
一:为什么使用flink
1.jdk实现流式处理
package net.xdclass.app; import net.xdclass.model.VideoOrder; import java.util.Arrays; import java.util.List; import java.util.stream.Collectors; /** * java实现流式计算 */ public class JdkStreamApp { public static void main(String[] args) { //总价 35 List<VideoOrder> videoOrders1 = Arrays.asList( new VideoOrder("20190242812", "springboot教程", 3), new VideoOrder("20194350812", "微服务SpringCloud", 5), new VideoOrder("20190814232", "Redis教程", 9), new VideoOrder("20190523812", "⽹⻚开发教程", 9), new VideoOrder("201932324", "百万并发实战Netty", 9)); //总价 54 List<VideoOrder> videoOrders2 = Arrays.asList( new VideoOrder("2019024285312", "springboot教程", 3), new VideoOrder("2019081453232", "Redis教程", 9), new VideoOrder("20190522338312", "⽹⻚开发教程", 9), new VideoOrder("2019435230812", "Jmeter压⼒测试", 5), new VideoOrder("2019323542411", "Git+Jenkins持续集成", 7), new VideoOrder("2019323542424", "Idea全套教程", 21)); //平均价格 double videoOrder1Avg1 = videoOrders1.stream().collect(Collectors.averagingInt(VideoOrder::getMoney)); double videoOrder1Avg2 = videoOrders2.stream().collect(Collectors.averagingInt(VideoOrder::getMoney)); System.out.println("videoOrder1Avg1=" + videoOrder1Avg1); System.out.println("videoOrder1Avg2=" + videoOrder1Avg2); //订单总价 int total1 = videoOrders1.stream().mapToInt(VideoOrder::getMoney).sum(); int total2 = videoOrders2.stream().mapToInt(VideoOrder::getMoney).sum(); System.out.println("total1=" + total1); System.out.println("total2=" + total2); } }
2.JDK8 Stream也是流处理,flink也是流处理, 那区别点来
数据来源和输出有多样化怎么处理;
jdk stream -写代码
flink - ⾃带很多组件
海量数据需要进⾏实时处理
jdk stream - 内部jvm单节点处理,单机内部并⾏处理
flink - 节点可以分布在不同机器的JVM上,多机器并⾏处理
统计时间段内数据,但数据达到是⽆序的
jdk stream -写代码
flink - ⾃带窗⼝函数和watermark处理迟到数据
二:常见的知识点
1.官网
https://flink.apache.org/zh/flink-architecture.html
2.用处
⽤来做啥:实时数仓建设、实时数据监控、实时反作弊⻛控、 画像系统等
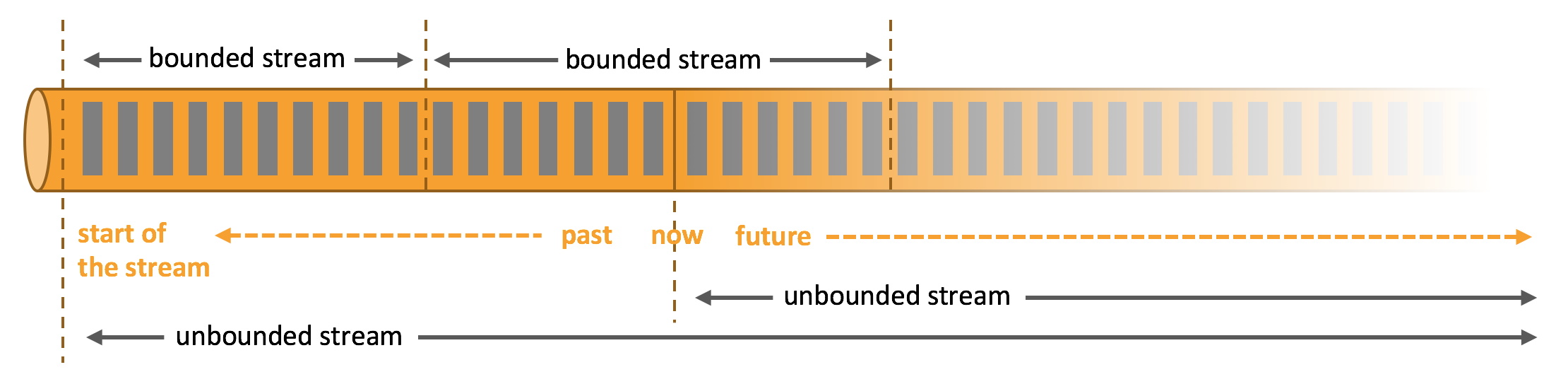
3.有界流和无界流
任何类型的数据都可以形成一种事件流。信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流。
数据可以被作为 无界 或者 有界 流来处理。
-
无界流 有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
-
有界流 有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理
4.operator算子
source、transformation、sink 都是 operator算⼦
三:flink小案例与原理说明
1.pom
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>net.xdclass</groupId> <artifactId>xdclass-flink</artifactId> <version>1.0-SNAPSHOT</version> <properties> <encoding>UTF-8</encoding> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <java.version>1.8</java.version> <scala.version>2.12</scala.version> <flink.version>1.13.1</flink.version> </properties> <dependencies> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.16</version> <scope>provided</scope> </dependency> <!--flink客户端--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients_${scala.version}</artifactId> <version>${flink.version}</version> </dependency> <!--java版本--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> </dependency> <!--streaming的java版本--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_${scala.version}</artifactId> <version>${flink.version}</version> </dependency> <!--日志输出--> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.7</version> <scope>runtime</scope> </dependency> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> <scope>runtime</scope> </dependency> <!--json依赖包--> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.44</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>8</source> <target>8</target> </configuration> </plugin> </plugins> </build> </project>
2.Tuple元组数据类型 + Map + FlatMap操作介绍
-
什么是Tuple类型
-
元组类型, 多个语言都有的特性, flink的java版 tuple最多支持25个
-
用途
- 函数返回(return)多个值,多个不同类型的对象
- List集合不是也可以吗,集合里面是单个类型
- 列表只能存储相同的数据类型,而元组Tuple可以存储不同的数据类型
-
-
什么是java里面的Map操作
- 一对一 转换对象,比如DO转DTO
-
什么是java里面的FlatMap操作
- 一对多转换对象
3.flnk入门
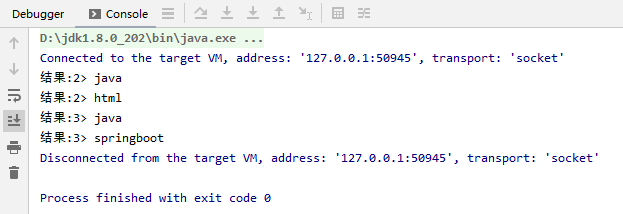
package net.xdclass.app; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; /** * flink入门 */ public class HelloWord { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> stringDS = env.fromElements("java,html", "java,springboot"); SingleOutputStreamOperator<String> flatMapDS = stringDS.flatMap(new FlatMapFunction<String, String>() { @Override public void flatMap(String s, Collector<String> collector) throws Exception { final String[] split = s.split(","); for (String word : split) { collector.collect(word); } } }); flatMapDS.print("结果"); env.execute("hello world"); } }
效果:
4.Flink可视化控制台
win | linux 需要安装
-
win 百度搜索博文参考不同系统安装
可以参考:https://blog.csdn.net/q_a_z_w_s_x___/article/details/115327163
效果:
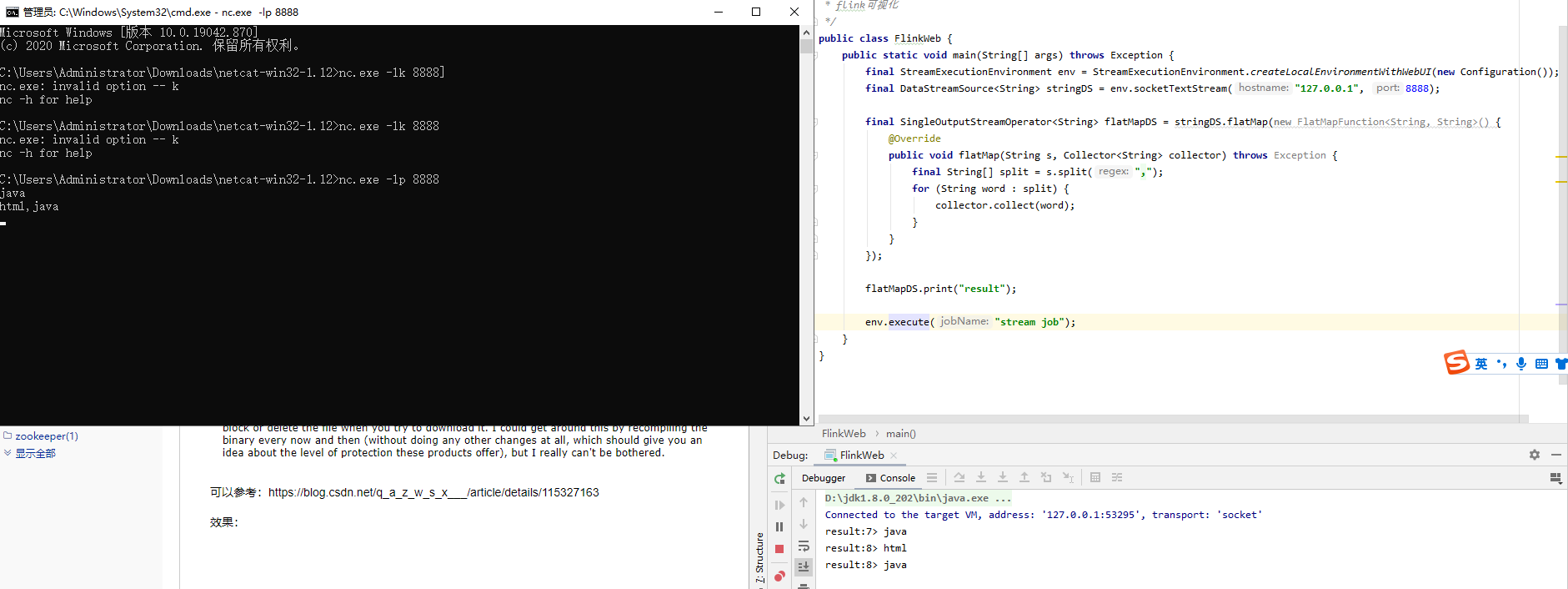
程序如下:
package net.xdclass.app; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; /** * flink可视化 */ public class FlinkWeb { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration()); final DataStreamSource<String> stringDS = env.socketTextStream("127.0.0.1", 8888); final SingleOutputStreamOperator<String> flatMapDS = stringDS.flatMap(new FlatMapFunction<String, String>() { @Override public void flatMap(String s, Collector<String> collector) throws Exception { final String[] split = s.split(","); for (String word : split) { collector.collect(word); } } }); flatMapDS.print("result"); env.execute("stream job"); } }
8081端口:
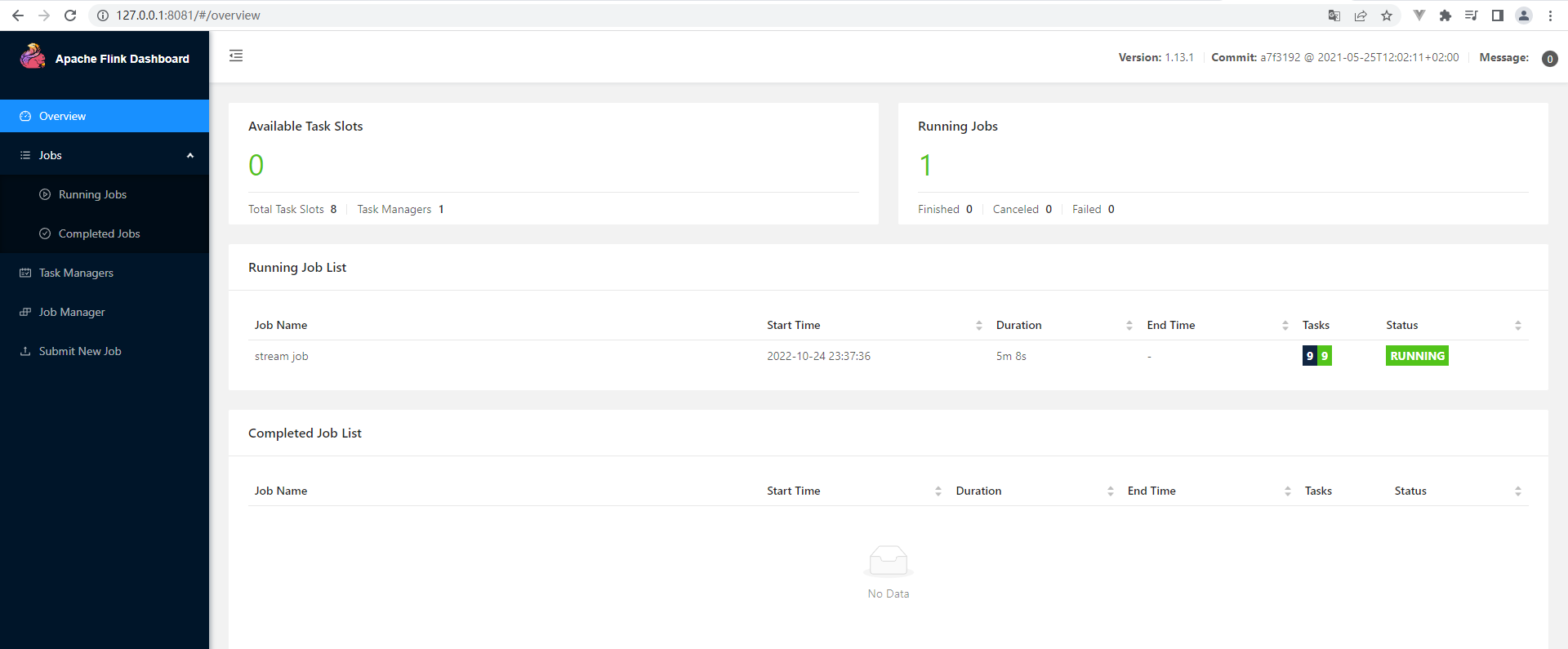
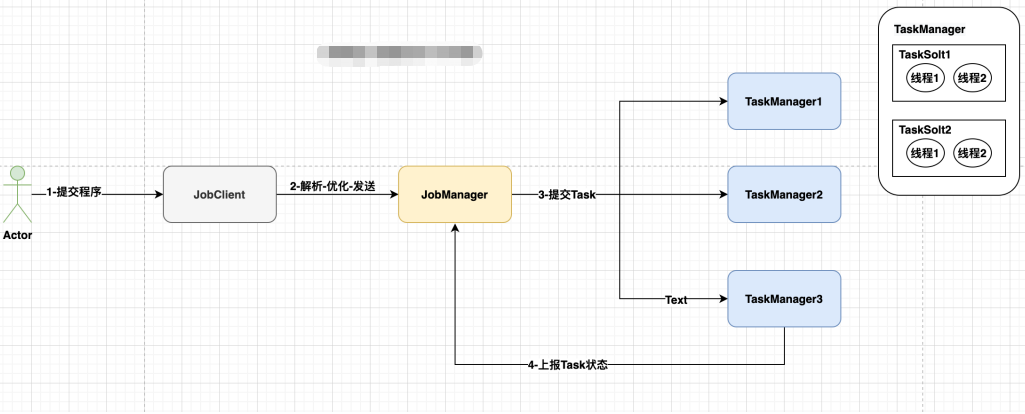
5.运行流程
-
用户提交Flink程序到JobClient,
-
JobClient的 解析、优化提交到JobManager
-
TaskManager运行task, 并上报信息给JobManager
![]()
6.框架与原理
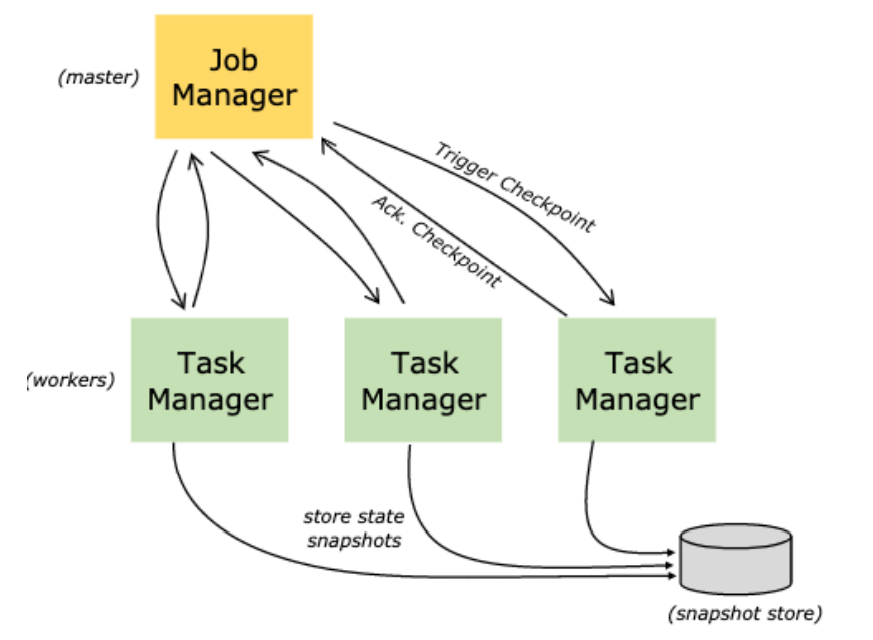
Flink 是⼀个分布式系统,需要有效分配和管理计算资源才能执⾏流应⽤程序
运行时由两种类型的进程组成
- 一个 JobManager
- 一个或者多个 TaskManager
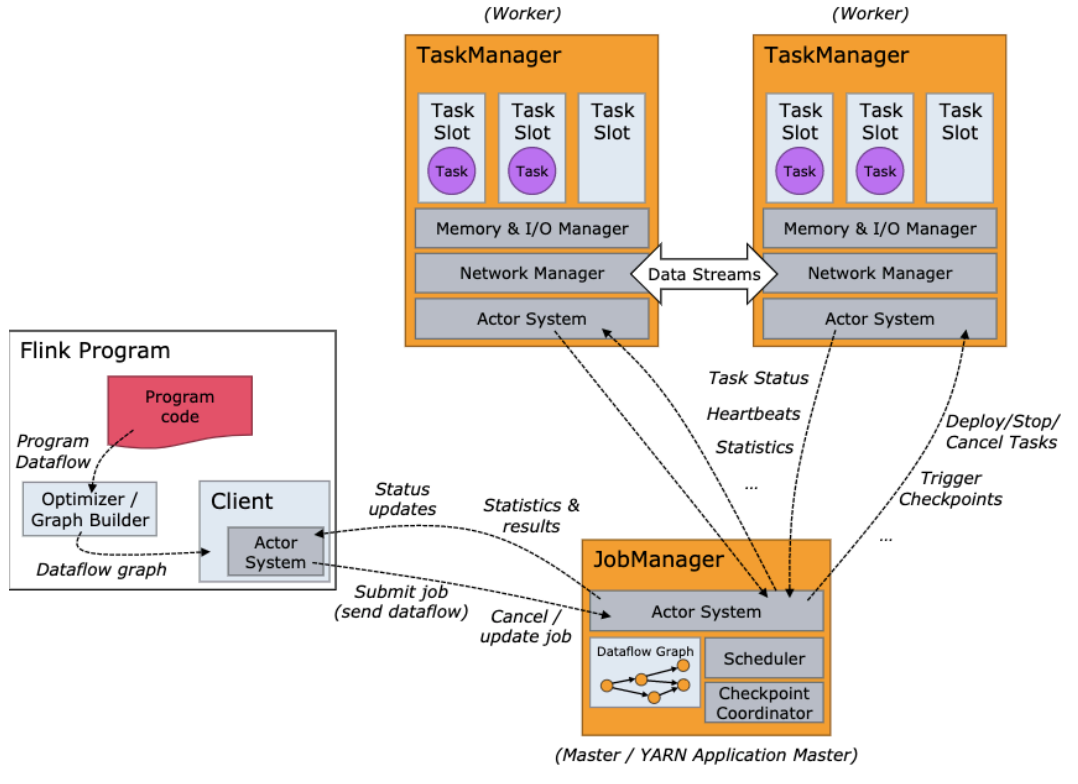
-
什么是JobManager
-
协调 Flink 应用程序的分布式执行的功能
- 它决定何时调度下一个 task(或一组 task)
- 对完成的 task 或执行失败做出反应
- 协调 checkpoint、并且协调从失败中恢复等等
-
-
什么是TaskManager
- 负责计算的worker,还有上报内存、任务运行情况给JobManager等
- 至少有一个 TaskManager,也称为 worker执行作业流的 task,并且缓存和交换数据流
- 在 TaskManager 中资源调度的最小单位是 task slot
-
Jobmanager进阶
-
JobManager进程由三个不同的组件组成
-
ResourceManager
- 负责 Flink 集群中的资源提供、回收、分配 - 它管理 task slots
-
Dispatcher
- 提供了一个 REST 接口,用来提交 Flink 应用程序执行
- 为每个提交的作业启动一个新的 JobMaster。
- 运行 Flink WebUI 用来提供作业执行信息
-
JobMaster
- 负责管理单个JobGraph的执行,Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster
- 至少有一个 JobManager,高可用(HA)设置中可能有多个 JobManager,其中一个始终是 leader,其他的则是 standby
-
-
-
TaskManager 进阶
-
TaskManager中 task slot 的数量表示并发处理 task 的数量
-
一个 task slot 中可以执行多个算子,里面多个线程
-
算子 opetator
- source
- transformation
- sink
-
-
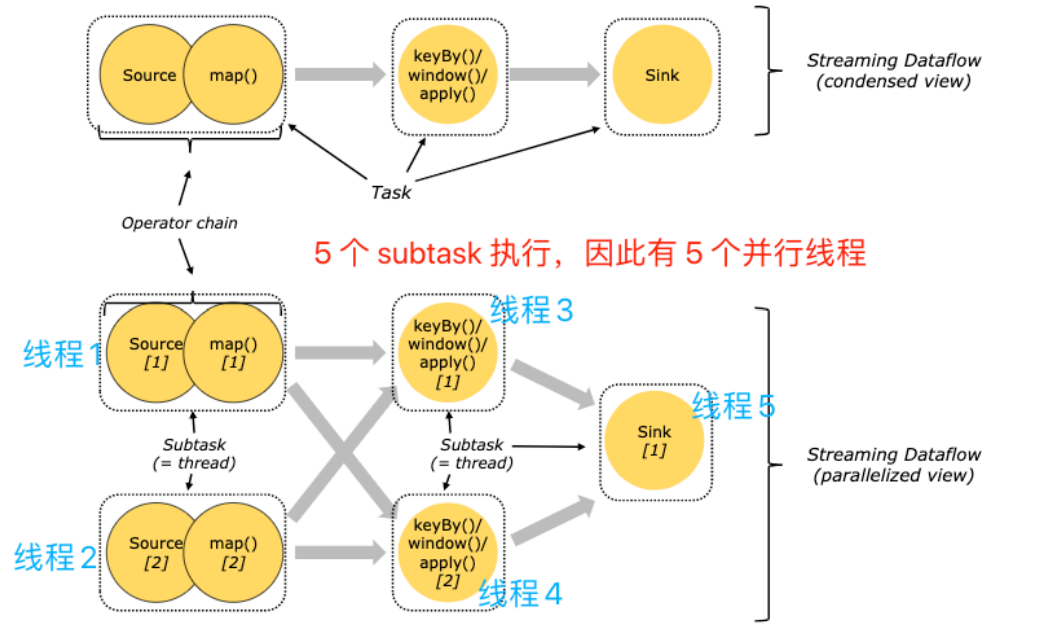
对于分布式执行,Flink 将算子的 subtasks 链接成 tasks,每个 task 由一个线程执行
- 图中source和map算子组成一个算子链,作为一个task运行在一个线程上
-
将算子链接成 task 是个有用的优化:它减少线程间切换、缓冲的开销,并且减少延迟的同时增加整体吞吐量
-
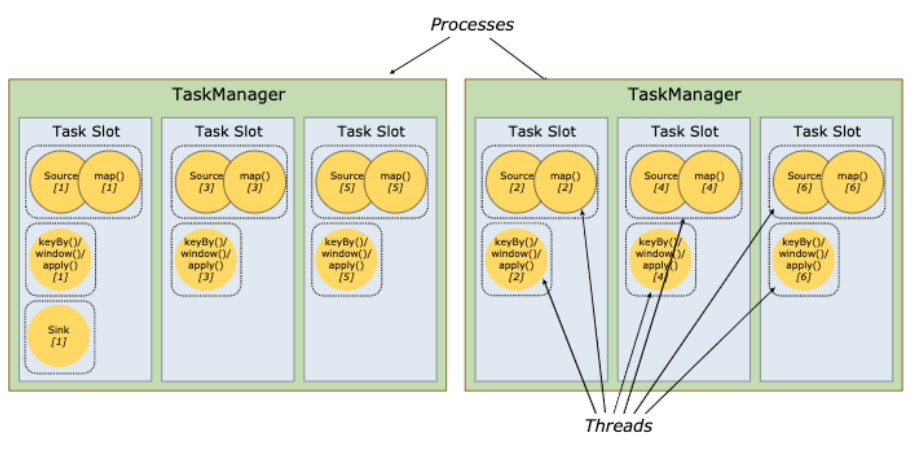
Task Slots 任务槽
-
Task Slot是Flink中的任务执行器,每个Task Slot可以运行多个subtask ,每个subtask会以单独的线程来运行
-
每个 worker(TaskManager)是一个 JVM 进程,可以在单独的线程中执行一个(1个solt)或多个 subtask
-
为了控制一个 TaskManager 中接受多少个 task,就有了所谓的 task slots(至少一个)
-
每个 task slot 代表 TaskManager 中资源的固定子集
-
注意
- 所有Task Slot平均分配TaskManger的内存, TaskSolt 没有 CPU 隔离
- 当前 TaskSolt 独占内存空间,作业间互不影响
- 一个TaskManager进程里有多少个taskSolt就意味着多少个并发
- task solt数量建议是cpu的核数,独占内存,共享CPU
5 个 subtask 执行,因此有 5 个并行线程
-
Task 正好封装了一个 Operator 或者 Operator Chain 的 parallel instance。
-
Sub-Task 强调的是同一个 Operator 或者 Operator Chain 具有多个并行的 Task
- Task Slot是Flink中的任务执行器,每个Task Slot可以运行多个task即subtask ,每个sub task会以单独的线程来运行
