
Redis数据结构及各自适用场景
首先,redis 内部使用一个redisObject 核心对象来表示所有的 key 和 value,
redisObject 里包括这些属性:数据类型--type{String/hash/list/set/sorted set} 编码方式--encoding{raw/int/ht/zipmp/linkedlist/zaplist/intset} 数据指针---ptr 虚拟内存--vm 其他信息
下面具体介绍五种基本数据类型:
String:
value 值可以是字符型,也可以是数字。
其实没有什么特别的特点,正常的持久化那些基本操作,get set 然后获取字符串长度,让字符串拼接等 如果是数字的话,可以incre decre 计数功能
使用场景:比如计数功能,对字符串的一些存取功能等等 ,没有什么特别的功能。
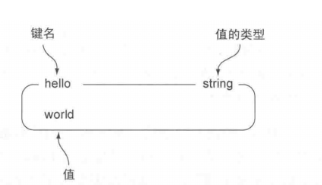
hash:
值本身也是键值对的形式,无序的。可以添加,获取,移动元素,获取所有键值对,
使用场景:比如我们存的用户信息,一个用户id ,对应用户的身高,体重,姓名,等等n个信息,如果将这些信息作为一个整体存的话,在序列化反序列化的时候开销就比较大,如果 "id-姓名"---张三 "id-年龄"---25 "id-身高"---178 这样存储的话冗余量又太大
所有hash 就可以很好的用上,id就作为hash-key 找到这个用户信息,里面存的即 "姓名---值" “年龄--值” 这样的形式,实现存储修改获取部分数据。
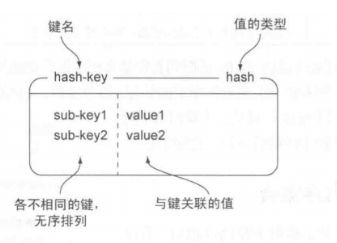
List:
list 是用的一个双向链表,所以他是有顺序的,其特点就跟链表特点一样了,从链表的两端推入或者弹出元素,根据偏移量进行修剪[trim] ,读取单个或者多个元素,根据值查找或者移除元素。
使用场景:
- 用户关注列表,新增一个关注在后面增加一个。
- 异步队列使用【将需要延后处理的任务结构体序列化成字符串进redis 的列表,另一个线程从这个列表中轮询数据进行处理】。
- 秒杀场景,秒杀前将本场秒杀的商品放到list中,因为list的pop操作是原子性的,所以即使有多个用户同时请求,也是依次pop,list空了pop抛出异常就代表商品卖完了.
![]()
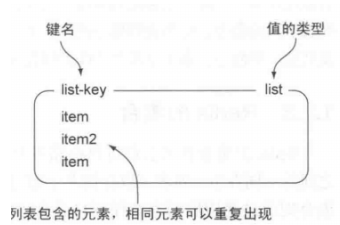
set:
存储的是一堆不重复的无序数据,操作有添加,获取,移除单元素,检测是否存在元素,计算交集,并集,差集,从集合里随机获取元素等
set 的内部实现是一个 value永远为null的HashMap,实际就是通过计算hash的方式来快速排重的,这也是set能提供判断一个成员是否在集合内的原因。
使用场景:不可重复,但是value可以为null ,用在一些去重的场景,比如用户只能参加一次活动,一个用户只能中一次奖等等去重场景。还有就是求交集并集补集的场景。
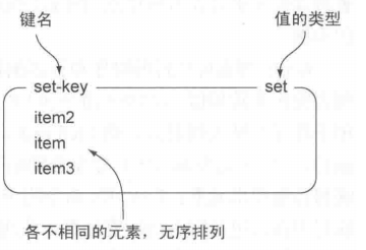
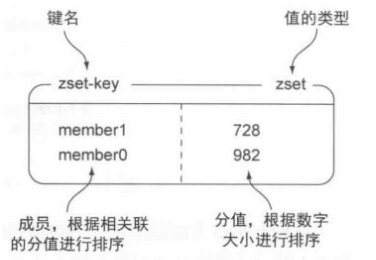
Sorted Set:
set基础上增加了的顺序的特性,每一个value加入的时候带有一个分值以表示权重,
部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
使用场景:各类排序场景:歌曲排行榜,播放次数,播放数,点赞数等等需要排序的场景。
扩展:除了以上五种数据结构,了解其他的数据结构吗?
布隆过滤器:bloom filter:判断是否存在(用户只能参加一次活动)
1.向布隆过滤器中添加 key 时,会使用多个 hash 函数对 key 进行 hash
运算,然后对位数组长度进行取模运算得到一个位置,这样添加一个key会在多个位加1。
2. 向布隆过滤器询问 key 是否存在时,跟 add 一样,也会把 hash 的几个位置都算出来,看看位数组中这几个位置是否都为 1,只要有一个位为 0,那么说明布隆过滤器中这个 key 不存在
HyperLogLog:统计海量去重元素数量(统计页面uv):
16384个桶(16*1024),当一个元素到来时,它会散列(hash)到其中一个桶,每个桶占6bit.
位图:大量是否的统计(一年的打卡数量)
Stream:支持多播的可持久化的消息队列()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号