记忆常用公式
 经常使用的公式、表达需要记忆背诵下来,熟练使用。
经常使用的公式、表达需要记忆背诵下来,熟练使用。
0 前言
Latex符号与公式集合 - CSDN:相对较全的latex数学符号,包括基本运算、高级运算、集合运算、三角运算、占位宽度、关系运算符、箭头、矩阵、希腊字符、函数、其他杂七杂八。
1 高数部分
1.1 三角函数
1.1.1 三角函数的基本定义
1.1.2 三角恒等式
(一) 两角和与差
(二) 积化和差公式
(三) 和差化积公式
(四) 二倍角公式
(五) 半角公式
(六) 辅助角公式
其中,\(\varphi\)满足\(\cos \varphi=\dfrac{a}{\sqrt{a^2+b^2}}, \quad \sin \varphi=\dfrac{b}{\sqrt{a^2+b^2}}\)
(七) 万能公式
(八) 降幂公式
(九) 余弦定理
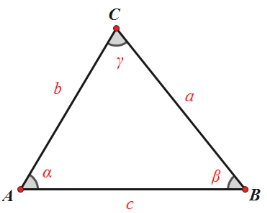
| 余弦定理表达式1 | 余弦定理表达式2 | 余弦定理表达式3 |
|---|---|---|
| \(c^2 = a^2+b^2-2ab \cos \gamma\) | \(\cos \gamma = \dfrac{a^2 + b^2 - c^2}{2ab}\) | \(\cos \gamma= \dfrac{\sin^2 \alpha + \sin^2 \beta - \sin^2 \gamma}{2\sin \alpha \sin \beta}\) |
| \(b^2 = a^2+c^2-2ac \cos \beta\) | \(\cos \beta = \dfrac{a^2 + c^2 - b^2}{2ac}\) | \(\cos \beta = \dfrac{\sin^2 \alpha+ \sin^2 \gamma - \sin^2 \beta}{2\sin \alpha \sin \gamma}\) |
| \(a^2 = b^2+c^2-2bc \cos \alpha\) | \(\cos \alpha = \dfrac{b^2 + c^2 - a^2}{2bc}\) | \(\cos \alpha = \dfrac{\sin^2 \beta + \sin^2 \gamma - \sin^2 \alpha}{2\sin \beta \sin \gamma}\) |
1.2 导数
1.2.1 导数的定义式
1.2.2 常用函数的导数
- 指数类函数
- 对数类函数
- 正切函数
- 反三角函数类
1.3 泰勒级数/泰勒展开
1.3.1 标准公式
(一)在\(x=0\)处展开(麦克劳林公式)
- 佩亚诺余项
- 拉格朗日余项
(二)在\(x=x_0\)处展开
- 佩亚诺余项
- 拉格朗日余项
(三)含有\(\Delta x\)的展开(常用于论文中的近似)
1.3.2 常用的带有佩亚诺余项的麦克劳林公式
注意:
1、记忆常见函数的泰勒展开时候要学会利用函数之间求导与积分的关系;
2、注意代换方法,比如知道\(e^x\)的展开,也可以推导出\(e^{2x}\)的展开。
1.3.3 常用的等价无穷小
| 当\(x \to 0\)时 | 当\(x \to 0\)时 |
|---|---|
| \(\sin x \sim x, \tan x \sim x\) | \(e^x - 1 \sim x\) |
| \(\ln(1+x) \sim x\) | \(a^x - 1 \sim x \ln a, (a>0, a \neq 1)\) |
| \(1-\cos x \sim \dfrac{1}{2}x^2\) | \((1 + \beta x)^\alpha-1 \sim \alpha\beta x\) |
| \(\arcsin x \sim x\) | \(x - \ln(1+x) \sim \dfrac{1}{2}x^2\) |
| \(\arctan x \sim x\) | \(\ln(x+\sqrt{1+x^2}) \sim x\) |
1.3.4 两个重要极限
- \(e\)的定义式(极限)
- \(\mathrm{sinc}\)函数在零点的值
1.4 数列
1.4.1 等差数列求和
1.4.2 等比数列求和
若数列\(\begin{Bmatrix} a_n \end{Bmatrix}\)为等比数列,且首项为\(a_1\),公比为\(q\),前\(n\)项和为\(S_n\),则有:
- 当公比为\(q = 1\)时:
- 当公比\(q \neq 1\)时:
1.4.3 常见其他数列求和
- \(a_n = n^2\)的求和公式
- 复指数求和
在计算序列的DFT时候,经常碰到如下形式的求和:已知序列\(\boldsymbol x(n) = [1, 1, 1, 1, 1, 0, 0, 0, 0, 0]\),求该序列的DFT。
重点是该分式如何进一步化简,其主要思路参考【信号与系统:如何化简、计算两个复指数的和/差 - bilibili】,简单来说,核心思想是提取和(差)式的两个指数的频率的平均值:
1.5 积分
1.5.1 积分换元
(一) 积分换元
积分换元需要考虑下面三个方面:
- 旧元换新元;
- 积分限变化;
- 雅可比行列式;
下面重点说一下雅可比
假设我们要用换元法计算下面的积分:
所要换的元为
我们把
那么就可以把这个积分写成:
特别要注意:雅可比行列式要加绝对值。
再比如,用极坐标的积分变换:
我们发现\(x\)和\(y\)都是关于\(r\)和\(\theta\)的二元函数,因此:
所以:
我们也可以把这个结论拓展到三维情况,这个交给读者自行推导,这里给出结论:
若:
则:
带回计算,得:
(二) 离散求和换元
离散求和换元比积分换元要简单,只需考虑下面两个方面即可:
- 旧元换新元;
- 积分限变化;
1.5.2 变限积分求导公式
1.5.3 重要积分
(一) 复指数函数积分
可以从\(\delta(t)\)的傅里叶变换推导。
(二) 伽马\(\Gamma\)函数积分
\(\Gamma\)函数的定义:
容易证得,该积分对于\(\alpha > 0\)均收敛。
\(\Gamma\)函数的性质:
-
(1) \(\Gamma(1) = 1, \Gamma(\dfrac{1}{2}) = \sqrt{\pi}\);
-
(2) \(\Gamma(\alpha+1) = \alpha\Gamma(\alpha)\);
-
(3) \(\Gamma(n+1) = n!, \quad n \in \mathbb N\);
\(\Gamma\)函数的另一种形式:
特别注意\(\Gamma\)函数的各种变形。
1.6 重要不等式
1.6.1 柯西-施瓦茨不等式
- 二维形式
等号成立条件:当且仅当\(ad = bc\)。
- 三角形式
等号成立条件:\(ad = bc\)且\(ac + bd \leq 0\)
- 概率形式
等号成立条件:当且仅当\(P(X+kY=0)=1\)时,"="成立
- 积分形式
等号成立条件:\(f(x) = kg(x)\)
- 向量形式
等号成立条件:\(\boldsymbol x = k\boldsymbol y\)
1.6.2 均值不等式
均方根QM \(\geq\) 算术平均AM \(\geq\) 几何平均GM \(\geq\) 调和平均HM
当且仅当\(x_1 = x_2 = \cdots = x_n\)时,取"="
1.7 复数的运算法则
1.7.1 复数表示方法
复数主要有三种表示方法:直角坐标系表示,极坐标系表示,三角函数表示
其中,\(a\) 和 \(b\) 表示复数的实部和虚部,\(r\) 和 \(\varphi\) 表示复数的模长和辐角。根据定义,可以看到其关系为:
1.7.2 复数的四则运算、共轭运算、模长运算
(1) 基本四则运算
设 \(z_1 = a+\mathrm{i}b\) 和 \(z_2 = c + \mathrm{i}d\) 是任意两个复数,则其基本四则运算为:
- 加法运算,复数的加法按照以下规定的法则进行:
- 减法运算,复数的减法按照以下规定的法则进行:
- 乘法运算,复数的乘法按照以下的法则进行:
- 除法运算,复数的除法是通过分母实数化来计算:
(2) 基本共轭运算
- 共轭运算,复数的共轭按照以下的法则进行:
(3) 基本模长运算
- 模长是将复数的实部与虚部的平方和的正的平方根的值称为该复数的模:
(4) 混合运算
- 复数加减运算后取共轭
- 复数乘除运算后取共轭
|
小结1: 若$\mathrm{R}(z_1, z_2, \cdots, z_n)$表示 $n$ 个复数基本四则运算的组合,则它满足规律 : |
- 复数相乘运算后取模长
- 复数相除运算后取模长
小结2: 复数模长的一些性质
|
1.8 集合
1.8.1 一些基本概念
(一) 属于与包含
属于是指元素与集合的关系,包含是指集合与集合间关系。属于和包含的区别是:
-
(1)属于用符号\(\in\)表示:若元素\(a\)是集合\(\mathbb{A}\)的元素,则称\(a\)属于\(\mathbb{A}\),记为\(a \in \mathbb{A}\);
-
(2)包含是集合与集合间关系,包含于用符号\(\subseteq\)表示:若集合\(\mathbb{B}\)是集合\(\mathbb{A}\)的子集,则称\(\mathbb{B}\)包含于\(\mathbb{A}\),记为\(\mathbb{B} \subseteq \mathbb{A}\)。
