Deepmind新文:TOWARDS A UNIFIED AGENT WITH FOUNDATION MODELS
原文链接:https://arxiv.org/abs/2307.09668
摘要:语言模型和视觉语言模型最近在理解人类意图、推理、场景理解和类似计划的文本行为等方面展示出了前所未有的能力。在这项工作中,我们研究了如何在强化学习(RL)代理中嵌入和利用这些能力。我们设计了一个使用语言作为核心推理工具的框架,探索这如何使代理能够解决一系列基本的RL挑战,如有效的探索、重用经验数据、调度技能和从观察中学习,这些传统上需要独立的、垂直设计的算法。我们在一个稀疏奖励模拟的机器人操作环境上测试了我们的方法,其中一个机器人需要堆叠一组对象。我们演示了在探索效率和重用离线数据集数据的能力方面比基线上的实质性性能改进,并说明了如何重用学习到的技能来解决新任务或模仿人类专家的视频。
1 介绍
近年来,文献中出现了一系列显著的深度学习(DL)成功故事(3),特别是在自然语言处理(4;19;8;29)和计算机视觉(2;25;36;37)领域取得了突破。尽管在模式上不同,这些结果有一个共同的结构:大型神经网络,通常是变形金刚(46),在巨大的网络数据集(39;19)上使用自监督学习方法(19;6)。虽然结构简单,但这个配方导致了惊人有效的大型语言模型(LLMs)(4)的开发,能够处理和生成具有优秀的类人能力的文本,视觉变压器(ViTs)(25;13)能够在没有监督的情况下从图像和视频中提取有意义的表示(6;18),以及视觉语言模型(vlm)(2;36;28),可以将那些描述语言视觉输入的数据模式,或者将语言描述转换为视觉输出。这些模型的规模和能力导致社区创造了术语基础模型(3),这表明了如何将这些模型作为涉及各种输入模式的下游应用程序的主干。
这让我们引出了以下问题:我们能否利用(视觉)语言模型的性能和能力来设计更高效和通用的强化学习代理?在接受了网络尺度的文本和视觉数据的训练后,文献观察到在这些模型中出现了常识推理、提出和排序子目标、视觉理解和其他属性的现象(19;4;8;29)。这些都是需要与环境互动和从环境中学习的基本特征,但这可能需要不切实际的时间才能从试验和错误中出现白板。利用存储在基础模型中的知识,可以极大地引导这个过程。
基于这个想法,我们设计了一个框架,将语言放在RL机器人代理的核心,特别是在从头学习的环境中。我们的核心贡献和发现如下:
我们表明,这个框架,利用LLMs和VLMs,可以解决一系列的基本问题在RL设置,如1)有效地探索稀疏奖励环境,2)重使用收集的数据来引导新任务的学习顺序,3)调度学习技能来解决新任务和 4)从观察学习的专家代理。在最近的文献中,这些任务需要不同的、专门设计的算法来单独处理,而我们证明了基础模型的能力释放了开发一个更统一的方法的可能性。
2 相关工作
在过去的几年里,缩放模型的参数计数和训练数据集的大小和多样性,导致了(视觉)语言模型的前所未有的能力(4;19;2;19;8)。这反过来又导致了一些应用程序在与世界交互的智能体中利用这些模型。之前的工作已经在模拟环境中使用了LLMs和VLMs以及RL代理(12;44),但它们依赖于为培训代理收集大量的演示。相反,我们关注从头开始学习RL代理的问题,并利用LLMs和VLMs来加速进展。