- Flink 算子之间可以通过【一对一】模式或【重新分发】模式传输数据
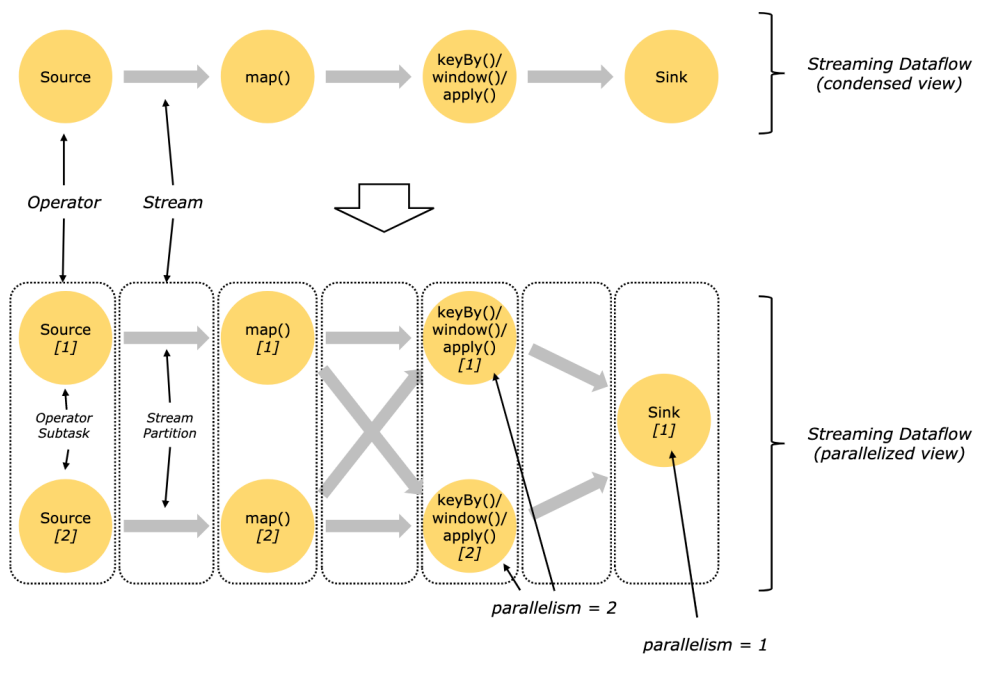
7.并行度
- 程序在多节点并行执行,所以就有并行度 Parallelism
- 一个算子的子任务subtask 的个数就是并行度( parallelism)
-
并行度的调整配置
-
Flink流程序中不同的算子可能具有不同的并行度,可以在多个地方配置,有不同的优先级
-
Flink并行度配置级别 (高到低)
-
算子
- map( xxx ).setParallelism(2)
-
全局env
- env.setParallelism(2)
-
客户端cli
- ./bin/flink run -p 2 xxx.jar
-
Flink配置文件
- /conf/flink-conf.yaml 的 parallelism.defaul 默认值
-
-
某些算子无法设置并行度
-
本地IDEA运行 并行度默认为cpu核数
-
-
一个很重要的区分 TaskSolt和parallelism并行度配置
- task slot是静态的概念,是指taskmanager具有的并发执行能力;
- parallelism是动态的概念,是指 程序运行时实际使用的并发能力
- 前者是具有的能力比如可以100个,后者是实际使用的并发,比如只要20个并发就行。
8.运行模式
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
- STREAMING 流处理
- BATCH 批处理
- AUTOMATIC 根据source类型自动选择运行模式,基本就是使用这个
四:SOURCE
1.Api层级
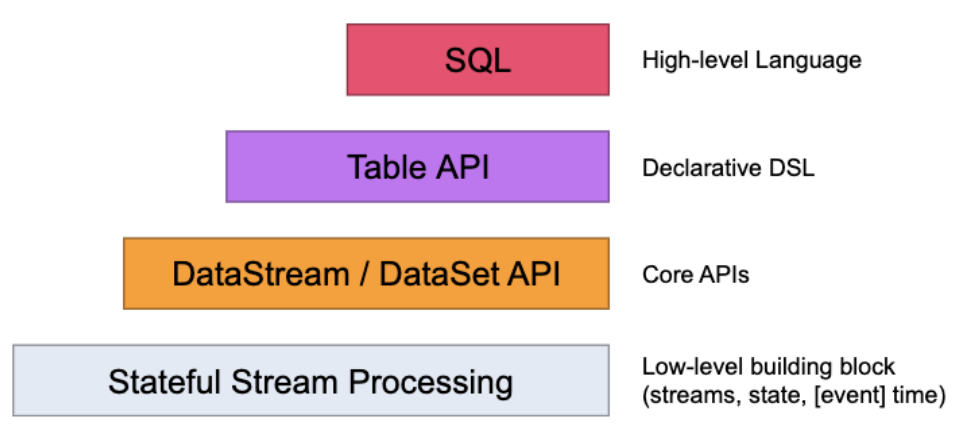
Flink的API层级 为流式/批式处理应用程序的开发提供了不同级别的抽象
-
第一层是最底层的抽象为有状态实时流处理,抽象实现是 Process Function,用于底层处理
-
第二层抽象是 Core APIs,许多应用程序不需要使用到上述最底层抽象的 API,而是使用 Core APIs 进行开发
- 例如各种形式的用户自定义转换(transformations)、联接(joins)、聚合(aggregations)、窗口(windows)和状态(state)操作等,此层 API 中处理的数据类型在每种编程语言中都有其对应的类。
-
第三层抽象是 Table API。 是以表Table为中心的声明式编程API,Table API 使用起来很简洁但是表达能力差
- 类似数据库中关系模型中的操作,比如 select、project、join、group-by 和 aggregate 等
- 允许用户在编写应用程序时将 Table API 与 DataStream/DataSet API 混合使用
-
第四层最顶层抽象是 SQL,这层程序表达式上都类似于 Table API,但是其程序实现都是 SQL 查询表达式
- SQL 抽象与 Table API 抽象之间的关联是非常紧密的
2.Flink编程模型
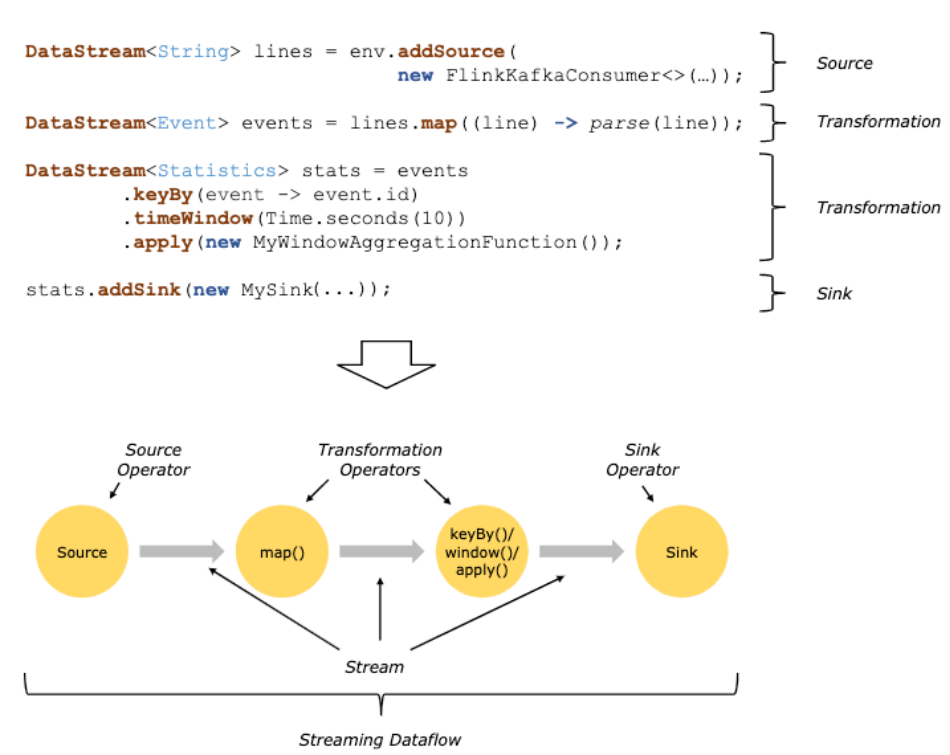
3.source来源
-
-
元素集合
- env.fromElements
- env.fromColletion
- env.fromSequence(start,end);
-
文件/文件系统
- env.readTextFile(本地文件);
- env.readTextFile(HDFS文件);
-
基于Socket
- env.socketTextStream("ip", 8888)
-
自定义Source,实现接口自定义数据源,rich相关的api更丰富
-
并行度为1
- SourceFunction
- RichSourceFunction
-
并行度大于1
- ParallelSourceFunction
- RichParallelSourceFunction
-
-
-
Connectors与第三方系统进行对接(用于source或者sink都可以)
- Flink本身提供Connector例如kafka、RabbitMQ、ES等
- 注意:Flink程序打包一定要将相应的connetor相关类打包进去,不然就会失败
-
Apache Bahir连接器
- 里面也有kafka、RabbitMQ、ES的连接器更多
4.预定义的source-元素集合
package net.xdclass.app; import com.google.common.collect.Lists; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * :预定义的Source 数据源 */ public class FlinkSource1 { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // fromelements DataStreamSource<String> stringDS = env.fromElements("java,springboot", "java,html"); stringDS.print(); // fromCollection DataStreamSource<String> collectionDS = env.fromCollection(Lists.newArrayList("alibabacloud,rabbitmq", "hadoop,hbase")); collectionDS.print(); // fromSequence DataStreamSource<Long> sequenceDs = env.fromSequence(0, 10); sequenceDs.print(); env.execute("source job"); } }
5.预定义的source-文件/文件系统
package net.xdclass.app; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class FlinkTextSource2 { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStreamSource<String> textFile = env.readTextFile("E:\\study\\flinkText.txt"); textFile.print(); env.execute("text file job"); } }
6.预定义的source-基于socket
package net.xdclass.app; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class FlinkSocketSource3 { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); DataStreamSource<String> socketTextStream = env.socketTextStream("127.0.0.1", 8888); socketTextStream.print(); env.execute("socket text job"); } }
7.自定义Source,实现接口自定义数据源
自定义source
package net.xdclass.source; import net.xdclass.model.VideoOrder; import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction; import java.util.ArrayList; import java.util.List; import java.util.Random; import java.util.UUID; public class VideoOrderSource extends RichParallelSourceFunction<VideoOrder> { private volatile Boolean flag = true; private Random random = new Random(); private static List<String> list = new ArrayList<>(); static { list.add("spring boot2.x课程"); list.add("微服务SpringCloud课程"); list.add("RabbitMQ消息队列"); list.add("Kafka课程"); list.add("⼩滴课堂⾯试专题第⼀季"); list.add("Flink流式技术课程"); list.add("⼯业级微服务项⽬⼤课训练营"); list.add("Linux课程"); } @Override public void run(SourceContext<VideoOrder> sourceContext) throws Exception { while (flag) { Thread.sleep(1000); String uuid = UUID.randomUUID().toString(); int money = random.nextInt(100); int videoNum = random.nextInt(list.size()); String title = list.get(videoNum); // 添加 sourceContext.collect(new VideoOrder(uuid, title, money)); } } @Override public void cancel() { flag = false; } }
使用
package net.xdclass.app; import net.xdclass.model.VideoOrder; import net.xdclass.source.VideoOrderSource; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * 自定义的Source */ public class FlinkOwnerSource4 { public static void main(String[] args) throws Exception { StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); environment.setParallelism(1); DataStreamSource<VideoOrder> videoOrderDataStreamSource = environment.addSource(new VideoOrderSource()); videoOrderDataStreamSource.print(); environment.execute("自定义source job"); } }
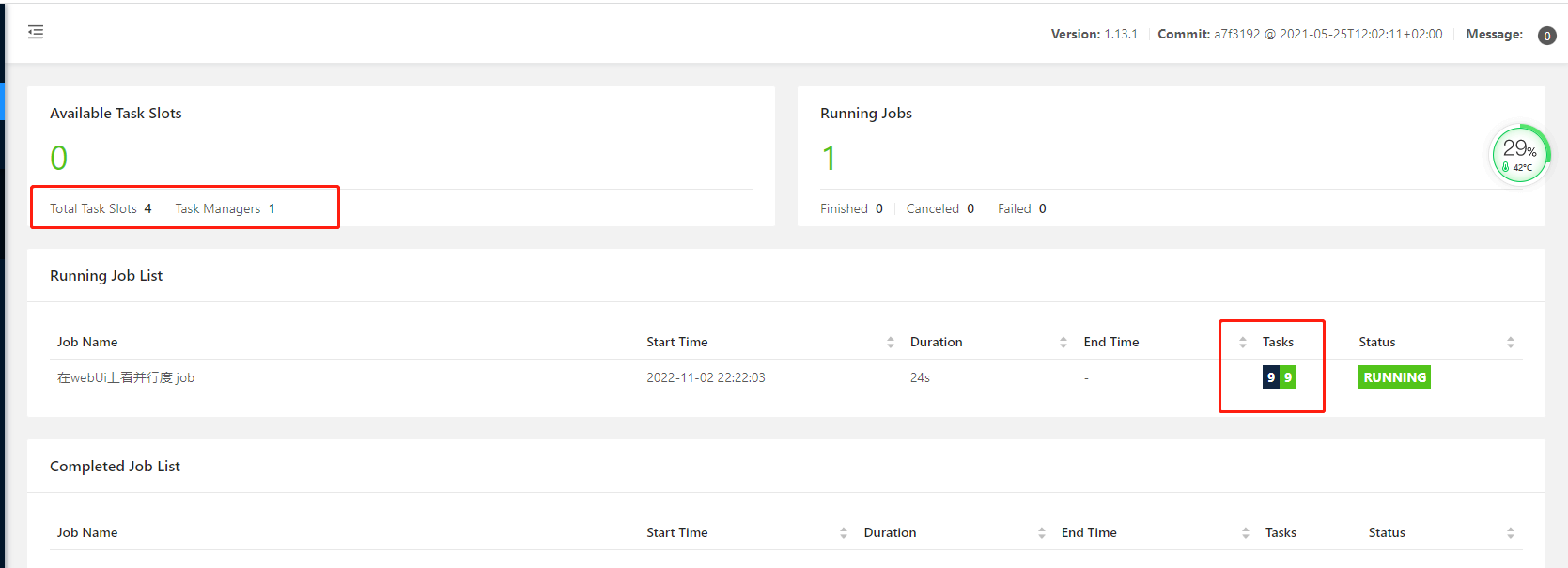
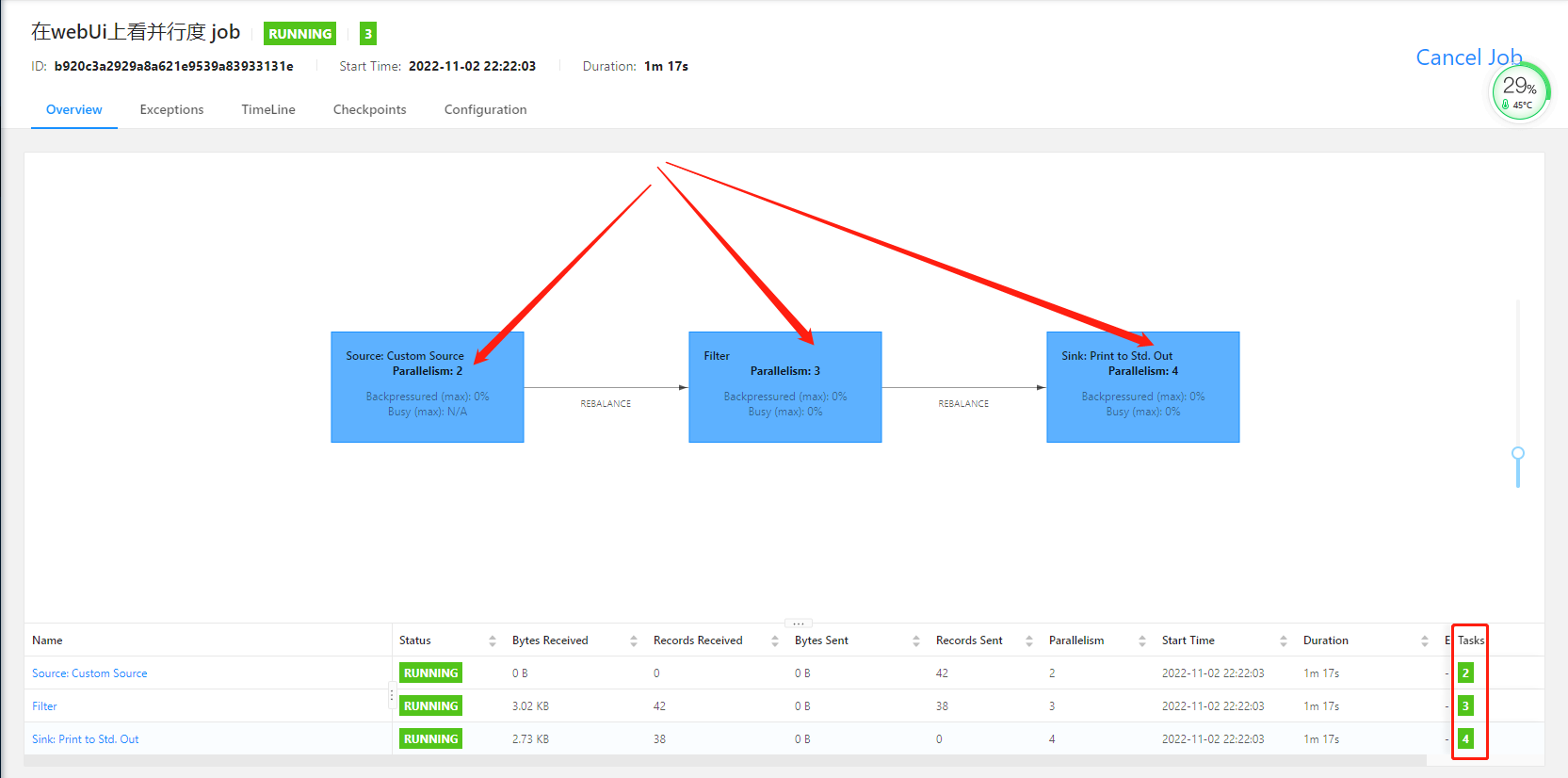
8.webUi上看并行度
程序:
package net.xdclass.app; import net.xdclass.model.VideoOrder; import net.xdclass.source.VideoOrderSource; import org.apache.flink.api.common.RuntimeExecutionMode; import org.apache.flink.api.common.functions.FilterFunction; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * 在webUi上看并行度 */ public class FlinkWebParallelism { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration()); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); env.setParallelism(2); DataStreamSource<VideoOrder> videoOrderDataStreamSource = env.addSource(new VideoOrderSource()); DataStream<VideoOrder> filterDS = videoOrderDataStreamSource.filter(new FilterFunction<VideoOrder>() { @Override public boolean filter(VideoOrder videoOrder) throws Exception { return videoOrder.getMoney() > 20; } }).setParallelism(3); filterDS.print().setParallelism(4); env.execute("在webUi上看并行度 job"); } }
- 数据流中最⼤的并⾏度,就是算⼦链中最⼤算⼦的数量,⽐如 source 2个并⾏度,filter 4个,sink 4个,最⼤就是4
- 9 = 2+3+4
四:Sink
1.输出源
-
Sink 输出源
-
预定义
- writeAsText (过期)
-
自定义
-
SinkFunction
-
RichSinkFunction
- Rich相关的api更丰富,多了Open、Close方法,用于初始化连接等
-
-
flink官方提供 Bundle Connector
- kafka、ES 等
-
Apache Bahir
- kafka、ES、Redis等
-
2.⾃定义的Sink 连接Mysql存储商品订单
执行sql
CREATE TABLE `video_order` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `user_id` int(11) DEFAULT NULL, `money` int(11) DEFAULT NULL, `title` varchar(32) DEFAULT NULL, `trade_no` varchar(64) DEFAULT NULL, `create_time` date DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
添加依赖:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.25</version>
</dependency>
执行程序:
package net.xdclass.app.sink; import net.xdclass.model.VideoOrder; import net.xdclass.app.source.VideoOrderSource; import org.apache.flink.api.common.RuntimeExecutionMode; import org.apache.flink.api.common.functions.FilterFunction; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class Flink06CustomMysqSinkApp { /** * source * transformation * sink * * @param args */ public static void main(String[] args) throws Exception { //构建执行任务环境以及任务的启动的入口, 存储全局相关的参数 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); env.setParallelism(1); DataStream<VideoOrder> videoOrderDS = env.addSource(new VideoOrderSource()); DataStream<VideoOrder> filterDS = videoOrderDS.filter(new FilterFunction<VideoOrder>() { @Override public boolean filter(VideoOrder videoOrder) throws Exception { return videoOrder.getMoney()>50; } }); filterDS.print(); filterDS.addSink(new MysqlSink()); //DataStream需要调用execute,可以取个名称 env.execute("custom mysql sink job"); } }