-
注意1,集合\(\mathbb{B}\)是集合\(\mathbb{A}\)的子集也可以用包含符号\(\supseteq\)表示,称\(\mathbb{A}\)包含\(\mathbb{B}\),记为\(\mathbb{A} \supseteq \mathbb{B}\);
-
注意2,\(\subsetneqq\)表示真包含于,\(\subseteq\)表示包含于 —— \(\mathbb{B}\)真包含于\(\mathbb{A}\),\(\mathbb{B}\)不可以等于\(\mathbb{A}\),\(\mathbb{B}\)包含于\(\mathbb{A}\),\(\mathbb{B}\)可以等于\(\mathbb{A}\)。
-
注意3, 一般情况下,\(\subsetneqq\)、\(\subsetneq\)、\(\subset\)这三个符号都表示真包含于 —— 其中,\(\subsetneqq\)是真包含于的正统符号,\(\subsetneq\)不是规范符号(课本没有这个符号,有时候题目有出现,是真包含于的意思),\(\subset\)表示空间几何直线、平面之间的位置关系,如\(l \subset \alpha\):直线\(l\)在平面\(\alpha\)内。
-
注意4,\(\subset\)这个符号有一定歧义,有的书上是真包含于(常用),有的是包含于。
-
(二) 常见集合符号
| 集合符号 | 释义 | |
|---|---|---|
| \(\emptyset\) | 空集 | |
| \(\mathbb{N}\) | 全体非负整数的集合,简称非负整数集(或自然数集) | |
| \(\mathbb{N}^{+} \quad \text{or} \quad \mathbb{N}^{*}\) | 非负整数集内排除0的集,也称正整数集 | |
| \(\mathbb{Z}\) | 全体整数的集合,通常称作整数集 | |
| \(\mathbb{Q}\) | 全体有理数的集合,通常简称有理数集 | |
| \(\mathbb{R}\) | 全体实数的集合,通常简称实数集 | |
| \(\mathbb{C}\) | 全体复数的集合,通常简称复数集 |
1.8.2 集合的笛卡尔乘积
(一) 定义
设\(\mathbb{A}\)和\(\mathbb{B}\)为集合,\(\mathbb{A}\)与\(\mathbb{B}\)的笛卡儿积记作\(\mathbb{A} \times \mathbb{B}\):
例题:设\(\mathbb{A} = \{1, 2\}\),\(\mathbb{B} = \{a, b, c\}\),则\(\mathbb{A} \times \mathbb{B}\)和\(\mathbb{B} \times \mathbb{A}\)分别为:
推广:设\(\mathbb{A}_1, \mathbb{A}_2, \cdots, \mathbb{A}_n\)是\(n\)个集合,则\(n\)阶笛卡尔积为:
如:\((1, 1, 0)\)为\(3\)维空间中的一个矢量,则可称\((1, 1, 0) \in \mathbb{R} \times \mathbb{R} \times \mathbb{R}\)。
(二) 笛卡儿积的性质
-
(1)若\(\mathbb{A}\)或\(\mathbb{B}\)中有一个为空集,则\(\mathbb{A} \times \mathbb{B}\)就是空集:\(\mathbb{A} \times \emptyset = \emptyset \times \mathbb{B} = \emptyset\);
-
(2)不适合交换律:\(\mathbb{A} \times \mathbb{B} \neq \mathbb{B} \times \mathbb{A}, \quad \mathbb{A} \neq \mathbb{B}, \mathbb{A} \neq \emptyset, \mathbb{B} \neq \emptyset\);
-
(3)不适合结合律:\((\mathbb{A} \times \mathbb{B}) \times \mathbb{C} \neq \mathbb{A} \times (\mathbb{B} \times \mathbb{C}), \quad \mathbb{A} \neq \emptyset, \mathbb{B} \neq \emptyset, \mathbb{C} \neq \emptyset\);
-
(4)对并或交满足分配律:\(\mathbb{A} \times (\mathbb{B} \cup \mathbb{C}) = (\mathbb{A} \times \mathbb{B}) \cup (\mathbb{A} \times \mathbb{C}) \quad \mathbb{A} \times (\mathbb{B} \cap \mathbb{C}) = (\mathbb{A} \times \mathbb{B}) \cap (\mathbb{A} \times \mathbb{C})\)
-
(5)若\(|\mathbb{A}| = m, |\mathbb{B} = n|\),则\(|\mathbb{A} \times \mathbb{B}| = mn\);
1.8.3 测度论简介
参考链接1:【测度论】Ch1. 问题引入 - Dylaaan的文章 - 知乎
参考链接2:概率论中零测集的意义是什么? - 知乎
参考链接3:实分析与复分析零测集所起的作用 - 百度文库
参考链接4:零测集的概念及性质 - 未知来源
参考链接5:Lebesgue零测度 - CSDN
参考链接5:为什么有理数测度为0? - 知乎
2 概率部分
2.1 常用的统计分布模型
2.1.1 离散分布模型
(一) 两点分布(伯努利分布/0-1分布)——\(X \sim Bern(p)\)
- 分布函数与密度函数
随机变量\(X\)只可能取 0 or 1 两个值,其分布函数为:
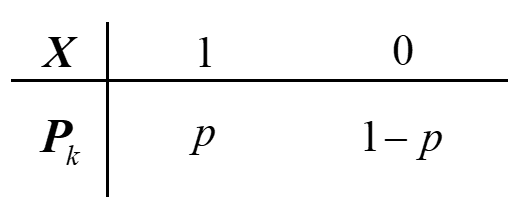
- 期望与方差
(二) 二项分布——\(X \sim B(n, p)\)
- 分布函数与密度函数
- 期望与方差
- 二项分布的性质
(1) 如果\(X \sim B(n,p)\)和\(Y \sim B(m,p)\),且\(X\)和\(Y\)相互独立,那么\(X+Y\)也服从二项分布,它的分布为:
(2) 伯努利分布是二项分布在\(n = 1\)时的特殊情况。\(X \sim B(1,p)\)与\(X \sim Bern(p)\)的意思是相同的。相反,任何二项分布\(B(n,p)\)都是\(n\)次独立伯努利试验的和,每次试验成功的概率为\(p\)。
(3) 泊松近似,当试验的次数趋于无穷大,而乘积\(np\)固定时,二项分布收敛于泊松分布。因此参数为\(λ=np\)的泊松分布可以作为二项分布\(B(n,p)\)的近似,近似成立的前提要求\(n\)足够大,而\(p\)足够小,\(np\)不是很小。
二项展开式: \((a + b)^n = \sum\limits_{r = 0}^{n} C_n^r a^{n-r}b^r\)
排列/组合数计算: \(A_n^m = \dfrac{n!}{(n-m)!}, C_n^m = \dfrac{A_n^m}{m!} = \dfrac{n!}{m! (n-m)!}\)
组合数性质:\(C_n^m = C_n^{n-m}\)、\(C_{n+1}^m = C_n^m + C_n^{m-1}\)、\(C_n^0 = 1\)
(三) 泊松分布——\(X \sim P(\lambda)\)
- 分布函数与密度函数
- 期望与方差
2.1.2 连续分布模型
(一) 均匀分布——\(X \sim U(a,b)\)
- 分布函数与密度函数
- 期望与方差
(二) 指数分布——\(X \sim Exp(\lambda)\)
- 分布函数与密度函数
- 期望与方差
(三) 正态分布——\(X \sim N(\mu, \sigma^2)\)
- 分布函数与密度函数
-期望与方差
- 二维联合正态分布
假设\((X, Y) \sim (\mu_1, \mu_2, \sigma_1^2, \sigma_2^2, \rho)\),则其联合概率密度函数为:
其中\(ρ\)是\(X\)与\(Y\)之间的相关系数,\(\sigma_{X}>0\)且\(\sigma_{Y}>0\)。在这种情况下
- 多元正态分布
注意这里的\(|\mathbf{\Sigma}|\)表示协方差矩阵的行列式。
- 高斯分布的几个重要性质
① 根据高斯函数性质知,两个高斯函数卷积的结果仍为高斯函数;
② 高斯函数的一个积分性质:\(\displaystyle\int_{\boldsymbol x} \exp\left\{ -(\boldsymbol{Ax+b})^2\right\} \text{ d}{\boldsymbol x} = \text{Const}\);
③ 边缘和条件高斯分布:给定\(\boldsymbol x\)的边缘高斯分布和\(\boldsymbol y\)在\(\boldsymbol x\)下的条件高斯分布,则可以推导出\(\boldsymbol y\)的边缘分布:
详细关于高斯正态分布乘积、卷积的公式证明请参考:高斯函数与正态分布乘积与卷积的性质 - 小信号 - 博客园:强推,写的不错!!!