之前的工作也研究了利用llm和vlm进行机器人应用;特别是(1;21;50;20)利用llm在长期任务中规划子目标,并与vlm一起进行场景理解和总结。这些子目标可以通过有语言条件的政策形成行动(22;30)。虽然这些工作大多集中于部署和调度已经通过llm学习到的技能,尽管是在现实世界中,但我们的工作集中于一个从头开始学习这些行为的RL系统,突出了这些模型给探索、转移和体验重用带来的好处。
已经提出了几种方法来处理稀疏奖励任务,或通过课程学习(43513116)、内在动机(1735),或层次分解(3227)。我们演示了llm如何在不需要任何额外的学习或微调的情况下,以零镜头生成学习课程,并且vlm可以自动为这些子目标提供奖励,极大地提高了学习速度。
相关的工作也研究了通过学习手头的新任务的奖励模型来重用机器人经验的大型数据集(5)。然而,对于每个新任务,需要收集大量的期望奖励的人工注释。相反,正如在并发相关工作(48)中所报道的那样,我们展示了利用过去的经验,这些vlm可以通过来自目标域的少量数据来微调。
(15)是与我们的工作最相似的方法:他们提出了llm和vlm之间的相互作用,以学习《我的世界》中的稀疏奖励任务(23;24)。然而,也有一些显著的差异:他们使用大量的互联网视频、帖子和教程数据集来调整他们的模型,同时我们证明了可以用1000个数据点有效地调整VLM,并使用现成的llm;此外,我们还研究和实验这个框架如何用于数据重用和传输,以及从观察中学习,除了探索和技能调度,提出了一个更统一的方法来应对强化学习的一些核心挑战。
3 准备工作
我们使用Lee等人(26)的模拟机器人环境,用MuJoCo物理模拟器(45)模拟实验:一个机械臂与由篮子中的一个红色、一个蓝色和一个绿色物体组成的环境互动。我们将其形式化为一个马尔可夫决策过程(MDP):状态空间S表示物体和末端执行器的三维位置。机器人是通过位置控制来控制的:动作空间A由一个x,y位置组成,我们使用已知的机器人逆运动学到达,机器人手臂可以选择或放置一个物体,灵感来自(49;40)。观测空间O由128×128×3 RGB图像组成,这些图像来自于固定在篮子边缘的两个摄像机。agent接收到待解决的语言描述任务$T$,可以有两种形式:"Stack $X $on top of $X $"把$X $堆叠在$X $上,其中$X$和$Y$取自{“红色对象”,“绿色对象”,“蓝色对象”}没有替换,或“Stack all three objects”(“堆叠所有三个对象”),我们也称之为$Triple Stack$三重堆叠。
如果情节成功,+1会得到积极的奖励,而在其他情况下会得到0的奖励。我们将任务的稀疏性定义为当执行从均匀分布中采样的随机动作时,解决任务并获得单一奖励所需的环境步骤的平均数量。采用我们采用的MDP设计,堆叠两个对象的稀疏性为103,而最优策略可以通过2个选择和放置动作/步骤(49;40)来解决任务。通过评估一个随机策略的轨迹来衡量,叠加所有三个对象的稀疏性超过106,而一个最优策略可以通过4个步骤来解决任务。
