10 对偶问题及强弱对偶定理
10.1 对偶问题的提出
10.2 对偶问题的构造
考虑如下约束问题\((P)\):
\[\begin{array}{cl}
\min & f(\boldsymbol x) \\
\text{s.t.} & g_{i}(\boldsymbol x) \leq 0 \quad i=1, \ldots, m \\
& h_{i}(\boldsymbol x)=0 \quad i=1, \ldots, l \\
& \boldsymbol x \in \boldsymbol X
\end{array}
\]
和前面的约束优化相比,原问题\((P)\)多了一条集合约束\(\boldsymbol x \in \boldsymbol X\),若集合\(\boldsymbol X = \mathbb{R}^n\),则和前面讨论的约束问题是一样的。除此以外,\(\boldsymbol X\)还可以是\(\boldsymbol Z^n\)、\(\boldsymbol Z_+^n\)或\(\{0, 1\}\)等等。
对应的对偶问题\((D)\)的构造,本节考虑的是Lagrange对偶问题,Lagrange对偶问题的构造分三步走
\[L(\boldsymbol x, \boldsymbol \lambda, \boldsymbol \mu) = f(\boldsymbol x) + \sum_{i=1}^m \lambda_i g_i(\boldsymbol x) + \sum_{i=1}^l \mu_1 h_i(\boldsymbol x)
\]
\[d(\boldsymbol \lambda, \boldsymbol \mu) = \min\limits_{\boldsymbol x \in \boldsymbol X} \{f(\boldsymbol x) + \sum_{i=1}^m \lambda_i g_i(\boldsymbol x) + \sum_{i=1}^l \mu_i h_i(\boldsymbol x) \}
\]
\[\begin{array}{cl}
\max & d(\boldsymbol \lambda, \boldsymbol \mu) \\
\text{s.t.} & \lambda_i \leq 0 \quad i=1, \ldots, m
\end{array}
\]
10.3 原问题和对偶问题的关系
对偶问题\((D)\)可以写为:
\[\max\limits_{\boldsymbol \lambda > \boldsymbol 0, \boldsymbol \mu} \text{ } \min\limits_{\boldsymbol x \in \boldsymbol X} L(\boldsymbol x, \boldsymbol \lambda, \boldsymbol \mu)
\]
即对偶问题可以先看做是对Lagrange函数中的\(\boldsymbol x\)求最小,再对\(\boldsymbol \lambda, \boldsymbol \mu\)求最大。
对上式换一种形式:
\[\min\limits_{\boldsymbol x \in \boldsymbol X}\text{ } \max\limits_{\boldsymbol \lambda > \boldsymbol 0, \boldsymbol \mu} L(\boldsymbol x, \boldsymbol \lambda, \boldsymbol \mu)
\]
做一个简单的分析
\[\begin{aligned}
\max_{\boldsymbol \lambda \geq \boldsymbol 0, \boldsymbol \mu} L(\boldsymbol x, \boldsymbol \lambda, \boldsymbol \mu) &=\max \left\{f(\boldsymbol x)+\sum_{i=1}^{m} \lambda_{i} g_{i}(\boldsymbol x)+\sum_{i=1}^{l} \mu_{i} h_{i}(\boldsymbol x)\right\} \\
&= \begin{cases}f(\boldsymbol x) & g_{i}(\boldsymbol x) \leq 0, h_{j}(\boldsymbol x)=0, i=1, \ldots, m, j=1, \ldots, l \\
+\infty & \text { others }\end{cases}
\end{aligned}
\]
求最大值是很容易求到\(+\infty\),若\(h_i(\boldsymbol x) \neq 0\),因为\(\boldsymbol \mu\)无符号要求,则\(\sum_{i=1}^{l} \mu_{i} h_{i}(\boldsymbol x)\)将可能取到\(+\infty\);若\(g_{i}(\boldsymbol x) \geq 0\),同理可得\(\sum_{i=1}^{m} \lambda_{i} g_{i}(\boldsymbol x)\)将可能取到\(+\infty\)。
- 如果不想取到\(+\infty\),则\(g_{i}(\boldsymbol x) \leq 0, h_{j}(\boldsymbol x)=0 \quad i=1, \ldots, m, j=1, \ldots, l\);
- 若要取到最大,则\(g_{i}(\boldsymbol x) = 0, i=1, \ldots, m\),\(\max\limits_{\boldsymbol \lambda \geq \boldsymbol 0, \boldsymbol u} L(\boldsymbol x, \boldsymbol \lambda, \boldsymbol \mu) = f(\boldsymbol x)\)。
对\(\max\limits_{\boldsymbol \lambda \geq \boldsymbol 0, \boldsymbol u} L(\boldsymbol x, \boldsymbol \lambda, \boldsymbol \mu) = f(\boldsymbol x)\)求最小值时,\(+\infty\)将毫无意义,因此有:
\[\min\limits_{\boldsymbol x \in \boldsymbol X}\text{ } \max\limits_{\boldsymbol \lambda > \boldsymbol 0, \boldsymbol \mu} L(\boldsymbol x, \boldsymbol \lambda, \boldsymbol \mu) = \min\limits_{\boldsymbol x \in \boldsymbol X}\text{ } f(\boldsymbol x)
\]
在约束条件\(g_{i}(\boldsymbol x) \leq 0, h_{j}(\boldsymbol x)=0 \quad i=1, \ldots, m, j=1, \ldots, l\)下,整理即可得:
\[\begin{array}{cl}
\min & f(\boldsymbol x) \\
\text{s.t.} & g_{i}(\boldsymbol x) \leq 0 \quad i=1, \ldots, m \\
& h_{i}(\boldsymbol x)=0 \quad i=1, \ldots, l \\
& \boldsymbol x \in \boldsymbol X
\end{array}
\]
又回到了原问题\((P)\),因此对偶问题\((D)\):
\[\max\limits_{\boldsymbol \lambda > \boldsymbol 0, \boldsymbol \mu} \text{ } \min\limits_{\boldsymbol x \in \boldsymbol X} L(\boldsymbol x, \boldsymbol \lambda, \boldsymbol \mu)
\]
交换下求最值的顺序即可得到原问题\((P)\):
\[\min\limits_{\boldsymbol x \in \boldsymbol X}\text{ } \max\limits_{\boldsymbol \lambda > \boldsymbol 0, \boldsymbol \mu} L(\boldsymbol x, \boldsymbol \lambda, \boldsymbol \mu)
\]
因此原问题可以看做是对Lagrange函数先对\(\boldsymbol \lambda, \boldsymbol \mu\)求最大,在对\(\boldsymbol x\)求最小。对偶问题是先对\(\boldsymbol x\)求最小,再对\(\boldsymbol \lambda, \boldsymbol \mu\)求最大。
10.4 对偶间隙【对偶间隔】
原问题\((P)\)的最优值\(v(P)\)和对偶问题\((D)\)的最优值\(v(D)\)的差,即\(v(P) - v(D)\)。
10.5 弱对偶定理
10.5.1 弱对偶定理的描述及证明
设\(v(P)\)是原问题\((P)\)的最优值,\(v(D)\)是对偶问题\(v(D)\)的最优值,则\(v(D) \leq v(P)\),即对偶间隙\(v(P) - v(D) \geq 0\)
弱对偶定理是天然成立的,由构造对偶问题的过程决定。
定理的证明:
记原问题\((P)\)的可行集\(\boldsymbol S\)为:
\[\boldsymbol S = \{\boldsymbol x \in \boldsymbol X \mid g_i(\boldsymbol x) \leq 0, i = 1, \cdots, m; h_{i}(\boldsymbol x) = 0, i = 1, \cdots, l \}
\]
可以得到:
\[\boldsymbol S \subseteq \boldsymbol X
\]
因此:
\[d(\boldsymbol \lambda, \boldsymbol \mu) = \min\limits_{\boldsymbol x \in \boldsymbol X} \{ f(\boldsymbol x)+ \sum_{i=1}^m \lambda_i g_i(\boldsymbol x) + \sum_{i=1}^l \mu_i h_i(\boldsymbol x) \} \leq \min_{\boldsymbol x \in \boldsymbol S} \{ f(\boldsymbol x)+ \sum_{i=1}^m \lambda_i g_i(\boldsymbol x) + \sum_{i=1}^l \mu_i h_i(\boldsymbol x) \}
\]
因为\(h_i(\boldsymbol x) = 0\),因此\(\sum\limits_{i=1}^l \mu_i h_i(\boldsymbol x) = 0\);因为\(\lambda_i \geq 0, g_i(\boldsymbol x) \leq 0\),因此\(\sum\limits_{i=1}^m \lambda_i g_i(\boldsymbol x) \leq 0\),所以有:
\[\min_{\boldsymbol x \in \boldsymbol S} \{ f(\boldsymbol x)+ \sum_{i=1}^m \lambda_i g_i(\boldsymbol x) + \sum_{i=1}^l \mu_i h_i(\boldsymbol x) \} \leq \min_{\boldsymbol x \in \boldsymbol S} \{ f(\boldsymbol x) \}
\]
即,\(\forall \boldsymbol \lambda \geq \boldsymbol 0, \boldsymbol \mu\),有:
\[d(\boldsymbol \lambda, \boldsymbol \mu) \leq \min_{\boldsymbol x \in \boldsymbol S} \{f(\boldsymbol x)\}
\]
因此:
\[\max_{\boldsymbol \lambda \geq \boldsymbol 0, \boldsymbol \mu} d(\boldsymbol \lambda, \boldsymbol \mu) \leq \min_{\boldsymbol x \in \boldsymbol S}\{f(\boldsymbol x)\}
\]
即:\(v(D) \leq v(P)\)。由证明过程也可以得出不等式:
\[d(\boldsymbol \lambda, \boldsymbol \mu) \leq v(D) \leq v(P) \leq f(\boldsymbol x)
\]
10.5.2 弱对偶定理的推论
(一) 推论一
假设\(\bar{\boldsymbol x} \in \boldsymbol S\),\((\bar{\boldsymbol \lambda}, \bar{\boldsymbol \mu})\),且\(d(\bar{\boldsymbol \lambda}, \bar{\boldsymbol \mu}) = f(\bar{\boldsymbol x})\),则\(v(P) = v(D)\),且\(\bar{\boldsymbol x}, (\bar{\boldsymbol \lambda}, \bar{\boldsymbol \mu})\)是问题\((P)\)和\((D)\)的最优解。
证明:
\[d(\bar{\boldsymbol \lambda}, \bar{\boldsymbol \mu}) \leq v(D) \leq f(\bar{\boldsymbol x}) \quad \Longrightarrow \quad d(\bar{\boldsymbol \lambda}, \bar{\boldsymbol \mu}) = v(D) = f(\bar{\boldsymbol x})
\]
\[d(\bar{\boldsymbol \lambda}, \bar{\boldsymbol \mu}) \leq v(P) \leq f(\bar{\boldsymbol x}) \quad \Longrightarrow \quad d(\bar{\boldsymbol \lambda}, \bar{\boldsymbol \mu}) = v(P) = f(\bar{\boldsymbol x})
\]
因此\(v(P) = v(D)\)。
(二) 推论二
若\(v(P) = -\infty\),则\(d(\boldsymbol \lambda, \boldsymbol \mu) = -\infty, \forall (\boldsymbol \lambda, \boldsymbol \mu), \boldsymbol \lambda \geq \boldsymbol 0\);
若\(v(D) = +\infty\),则\(v(P) = +\infty, \forall (\boldsymbol \lambda, \boldsymbol \mu), \boldsymbol \lambda \geq \boldsymbol 0\),同时原问题无解。
10.6 强对偶定理
先给出结论,强对偶定理即\(v(D) = v(P)\),也即对偶间隙\(v(D) - v(P) = 0\),但是强对偶定理不同于弱对偶定理,强对偶定理不是天然成立的,而是有条件的!