(四) 瑞利分布
瑞利分布(Rayleigh distribution),又译为莱利分布,当一个随机二维向量的两个分量呈独立的、有着相同的方差、均值为0的正态分布时,这个向量的模呈瑞利分布。例如,当随机复数的实部和虚部独立同分布于0均值,同方差的正态分布时,该复数的绝对值服从瑞利分布。该分布是以瑞利命名的。
- 概率密度函数与分布函数
-期望与方差
2.2 几个重要性质
2.2.1 全概率公式
2.2.2 全期望公式
2.2.3 重期望公式
2.3 各种矩估计函数的性质
2.4 相关函数及协方差函数
| 常用函数 | 表达式 |
|---|---|
| 数学期望 | \(\mu_X(t) = E[X(t)]\) |
| 方差函数 | \(\sigma_X^2 = E[X(t) - \mu_X(t)]^2\) |
| 自相关函数 | \(R_X(t_1, t_2) = E[X(t_1) X(t_2)]\) |
| 协方差函数 | \(C_X(t_1, t_2) = \text{Cov}[X(t_1), X(t_2)] = E[(X(t_1) - \mu_X(t_1))(X(t_2) - \mu_X(t_2))]\) |
| 相关/协方差函数 | 表达式 |
|---|---|
| 自协方差 | $C_X(t_1, t_2)$ $=$ $E([X(t_1)$ $-$ $\mu_X(t_1)][X(t_2)$ $-$ $\mu_X(t_2)])$ $=$ $E[X(t_1)X(t_2)]$ $-$ $\mu_X(t_1)\mu_X(t_2)$ |
| 互协方差 | $C_{XY}(t_1, t_2)$ $=$ $E[X(t_1)$ $-$ $\mu_X(t_1)][Y(t_2)$ $-$ $\mu_Y(t_2)]$ |
| 自相关函数 | $R_X(t_1, t_2)$ $=$ $E[X(t_1)X(t_2)]$ |
| 互相关函数 | $R_{XY}(t_1, t_2)$ $=$ $E[X(t_1)Y(t_2)]$ |
| 注1:特别的若$\begin{Bmatrix} X(t), t \in T\end{Bmatrix}$的期望函数为0,则协方差函数和自相关函数相等。若$X(t_1),X (t_2)$随机程的两状态相互独立,则有$C_X(t_1, t_2) = 0$; 注2:特别的若$X(t), Y(t)$之一的期望为0,则互协方差等于互相关函数。若$X(t),Y(t)$相互独立,则$C_{XY}(t_1, t_2) = 0$,$X(t), Y(t)$称为互不相关的。相互独立的两个随机过程必是互不相关的。反之如果互相关的不一定相互独立。 |
|
| 谱密度函数 | 表达式 |
|---|---|
| 自谱密度函数 | $S_X(\omega) = \displaystyle\int_{-\infty}^{\infty} R_X(\tau) \text{e}^{-j\omega t} \text{ d}\tau$ |
| 互谱密度函数 | $S_{XY}(\omega) = \displaystyle\int_{-\infty}^{\infty} R_{XY}(\tau) \text{e}^{-j\omega t} \text{ d}\tau$ |
| 注:谱密度函数就是相关函数的傅里叶变换式;反之,相关函数就是谱密度函数的傅里反变换。 | |
2.4.2 随机向量期望与协方差
此处仅给出在经典统计学意义下的随机向量(不考虑在测度论框架下的随机向量定义),即此处的随机向量的各个分量均为随机变量,且均值为\(\mu\),方差为\(\sigma^2\),则我们可以按如下方式来定义一个随机向量:
定义 1 :设\(\boldsymbol X = [X_1, X_2, \cdots, X_n]^{\mathrm T}\)为随机向量,若其每个分量\(X_i\)为随机变量,且称\(\boldsymbol X\)为\(n \times 1\)随机向量,记\(\mathbb{E}(\boldsymbol X) = [\mathbb{E}(X_1), \mathbb{E}(X_2), \cdots, \mathbb{E}(X_n)]^{\mathrm T}\)为\(\boldsymbol X\)的均值。
定义 2 :称\(\mathrm{Cov}(\boldsymbol X) = \mathbb{E}[(\boldsymbol X - \mathbb{E} \boldsymbol X)(\boldsymbol X - \mathbb{E} \boldsymbol X)^{\mathrm T}]\)为\(\boldsymbol X\)的自协方差矩阵,自协方差矩阵必为半正定对称矩阵。
定义 3 :设\(\boldsymbol X\)与\(\boldsymbol Y\)分别为\(n \times 1\)和\(m \times 1\)随机向量,称\(\mathrm{Cov}(\boldsymbol X, \boldsymbol Y) = \mathbb{E}[(\boldsymbol X - \mathbb{E} \boldsymbol X)(\boldsymbol Y - \mathbb{E} \boldsymbol Y)^{\mathrm T}]\)为\(\boldsymbol X\)与\(\boldsymbol Y\)的协方差矩阵。
3 线性代数/矩阵论部分
3.1 转置和逆
- Penrose的广义逆矩阵
设矩阵\(\boldsymbol A \in \mathbb{C}^{m \times n}\),若矩阵\(\boldsymbol X \in \mathbb C^{n \times m}\)满足以下4个Penrose方程:
则称\(\boldsymbol X\)为\(\boldsymbol A\)的Moore-Penrose逆(伪逆),记为\(\boldsymbol{A}^{\dagger}\)。
- 矩阵求逆公式
3.2 矩阵和向量求导
输入向量有的地方使用列向量,也有的使用行向量,其实本质上没有什么不同,只是表示方式不一样。一般情况下可能都是使用分母布局,就是求导结果按照分母列向量的形式排列(默认向量都是列向量)。
3.2.1 向量对向量求导
3.2.2 标量对向量求导
参考链接:
其中,$$a$$为常数列向量。
矩阵求导公式的数学推导(矩阵求导——基础篇) - Iterator的文章 - 知乎
3.2.3 迹的求导
(一)迹的定义
设矩阵\(\boldsymbol A\)为方阵,即\(\boldsymbol A_{n \times n}\),矩阵\(\boldsymbol B\)也为方阵\(\boldsymbol B_{n \times n}\),则矩阵的迹为:
(二)性质
-
\(\mathrm{tr}(\boldsymbol {AB}) = \mathrm{tr}(\boldsymbol {BA})\)
-
\(\mathrm{tr}(\boldsymbol A) = \mathrm{tr}(\boldsymbol A^{\mathrm T})\)
-
\(\nabla_{\boldsymbol A} \mathrm{tr}(\boldsymbol {AB}) = \boldsymbol A^{\mathrm T}\)
-
\(\nabla_{\boldsymbol A} \mathrm{tr}(\boldsymbol {ABA}^{\mathrm T}\boldsymbol {C}) = \boldsymbol {CAB} + \boldsymbol C^{\mathrm T} \boldsymbol A \boldsymbol A^{\mathrm T}\)
3.3 求方阵的n次方方法总结
3.3.1 对角化
若矩阵\(\boldsymbol {A}\)可以相似对角化后,那么先相似对角化再求\(\boldsymbol {A}^n\),这属于常规思路。
(一)矩阵可对角化的条件(3个)
-
\(n\)阶矩阵可对角化的充分必要条件是有个线性无关的特征向量。若 阶矩阵定理2 矩阵 的属于不同特征值的特征向量是线性无关的。
-
若\(n\)阶矩阵有个互不相同的特征值,则可对角化。
-
\(n\)阶矩阵可对角化的充分必要条件是:每个特征值对应的特征向量线性无关的最大个数等于该特征值的重数(即的每个特征值对应的齐次线性方程组的基础解系所含向量个数等于该特征值的重数,也即的每个特征子空间的维数等于该特征值的重数)。
(二)矩阵对角化
设\(n×n\)矩阵有\(n\)个线性无关的特征向量\(\boldsymbol x_1, \boldsymbol x_2, \cdots, \boldsymbol x_n\),令矩阵\(\boldsymbol S = (\boldsymbol x_1, \boldsymbol x_2, \cdots, \boldsymbol x_n)\),则有
即,矩阵可对角化为
3.4 矩阵特征值求解
3.4.1 特征值分解理论基础
\(\boldsymbol A\)为\(n\)阶矩阵,若数\(λ\)和\(n\)维非0列向量\(\boldsymbol x\)满足\(\boldsymbol{Ax} = λ \boldsymbol x\),那么数\(λ\)称为\(\boldsymbol A\)的特征值,\(\boldsymbol x\)称为\(\boldsymbol A\)的对应于特征值λ的特征向量。式\(\boldsymbol{Ax} = λ \boldsymbol x\)也可写成\((\boldsymbol{A} - λ\boldsymbol{E})\boldsymbol{x} = \boldsymbol 0\),并且\(|λ\boldsymbol E - \boldsymbol A|\)叫做\(\boldsymbol A\)的特征多项式。当特征多项式等于0的时候,称为\(\boldsymbol A\)的特征方程,特征方程是一个齐次线性方程组,求解特征值的过程其实就是求解特征方程的解。
3.4.2 特征值分解实例计算
例子1:计算矩阵\(\boldsymbol A = \left(\begin{array}{ccc} 4 & 6 & 0 \\ -3 & -5 & 0 \\ -3 & -6 & 1 \end{array}\right)\)的特征值和特征向量
解:
- STEP 1:计算\(|\boldsymbol A - λ\boldsymbol I|\)
\(\quad\)解得:\(\lambda_1 = -2, \lambda_2 = \lambda_3 = 1\)
- STEP 2: 把每个特征值\(\lambda\)带入到下方的线性方程组\((\boldsymbol A - \lambda \boldsymbol I) \boldsymbol x = \boldsymbol 0\),求出特征向量
\(\quad\)(1) 当\(\lambda_{1} = -2\)时,解线性方程组:\((\boldsymbol A - (-2)\boldsymbol I)\boldsymbol x = \boldsymbol 0\)。
\(\qquad\)所以,\(\left\{\begin{array}{r} x_{1} + x_{2} = 0 \\ -x_{1} + x_{3} = 0 \end{array}\right.\)。可以看到\(x_3\)为自由变量,因此:
\(\qquad\)取\(x_3 = 1\),可解得\(\left\{\begin{array}{l} x_{1} = -1 \\ x_{2} = 1 \\ x_{3} = 0 \end{array}\right.\),所以\(\lambda_1\)的特征向量为:\(\boldsymbol{p}_1=\left(\begin{array}{c} -1 \\ 1 \\ 1 \end{array}\right)\)。
\(\quad\)(2) 当\(\lambda_{2}=\lambda_{3}=1\)时,解线性方程组:\((\boldsymbol A − \boldsymbol I) \boldsymbol x = \boldsymbol 0\)
\(\qquad\)所以,\(x_{1}+2x_{2}=0\)。可以看到\(x_2\)、\(x_3\)为自由变量,因此:
\(\qquad\)先取\(x_{2} = 1\)、\(x_{3} = 0\),可解得\(\left\{\begin{array}{l} x_{1} = -2 \\ x_{2} = 1 \\ x_{3} = 0 \end{array}\right.\),所以\(\lambda_2\)的特征向量为:\(\boldsymbol{p}_2 = \left(\begin{array}{c} -2 \\ 1 \\ 0 \end{array}\right)\)
\(\qquad\)再取\(x_{2} = 0\)、\(x_{3} = 1\),可解得\(\left\{\begin{array}{l} x_{1} = 0 \\ x_{2} = 0 \\ x_{3} = 1 \end{array}\right.\),所以\(\lambda_3\)的特征向量为:\(\boldsymbol p_3 = \left(\begin{array}{c} 0 \\ 0 \\ 1 \end{array}\right)\)
综上所述:矩阵\(\boldsymbol A\)的特征值为\(\lambda_{1}=-2,\lambda_{2}=\lambda_{3}=1\),对应的特征向量为:
3.5 线性变换/基变换

参考资料:
3 相似与对角化 - 御手洗洁精的文章 - 知乎
求线性变换A在基下的矩阵 - 豆瓣:实例计算!
