
学习过es,但是每次学习,感觉都不同,今天重新做一次梳理。
gitee:https://gitee.com/juncaoit/fast
一:ELK介绍
1.说明
elasticsearch,logstash,kibana
2.介绍
elasticsearch:全文搜搜引擎,基于java。
logstash:具有实时传输的数据收集引擎,用来数据收集
kibana:提供分析与可视化。可以再es索引中查找,交互数据,生成各种维度的表格,图形
3.为什么使用
elasticsearch:
数据量庞大
搜索要求快,准,多维度的使用
logstash:
数据源丰富,数据库,日志,分散的数据都可以收集
kibana:
分析展示,展示数据的价值
二:单机安装es
1.上传
规划目录:

上传:

2.解压
tar -zxvf elasticsearch-7.6.1-linux-x86_64.tar.gz -C ../software/

3.配置jdk
删除不必要的jdk:
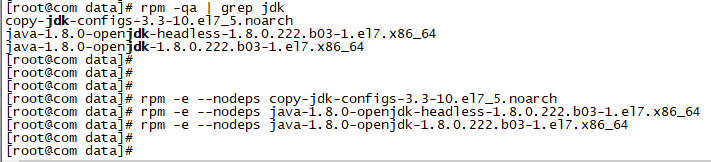
配置:
export JAVA_HOME=/opt/software/elasticsearch-7.6.1/jdk
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
在es的目录下,有jdk,版本是13的

4.添加用户
groupadd tedu
useradd tedu -g tedu
chown -R tedu:tedu elasticsearch-7.6.1/

5.启动
su tedu
./bin/elasticsearch
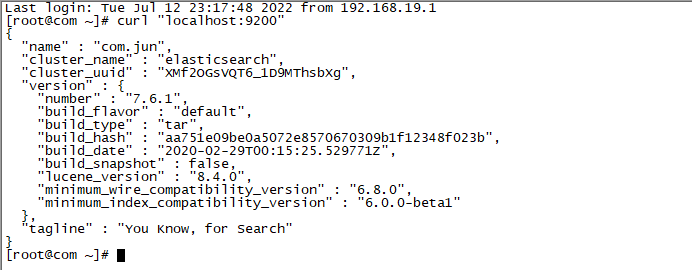
6.测试
curl "localhost:9200"
三:集群安装es
1.三台安装
2.修改配置文件config/
es01节点(后面只是name不同)
cluster.name: es-cluster
node.name: es01
path.data: /opt/software/elasticsearch-7.6.1/data
path.logs: /opt/software/elasticsearch-7.6.1/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
discovery.seed_hosts: ["192.168.19.132", "192.168.19.133", "192.168.19.134"]
cluster.initial_master_nodes: ["192.168.19.132"]
http.cors.enabled: true
http.cors.allow-origin: "*"
3.出现的问题进行处理
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
[2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
【1】的处理:
vi /etc/security/limits.conf
添加:
* soft nofile 65536
* hard nofile 65536
切换成root,使用下面命令查询效果
ulimit -Hn
ulimit -Sn
【2】的处理
vi /etc/sysctl.conf
添加:
vm.max_map_count=262144
然后重启:
reboot
4.测试
四:head插件
1.安装nodejs
head插件的运行环境是node
wget https://nodejs.org/dist/v15.0.0/node-v15.0.0-linux-x64.tar.gz
2.解压
tar -zxvf node-v15.0.0-linux-x64.tar.gz -C ../software/
3.配置环境变量
export NODE_HOME=/opt/software/node-v15.0.0-linux-x64
export PATH=$NODE_HOME/bin:$PATH
验证:

4.下载head插件
git:https://github.com/mobz/elasticsearch-head
yum -y install git
git clone https://github.com/mobz/elasticsearch-head.git
git一直没有拉下来,下载了zip

解压:
unzip elasticsearch-head-master.zip -d ../software/
5.npm安装
在head插件文件夹的根目录下执行npm安装
npm install -g grunt
yum install bzip2
npm insall
6.配置head文件
GruntFile.js中97行配置,添加hostname
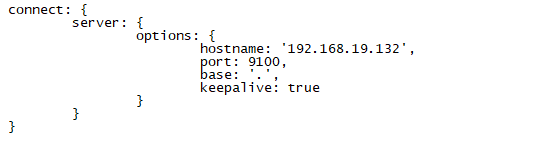
注意添加引号
7.head根目录下启动
grunt server
8.访问
192.168.19.132:9100