10.6.1 几何解释
考虑简单的原问题\((P)\):
\[\begin{array}{cl}
\min & f(\boldsymbol x) \\
\text{s.t.} & g(\boldsymbol x) \leq 0 \\
& \boldsymbol x \in \boldsymbol X
\end{array}
\]
构造对应的对偶问题\((D)\):
\[L(\boldsymbol x, \lambda) = f(\boldsymbol x) + \lambda g(\boldsymbol x)
\]
\[d(\lambda) = \min_{\boldsymbol x \in \boldsymbol X} \{f(\boldsymbol x) + \lambda g(\boldsymbol x) \}
\]
\[\max_{\lambda \geq 0} d(\lambda)
\]
记:
\[G=\left\{\left(\begin{array}{l}
y \\
z
\end{array}\right) \bigg| \begin{array}{l}
g(\boldsymbol x)=y \\
f(\boldsymbol x)=z
\end{array}, \boldsymbol x \in \boldsymbol X\right\}
\]
则将\(n\)维空间中的\(\boldsymbol X\)映射到了二维空间,将更容易做几何解释。因此原问题\((P)\)变为:
\[\begin{aligned}
&\min \quad z \\
&\text { s.t } \quad y \leq 0 \\
&\left(\begin{array}{l}
y \\
z
\end{array}\right) \in \boldsymbol G
\end{aligned}
\]
对偶问题\((D)\)变为:
\[\max_{\lambda \geq 0} d(\lambda)
\]
其中,\(d(\lambda) = \min \{z + \lambda y\}, \quad \left(\begin{array}{l} y \\ z \end{array}\right)\),作图分析:
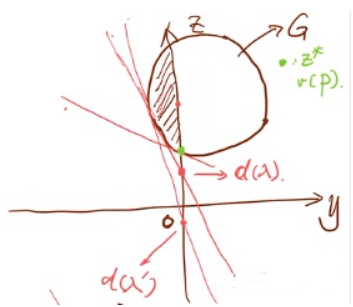
如果\(\boldsymbol G\)区域是一个圆形(凸集),则\(v(P) = v(D)\),但如果\(\boldsymbol G\)区域不是一个圆形,如下图:
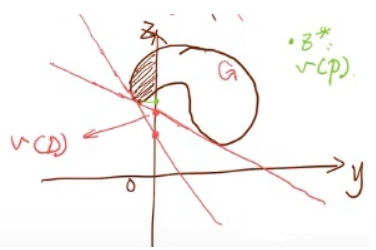
则\(v(P) \geq v(D)\),因此由图形很容易猜测,若区域\(\boldsymbol G\)是凸集,则\(v(P) = v(D)\)。但实际上的强对偶理论要比凸集来得复杂的多,
10.6.2 强对偶定理的描述及证明
(一) 强对偶定理的描述
集合\(\boldsymbol X\)为非空凸集,\(f(\boldsymbol x)\)和\(g_i(\boldsymbol x), i = 1, \cdots, m\)是凸函数,\(h_i(\boldsymbol x), i = 1, \cdots, l\)均为线性函数;
存在\(\hat{\boldsymbol x} \in \boldsymbol X\)使得:
\[g_i(\hat{\boldsymbol x}) < 0, i = 1, \cdots, m; \quad h_i(\hat{\boldsymbol x}) = 0, i = 1, \cdots, l
\]
且\(0 \in \text{int } h(\boldsymbol X)\),其中\(h(\boldsymbol X) = \{h_1(\boldsymbol x), \cdots, h_l(\boldsymbol x) \mid \boldsymbol x \in \boldsymbol X\}\)
则强对偶成立:
\[\min \{f(\boldsymbol x) \mid \boldsymbol x \in \boldsymbol S \} = \max \{d(\boldsymbol \lambda, \boldsymbol \mu) \mid \boldsymbol \lambda \geq \boldsymbol 0, \boldsymbol \mu\} \Longleftrightarrow v(P) = v(D)
\]
(二) 定理中条件的说明
要求原问题\((P)\)是凸问题;
存在\(\boldsymbol X\)中的一点\(\hat{\boldsymbol x}\)使得\(g_i(\boldsymbol x)\)严格小于\(0\),即在画出的\(\boldsymbol G\)区域中存在一点在\(z\)轴的左边,结合图像很容易就能理解,如果这个条件不成立的话,将找不到最优解,结合图像进行理解:

集合图像理解很容易可以得出找不到最优解的结论
定理的证明(TODO):需要利用凸集的性质,目前这块学的不好,待补充。
本小节参考资料:
【1】如何通俗地讲解对偶问题?尤其是拉格朗日对偶lagrangian duality? - 李竞宜的回答 - 知乎
【2】拉格朗日乘子的几何解释
10.7 对偶问题的性质及求解办法
10.7.1 对偶问题的性质
(一) 对偶函数一定是凹函数
证明过程:为什么拉格朗日对偶函数一定是凹函数;该博客介绍的很详细,包括不等式如何过去,比书本要好多了。
(二) 对偶问题是凸优化问题
已知对偶函数\(d(\boldsymbol \lambda, \boldsymbol \mu)\),对偶问题\((D)\):
\[\max_{\boldsymbol \lambda \geq \boldsymbol 0, \boldsymbol \mu} \text{ } d(\boldsymbol \lambda, \boldsymbol \mu)
\]
因为对偶函数是凹函数,对凹函数求最大相当于凸函数求最小,问题等价于:
\[\min_{\boldsymbol \lambda \geq \boldsymbol 0, \boldsymbol \mu} \text{ } -d(\boldsymbol \lambda, \boldsymbol \mu)
\]
因此对偶问题是凸优化问题。
10.7.2 对偶问题的求解
(一) 特殊问题对偶问题的求解
-
如果原问题\((P)\)是线性优化问题,则其对偶问题\((D)\)仍是线性优化问题,则可以用解线性优化的办法求解对偶问题,即可以使用单纯形法和内点法;
-
如果原问题\((P)\)是凸二次规划问题,则其对偶问题\((D)\)仍是凸二次规划问题,则可以使用有效集法进行求解;
-
如果如果原问题\((P)\)是二阶锥规划问题或半定规划问题,则其对应的对偶问题分别为二阶锥规划问题、半定规划问题,可以使用内点法进行求解。
(二) 一般问题对偶函数的求解
一般形式的函数的对偶问题将无法使用上述提到的方法,对于一般函数的对偶问题的求解有专门的方法,比较常见的是
- 割平面法又称为外逼近法【cutting plane method】
- 次梯度法【subgradient method】
- bundle method
(三) 几何解释
先对问题做一个化简,记
\[g(\boldsymbol{x})=\left(\begin{array}{c}
g_{1}(\boldsymbol{x}) \\
\vdots \\
g_{m}(\boldsymbol{x})
\end{array}\right), h(\boldsymbol{x})=\left(\begin{array}{c}
h_{1}(\boldsymbol{x}) \\
\vdots \\
h_{l}(\boldsymbol{x})
\end{array}\right), \lambda=\left(\begin{array}{c}
\lambda_{1} \\
\vdots \\
\lambda_{m}
\end{array}\right), \boldsymbol{\mu}=\left(\begin{array}{c}
\mu_{1} \\
\vdots \\
\mu_{l}
\end{array}\right)
\]
则对偶问题\((D)\)可以写为:
\[\begin{cases}
\max & d(\boldsymbol \lambda, \boldsymbol \mu) \\
\text { s.t. } & \lambda_{i} \geq 0, i=1, \cdots, m
\end{cases}
\]
其中,\(d(\boldsymbol \lambda, \boldsymbol \mu) = \min\limits_{\boldsymbol x \in \boldsymbol X} \{f(\boldsymbol x) + \boldsymbol \lambda^{\mathrm{T}} g(\boldsymbol{x}) + \boldsymbol \mu^{\mathrm{T}} h(\boldsymbol{x})\}\),对偶问题的等价问题可以写为:
\[\left\{\begin{array} { l l }
\max & d (\boldsymbol \lambda , \boldsymbol \mu) \\
\text{s.t.} & \boldsymbol \lambda \geq \boldsymbol 0
\end{array}
\Leftrightarrow
\left\{\begin{array}{rl}
\max & \theta \\
\text{s.t.} & \theta \leq f(\boldsymbol x)+ \boldsymbol \lambda^{T} g(\boldsymbol x)+ \boldsymbol \mu^{T} h(\boldsymbol x), \forall \boldsymbol x \in \boldsymbol X \text{ }(*)\\
& \boldsymbol \lambda \geq \boldsymbol 0
\end{array}\right.\right.