其中,自定义的source
package net.xdclass.app.source; import net.xdclass.model.VideoOrder; import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction; import java.util.*; public class VideoOrderSource extends RichParallelSourceFunction<VideoOrder> { private volatile Boolean flag = true; private Random random = new Random(); private static List<String> list = new ArrayList<>(); static { list.add("spring boot2.x课程"); list.add("微服务SpringCloud课程"); list.add("RabbitMQ消息队列"); list.add("Kafka课程"); list.add("⼩滴课堂⾯试专题第⼀季"); list.add("Flink流式技术课程"); list.add("⼯业级微服务项⽬⼤课训练营"); list.add("Linux课程"); } @Override public void run(SourceContext<VideoOrder> sourceContext) throws Exception { while (flag) { Thread.sleep(1000); String id = UUID.randomUUID().toString(); int userId = random.nextInt(10); int money = random.nextInt(100); int videoNum = random.nextInt(list.size()); String title = list.get(videoNum); sourceContext.collect(new VideoOrder(id,title,money,userId,new Date())); } } @Override public void cancel() { flag = false; } }
自定义的sink:
package net.xdclass.app.sink; import net.xdclass.model.VideoOrder; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.functions.sink.RichSinkFunction; import java.sql.Connection; import java.sql.Date; import java.sql.DriverManager; import java.sql.PreparedStatement; public class MysqlSink extends RichSinkFunction<VideoOrder> { private Connection conn; private PreparedStatement ps; /** * 初始化连接 * @param parameters * @throws Exception */ @Override public void open(Configuration parameters) throws Exception { System.out.println("open======="); conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/world?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&serverTimezone=Asia/Shanghai", "root", "123456"); String sql = "INSERT INTO `video_order` (`user_id`, `money`, `title`, `trade_no`, `create_time`) VALUES(?,?,?,?,?);"; ps = conn.prepareStatement(sql); } /** * 关闭链接 * @throws Exception */ @Override public void close() throws Exception { System.out.println("close======="); if(conn != null){ conn.close(); } if(ps != null){ ps.close();; } } /** * 执行对应的sql * @param value * @param context * @throws Exception */ @Override public void invoke(VideoOrder value, Context context) throws Exception { ps.setInt(1,value.getUserId()); ps.setInt(2,value.getMoney()); ps.setString(3,value.getTitle()); ps.setString(4,value.getTradeNo()); ps.setDate(5,new Date(value.getCreateTime().getTime())); ps.executeUpdate(); } }
说明:
自定义MysqlSink
-
建议继承RichSinkFunction函数
- 用open()函数初始化JDBC连接
- invoke SQL预编译器等运行时环境
- close()函数做清理工作
-
如果选择继承SinkFunction,会在每次写入一条数据时都会创建一个JDBC连接
3.实战Bahir Connetor实战存储 数据到Redis
添加依赖:
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
</dependency>
redis的sink
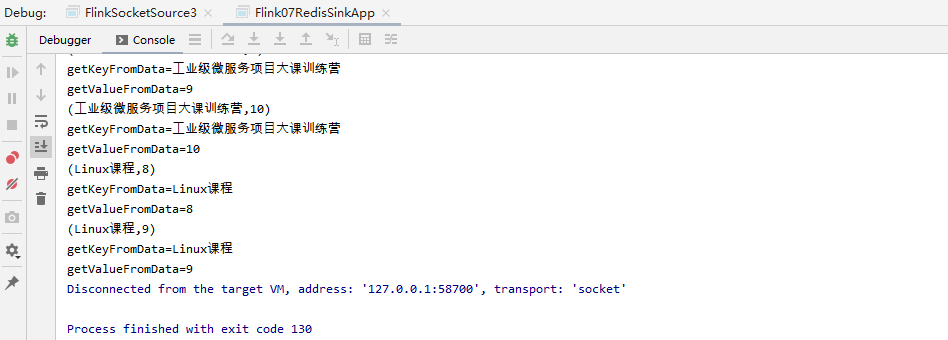
package net.xdclass.app.sink; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription; import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper; /** * **/ public class VideoOrderCounterSink implements<Tuple2<String, Integer>> { /*** * 选择需要用到的命令,和key名称 * @return */ @Override public RedisCommandDescription getCommandDescription() { return new RedisCommandDescription(RedisCommand.HSET, "VIDEO_ORDER_COUNTER"); } /** * 获取对应的key或者filed */ @Override public String getKeyFromData(Tuple2<String, Integer> data) { System.out.println("getKeyFromData=" + data.f0); return data.f0; } /** * 获取对应的值 */ @Override public String getValueFromData(Tuple2<String, Integer> data) { System.out.println("getValueFromData=" + data.f1.toString()); return data.f1.toString(); } }
实战程序:
package net.xdclass.app.sink; import net.xdclass.app.source.VideoOrderSource; import net.xdclass.model.VideoOrder; import org.apache.flink.api.common.RuntimeExecutionMode; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.redis.RedisSink; import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig; import java.util.Date; /** * apche bahir connector */ public class Flink07RedisSinkApp { public static void main(String[] args) throws Exception { //构建执行任务环境以及任务的启动的入口, 存储全局相关的参数 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); env.setParallelism(1); DataStream<VideoOrder> ds = env.addSource(new VideoOrderSource()); //transformation DataStream<Tuple2<String, Integer>> mapDS = ds.map(new MapFunction<VideoOrder, Tuple2<String, Integer>>() { @Override public Tuple2<String, Integer> map(VideoOrder value) throws Exception { return new Tuple2<>(value.getTitle(), 1); } }); //分组 KeyedStream<Tuple2<String, Integer>, String> keyByDS = mapDS.keyBy(new KeySelector<Tuple2<String, Integer>, String>() { @Override public String getKey(Tuple2<String, Integer> value) throws Exception { return value.f0; } }); //统计每组有多少个 DataStream<Tuple2<String, Integer>> sumDS = keyByDS.sum(1); //控制台打印 sumDS.print(); //单机redis FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("127.0.0.1").setPort(6379).build(); sumDS.addSink(new RedisSink<>(conf, new VideoOrderCounterSink())); //DataStream需要调用execute,可以取个名称 env.execute("custom redis sink job"); } }
效果:

4.核⼼Source Sink对接 Kafka Connetor实战
创建topic:
bin/kafka-topics.sh --create --zookeeper 192.168.19.131:2181 --replication-factor 1 --partitions 1 --topic xdclass-topic
查看topic:
bin/kafka-topics.sh --list --zookeeper 192.168.19.131:2181
生产者发送消息:
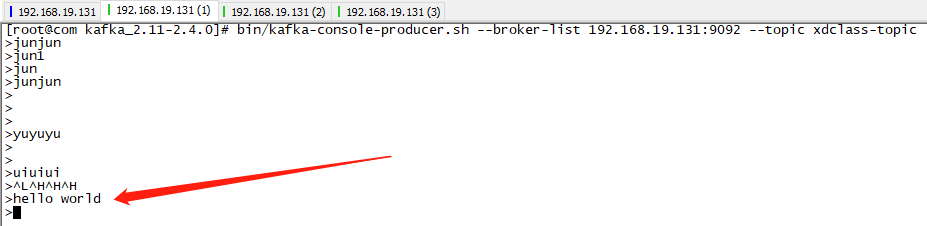
bin/kafka-console-producer.sh --broker-list 192.168.19.131:9092 --topic xdclass-topic
消费者消费消息:
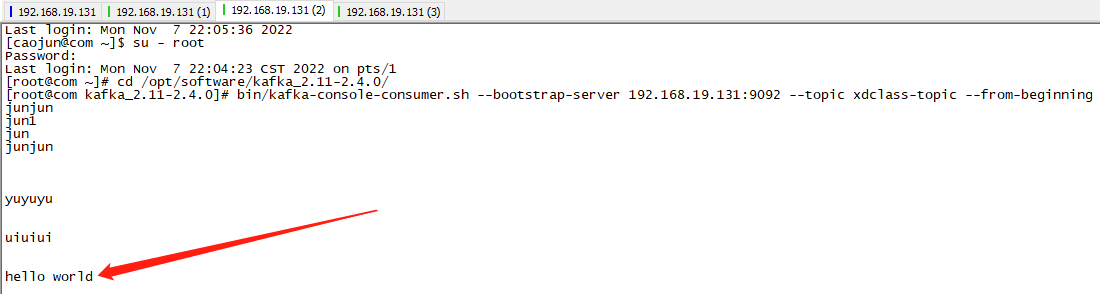
bin/kafka-console-consumer.sh --bootstrap-server 192.168.19.131:9092 --topic xdclass-topic --from-beginning
5.从kafka中读取消息,以及将消息写到kafka中
flink官方提供的连接器
添加依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
运行程序:
package net.xdclass.app.source; import org.apache.flink.api.common.RuntimeExecutionMode; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer; import java.util.Properties; /** * 从kafka中读取数据 */ public class KafkaSource { public static void main(String[] args) throws Exception { //构建执行任务环境以及任务的启动的入口, 存储全局相关的参数 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); Properties props = new Properties(); //kafka地址 props.setProperty("bootstrap.servers", "192.168.19.131:9092"); //组名 props.setProperty("group.id", "video-order-group"); //字符串序列化和反序列化规则 props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); //offset重置规则 props.setProperty("auto.offset.reset", "latest"); //自动提交 props.setProperty("enable.auto.commit", "true"); props.setProperty("auto.commit.interval.ms", "2000"); //有后台线程每隔10s检测一下Kafka的分区变化情况 props.setProperty("flink.partition-discovery.interval-millis", "10000"); FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<String>("xdclass-topic", new SimpleStringSchema(), props); //设置从记录的消费者组内的offset开始消费 consumer.setStartFromGroupOffsets(); DataStream<String> kafkaDS = env.addSource(consumer); kafkaDS.print("kafka:"); DataStream<String> mapDS = kafkaDS.map(new MapFunction<String, String>() { @Override public String map(String value) throws Exception { return "hahaha:" + value; } }); FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<String>("xdclass-order", new SimpleStringSchema(), props); mapDS.addSink(producer); //DataStream需要调用execute,可以取个名称 env.execute("kafka source job"); } }