启动两个es节点,观察
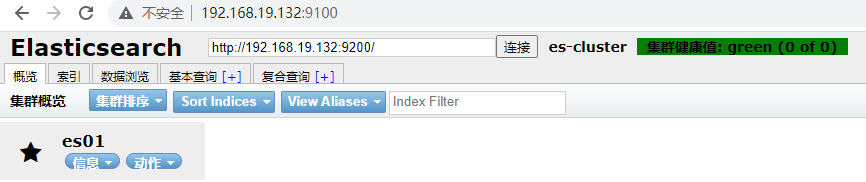 、
、
五:kibana
1.解压
版本需要对应
tar -zxvf kibana-7.6.1-linux-x86_64.tar.gz -C ../software/
2.配置
config/kibana.yml
server.host: "192.168.19.132"
elasticsearch.hosts: ["http://192.168.19.132:9200"]
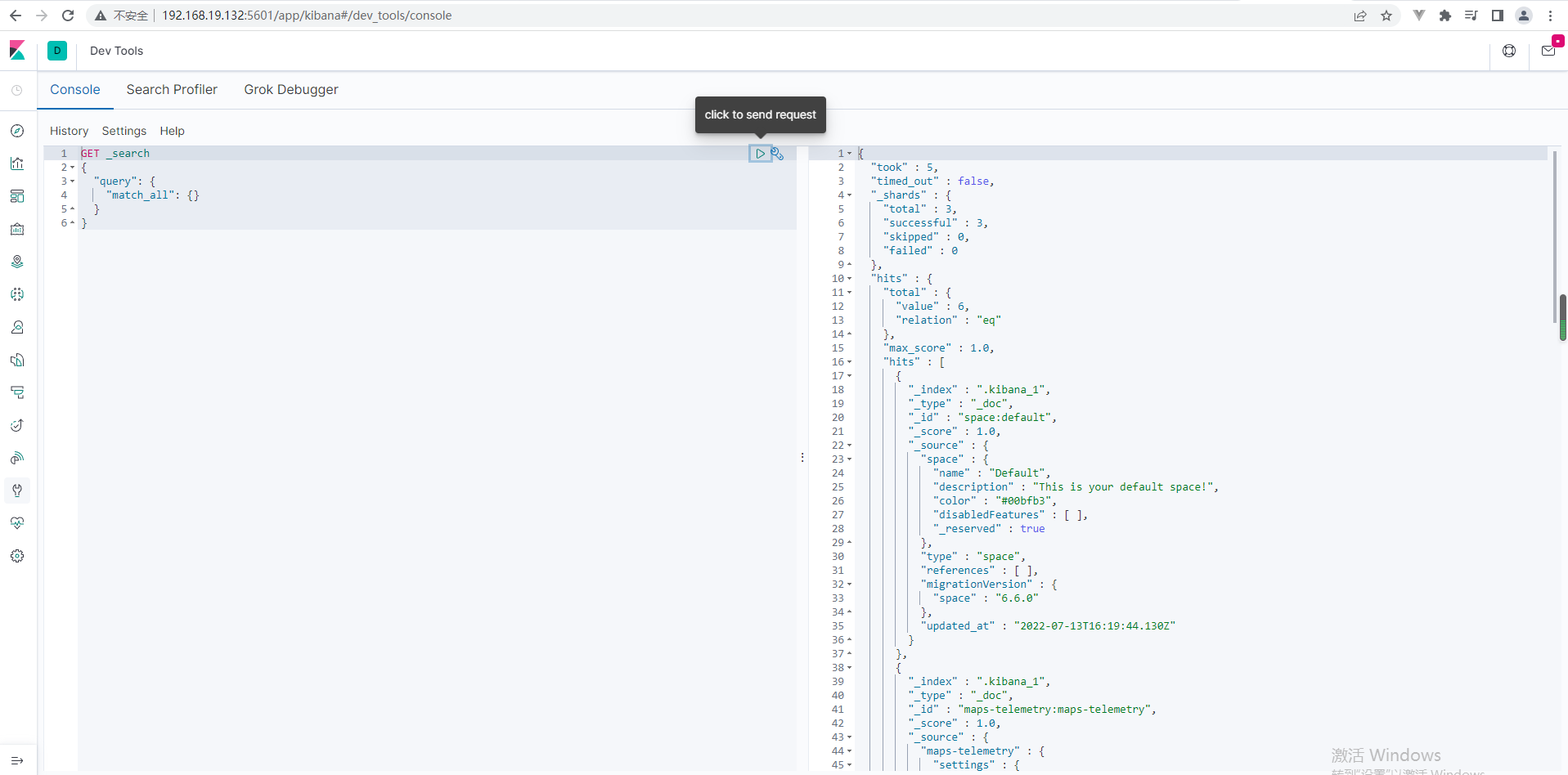
3.启动
bin/kibana --allow-root
4.访问
http://192.168.19.132:5601
六:重要概念
1.分片
单台存储是有限的,es可以将一个index的数据分为多个分片
2.rest方式
curl格式:curl -H 请求头 -d 请求体 -X POST 接口地址
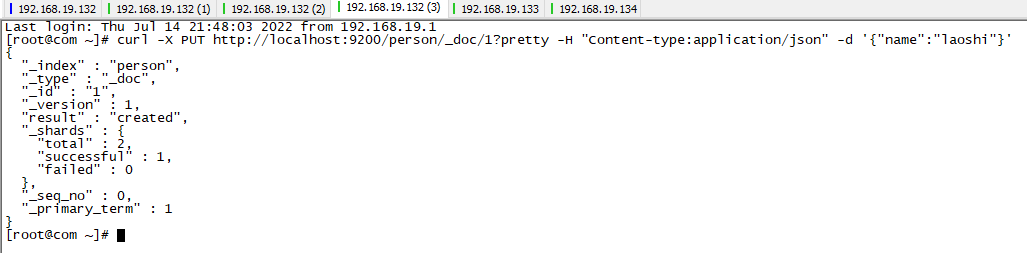
例如:
新增一个索引文件,并且以漂亮格式展示响应
curl -X PUT http://localhost:9200/person/_doc/1?pretty -H "Content-type:application/json" -d '{"name":"laoshi"}'
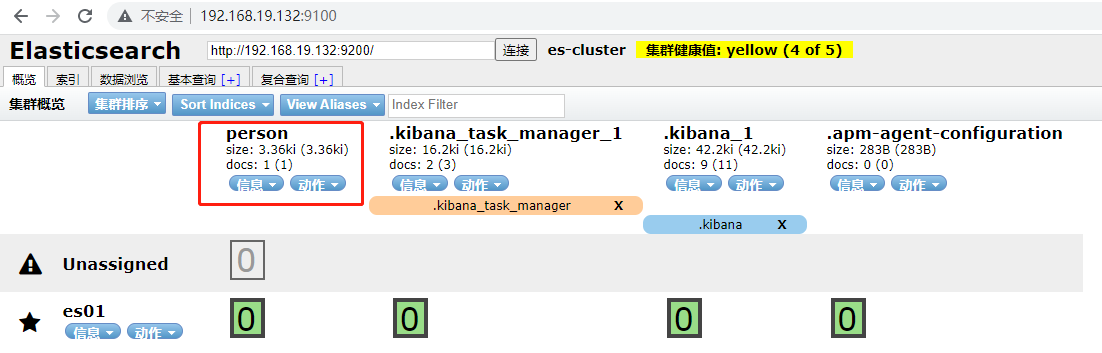
效果:
head上:
七:索引管理
1.索引的创建
put请求,表示新增
# 新增索引
PUT /index01
2.插入文档
put请求
# 索引中添加文档数据
PUT /index01/_doc/1
{
"name":"tom"
}
3.查询文档
# 查询文档
GET /index01/_doc/1
4.更新文档
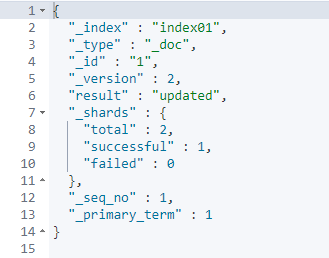
使用put再做一次相同的改变
# 更新
PUT /index01/_doc/1
{
"name":"tom2"
}
只有version有变化
5.删除文档
# 删除文档
DELETE /index01/_doc/1
6.删除索引
#删除索引
DELETE /index01
7.批量索引
减少网络往返
# 批量索引
PUT /index05/_bulk
{"index":{"_id":"1"}}
{"id":"1", "name":"雅典娜", "job":"html", "age":"38", "salary":20000, "gender":"female", "like":"牛奶"}
{"index":{"_id":"2"}}
{"id":"2", "name":"马云云", "job":"html", "age":"22", "salary":35000, "gender":"male", "like":"香蕉"}
{"index":{"_id":"3"}}
{"id":"1", "name":"强东", "job":"go", "age":"24", "salary":10000, "gender":"male", "like":"苹果"}
{"index":{"_id":"4"}}
{"id":"1", "name":"小马", "job":"python", "age":"18", "salary":50000, "gender":"male", "like":"李子"}
八:搜索功能
1.match_all
query查询类型
# 查询功能
GET /index05/_search
{
"query": {
"match_all": {}
}
}
2.term(词项)
词项,分词计算的基本单位
中文会被拆分,例如李老师,则是李,老,师
term查询,返回的文档包含了提供的确切词项的文档,如果没有包含,则不展示
#term查询
GET /index05/_search
{
"query": {
"term": {
"name": {
"value": "马"
}
}
}
}
效果:【符合预期】
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.7549127,
"hits" : [
{
"_index" : "index05",
"_type" : "_doc",
"_id" : "4",
"_score" : 0.7549127,
"_source" : {
"id" : "1",
"name" : "小马",
"job" : "python",
"age" : "18",
"salary" : 50000,
"gender" : "male",
"like" : "李子"
}
},
{
"_index" : "index05",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.6407243,
"_source" : {
"id" : "2",
"name" : "马云云",
"job" : "html",
"age" : "22",
"salary" : 35000,
"gender" : "male",
"like" : "香蕉"
}
}
]
}
}
在看一个,term是马云
#term查询
GET /index05/_search
{
"query": {
"term": {
"name": {
"value": "马云"
}
}
}
}
效果:为空
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
3.boost加权
是的查询结果的文档评分最终会乘以boost的结果进行返回
在value下添加
主要是组合查询了,不同的条件添加不同的权重
#boost加权
GET /index05/_search
{
"query": {
"term": {
"name": {
"value": "马",
"boost": 2
}
}
}
}
效果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.5098253,
"hits" : [
{
"_index" : "index05",
"_type" : "_doc",
"_id" : "4",
"_score" : 1.5098253,
"_source" : {
"id" : "1",
"name" : "小马",
"job" : "python",
"age" : "18",
"salary" : 50000,
"gender" : "male",
"like" : "李子"
}
},
{
"_index" : "index05",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.2814486,