\]
记最优解为\(\bar{\theta}\),则\(\bar{\theta} = v(D)\),现在关心的是\(\theta\)一定能求解吗。
假设\(\boldsymbol X\)有有限个点\(\boldsymbol x_1, \cdots, \boldsymbol x_N\),并且\(N\)不是特别大,则\((*)\)式变为:
\[\theta \leq f(\boldsymbol x)+ \boldsymbol \lambda^{T} g(\boldsymbol x_i)+ \boldsymbol \mu^{T} h(\boldsymbol x_i), i = 1, \cdots, N
\]
问题变为了一个线性规划问题,可以通过单纯形法或内点法进行求解,也可以借用软件cplex进行求解,但是当\(N\)非常大或\(\boldsymbol X\)有无穷多点时,\((*)\)代表的是无穷多个线性不等式,无法通过软件进行求解并且也不可能手动去算当\(N\)非常大时,这时候应该如何来求解这个问题呢。
考虑\(N = 5\)的情况,将\(\boldsymbol X\)中的5个点代入得到5条直线,\(d(\boldsymbol \lambda, \boldsymbol \mu)\)的图形如图红色所示:
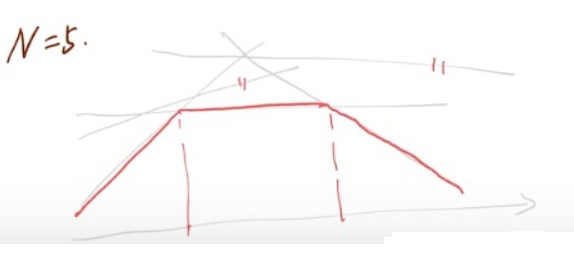
可以发现起约束作用的直线只有三条,另外两条不起作用。当\(N = 5\)时就已经有多余的直线了,那么当\(N\)非常大时,肯定也有多余的直线,并且不起约束作用的直线应该是很多的。因此一个很顺其自然的想法就是从无穷多个点中每次取一部分去试,直到试出最优解,外逼近法的算法就是基于这个思想,只不过要考虑的因素有很多,比如如何从\(\boldsymbol X\)中选取子集,算法的终止条件是什么?
还是以\(N = 5\)为例,原来的集合\(\boldsymbol X = \{\boldsymbol x_1, \boldsymbol x_2, \boldsymbol x_3, \boldsymbol x_4, \boldsymbol x_5\}\),现从\(\boldsymbol X\)中取出两点构成\(\boldsymbol X\)的子集记为\(\boldsymbol X^0\),假设取出的点为\(\boldsymbol x_1\)和\(\boldsymbol x_3\),则:
\[\boldsymbol X^0 = \{\boldsymbol X_1, \boldsymbol X_3\}
\]
因此对偶问题\((D)\)变为:
\[\begin{cases}
\max & \theta \\
\text { s.t. } & \theta \leq f(\boldsymbol x)+ \boldsymbol \lambda^{T} g(\boldsymbol x)+ \boldsymbol \mu^{T} h(\boldsymbol x), \forall \boldsymbol x \in \boldsymbol X_0 \\
& \boldsymbol \lambda \geq \boldsymbol 0
\end{cases}
\]
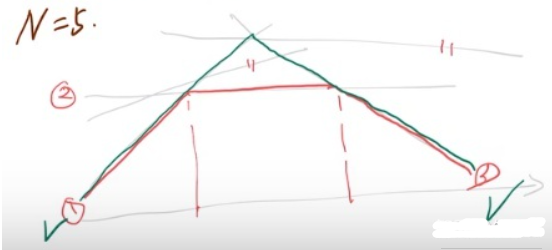
记现问题的最优解为\(\theta^0\),则\(\theta^0 \geq \bar{\theta}\),根据图像以及\(\boldsymbol X\)的范围很容易就想明白。
两个方程,两个未知量可以解出\(\boldsymbol \lambda^0\)、\(\boldsymbol \mu^0\),已知\(\boldsymbol \lambda^0\)、\(\boldsymbol \mu^0\)可以求解\(d(\boldsymbol \lambda^0, \boldsymbol \mu^0)\),即求解
\[\min_{\boldsymbol x \in \boldsymbol X^0} \{f(\boldsymbol x) + (\boldsymbol \lambda^0)^{\mathrm{T}} g(\boldsymbol x) + (\boldsymbol \mu^0)^{\mathrm{T}} h(\boldsymbol x)\}
\]
解得最优解为\(\boldsymbol x^0 \in \boldsymbol X\),算出\(d(\boldsymbol \lambda^0, \boldsymbol \mu^0)\)和\(\boldsymbol x^0\)以后,就要进行判断是否算出了最优解:
-
若\(\boldsymbol x^0\)是问题\((P)\)的可行解,即$$g(\boldsymbol x^0) \leq \boldsymbol 0, h(\boldsymbol x^0) = \boldsymbol 0$$并且\((\boldsymbol \lambda^0)^{\mathrm{T}} g(\boldsymbol x^0) = 0\),则$$f(\boldsymbol x^0) = f(\boldsymbol x^0) + \boldsymbol \lambda^{0\mathrm{T}} g(\boldsymbol x^0) + \boldsymbol \mu^{0\mathrm{T}} h(\boldsymbol x^0) = d(\boldsymbol \lambda^0, \boldsymbol \mu^0)$$则强对偶成立,\(\boldsymbol x^0\)是问题\((P)\)的最优解,\(\boldsymbol \lambda^0\)、\(\boldsymbol \mu^0\)是问题\((D)\)的最优解。因此不需要在试其他点了,一步到位,但是一般这个条件是很难达到的。
-
若\(d(\boldsymbol \lambda^0, \boldsymbol \mu^0) = \theta^0\),因为$$\bar{\theta} = v(D) \leq \theta^0$$又因为$$d(\boldsymbol \lambda^0, \boldsymbol \mu^0) \leq v(D)$$因此\(d(\boldsymbol \lambda^0, \boldsymbol \mu^0) = v(D)\),所以\((\boldsymbol \lambda^0, \boldsymbol \mu^0)\)是问题\((D)\)的最优解。
如果上面两种情况都不满足的话,说明选取的点不够好,近似效果不行,需要重新选取点。一般重新选取点是将最优解\(\boldsymbol x^0\)加入到原先的子集\(\boldsymbol X^0\)中,即新的子集为\(\boldsymbol X' := \boldsymbol X^0 \cup \boldsymbol x^0\),即比之前多了一个约束条件。选取新的子集以后在重述上面的步骤,直到上述两种情况中有一种情况发生。上述的方法就为外逼近方法。
(四) 外逼近法算法实现
前面已经图文并茂的介绍了外逼近方法,这里给出算法的具体实现思路,有了前面的讲解后将非常容易的理解
\[\begin{cases} \max & \theta \\
\text { s.t. } & \theta \leq f(\boldsymbol{x}) + \boldsymbol\lambda^{\mathrm{T}}g(\boldsymbol{x}) + \boldsymbol\mu^{\mathrm{T}}, \forall \boldsymbol x \in \boldsymbol X^k \\
& \boldsymbol{\lambda} \geq \boldsymbol 0
\end{cases}
\]
-
STEP 3:求解相应的子问题$$\min {f(\boldsymbol x) + \boldsymbol \lambda^{k\mathrm{T}} g(\boldsymbol x) + \boldsymbol \mu^{k\mathrm{T}} h(\boldsymbol x) \mid \boldsymbol x \in \boldsymbol X }$$记其最优解为\(\boldsymbol x^k\),最优值为\(d(\boldsymbol \lambda^k, \boldsymbol \mu^k)\);
-
STEP 4:
- 情况1 —— 若\(\boldsymbol x^k\)是原问题\((P)\)的可行解,且\(\boldsymbol \lambda^{k\mathrm{T}} g(\boldsymbol x^k) = 0\),则算法终止,其中\(\boldsymbol x^k\)和\((\boldsymbol \lambda^k, \boldsymbol \mu^k)\)分别是原问题\((P)\)和对偶问题\((D)\)的最优值,且最优值相等;
- 情况2 —— 若\(\theta^k = d(\boldsymbol \lambda^k, \boldsymbol \mu^k)\),则算法终止,其中\((\boldsymbol \lambda^k, \boldsymbol \mu^k)\)是对偶问题\((D)\)的最优解,最优值为\(\theta^k\),若情况1和情况2均没发生,则转STEP 5;
-
STEP 5:\(\boldsymbol X^{k+1}:=\boldsymbol X^k \cup \{\boldsymbol x^k\}, k:=k+1\),转STEP 2。
(五) 其他说明
-
\(\boldsymbol X\)的子集合\(\boldsymbol X^{1}\)必须包含\((P)\)的一个可行点,若\(\boldsymbol x \in \boldsymbol X^1\),并且\(\boldsymbol x\)是问题\((P)\)的可行点,则有:$$\theta \leq f(\boldsymbol x) + \boldsymbol \lambda^{\text{T}} g(\boldsymbol x) + \boldsymbol \mu^{\text{T}} h(\boldsymbol x) \leq f(\boldsymbol x)$$因此要求子集合包含问题\((P)\)的可行点是为了给\(\theta\)一个上界,如果\(\boldsymbol X^1\)选取不恰当,很容易得到\(+\infty\)。
-
\(\boldsymbol X\)包含无穷多点,在迭代过程中生成的子集\(\boldsymbol X^k\)去掉多余的点,提高算法效率。
算法的缺点:在最优解的位置具有不稳定性,无法判断解的最优性。
11 线性规划
11.1 线性优化研究的问题
线性优化研究的问题具有以下特点:
-
目标函数为决策变量的线性函数
-
约束条件为线性等式或线性不等式约束
11.1.1 线性优化的标准型
线性优化问题的标准型具有以下形式,记该问题为\((LP)\):
\[\begin{cases} \min & \boldsymbol c^{\text{T}} \boldsymbol x \\
\text { s.t. } & \boldsymbol{Ax = b} \\
& \boldsymbol{x} \geq \boldsymbol 0
\end{cases}
\]
其中,\(\boldsymbol c \in \mathbb{R}^n\),\(\boldsymbol A \in \mathbb{R}^{m \times n}\),\(\boldsymbol b \in \mathbb{R}^{m}\),通常来说都是假设系数矩阵\(\boldsymbol A\)行满秩,即\(\text{rank}(\boldsymbol A) = m\),行满秩即无多余约束条件,且不存在方程组无解的情况。
11.1.2 非标准型和标准型之间的转换
并非所有的线性优化问题都是标准的线性优化问题,但是只要是线性优化问题就一定可以化为标准型。
\[\max \boldsymbol d^{\text{T}} \boldsymbol x \Longleftrightarrow \min -\boldsymbol d^{\text{T}} \boldsymbol x
\]
\[\boldsymbol a_{i}^{\text{T}} \boldsymbol x \leq b_{i} \Leftrightarrow \left\{\begin{array}{l}
\boldsymbol a_{i}^{\text{T}} \boldsymbol x+s=b_{i} \\
s \geq 0
\end{array}, \boldsymbol a_{i}^{\text{T}} \boldsymbol x \geq b_{i} \Leftrightarrow \left\{\begin{array}{l}
\boldsymbol a_{i}^{\text{T}} \boldsymbol x-s=b_{i} \\
s \geq 0
\end{array}\right.\right.