生产者:
bin/kafka-console-producer.sh --broker-list 192.168.19.131:9092 --topic xdclass-topic
对应的消费者:
bin/kafka-console-consumer.sh --bootstrap-server 192.168.19.131:9092 --topic xdclass-topic --from-beginning
程序中写的topic,得到的消费:
bin/kafka-console-consumer.sh --bootstrap-server 192.168.19.131:9092 --topic xdclass-order

五:Transformation
1.map
package net.xdclass.app.transformation; import net.xdclass.model.VideoOrder; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.Date; /** * map算子 */ public class MapTransformation { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); final DataStreamSource<VideoOrder> ds = env.fromElements(new VideoOrder("22333", "java", 20, 10, new Date()), new VideoOrder("445534", "go", 30, 20, new Date()), new VideoOrder("9986", "python", 40, 30, new Date()), new VideoOrder("23232", "java", 40, 30, new Date()) ); final SingleOutputStreamOperator<Tuple2<String, Integer>> mapDS = ds.map(new MapFunction<VideoOrder, Tuple2<String, Integer>>() { @Override public Tuple2<String, Integer> map(VideoOrder value) throws Exception { return new Tuple2<>(value.getTitle(), 1); } }); mapDS.print(); env.execute("map算子"); } }
2.flatmap
package net.xdclass.app.transformation; import net.xdclass.model.VideoOrder; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; import java.util.Date; /** * flatmap算子 */ public class FlatMapTransformation { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); final DataStreamSource<VideoOrder> ds = env.fromElements(new VideoOrder("22333", "java", 20, 10, new Date()), new VideoOrder("445534", "go", 30, 20, new Date()), new VideoOrder("9986", "python", 40, 30, new Date()), new VideoOrder("23232", "java", 40, 30, new Date()) ); SingleOutputStreamOperator<Tuple2<String, Integer>> flatMapDS = ds.flatMap(new FlatMapFunction<VideoOrder, Tuple2<String, Integer>>() { @Override public void flatMap(VideoOrder videoOrder, Collector<Tuple2<String, Integer>> collector) throws Exception { collector.collect(new Tuple2<>(videoOrder.getTitle(), 1)); } }); flatMapDS.print(); env.execute("flatmap算子"); } }
3.RichMap和RichFlatMap 算子
-
Rich相关的api更丰富,多了Open、Close方法,用于初始化连接等
-
RichXXX相关Open、Close、setRuntimeContext等 API方法会根据并行度进行操作的
- 比如并行度是4,那就有4次触发对应的open/close方法等,是4个不同subtask
- 比如 RichMapFunction、RichFlatMapFunction、RichSourceFunction等
程序:
package net.xdclass.app.transformation; import net.xdclass.model.VideoOrder; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.functions.RichMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.Date; /** * RichMap算子 */ public class RichMapTransformation { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(2); final DataStreamSource<VideoOrder> ds = env.fromElements(new VideoOrder("22333", "java", 20, 10, new Date()), new VideoOrder("445534", "go", 30, 20, new Date()), new VideoOrder("9986", "python", 40, 30, new Date()), new VideoOrder("23232", "java", 40, 30, new Date()) ); SingleOutputStreamOperator<Tuple2<String, Integer>> mapDs = ds.map(new RichMapFunction<VideoOrder, Tuple2<String, Integer>>() { @Override public Tuple2<String, Integer> map(VideoOrder videoOrder) throws Exception { return new Tuple2<>(videoOrder.getTitle(), 1); } @Override public void open(Configuration parameters) throws Exception { super.open(parameters); System.out.println("open===="); } @Override public void close() throws Exception { System.out.println("close===="); } }); mapDs.print(); env.execute("rich map算子"); } }
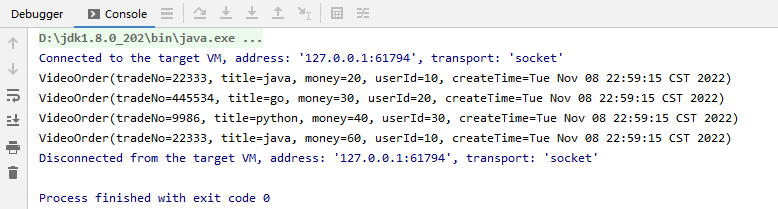
4.KeyBy分组与sum
KeyBy分组概念介绍
- keyBy是把数据流按照某个字段分区
- keyBy后是相同的数据放到同个组里面,再进行组内统计
package net.xdclass.app.transformation; import net.xdclass.model.VideoOrder; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.Date; /** * keyby分组 */ public class KeyByTransformation { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); final DataStreamSource<VideoOrder> ds = env.fromElements( new VideoOrder("22333", "java", 20, 10, new Date()), new VideoOrder("445534", "go", 30, 20, new Date()), new VideoOrder("9986", "python", 40, 30, new Date()), new VideoOrder("23232", "java", 40, 30, new Date()) ); final KeyedStream<VideoOrder, String> keyedStream = ds.keyBy(new KeySelector<VideoOrder, String>() { @Override public String getKey(VideoOrder videoOrder) throws Exception { return videoOrder.getTitle(); } }); final SingleOutputStreamOperator<VideoOrder> sumDS = keyedStream.sum("money"); sumDS.print(); env.execute("keyby分组"); } }
效果:
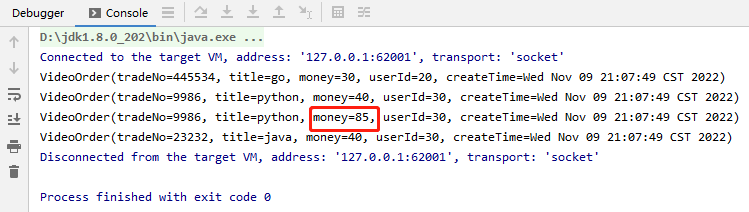
5.filter与sum算子
package net.xdclass.app.transformation; import net.xdclass.model.VideoOrder; import org.apache.flink.api.common.functions.FilterFunction; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.Date; /** * filter算子 */ public class FilterTransformation { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); final DataStreamSource<VideoOrder> ds = env.fromElements( new VideoOrder("22333", "java", 20, 10, new Date()), new VideoOrder("445534", "go", 30, 20, new Date()), new VideoOrder("9986", "python", 40, 30, new Date()), new VideoOrder("76767", "python", 45, 70, new Date()), new VideoOrder("23232", "java", 40, 30, new Date()) ); final SingleOutputStreamOperator<VideoOrder> moneySumDS = ds.filter(new FilterFunction<VideoOrder>() { @Override public boolean filter(VideoOrder videoOrder) throws Exception { return videoOrder.getMoney() > 25; } }).keyBy(new KeySelector<VideoOrder, String>() { @Override public String getKey(VideoOrder videoOrder) throws Exception { return videoOrder.getTitle(); } }).sum("money"); moneySumDS.print(); env.execute("filter"); } }
效果:
6.reduce
- keyBy分组后聚合统计sum和reduce实现一样的效果
- sum是简单聚合,reduce是可以自定义聚合
程序:
package net.xdclass.app.transformation; import net.xdclass.model.VideoOrder; import org.apache.flink.api.common.functions.ReduceFunction; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.Date; /** * reduce算子 * keyBy分组后聚合统计sum和reduce实现一样的效果 */ public class ReduceTransformation { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); final DataStreamSource<VideoOrder> ds = env.fromElements( new VideoOrder("22333", "java", 20, 10, new Date()), new VideoOrder("445534", "go", 30, 20, new Date()), new VideoOrder("9986", "python", 40, 30, new Date()), new VideoOrder("76767", "python", 45, 70, new Date()), new VideoOrder("23232", "java", 40, 30, new Date()) ); final KeyedStream<VideoOrder, String> keyByDS = ds.keyBy(new KeySelector<VideoOrder, String>() { @Override public String getKey(VideoOrder videoOrder) throws Exception { return videoOrder.getTitle(); } }); final SingleOutputStreamOperator<VideoOrder> reduceDS = keyByDS.reduce(new ReduceFunction<VideoOrder>() { @Override public VideoOrder reduce(VideoOrder videoOrder1, VideoOrder videoOrder2) throws Exception { VideoOrder videoOrder = new VideoOrder(); videoOrder.setTitle(videoOrder1.getTitle()); videoOrder.setMoney(videoOrder1.getMoney() + videoOrder2.getMoney()); return videoOrder; } }); reduceDS.print(); env.execute("reduce job"); } }