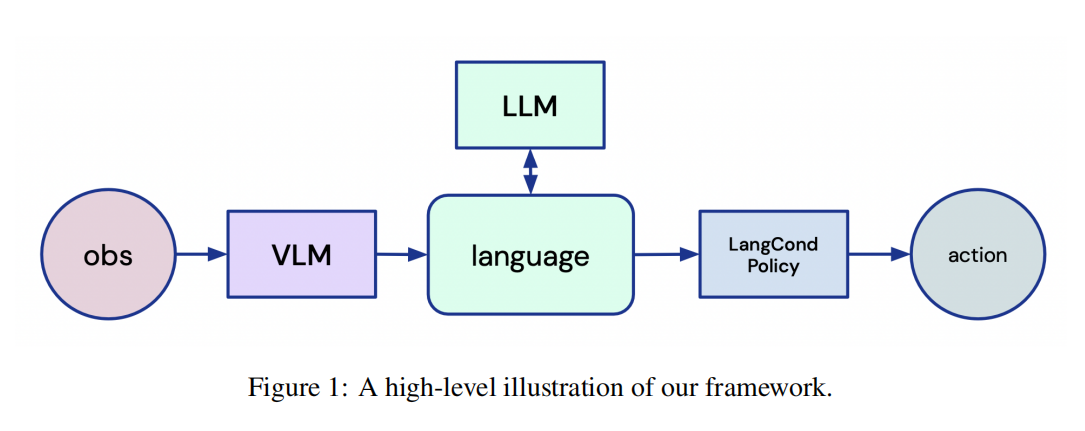
4 一个针对以语言为中心的代理的框架
这项工作的目标是研究基础模型(3)的使用,在巨大的图像和文本数据集上进行预训练,以设计一个更通用和统一的RL机器人代理。我们提出了一个框架,从头开始增强RL代理,能够使用llm和vlm的杰出能力来推理他们的环境,他们的任务,以及完全通过语言采取的行动。
为此,代理首先需要将视觉输入映射到文本描述中。其次,我们需要用这样的文本描述和任务描述来提示一个LLM,以便向代理提供语言指令。最后,代理需要将LLM的输出接地为动作。
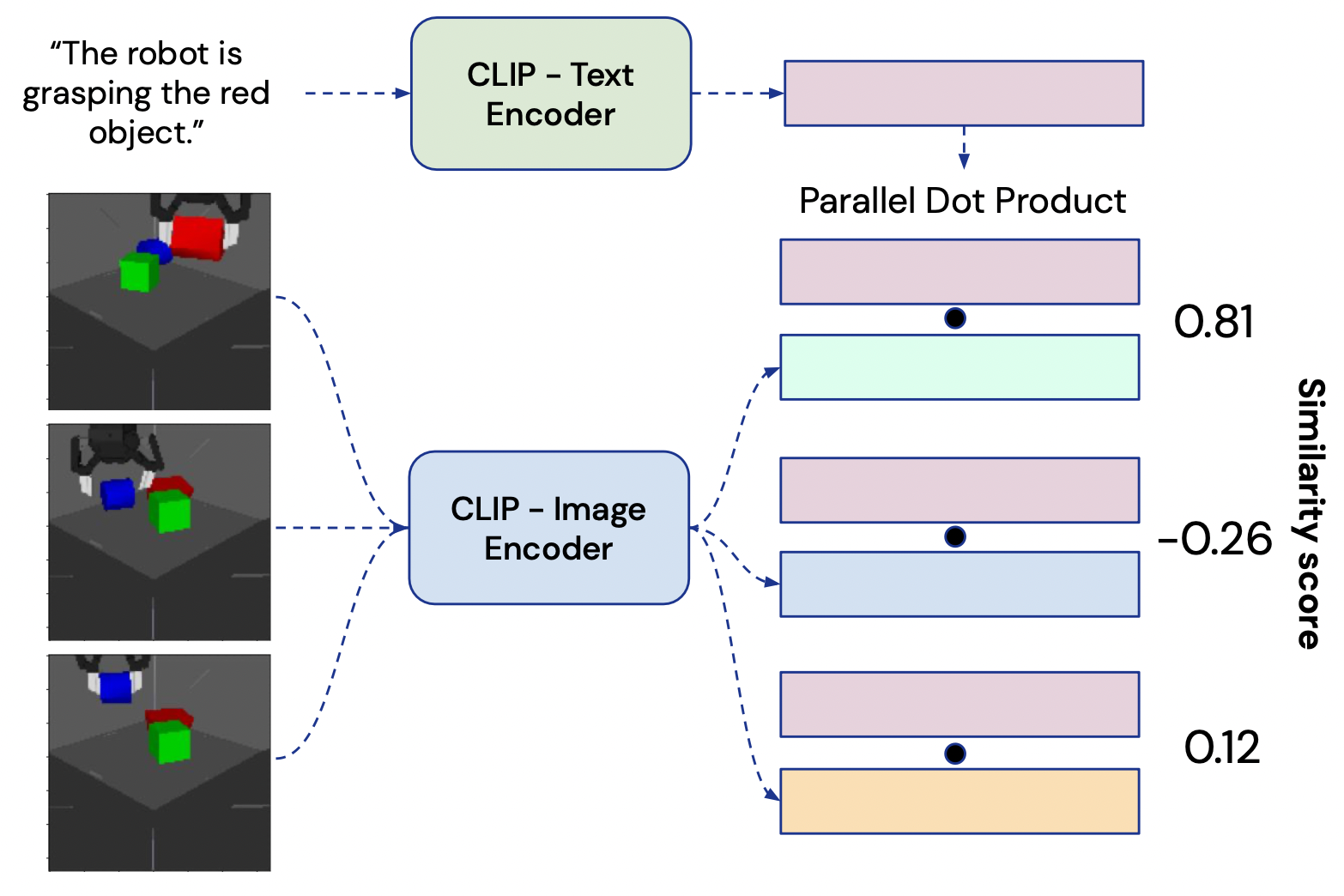
使用VLMs来桥接视觉和语言: 描述从RGB相机中获取的视觉输入(第3部分)在语言形式中,我们使用CLIP,一个大型的、具有对比性的视觉语言模型(36)。CLIP由一个图像编码器$\phi_I$和一个文本编码器$\phi_T$组成,在大量嘈杂配对的图像和文本描述的数据集上进行训练,我们也称之为标题captions。每个编码器输出一个128维的嵌入向量:图像的嵌入和匹配的文本描述被优化以具有较大的余弦相似度。为了从环境中生成图像的语言描述,agent将观察$o_t$提供给$\phi_I$,并将一个可能的标题caption$l_n$提供给$\phi_T$(图2)。我们计算嵌入向量之间的点积,并考虑结果大于超参数$γ$的描述正确(我们的实验中$γ$=0.8,详见附录)。当我们关注机器人的堆叠任务时,描述的形式是“机器人正在抓住X”或“X在Y之上”,其中X和Y是从{“红色物体”,“绿色物体”,“蓝色物体”}没有替换。我们在模拟堆叠域的少量数据上微调CLIP;更多关于如何工作的更多细节和对微调数据需求的分析见附录。
通过LLM的语言进行推理:语言模型以语言形式的prompt提示符作为输入,通过自回归计算下一个标记的概率分布并从该分布中抽样,生成语言作为输出。在我们的设置中,llm的目标是获取一个表示手头任务的文本指令(例如,“将红色对象堆叠在蓝色对象上”),并生成一组子目标供机器人解决。我们使用FLAN-T5(10),这是一个基于语言指令数据集的LLM。我们进行的定性分析显示,它的表现略优于未细化指令的llm。
这些 LLMs 具有非凡的情境学习能力,因此我们可以使用现成的 LLMs(4;34),而无需进行域内微调,只需提供两个任务指令和所需语言输出的示例即可引导 LLMs 的行为:我们描述环境设置,要求 LLMs 找到能够解决拟议任务的子目标,并提供两个此类任务的示例和相对的子目标分解。这样,LLM 就能模拟出所需的行为,不仅在内容上,而且在输出语言的格式上都能实现高效解析。在附录中,我们将更详细地介绍我们使用的提示和 LLM 的行为。