\]
其中,\(s\)为松弛变量。
\[x_i = x_i^+ - x_i^-, \quad x_i^+ \geq 0, x_i^- \geq 0
\]
11.2 可行集与多面体的性质
11.2.1 可行集
线性优化的可行集:
\[\boldsymbol S = \{ \boldsymbol x \mid \boldsymbol{Ax = b}, \boldsymbol x \geq \boldsymbol 0 \}
\]
并且可行集是一个多面体。
11.2.2 多面体的性质
-
极点(extreme point):给出凸集\(\boldsymbol C\),若\(\boldsymbol x \in \boldsymbol C\)不能表示成\(\boldsymbol C\)中另外两点的凸组合,则称\(\boldsymbol x\)为\(\boldsymbol C\)的极点。
-
方向(recession direction):给出凸集\(\boldsymbol C\),若非零向量\(\boldsymbol d\)满足对于任意的\(\boldsymbol x \in \boldsymbol C\)均有\(\boldsymbol x + \lambda \boldsymbol d \in \boldsymbol C, \forall \lambda > 0\),则称\(\boldsymbol d\)为集合\(\boldsymbol C\)的方向。
-
极方向(extreme direction):若方向\(\boldsymbol d\)不能表示成另外两个方向的正线性组合,即不存在\(\lambda_1 > 0 , \lambda_2 > 0\),使得\(\boldsymbol d = \lambda_1 \boldsymbol d_1 + \lambda_2 \boldsymbol d_2\),则称\(\boldsymbol d\)为\(\boldsymbol C\)的极方向。
11.3 极点的刻画
11.3.1 定理
考虑多面体\(\boldsymbol S = \{ \boldsymbol x \mid \boldsymbol{Ax = b}, \boldsymbol x \geq \boldsymbol 0 \}\),这里假设\(\boldsymbol A \in \mathbb{R}^{m \times n}\)行满秩,\(\boldsymbol x \in \boldsymbol S\)是\(\boldsymbol S\)的极点,当且仅当\(\boldsymbol x\)可以表示为\(\left(\begin{array}{cc} \boldsymbol B^{-1} \boldsymbol b \\ \boldsymbol 0 \end{array}\right)\),其中\(\boldsymbol A = (\boldsymbol B, \boldsymbol N)\),\(\boldsymbol B\)可逆且\(\boldsymbol B^{-1} \boldsymbol b > \boldsymbol 0\)
说明:
记\(\boldsymbol A = (\boldsymbol B, \boldsymbol N)\)是将\(\boldsymbol A\)中的列重新进行了排列,将\(\boldsymbol A\)中线性无关的列组成矩阵\(\boldsymbol B\),剩余的列组成矩阵\(\boldsymbol N\)。对\(\boldsymbol A\)进行分块以后相应的对\(\boldsymbol x\)也需要进行分块,\(\boldsymbol x\)的分块表示为\(\left(\begin{array}{cc} \boldsymbol x_B \\ \boldsymbol x_N \end{array}\right)\),因此\(\boldsymbol{Ax = b}\)可表示为
\[(\boldsymbol B, \boldsymbol N)\left(\begin{array}{cc} \boldsymbol x_B \\ \boldsymbol x_N \end{array}\right) = \boldsymbol b \Longrightarrow \boldsymbol B \boldsymbol x_B + \boldsymbol N \boldsymbol x_N = \boldsymbol b
\]
因此如果给了\(\boldsymbol x_N\)一组值,\(\boldsymbol B\)和\(\boldsymbol N\)已知,则\(\boldsymbol x_B\)的值就可以求解出来。如果想要求解一组简单的值,可以令
\[\boldsymbol x_N = \boldsymbol 0
\]
因此
\[\boldsymbol B \boldsymbol x_B = \boldsymbol b
\]
又知\(\boldsymbol B\)可逆,因此可以得到
\[\boldsymbol x_B = \boldsymbol B^{-1} \boldsymbol b
\]
可得方程的一个解为
\[\left(\begin{array}{cc} \boldsymbol x_B \\ \boldsymbol x_N \end{array}\right)
\]
后面的定理中将不再说明矩阵\(\boldsymbol A\)的分解。
11.3.2 证明
证明略,具体参考视频和转载的知乎笔记。
11.4 方向的刻画
若\(\boldsymbol d\)为方向,由前面的定义可知\(\boldsymbol x + \lambda \boldsymbol d \in \boldsymbol S\),则满足
\[\boldsymbol A(\boldsymbol x + \lambda \boldsymbol d) = \boldsymbol b\tag{11-4-1}
\]
因为\(\boldsymbol x \in \boldsymbol S\),则满足
\[\boldsymbol {Ax = b}
\]
由\((11-4-1)\)式可得
\[\boldsymbol {Ad = 0}
\]
且满足\(\boldsymbol x + \lambda \boldsymbol d \geq \boldsymbol 0\),因此\(\boldsymbol d \geq \boldsymbol 0\),否则若\(\boldsymbol d \ngeq 0\),当\(\lambda\)非常大的时候,\(\boldsymbol x + \lambda \boldsymbol d \ngeq 0\),因此\(\boldsymbol d\)是集合\(\boldsymbol S\)的方向等价为
\[\boldsymbol{Ad = 0}, \boldsymbol d \geq \boldsymbol 0
\]
11.5 极方向的刻画
11.5.1 定理
考虑多面体\(\boldsymbol S = \{\boldsymbol x \mid \boldsymbol{Ax = b}, \boldsymbol x \geq \boldsymbol 0 \}\),这里假设\(\boldsymbol A \in \mathbb{R}^{m \times n}\)行满秩,\(\boldsymbol d \in \mathbb{R}^n\)是\(\boldsymbol S\)的极方向当且仅当存在矩阵\(\boldsymbol A\)的分解\(\boldsymbol A = (\boldsymbol B, \boldsymbol N)\),使得
\[\boldsymbol d = t \left(\begin{array}{cc} -\boldsymbol B^{-1} \boldsymbol a_j \\ \boldsymbol e_j \end{array}\right)
\]
其中,\(t > 0, \boldsymbol B^{-1} \boldsymbol a_j \leq \boldsymbol 0\),\(\boldsymbol a_j\)为矩阵\(N\)的第\(j\)列,\(\boldsymbol e_j \in \mathbb{R}^{n-m}\)的第\(j\)个分量为1,其余分量为0的向量,且极方向有限多个。
说明:\(t > 0, \boldsymbol B^{-1} \boldsymbol a_j \leq \boldsymbol 0\),即\(\boldsymbol d > \boldsymbol 0\)。
11.5.2 证明
略,具体证明过程请参考视频和转载笔记。
11.6 可行集的其他表示
可行集的表示除了\(\boldsymbol S = \{ \boldsymbol x \mid \boldsymbol{Ax = b}, \boldsymbol x \geq \boldsymbol 0 \}\)还有另外的方式。假设\(\boldsymbol S\)的极点为\(\boldsymbol x_1, \cdots, \boldsymbol x_k\),极方向为\(\boldsymbol d_1, \cdots, \boldsymbol d_l\),则\(\boldsymbol x \in \boldsymbol S\)当且仅当\(\boldsymbol x\)具有如下形式
\[\boldsymbol x = \sum_{i = 1}^k \lambda_i \boldsymbol x_i + \sum_{j = 1}^l \mu_j \boldsymbol d_j
\]
其中\(\sum_{i=1}^k \lambda_i = 1, \lambda_i \geq 0, i=1, \cdots, k, \mu_j \geq 0, j = 1, \cdots, l\)
即可行集中的点可以表示为极点的凸组合加极方向的非负组合,这个定理结合图形很容易理解,这里暂时不做证明。
11.7 单纯形法
因为可行集有另外一种表示,因此问题\((LP)\)可以等价为:
\[\begin{cases}
\min & \boldsymbol c^{\text{T}}\left(\sum\limits_{i=1}^{k} \lambda_{i} \boldsymbol x_{i}+\sum\limits_{j=1}^{l} \mu_{j} \boldsymbol d_{j}\right) \\
\text { s.t } & \sum\limits_{i=1}^{k} \lambda_{i}=1, \lambda_{i} \geq 0, i=1, \ldots, k, \mu_{j} \geq 0, j=1, \ldots, l
\end{cases}
\]
即
\[\begin{cases}
\min & \boldsymbol c^{\text{T}}\left(\sum\limits_{i=1}^{k} \lambda_{i} \boldsymbol x_{i} \right) + \boldsymbol c^{\text{T}} \left(\sum\limits_{j=1}^{l} \mu_{j} \boldsymbol d_{j}\right) \\
\text { s.t } & \sum\limits_{i=1}^{k} \lambda_{i}=1, \lambda_{i} \geq 0, i=1, \ldots, k, \mu_{j} \geq 0, j=1, \ldots, l
\end{cases}
\]
当选取了极点和极方向以后,问题就转换为了关于\(\lambda_i, \mu_i\)的线性问题了。
-
若存在某个\(j\)使得\(\boldsymbol c^{\text{T}} \boldsymbol d_j < 0\),因为\(\mu_j\)可以取任意大,因此\(v(LP) = -\infty\);
-
若\(\boldsymbol c^{\text{T}} \boldsymbol d_j < 0\),因为\(\mu_j\)可以取任意大,因此要使得目标函数最小,则\(\mu_j = 0\),问题转换为
\[\begin{cases}
\min & \boldsymbol c^{\text{T}}\left(\sum\limits_{i=1}^{k} \lambda_{i} \boldsymbol x_{i} \right) + \boldsymbol c^{\text{T}} \left(\sum\limits_{j=1}^{l} \mu_{j} \boldsymbol d_{j}\right) \\
\text { s.t } & \sum\limits_{i=1}^{k} \lambda_{i}=1, \lambda_{i} \geq 0, i=1, \ldots, k, \mu_{j} \geq 0, j=1, \ldots, l
\end{cases}
\]
\[\Updownarrow
\]
\[\min_{i=1,\cdots,k} \boldsymbol c^{\text{T}} \boldsymbol x_i
\]
因此最小值在极点处取到;即线性优化问题\((LP)\)有最优解,当且仅当\(\boldsymbol c^{\text{T}} \boldsymbol d_j \geq 0, j = 1,\cdots,l\),并且若有最优解,则必在某个极点取到。
如果极点非常多,一个一个将极点带进去进行比较求最小,时间成本将非常高,因此就有了单纯形法。单纯形法的基本思想是找到找到一个极点\(\bar{\boldsymbol x}\),判断极点\(\bar{\boldsymbol x}\)是否为最优解,若\(\bar{\boldsymbol x}\)不是,则寻找一个更优的极点,避免遍历所有的极点。因此问题的关键是如何判断当前极点是否为最优解,如果不是,如何选取更优的极点。