效果:
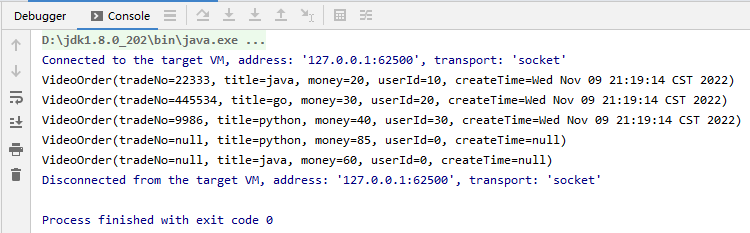
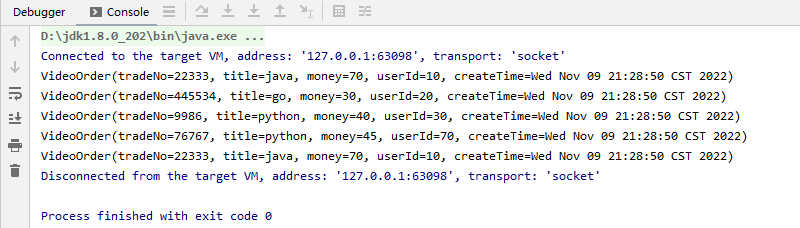
7.maxBy-max-minBy-min 区别和应用
-
如果是用了keyby,在后续算子要用maxby,minby类型,才可以再分组里面找对应的数据
- 如果是用max、min等,就不确定是哪个key中选了
- 如果是keyBy的是对象的某个属性,则分组用max/min聚合统计,只有聚合的字段会更新,其他字段还是旧的,导致对象不准确
- 需要用maxby/minBy才对让整个对象的属性都是最新的
程序:
package net.xdclass.app.transformation; import net.xdclass.model.VideoOrder; import org.apache.flink.api.common.functions.ReduceFunction; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.util.Date; /** * maxBy算子 */ public class MaxByTransformation { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); final DataStreamSource<VideoOrder> ds = env.fromElements( new VideoOrder("22333", "java", 70, 10, new Date()), new VideoOrder("445534", "go", 30, 20, new Date()), new VideoOrder("9986", "python", 40, 30, new Date()), new VideoOrder("76767", "python", 45, 70, new Date()), new VideoOrder("23232", "java", 30, 30, new Date()) ); final KeyedStream<VideoOrder, String> keyByDS = ds.keyBy(new KeySelector<VideoOrder, String>() { @Override public String getKey(VideoOrder videoOrder) throws Exception { return videoOrder.getTitle(); } }); final SingleOutputStreamOperator<VideoOrder> moneyDS = keyByDS.maxBy("money"); moneyDS.print(); env.execute("reduce job"); } }
效果:
六:Flink滑动
1.理解
-
背景
- 数据流是一直源源不断产生,业务需要聚合统计使用,比如每10秒统计过去5分钟的点击量、成交额等
- Windows 就可以将无限的数据流拆分为有限大小的“桶 buckets”,然后程序可以对其窗口内的数据进行计算
- 窗口认为是Bucket桶,一个窗口段就是一个桶,比如8到9点是一个桶,9到10点是一个桶
-
分类
-
time Window 时间窗口,即按照一定的时间规则作为窗口统计
- time-tumbling-window 时间滚动窗口 (用的多)
- time-sliding-window 时间滑动窗口 (用的多)
- session WIndow 会话窗口,即一个会话内的数据进行统计,相对少用
-
count Window 数量窗口,即按照一定的数据量作为窗口统计,相对少用
-
-
窗口属性
-
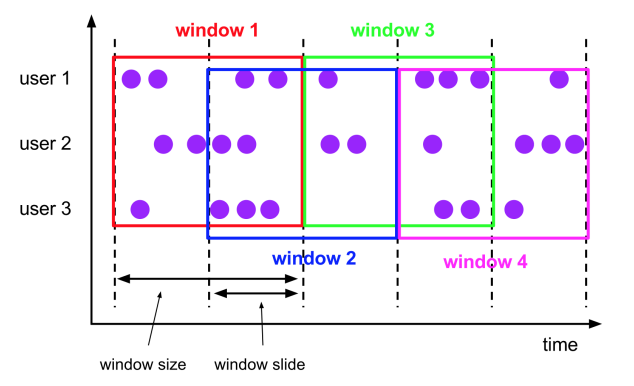
滑动窗口 Sliding Windows
- 窗口具有固定大小
- 窗口数据有重叠
- 例子:每10s统计一次最近1min内的订单数量
![]()
-
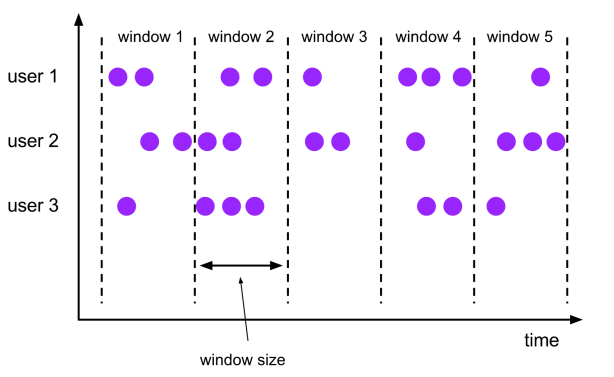
滚动窗口 Tumbling Windows
- 窗口具有固定大小
- 窗口数据不重叠
- 例子:每10s统计一次最近10s内的订单数量
![]()
-
窗口大小size 和 滑动间隔 slide
- tumbling-window:滚动窗口: size=slide,如:每隔10s统计最近10s的数据
- sliding-window:滑动窗口: size>slide,如:每隔5s统计最近10s的数据
- size<slide的时候,如每隔15s统计最近10s的数据,那么中间5s的数据会丢失,所以开发中不用
-
2.Window窗口API
什么情况下才可以使⽤WindowAPI
有keyBy ⽤ window() api
没keyBy ⽤ windowAll() api ,并⾏度低
⽅括号 ([…]) 中的命令是可选的,允许⽤多种不同的⽅式⾃定 义窗⼝逻辑

3.继续理解
-
一个窗口内 的是左闭右开
-
countWindow没过期,但timeWindow在1.12过期,统一使用window;
-
窗口分配器 Window Assigners
- 定义了如何将元素分配给窗口,负责将每条数据分发到正确的 window窗口上
- window() 的参数是一个 WindowAssigner,flink本身提供了Tumbling、Sliding 等Assigner
-
窗口触发器 trigger
- 用来控制一个窗口是否需要被触发
- 每个 窗口分配器WindowAssigner 都有一个默认触发器,也支持自定义触发器
-
窗口 window function ,对窗口内的数据做啥?
-
定义了要对窗口中收集的数据做的计算操作
-
增量聚合函数
aggregate(agg函数,WindowFunction(){ })- 窗口保存临时数据,每进入一个新数据,会与中间数据累加,生成新的中间数据,再保存到窗口中
- 常见的增量聚合函数有 reduceFunction、aggregateFunction
- min、max、sum 都是简单的聚合操作,不需要自定义规则
AggregateFunction<IN, ACC, OUT>IN是输入类型,ACC是中间聚合状态类型,OUT是输出类型,是聚合统计当前窗口的数据 -
全窗口函数
apply(new processWindowFunction(){ })- 窗口先缓存该窗口所有元素,等窗口的全部数据收集起来后再触发条件计算
- 常见的全窗口聚合函数 windowFunction(未来可能弃用)、processWindowFunction(可以获取到窗口上下文 更多信息)
IN是输入类型,OUT是输出类型,KEY是分组类型,W是时间窗WindowFunction<IN, OUT, KEY, W extends Window> -
如果想处理每个元素更底层的API的时候用
//对数据进行解析 ,process对每个元素进行处理,相当于 map+flatMap+filterprocess(new KeyedProcessFunction(){processElement、onTimer})
-
4.滚动窗口
滚动窗口 Tumbling Windows
- 窗口具有固定大小
- 窗口数据不重叠
-
比如指定了一个5分钟大小的滚动窗口,无限流的数据会根据时间划分为[0:00, 0:05)、[0:05, 0:10)、[0:10, 0:15)等窗口
程序:
数据源产生:
package net.xdclass.app.window; import net.xdclass.model.VideoOrder; import net.xdclass.utils.TimeUtil; import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction; import java.util.*; public class VideoOrderSource2 extends RichParallelSourceFunction<VideoOrder> { private volatile Boolean flag = true; private Random random = new Random(); private static List<VideoOrder> list = new ArrayList<>(); static { list.add(new VideoOrder("", "java", 10, 0, null)); list.add(new VideoOrder("", "spring boot", 15, 0, null)); } @Override public void run(SourceContext<VideoOrder> sourceContext) throws Exception { while (flag) { Thread.sleep(2000); String id = UUID.randomUUID().toString().substring(30); int userId = random.nextInt(10); int videoNum = random.nextInt(list.size()); VideoOrder videoOrder = list.get(videoNum); videoOrder.setUserId(userId); videoOrder.setCreateTime(new Date()); videoOrder.setTradeNo(id); System.out.println("产生:"+videoOrder.getTitle()+",价格:"+videoOrder.getMoney()+", 时间:"+ TimeUtil.format(videoOrder.getCreateTime())); sourceContext.collect(videoOrder); } } @Override public void cancel() { flag = false; } }
main函数:
package net.xdclass.app.window; import net.xdclass.model.VideoOrder; import org.apache.flink.api.common.RuntimeExecutionMode; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; /** * 滚动窗口 */ public class TumbingWindow { public static void main(String[] args) throws Exception { //构建执行任务环境以及任务的启动的入口, 存储全局相关的参数 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); env.setParallelism(1); //数据源 source DataStream<VideoOrder> ds = env.addSource(new VideoOrderSource2()); KeyedStream<VideoOrder, String> keyByDS = ds.keyBy(new KeySelector<VideoOrder, String>() { @Override public String getKey(VideoOrder value) throws Exception { return value.getTitle(); } }); DataStream<VideoOrder> sumDS = keyByDS.window(TumblingProcessingTimeWindows.of(Time.seconds(5))).sum("money"); sumDS.print(">>>"); //DataStream需要调用execute,可以取个名称 env.execute("tumbling window job"); } }
效果:
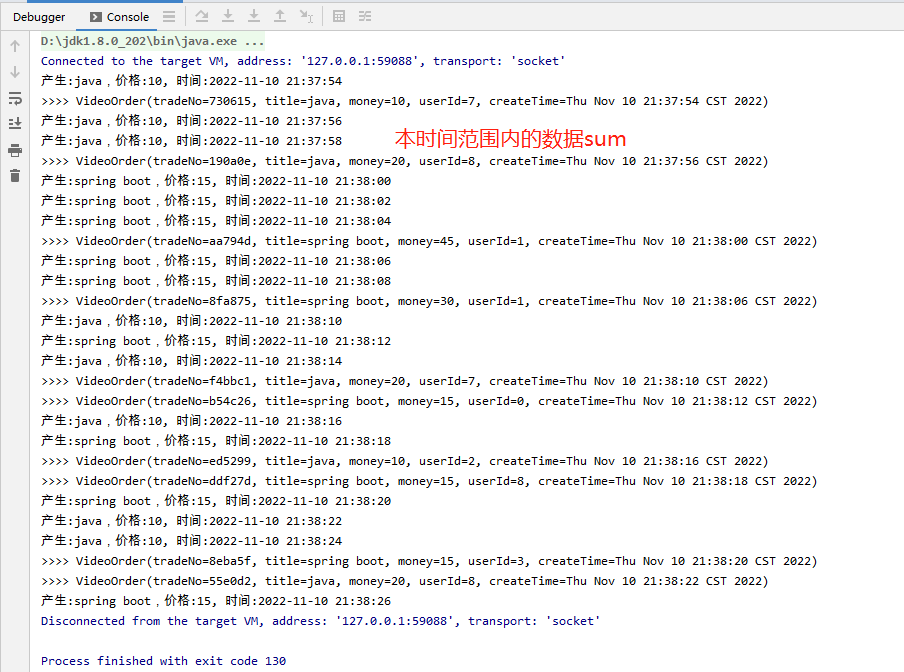
5.滑动窗口
-
滑动窗口 Sliding Windows
- 窗口具有固定大小
- 窗口数据有重叠
- 例子:每10s统计一次最近1min内的订单数量
-
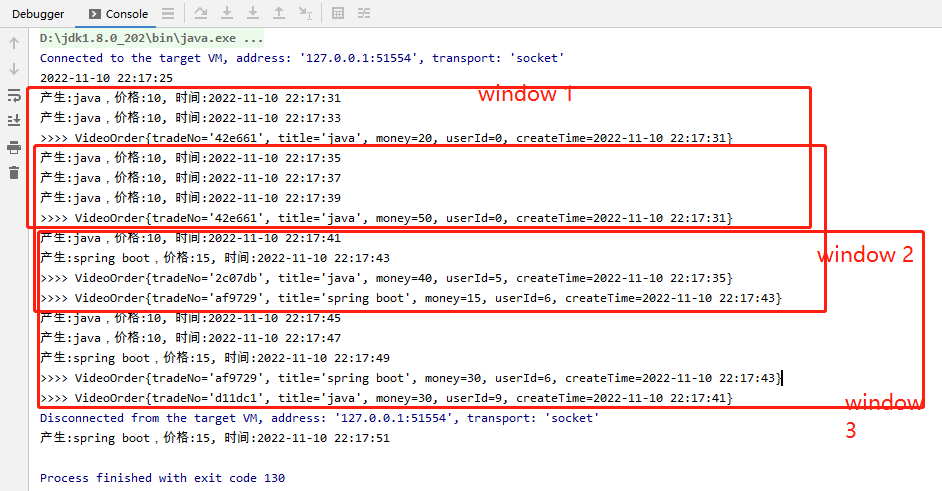
案例实战
- 每5秒统计过去20秒的不同视频的订单总价
程序:
package net.xdclass.app.window; import net.xdclass.model.VideoOrder; import net.xdclass.utils.TimeUtil; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import java.util.Date; /** * 滑动窗口 * 每5秒统计过去10秒的不同视频的订单总价 */ public class SlidingWindow { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); final DataStreamSource<VideoOrder> ds = env.addSource(new VideoOrderSource2()); final KeyedStream<VideoOrder, String> keyByDS = ds.keyBy(new KeySelector<VideoOrder, String>() { @Override public String getKey(VideoOrder videoOrder) throws Exception { return videoOrder.getTitle(); } }); SingleOutputStreamOperator<VideoOrder> moneySum = keyByDS.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))).sum("money"); System.out.println(TimeUtil.format(new Date())); moneySum.print(">>>"); env.execute("滑动窗口job"); } }
效果:
6.countWindow
-
基于数量的滚动窗口, 滑动计数窗口
-
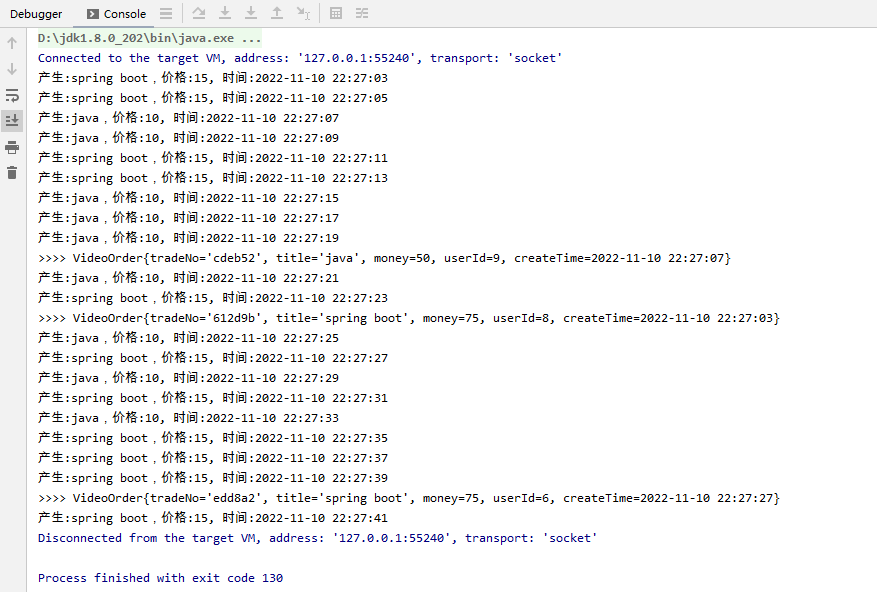
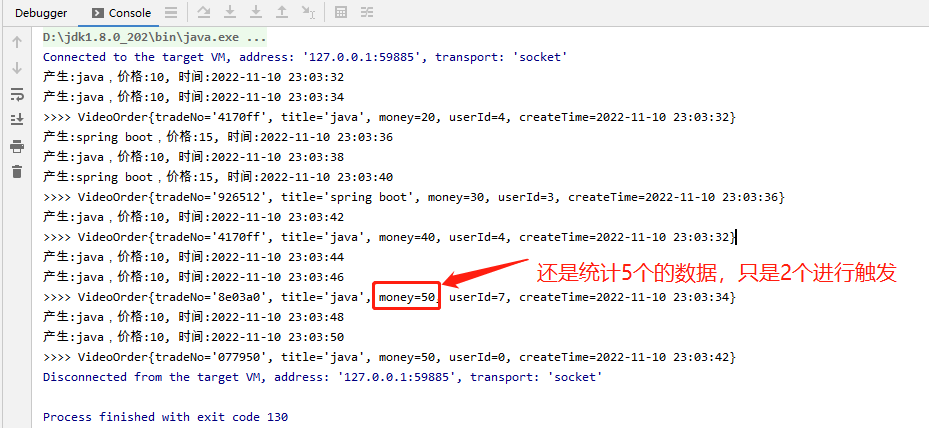
案例:
- 统计分组后同个key内的数据超过5次则进行统计 countWindow(5)
- 只要有2个数据到达后就可以往后统计5个数据的值, countWindow(5, 2)
第一种情况的统计:
package net.xdclass.app.window; import net.xdclass.model.VideoOrder; import net.xdclass.utils.TimeUtil; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import java.util.Date; /** * count窗口 */ public class CountWindow { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); final DataStreamSource<VideoOrder> ds = env.addSource(new VideoOrderSource2()); final KeyedStream<VideoOrder, String> keyByDS = ds.keyBy(new KeySelector<VideoOrder, String>() { @Override public String getKey(VideoOrder videoOrder) throws Exception { return videoOrder.getTitle(); } }); SingleOutputStreamOperator<VideoOrder> moneySum = keyByDS.countWindow(5).sum("money"); moneySum.print(">>>"); env.execute("滑动窗口job"); } }