"_source" : {
"id" : "2",
"name" : "马云云",
"job" : "html",
"age" : "22",
"salary" : 35000,
"gender" : "male",
"like" : "香蕉"
}
}
]
}
}
4.range
返回一个范围内包含的文档
#range
GET /index05/_search
{
"query": {
"range": {
"salary": {
"gte": 10000,
"lte": 30000
}
}
}
}
5.exist
包含这个字段,则返回
文档的字段不存在的原因:
写入的索引字段值在json中是null或者[]
字段设置了“index”:false的映射导致不会写到索引中
字段设置了ignore_above,当超过长度不会写入索引
# exist
GET /index05/_search
{
"query": {
"exists": {
"field": "name"
}
}
}
6.match
先分词计算
这里可以发现与term不一样。通过分词之后的数据进行查询
默认是或的关系
#match
GET /index05/_search
{
"query": {
"match": {
"name": "马云"
}
}
}
效果:
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 2.2080264,
"hits" : [
{
"_index" : "index05",
"_type" : "_doc",
"_id" : "2",
"_score" : 2.2080264,
"_source" : {
"id" : "2",
"name" : "马云云",
"job" : "html",
"age" : "22",
"salary" : 35000,
"gender" : "male",
"like" : "香蕉"
}
},
{
"_index" : "index05",
"_type" : "_doc",
"_id" : "4",
"_score" : 0.7549127,
"_source" : {
"id" : "1",
"name" : "小马",
"job" : "python",
"age" : "18",
"salary" : 50000,
"gender" : "male",
"like" : "李子"
}
}
]
}
}
调整逻辑关系
相关性更加明确
GET /index05/_search
{
"query": {
"match": {
"name":{
"query": "马云",
"operator": "and"
}
}
}
}
效果:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 2.2080264,
"hits" : [
{
"_index" : "index05",
"_type" : "_doc",
"_id" : "2",
"_score" : 2.2080264,
"_source" : {
"id" : "2",
"name" : "马云云",
"job" : "html",
"age" : "22",
"salary" : 35000,
"gender" : "male",
"like" : "香蕉"
}
}
]
}
}
7.bool
定义多个子查询
GET /index05/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "马云"
}
},
{
"term": {
"job": {
"value": "python"
}
}
}
]
}
}
}
must与must_not结合使用的逻辑关系:
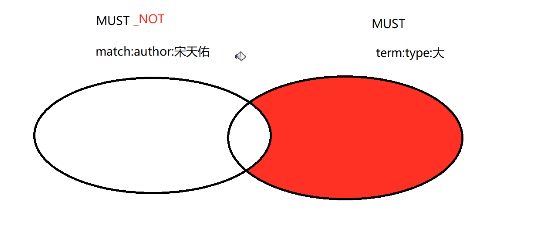
should:查询结果可能是也可能不是这个条件的子集,should和must同时使用,should的唯一作用就是影响最终的相关性的评分计算。
filter:查询结果必须是该条件的子集,但是满足filter子条件的结果要忽略评分,也就是其他的子条件的查询评分不会为filter的存在而变化
九:索引的映射设置
1.mapping
决定如何存储,如何生成存储,定义字段类型
存在静态映射与动态映射
2.动态映射
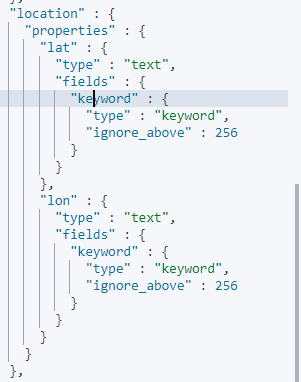
## 动态索引 PUT /index01/_doc/1 { "name":"小马", "job":"python", "age":"18", "salary":50000, "gender":"male", "like":"李子", "address":"北京市大兴区", "sorted":false, "emplotedTime":"2020-01-12", "location": { "lat":"41.43", "lon":"67.98" }, "ip":"192.168.5.102" } GET /index01/_mapping
效果:
{ "index01" : { "mappings" : { "properties" : { "address" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "age" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "emplotedTime" : { "type" : "date" }, "gender" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "ip" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "job" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "like" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "location" : { "properties" : { "lat" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "lon" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } }, "name" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "salary" : { "type" : "long" }, "sorted" : { "type" : "boolean" } } } } }
3.结构
字符串类型:

fields是一个可选的属性,它表示给当前字段的扩展属性,扩展了一个keyword。具备了text'的特点,也具备了keyword的特点
上面的可以查询到,因为分词;下面的反而搜不到,因为存的是一个整的词。
GET /index01/_search { "query": { "term": { "address": { "value": "北" } } } } GET /index01/_search { "query": { "term": { "address.keyword": { "value": "北" } } } }
4.整数类型
默认long
5.浮点类型
默认double
6.日期
默认对应是date,是因为几种类型被识别
7.对象
8.添加静态映射
#添加mapping PUT /index02 { "mappings": { "properties": { "email":{ "type": "keyword" } } } } GET /index02/_mapping PUT /index02/_doc/1 { "email":"1354488@qq.com", "name":"tom" } GET /index02/_doc/1 GET /index02/_mapping
效果:
不存在的则按照动态mapping生成。
{ "index02" : { "mappings" : { "properties" : { "email" : { "type" : "keyword" }, "name" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } } } }
9.索引之后,添加静态映射
# 后添加映射 PUT /index04 PUT /index04/_mapping { "properties":{ "name":{ "type":"text" } } } GET /index04/_mapping
十:分词器与热词设置
1.分词
主要有Tokenization与Normalization
Tokenization:将文本分成一小块一小块,称之为token
Mormalization:词条允许在单个术语上进行匹配,q允许精确匹配,还可以使用相关性查询
2.分词器
自带的分词器,standard analyzer
# 分词器测试 POST /_analyze { "text": ["王者荣耀"], "analyzer": "standard" }
效果:
{ "tokens" : [ { "token" : "王", "start_offset" : 0, "end_offset" : 1, "type" : "<IDEOGRAPHIC>", "position" : 0 }, { "token" : "者", "start_offset" : 1, "end_offset" : 2, "type" : "<IDEOGRAPHIC>", "position" : 1 }, { "token" : "荣", "start_offset" : 2, "end_offset" : 3, "type" : "<IDEOGRAPHIC>", "position" : 2 }, { "token" : "耀", "start_offset" : 3, "end_offset" : 4, "type" : "<IDEOGRAPHIC>", "position" : 3 } ] }
3.ik分词器
上传