线性变换在不同基下的矩阵相同吗
为什么基变换是右乘一个过渡矩阵,而不是左乘一个过渡矩阵? - 王涛的回答 - 知乎
变换矩阵的左乘与右乘区别 - CSDN
基变换与坐标变换 - 原创力文档
3.6 正定矩阵
3.6.1 正定矩阵定义
3.6.2 正定矩阵性质
3.6.3 正定矩阵意义
看论文,看书,总是会发现突然作者来一句,我们可以证明矩阵正定,所以balabala。证明如下…
往往这个时候,我们会很纳闷,上网一搜,会发现都是证明矩阵正定的各种方法,而很少有人去讨论,到底为什么我们要去证明一个矩阵是正定的,以及矩阵正定到底意味着什么。然后往往看了一大圈回来还是一脸问号。
那今天本文就非常简单的定性讨论下为什么大家要去证明一个矩阵是正定的,以及正定的意义。
(一) 可以将正定矩阵理解为矩阵版标量正系数
在标量中:\(y = ax\),当\(a>0\)时,\(y\)将与\(x\)的正负号相同,即如果\(x>0\)则\(y>0\),\(x<0\)则\(y<0\)。与\(a\)相乘不会改变正负号。
那该性质如何在多维空间中表示呢?这里我们说,简单理解正定矩阵便是符合标量中\(a\)性质的矩阵。
也则是\(\boldsymbol x^{\mathrm T} \boldsymbol{Ax}>0\)的含义。\(\boldsymbol A\)正定,则其中一个性质是\(\boldsymbol A\)与\(\boldsymbol x\)同向夹角小于九十度,所以\(\boldsymbol{Ax}\)将会与\(\boldsymbol x\)同向,而不会将\(\boldsymbol x\)变换到与之完全相反的方向。
总结:在标量空间中我们有\(y=ax\), 我们可以规定\(a>0\)。而在多维空间中,\(\boldsymbol{y=Ax}\), 我们定义矩阵"\(\boldsymbol A>0\)"的方式便是正定,而矩阵\(\boldsymbol A>0\)不能这么定义,\(\boldsymbol x^{\mathrm T} \boldsymbol{Ax}>0\)便是正确的定义方式,其在标量空间中等价于 \(a>0\)。
正定矩阵意味着对于任意向量的变换后夹角都是锐角,这意味着对于任何的迭代(优化、搜索)过程,迭代前后两个点充分的近。除了优化外,在微分方程迭代计算中,一般状态迭代矩阵满足\(M = E + \Delta U\),\(\Delta U\)是微分矩阵近似得到的差分矩阵,通常都是正定的,这样才能保证变化的微小型,从而确保迭代的稳定性。
(二) 系统(求解的问题)具有全局最小值
从系统角度看,如果一个矩阵是正定的,那么我们可以简单理解这个系统拥有全局最小值。而绝大部分问题都可以抽象为解决一个优化问题,如果能证明或者将问题用正定矩阵表示,那么从理论上该问题便拥有全局最优解。
比如如果矩阵二阶导为正定矩阵\(\boldsymbol x^{\mathrm T} \boldsymbol{Ax}>0\),则证明其具有局部最小值解,反之\(\boldsymbol x^{\mathrm T} \boldsymbol{Ax}<0\),则证明其具有局部最大值解,如果不满足上述两种则证明函数会有鞍点(saddle point)。

从上图可以看A为最小值,B为鞍点,C为最大值。
而如果理论上拥有全局最优解,便会给我们使用很多已知成熟的方式去求解最优值的方法,(简单举个例子:比如使用Hessian矩阵求解最优等),这也是机器学习,优化问题最喜欢去研究和解决的情况。
(三) 数学角度
从数学视角看,当我们说矩阵正定,相当于对矩阵做了相当强的一种限制,那么在这个限制里就会发现相当多有趣的性质,另外有许多矩阵是正定的,比如协方差矩阵,动力矩阵等等。这就给了数学家研究归纳性质的强烈兴趣。
上文转载自:一个矩阵正定(Possitive definite) 到底能说明什么,能解决什么问题? - 若辰的文章 - 知乎
其他比较好的文章:正定矩阵的几何意义 - Flyingpie的文章 - 知乎
3.7 矩阵行列式的相关性质
(一) The Matrix Determinant Lemma(MDL)定理
(二)
当矩阵\(\boldsymbol A(t)\)可逆时,有如下:
4 微分方程
4.1 常数变异法
求解非齐次线性微分方程的常用方法便是常数变易法,下面,我们首先以一阶非齐次线性微分方程来引入常数变易法。
我们联想一阶齐次线性微分方程的解法:
分离变量法:
-
STEP 1:两边同时除以\(y\):\(\dfrac{\mathrm{d}y}{y} = - P(x)\mathrm{d}x\)
-
STEP 2:两边积分得:\(\ln y = \displaystyle\int -P(x)\mathrm{d}x + C\)
-
STEP 3:求的结果:\(y = C\mathrm{e}^{-\int P(x)\mathrm{d}x}\)
下面进行常数变异:\(C \longrightarrow C(x)\)
接下来就是将\(y = C(x)\mathrm{e}^{-\int P(x)\mathrm{d}x}\)带回\(\dfrac{\mathrm{d}y}{\mathrm{d}x} + P(x)y = Q(x)\),求解出\(C(x)\)。
最后,根据初始条件,得到解。
4.2 拉普拉斯变换
拉普拉斯变换的导数定理(见拉普拉斯变换)使得我们可以把常系数线性微分方程化为代数方程,不论是否齐次。在常系数齐次线性微分方程中,我们通过把方程写为算子\(\dfrac{\mathrm{d}}{\mathrm{d}t}\)的代数方程,实现了化微分方程为代数方程,但这种操作对非齐次方程没有用。拉普拉斯变换是另一种化为代数方程的思路,而且不拘泥于齐次与否。
4.2.1 拉普拉斯变换的导数定理
设\([0, +\infty]\)上有\(k\)次可导函数\(f(t)\),其拉普拉斯变换为:
则有
进一步推广的到2阶:
4.2.2 函数乘以一个指数函数后的拉普拉斯变换
对于\(f(t)\),若设其拉普拉斯变换为\(F(s)\),则
4.2.3 常见信号的拉氏变换
常见Laplace拉氏变换对公式表及反变换法 - 百度文库
常用拉氏变换表 - 博客园
冲激偶 的 拉普拉斯变换 - 八卦掌的文章 - 知乎
4.2.4 利用拉普拉斯变换求解常系数微分方程
例子1: 求方程\(x'''+3x''+3x'+x=1\)的满足初始条件\(x(0) = x'(0) = x''(0)\)的解。
解:根据初始条件对方程两端进行Laplace变换得:
把上式分解为:
进行逆Laplace变换得:
参考链接:拉普拉斯变换求解微分方程(组)典型范例
部分分式展开法
5 物理部分
5.1 散度旋度定理与几个重要等式
5.1.1 散度定理
| 散度 | 旋度 |
|---|---|
| \(\text{div } \vec{F} = \lim\limits_{\Delta V \to 0} \dfrac{ \displaystyle\oint_S \vec{F}\mathrm{d}\vec{S}}{\Delta V}\) | \(\text{rot } \vec{F} = \lim\limits_{\Delta S \to 0} \dfrac{ \displaystyle\oint_l \vec{F}\mathrm{d}\vec{l}}{\Delta S}\) |
5.1.2 哈密顿算子
哈密顿算子的两个性质:矢量性和微分性
4.1.3 拉普拉斯算子
(一) 标量拉普拉斯算子——\(\nabla^2 \mu\)
在直角坐标系中的展开形式
(二) 矢量拉普拉斯算子——\(\nabla^2 \vec{A}\)
简记为“旋了又旋(玄了又玄)”
注意:不要把拉普拉斯算子中的上角标看成是“平方”,因为一是本身的意义就不是平方,二是这就是一个符号。
5.1.4 几个重要算式
(1) 变换1:\(\nabla \cdot (\vec{A} \times \vec{B}) = \vec{B} \cdot (\nabla \times \vec{A}) - \vec{A} \cdot (\nabla \times \vec{B})\)
(2) 变换2:\(\nabla \times {u \vec{A}} = u \nabla \times \vec{A} + \nabla u \times \vec{A}\)
(3) 恒等式1:\(\nabla \times (\nabla u) \equiv 0\)
(4) 恒等式2:\(\nabla \cdot (\nabla \times \vec{A}) \equiv 0\)