将指令转化为行动:llm提供的语言目标通过使用语言条件的策略网络建立行动。这个网络,参数化为变压器(46),采取嵌入的语言子目标和MDP的状态t时间步,包括对象和机器人末端执行器的位置,作为输入,每个表示为不同的向量,并输出一个动作为机器人执行时间步t + 1。这个网络是在一个RL循环中从头开始训练的,如我们下面所述。
收集和推断学习范式:我们的agent通过一种受收集和推断范式启发的方法从与环境的交互中学习(38)。在收集阶段,代理与环境交互,并以状态、观察、行动和当前目标的形式如$(s_t,o_t,a_t,g_i)$收集数据,通过其策略网络$f_\theta(s_t,g_i)\rightarrow a_t$预测行动。在每一集之后,代理使用VLM来推断收集的数据中是否遇到了任何子目标,从而提取额外的奖励,我们稍后将更详细地解释。如果该episode以奖励结束,或者如果VLM提供任何奖励,代理将该episode数据存储到奖励时间步$[(s_0,o_0,a_0,g_i)$,…$(s_{T_r−1},o_{T_r−1},a_{T_r−1},g_i)]$在体验缓冲区中。我们在图4(左)中说明了这个管道。这些步骤由N个分布式的并行代理执行,这些代理将数据收集到相同的体验缓冲区中(在我们的工作中是N个=1000)。在推断阶段,我们在每个代理完成一个episode后,通过行为克隆来训练策略,因此每N个episodes,对成功的episode实施一种自我模仿的形式(33;14;7)。然后,将策略的更新权重与所有分布式代理共享,并重复此过程。
5 应用和结果
我们描述了组成我们的框架的构建块。使用语言作为agent的核心提供了一个统一的框架来解决RL中的一系列基本挑战。在接下来的章节中,我们将调查每一个贡献,重点是探索、重用过去的经验数据、安排和重用技能,以及从观察中学习。在算法1中也描述了总体框架。
5.1 探索-通过语言生成课程
RL从精心制作的、密集的奖励中获益良多(5)。然而,在许多现实世界的环境中,密集的奖励的存在是很罕见的。机器人代理需要能够在复杂的环境中学习广泛的任务,但是随着任务数量的增加,工程密集的奖励功能变得非常耗费时间。因此,有效和普遍的探索对于克服这些挑战和扩大RL是必要的。
多年来,人们发展了各种各样的方法来解决对稀疏奖励环境的探索(43、51、31、16、17、35、32、27)。许多人提出通过课程生成和学习,将长期任务分解为更短、更容易学习的任务。通常,这些方法需要从头开始学习分解任务,阻碍了整体的学习效率。我们将演示利用LLM的RL代理如何利用在没有任何过去环境交互的情况下生成的文本子目标课程。
为了指导探索,代理向LLM提供任务描述$T_n$,指导LLM将其任务分解为更短的子目标,有效地生成文本形式1的目标$g_{0:G}$的课程。代理选择操作作为$f_\theta(s_t,T_n)\rightarrow a_t$ 在。虽然环境提供了一个奖励只有$T_n$解决,VLM部署作为一个额外的,稀疏奖励模型:鉴于观察$o_{0:T}$收集在事件和所有文本子目标$g_{0:G}$LLM,它验证如果任何子目标解决在任何步骤。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号