
很多知识点,这里是学习过程中的记录,也不知道有些知识点是否需要完全记住。如果后续再使用,就直接百度下。这里只做一个后续的机器学习的入门。
git地址:
一:介绍torch
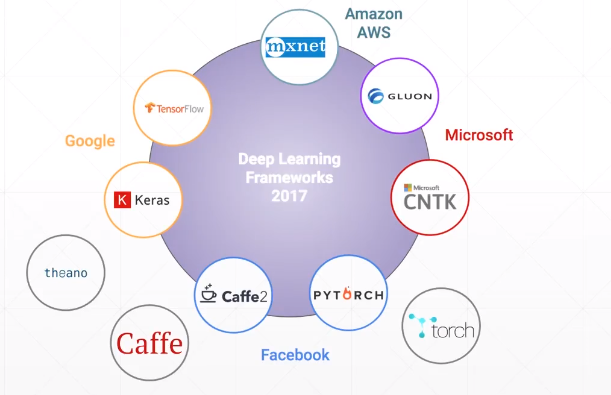
1.常见的机器学习框架
2.能带来什么
GPU加速
自动求导
import torch from torch import autograd x = torch.tensor(1.) a = torch.tensor(1., requires_grad=True) b = torch.tensor(2., requires_grad=True) c = torch.tensor(3., requires_grad=True) y = a ** 2 * x + b * x + c print('before=', a.grad, b.grad, c.grad) # before= None None None grads = autograd.grad(y, [a, b, c]) print('after=', grads[0], grads[1], grads[2]) # after= tensor(2.) tensor(1.) tensor(1.)
大量的Api,Tensor运算,神经网络
二:线性回归(linera包)
1.线性回归的小例子
import numpy as np # 线性回归 # 求loss # loss = (wx +b - y) ** 2 def compute_error_for_line_given_point(b, w, points): totalError = 0 for i in range(0, len(points)): x = points[i, 0] y = points[i, 1] totalError = totalError + (y - (w * x + b)) ** 2 return totalError / float(len(points)) # 求梯度 def step_graient(b_current, w_current, points, learningRate): b_gradient = 0 w_gradient = 0 N = float(len(points)) for i in range(0, len(points)): x = points[i, 0] y = points[i, 1] b_gradient += -(2 / N) * (y - (w_current * x) + b_current) w_gradient += -(2 / N) * x * (y - (w_current * x) + b_current) new_b = b_current - (learningRate * b_gradient) new_w = w_current - (learningRate * w_gradient) return [new_b, new_w] # 迭代 def gradient_descent_runner(points, starting_b, string_w, learing_rate, num_iterations): b = starting_b w = starting_b for i in range(num_iterations): b, w = step_graient(b, w, np.array(points), learing_rate) return [b, w] def run(): points = np.genfromtxt("data.csv", delimiter=',') learning_rate = 0.0001 initial_b = 0 initial_w = 0 number_iterations = 1000 print("running") [b, w] = gradient_descent_runner(points, initial_b, initial_w, learning_rate, number_iterations) print("b={0}, w ={1}, error={2}".format(b, w, compute_error_for_line_given_point(b, w, points))) if __name__ == '__main__': run()
效果:
D:\Python310\python.exe E:/bme-job/torchProjectDemo/linera/linear.py running b=-0.01828261556448748, w =1.332228668839499, error=108.90064375443478 Process finished with exit code 0
其中,data.csv
32.5023,31.7070 52.4268,68.7759 61.5303,62.5623 47.4756,71.5466 59.8132,87.2309 55.1421,78.2115 52.2117,79.6419
2.手写数字集minist引入
one-hot
pred = w3 * {w2 [ w1 * x + b1] + b2} + b3
ReLu函数:

[w1, w2, w3]
[b1, b2, b3]
二:基本数据类型(datatype包)
1.常见的
没有string类型

2.对于string,使用别的方式进行处理
one-hot
Embedding
word2vec
glove
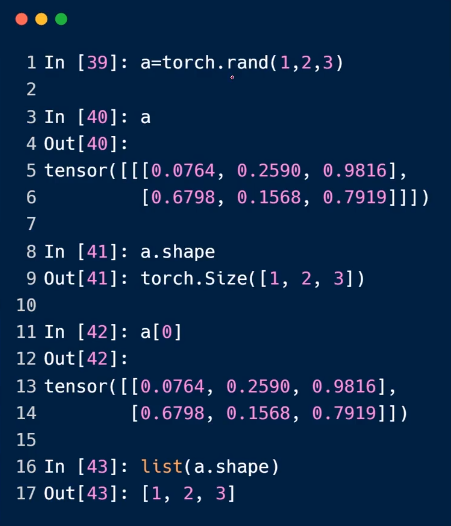
3.dim=0
标量
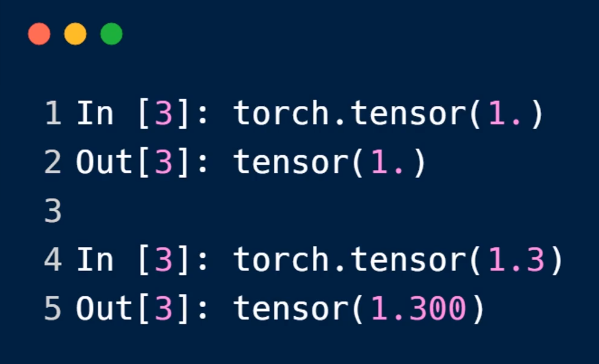
4.dim=1
小写的时候,写入的是具体的值,列表
大写的时候,传入的是,size的张量
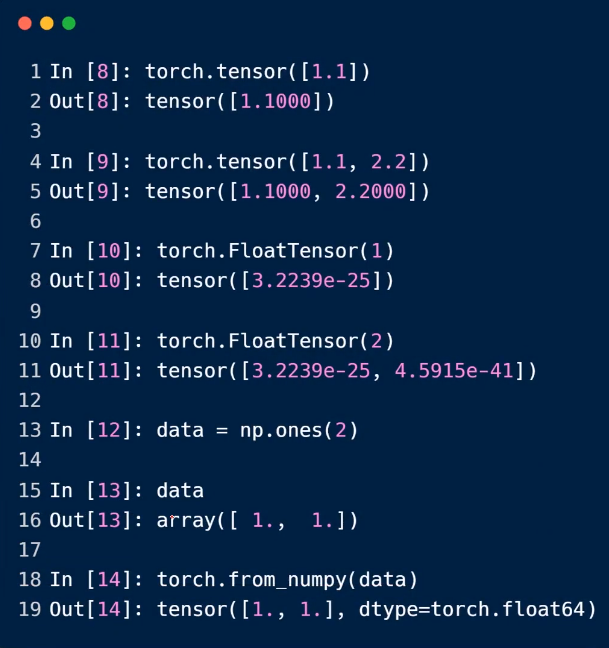
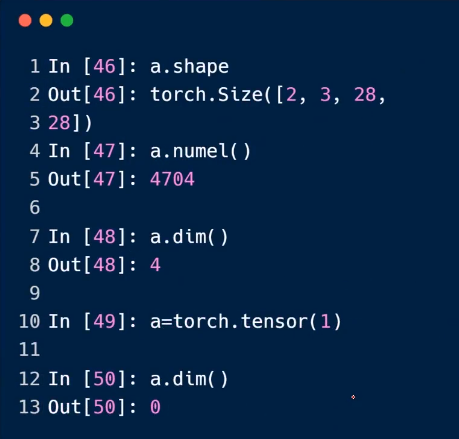
5.dim=2
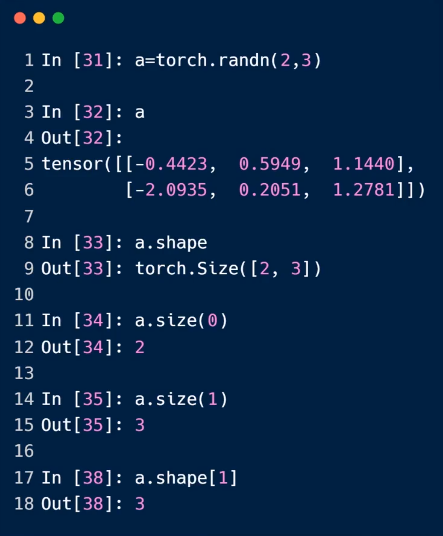
6.dim=3
均匀分布
7.mixed
8.程序
import torch import numpy as np """ 数据类型 """ # 常见的类型判断 a = torch.randn(2,3) # 正态分布 print(a.type()) # torch.FloatTensor print(type(a)) # <class 'torch.Tensor'>, python自带 print(isinstance(a, torch.FloatTensor)) # True # 标量 b = torch.tensor(2.) print(b) # tensor(2.) # 获取形状 print(b.shape) # torch.Size([]) print(b.size()) # torch.Size([]) # 向量 x = torch.tensor([2.3]) y = torch.tensor([2, 4]) print(y) # numpy转torch data = np.ones(4) xx = torch.from_numpy(data) print(xx) # print(x.shape) print(x.numel()) # 占用内存 print(x.dim()) # 维度
三:创建tensor(datatype包)
1.创建
从numpy中
直接传入list的方式
非初始化的api
# numpy data = np.ones(4) xx = torch.from_numpy(data) # 直接传入 y = torch.tensor([2, 3]) print(y)
2.默认类型的修改
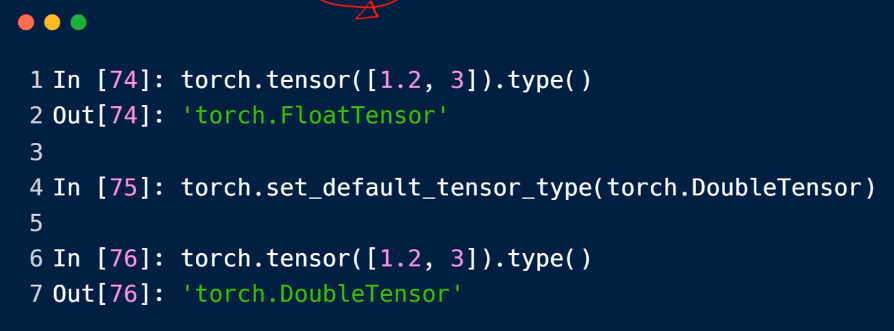
3.api
rand,ranfint,*_like
randint中,前包含后不包含
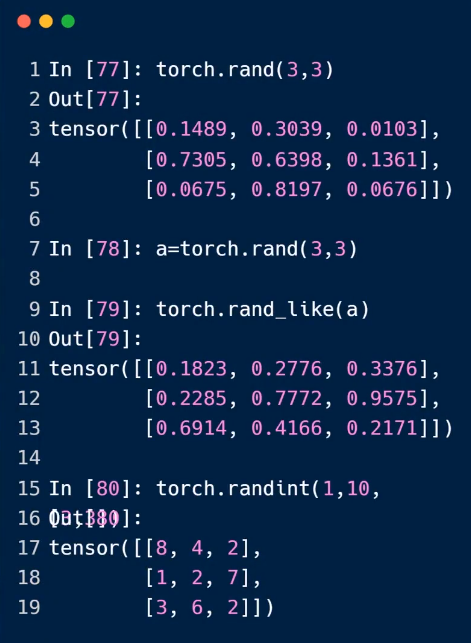
randn
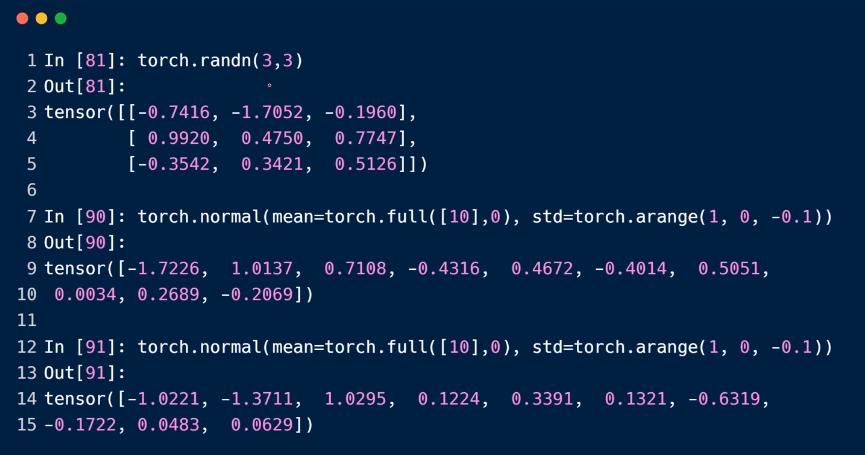
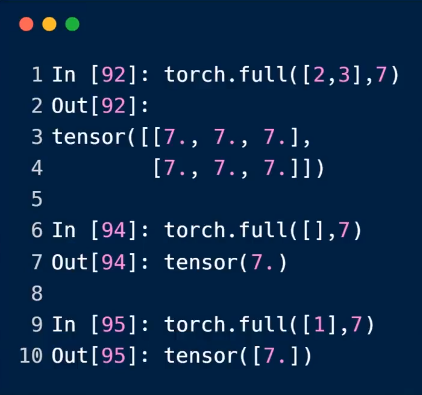
full
全部设置一样的数据
下面一个数据的时候,可以是标量,也可以是向量,所以第二个和第三个案例,是需要注意的。
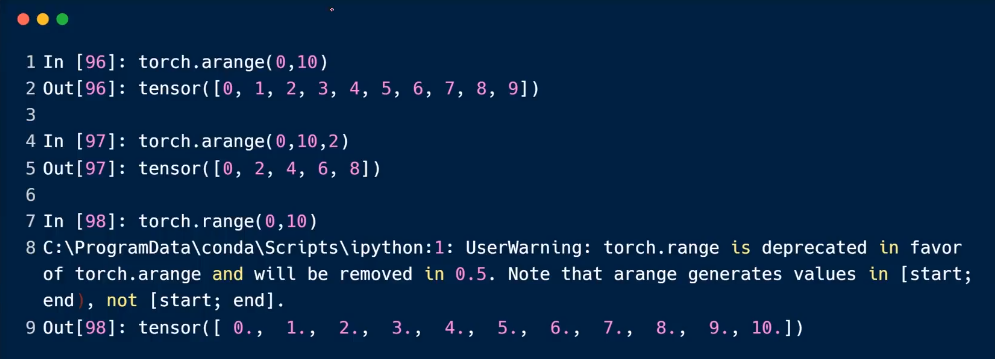
arange与range
建议使用arrange,等差的数列
第三个参数是阶梯值
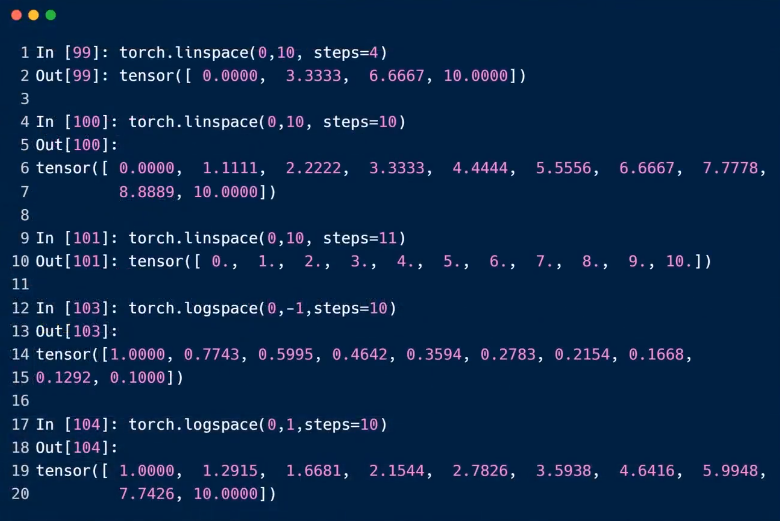
linspace,logspace
这里是前包含与后包含
第三个参数是切分的个数,不是阶梯值
logspace是以10位第,指数是被切割后的数据。
ones,zeros,eye
eye只适合传入一个,两个参数
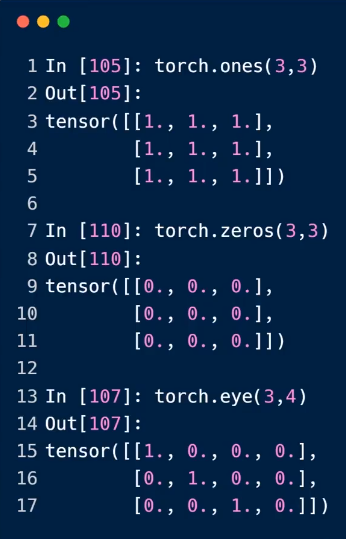
4.可以直接使用的api
#### a = torch.rand(2, 5) print(a) b = torch.randint(1, 10, [3, 4]) print(b) c = torch.full([2, 3], 7) # 2行3列 print(c) d = torch.full([], 6) # 标量 print(d) e = torch.arange(0, 10) print(e) f = torch.linspace(0, 10, steps=3) print(f) g = torch.logspace(0, 1, steps=10) print(g) torch.ones(3,3) torch.zeros(3,4) torch.eye(4)
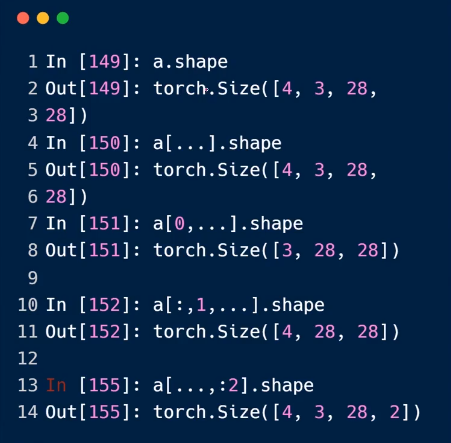
四:索引与切片
1.索引与切片
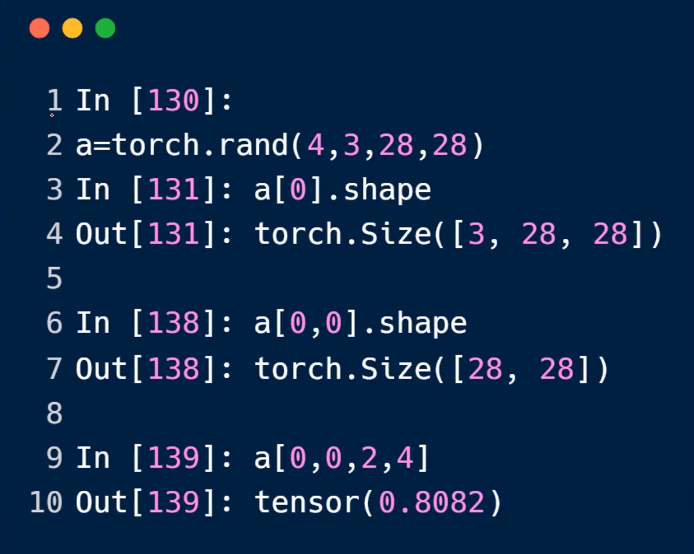
选择开始或者最后的N个值
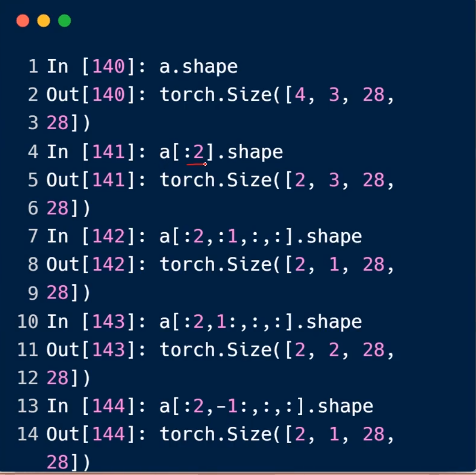
隔行采样
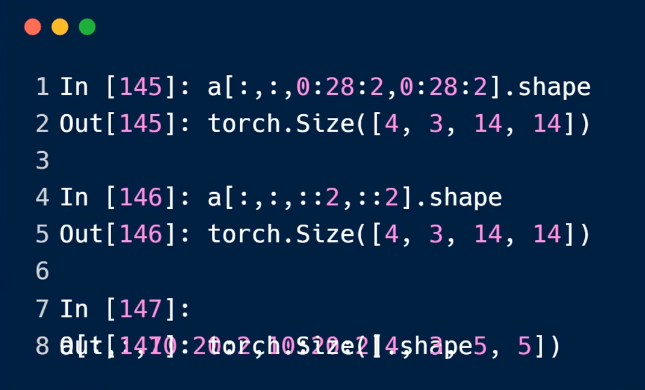
特殊方式进行采样:
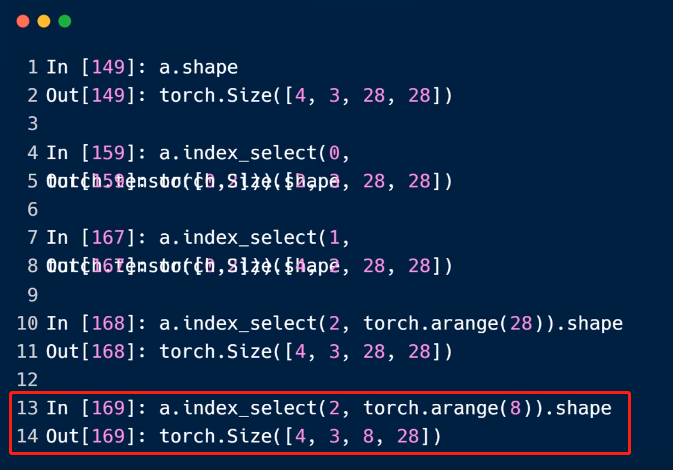
...
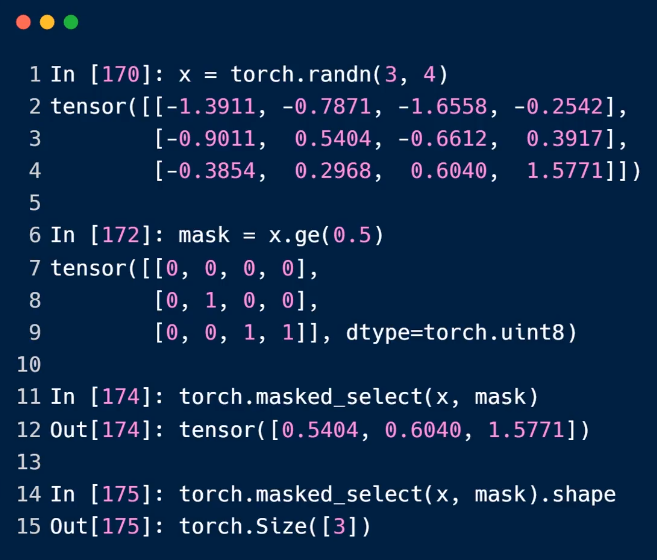
通过mask选择
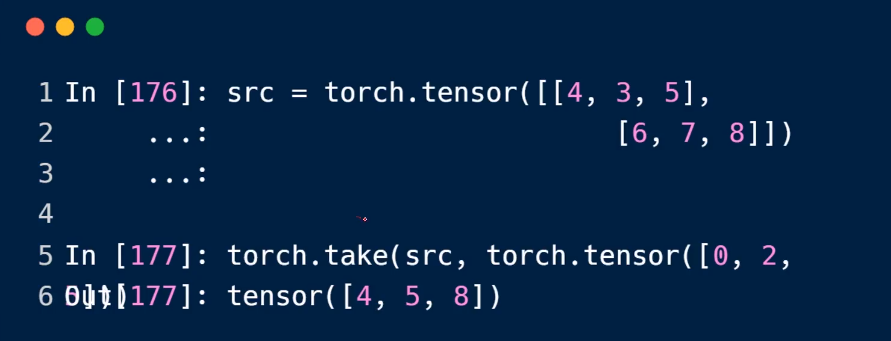
take方式,这种方式会被打平
2.程序
import torch data = torch.rand(4, 3, 28, 28) print(data[0].shape) # torch.Size([3, 28, 28]) print(data[0][0].shape) # torch.Size([28, 28]) print(data[0][0][4][2].item()) print(data[:2].shape) # torch.Size([2, 3, 28, 28]) print(data[:2, :1, :, :].shape) # torch.Size([2, 1, 28, 28]) print(data[:1, -1, :, :].shape) # torch.Size([1, 28, 28]) print(data[:,:,::2,::2].shape) # torch.Size([4, 3, 14, 14]) x = torch.randn(3,4) print(x) mask = x.ge(0.5) print(mask)
五:维度变换(transform)
1.api
view、reshape
squeeze,unsqueeze
Transpose、t、permute
Expand、repeat
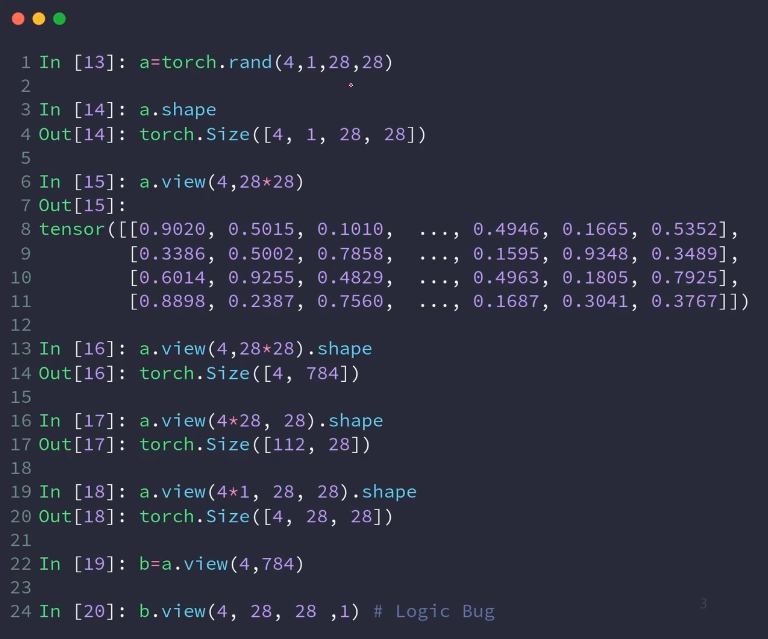
2.view、reshape
使用方式一样
3.squeeze与unsqueeze
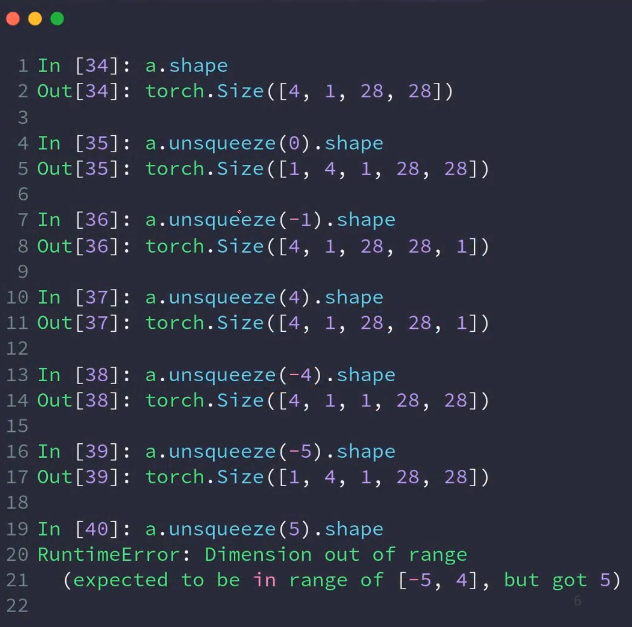
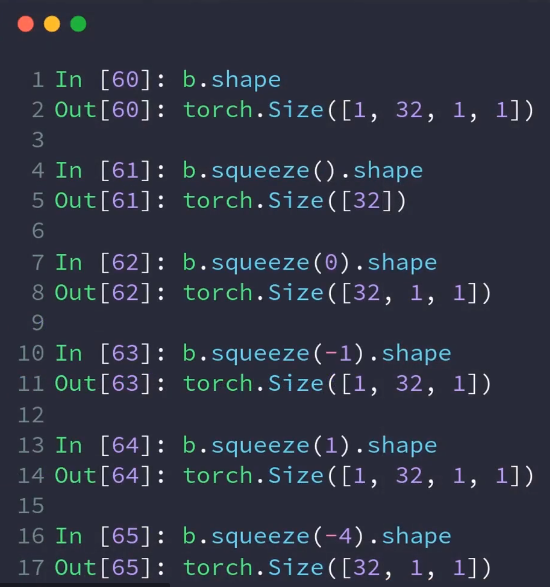
import torch # unsqueeze data = torch.rand(4, 2, 28, 28) # 在位置上插入 print(data.unsqueeze(0).shape) # torch.Size([1, 4, 2, 28, 28]) print(data.unsqueeze(1).shape) # torch.Size([4, 1, 2, 28, 28]) #squeeze # 指定删除的维度,不然全部挤压 data = torch.rand(1, 2, 28, 1) print(data.squeeze().shape) # torch.Size([2, 28])
4.expand、repeat