5.2 麦克斯韦方程组
6 信号处理部分
6.1 常用傅氏变换及其性质
【重要知识】常用信号的傅里叶变换+重要口诀总结 - Bilibili
信号与系统 - Wreng - 博客园:总结了傅里叶变换和拉普拉斯变换的基础知识。
Vinson88 - 博客园:这个博主主要记录了几篇(数字)信号处理、通信方向的知识,其中有几篇博客文章正好是我比较疑惑的问题,可以看看该博主的见解。
6.2 常见信号的运算
6.2.1 常见的信号空间
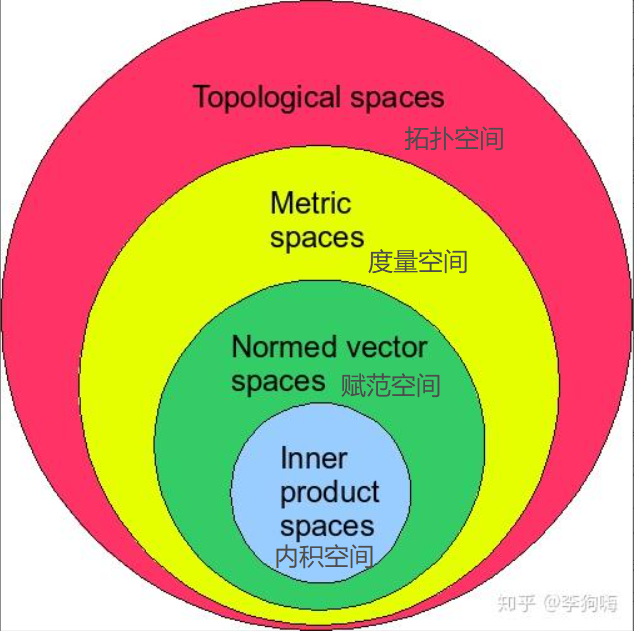
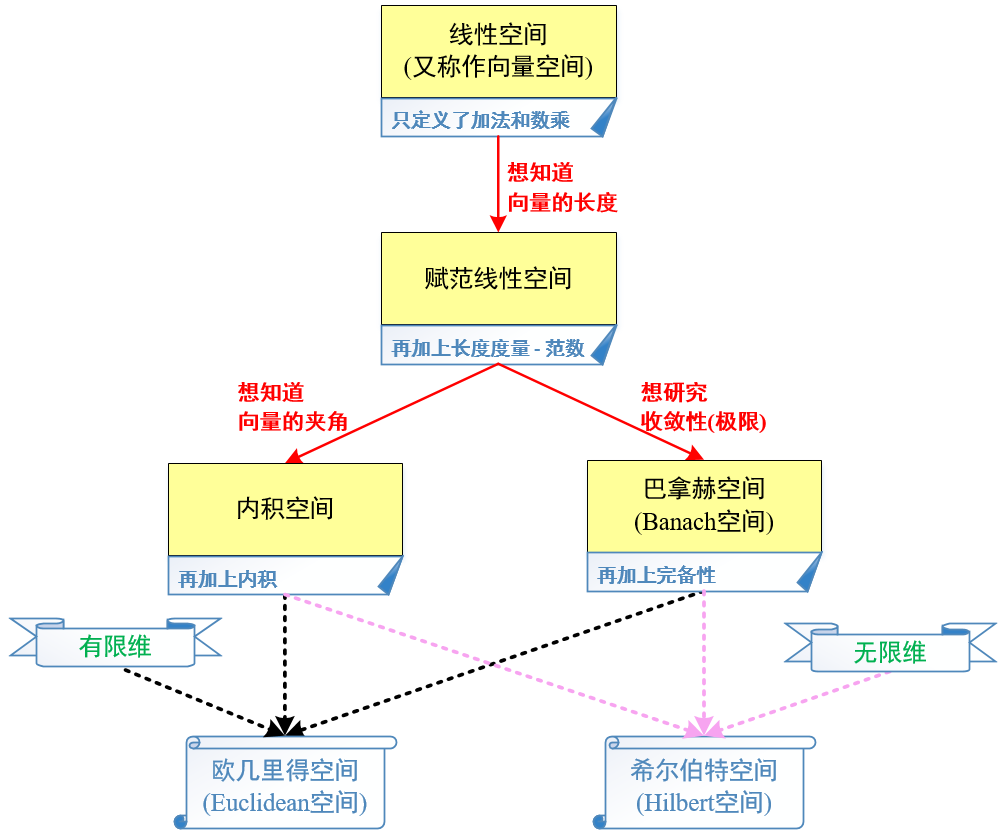
(一) 希尔伯特空间
希尔伯特空间(Hilbert space)指的其实就是完备的内积空间,即希尔伯特空间是一种特殊的内积空间,其特殊性就体现在其完备性上,因为一个内积空间不一定是完备空间。而非完备的内积空间又称为准希尔伯特空间(pre-Hilbert space)。
那么,这其中包含有两个概念,即:“完备空间”和“内积空间”,两者的交集即为“完备的内积空间”,下面分开进行解释。
(二) 完备空间
在数学分析中,完备空间又称完备度量空间或称柯西空间(Cauchy space)。如果一个度量空间\(\mathbb M\)中的所有柯西序列都收敛在该空间\(\mathbb M\)中的一点,则称该空间\(\mathbb M\)为完备空间。
这个定义中又涉及到两个的概念,即“度量空间(Metric space)”和“柯西序列(Cauchy sequence)”
- 度量空间
在数学中,度量空间是个具有距离函数的集合,该距离函数定义集合内所有元素间之距离。此距离函数被称为集合上的度量。度量空间中最符合人们对于现实直观理解的是三维欧几里得空间(Euclidean space)。
这里的“距离”是一个抽象概念,不仅仅指两点间的直线距离,还包括向量距离、函数距离、曲面距离等。定义为:
设\(\mathbb W\)是一个非空集合,对中任意两点\(x\)和\(y\),在度量\(d\)的作用下,有一实数\(d(x, y)\)与该两点对应且满足:
(1) 正定性:\(d(x,y) \geq 0\),当且仅当\(x=y\)时取等号;
(2) 对称性:\(d(x,y) = d(y,x)\);
(3) 三角不等性:\(d(x,y) \leq d(x,z) + d(y, z)\);
那么就称\(d(x,y)\)为\(\mathbb W\)中的一个距离(度量),称\(\mathbb W\)为一个对于度量\(d\)而言的度量空间。
- 柯西序列
在数学中,柯西序列、柯西列、柯西数列或基本列是指这样一个数列,它的元素随着序数的增加而愈发靠近。任何收敛数列必然是柯西列,任何柯西列必然是有界序列。
完备性
前面提到“如果一个度量空间\(\mathbb M\)中的所有柯西序列都收敛在该空间\(\mathbb M\)中的一点,则称该空间\(\mathbb M\)为完备空间。”可以把实数和有理数作为具体的例子。由实数\(\mathbb R\)定义的序列在通常定义的距离意义下是完备的。而由有理数\(\mathbb Q\)定义的序列在通常定义的距离意义下则不是完备的。
例如一个由有理数构成的序列:\(x_0 = 1, x_{n+1} = \dfrac{1}{2}\left(x_n + \dfrac{x_n}{2}\right)\),也即:\(\left(1, \dfrac{3}{2}, \dfrac{17}{12}, \cdots \right)\),可以用巴比伦方法证明其结果收敛于\(\sqrt{2} \notin \mathbb Q\)
说了这么多,用一句通俗但不严谨的话来表达就是:通常见到的空间中,实数空间是完备空间。

(三) 内积空间
指的是添加了一个“运算方法”(或称“结构”)的向量空间(或称为“线性空间”,两者同义),这个新添加的运算方法即“内积(Inner product)”又称“标量积(Scalar product)”或称“点积(Dot product)”。内积将一对向量与一个纯量连接起来,允许我们严格地谈论向量的“夹角”和“长度”,并进一步谈论向量的正交性。
这其中又涉及了“向量空间(Vector space)”的概念。
而且,内积空间具有基于空间本身的内积所自然定义的范数,\(\| x \| = \sqrt{\langle x, x \rangle}\),且其满足平行四边形定理,也就是说内积可以诱导一个范数,所以内积空间一定是“赋范空间”。这其中又涉及了“赋范空间(Normed vector space)”的概念。 一步一步来,先说说向量空间(或称“线性空间”,两者同义)。
- 向量空间
一般向量空间的定义如下:定义在一个域\(\mathbb F\)(例如,实数域\(\mathbb R\)、复数域\(\mathbb C\))上的向量空间\(\mathbb V\)是由向量组成的一个集合,并赋予该集合向量与向量之间的加法:\(\mathbb{V} + \mathbb{V} \to \mathbb V\) ;和标量与向量之间乘法:\(\mathbb{F} \times \mathbb{V} \to\mathbb{V}\) 。向量空间中向量加法与标量乘法运算满足基本的8条性质(自行去网上检索,这里不再列出)。
8条性质中并不包含向量与向量之间的乘法。而这也是正是内积作为区别内积空间与一般向量空间的附加条件的原因。这也是为什么内积空间包含三个运算:向量与向量之间的加法,标量与向量之间的乘法,以及向量与向量之间的乘法。 在了解了向量空间的基础上,再反过头来,补充一下赋范空间的概念和这几个空间之间的关系。由于赋范空间定义在向量空间的基础之上,所以也称为线性赋范空间,简称赋范空间。注意,前面提到向量空间就是线性空间,两者同义。
- (线性)赋范空间
范数常常被用来度量某个向量空间(或矩阵)中的每个向量的长度或大小。其定义是:设\(\mathbb V\)是定义在一个域\(\mathbb F\)上的向量空间,函数\(\| \cdot \|\)作用于\(\mathbb V\),且满足条件:
(1) 正定性:\(\forall x \in \mathbb V, \| x \| \geq 0\),当且仅当\(x = 0\)时取等号;
(2) 齐次性:\(\forall x \in \mathbb V, \alpha \in \mathbb F\),有\(\| \alpha x \| = |\alpha| \| x \|\);
(3) 三角不等式:\(\forall x,y \in \mathbb V\),有\(\| x+y \| \leq \|x\| + \|y\|\);
称\(\| \cdot \|\)是\(\mathbb V\)上的一个范数,定义了范数\(\| \cdot \|\)的向量空间\(\mathbb V\)称为(线性)赋范空间。通过将赋范空间和上面的度量空间相比较,可知“范数”与“距离”之间的区别有:
① 距离(或称“度量”)是定义在任意非空集合上的,而范数则定义在向量空间上;
② 在向量空间中,范数可以诱导距离(或称“度量”),反之不成立,这也意味着赋范空间一定属于度量空间;
③ 范数的“齐次性”表明范数可以看做是强化后的距离概念。
(四) 总结
说了这么多感觉有点乱,所以再总结一下各个空间之间的关系:
-
范数运算 + 向量空间 = (线性)赋范空间
-
(线性)赋范空间 + 内积运算 = 内积空间
-
(线性)赋范空间 + 完备性 = 巴拿赫空间
-
内积空间 + 完备性 + 有限维 = 欧几里得空间
-
内积空间 + 完备性 = 希尔伯特空间
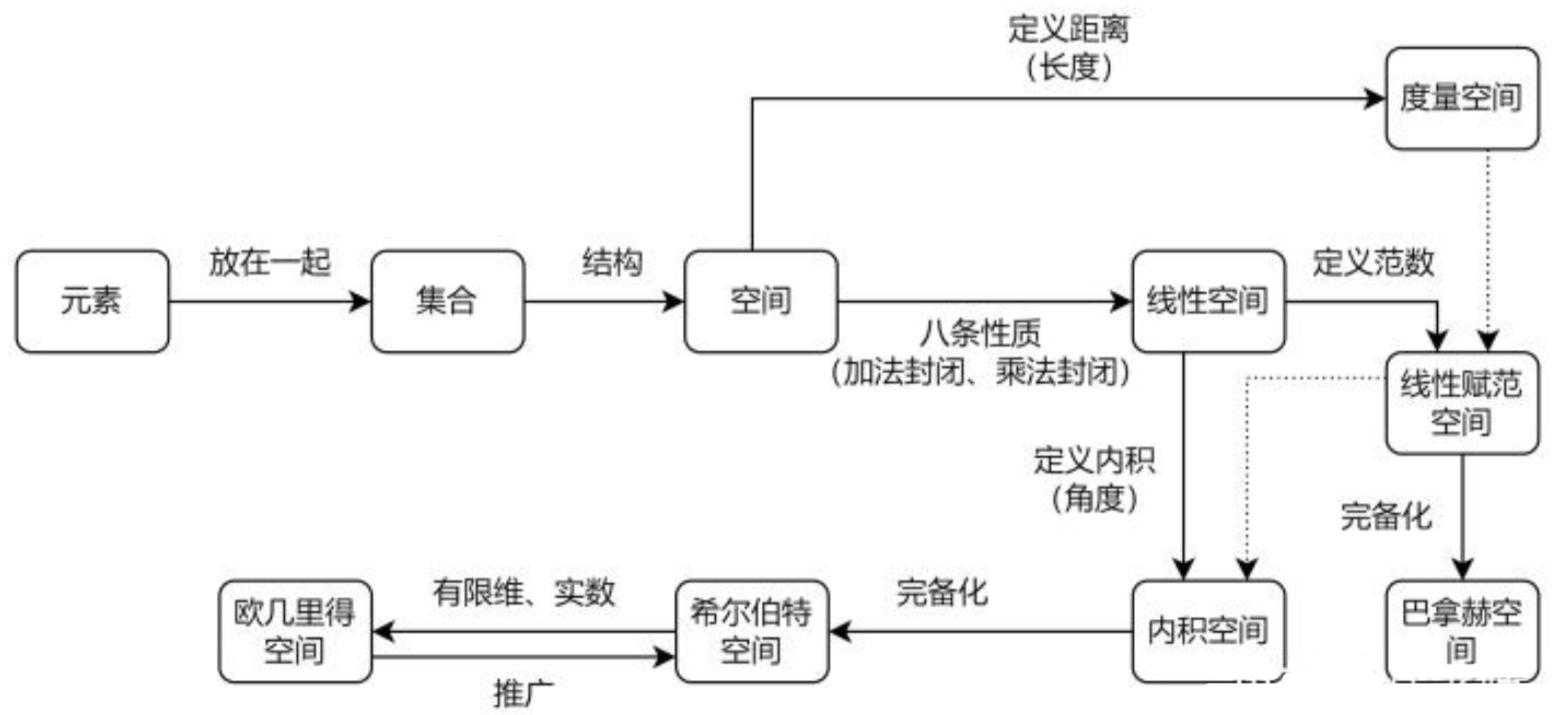
最后补充一句:希尔伯特空间(Hilbert space)是有限维欧几里得空间(Euclidean space)的一个推广,使之不局限于实数的情形和有限的维数,但又不失完备性(不像一般的非欧几里得空间那样破坏了完备性)。
而且从上面的关系可知,希尔伯特空间可以看做是增加了内积运算的巴拿赫空间(Banach space)。
参考链接1:希尔伯特空间、内积空间的定义有什么关系和区别? - 李狗嗨的回答 - 知乎
参考链接2:如何理解希尔伯特空间? - TimXP的回答 - 知乎
参考链接3:希尔伯特空间 - yang的文章 - 知乎
参考链接4:向量的夹角为什么可以用内积来算,是巧合吗? - 川南雁的回答 - 知乎
6.2.2 内积
任意信号\(x(t)\)与\(y(t)\)的内积定义为:
特别的,对于实信号\(x(t)\)与\(y(t)\)的内积定义为:
|
时域内积等于频域内积:设信号$x(t)$与$y(t)$的傅氏变换为$X(f)$和$Y(f)$,则有: $$ \int_{-\infty}^{\infty}x(t)\overline{y(t)}\mathrm{d}t = \int_{-\infty}^{\infty}X(f)\overline{Y(f)}\mathrm{d}f $$ 如果两个信号在时域正交,那么它们在频域也是正交的。 |
|
信号能量与内积的关系:信号能量是信号与其自身的内积: $$ E_x = \int_{-\infty}^{\infty}|x(t)|^2\mathrm{d}t = \int_{-\infty}^{\infty}x(t)\overline{x(t)}\mathrm{d}t $$ |
|
互能量与内积的关系:两个信号的内积也称为互能量: $$ E_{xy} = \int_{-\infty}^{\infty}x(t)\overline{y(t)}\mathrm{d}t \qquad E_{yx} = \int_{-\infty}^{\infty}y(t)\overline{x(t)}\mathrm{d}t $$ 此时,有: \[E_{xy} = \overline{E_{yx}}
\] 特别的,对于实信号: \[E_{xy} = E_{yx}
\] |
6.2.3 相关函数
能量信号\(x(t)\)与\(y(t)\)的互相关函数:
特别的,对于实信号的互相关函数:
|
互相关函数的共轭对称性:
$$
R_{xy}(\tau) = \overline{R_{yx}(-\tau)}
$$
实信号互相关函数的对称性: \[R_{xy}(\tau) = R_{yx}(-\tau)
\] |
能量信号\(x(t)\)的自相关函数:
特别的,对于实信号的自相关函数:
|
自相关函数的共轭偶对称性:
$$
R_{x}(\tau) = \overline{R_{x}(-\tau)}
$$
实信号的自相关函数是偶函数: \[R_{x}(\tau) = R_{y}(-\tau)
\] |
| 自相关函数和能量的联系:$x(t)$的能量是自相关函数在$\tau=0$处的值 $$ E_x = R_{x}(0) = \int_{-\infty}^{\infty}x(t)\overline{x(t+0)}\mathrm{d}t = \int_{-\infty}^{\infty}|x(t)|^2\mathrm{d}t $$ |
6.2.4 卷积
卷积的本质是两个序列/函数的平移,加权叠加。
对于函数\(x(t)\)和\(h(t)\),卷积的结果是:
6.3 噪声的白化
噪声白化是指对噪声数据进行去相关,且噪声协方差被单位化的过程。若\(\boldsymbol a\)为\(m×1\)维随机向量序列(均值=0),则其协方差矩阵可表示为一个\(m×m\)维的矩阵\(\boldsymbol C_a\),如果该协方差矩阵\(\boldsymbol C_a\)非奇异且不为单位矩阵,则称随机向量\(\boldsymbol a\)为有色(或非白)随机向量。
令协方差矩阵特征值分解为:
记:
此时,令变换:
则\(\boldsymbol b\)的协方差矩阵为单位矩阵\(\boldsymbol I\),即随机向量\(\boldsymbol b\)是标准白色随机向量,换言之,有色的随机向量\(\boldsymbol a\)经过线性变换后变成了白色随机向量。一般将线性变换矩阵\(\boldsymbol W\)称为随机向量\(\boldsymbol a\)的白化矩阵。
通过研究发现,对于某一随机变量,能使其进行白化的变换矩阵并不是唯一存在的例如上述分析的\(\boldsymbol W\)矩阵和通常MNF变换(最小噪声分离变换)中使用的白化矩阵\(\boldsymbol F^{\mathrm T}\)都可以达到使\(\boldsymbol a\)白化的效果。进一步的研究显示,当采用不同的白化矩阵所得的白化结果\(\boldsymbol b\)并不一样。
虽然变换矩阵\(\boldsymbol W\)和\(\boldsymbol F^{\mathrm T}\)都可以使随机变量\(\boldsymbol a\)“白化”,但白化矩阵\(\boldsymbol W\)的变换结果并不改变变量\(\boldsymbol a\)原有的分布特征,而白化矩阵\(\boldsymbol F^{\mathrm T}\)则不论变量\(\boldsymbol a\)原有的分布特征如何,变化后均呈高斯分布。
张颢老师说过:在很多情况下,噪声是不是白的不本质,因为可以通过白化矩阵转换为“白的”。
参考资料:基于噪声白化的高光谱数据子空间维数算法 - 万方
参考资料:数据白化 - CSDN
参考资料:白噪声和有色噪声 - CSDN
参考资料:随机信号处理笔记之色噪声及白化滤波器 - CSDN
6.4 分贝(dB)
6.4.1 分贝的基本定义
分贝 \(\text{dB}\) 定义为两个数值的对数比率,这两个数值分别是测量值和参考值(也称为基准值),存在两种定义情况。
- 一种为功率之比:
- 一种为幅值之比:
其中,\(P_0\)和\(U_0\)为功率和幅值的参考值。
使用功率之比公式进行计算的例子如:声功率(\(\mathrm{W}\)),声强(\(\mathrm{W/m}^2\)),电功率,电强等。
使用幅值之比公式进行例子如:声压(\(\mathrm{Pa}\)),电压(\(\mathrm{V}\)),加速度(\(\mathrm{m/s}^2\)),温度等。
分贝值完全依赖于测量值与参考值之比,因此计算时选择合适的参考值很关键。 没有特殊要求时,参考值通常为1。
通常,参考功率被定义为标准参考值,如1毫瓦(\(\text{mW}\))或1瓦(\(\text{W}\)),具体取决于特定的应用或标准。
6.4.2 分贝的性质
贝尔最初是用来表示电信功率讯号的增益和衰减的单位,1个贝尔的增益是以功率在放大后与放大前的比值。所以,电压增益的分贝表达式是从功率的角度来考虑的,即分贝应该理解为功率的增大或衰减情况。
- 当用对数 \(\text{dB}\) 表达增益随频率变化的曲线时,可大大扩大线性增益变化的区间。例如:人耳可听的声压幅值波动范围为\(2×10^{-5} \mathrm{Pa} \sim 20\mathrm{Pa}\),而用幅值 \(\text{dB}\) 表示时对应的 \(\text{dB}\) 数值仅仅为\(0 \sim 120 \text{ dB}\)。
- 计算多级放大的总增益时,可将乘法化为加法进行运算。
- \(\text{dB}\) 值可正可负。正值表示增大,负值表示衰减。若\(\dfrac{X}{X_0}<1\),则 \(\text{dB}\) 值为负值。也就是说测量值大于参考值的为正,小于参考值的为负。
- 幅值比互为倒数时, \(\text{dB}\) 值互为正负。这是因为:
- \(\text{dB}\) 值与线性幅值比的关系如下表所示

红色字体表示的是几个比较重要的 \(\text{dB}\) 值,我们应该要记住,因为我们经常要用到它们。像增大 \(+6\text{ dB}\) 表示线性幅值增大一倍。
6.4.3 特别说明\(-3\text{ dB }\)和\(0 \text{ dB}\)
通过上表易知\(-3\text{ dB }\)对应的幅值比为\(0.707\),即\(\dfrac{\sqrt 2}{2}\)倍,也就是说幅值是原来的\(\dfrac{\sqrt 2}{2}\)倍。若按功率比来计算,则功率比为\(\dfrac{1}{2}\),也就是原功率的一半,故\(-3\text{ dB }\)称为“半功率点”或者“截止频率点”。这时功率是正常时的一半,电压或电流是正常时的\(0.707\)。在电声系统中,\(\pm 3 \text{ dB}\) 的差别被认为不会影响总特性。所以各种设备指标,如频率范围,输出电平等,不加说明的话都可能有\(\pm 3 \text{ dB}\)的出入。
\(0 \text{ dB}\) 表示输出与输入或两个比较信号一样大。分贝是一个相对大小的量,没有绝对的量值。
6.4.4 \(\text{dB}\)、\(\text{dBm}\)、\(\text{dBc}\)之间的区别
(1) dBm
\(\text{dBm}\) 是一个考征功率绝对值的值,计算公式为:
其中,\(P\)代表信号的功率。
