
分页查询优化limit的方法和原理
一、背景
直接从数据库查询所有数据,耗时、耗内存,改为分页查询部分数据
二、常规分页查询
1. mysql: limit 从第m条数据开始,查询n条数据
select * from table limit m,n
2. sql server: top+子查询
3. 原理:从数据库的第一条记录开始扫描
a. 越往后,即m越大,查询越慢
b. 查询的数据越多,即n越大,查询越慢
三、优化方式
1. 使用子查询进行优化,先查出一个id,再根据id进行limit,查出数据
2. 根据id做限定进行优化,把id作为where的条件
3. 使用临时表进行优化,先查出所有id,再试用in查出数据
select * from table where id in (select id from table limit m,n)
四、优化原理
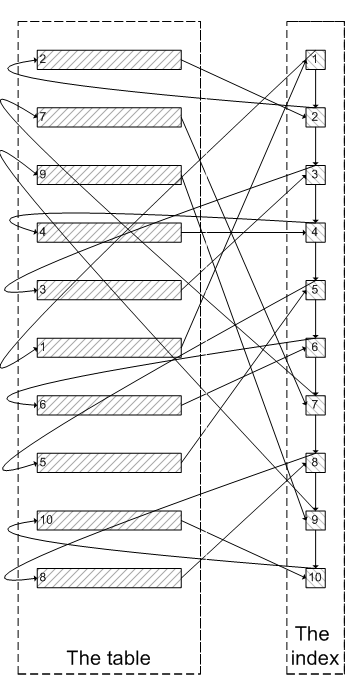
1. select * from table limit m,n 的查询过程
a. 查询到索引叶子节点数据
b. 根据叶子节点上的主键值,去聚集索引,查询需要的全部字段值
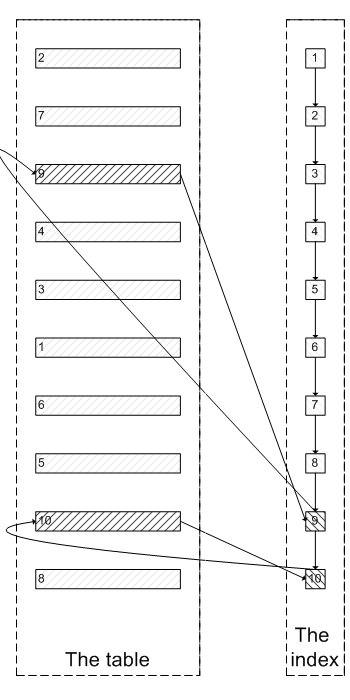
2. 优化后
参考:
https://mp.weixin.qq.com/s/CmlfkRki0lCiDEIsz5pDpg

 浙公网安备 33010602011771号
浙公网安备 33010602011771号