11.7.1 如何判断最优解
取\(\boldsymbol x \in \boldsymbol S\),对\(\boldsymbol A\)做了一个相应的分块以后, 对\(\boldsymbol x\)和\(\boldsymbol c\)也做一个相应的分块
\[\boldsymbol x = \left(\begin{array}{c} \boldsymbol x_B \\ \boldsymbol x_N \end{array}\right), \quad \boldsymbol c = \left(\begin{array}{c} \boldsymbol c_B \\ \boldsymbol c_N \end{array}\right)
\]
因此\(\boldsymbol{Ax = b}\)即:
\[(\boldsymbol B, \boldsymbol N) \left(\begin{array}{c} \boldsymbol x_B \\ \boldsymbol x_N \end{array}\right) = \boldsymbol B \boldsymbol x_B + \boldsymbol N \boldsymbol x_N = \boldsymbol b
\]
解得
\[\boldsymbol x_B = \boldsymbol B^{-1} \boldsymbol b - \boldsymbol B^{-1} \boldsymbol N \boldsymbol x_N
\]
若对\(\forall \boldsymbol x \in \boldsymbol S, \boldsymbol c^{\text{T}}\boldsymbol x \geq 0\)恒成立,则\(\bar{\boldsymbol x}\)是最优解,即:
\[\begin{aligned}
\boldsymbol c^{\text{T}} \boldsymbol x-\boldsymbol c^{\text{T}} \bar{\boldsymbol x} &=\left[\begin{array}{cc}
\boldsymbol c_{B}^{\text{T}} & \boldsymbol c_{N}^{\text{T}}
\end{array}\right]\left[\begin{array}{c}
\boldsymbol x_{B} \\
\boldsymbol x_{N}
\end{array}\right]-\left[\begin{array}{cc}
\boldsymbol c_{B}^{\text{T}} & \boldsymbol c_{N}^{\text{T}}
\end{array}\right]\left[\begin{array}{c}
\boldsymbol B^{-1} \boldsymbol b \\
\boldsymbol 0
\end{array}\right] \\
&=\boldsymbol c_{B}^{\text{T}} \boldsymbol x_{B}+\boldsymbol c_{N}^{\text{T}} \boldsymbol x_{N}-\boldsymbol c_{B}^{\text{T}} \boldsymbol B^{-1} \boldsymbol b \\
&=\boldsymbol c_{B}^{\text{T}} \boldsymbol B^{-1} \boldsymbol b-\boldsymbol c_{B}^{T} \boldsymbol B^{-1} \boldsymbol N \boldsymbol x_{N}+\boldsymbol c_{N}^{\text{T}} \boldsymbol x_{N}-\boldsymbol c_{B}^{\text{T}} \boldsymbol B^{-1} \boldsymbol b \\
&=\left(\boldsymbol c_{N}^{\text{T}}-\boldsymbol c_{B}^{\text{T}} \boldsymbol B^{-1} \boldsymbol N\right) x_{N} \quad(*)
\end{aligned}
\]
因为\(\boldsymbol x_N \geq \boldsymbol 0\),因此有:
若\(\boldsymbol c_N^{\text{T}} - \boldsymbol c_B^{\text{T}} \boldsymbol B^{-1} \boldsymbol N \geq 0\),则\((*)\)式大于等于0恒成立,即\(\bar{\boldsymbol x}\)是最优解。
11.7.2 如何选取下一个极点
若\(\boldsymbol c_N^{\text{T}} - \boldsymbol c_B^{\text{T}} \boldsymbol B^{-1} \boldsymbol N \geq \boldsymbol 0\)不成立,即存在某个分量小于0,设第\(j\)个分量小于0,即\(c_j - \boldsymbol c_B^{\text{T}} \boldsymbol B a_j < 0\),记
\[\boldsymbol d_j = \left(\begin{array}{c} -\boldsymbol B^{-1} \boldsymbol a_j \\ \boldsymbol e_j \end{array}\right)
\]
则
\[\boldsymbol c^{\text{T}} \boldsymbol d_j = \left(c_B^{\text{T}}, c_N^{\text{T}} \right)\left(\begin{array}{c} -\boldsymbol B^{-1} \boldsymbol a_j \\ \boldsymbol e_j \end{array}\right) = c_j - \boldsymbol c_B^{\text{T}} \boldsymbol B^{-1} \boldsymbol a_j < 0
\]
记
\[\boldsymbol r_j = \boldsymbol B^{-1} \boldsymbol a_j
\]
如果\(\boldsymbol r_j \leq \boldsymbol 0\),则\(\boldsymbol d_j \geq 0\),由前面的定理可知\(\boldsymbol d_j\)为极方向,但是
\[\boldsymbol c^{\text{T}}(\bar{\boldsymbol x} + \lambda \boldsymbol d_j) = \boldsymbol c^{\text{T}} \bar{\boldsymbol x} + \lambda \boldsymbol c^{\text{T}} \boldsymbol d_j \to \infty
\]
优化问题无解。
如果\(\boldsymbol r_j \leq \boldsymbol 0\)不成立,则\(\boldsymbol d_j\)不为极方向,不可以沿着这个方向走任意远,需要在约束条件内走最远,即要满足
\[\bar{\boldsymbol x} + \lambda \boldsymbol d_j = \left(\begin{array}{c} \boldsymbol B^{-1} \boldsymbol b \\ \boldsymbol 0 \end{array}\right) + \lambda \left(\begin{array}{c} -\boldsymbol B^{-1} \boldsymbol a_j \\ \boldsymbol e_j \end{array}\right) = \left(\begin{array}{c} \boldsymbol B^{-1} \boldsymbol b - \boldsymbol B^{-1} \boldsymbol a_j \\ \lambda \boldsymbol e_j \end{array}\right) \geq \boldsymbol 0
\]
恒成立。因为\(\lambda \boldsymbol e_j \geq \boldsymbol 0\),因此只需关心\(\boldsymbol B^{-1} \boldsymbol b - \boldsymbol B^{-1} \boldsymbol a_j \geq \boldsymbol 0\)是否成立即可,记
\[\boldsymbol b = \boldsymbol B^{-1} \boldsymbol b
\]
即
\[\bar{\boldsymbol b} - \lambda \boldsymbol r_j \geq \boldsymbol 0
\]
因此每个分量都需要大于等于0,即
\[\left[\begin{array}{c}
\bar{b}_{1}-\lambda r_{j 1} \\
\vdots \\
\bar{b}_{m}-\lambda r_{j m}
\end{array}\right] \geq \boldsymbol 0
\]
即
\[\bar{b}_i - \lambda r_{ji} \geq 0, i = 1, \cdots, m
\]
可以得到
\[\lambda \geq \min\{ \dfrac{\bar{b}_i}{r_{ji}} \mid r_{ji} > 0 \}
\]
因此
\[\lambda^* = \min\{ \dfrac{\bar{b}_i}{r_{ji}} \mid r_{ji} > 0 \}
\]
下一个更优的极点为
\[\boldsymbol x^* = \bar{\boldsymbol x} + \lambda^* \boldsymbol d_j
\]
总结:
若从\(\bar{\boldsymbol x}=\left(\begin{array}{c} \boldsymbol B^{-1} \boldsymbol b \\ \boldsymbol 0 \end{array}\right)\)出发满足\(\boldsymbol c_N^{\text{T}} - \boldsymbol c_B^{\text{T}} \boldsymbol B^{-1} \boldsymbol N \geq \boldsymbol 0\),则当前解即为最优解,如果不满足,下一个选取的极点为\(\bar{\boldsymbol x} + \lambda^* \boldsymbol d_j\),其中
\[\bar{\boldsymbol d}_j=\left(\begin{array}{c}
\boldsymbol B^{-1} \boldsymbol a_j \\
\boldsymbol e_j
\end{array}\right), \quad \lambda^* = \min \{ \dfrac{\bar{b}_i}{r_{ji}} \mid r_{ji} > 0 \}
\]
12 等式约束的二次规划问题
12.1 等式约束的二次规划问题描述
考虑如下的等式约束的二次规划问题\((\overline{QP})\):
\[\begin{cases}
\min & \dfrac{1}{2}\boldsymbol x^{\text{T}} \boldsymbol Q \boldsymbol x + \boldsymbol c^{\text{T}} \boldsymbol x \\
\text { s.t } & \boldsymbol a_i^{\text{T}} \boldsymbol x - b_i = 0, i \in \boldsymbol I = \{1, \cdots, m\}
\end{cases}
\]
也可以写为:
\[\begin{cases}
\min & \dfrac{1}{2}\boldsymbol x^{\text{T}} \boldsymbol Q \boldsymbol x + \boldsymbol c^{\text{T}} \boldsymbol x \\
\text { s.t } & \boldsymbol{Ax = b}
\end{cases}
\]
其中,\(\boldsymbol A = \left(\begin{array}{c} \boldsymbol a_1^{\mathrm{T}} \\ \vdots \\ \boldsymbol a_m^{\mathrm{T}} \end{array}\right)\),\(\boldsymbol b = \left(\begin{array}{c} b_1 \\ \vdots \\ b_m \end{array}\right)\)
假设\(\boldsymbol Q \succeq 0\),\(\boldsymbol A \in \mathbb{R}^{m \times n}\)、\(\text{rank}(\boldsymbol A) = m\),对于等式约束问题,常用的有KKT法、变量消去法、零空间法等,这一节暂时只会介绍前两种。
12.2 等式约束求解方法
12.2.1 KKT法
(一) KKT法的原理
因为问题\((\overline{QP})\)是凸问题,因此KKT点即为最优解,KKT条件为:
\[\left\{\begin{array}{r}
\boldsymbol Q \boldsymbol x+\boldsymbol c+\boldsymbol A^{\text{T}} \boldsymbol \lambda = \boldsymbol 0 \\
\boldsymbol A \boldsymbol x=\boldsymbol b
\end{array}\right.