# 扩展 # expand,不增加数据 b = torch.rand(1, 32, 14, 14) print(b.expand(4, 32, 14, 14).shape) # torch.Size([4, 32, 14, 14]) print(b.expand(-1, 32, 14, 14).shape) # torch.Size([1, 32, 14, 14]),-1表示不变 # repeat,拷贝次数 b = torch.rand(1, 32, 14, 14) print(b.repeat(4, 32, 1, 1).shape) # torch.Size([4, 1024, 14, 14])
5.Transpose、t、permute
t:只适用于二维
六:自动扩展Broadcasting
1.做法
小维度相同,大维度进行补充
小维度进行扩张
2.举例子
A:[4,3,14,14]
B:[32, 1,1]
=》 [32, 1,1] => [1,32, 1,1] => [4, 32, 14, 14]
七:合并与分割(merge)
1.api
cat
stack
split
chunk
2.api
cat:

stack
前面加上一个维度

split:
下面的两种情况,都是给定的参数。一个是固定的,一个是随意的设置。
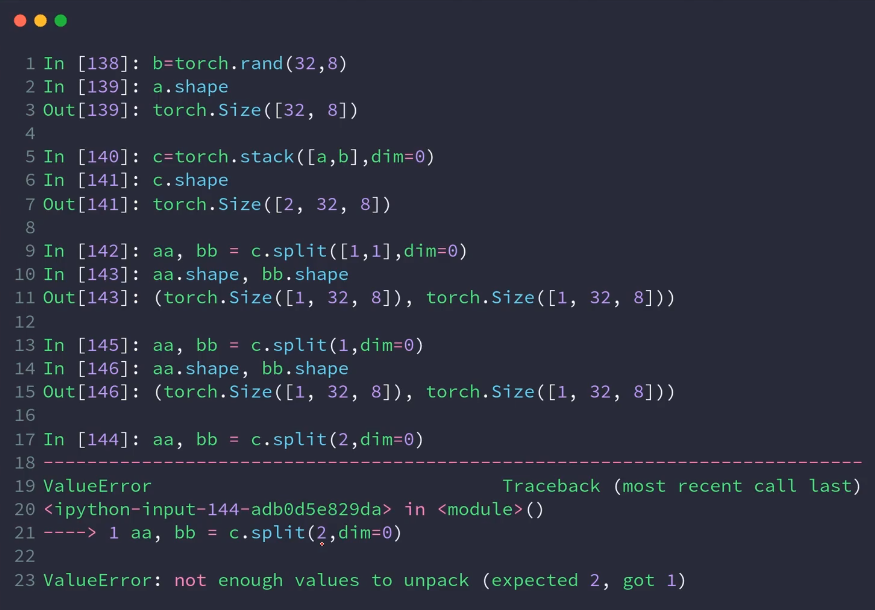
3.程序
import torch # cat a = torch.rand(4, 32, 8) b = torch.rand(5, 32, 8) c = torch.cat([a, b], dim=0) print(c.shape) # torch.Size([9, 32, 8]) # stack a1 = torch.rand(4, 3, 16, 32) a2 = torch.rand(4, 3, 16, 32) c = torch.stack([a1, a2], dim=2) print(c.shape) # torch.Size([4, 3, 2, 16, 32]), 掺入一个新的维度 # split x, y = a.split(2, dim=0) print(x.shape) # torch.Size([2, 32, 8]) print(y.shape) # torch.Size([2, 32, 8]) # chunk aa, bb = c.chunk(2, dim=0) print("aa", aa.shape) # aa torch.Size([2, 3, 2, 16, 32])
八:数学运算
1.api
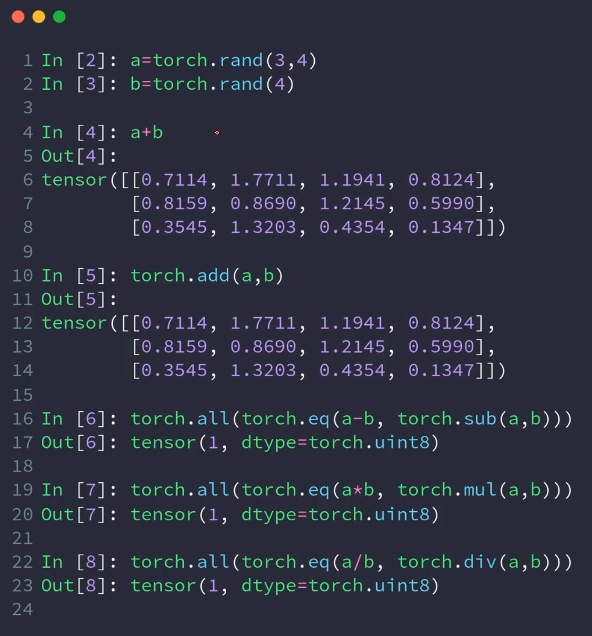
add,minus,multiply,divide:对应位置的处理
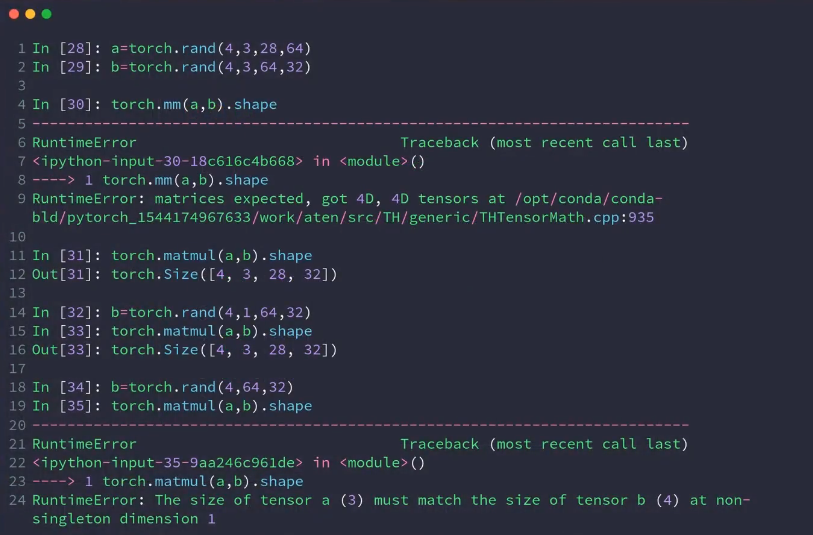
matmul:mm,matmul,@,矩阵相乘
pow
sqrt,rsqrt(平方根的导数)
round:四舍五入
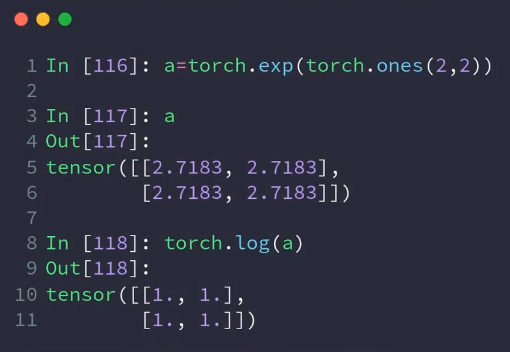
exp:e的对数
log:以e为底
trunc:取整数
frac:取小数
clamp:可以(min),(min,max)
2.api
basic
矩阵相乘

多维上处理
次方:

e:
小数:

clamp:

3.程序
import torch # ADD a = torch.rand(3, 4) b = torch.rand(4) torch.add(a, b) #clamp
九:统计属性
1.api
norm:范数
mean:
sum
prod
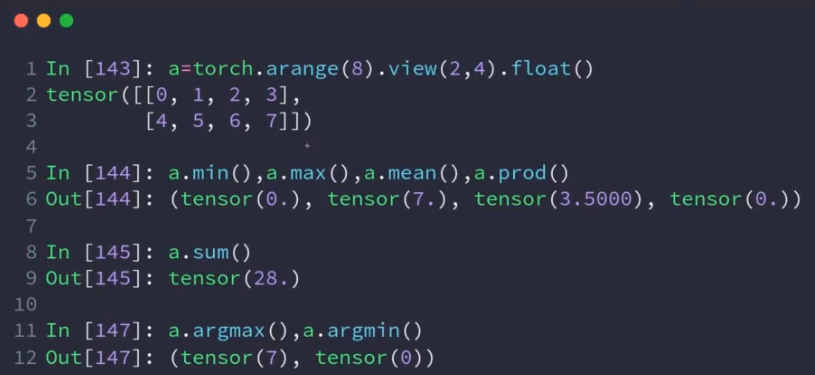
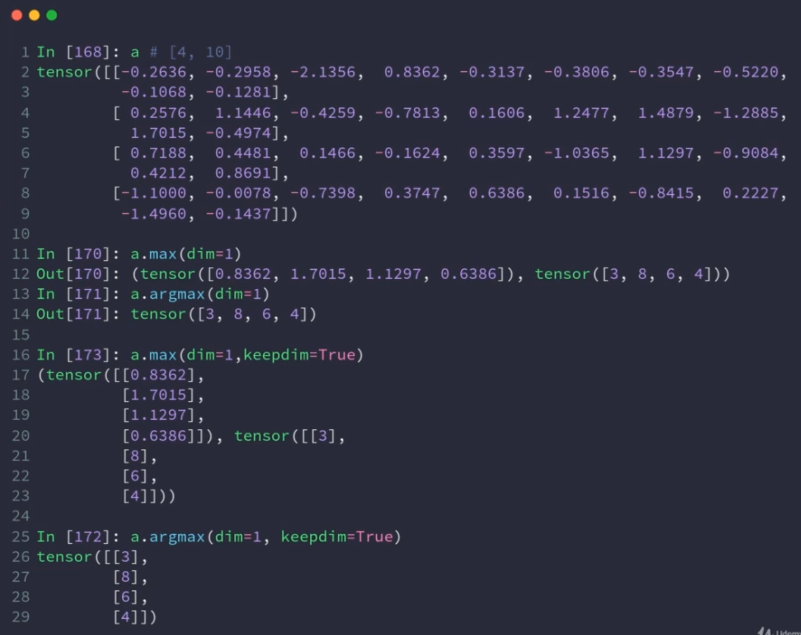
max,min,
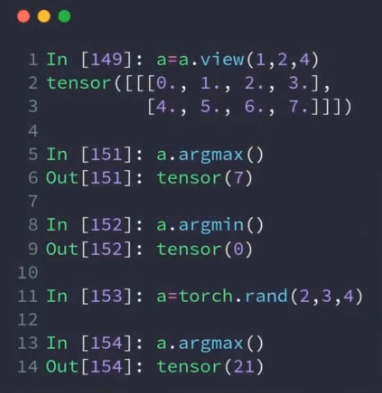
argmin,argmax:返回索引,打平;可以加维度
kthvalue
topk

2.api
norm-p
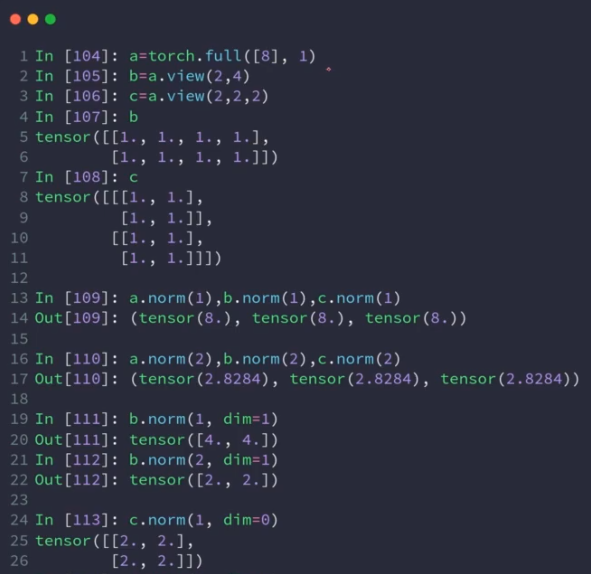
保证不被打平:

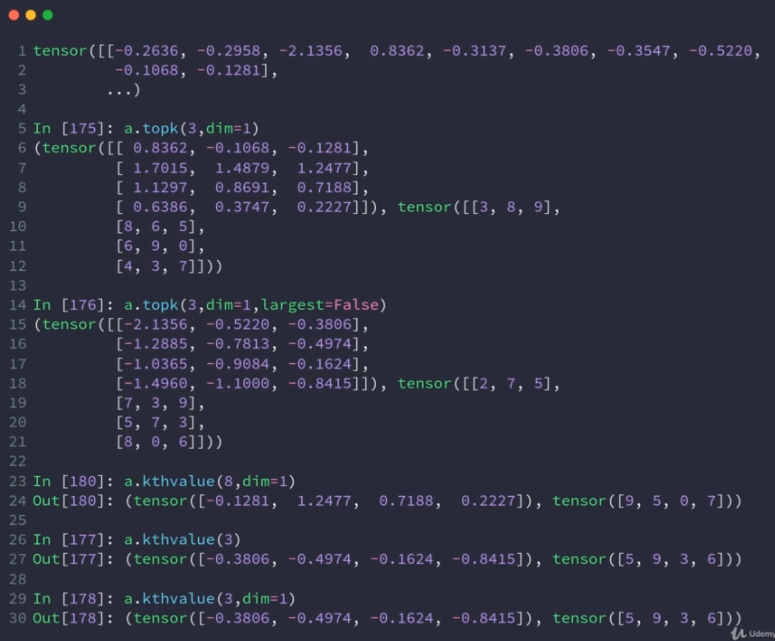
十:激活函数与loss
1.sigmoid
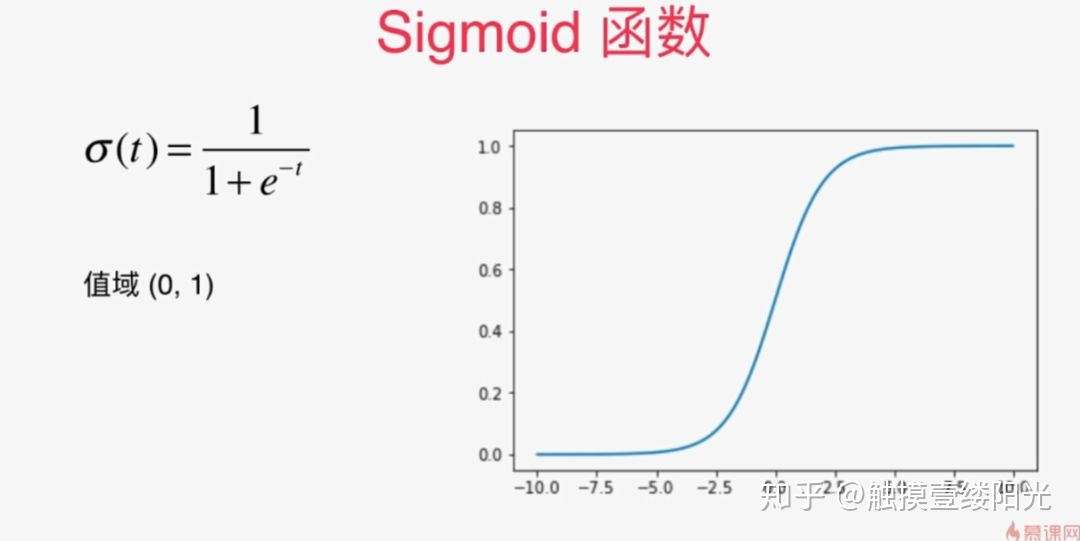
求导情况:
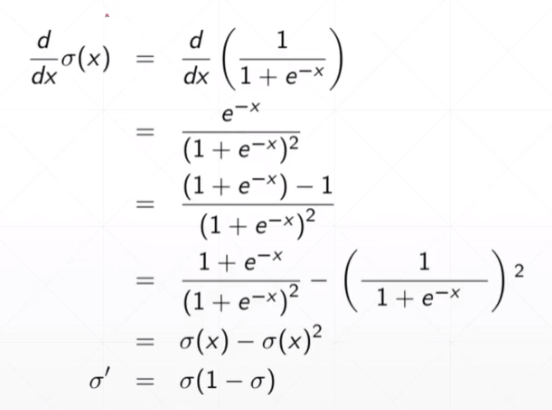
两边接近0,1:
# sigmoid a = torch.linspace(-100, 100,10) b = torch.sigmoid(a) print(b)
2.tanh

# tanh a = torch.linspace(-1, 1,10) b = torch.tanh(a) print(b)
3.ReLU

#ReLu a = torch.linspace(-1, 1,10) b = torch.relu(a) print(b)
4.loss

5.loss - MSE
均方差
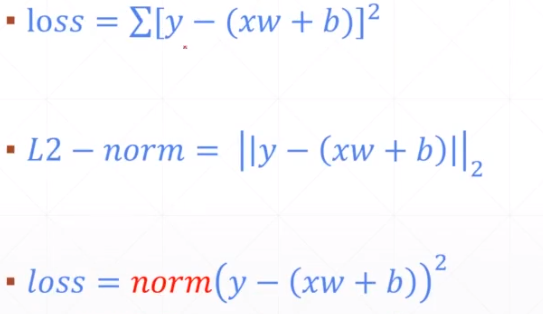
api:

torch.autograd.grad(loss, [w1,w2,w3])
# x = torch.ones(1) w = torch.full([1], 2.) w.requires_grad_() mse = F.mse_loss(torch.ones(1), x * w) xx = torch.autograd.grad(mse, [w]) print(xx)
第二种方式:
loss.backgrad()
# x = torch.ones(1) w = torch.full([1], 2.) w.requires_grad_() mse = F.mse_loss(torch.ones(1), x * w) xx = torch.autograd.grad(mse, [w]) print(xx) mse = F.mse_loss(torch.ones(1), x * w) mse.backward() yy = w.grad print(yy)
5.loss - softmax
参考:https://zhuanlan.zhihu.com/p/105722023
oftmax的含义就在于不再唯一的确定某一个最大值,而是为每个输出分类的结果都赋予一个概率值,表示属于每个类别的可能性。
其中 为第i个节点的输出值,C为输出节点的个数,即分类的类别个数。通过Softmax函数就可以将多分类的输出值转换为范围在[0, 1]和为1的概率分布。
偏导数的最终表达式如下:
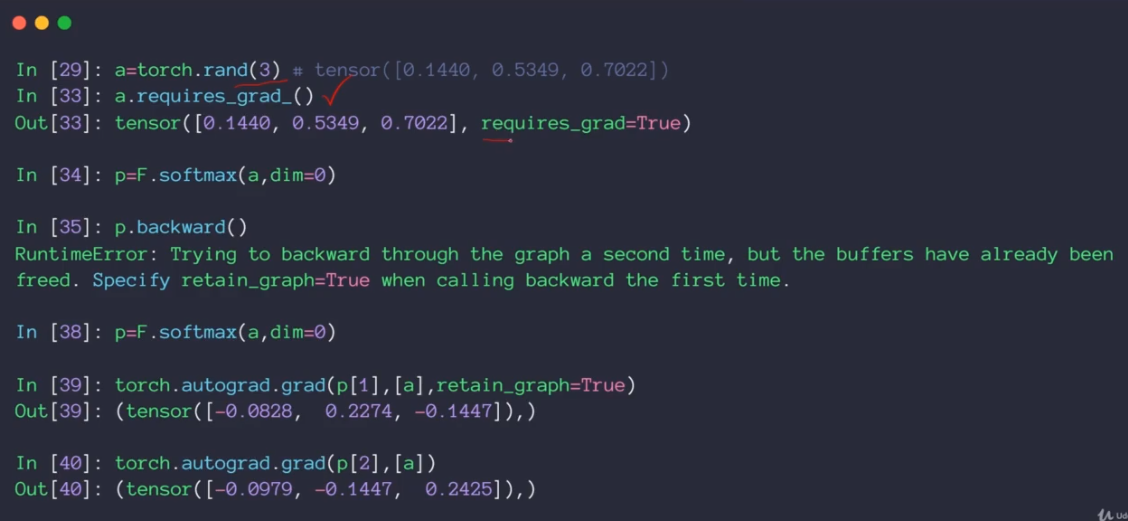
# a = torch.rand(3) a.requires_grad_() p = F.softmax(a, dim=0) y = torch.autograd.grad(p[1], [a], retain_graph=True) print(y) y = torch.autograd.grad(p[2], [a], retain_graph=True) print(y)
6.loss - Cross Entropy Loss
分类使用的loss,这里不进行说明。
十一:感知机
1.单层感知机
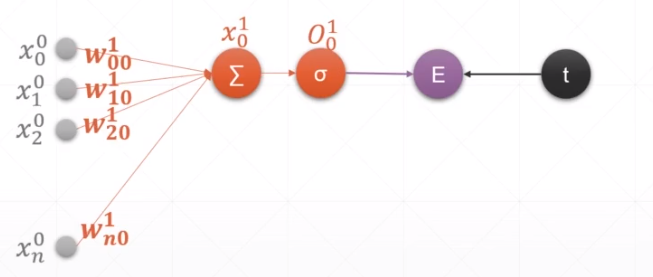
上标:表示第几层
w:链接左和右
求导过程:
loss使用的是MSE