解压到es的plugins/ik
unzip elasticsearch-analysis-ik-7.6.1.zip -d ../software/elasticsearch-7.6.1/plugins/ik
启动es
没有上传ik的不用重启
是否加载
[es01] try load config from /opt/software/elasticsearch-7.6.1/plugins/ik/config/IKAnalyzer.cfg.xml
检验:
#ik POST /_analyze { "text": ["疑是银河落九天"], "analyzer": "ik_max_word" }
效果:
{ "tokens" : [ { "token" : "疑是银河落九天", "start_offset" : 0, "end_offset" : 7, "type" : "CN_WORD", "position" : 0 }, { "token" : "疑是", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 1 }, { "token" : "银河", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 2 }, { "token" : "落九天", "start_offset" : 4, "end_offset" : 7, "type" : "CN_WORD", "position" : 3 }, { "token" : "九天", "start_offset" : 5, "end_offset" : 7, "type" : "CN_WORD", "position" : 4 }, { "token" : "九", "start_offset" : 5, "end_offset" : 6, "type" : "TYPE_CNUM", "position" : 5 }, { "token" : "天", "start_offset" : 6, "end_offset" : 7, "type" : "COUNT", "position" : 6 } ] }
4.分词进步
#ik POST /_analyze { "text": ["王者荣耀"], "analyzer": "ik_max_word" }
效果:不认识王者荣耀四个字
{ "tokens" : [ { "token" : "王者", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 0 }, { "token" : "荣耀", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 1 } ] }
5.本地ik词典的配置
在我们解压的ik分词器文件夹中/plugins/ik/config有一个xml配置文件可以指定词典使用。