[例1] 如果发射功率\(P\)为\(1 \text{ mw}\),折算为 \(\text{dBm}\) 后为 $ 0 \text{ dBm}$ 。
[例2] \(40 \text{ W}\)的功率,\(\text{dBm}\) 折算值:\(10\log_{10} \dfrac{40\text{ W}}{1\text{ mw}} =10 \log_{10}(40000) = 46 \text{ dBm}\)。
(2) dBi和dBd
\(\text{dBi}\) 和 \(\text{dBd}\) 是考征增益的值(功率增益),两者都是一个相对值, 但参考基准不一样。\(\text{dBi}\) 的参考基准为全方向性天线,\(\text{dBd}\) 的参考基准为偶极子,故两者略有不同。一般认为表示同一增益,用 \(\text{dBi}\) 表示比用 \(\text{ dBd}\) 表示要大 \(2. 15\)。
[例3] \(0 \text{ dBd} = 2.15 \text{ dBi}\)。
[例4] 一面增益为\(16 \text{ dBd}\) 的天线,其增益折算成单位为 \(\text{dBi}\) 时,为 \(18.15 \text{ dBi}\) (一般忽略小数位,为 \(18\text{ dBi}\))。
(3) dB
\(\text{dB}\) 表示相对值。在计算信号\(A\)的功率\(P_A\)大于或小于信号\(B\)的功率\(P_B\)多少 \(\text{dB}\) 时,可按公式 \(10 \log_{10} \dfrac{P_A}{P_B}\) 计算。
[例5] 甲功率比乙功率大一倍,则\(10 \log_{10} \dfrac{P_{甲}}{P_{乙}} = 10 \log_{10} 2 = 3\text{ dB}\)。也就是说甲的功率比乙的功率大\(3\text{ dB}\)。
[例6] 如果信号\(A\)的功率为\(46 \text{ dBm}\),信号\(B\)的功率为\(40 \text{ dBm}\),则可以说\(A\)比\(B\)大\(6 \text{ dB}\)。
[例7] 如果\(A\)天线为\(12\text{ dBd}\),\(B\)天线为\(14 \text{ dBd}\),则可以说A比B小\(2 \text{ dB}\)。
(4) dBc
有时也会看到 \(\text{dBc}\),它也是一个表示功率相对值的单位,与 \(\text{dB}\) 的计算方法完全一样。一般来说,\(\text{dBc}\) 是相对于载波 (Carrier) 功率而言,在许多情况下,用来度量与载波功率的相对值,如用来度量干扰(同频干扰、互调干扰、交调干扰、带外干扰等)以及耦合、杂散等的相对量值。在采用 \(\text{dBc}\) 的地方,原则上也可以使用 \(\text{dB}\) 替代。
6.4.5 分贝的基本计算
\(\text{dB}\) 的意义其实再简单不过了,就是把一个很大(后面跟一长串\(0\)的)或者很小(前面有一长串\(0\)的)的数比较简短地表示出来。如(此处以功率为例):
\(\text{dB}\) 的引入是为了将乘除关系变为加减关系,更便于工程运算。因此一般来讲,在工程中 \(\text{dB}\) 之间只有加减,没有乘除。
一般来讲,在工程中,\(\text{dB}\) 和 \(\text{dB}\) 之间只有加减,没有乘除,而用得最多的是减法。
\(\text{dBm}\) 减 \(\text{dBm}\) 是两个功率相除,信号功率和噪声功率相除就是信噪比(SNR)。比如:
\(\text{dBm}\) 加 \(\text{dBm}\) 实际上是两个功率相乘,没有实际的物理意义。
那么 \(\text{dB}\) 可以任意相加吗?怎么相加?如\(70\text{ dB } + 60 \text{ dB }\)等于\(130 \text{ dB }\)吗?在信号处理中,如果要将两个信号的分贝相加,可以使用以下公式进行计算(以功率计算公式为例):
对于上面提到的例子,将\(70\text{ dB } + 60 \text{ dB }\),可以进行如下计算:
可以看到得到的结果为\(70.41 \text{ dB}\),记住不是\(130\text{ dB}\)。
参考链接:什么是分贝dB? - linmue-谭祥军的文章 - 知乎
参考链接:好问题:-3dB、0.707、截止频率,三者啥关系?- 芯语 - 面包板
参考链接:dB、dBm、dBc的解释说明
参考链接: 【Get深一度】信号处理(三)——3db带宽 - CSDN
参考链接: 带宽、特征频率、截止频率、-3dB什么意思 - CSDN
参考链接:分贝(dB)的概念辨析- CSDN
参考链接:增益比值 dB 以及 dBw-dBmv 等之详解 - 乐鑫科技
6.5 自由度(Degrees of Freedom, DoF)
6.5.1 统计中的自由度
在传统的统计学中,自由度原本的意思是一个随机向量中能够发生变化的分量的维度数量,例如:如果一个向量\(\boldsymbol x \in \mathbb{R}^n\)中有\(p\)个分量可以自由发生变化,那这个向量\(\boldsymbol x\)的自由度为\(p\)。下面结合一个简单的例子理解。
考虑以下情况中进行线性回归拟合模型:\(\boldsymbol y \in \mathbb{R}^n, \boldsymbol X \in \mathbb{R}^{n \times p}\)且\(\boldsymbol X\)是列满秩的,则利用拟合模型所得的预测结果\(\hat{\boldsymbol y} = \boldsymbol X \hat{\beta}\)即为\(\boldsymbol y\)在\(\boldsymbol X\)的\(p\)维列空间上的正交投影,而其残差\(\boldsymbol r = \boldsymbol y - \hat{\boldsymbol y}\)即为\(\boldsymbol y\)在\(\boldsymbol X\)的\(p\)维列空间的正交补上的投影,维度为\(n-p\)。则我们可以说这个线性模型的自由度(DoF)或模型自由度为\(p\)、而其残差自由度为\(n-p\)。
对于残差自由度而言,顾名思义,如果用\(\sigma^2\)来表示误差的方差的话,那残差\(\boldsymbol r\)实际上在\(p\)个方向上的投影均为0、而在剩余的\(n-p\)个方向上自由的变化。
6.5.2 矩阵自由度
(一) 自由度概念再解释
下面是两个比较好理解的自由度定义:
- 自由度是\(n\)个变量在某个(些)约束下,能够自由变化的最多变量个数\(m\)为该约束下的自由度;
- 自由度是用约束式求解矩阵所需要的最少个数。
维基百科的解释:数学上,自由度是一个随机向量的维度数,也就是一个向量能被完整描述所需的最少单位向量数。举例来说,从电脑屏幕到厨房的位移能够用三维向量\(a\boldsymbol i + b\boldsymbol j + c\boldsymbol k\)来描述,因此这个位移向量的自由度是3。自由度也通常与这些向量的坐标平方和,以及卡方分布中的参数有所关联。
再来看两个例子:
若存在2个变量\(a\)和\(b\),而\(a+b=6\),那么他的自由度为1。因为其实只有\(a\)才能真正的自由变化,\(b\)会被\(a\)选值的不同所限制。在这个例子中\(a+b=6\)就是约束,可以自由变化的变量最多个数为1。所以自由度为1;
对于一个二维旋转矩阵, \(\boldsymbol{M}_{\mathrm{rot2d}}=\left(\begin{array}{cc} \cos \theta & -\sin \theta \\ \sin \theta \sigma_Y & \cos \theta \end{array}\right)\),虽然这个\(2\times 2\)的矩阵有四个变量,但是一旦其中的一个值确定了,其他三个值就确定了。比如说当知道\((0, 0)\)位置下的 \(\cos \theta = 1\),那么则有\(\sin\theta = 0\),不会等于其他数字。所以在二维旋转矩阵这个约束下,可以自由变化的最多变量个数为1,矩阵自由度为1。用几何的方式来思考也很好理解,在一个二维平面下的旋转,只有一个变量就是旋转角度\(\theta\)值。
(二) 矩阵自由度