效果:
第二种情况案例程序:
package net.xdclass.app.window; import net.xdclass.model.VideoOrder; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; /** * count窗口 * 只要有2个数据到达后就可以往后统计5个数据的值, countWindow(5, 2) */ public class Count2Window { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); final DataStreamSource<VideoOrder> ds = env.addSource(new VideoOrderSource2()); final KeyedStream<VideoOrder, String> keyByDS = ds.keyBy(new KeySelector<VideoOrder, String>() { @Override public String getKey(VideoOrder videoOrder) throws Exception { return videoOrder.getTitle(); } }); SingleOutputStreamOperator<VideoOrder> moneySum = keyByDS.countWindow(5, 2).sum("money"); moneySum.print(">>>"); env.execute("滑动窗口job"); } }
效果:
七:增量聚合和全窗口函数
1.增量聚合AggregateFunction
窗口 window function ,对窗口内的数据做啥?
-
定义了要对窗口中收集的数据做的计算操作
-
增量聚合函数
aggregate(agg函数,WindowFunction(){ })- 窗口保存临时数据,每进入一个新数据,会与中间数据累加,生成新的中间数据,再保存到窗口中
- 常见的增量聚合函数有 ReduceFunction、AggregateFunction
- min、max、sum 都是简单的聚合操作,不需要自定义规则
AggregateFunction<IN, ACC, OUT>IN是输入类型,ACC是中间聚合状态类型,OUT是输出类型,是聚合统计当前窗口的数据
程序:
package net.xdclass.app.window; import net.xdclass.model.VideoOrder; import org.apache.flink.api.common.RuntimeExecutionMode; import org.apache.flink.api.common.functions.AggregateFunction; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.datastream.WindowedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; /** * 滚动窗口的增量聚合 */ public class TumbingAggregateWindow { public static void main(String[] args) throws Exception { //构建执行任务环境以及任务的启动的入口, 存储全局相关的参数 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC); env.setParallelism(1); //数据源 source DataStream<VideoOrder> ds = env.addSource(new VideoOrderSource2()); KeyedStream<VideoOrder, String> keyByDS = ds.keyBy(new KeySelector<VideoOrder, String>() { @Override public String getKey(VideoOrder value) throws Exception { return value.getTitle(); } }); WindowedStream<VideoOrder, String, TimeWindow> windowDS = keyByDS.window(TumblingProcessingTimeWindows.of(Time.seconds(5))); final SingleOutputStreamOperator<VideoOrder> aggregateDS = windowDS.aggregate(new AggregateFunction<VideoOrder, VideoOrder, VideoOrder>() { @Override public VideoOrder createAccumulator() { VideoOrder videoOrder = new VideoOrder(); return videoOrder; } @Override public VideoOrder add(VideoOrder videoOrder, VideoOrder accumulator) { accumulator.setTitle(videoOrder.getTitle()); accumulator.setMoney(videoOrder.getMoney() + accumulator.getMoney()); if(accumulator.getCreateTime()==null){ accumulator.setCreateTime(videoOrder.getCreateTime()); } return accumulator; } @Override public VideoOrder getResult(VideoOrder accumulator) { return accumulator; } @Override public VideoOrder merge(VideoOrder videoOrder, VideoOrder acc1) { return null; } }); aggregateDS.print(">>>"); //DataStream需要调用execute,可以取个名称 env.execute("tumbling window job"); } }
效果:
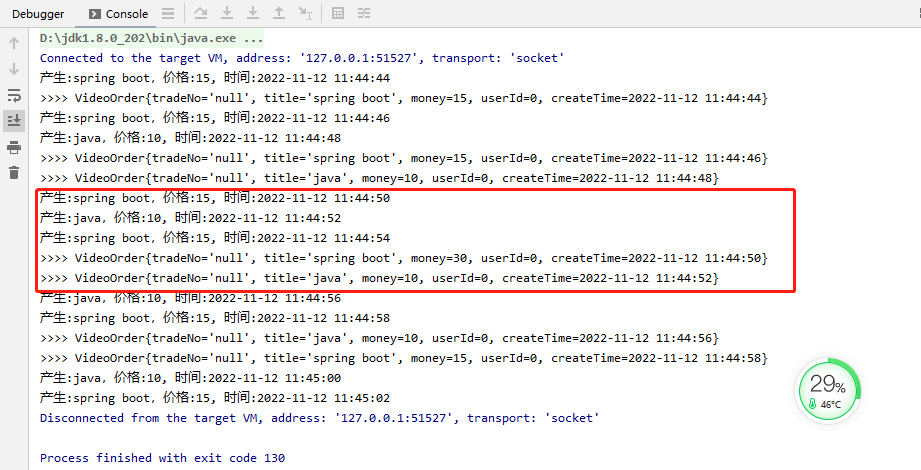
2.全窗口函数【先说windowFunction】
-
-
apply(new WindowFunction(){ })- 窗口先缓存该窗口所有元素,等窗口的全部数据收集起来后再触发条件计算
- 常见的全窗口聚合函数 windowFunction(未来可能弃用)、processWindowFunction(可以获取到窗口上下文 更多信息,包括窗口信息)
WindowFunction<IN, OUT, KEY, W extends Window>
IN是输入类型,OUT是输出类型,KEY是分组类型,W是时间窗
-
程序:
package net.xdclass.app.window; import net.xdclass.model.VideoOrder; import net.xdclass.utils.TimeUtil; import org.apache.commons.collections.IteratorUtils; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.datastream.WindowedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.windowing.WindowFunction; import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.util.Collector; import org.apache.flink.util.IterableUtils; import java.util.Date; import java.util.List; import java.util.stream.Collectors; import static sun.security.krb5.Confounder.intValue; /** * 滑动窗口 * 每5秒统计过去10秒的不同视频的订单总价 */ public class SlidingApplyWindow { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); final DataStreamSource<VideoOrder> ds = env.addSource(new VideoOrderSource2()); final KeyedStream<VideoOrder, String> keyByDS = ds.keyBy(new KeySelector<VideoOrder, String>() { @Override public String getKey(VideoOrder videoOrder) throws Exception { return videoOrder.getTitle(); } }); WindowedStream<VideoOrder, String, TimeWindow> windowDS = keyByDS.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))); final SingleOutputStreamOperator<VideoOrder> applyDS = windowDS.apply(new WindowFunction<VideoOrder, VideoOrder, String, TimeWindow>() { @Override public void apply(String key, TimeWindow timeWindow, Iterable<VideoOrder> iterable, Collector<VideoOrder> collector) throws Exception { List<VideoOrder> list = IteratorUtils.toList(iterable.iterator()); int total = list.stream().mapToInt(VideoOrder::getMoney).sum(); VideoOrder videoOrder = new VideoOrder(); videoOrder.setMoney(total); videoOrder.setTitle(list.get(0).getTitle()); videoOrder.setCreateTime(list.get(0).getCreateTime()); collector.collect(videoOrder); } }); applyDS.print(">>>"); env.execute("滑动窗口job"); } }
效果:
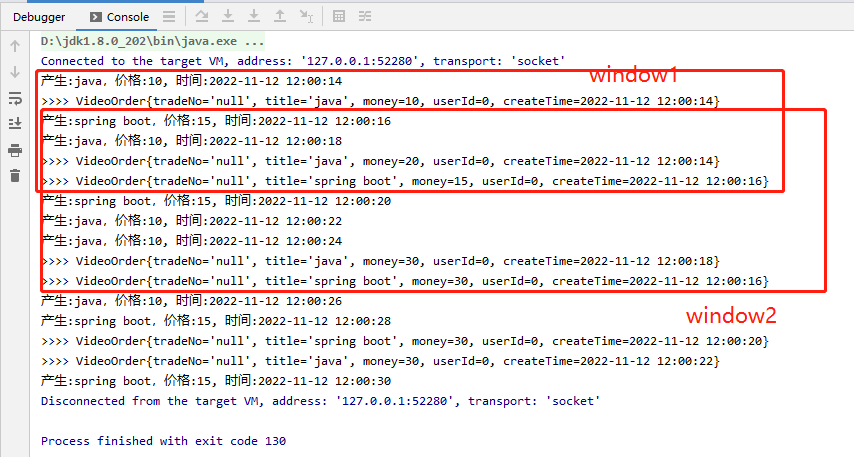
3.全窗口函数【先说processFunction】
-
-
process(new ProcessWindowFunction(){})- 窗口先缓存该窗口所有元素,等窗口的全部数据收集起来后再触发条件计算
- 常见的全窗口聚合函数 windowFunction(未来可能弃用)、processWindowFunction(可以获取到窗口上下文 更多信息,包括窗口信息)
ProcessWindowFunction<IN, OUT, KEY, W extends Window>
IN是输入类型,OUT是输出类型,KEY是分组类型,W是时间窗
-
程序:
package net.xdclass.app.window; import net.xdclass.model.VideoOrder; import org.apache.commons.collections.IteratorUtils; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.datastream.WindowedStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction; import org.apache.flink.streaming.api.functions.windowing.WindowFunction; import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.util.Collector; import java.util.List; /** * 滑动窗口的processFunction全量窗口 * 每5秒统计过去10秒的不同视频的订单总价 */ public class SlidingProcessWindow { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); final DataStreamSource<VideoOrder> ds = env.addSource(new VideoOrderSource2()); final KeyedStream<VideoOrder, String> keyByDS = ds.keyBy(new KeySelector<VideoOrder, String>() { @Override public String getKey(VideoOrder videoOrder) throws Exception { return videoOrder.getTitle(); } }); WindowedStream<VideoOrder, String, TimeWindow> windowDS = keyByDS.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5))); final SingleOutputStreamOperator<VideoOrder> applyDS = windowDS.process(new ProcessWindowFunction<VideoOrder, VideoOrder, String, TimeWindow>() { @Override public void process(String key, Context context, Iterable<VideoOrder> iterable, Collector<VideoOrder> collector) throws Exception { List<VideoOrder> list = IteratorUtils.toList(iterable.iterator()); int total = list.stream().mapToInt(VideoOrder::getMoney).sum(); VideoOrder videoOrder = new VideoOrder(); videoOrder.setMoney(total); videoOrder.setTitle(list.get(0).getTitle()); videoOrder.setCreateTime(list.get(0).getCreateTime()); collector.collect(videoOrder); } }); applyDS.print(">>>"); env.execute("滑动窗口job"); } }
效果:
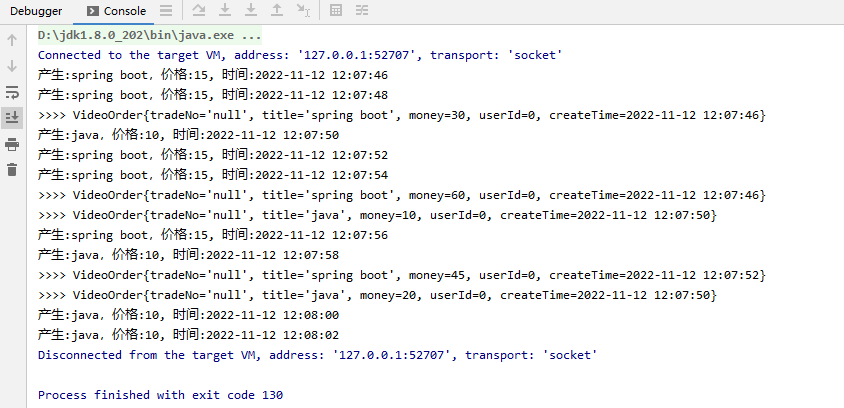
八:迟到的乱序数据处理
1.时间概念说明
-
背景
- 前面我们使用了Window窗口函数,flink怎么知道哪个是字段是对应的时间呢?