非热加载的方式处理:
/opt/software/elasticsearch-7.6.1/plugins/ik/config vi my_main.dic
添加:
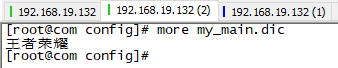
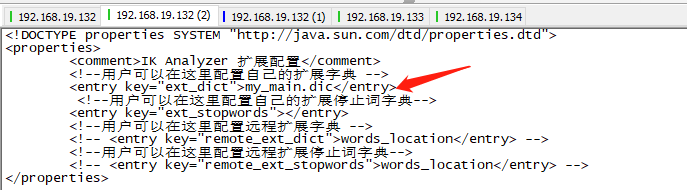
测试效果:
{ "tokens" : [ { "token" : "王者荣耀", "start_offset" : 0, "end_offset" : 4, "type" : "CN_WORD", "position" : 0 }, { "token" : "王者", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 1 }, { "token" : "荣耀", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 2 } ] }
6.本地ik词典的配置
下载安装tomcat
tar -zxvf apache-tomcat-9.0.64.tar.gz -C ../software/
然后进入root目录
/opt/software/apache-tomcat-9.0.64/webapps/ROOT
vi hot.dic

启动tomcat
# bin/startup.sh
访问:

在ik远程字典中进行配置,然后启动es
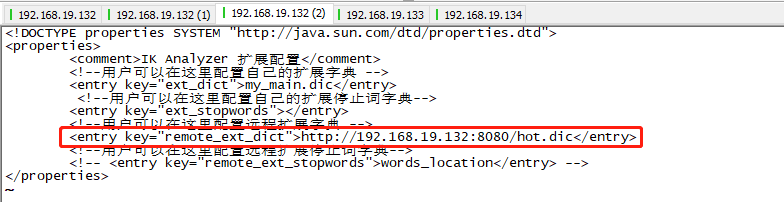
校验效果:
{ "tokens" : [ { "token" : "王者荣耀", "start_offset" : 0, "end_offset" : 4, "type" : "CN_WORD", "position" : 0 }, { "token" : "王者荣", "start_offset" : 0, "end_offset" : 3, "type" : "CN_WORD", "position" : 1 }, { "token" : "王者", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 2 }, { "token" : "荣耀", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 3 } ] }
十一:java调用
1.pom
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.6.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.6.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.6.2</version>
</dependency>
2.新增索引
/** * 新建索引 */ @Override public CreateIndexResponse createIndex(String index) throws IOException { CreateIndexRequest createRequest = new CreateIndexRequest(index); createRequest.settings(Settings.builder() .put("number_of_shards", "3") .put("number_of_replicas", "2")); CreateIndexResponse createIndexResponse = highLevelClient.indices().create(createRequest, RequestOptions.DEFAULT); return createIndexResponse; }
3.删除索引
/** * 删除索引 */ @Override public AcknowledgedResponse deleteIndex(String index) throws IOException { DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest(index); return highLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT); }
4.新增文档
/** * 增加文档 */ @Override public boolean add(EsDto esDto, String index, String id){ // 执行 IndexRequest indexRequest = new IndexRequest(index).id(id).source(esDto.getJsonStr(), XContentType.JSON); try { IndexResponse response = highLevelClient.index(indexRequest, RequestOptions.DEFAULT); log.info("增加返回结果:{}", JSONObject.toJSON(response)); } catch (IOException e) { e.printStackTrace(); } return true; }
5.查询文档
/** * 查询文档 */ @Override public Map get(String index, String id){ GetRequest getRequest = new GetRequest(index, id); try { GetResponse response = highLevelClient.get(getRequest, RequestOptions.DEFAULT); return response.getSource(); } catch (IOException e) { e.printStackTrace(); } return Maps.newHashMap(); }
6.判断是否存在
/** * 是否存在文档 */ @Override public Boolean exist(String index, String id){ GetRequest getRequest = new GetRequest(index, id); try { boolean exists = highLevelClient.exists(getRequest, RequestOptions.DEFAULT); return exists; } catch (IOException e) { e.printStackTrace(); } return false; }
7.删除文档
/** * 删除文档 */ @Override public boolean delete(String index, String id){ DeleteRequest deleteRequest = new DeleteRequest(index, id); try { DeleteResponse response = highLevelClient.delete(deleteRequest, RequestOptions.DEFAULT); log.info("删除文档返回结果:{}", JSONObject.toJSON(response)); return true; } catch (IOException e) { e.printStackTrace(); } return false; }
8.更新文档
index必须存在
/** * 更新文档 */ @Override public boolean update(EsDto esDto, String index, String id){ UpdateRequest updateRequest = new UpdateRequest(index, id).doc(esDto.getJsonStr()); try { UpdateResponse response = highLevelClient.update(updateRequest, RequestOptions.DEFAULT); log.info("更新文档返回结果:{}", JSONObject.toJSON(response)); return true; } catch (IOException e) { e.printStackTrace(); } return false; }
9.批量新增
索引可以不存在
public void bulk(String index) throws IOException { BulkRequest request = new BulkRequest(); request.add(new IndexRequest(index).id("2") .source(XContentType.JSON, "age", "18", "address", "长江中下游")); request.add(new IndexRequest(index).id("3") .source(XContentType.JSON, "age", "20", "address", "长江下游")); highLevelClient.bulk(request, RequestOptions.DEFAULT); }
10.bool查询
/** * bool查询 */ @Override public List<String> searchBool(String index, String key, String value) { List<String> result = Lists.newArrayList(); BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); // query1 TermQueryBuilder query1 = QueryBuilders.termQuery(key, value); // query2 ExistsQueryBuilder query2 = QueryBuilders.existsQuery(key); // 组合 boolQueryBuilder.must(query1); boolQueryBuilder.must(query2); SearchResponse searchResponse = commonQuery(index, boolQueryBuilder, 0, 10); if(Objects.nonNull(searchResponse)){ // 解析 SearchHit[] hits = searchResponse.getHits().getHits(); List resultList = Lists.newArrayList(); for (SearchHit hit : hits){ String sourceAsString = hit.getSourceAsString(); result.add(sourceAsString); } return result; } return result; } /** * 公共的查询 */ private SearchResponse commonQuery(String index, QueryBuilder queryBuilder, int from, int size){ SearchRequest searchRequest = new SearchRequest(index); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); searchSourceBuilder.query(queryBuilder); searchSourceBuilder.from(from); searchSourceBuilder.size(size); searchRequest.source(searchSourceBuilder); try { return highLevelClient.search(searchRequest, RequestOptions.DEFAULT); } catch (IOException e) { e.printStackTrace(); } return null; }
11.match查询
/** * match查询 */ @Override public SearchResponse searchMatch(String index, String key, String value){ // 组装 MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery(key, value); // 公共查询 return commonQuery(index, matchQueryBuilder, 0, 10); }
十二:聚合
1.stat
GET /index01/_search { "aggs": { "NAME": { "stats": { "field": "salary" } } } }
效果:
{ "took" : 0, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "index01", "_type" : "_doc", "_id" : "1", "_score" : 1.0, "_source" : { "name" : "小马", "job" : "python", "age" : "18", "salary" : 50000, "gender" : "male", "like" : "李子", "address" : "北京市大兴区", "sorted" : false, "emplotedTime" : "2020-01-12", "location" : { "lat" : "41.43", "lon" : "67.98" }, "ip" : "192.168.5.102" } } ] }, "aggregations" : { "NAME" : { "count" : 1, "min" : 50000.0, "max" : 50000.0, "avg" : 50000.0, "sum" : 50000.0 } } }
2.job中都会html的个数
桶的概念
GET /index05/_search { "aggs": { "NAME": { "terms": { "field": "job.keyword", "size": 10 } } } }
效果:
{ "took" : 1, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 4, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "index05", "_type" : "_doc", "_id" : "1", "_score" : 1.0, "_source" : { "id" : "1", "name" : "雅典娜", "job" : "html", "age" : "38", "salary" : 20000, "gender" : "female", "like" : "牛奶" } }, { "_index" : "index05", "_type" : "_doc", "_id" : "2", "_score" : 1.0, "_source" : { "id" : "2", "name" : "马云云", "job" : "html", "age" : "22", "salary" : 35000, "gender" : "male", "like" : "香蕉" } }, { "_index" : "index05", "_type" : "_doc", "_id" : "3", "_score" : 1.0, "_source" : { "id" : "1", "name" : "强东", "job" : "go", "age" : "24", "salary" : 10000, "gender" : "male", "like" : "苹果" } }, { "_index" : "index05", "_type" : "_doc", "_id" : "4", "_score" : 1.0, "_source" : { "id" : "1", "name" : "小马", "job" : "python", "age" : "18", "salary" : 50000, "gender" : "male", "like" : "李子" } } ] }, "aggregations" : { "NAME" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : "html", "doc_count" : 2 }, { "key" : "go", "doc_count" : 1 }, { "key" : "python", "doc_count" : 1 } ] } } }
3.子聚合
不同job下对like的喜欢不同做统计
GET /index05/_search { "size": 0, "aggs": { "job-info": { "terms": { "field": "job.keyword" }, "aggs": { "jon-like-info": { "terms": { "field": "like.keyword", "size": 10 } } } } } }
效果:
{ "took" : 1, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 4, "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "aggregations" : { "job-info" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : "html", "doc_count" : 2, "jon-like-info" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : "牛奶", "doc_count" : 1 }, { "key" : "香蕉", "doc_count" : 1 } ] } }, { "key" : "go", "doc_count" : 1, "jon-like-info" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : "苹果", "doc_count" : 1 } ] } }, { "key" : "python", "doc_count" : 1, "jon-like-info" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : "李子", "doc_count" : 1 } ] } } ] } } }
4.不同工种的薪资水平
GET /index05/_search { "size": 0, "aggs": { "job-info": { "terms": { "field": "job.keyword" }, "aggs": { "jon-salary": { "stats": { "field": "salary" } } } } } }
5.先查询,后sum
GET /index05/_search
{
"query": {
"match": {
"name": "马"
}
},
"aggs": {
"salary_sum": {
"sum": {
"field": "salary"
}
}
}
}
6.多层聚合
分桶的时候,才能一层层进行聚合
# 三層聚合
GET /index05/_search
{
"size": 0,
"aggs": {
"job-info": {
"terms": {
"field": "job.keyword"
},
"aggs": {
"jon-salary": {
"terms": {
"field": "gender.keyword"
},
"aggs": {
"NAME": {
"stats": {
"field": "salary"
}
}
}
}
}
}
}
}
7.top-hits
# top-hits
GET /index05/_search
{
"size": 0,
"aggs": {
"NAME": {
"top_hits": {
"size": 2,
"sort": [
{
"salary": {
"order": "desc"
}
}
],
"_source": {
"includes": ["id", "name"]
}
}
}
}
}
8.range
#rangge
GET /index05/_search
{
"size": 0,
"aggs": {
"range_info": {
"range": {
"field": "salary",
"ranges": [
{
"key": "D",
"from": 5000,
"to": 10000
},
{
"key": "C",
"from": 10000,
"to": 20000
}
]
}
}
}
}
9.直方图
# 直方图 GET /index05/_search { "size": 0, "aggs": { "NAME": { "histogram": { "field": "salary", "interval": 5000 } } } }
进一步做正真的直方图:
# 批量索引 PUT /index06/_bulk {"index":{"_id":"1"}} {"id":"1", "name":"雅典娜", "job":"html", "age":38, "salary":20000, "gender":"female", "like":"牛奶"} {"index":{"_id":"2"}} {"id":"2", "name":"马云云", "job":"html", "age":22, "salary":35000, "gender":"male", "like":"香蕉"} {"index":{"_id":"3"}} {"id":"1", "name":"强东", "job":"go", "age":24, "salary":10000, "gender":"male", "like":"苹果"} {"index":{"_id":"4"}} {"id":"1", "name":"小马", "job":"python", "age":18, "salary":50000, "gender":"male", "like":"李子"} {"index":{"_id":"5"}} {"id":"1", "name":"小军", "job":"java", "age":18, "salary":50000, "gender":"male", "like":"雪花"}
# 直方图 GET /index06/_search { "size": 0, "aggs": { "age-info": { "histogram": { "field": "age", "interval": 5 }, "aggs": { "salary-info": { "avg": { "field": "salary" } } } } } }
效果:
{ "took" : 2, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 5, "relation" : "eq" }, "max_score" : null, "hits" : [ ] }, "aggregations" : { "age-info" : { "buckets" : [ { "key" : 15.0, "doc_count" : 2, "salary-info" : { "value" : 50000.0 } }, { "key" : 20.0, "doc_count" : 2, "salary-info" : { "value" : 22500.0 } }, { "key" : 25.0, "doc_count" : 0, "salary-info" : { "value" : null } }, { "key" : 30.0, "doc_count" : 0, "salary-info" : { "value" : null } }, { "key" : 35.0, "doc_count" : 1, "salary-info" : { "value" : 20000.0 } } ] } } }
10.min_bucket
找到最小的那个
#min_bucket GET /index05/_search { "size": 0, "aggs": { "job-info": { "terms": { "field": "job.keyword" }, "aggs": { "jon-salary": { "avg": { "field": "salary" } } } }, "min_bulk_info":{ "min_bucket": { "buckets_path": "job-info>jon-salary" } } } }
11.聚合总结
bucket
 、
、
metric:

可以使用avg的单值聚合,也可以是stats多值聚合
pipeline:
十三:Logstash
1.解压
unzip logstash-7.6.1.zip -d ../software/
2.修改配置
vi jvm.options
注释:

3.测试
bin/logstash -e 'input {stdin{}} output {stdout{}}'
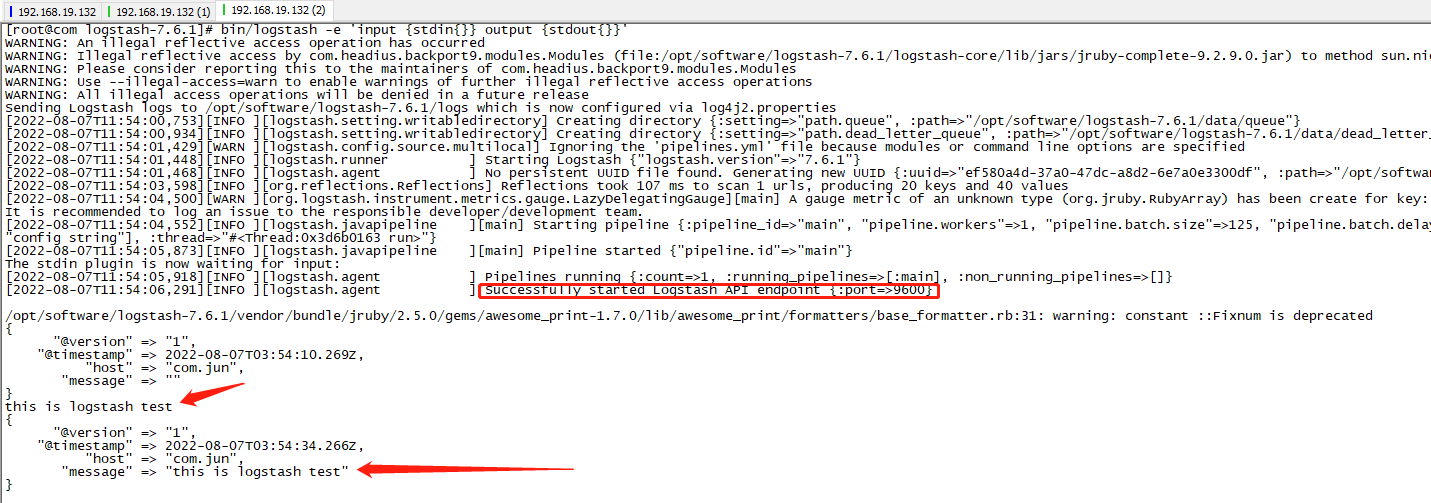
4.入门案例
将-e后面的内容写入到配置文件中
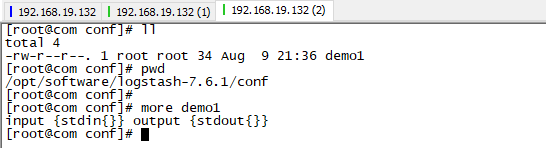
bin/logstash -f conf/demo1
案例二
bin/logstash -f conf/demo2
input{ exec{ command => 'ls' interval => 30 } } output{ stdout{} }
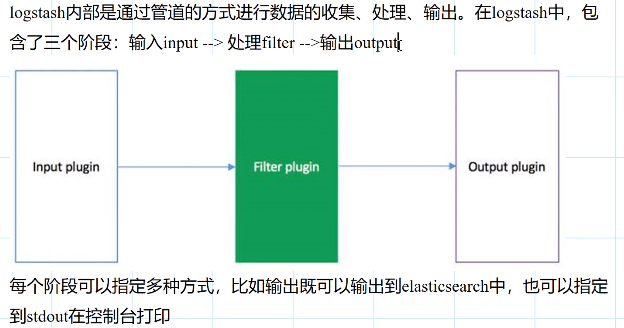
5.原理
6.input插件-exec
在入门案例中已经说明
7.input插件-file
监控文件中的新事件,相当于tail
input{ file{ path => '/opt/software/logstash-7.6.1/conf/tomcat.log' } } output{ stdout{} }
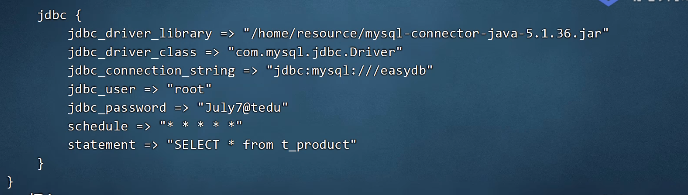
8.input插件-jdbc
有两种方式,后续有时间,再进行验证效果
9.output插件-stdout
上面已经说过,可以加编码格式