可以明显的看到求导后,和什么有关系。
程序
# 单层感知机 x = torch.randn(1,10) w = torch.randn(1,10, requires_grad=True) o= torch.sigmoid(x@w.t()) print(o.shape) loss = F.mse_loss(torch.ones(1,1), o) loss.backward() print(w.grad)
2.MLP感知机
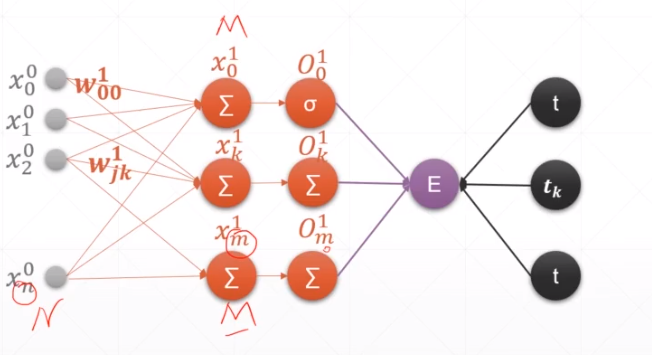
求导:
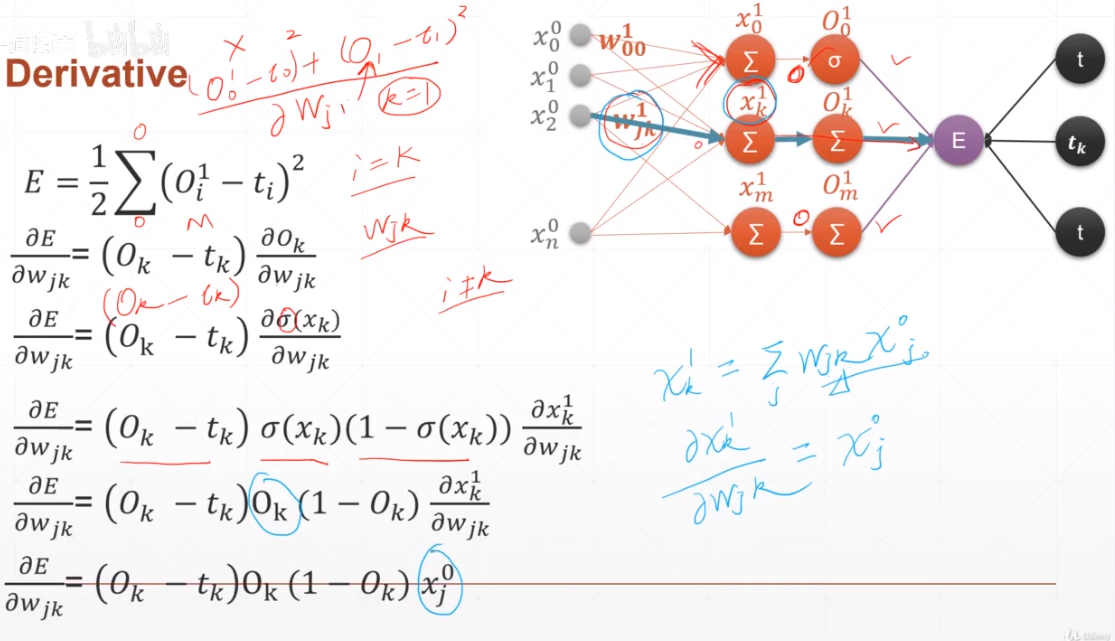
#MLP x = torch.randn(1,10) w = torch.randn(2,10, requires_grad=True) o= torch.sigmoid(x@w.t()) print(o.shape) loss = F.mse_loss(torch.ones(1,2), o) loss.backward() print(w.grad)
十二:函数极小值的实战
1.函数
f(x, y) = (x**2 + y -11) ** 2 + (x + y**2 - 7) ** 2
import numpy as np import matplotlib.pyplot as plt def himmelblau(x): return (x[0] ** 2 + x[1] - 11) ** 2 + (x[0] + x[1] ** 2 - 7) ** 2 x = np.arange(-6, 6, 0.1) y = np.arange(-6, 6, 0.1) X, Y = np.meshgrid(x, y) Z = himmelblau([X, Y]) fig = plt.figure('himmelblau') ax = fig.gca(projection='3d') ax.plot_surface(X, Y, Z) ax.view_init(60, -30) ax.set_xlabel('x') ax.set_ylabel('y') plt.show()
效果:
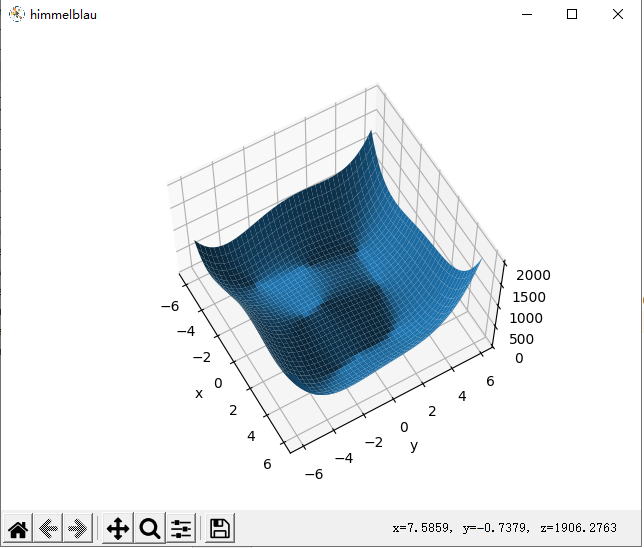
2.求最小值
import torch from neo import himmelblau x = torch.tensor([0., 0.], requires_grad=True) optimizer = torch.optim.Adam([x], lr = 1e-3) for step in range(20000): pred = himmelblau(x) optimizer.zero_grad() pred.backward() optimizer.step() if step % 2000 == 0: print('step {}: x ={}, f(x) = {}'.format(step, x.tolist(), pred.item()))
效果:
D:\Python310\python.exe E:/bme-job/torchProjectDemo/neo/minComp.py step 0: x =[0.0009999999310821295, 0.0009999999310821295], f(x) = 170.0 step 2000: x =[2.3331806659698486, 1.9540694952011108], f(x) = 13.730916023254395 step 4000: x =[2.9820079803466797, 2.0270984172821045], f(x) = 0.014858869835734367 step 6000: x =[2.999983549118042, 2.0000221729278564], f(x) = 1.1074007488787174e-08 step 8000: x =[2.9999938011169434, 2.0000083446502686], f(x) = 1.5572823031106964e-09 step 10000: x =[2.999997854232788, 2.000002861022949], f(x) = 1.8189894035458565e-10 step 12000: x =[2.9999992847442627, 2.0000009536743164], f(x) = 1.6370904631912708e-11 step 14000: x =[2.999999761581421, 2.000000238418579], f(x) = 1.8189894035458565e-12 step 16000: x =[3.0, 2.0], f(x) = 0.0 step 18000: x =[3.0, 2.0], f(x) = 0.0 Process finished with exit code 0
十三:Logistics Regression
1.说明
y = xw + b
y = sigimod(xw + b)
十四:交叉熵
1.corss Entropy
衡量两个分布的情况
Dkl:散度

2.说明
在F.cross_entropy中,已经包含了softmax与entropy
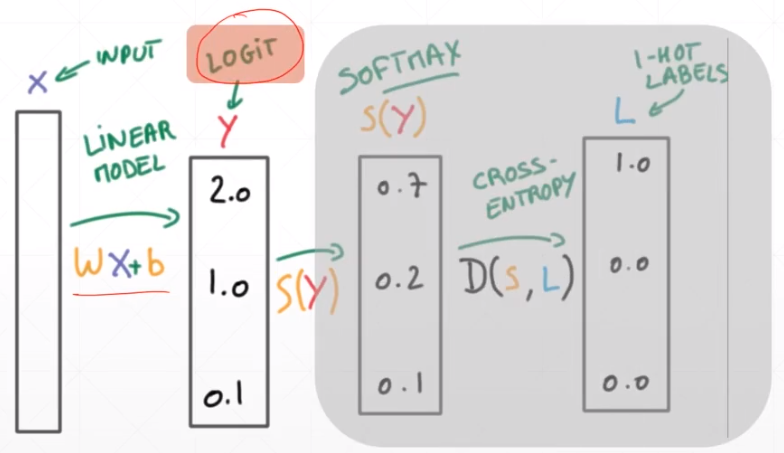
import torch import torch.nn.functional as F x = torch.randn(1, 784) w = torch.randn(10, 784) logits = x @ w.t() pred = F.softmax(logits, dim=1) pred_log = torch.log(pred) F.cross_entropy(logits, torch.tensor([3])) F.nll_loss(pred_log, torch.tensor([3]))
3.举例子
0~1编码。
二分类:


十五:基础多分类问题实战
1.说明
多层感知机
2.程序
import torch import torch.nn.functional as F import torch.nn as nn import torchvision.datasets as datasets from torchvision.transforms import transforms batch_size = 200 learning_rate = 0.01 epochs = 10 train_loader = torch.utils.data.DataLoader( datasets.MNIST('../data', train=True, download=True, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ])), batch_size=batch_size, shuffle=True) test_loader = torch.utils.data.DataLoader( datasets.MNIST('../data', train=False, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ])), batch_size=batch_size, shuffle=True) w1, b1 = torch.randn(200, 784, requires_grad=True), torch.zeros(200, requires_grad=True) w2, b2 = torch.randn(200, 200, requires_grad=True), torch.zeros(200, requires_grad=True) w3, b3 = torch.randn(10, 200, requires_grad=True), torch.zeros(10, requires_grad=True) torch.nn.init.kaiming_normal_(w1) torch.nn.init.kaiming_normal_(w2) torch.nn.init.kaiming_normal_(w3) def forward(x): x = x @ w1.t() + b1 x = F.relu(x) x = x @ w2.t() + b2 x = F.relu(x) x = x @ w3.t() + b3 x = F.relu(x) return x optimizer = torch.optim.SGD([w1, b1, w2, b2, w3, b3], lr=learning_rate) criteon = nn.CrossEntropyLoss() for epoch in range(epochs): for batch_idx, (data, target) in enumerate(train_loader): data = data.view(-1, 28 * 28) logits = forward(data) loss = criteon(logits, target) optimizer.zero_grad() loss.backward() optimizer.step() if batch_idx % 100 == 0: print("train epoch:{} [{}/{} ({:.0f}%)] loss:{:.6f}".format(epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item())) test_loss = 0 correct = 0 for data, target in test_loader: data = data.view(-1, 28 * 28) logits = forward(data) test_loss += criteon(logits, target).item() pred = logits.data.max(1)[1] correct += pred.eq(target.data).sum() test_loss /= len(test_loader.dataset) print("test set: avg loss:{:.4f}, accurracy:{}/{} ({:.0f}%)".format(test_loss, correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset)))
十六:更高层的多层感知机MLP的代码实现
1.代码
从十四处修改。
import torch import torch.nn.functional as F import torch.nn as nn import torchvision.datasets as datasets from torchvision.transforms import transforms batch_size = 200 learning_rate = 0.01 epochs = 10 train_loader = torch.utils.data.DataLoader( datasets.MNIST('../data', train=True, download=True, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ])), batch_size=batch_size, shuffle=True) test_loader = torch.utils.data.DataLoader( datasets.MNIST('../data', train=False, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ])), batch_size=batch_size, shuffle=True) class MLP(nn.Module): def __init__(self): super(MLP, self).__init__() self.model = nn.Sequential( nn.Linear(784, 200), nn.ReLU(inplace=True), nn.Linear(200, 200), nn.ReLU(inplace=True), nn.Linear(200, 10), nn.ReLU(inplace=True) ) def forward(self, x): x = self.model(x) return x net = MLP() optimizer = torch.optim.SGD(net.parameters(), lr=learning_rate) criteon = nn.CrossEntropyLoss() for epoch in range(epochs): for batch_idx, (data, target) in enumerate(train_loader): data = data.view(-1, 28 * 28) logits = net(data) loss = criteon(logits, target) optimizer.zero_grad() loss.backward() optimizer.step() if batch_idx % 100 == 0: print("train epoch:{} [{}/{} ({:.0f}%)] loss:{:.6f}".format(epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item()))
十七:测试方法
1.argmax
import torch import torch.nn.functional as F logits = torch.rand(4, 10) print(logits) pred = F.softmax(logits, dim=1) pred_label = pred.argmax(dim=1) print(pred_label) logits_label = logits.argmax(dim=1) print(logits_label) correct = torch.eq(pred_label, logits_label) p = correct.sum().float().item()/4 print(p)
效果:
D:\Python310\python.exe E:/bme-job/torchProjectDemo/testfunc/__init__.py tensor([[0.1136, 0.3696, 0.1820, 0.0226, 0.7538, 0.1207, 0.1534, 0.2651, 0.7911, 0.8177], [0.7851, 0.0472, 0.5592, 0.6051, 0.0040, 0.4928, 0.7743, 0.3060, 0.9892, 0.1030], [0.5440, 0.1287, 0.6918, 0.1310, 0.0184, 0.3540, 0.4793, 0.9201, 0.4526, 0.5501], [0.1208, 0.8229, 0.9587, 0.9668, 0.8220, 0.4514, 0.1743, 0.1008, 0.2912, 0.4670]]) tensor([9, 8, 7, 3]) tensor([9, 8, 7, 3]) 1.0 Process finished with exit code 0
十八:可视化
1.安装visdom
pip install visdom
2.处理
参考:
https://blog.csdn.net/FairyTale__/article/details/104576538
3.学习可参考
https://www.w3cschool.cn/article/86830765.html
十九:过拟合与欠拟合
1.使用val数据
import torch import torch.nn.functional as F import torch.nn as nn import torchvision.datasets as datasets from torchvision.transforms import transforms from visdom import Visdom batch_size = 200 learning_rate = 0.01 epochs = 10 viz = Visdom() train_db = datasets.MNIST('../data', train=True, download=True, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ])) train_loader = torch.utils.data.DataLoader(train_db, batch_size=batch_size, shuffle=True) test_db = datasets.MNIST('../data', train=False, transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ])) test_loader = torch.utils.data.DataLoader(test_db, batch_size=batch_size, shuffle=True) # 得到val loader train_db, val_db = torch.utils.data.random_split(train_db, [50000, 10000]) train_loader = torch.utils.data.DataLoader(train_db, batch_size=batch_size, shuffle=True) val_loader = torch.utils.data.DataLoader(val_db, batch_size=batch_size, shuffle=True) w1, b1 = torch.randn(200, 784, requires_grad=True), torch.zeros(200, requires_grad=True) w2, b2 = torch.randn(200, 200, requires_grad=True), torch.zeros(200, requires_grad=True) w3, b3 = torch.randn(10, 200, requires_grad=True), torch.zeros(10, requires_grad=True) torch.nn.init.kaiming_normal_(w1) torch.nn.init.kaiming_normal_(w2) torch.nn.init.kaiming_normal_(w3) def forward(x): x = x @ w1.t() + b1 x = F.relu(x) x = x @ w2.t() + b2 x = F.relu(x) x = x @ w3.t() + b3 x = F.relu(x) return x optimizer = torch.optim.SGD([w1, b1, w2, b2, w3, b3], lr=learning_rate) criteon = nn.CrossEntropyLoss() for epoch in range(epochs): for batch_idx, (data, target) in enumerate(train_loader): data = data.view(-1, 28 * 28) logits = forward(data) loss = criteon(logits, target) optimizer.zero_grad() loss.backward() optimizer.step() if batch_idx % 100 == 0: print("train epoch:{} [{}/{} ({:.0f}%)] loss:{:.6f}".format(epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item())) test_loss = 0 correct = 0 for data, target in val_loader: data = data.view(-1, 28 * 28) logits = forward(data) test_loss += criteon(logits, target).item() pred = logits.argmax(dim=1) correct += pred.eq(target).float().sum().item() test_loss /= len(test_loader.dataset) print("test set: avg loss:{:.4f}, accurracy:{}/{} ({:.0f}%)".format(test_loss, correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset))) test_loss = 0 correct = 0 for data, target in val_loader: data = data.view(-1, 28 * 28) logits = forward(data) test_loss += criteon(logits, target).item() pred = logits.argmax(dim=1) correct += pred.eq(target).float().sum().item() test_loss /= len(test_loader.dataset) print("test set: avg loss:{:.4f}, accurracy:{}/{} ({:.0f}%)".format(test_loss, correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset)))
2.降低overfitting

3.REgularization

4.常见的Regularization
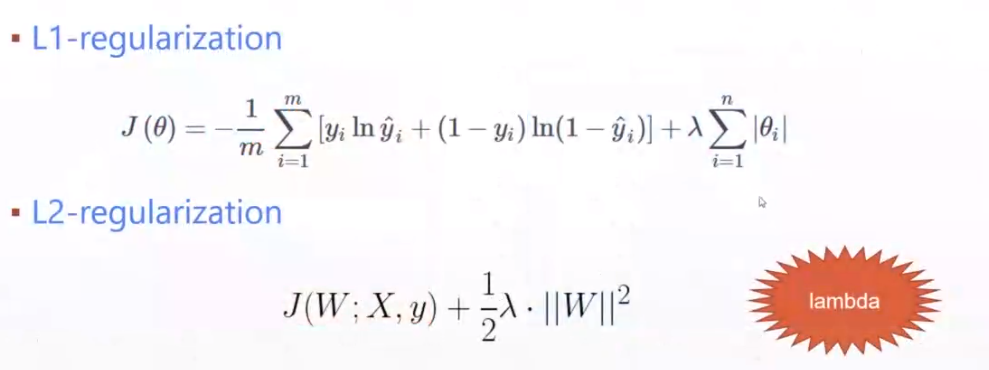
L2-Regularization
weight_decay进行约束
import torch net = MLP() optimizer = torch.optim.SGD(net.parameters(), lr = 0.001, weight_decay = 0.01)
L1-Regularization
人为自己写
import torch for param in model.parameters(): regularization_loss += torch.sum(torch.abs(param)) classify_loss = criteon(logits, target) loss = classify_loss + 0.01 * regularization_loss
5.momentum
动量
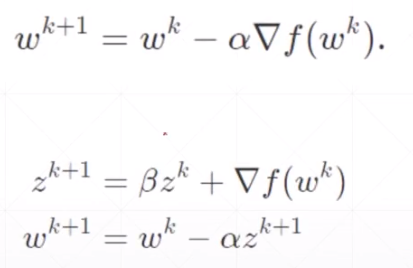
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum = 0.07)
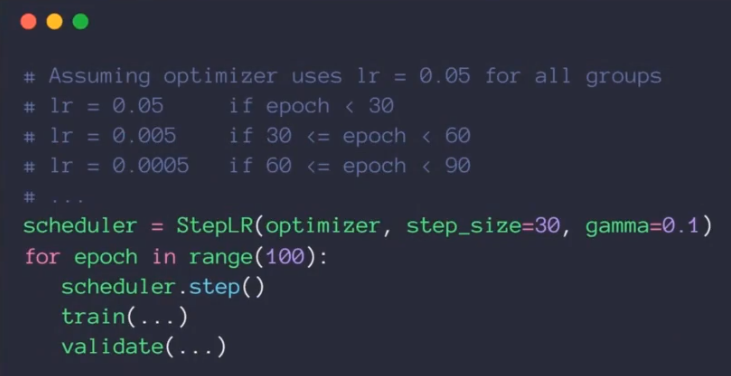
6.步进
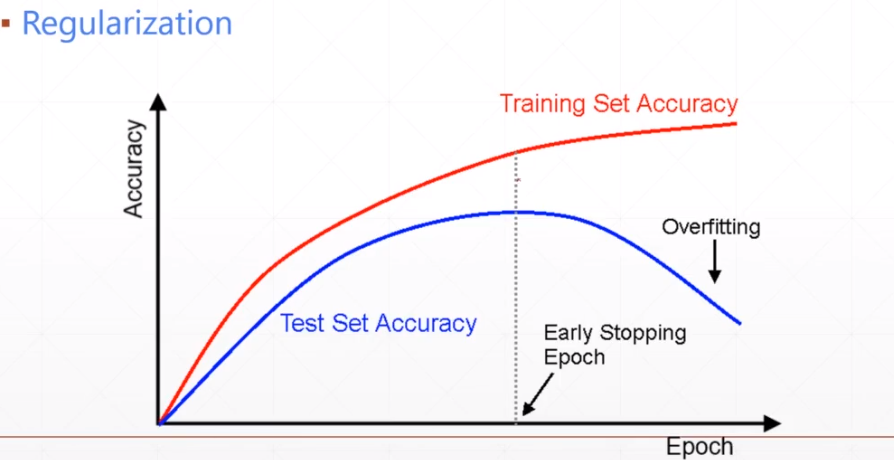
7.early stopping
8.dropout
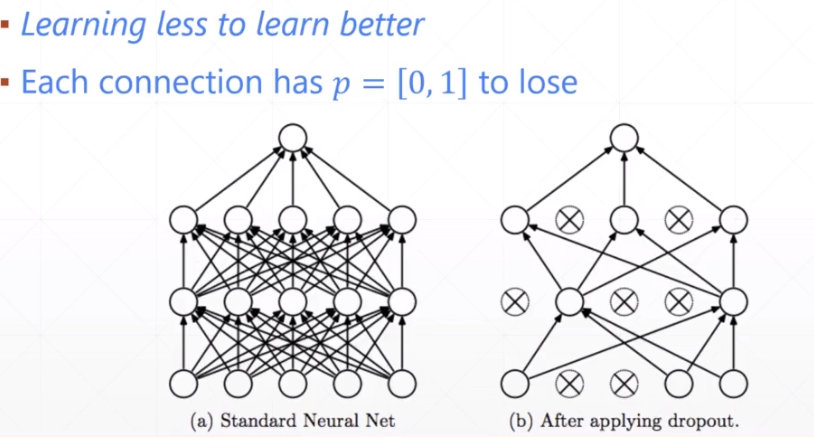
实现:
class MLP(nn.Module): def __init__(self): super(MLP, self).__init__() self.model = nn.Sequential( nn.Linear(784, 200), nn.Dropout(0.5), nn.ReLU(inplace=True), nn.Linear(200, 200), nn.ReLU(inplace=True), nn.Linear(200, 10), nn.ReLU(inplace=True) ) def forward(self, x): x = self.model(x) return x
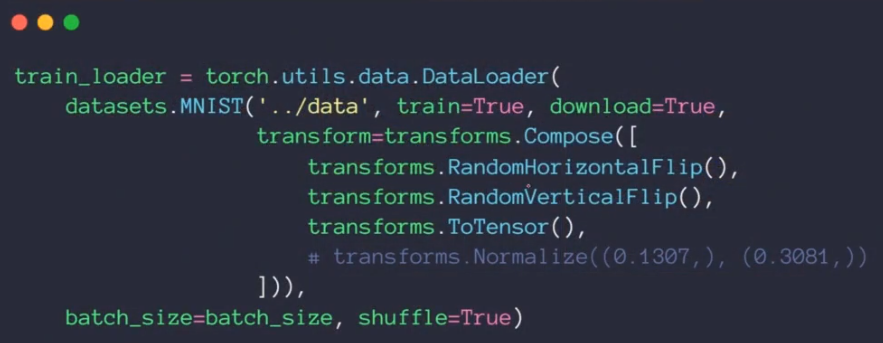
9.Data argumentation