- 由于网络问题,数据先产生,但是乱序延迟了,那属于哪个时间窗呢?
- Flink里面定义窗口,可以引用不同的时间概念
-
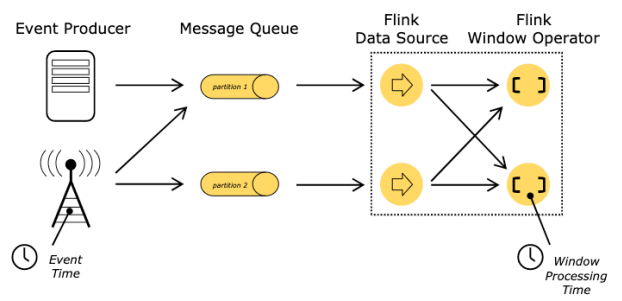
Flink里面时间分类
-
事件时间EventTime(重点关注)
- 事件发生的时间
- 事件时间是每个单独事件在其产生进程上发生的时间,这个时间通常在记录进入 Flink 之前记录在对象中
- 在事件时间中,时间值 取决于数据产生记录的时间,而不是任何Flink机器上的
-
进入时间 IngestionTime
- 事件到进入Flink
-
处理时间ProcessingTime
-
事件被flink处理的时间
-
指正在执行相应操作的机器的系统时间
-
是最简单的时间概念,不需要流和机器之间的协调,它提供最佳性能和最低延迟
-
但是在分布式和异步环境中,处理时间有不确定性,存在延迟或乱序问题
![]()
-
-
-
大家的疑惑
- 事件时间已经能够解决所有的问题了,那为何还要用处理时间呢????
- 处理时间由于不用考虑事件的延迟与乱序,所以处理数据的速度高效
- 如果一些应用比较重视处理速度而非准确性,那么就可以使用处理时间,但结果具有不确定性
- 事件时间有延迟,但是能够保证处理的结果具有准确性,并且可以处理延迟甚至无序的数据
-
举个例子
-
小滴课堂-老王 做了一个电商平台买 "超短男装衣服",如果要统计10分钟内成交额,你认为是哪个时间比较好?
- (EventTime) 下单支付时间是2022-11-11 01-01-01
- (IngestionTime ) 进入Flink时间2022-11-11 01-03-01(网络拥堵、延迟)
- (ProcessingTime)进入窗口时间2022-11-11 01-31-01(网络拥堵、延迟)
-
2.乱序延迟时间处理-Watermark讲解
-
背景
-
一般我们都是用EventTime事件时间进行处理统计数据
-
但数据由于网络问题延迟、乱序到达会导致窗口计算数据不准确
-
需求:比如时间窗是 [12:01:01,12:01:10 ) ,但是有数据延迟到达
- 当 12:01:10 秒数据到达的时候,不立刻触发窗口计算
- 而是等一定的时间,等迟到的数据来后再关闭窗口进行计算
-
-
生活中的例子
-
小滴课堂:每天10点后就是迟到,需要扣工资
-
老王上班 路途遥远(延迟) 经常迟到
- HR就规定迟到5分钟后就罚款100元(5分钟就是watermark)
- 迟到30分钟就是上午事假处理 (5~30分就是 allowLateness )
- 不请假都是要来的 (超过30分钟就是侧输出流,sideOutPut兜底)
-
超过5分钟就不用来了吗?还是要来的继续工作的,不然今天上午工资就没了
-
那如果迟到30分钟呢? 也要来的,不然就容易产生更大的问题,缺勤开除。。。。
-
-
Watermark 水位线介绍
-
由flink的某个operator操作生成后,就在整个程序中随event数据流转
- With Periodic Watermarks(周期生成,可以定义一个最大允许乱序的时间,用的很多)
- With Punctuated Watermarks(标点水位线,根据数据流中某些特殊标记事件来生成,相对少)
-
衡量数据是否乱序的时间,什么时候不用等早之前的数据
-
是一个全局时间戳,不是某一个key下的值
-
是一个特殊字段,单调递增的方式,主要是和数据本身的时间戳做比较
-
用来确定什么时候不再等待更早的数据了,可以触发窗口进行计算,忍耐是有限度的,给迟到的数据一些机会
-
注意
- Watermark 设置太小会影响数据准确性,设置太大会影响数据的实时性,更加会加重Flink作业的负担
- 需要经过测试,和业务相关联,得出一个较合适的值即可
-
-
窗口触发计算的时机
-
watermark之前是按照窗口的关闭时间点计算的 [12:01:01,12:01:10 )
-
watermark之后,触发计算的时机
- 窗口内有数据
- Watermaker >= Window EndTime窗口结束时间
-
触发计算后,其他窗口内数据再到达也被丢弃
-
Watermaker = 当前计算窗口最大的事件时间 - 允许乱序延迟的时间
-
3.watermark的案例说明
-
window大小为10s,窗口是W1 [23:12:00~23:12:10) 、 W2[23:12:10~23:12:20)
- 下面是数据的event time
- 数据A 23:12:07
- 数据B 23:12:11
- 数据C 23:12:08
- 数据D 23:12:17
- 数据E 23:12:09
-
没加入watermark,由上到下进入flink
- 数据B到了之后,W1就进行了窗口计算,数据只有A
- 数据C 迟到了3秒,到了之后,由于W1已经计算了,所以就丢失了数据C
-
加入watermark, 允许5秒延迟乱序,由上到下进入flink
-
数据A到达
- watermark = 12:07 - 5 = 12:02 < 12:10 ,所以不触发W1计算, A属于W1
-
数据B到达
- watermark = max{ 12:11, 12:07} - 5 = 12:06 < 12:10 ,所以不触发W1计算, B属于W2
-
数据C到达
- watermark = max{12:08, 12:11, 12:07} - 5 = 12:06 < 12:10 ,所以不触发W1计算, C属于W1
-
数据D到达
- watermark = max{12:17, 12:08, 12:11, 12:07} - 5 = 12:12 > 23:12:10 , 触发W1计算, D属于W2
-
数据E到达
- watermark = max{12:09, 12:17, 12:08, 12:11, 12:07} - 5 = 12:12 > 23:12:10 , 之前已触发W1计算, 所以丢失了E数据,
-
-
Watermaker 计算 = 当前计算窗口最大的事件时间 - 允许乱序延迟的时间
-
什么时候触发W1窗口计算
-
Watermaker >= Window EndTime窗口结束时间
-
当前计算窗口最大的事件时间 - 允许乱序延迟的时间 >= Window EndTime窗口结束时间
-
4.watermark实战
-
需求
- 分组统计不同视频的成交总价
- 数据有乱序延迟,允许3秒的时间
程序:
package net.xdclass.app.watermark; import net.xdclass.utils.TimeUtil; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.api.java.tuple.Tuple3; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.windowing.WindowFunction; import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.util.Collector; import java.time.Duration; import java.util.ArrayList; import java.util.List; public class WatermarkWindow { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // 格式=》 java,2022-11-11 09-10-10,15 final DataStreamSource<String> ds = env.socketTextStream("127.0.0.1", 8888); final SingleOutputStreamOperator<Tuple3<String, String, Integer>> flatMapDS = ds.flatMap(new FlatMapFunction<String, Tuple3<String, String, Integer>>() { @Override public void flatMap(String value, Collector<Tuple3<String, String, Integer>> collector) throws Exception { final String[] split = value.split(","); collector.collect(Tuple3.of(split[0], split[1], Integer.parseInt(split[2]))); } }); // 指定watermark final SingleOutputStreamOperator<Tuple3<String, String, Integer>> watermarkDS = flatMapDS.assignTimestampsAndWatermarks(WatermarkStrategy .<Tuple3<String, String, Integer>>forBoundedOutOfOrderness(Duration.ofSeconds(3)) .withTimestampAssigner((event, timpstamp) -> TimeUtil.strToDate(event.f1).getTime())); // 分组 final KeyedStream<Tuple3<String, String, Integer>, String> keyByDS = watermarkDS.keyBy(new KeySelector<Tuple3<String, String, Integer>, String>() { @Override public String getKey(Tuple3<String, String, Integer> value) throws Exception { return value.f0; } }); // 开窗 final SingleOutputStreamOperator<String> sumDS = keyByDS.window(TumblingEventTimeWindows.of(Time.seconds(10))) .apply(new WindowFunction<Tuple3<String, String, Integer>, String, String, TimeWindow>() { @Override public void apply(String key, TimeWindow timeWindow, Iterable<Tuple3<String, String, Integer>> input, Collector<String> collector) throws Exception { List<String> timeList = new ArrayList<>(); int total = 0; for (Tuple3<String, String, Integer> order : input) { timeList.add(order.f1); total = total + order.f2; } String outStr = String.format("分组key:%s,聚合值:%s,窗口开始结束:[%s~%s),窗口所有事件时间:%s", key, total, TimeUtil.format(timeWindow.getStart()), TimeUtil.format(timeWindow.getEnd()), timeList); collector.collect(outStr); } }); sumDS.print(); env.execute("watermark job"); } }
分析结果:
测试数据
-
窗口 [23:12:00 ~ 23:12:10) | [23:12:10 ~ 23:12:20)
-
java,2022-11-11 23:12:07,10
java,2022-11-11 23:12:11,10
java,2022-11-11 23:12:08,10
mysql,2022-11-11 23:12:13,10
java,2022-11-11 23:12:13,10
java,2022-11-11 23:12:17,10
java,2022-11-11 23:12:09,10
java,2022-11-11 23:12:20,10
java,2022-11-11 23:12:22,10
java,2022-11-11 23:12:23,10
效果:

5.二次兜底allowedLateness
-
背景
- 超过了watermark的等待后,还有延迟数据到达怎么办?
- watermark先输出,然后配置allowedLateness 再延长时间,然后到了后更新之前的窗口数据
要点:
在原有的基础上添加如下程序

完整程序:
package net.xdclass.app.watermark; import net.xdclass.utils.TimeUtil; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.api.java.tuple.Tuple3; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.windowing.WindowFunction; import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.util.Collector; import java.time.Duration; import java.util.ArrayList; import java.util.List; /** * watermark机制中二次兜底 */ public class WatermarkAllowedLatenessWindow { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // 格式=》 java,2022-11-11 09-10-10,15 final DataStreamSource<String> ds = env.socketTextStream("127.0.0.1", 8888); final SingleOutputStreamOperator<Tuple3<String, String, Integer>> flatMapDS = ds.flatMap(new FlatMapFunction<String, Tuple3<String, String, Integer>>() { @Override public void flatMap(String value, Collector<Tuple3<String, String, Integer>> collector) throws Exception { final String[] split = value.split(","); collector.collect(Tuple3.of(split[0], split[1], Integer.parseInt(split[2]))); } }); // 指定watermark final SingleOutputStreamOperator<Tuple3<String, String, Integer>> watermarkDS = flatMapDS.assignTimestampsAndWatermarks(WatermarkStrategy .<Tuple3<String, String, Integer>>forBoundedOutOfOrderness(Duration.ofSeconds(3)) .withTimestampAssigner((event, timpstamp) -> TimeUtil.strToDate(event.f1).getTime())); // 分组 final KeyedStream<Tuple3<String, String, Integer>, String> keyByDS = watermarkDS.keyBy(new KeySelector<Tuple3<String, String, Integer>, String>() { @Override public String getKey(Tuple3<String, String, Integer> value) throws Exception { return value.f0; } }); // 开窗 final SingleOutputStreamOperator<String> sumDS = keyByDS.window(TumblingEventTimeWindows.of(Time.seconds(10))) .allowedLateness(Time.minutes(1)) .apply(new WindowFunction<Tuple3<String, String, Integer>, String, String, TimeWindow>() { @Override public void apply(String key, TimeWindow timeWindow, Iterable<Tuple3<String, String, Integer>> input, Collector<String> out) throws Exception { List<String> timeList = new ArrayList<>(); int total = 0; for (Tuple3<String, String, Integer> order : input) { timeList.add(order.f1); total = total + order.f2; } String outStr = String.format("分组key:%s,聚合值:%s,窗口开始结束:[%s~%s),窗口所有事件时间:%s", key, total, TimeUtil.format(timeWindow.getStart()), TimeUtil.format(timeWindow.getEnd()), timeList); out.collect(outStr); } }); sumDS.print(); env.execute("watermark job"); } }
- 测试数据
java,2022-11-11 23:12:07,10
java,2022-11-11 23:12:11,10
java,2022-11-11 23:12:08,10
java,2022-11-11 23:12:13,10
java,2022-11-11 23:12:23,10
#延迟1分钟内,所以会输出
java,2022-11-11 23:12:09,10
java,2022-11-11 23:12:02,10
java,2022-11-11 23:14:30,10
#延迟超过1分钟,不会输出
java,2022-11-11 23:12:03,10
6.最后的兜底slideoutput
背景
- 超过了watermark的等待后,还有延迟数据到达怎么办?