可以依据上文对自由度的解释应用到矩阵中。比如一个\(3 \times 3\)的矩阵,具有9个元素,那么它的自由度最高就是9。但是9个元素可能由几个变量通过一定方式组合而成,比如旋转矩阵,只有\(\alpha,\beta,\gamma\)三个旋转变量,通过三角函数组成了旋转矩阵,自由度只有3而不是9。
以下是一个Stack Overflow上的回答,以下是翻译,也可以增加对矩阵自由度的理解:
有几种方式来思考矩阵的自由度:
-
考虑一个\(m \times n\)的矩阵。这个矩阵有\(mn\)个元素/变量。在没有任何约束条件下,我们可以任意改变\(mn\)个数值来构造出\(mn\)个互相不同的矩阵,所以它有\(mn\)个自由度。
-
一个上三角矩阵,维度是\(m \times m\),我们知道在这个矩阵里很多值都是0,实际上只有\(m+(m-1)+ \cdots +2+1\)个非0元素/变量,所以这个值就是上三角矩阵的自由度。
-
一个\(2 \times 2\)的旋转矩阵,自由度等于多少?这对矩阵中可能的值施加了巨大的限制。确实,一旦其中一个值确定了之后,其他的所有值都被确定了。这个旋转矩阵只有一个自由度。
-
如果我们“equivalence classes”即“等价类”呢?如果我们知道任意矩阵的所有缩放都是相等的呢?我们还剩多少个自由度?对于任意矩阵,当位置\((1,1)\)上的元素非0,我们就可以对矩阵的所有元素除以这个元素,这时\((1,1)\)上的元素就等于1。现在考虑有两个矩阵\(\boldsymbol A\)和\(\boldsymbol B = 2\boldsymbol A\),当我们缩放这两个矩阵使得它们的第一个元素为1,我们会发现这两个矩阵是等价的。因此,我们消除了一个自由度。这就是单应(矩阵)的例子。所以,对于一个\(3\times 3\)的单应矩阵,只有8个自由度。这些自由度也可以用几何的方式来解释。
|
\(n\)阶方阵的秩等于\(r\),也就是等价于它的列/行秩等于\(r\),因此,为了构造一个秩为\(r\)的方阵,可以先选\(r\)个线性无关的\(n\)维向量作为它的列/行向量,这就有\(n \times r\)的自由度,另外剩下的\(n-r\)个列/行向量必须能用已选定的\(r\)个列/行向量线性表出,也就是它们要分别能写成已选定的\(r\)个列/行向量的线性组合,每一个线性组合有\(r\)个系数,也就是有\(r\)个自由度,\(n-r\)个向量就有\((n-r)\times r\)个自由度,这样这个矩阵就能被确定下来了,所以一共的自由度是: \[n \times r + (n-r) \times r = (2n-r) \times r
\] 而且这个结论可以推广到非方阵的情形. |
6.5.3 方程自由度
自由度是指变量比方程多的情况。如果有10个变量和7个方程就有3个自由度。也就是说,其中3个变量可以假设你想要的任何值,对于这3个变量的任何给定值,剩下的7个变量都有一个特定的解。
也就是说,方程的数量+自由度总是会给出你有多少变量。
如果方程的数量大于变量的数量你就没有任何自由度方程组通常是完全不可解的。
如果你有自由度,你通常需要找到一些额外的约束来添加额外的方程。它的思想是让方程和变量的数量完全相同在这种情况下只有一个解。这是在方程是线性无关的假设下。在计算自由度之前,你必须先去掉所有线性相关的方程。
例如,\(2x + 3y = 5\)和\(4x + 6y = 10\)是两个方程,但它们不是线性独立的,所以当你去掉一个,你看到只有一个方程有两个变量,所以你有一个方程和一个自由度。
参考链接1:漫谈统计学习-自由度(DoF) - Chunxi Huang的文章 - 知乎
参考链接2:关于矩阵的自由度DOF的理解 - LYF0816LYF的文章 - CSDN
参考链接3:矩阵、方程自由度的理解 - 迪迦谁占了的文章 - CSDN
6.6 信号子带划分
子带技术的基本思想是利用分析滤波器组,将待处理的全带信号划分为子带信号,从而将相应的信号处理转移至子带域,最后再利用综合滤波器组将处理后的子带信号进行重构得到输出信号。将输入信号划分为多个子带信号,这种结构可以更有效地对信号进行处理,并且能够降低复杂度以及减少自适应滤波器的阶数。
6.7 信号去相关
雷达到目标的不同散射体之间的相对路径长度就会发生变化,导致每个脉冲的回波相位发生变化,合成回波的幅度也发生波动,这就是去相关现象。对于刚体目标,RCS的去相关现象主要是由距离和视角变化引起的。而对于非刚体目标,比如地面灌木丛、草地、树木、海面、海浪等,除了与距离和视角变化有关外,还与目标本身的特性有关,如目标内部发生运动等。
相干雷达高度表与目标之间存在相对运动或者目标为非刚体目标,则会出现去相关现象,也就是信号相位并非一致,这样使得回波幅度不能相干积累。
6.8 Capon谱/最小方差谱估计(MVDR算法)
最小方差谱估计方法(MVDR)也称作Capon方法,其基本思想是设计与输入数据相关的带通滤波器组的过程。Capon方法应用一个带通滤波器来计算一个估计的谱值。为了得到统计稳定的谱估计值,需要将原始样本分成子序列进行处理,并将每一个子序列所获得的结果取平均值。
Capon算法又被称为最小方差无偏估计算法(MVDR),是一种空间谱估计算法,通过对接收到的信号进行处理,实现信号源的空间定位。它是基于波束成型技术发展而来,具有很高的方向性和性能可靠性,广泛应用于雷达、通信、声学等领域中。
对一个长度为\(m\)的有限长脉冲响应滤波器\(\boldsymbol h = [h_0, h_1, h_2, \cdots, h_m]^{\mathrm T}\),当输入原始数据序列\(\{x(t)\}\)时,滤波器在\(t\)时刻的输出为:
则滤波器输出的功率表示为:
式中\(\boldsymbol R\)表示数据矢量的协方差矩阵。
滤波器\(\boldsymbol h\)对频率为\(\omega\)的正弦分量的响应为:
式中\(\boldsymbol a(\omega) = [1, \mathrm e^{-\mathrm j \omega}, \cdots, \mathrm e^{-\mathrm j m \omega}]^{\mathrm T}\)。
如果想使滤波器对于当前值\(\omega\)周围的频带具有良好的选择性,则可以考虑最小化滤波器输出噪声均方值,其约束条件为滤波器使频率\(\omega\)无失真地通过,即:
由拉格朗日乘子法可以解得滤波器响应为:
代入可求得滤波器的输出功率为:
因此信号在通带的中心频率处的功率谱密度估计式为:
式中\(\beta\)为带通滤波器的频率带宽。由于带通滤波器的设计是依赖于数据的,所以\(\beta\)未必是与数据独立的,也未必是与频率独立的,因此并不能简单地被当作一个缩放比例。
最简单的一种可能性是\(\beta = \dfrac{1}{m+1}\),这是由时间带宽积决定的。而关于\(\beta\)的一个更加精确的表达式可以如下获得:一人带通滤波器的(等效)带宽可以被定义为中心为\(W\)的矩形脉宽,在滤波器的频率响应中,其集中了信号的全部能量。根据此定义,可以假定\(\beta\)满足:
在当前情况下,\(H(w)= 1\),因此可以得到:
上式中二次型中矩阵的第\((k, p)\)个元素由下式给出:
则有:
这里\(\beta\)的表达式是基于这样的假设,即曲线\(|H(\psi)|^2 = |\boldsymbol h^{\mathrm H} \boldsymbol a(\psi)|^2, \psi \in [-\pi, \pi]\)下的绝大多数区域都位于中心频率\(\omega\)的周围。
在上面的推导中,假定可以获得真实的数据协方差矩阵\(\boldsymbol R\)。为了在实际中应用,必须用样本估计值代替公式中的\(\boldsymbol R\)。例如应用:
则根据不同的\(\beta\),得到下列两种Capon谱估计器,分别为:
为了使\(\hat{\boldsymbol R}^{-1}\)存在,要求\(m < \dfrac{N}{2}\),其确定了Capon方法所能达到的分辨率极限。当\(m\)减小时,Capon方法的分辨率将会变差,但是方的估计精确性会得以提高。
参考链接1:关于Capon最优加权系数和MVDR加权系数等价的证明 - CSDN
参考链接2:Capon波束形成器推导和仿真 - CSDN
参考链接3:第五章功率谱估计第5节 - 百度文库
参考链接4:阵列信号的(空间谱)DOA估计概述 - 芯语 - 面包板
参考链接5:阵列信号DOA估计系列(一).概述 - CSDN

 浙公网安备 33010602011771号
浙公网安备 33010602011771号