\]
将KKT条件写成矩阵乘积的形式,即:
\[\left(\begin{array}{cc}
\boldsymbol Q & \boldsymbol A^{\text{T}} \\
\boldsymbol A & \boldsymbol 0
\end{array}\right) \left(\begin{array}{c}
\boldsymbol x \\
\boldsymbol \lambda
\end{array}\right) = \left(\begin{array}{c}
-\boldsymbol c \\
\boldsymbol b
\end{array}\right)
\]
若\(\left(\begin{array}{cc} \boldsymbol Q & \boldsymbol A^{\text{T}} \\ \boldsymbol A & \boldsymbol 0 \end{array}\right)\)可逆,则解唯一,其中\(\boldsymbol x\)是\(n\)维的,\(\boldsymbol \lambda\)是\(m\)维的,因此解的是\(n+m\)个变量,
(二) KKT法的缺点
当\(n\)和\(m\)都非常大的话,求解问题将非常复杂。
12.2.2 变量消去法
(一) 变量消去法的原理
为了克服KKT法的缺点就有了变量消去法,所谓变量消去法就是将\(\boldsymbol x\)的通解表示出来,在代入目标函数中,可以将求解\(n\)个变量的问题转化为求解\(n-m\)个变量。
和线性优化中相同的处理方式,对矩阵\(\boldsymbol A\)进行分块:
\[\boldsymbol A = (\boldsymbol A_B, \boldsymbol A_N)
\]
其中,\(\boldsymbol A_B \in \mathbb{R}^{m \times m}\),\(\boldsymbol A_N \in \mathbb{R}^{m \times (n-m)}\),\(\text{rank}(\boldsymbol A_B) = m\)。对矩阵\(\boldsymbol A\)进行相应的分块以后,需要对\(\boldsymbol x, \boldsymbol Q, \boldsymbol c\)也进行相应的分块:
\[\boldsymbol x = \left(\begin{array}{c}
\boldsymbol x_B \\
\boldsymbol x_N
\end{array}\right), \quad \boldsymbol Q = \left(\begin{array}{cc}
\boldsymbol Q_{BB} & \boldsymbol Q_{BN} \\
\boldsymbol Q_{NB} & \boldsymbol Q_{NN}
\end{array}\right), \quad \boldsymbol c = \boldsymbol x = \left(\begin{array}{c}
\boldsymbol c_B \\
\boldsymbol c_N
\end{array}\right)
\]
因此上述等式二次规划问题等价于:
\[\left\{\begin{aligned}
\min & f(\boldsymbol x)=\frac{1}{2}\left(\boldsymbol x_{B}^{\text{T}} \boldsymbol Q_{B B} \boldsymbol x_{B}+\boldsymbol x_{B}^{\text{T}} \boldsymbol Q_{B N} \boldsymbol x_{N}+\boldsymbol x_{N}^{\text{T}} \boldsymbol Q_{N B} \boldsymbol x_{B}+\boldsymbol x_{N}^{\text{T}} \boldsymbol Q_{N N} \boldsymbol x_{N}\right)+\boldsymbol c_{B}^{\text{T}} \boldsymbol x_{B}+\boldsymbol c_{N}^{\text{T}} \boldsymbol x_{N} \\
\text{ s.t } & \boldsymbol A_{B} \boldsymbol x_{B}+\boldsymbol A_{N} \boldsymbol x_{N}=\boldsymbol b
\end{aligned}\right.
\]
因为
\[\boldsymbol{Ax} = (\boldsymbol A_B, \boldsymbol A_N) \left(\begin{array}{c}
\boldsymbol x_B \\
\boldsymbol x_N
\end{array}\right) = \boldsymbol b \quad \Longleftrightarrow \quad
\boldsymbol A_B \boldsymbol x_B + \boldsymbol A_N \boldsymbol x_N = \boldsymbol b
\]
又因为矩阵\(\boldsymbol A_B\)可逆,因此可得:
\[\boldsymbol x_B = \boldsymbol A_B^{-1} \boldsymbol b - \boldsymbol A_B^{-1} \boldsymbol A_N \boldsymbol x_N
\]
将\(\boldsymbol x_B\)代入\(\boldsymbol x\)中,得:
\[\boldsymbol x = \left(\begin{array}{c}
\boldsymbol A_B^{-1}\boldsymbol b - \boldsymbol A_B^{-1}\boldsymbol A_N \boldsymbol x_N \\
\boldsymbol x_N
\end{array}\right) = \left(\begin{array}{c}
\boldsymbol A_B^{-1}\boldsymbol b\\
\boldsymbol 0
\end{array}\right) + \left(\begin{array}{c}
- \boldsymbol A_B^{-1}\boldsymbol A_N \\
\boldsymbol E_{n-m}
\end{array}\right) \boldsymbol x_N
\]
可以理解为\(\left(\begin{array}{c} \boldsymbol A_B^{-1}\boldsymbol b\\ \boldsymbol 0 \end{array}\right)\)为方程\(\boldsymbol{Ax = b}\)的特解,\(\left(\begin{array}{c} - \boldsymbol A_B^{-1}\boldsymbol A_N \\ \boldsymbol E_{n-m} \end{array}\right) \boldsymbol x_N\)为方程\(\boldsymbol{Ax = b}\)的基础解系。
将\(\boldsymbol x_B\)的表达式代入\(f(\boldsymbol x)\)中可得:
\[\begin{aligned}
\hat{f}\left(\boldsymbol x_{N}\right) &=\frac{1}{2} \boldsymbol x_{N}^{\text{T}}\left(\boldsymbol Q_{N N}-\boldsymbol A_{N}^{\text{T}} \boldsymbol A_{B}^{-1} \boldsymbol Q_{B N}-\boldsymbol Q_{N B} \boldsymbol A_{B}^{-1} \boldsymbol A_{N}+\boldsymbol A_{N}^{\text{T}} \boldsymbol A_{B}^{-1} \boldsymbol Q_{B B} \boldsymbol A_{B}^{-1} \boldsymbol A_{N}\right) \boldsymbol x_{N} \\
&+\left[\boldsymbol b^{\text{T}} \boldsymbol A_{B}^{-1}\left(\boldsymbol Q_{B N}-\boldsymbol Q_{B B} \boldsymbol A_{B}^{-1} \boldsymbol A_{N}\right)+\left(\boldsymbol c_{N}^{\text{T}}-\boldsymbol c_{B}^{\text{T}} A_{B}^{-1} A_{N}\right)\right] x_{N} \\
&+\frac{1}{2} \boldsymbol b^{\text{T}} \boldsymbol A_{B}^{-1} \boldsymbol Q_{B B} \boldsymbol A_{B}^{-1} \boldsymbol b+\boldsymbol c_{B}^{\text{T}} \boldsymbol A_{B}^{-1} \boldsymbol b
\end{aligned}
\]
记\((\overline{QP})\)
\[\hat{\boldsymbol Q}_N = \boldsymbol Q_{NN} - \boldsymbol A_N^{\mathrm{T}} \boldsymbol A_B^{-1} \boldsymbol Q_{BN} - \boldsymbol Q_{NB} \boldsymbol A_B^{-1}\boldsymbol A_N + \boldsymbol A_N^{\text{T}}\boldsymbol A_B^{-1} \boldsymbol Q_{BB} \boldsymbol A_B^{-1} \boldsymbol A_N
\]
\[\hat{\boldsymbol r}_N = \boldsymbol b^{\text{T}} \boldsymbol A_{B}^{-1}\left(\boldsymbol Q_{B N}-\boldsymbol Q_{B B} \boldsymbol A_{B}^{-1} \boldsymbol A_{N}\right)+\left(\boldsymbol c_{N}^{\text{T}}-\boldsymbol c_{B}^{\text{T}} A_{B}^{-1} A_{N}\right)
\]
\[\hat{\boldsymbol \delta} = \frac{1}{2} \boldsymbol b^{\text{T}} \boldsymbol A_{B}^{-1} \boldsymbol Q_{B B} \boldsymbol A_{B}^{-1} \boldsymbol b+\boldsymbol c_{B}^{\text{T}} \boldsymbol A_{B}^{-1} \boldsymbol b
\]
则转换为对应的无约束优化问题为:
\[\min \{\hat{f}(\boldsymbol x_N) = \dfrac{1}{2} \boldsymbol x_N^{\text{T}} \hat{\boldsymbol Q}_N \boldsymbol x_N + \hat{\boldsymbol r}_N \boldsymbol x_N + \hat{\boldsymbol \delta}\}
\]
若\(\hat{\boldsymbol Q}_N\)是正定矩阵,则问题\((\overline{QP})\)是凸问题,有唯一解,令
\[\nabla \hat{f}(\boldsymbol x_N) = \boldsymbol 0 \quad \Longrightarrow \quad \hat{\boldsymbol Q}_N \boldsymbol x_N + \hat{\boldsymbol r}_N = \boldsymbol 0
\]
解得:
\[\boldsymbol x_N^* = - \hat{\boldsymbol Q}_N^{-1} \hat{\boldsymbol r}_N
\]
因此:
\[\boldsymbol x^{*}=\left(\begin{array}{c}
\boldsymbol x_{B}^{*} \\
\boldsymbol x_{N}^{*}
\end{array}\right)=\left(\begin{array}{c}
\boldsymbol A_{B}^{-1} \boldsymbol b+\boldsymbol A_{B}^{-1} \boldsymbol A_{N} \hat{\boldsymbol Q}_{N}^{-1} \hat{\boldsymbol r}_{N} \\
-\hat{\boldsymbol Q}_{N}^{-1} \hat{\boldsymbol r}_{N}
\end{array}\right)
\]
即为问题\((\overline{QP})\)的最优解。最优解满足KKT条件,则对应的Lagrange乘子满足:
\[\boldsymbol Q\boldsymbol x^{*} \boldsymbol r + \boldsymbol A^{\text{T}} \boldsymbol \lambda^* = \boldsymbol 0
\]
\[\Updownarrow
\]
\[\left(\begin{array}{cc}
\boldsymbol Q_{B B} & \boldsymbol Q_{B N} \\
\boldsymbol Q_{N B} & \boldsymbol Q_{N N}
\end{array}\right)\left(\begin{array}{c}
\boldsymbol x_{B}^{*} \\
\boldsymbol x_{N}^{*}
\end{array}\right)+\left(\begin{array}{c}
\boldsymbol r_{B} \\
\boldsymbol r_{N}
\end{array}\right)+\left(\begin{array}{c}
\boldsymbol A_{B}^{\text{T}} \\
\boldsymbol A_{N}^{\text{T}}
\end{array}\right) \boldsymbol \lambda^{*}=\left(\begin{array}{l}
\boldsymbol 0 \\
\boldsymbol 0
\end{array}\right)
\]
得到:
\[\boldsymbol \lambda^{*} = -\boldsymbol A_B^{-1}(\boldsymbol Q_{BB} \boldsymbol x_B^* + \boldsymbol Q_{BN} \boldsymbol r_N + \boldsymbol r_B)
\]
由于\(\boldsymbol x_N\)是\(n - m\)维的,而\(\boldsymbol x\)是\(n\)维,变量个数从原来的\(n\)个变为\(n-m\)个,因此该方法被称为变量消去法。
(二) 变量消去法的优缺点
-
方法的优点:
-
方法的缺点:
- 当\(\boldsymbol A_B\)接近一奇异矩阵的时候解会非常的不稳定。
13 不等式约束的二次规划问题
上一节学习了等式约束的二次规划问题,介绍了变量消去法和KKT法两种求解的方法,但是一般的求解问题中都是带有不等式约束的,因此这一节将学习不等式约束的二次规划问题。
13.1 一般的二次规划问题
前面介绍了等式约束的二次规划的求解方法,求解的问题有可能是带有不等式约束的,考虑如下问题,记为\((QP)\):
\[\left\{\begin{aligned}
\min & \frac{1}{2} \boldsymbol x^{T} \boldsymbol Q \boldsymbol x+\boldsymbol c^{T} x \\
\text{ s.t } & \boldsymbol a_{i}^{T} \boldsymbol x-b_{i} \leq 0 \quad i \in \mathcal{I}=\{1, \ldots, m\} \\
& \boldsymbol a_{i}^{T} \boldsymbol x-b_{i}=0 \quad i \in \mathcal{E}=\{m+1, \ldots, m+l\}
\end{aligned}\right.
\]
13.2 最优解的性质
性质一:最优解为KKT点。
性质二:假设\(\boldsymbol x^*\)是问题\((QP)\)的最优解,\(\boldsymbol x^*\)对应的有效指标集:
\[I(\boldsymbol x^*) = \{ i \mid \boldsymbol a_i^{\mathrm{T}} \boldsymbol x^* = b_i, i \in \mathcal{I} \}
\]
则\(\boldsymbol x^*\)是等式约束二次规划\((QP_*)\)问题的最优解,\((QP_*)\)问题为:
\[\left\{\begin{aligned}
\min & \frac{1}{2} \boldsymbol x^{\mathrm{T}} \boldsymbol Q \boldsymbol x+\boldsymbol c^{\mathrm{T}} \boldsymbol x \\
\text{ s.t } & \boldsymbol a_{i}^{\mathrm{T}} \boldsymbol x-b_{i} \leq 0 \quad i \in \mathcal{I}(\boldsymbol x^*) \\
& \boldsymbol a_{i}^{\mathrm{T}} \boldsymbol x-b_{i}=0 \quad i \in \mathcal{E}
\end{aligned}\right.
\]
性质2证明:
因为\(\boldsymbol x^*\)是问题\((QP)\)的最优解,则满足KKT条件,即:
\[\left\{\begin{array}{rlr}
\boldsymbol Q \boldsymbol x^{*}+\boldsymbol c+\sum_{i \in \mathcal{E} \cup \mathcal{I}} \lambda_{i} \boldsymbol a_{i}=\boldsymbol 0 & \quad (1)\\
\lambda_{i} \geq 0 & i \in \mathcal{I} \quad (2)\\
\boldsymbol a_{i}^{\mathrm{T}} \boldsymbol x^{*}-b_{i} \leq 0 & i \in \mathcal{I} \quad (3)\\
\boldsymbol a_{i}^{\mathrm{T}} \boldsymbol x^{*}-b_{i}=0 & i \in \mathcal{E} \quad (4)\\
\lambda_{i}\left(\boldsymbol a_{i}^{\mathrm{T}} \boldsymbol x^{*}-b_{i}\right)=0 & i \in \mathcal{I} \quad (5)
\end{array}\right.
\]
由互补松弛条件可知:
\[\lambda_i = 0, \quad i \in \mathcal{I}\\mathcal{I}(\boldsymbol x^*)
\]
因此,上式的\((1)\)式可以改写为:
\[\boldsymbol Q \boldsymbol x^{*}+\boldsymbol c+\sum_{i \in \mathcal{E} \cup \mathcal{I}(\boldsymbol x^*)} \lambda_{i} \boldsymbol a_{i}=\boldsymbol 0
\]
因此上述KKT条件可以改写为:
\[\left\{\begin{array}{rlr}
\boldsymbol Q \boldsymbol x^{*}+\boldsymbol c+\sum_{i \in \mathcal{E} \cup \mathcal{I}(\boldsymbol x^*)} \lambda_{i} \boldsymbol a_{i}=\boldsymbol 0 & \quad (1)\\
\lambda_{i} \geq 0 & i \in \mathcal{I}(\boldsymbol x^*) \quad (2)\\
\boldsymbol a_{i}^{\mathrm{T}} \boldsymbol x^{*}-b_{i} \leq 0 & i \in \mathcal{I}(\boldsymbol x^*) \quad (3)\\
\boldsymbol a_{i}^{\mathrm{T}} \boldsymbol x^{*}-b_{i}=0 & i \in \mathcal{E} \quad (4)\\
\lambda_{i}\left(\boldsymbol a_{i}^{\mathrm{T}} \boldsymbol x^{*}-b_{i}\right)=0 & i \in \mathcal{I}(\boldsymbol x^*) \quad (5)
\end{array}\right.
\]
即问题\((QP_*)\)的KKT条件,即\(\boldsymbol x^*\)是问题\((QP_*)\)的KKT点。
由一般的二次规划问题的最优解可求等式约束的二次规划问题的最优解,等式约束的二次规划问题很容易可以通过变量消去法、零空间法或KKT法求得。很容易想如果知道了问题\((QP_*)\)的最优解,能否知道问题\((QP)\)的最优解呢?
13.3 定理
13.3.1 定理内容
设\(\bar{\boldsymbol x}\)是问题\((QP)\)的可行点,找到\(\bar{\boldsymbol x}\)对应的有效指标集\(\boldsymbol I(\bar{\boldsymbol x})\),求解问题\((\overline{QP})\)
\[\left\{\begin{aligned}
\min & \frac{1}{2} \boldsymbol x^{T} \boldsymbol Q \boldsymbol x+\boldsymbol c^{T} \boldsymbol x \\
\text{ s.t } & \boldsymbol a_{i}^{T} \boldsymbol x-b_{i} \leq 0 \quad i \in \mathcal{I}(\bar{\boldsymbol x}) \cup \mathcal{E}
\end{aligned}\right.
\]
得\(\bar{\boldsymbol x}\)是问题\((\overline{QP})\)的最优解,设\(\bar{\boldsymbol \lambda}\)是相应的乘子,若\(\bar{\lambda}_i \geq 0, \forall i \in \mathcal{I}(\bar{\boldsymbol x})\),则\(\bar{\boldsymbol x}\)是问题\((QP)\)的最优解。
13.3.2 定理证明
证明暂略,请参考视频讲解或者转载的笔记。
13.4 有效集法思路
有上述的定理就会想,如果对应的\(\bar{\lambda}_i \geq 0\)不成立,那么如何确定\((QP)\)问题的最优解呢?这就有了有效集法。
假设\(\boldsymbol x^0\)是问题\((QP)\)的可行点,\(\mathcal{I}(\boldsymbol x^0)\)是\(\boldsymbol x^0\)对应的有效指标集,若对应的等式二次规划问题\((QP^0)\):
\[\left\{\begin{aligned}
\min & \frac{1}{2} \boldsymbol x^{T} \boldsymbol Q \boldsymbol x+\boldsymbol c^{T} \boldsymbol x \\
\text{ s.t } & \boldsymbol a_{i}^{T} \boldsymbol x-b_{i} \leq 0 \quad i \in \mathcal{I}=(\boldsymbol x^0) \cup \mathcal{E}
\end{aligned}\right.
