系统笔记或者博客:
【1】 高等代数葵花宝典
【2】 线性代数与矩阵论 - 个人博客 - 老齐

 浙公网安备 33010602011771号
浙公网安备 33010602011771号