Flip:
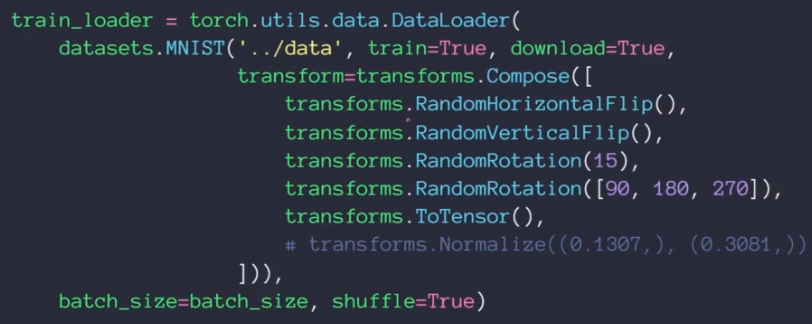
rotate:
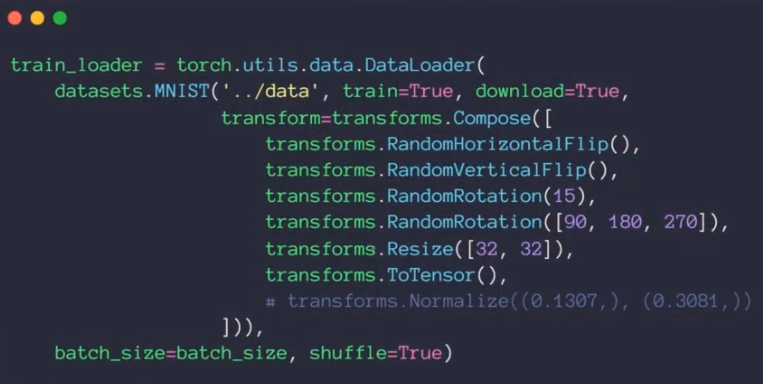
scale:
crop:
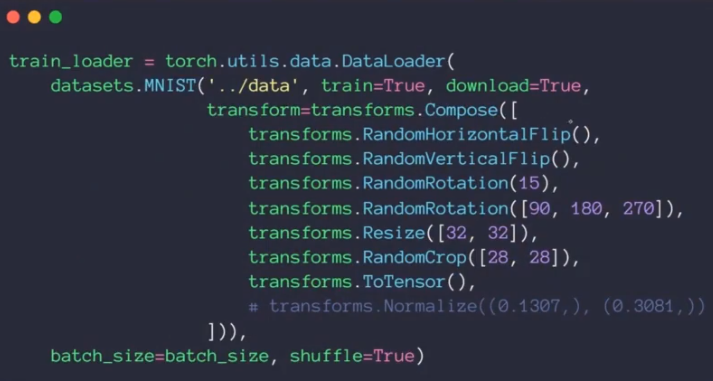
二十:module
1.save和load
不知道有没有用,先写下来,后面验证
import torch net = Net() net.load_state_dict(torch.load('ckpt.mdl')) torch.save(net.state_dict(), 'ckpt.mdl')
2.切换
net.train()
net.eval()
二十一:卷积与卷积神经网络
1.说明
网络:
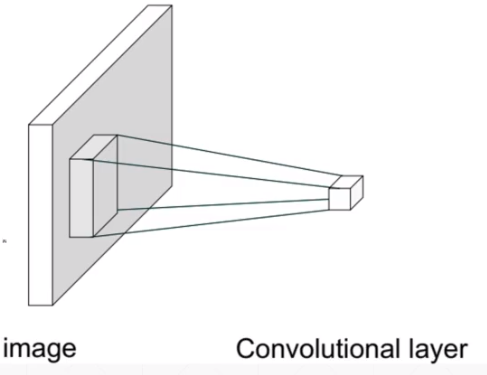
卷积:
2.卷积层基本概念

使用下面的数据进行理解:

3.F.conv2d
相当于1个图片,16个kenel, 3个grb
import torch import torch.nn as nn import torch.nn.functional as F x = torch.randn(1,3, 28, 28) w = torch.rand(16, 3, 5, 5) # 16ge kenel b = torch.rand(16) out = F.conv2d(x, w, b, stride=1, padding=1) # torch.Size([1, 16, 26, 26]) print(out.shape) out = F.conv2d(x, w, b, stride=2, padding=2) # torch.Size([1, 16, 14, 14]) print(out.shape)
3.池化
pooling
upsample
Relu
4.pooling
import torch import torch.nn as nn import torch.nn.functional as F x = torch.randn(1,3, 28, 28) w = torch.rand(16, 3, 5, 5) # 16ge kenel b = torch.rand(16) out = F.conv2d(x, w, b, stride=1, padding=1) # torch.Size([1, 16, 26, 26]) print(out.shape) out = F.conv2d(x, w, b, stride=2, padding=2) # torch.Size([1, 16, 14, 14]) print(out.shape) ## pooling x= out layer = nn.MaxPool2d(2, stride=2) # window = 2 * 2 out = layer(x) # torch.Size([1, 16, 7, 7]) print(out.shape) # torch.Size([1, 16, 7, 7]) out = F.avg_pool2d(x, 2, stride = 2) print(out.shape)
5.upsample
import torch import torch.nn as nn import torch.nn.functional as F x = torch.randn(1,3, 28, 28) w = torch.rand(16, 3, 5, 5) # 16ge kenel b = torch.rand(16) out = F.conv2d(x, w, b, stride=1, padding=1) # torch.Size([1, 16, 26, 26]) print(out.shape) out = F.conv2d(x, w, b, stride=2, padding=2) # torch.Size([1, 16, 14, 14]) print(out.shape) ## pooling x= out layer = nn.MaxPool2d(2, stride=2) # window = 2 * 2 out = layer(x) # torch.Size([1, 16, 7, 7]) print(out.shape) # torch.Size([1, 16, 7, 7]) out = F.avg_pool2d(x, 2, stride = 2) print(out.shape) ## upsample x = out out = F.interpolate(x, scale_factor=2, mode='nearest') # torch.Size([1, 16, 14, 14]) print(out.shape)
6.Batch Norm
按照chennel进行计算的
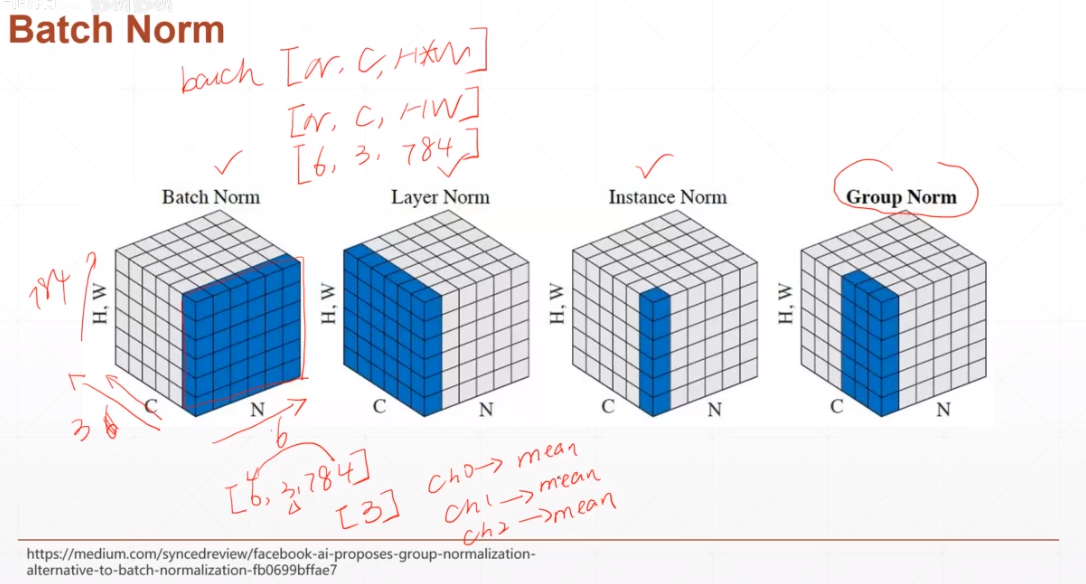
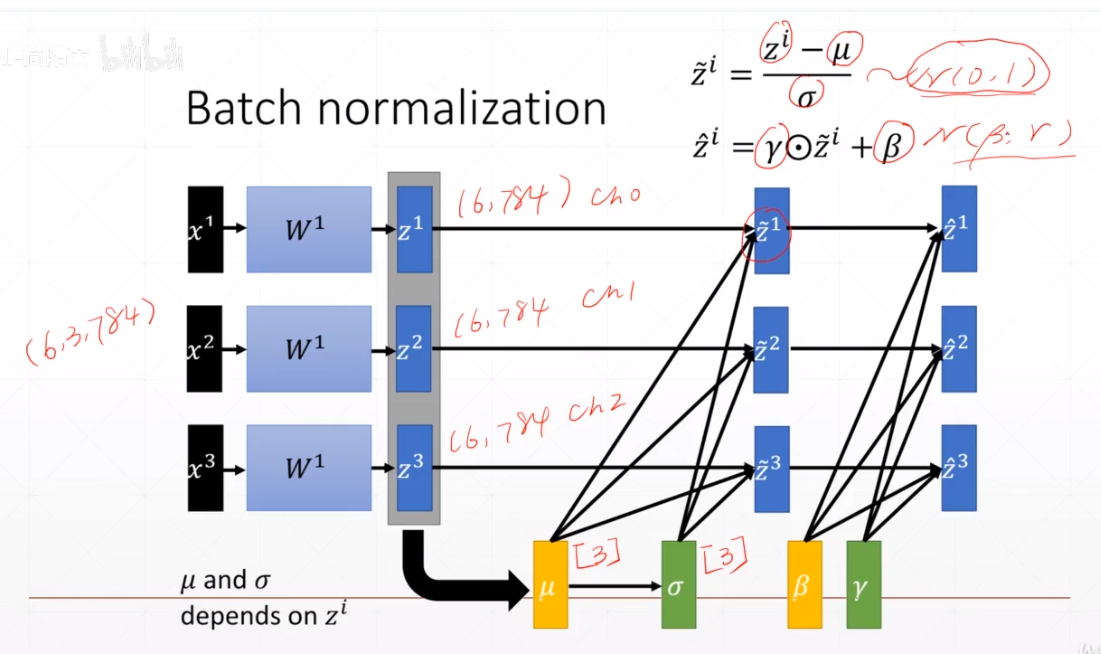
import torch
import torch.nn as nn
# 1d
x = torch.rand(100, 16, 784)
layer = nn.BatchNorm1d(16)
out = layer(x)
mean = layer.running_mean
print(mean)
var = layer.running_var
print(var)
# 2d
x = torch.rand(100, 16, 7, 6)
layer = nn.BatchNorm2d(16)
out = layer(x)
w = layer.weight #
print(w)
b = layer.bias #
print(b)
print(vars(layer))
二十三:Alex
1.下载dataset
import torch from torchvision import datasets from torchvision import transforms from torch.utils.data import DataLoader def main(): batch_size = 32 # 训练集 cifar_train = datasets.CIFAR10('cifar', True, transform=transforms.Compose([ transforms.Resize((32, 32)), transforms.ToTensor() ]), download=True) cifar_train = DataLoader(cifar_train, batch_size=batch_size, shuffle=True) # 测试集 test_train = datasets.CIFAR10('cifar', False, transform=transforms.Compose([ transforms.Resize((32, 32)), transforms.ToTensor() ]), download=True) test_train = DataLoader(test_train, batch_size=batch_size, shuffle=True) x, label = iter(cifar_train).next() print('x:', x.shape, 'label:', label.shape) if __name__ == '__main__': main()
2.module
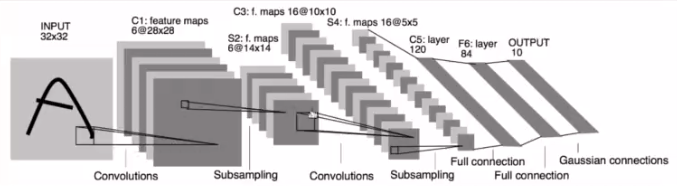
import torch from torch import nn import torch.nn.functional as F # 1986年的一个版本 class Lenet5(nn.Module): def __init__(self): super(Lenet5, self).__init__() # 卷积层 self.conv_unit = nn.Sequential( # x: torch.Size([b, 3, 32, 32]) => [b, 6, ] # 6是paper上的 nn.Conv2d(3, 6, kernel_size=5, stride=1, padding=0), nn.AvgPool2d(kernel_size=2, stride=2, padding=0), # # 16是paper上的 nn.Conv2d(6, 16, kernel_size=5, stride=1, padding=0), nn.AvgPool2d(kernel_size=2, stride=2, padding=0), ) # 卷积层的shape temp = torch.randn(2, 3, 32, 32) out = self.conv_unit(temp) print(out.shape) # torch.Size([2, 16, 5, 5]) # flatten 打平层 # fc unit 全连接 self.fc_unit = nn.Sequential( # 假设已经打平,则16 * 5 * 5 nn.Linear(16 * 5 * 5, 120), nn.ReLU(), nn.Linear(120, 84), nn.ReLU(), nn.Linear(84, 10) ) def forward(self, x): batch_size = x.size(0) # x = [b, 3, 32, 32] = > [b, 16, 5, 5] x= self.conv_unit(x) # [b, 16, 5, 5] => [b, 16 * 5 * 5] x = x.view(batch_size, -1) #[b, 16 * 5 * 5] =>[b, 10] logits = self.fc_unit(x) return logits def main(): # 测试 : torch.Size([2, 10]) net = Lenet5() temp = torch.randn(2, 3, 32, 32) out = net(temp) print(out.shape) # torch.Size([2, 10]) if __name__ == '__main__': main()
3.训练
import torch from torch import nn from torchvision import datasets from torchvision import transforms from torch.utils.data import DataLoader from lenet5 import Lenet5 import torch.optim as optim def main(): batch_size = 32 # 训练集 cifar_train = datasets.CIFAR10('cifar', True, transform=transforms.Compose([ transforms.Resize((32, 32)), transforms.ToTensor() ]), download=True) cifar_train = DataLoader(cifar_train, batch_size=batch_size, shuffle=True) # 测试集 cifar_test = datasets.CIFAR10('cifar', False, transform=transforms.Compose([ transforms.Resize((32, 32)), transforms.ToTensor() ]), download=True) cifar_test = DataLoader(cifar_test, batch_size=batch_size, shuffle=True) # x: torch.Size([32, 3, 32, 32]) label: torch.Size([32]) x, label = iter(cifar_train).next() print('x:', x.shape, 'label:', label.shape) # 训练 model = Lenet5() print(model) criteon = nn.CrossEntropyLoss() opitimizer = optim.Adam(model.parameters(), lr=1e-3) for epoch in range(1000): model.train() # x = [b, 3, 32, 32] # label = [b] for batchIdx, (x, label) in enumerate(cifar_train): # [b, 10] logits = model(x) # tensor scalar loss = criteon(logits, label) opitimizer.zero_grad() loss.backward() opitimizer.step() print(epoch, loss.item()) # test model.eval() with torch.no_grad(): total_correct = 0 total_sum = 0 for x, label in cifar_test: logits = model(x) pred = logits.argmax(dim=1) total_correct += torch.eq(pred, label).float().sum().item() total_sum += x.size(0) acc = total_correct / total_sum print("epoch acc", epoch, acc) if __name__ == '__main__': main()
效果:
D:\Python310\python.exe E:/bme-job/torchProjectDemo/cifar/__init__.py Files already downloaded and verified Files already downloaded and verified x: torch.Size([32, 3, 32, 32]) label: torch.Size([32]) torch.Size([2, 16, 5, 5]) Lenet5( (conv_unit): Sequential( (0): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1)) (1): AvgPool2d(kernel_size=2, stride=2, padding=0) (2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1)) (3): AvgPool2d(kernel_size=2, stride=2, padding=0) ) (fc_unit): Sequential( (0): Linear(in_features=400, out_features=120, bias=True) (1): ReLU() (2): Linear(in_features=120, out_features=84, bias=True) (3): ReLU() (4): Linear(in_features=84, out_features=10, bias=True) ) ) 0 2.8104629516601562 epoch acc 0 0.4473 1 1.3926700353622437 epoch acc 1 0.4833 2 1.3417390584945679 epoch acc 2 0.5184 3 1.369856357574463 epoch acc 3 0.5169 4 1.6428718566894531 epoch acc 4 0.5321 5 1.3155806064605713 epoch acc 5 0.5227 6 0.7842959761619568 epoch acc 6 0.5509 7 1.248106837272644 epoch acc 7 0.545
二十三:ResNet
1.说明
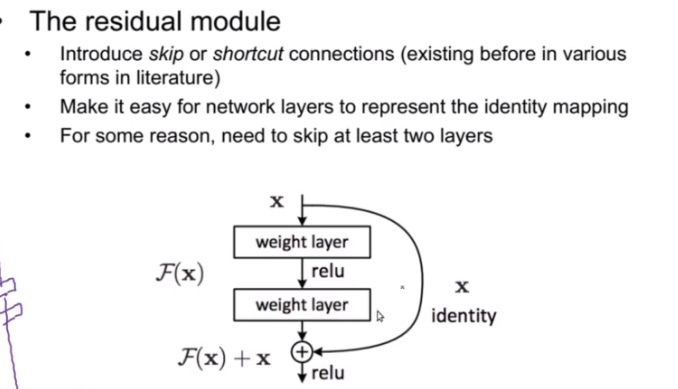
2.程序
二十四:RNN
1.说明
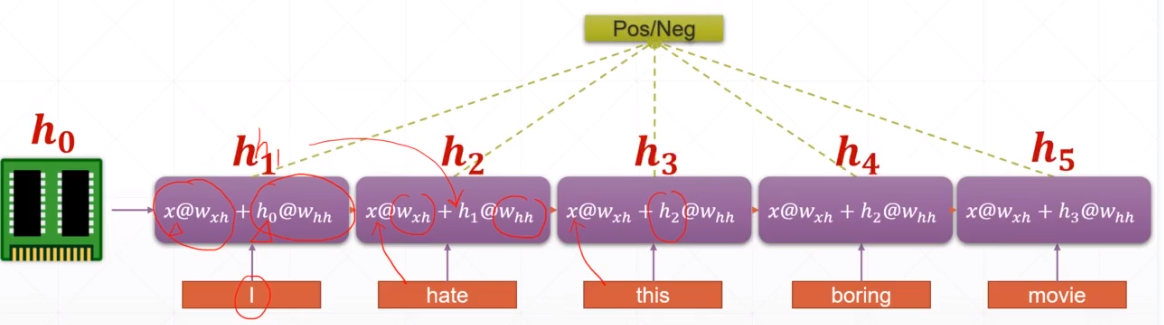
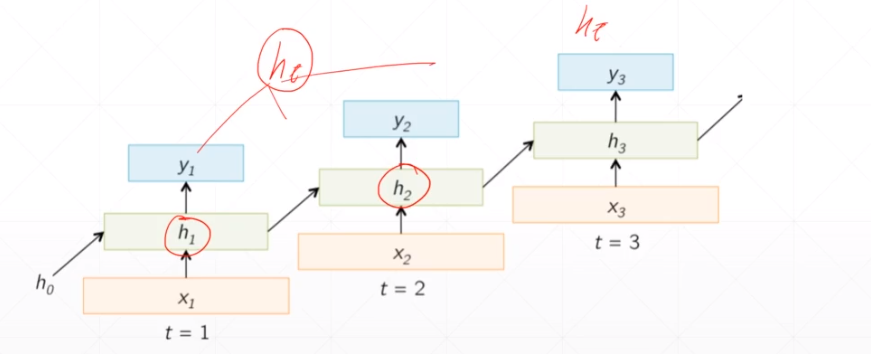
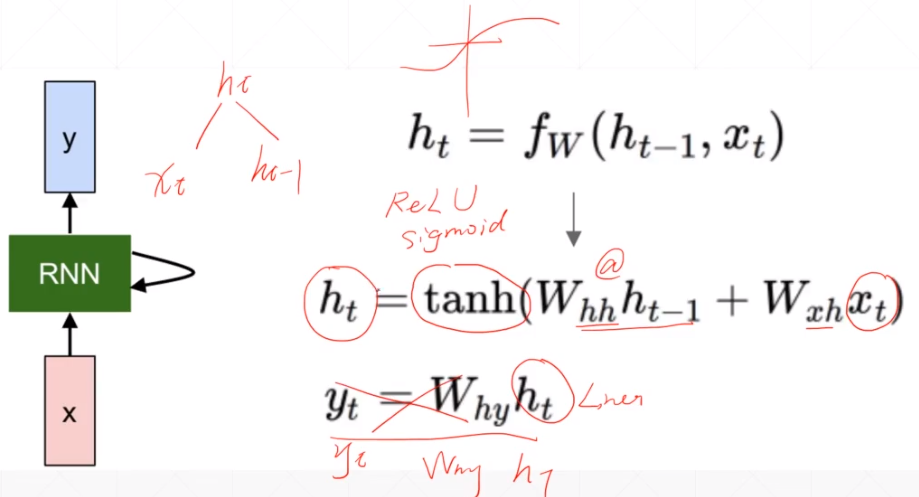
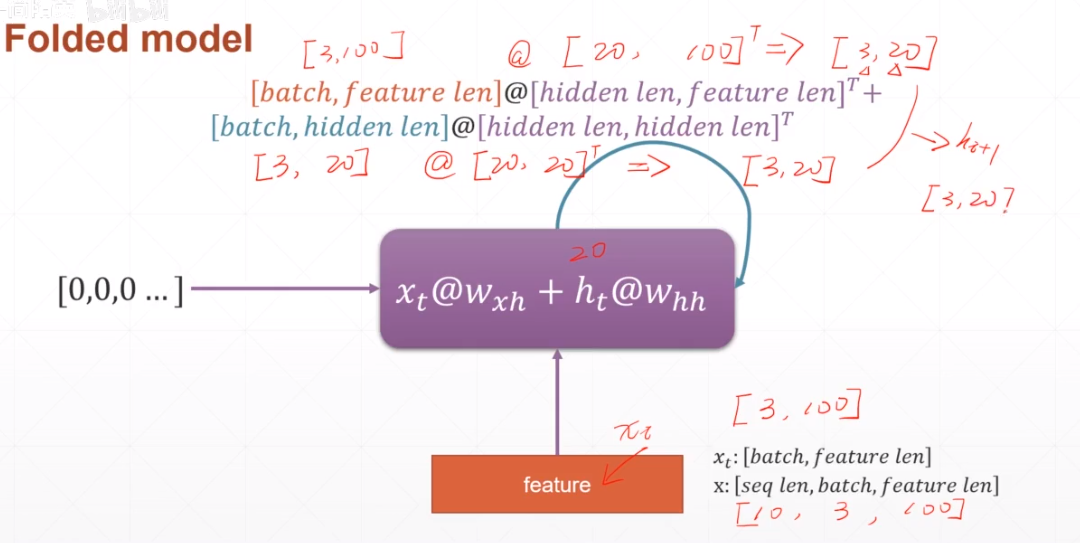
2.
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号