- watermark先输出,然后配置allowedLateness 再延长时间,然后到了后更新之前的窗口数据
- 数据超过了allowedLateness 后,就丢失了吗?用侧输出流 SideOutput
写法:
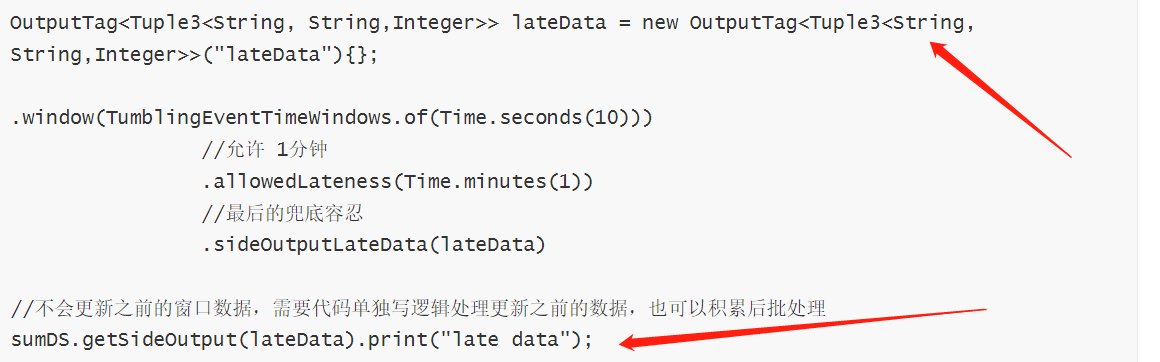
完整程序:
package net.xdclass.app.watermark; import net.xdclass.utils.TimeUtil; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.api.java.tuple.Tuple3; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.windowing.WindowFunction; import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.streaming.api.windowing.windows.TimeWindow; import org.apache.flink.util.Collector; import org.apache.flink.util.OutputTag; import java.time.Duration; import java.util.ArrayList; import java.util.List; /** * watermark机制中最后兜底 */ public class WatermarkSlideOutputWindow { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); // 格式=》 java,2022-11-11 09-10-10,15 final DataStreamSource<String> ds = env.socketTextStream("127.0.0.1", 8888); final SingleOutputStreamOperator<Tuple3<String, String, Integer>> flatMapDS = ds.flatMap(new FlatMapFunction<String, Tuple3<String, String, Integer>>() { @Override public void flatMap(String value, Collector<Tuple3<String, String, Integer>> collector) throws Exception { final String[] split = value.split(","); collector.collect(Tuple3.of(split[0], split[1], Integer.parseInt(split[2]))); } }); // 指定watermark final SingleOutputStreamOperator<Tuple3<String, String, Integer>> watermarkDS = flatMapDS.assignTimestampsAndWatermarks(WatermarkStrategy .<Tuple3<String, String, Integer>>forBoundedOutOfOrderness(Duration.ofSeconds(3)) .withTimestampAssigner((event, timpstamp) -> TimeUtil.strToDate(event.f1).getTime())); // 定义最后的兜底 final OutputTag<Tuple3<String, String, Integer>> lateData = new OutputTag<Tuple3<String, String, Integer>>("lateData"){}; // 分组 final KeyedStream<Tuple3<String, String, Integer>, String> keyByDS = watermarkDS.keyBy(new KeySelector<Tuple3<String, String, Integer>, String>() { @Override public String getKey(Tuple3<String, String, Integer> value) throws Exception { return value.f0; } }); // 开窗 final SingleOutputStreamOperator<String> sumDS = keyByDS.window(TumblingEventTimeWindows.of(Time.seconds(10))) .allowedLateness(Time.minutes(1)) .sideOutputLateData(lateData) .apply(new WindowFunction<Tuple3<String, String, Integer>, String, String, TimeWindow>() { @Override public void apply(String key, TimeWindow timeWindow, Iterable<Tuple3<String, String, Integer>> input, Collector<String> out) throws Exception { List<String> timeList = new ArrayList<>(); int total = 0; for (Tuple3<String, String, Integer> order : input) { timeList.add(order.f1); total = total + order.f2; } String outStr = String.format("分组key:%s,聚合值:%s,窗口开始结束:[%s~%s),窗口所有事件时间:%s", key, total, TimeUtil.format(timeWindow.getStart()), TimeUtil.format(timeWindow.getEnd()), timeList); out.collect(outStr); } }); sumDS.print(); sumDS.getSideOutput(lateData).print(); env.execute("watermark job"); } }
-
测试数据
-
窗口 [23:12:00 ~ 23:12:10) | [23:12:10 ~ 23: 12:20)
-
触发窗口计算条件
- 窗口内有数据
- watermark >= 窗口endtime
- 即 当前计算窗口最大的事件时间 - 允许乱序延迟的时间 >= Window EndTime窗口结束时间
-
java,2022-11-11 23:12:07,10 java,2022-11-11 23:12:11,10 java,2022-11-11 23:12:08,10 java,2022-11-11 23:12:13,10 java,2022-11-11 23:12:23,10 java,2022-11-11 23:12:09,10 java,2022-11-11 23:12:02,10 java,2022-11-11 23:14:30,10 #延迟超过1分钟,不会输出,配置了sideOutPut,会在兜底输出 java,2022-11-11 23:12:03,10 java,2022-11-11 23:12:04,10
效果:

7.总结
-
面试题:如何保证在需要的窗口内获得指定的数据?数据有乱序延迟
-
flink采用watermark 、allowedLateness() 、sideOutputLateData()三个机制来保证获取数据
-
watermark的作用是防止数据出现延迟乱序,允许等待一会再触发窗口计算,提前输出
-
allowLateness,是将窗口关闭时间再延迟一段时间.设置后就像window变大了
- 那么为什么不直接把window设置大一点呢?或者把watermark加大点?
- watermark先输出数据,allowLateness会局部修复数据并主动更新窗口的数据输出
- 这期间的迟到数据不会被丢弃,而是会触发窗口重新计算
-
sideOutPut是最后兜底操作,超过allowLateness后,窗口已经彻底关闭了,就会把数据放到侧输出流
- 测输出流 OutputTag tag = new OutputTag(){}, 由于泛型查除问题,需要重写方法,加花括号
-
-
应用场景:实时监控平台
- 可以用watermark及时输出数据
- allowLateness 做短期的更新迟到数据
- sideOutPut做兜底更新保证数据准确性
-
总结Flink的机制
-
第一层 窗口window 的作用是从DataStream数据流里指定范围获取数据。
-
第二层 watermark的作用是防止数据出现乱序延迟,允许窗口等待延迟数据达到,再触发计算
-
第三层 allowLateness 会让窗口关闭时间再延迟一段时间, 如果还有数据达到,会局部修复数据并主动更新窗口的数据输出
-
第四层 sideOutPut侧输出流是最后兜底操作,在窗口已经彻底关闭后,所有过期延迟数据放到侧输出流,可以单独获取,存储到某个地方再批量更新之前的聚合的数据
-
注意
- Flink 默认的处理方式直接丢弃迟到的数据
- sideOutPut还可以进行分流功能
- DataStream没有getSideOutput方法,SingleOutputStreamOperator才有
-
九:Flink状态State管理实战和Checkpoint讲解
1.概念
-
什么是State状态
- 数据流处理离不开状态管理,比如窗口聚合统计、去重、排序等
- 是一个Operator的运行的状态/历史值,是维护在内存中
- 流程:一个算子的子任务接收输入流,获取对应的状态,计算新的结果,然后把结果更新到状态里面
-
有状态和无状态介绍
- 无状态计算: 同个数据进到算子里面多少次,都是一样的输出,比如 filter
- 有状态计算:需要考虑历史状态,同个输入会有不同的输出,比如sum、reduce聚合操作
-
状态管理分类
-
ManagedState(用的多)
-
Flink管理,自动存储恢复
-
细分两类
-
Keyed State 键控状态(用的多)
- 有KeyBy才用这个,仅限用在KeyStream中,每个key都有state ,是基于KeyedStream上的状态
- 一般是用richFlatFunction,或者其他richfunction里面,在open()声明周期里面进行初始化
- ValueState、ListState、MapState等数据结构
-
Operator State 算子状态(用的少,部分source会用)
- ListState、UnionListState、BroadcastState等数据结构
-
-
-
RawState(用的少)
- 用户自己管理和维护
- 存储结构:二进制数组
-
-
State数据结构(状态值可能存在内存、磁盘、DB或者其他分布式存储中)
-
ValueState 简单的存储一个值(ThreadLocal / String)
- ValueState.value()
- ValueState.update(T value)
-
ListState 列表
- ListState.add(T value)
- ListState.get() //得到一个Iterator
-
MapState 映射类型
- MapState.get(key)
- MapState.put(key, value)
-
2.State后端存储
-
State状态后端:存储在哪里
-
Flink 内置了以下这些开箱即用的 state backends :
-
(新版)HashMapStateBackend、EmbeddedRocksDBStateBackend
- 如果没有其他配置,系统将使用 HashMapStateBackend。
-
(旧版)MemoryStateBackend、FsStateBackend、RocksDBStateBackend
- 如果不设置,默认使用 MemoryStateBackend。
-
-
状态详解
-
HashMapStateBackend 保存数据在内部作为Java堆的对象。
-
键/值状态和窗口操作符持有哈希表,用于存储值、触发器等
-
非常快,因为每个状态访问和更新都对 Java 堆上的对象进行操作
-
但是状态大小受集群内可用内存的限制
-
场景:
- 具有大状态、长窗口、大键/值状态的作业。
- 所有高可用性设置。
-
-
EmbeddedRocksDBStateBackend 在RocksDB数据库中保存状态数据
-
该数据库(默认)存储在 TaskManager 本地数据目录中
-
与HashMapStateBackend在java存储 对象不同,数据存储为序列化的字节数组
-
RocksDB可以根据可用磁盘空间进行扩展,并且是唯一支持增量快照的状态后端。
-
但是每个状态访问和更新都需要(反)序列化并可能从磁盘读取,这导致平均性能比内存状态后端慢一个数量级
-
场景
- 具有非常大状态、长窗口、大键/值状态的作业。
- 所有高可用性设置
-
-
旧版
-
MemoryStateBackend(内存,不推荐在生产场景使用)
FsStateBackend(文件系统上,本地文件系统、HDFS, 性能更好,常用)
RocksDBStateBackend (无需担心 OOM 风险,是大部分时候的选择)
配置
- 方式一:可以
flink-conf.yaml使用配置键在 中配置默认状态后端state.backend。
配置条目的可能值是hashmap (HashMapStateBackend)、rocksdb (EmbeddedRocksDBStateBackend) 或实现状态后端工厂StateBackendFactory的类的完全限定类名 #全局配置例子一 # The backend that will be used to store operator state checkpoints state.backend: hashmap # Optional, Flink will automatically default to JobManagerCheckpointStorage # when no checkpoint directory is specified. state.checkpoint-storage: jobmanager #全局配置例子二 state.backend: rocksdb state.checkpoints.dir: file:///checkpoint-dir/ # Optional, Flink will automatically default to FileSystemCheckpointStorage # when a checkpoint directory is specified. state.checkpoint-storage: filesystem
- 方式二:代码 单独job配置例子
//代码配置一 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStateBackend(new HashMapStateBackend()); env.getCheckpointConfig().setCheckpointStorage(new JobManagerCheckpointStorage()); //代码配置二 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStateBackend(new EmbeddedRocksDBStateBackend()); env.getCheckpointConfig().setCheckpointStorage("file:///checkpoint-dir"); //或者 env.getCheckpointConfig().setCheckpointStorage(new FileSystemCheckpointStorage("file:///checkpoint-dir"));
- 备注:使用 RocksDBStateBackend 需要加依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_${scala.version}</artifactId>
<version>1.13.1</version>
</dependency>
3.实战
-
sum()、maxBy() 等函数底层源码也是有ValueState进行状态存储
-
需求:
- 根据订单进行分组,统计找出每个商品最大的订单成交额
- 不用maxBy实现,用ValueState实现
package net.xdclass.app.state; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.common.functions.RichMapFunction; import org.apache.flink.api.common.state.ValueState; import org.apache.flink.api.common.state.ValueStateDescriptor; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.api.java.tuple.Tuple3; import org.apache.flink.configuration.Configuration; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; import org.apache.flink.util.OutputTag; import java.time.Duration; import java.util.ArrayList; import java.util.List; public class StateMaxByApp { /** * source * transformation * sink * * @param args */ public static void main(String[] args) throws Exception { //构建执行任务环境以及任务的启动的入口, 存储全局相关的参数 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); //java,2022-11-11 09-10-10,15 DataStream<String> ds = env.socketTextStream("127.0.0.1", 8888); DataStream<Tuple3<String, String, Integer>> flatMap = ds.flatMap(new FlatMapFunction<String, Tuple3<String, String, Integer>>() { @Override public void flatMap(String value, Collector<Tuple3<String, String, Integer>> out) throws Exception { String[] arr = value.split(","); out.collect(Tuple3.of(arr[0], arr[1], Integer.parseInt(arr[2]))); } }); SingleOutputStreamOperator<Tuple2<String, Integer>> maxVideoOrderDS = flatMap.keyBy(new KeySelector<Tuple3<String, String, Integer>, String>() { @Override public String getKey(Tuple3<String, String, Integer> value) throws Exception { return value.f0; } }).map(new RichMapFunction<Tuple3<String, String, Integer>, Tuple2<String, Integer>>() { private ValueState<Integer> maxVideoOrderState = null; @Override public void open(Configuration parameters) throws Exception { maxVideoOrderState = getRuntimeContext().getState(new ValueStateDescriptor<Integer>("maxValue", Integer.class)); } @Override public Tuple2<String, Integer> map(Tuple3<String, String, Integer> value) throws Exception { //获取历史值 Integer maxValue = maxVideoOrderState.value(); Integer currentValue = value.f2; //判断 if (maxValue == null || currentValue > maxValue) { //更新状态,当前最大的值存储到state maxVideoOrderState.update(currentValue); return Tuple2.of(value.f0, currentValue); } else { return Tuple2.of(value.f0, maxValue); } } @Override public void close() throws Exception { super.close(); } }); maxVideoOrderDS.print("最大订单:"); env.execute("watermark job"); } }
4.Checkpoint-SavePoint
-
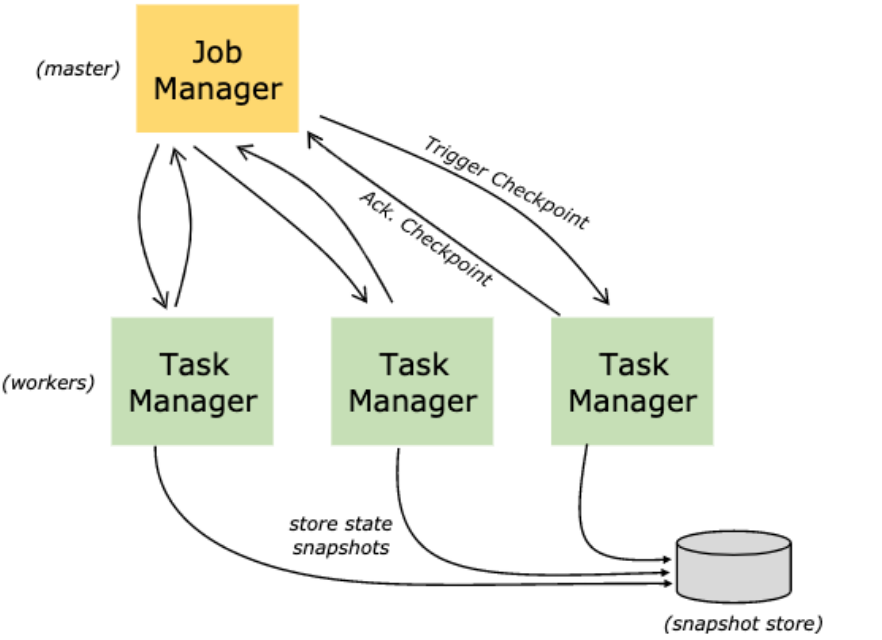
什么是Checkpoint 检查点
- Flink中所有的Operator的当前State的全局快照
- 默认情况下 checkpoint 是禁用的
- Checkpoint是把State数据定时持久化存储,防止丢失
- 手工调用checkpoint,叫 savepoint,主要是用于flink集群维护升级等
- 底层使用了Chandy-Lamport 分布式快照算法,保证数据在分布式环境下的一致性
-
开箱即用,Flink 捆绑了这些检查点存储类型:
- 作业管理器检查点存储 JobManagerCheckpointStorage
- 文件系统检查点存储 FileSystemCheckpointStorage
-
Savepoint 与 Checkpoint 的不同之处
- 类似于传统数据库中的备份与恢复日志之间的差异
- Checkpoint 的主要目的是为意外失败的作业提供【重启恢复机制】,
- Checkpoint 的生命周期由 Flink 管理,即 Flink 创建,管理和删除 Checkpoint - 无需用户交互
- Savepoint 由用户创建,拥有和删除, 主要是【升级 Flink 版本】,调整用户逻辑
- 除去概念上的差异,Checkpoint 和 Savepoint 的当前实现基本上使用相同的代码并生成相同的格式
5.端到端(end-to-end)状态一致性
数据一致性保证都是由流处理器实现的,也就是说都是在Flink流处理器内部保证的
在真实应用中,了流处理器以外还包含了数据源(例如Kafka、Mysql)和输出到持久化系统(Kafka、Mysql、Hbase、CK)
端到端的一致性保证,是意味着结果的正确性贯穿了整个流处理应用的各个环节,每一个组件都要保证自己的一致性。
-
Source
- 需要外部数据源可以重置读取位置,当发生故障的时候重置偏移量到故障之前的位置
-
内部
- 依赖Checkpoints机制,在发生故障的时可以恢复各个环节的数据
-
Sink:
- 当故障恢复时,数据不会重复写入外部系统,常见的就是 幂等和事务写入(和checkpoint配合)
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号