10.output组件-es
input{ stdin{} } output{ elasticsearch{ action => "index" hosts => ["192.168.19.132:9200"] index => "index111" } }
效果:
#logstash GET /index111/_search { "query": { "match_all": {} } }
{ "took" : 1, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "index111", "_type" : "_doc", "_id" : "LBJFg4IB0P-Q-DvAjHjt", "_score" : 1.0, "_source" : { "@timestamp" : "2022-08-09T15:42:29.192Z", "host" : "com.jun", "message" : "halou", "@version" : "1" } } ] } }
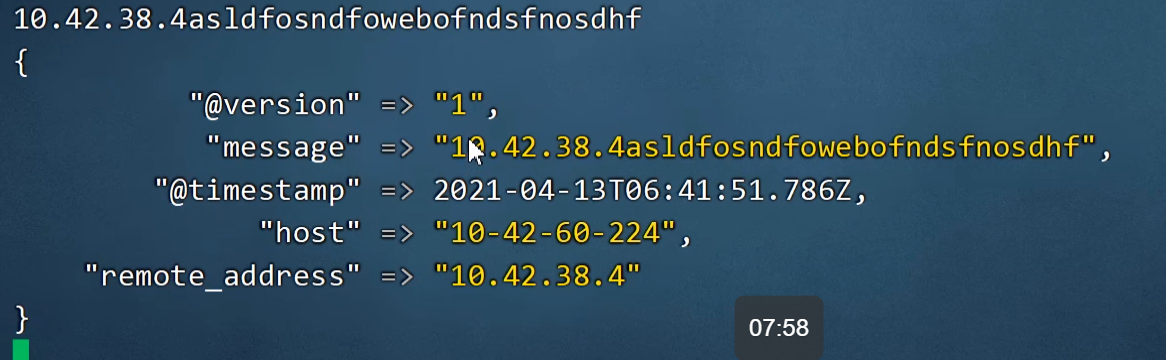
11.filter组件-grok插件

12.filter组件-grok插件-oniguruma语法

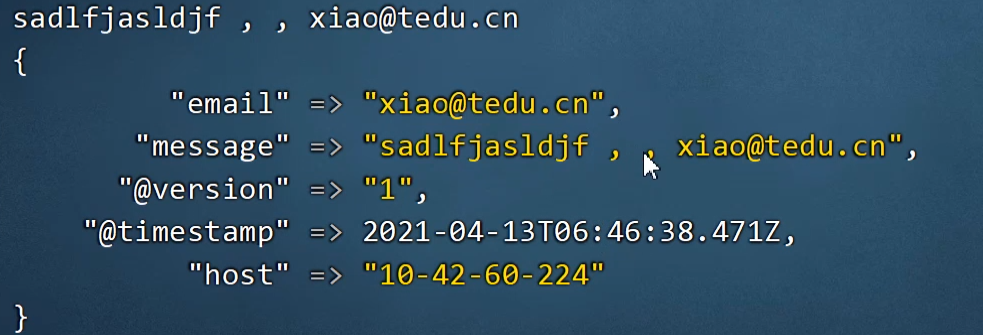
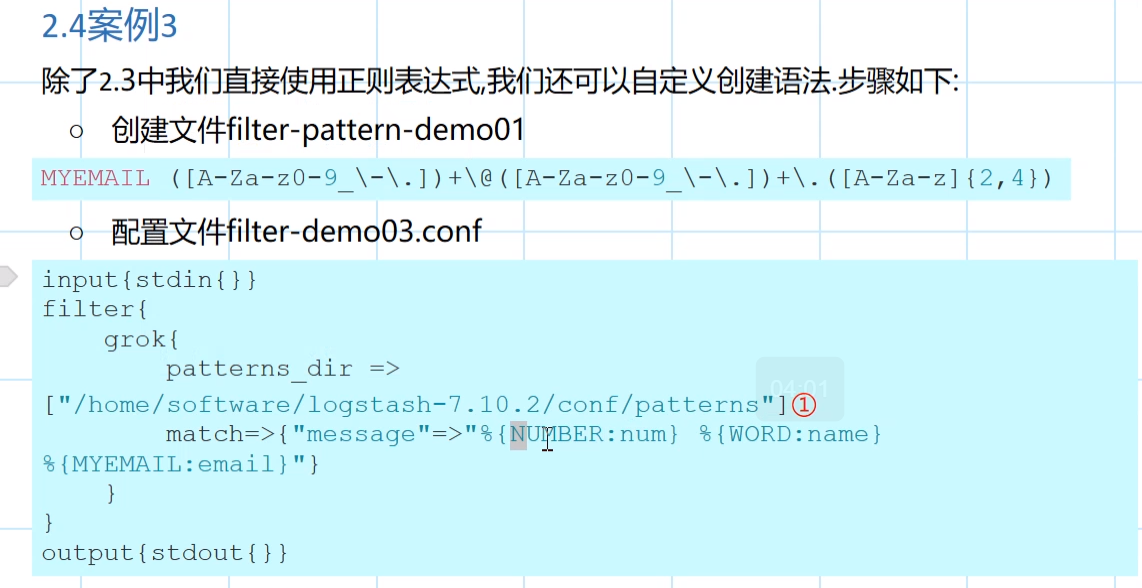
十四:kibana
1.可视化
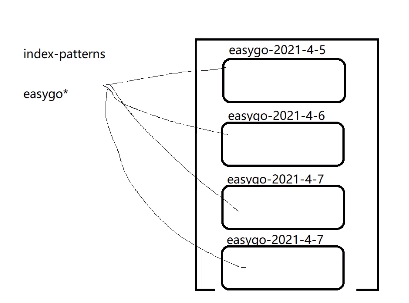
含义:
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号