\]
的最优解为\(\hat{\boldsymbol x}^0\),考虑以下两种情况:
13.4.1 情况一:\(\hat{\boldsymbol x}^0 = \boldsymbol x^0\)
-
若\(\lambda_i^0 \geq 0, \forall i \in \mathcal{I}(\boldsymbol x^0)\),这种情况就很好,由前面的定理可得\(\boldsymbol x^0\)就是问题\((QP)\)的最优解;
-
若存在\(p \in \mathcal{I}(\boldsymbol x^0), \lambda_p^0 < 0\),由前面的Lagrange乘子的意义可得,当乘子小于0的时候,右端项增大,目标函数的值将增大。在问题\((QP)\)中原来只要求\(\boldsymbol a_p^{\mathrm{T}}\boldsymbol x - b_p \leq 0\),而在\((QP^0)\)问题中要求\(\boldsymbol a_p^{\mathrm{T}}\boldsymbol x - b_p = 0\),相当于右端项变大了,目标函数值将变大,这在求最小值问题中是不合理的,因此在\(\boldsymbol x^0\)的有效集中需要将这一点去除。记\(\boldsymbol x^1 : = \boldsymbol x^0\),\(\mathcal{I}(\boldsymbol x^1) = \mathcal{I}(\boldsymbol x^0) \ \{p\}\),重新求对应等式二次规划问题的最优解。有效指标集中对应的Lagrange乘子可能很多小于0,这时候排除掉最小的即可,即排除掉扰动最大的点,对算法改进的也就越多。
13.4.2 情况二
-
若\(\hat{\boldsymbol x}^0\)是问题\((QP)\)的可行解,则记\(\boldsymbol x^1 := \hat{\boldsymbol x}^0\),产生新的迭代点和有效指标集\(\boldsymbol x^1\),在求解对应二次规划问题的可行解;
-
若\(\hat{\boldsymbol x}^0\)不是问题\((QP)\)的可行解,则一定是违反了一些不等式约束。
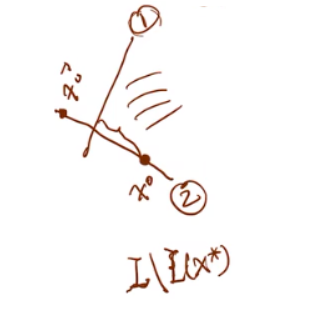
比如图上的\(\hat{\boldsymbol x}^0\)就违反了约束条件1,但是为什么仍然会找到\(\hat{\boldsymbol x}^0\),那肯定是因为\(\hat{\boldsymbol x}^0\)处的函数值比\(\boldsymbol x^0\)的小,因此\(\boldsymbol d = \hat{\boldsymbol x}^0 - \boldsymbol x^0\)是函数值下降方向。既然是下降方向,那肯定是沿着下降方向下降的越多越好,但是又不能超过边界,设沿着\(\boldsymbol d\)方向走\(\alpha > 0\)步,则要取到最优解\(\alpha\)越大越好,并且在可行域内,则\(\boldsymbol x^0 + \alpha \boldsymbol d\)满足问题\((QP)\)的约束条件,即:
\[\begin{cases}
\boldsymbol a_{i}^{T}\left(\boldsymbol x^{0}+\alpha \boldsymbol d\right)-b_{i} \leq 0 & i \in \mathcal{E} \quad (1)\\
\boldsymbol a_{i}^{T}\left(\boldsymbol x^{0}+\alpha \boldsymbol d\right)-b_{i} \leq 0 & i \in \mathcal{I} \backslash \mathcal{I}\left(x^{0}\right) \quad (2)\\
\boldsymbol a_{i}^{T}\left(\boldsymbol x^{0}+\alpha \boldsymbol d\right)-b_{i} \leq 0 & i \in \mathcal{I}\left(\boldsymbol x^{0}\right) \quad (3)
\end{cases}
\]
其中对条件\((1)(3)\)是天然成立的,因此只需考虑\((2)\)的情况即可,即:
\[\boldsymbol a_i^{\mathrm{T}}(\boldsymbol x^0 + \alpha \boldsymbol d) - b_i \leq 0, \quad i \in \mathrm{T} \backslash \mathcal{I}(\boldsymbol x^0)
\]
做一个变形得:
\[\alpha \boldsymbol a_i^{\mathrm{T}} \boldsymbol d \leq b_i - \boldsymbol a_i^{\text{T}} \boldsymbol x^0, \quad i \in \mathrm{T} \backslash \mathcal{I}(\boldsymbol x^0)
\]
如果
\[\boldsymbol a_i^{\mathrm{T}} \boldsymbol d \leq 0
\]
因为
\[b_i - \boldsymbol a_i^{\mathrm{T}} \boldsymbol x^0 \leq 0, \quad i \in \mathrm{T} \backslash \mathcal{I}(\boldsymbol x^0)
\]
不等式天然成立,现考虑\(\boldsymbol a_i^{\mathrm{T}} \boldsymbol d > 0\)的情况,两边同除以\(\boldsymbol a_i^{\mathrm{T}} \boldsymbol d\)得:
\[\alpha \leq \dfrac{b_i - \boldsymbol a_i^{\mathrm{T}}\boldsymbol x^0}{\boldsymbol a_i^{\mathrm{T}} \boldsymbol d}, \quad i \in \mathrm{T} \backslash \mathcal{I}(\boldsymbol x^0)
\]
则
\[\alpha \leq \min \left\{\frac{b_{i}-\boldsymbol a_{i}^{\text{T}} \boldsymbol x^{0}}{a_{i}^{\text{T}} \boldsymbol d} \mid, \quad i \in \mathcal{I} \backslash \mathcal{I}\left(\boldsymbol x^{0}\right), \boldsymbol a_{i}^{\text{T}} \boldsymbol d>0\right\}
\]
最优解在等号处取得,记
\[\alpha^* = \alpha \leq \min \left\{\frac{b_{i}-\boldsymbol a_{i}^{\text{T}} \boldsymbol x^{0}}{a_{i}^{\text{T}} \boldsymbol d} \mid, \quad i \in \mathcal{I} \backslash \mathcal{I}\left(\boldsymbol x^{0}\right), \boldsymbol a_{i}^{\text{T}} \boldsymbol d>0\right\} = \dfrac{b_q - \alpha_q^{\text{T}} \boldsymbol x^0}{\boldsymbol a_q^{\text{T}} \boldsymbol d}
\]
构造新的迭代点
\[\boldsymbol x^1 = \boldsymbol x^0 + \alpha^* \boldsymbol d
\]
及可行集
\[\boldsymbol I(\boldsymbol x^1) = \boldsymbol I(\boldsymbol x^0) \cup \{q\}
\]
在求解对应的二次规划问题,直到情况一的1成立
13.5 有效集法算法梳理
前面已经很详细的介绍了有效集方法的实现思路,这里给出具体的算法步骤
\[\left\{\begin{aligned}
\min & \frac{1}{2} \boldsymbol x^{\text{T}} \boldsymbol Q \boldsymbol x+ \boldsymbol c^{\text{T}} \boldsymbol x \\
\text{ s.t } & \boldsymbol a_{i}^{\text{T}} \boldsymbol x-b_{i} = 0, \quad i \in \mathcal{I}(\boldsymbol x^k) \cup \mathcal{E}
\end{aligned}\right.
\]
-
STEP 3:若\(\hat{\boldsymbol x}^k = \boldsymbol x^k\),考虑对应的乘子\(\boldsymbol \lambda^k\),若\(\lambda_i^k \geq 0, \forall i \in \boldsymbol I(\boldsymbol x^*)\),则算法终止,\(\boldsymbol x^*\)即为最优解,否则计算\(\lambda_p^{k} := \min \{\lambda_i^k, i \in \boldsymbol I(\boldsymbol x^k)\}\),令\(k:=k+1\);
-
STEP 4:若\(\hat{\boldsymbol x}^k \neq \boldsymbol x^k\)
- 情况1:\(\hat{\boldsymbol x}^k\)是问题\((QP)\)的可行点,则令\(\boldsymbol x^{k+1} = \hat{\boldsymbol x}^k\),更新有效指标集\(\boldsymbol I(\boldsymbol x^{k+1})\),
- 情况2:\(\hat{\boldsymbol x}^k\)不是问题\((QP)\)的可行点,则计算
\[\alpha^* = \alpha \leq \min \left\{\frac{b_{i}-\boldsymbol a_{i}^{\text{T}} \boldsymbol x^{0}}{a_{i}^{\text{T}} \boldsymbol d} \mid, \quad i \in \mathcal{I} \backslash \mathcal{I}\left(\boldsymbol x^{0}\right), \boldsymbol a_{i}^{\text{T}} \boldsymbol d>0\right\} = \dfrac{b_q - \alpha_q^{\text{T}} \boldsymbol x^0}{\boldsymbol a_q^{\text{T}} \boldsymbol d}
\]
其中,\(\boldsymbol d^k = \hat{\boldsymbol x}^k - {\boldsymbol x}^k\),令
\[\boldsymbol x^{k+1} = \boldsymbol x^k + \alpha_k \boldsymbol d^k, \quad \boldsymbol I(\boldsymbol x^{k+1}) = \boldsymbol I(\boldsymbol x^{k}) \cup \{\boldsymbol q \}, \quad k:=k+1
\]
转STEP 2。
【1】数值优化| 对偶问题及强弱对偶定理,数值优化 |对偶问题的性质及求解办法
【2】最优化| 线性优化
【3】数值优化| 不等式约束的二次规划问题
【4】数值优化| 等式约束的二次规划问题
【5】数值优化| 不等式约束的二次规划问题
 最优化方法基础知识👉第三部分
最优化方法基础知识👉第三部分

 浙公网安备 33010602011771号
浙公网安备 33010602011771号