Hive基础概念与数据导入导出
Hive是什么
Hive 是 Hadoop 家族中一款数据仓库产品,Hive 最大的特点就是提供了类 SQL 的语法,封装了底层的 MapReduce 过程,让有 SQL 基础的业务人员,也可以通过SQL直接利用 Hadoop 进行大数据的操作。像我一开始学习MapReduce的时候,就是通过一个个Java小demo去学习它们的原理和过程,要通过java去实现一些特定的MR过程对于当时Java用得不太多的我来说非常不友好。直到Hive的出现让这些变得简单了起来,我们大可以放心的去用SQL实现自己想实现的数据处理过程,Hive会自动执行MR过程来加速我们的运算。所以有了Hive,只要你会SQL,你就具备大数据分析的基础了。
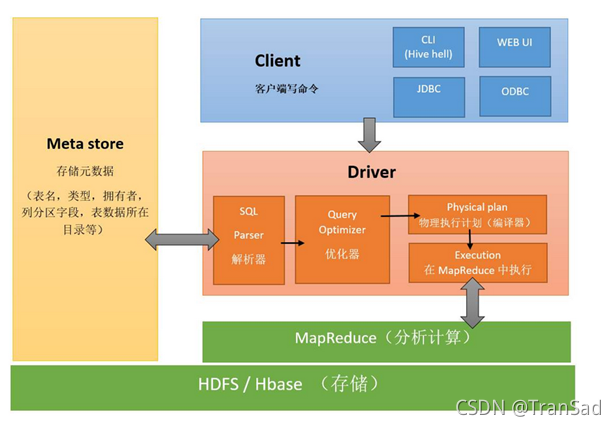
一般来说,Hive表的元数据存放在mysql中、数据存放在HDFS中(我记得安装Hive之后,里面就能很清楚地看到一个叫mysql表)。还有一点需要注意的是,Hive本质是将导入的结构化的数据文件映射为一张数据库表,它本身其实并没有什么专门的数据格式,只是将数据移动或复制到相应的HDFS目录。所以Hive的内容是读多少写多少,并不支持传统数据库那样对数据insert和update,Hive中所有数据都是在加载时确定好的。
Hive数据导入
将数据导入Hive,可以直接从本地文件导入,也可以从HDFS上导入,都是使用load。一般来说要导入的数据是上游或者本地已经有的数据文件。
若直接从本地导入,则可以通过:
load data local inpath 'file_path' into table tablename;命令来完成。
若从HDFS上导入,则可以:
load data inpath ‘hdfs_file_path’ into table tablename;
(这里再补充一点,将本地文件导入HDFS中的常用写法:hadoop fs -put localfile /user/hadoop/hadoopfile)
通过上面几种方法,就可以将数据导入Hive中。当然前提是tablename是我们事先创建好的表——再提一下,创建Hive表的一般写法:
CREATE EXTERNAL TABLE tablename(col1 INT, col2 string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t’;
Hive数据导出
Insert方式
前面说数据导入的时候,数据来源一般是本地或者HDFS上。对应地,Hive数据导出也是有两个地方,一个是本地目录,另一个是HDFS目录。
将数据导出到本地目录:
insert overwrite local directory 'path' row format delimited fields terminated by '\t' select * from tablename;
这里insert到本地和上面load从本地,其实都用了“local”来规定“本地”。如果我们只是平时在自己的电脑+虚拟机环境下使用是没问题的。但假如在真正的集群环境下使用,则这个“local”多半是指某个节点的本地磁盘,我们有可能没有权限去访问那个路径,就算导出到那里了也无法真正拿到数据。最后,红色标记语句的作用是使其产生分隔符,否则导出数据全都堆成一块了。
将数据导出到HDFS目录:
insert overwrite directory 'hdfs_path' select * from tablename;
get方式
HDFS的get和put方式其实多用于本地和HDFS的文件传输。之前讲过,如果要把数据存入Hive,可以以HFDS做过渡,先用put的方式上传到HDFS,再从HDFS传到Hive。然而要从Hive中导出数据到本地,我们可以直接用get的方式——因为Hive的根本数据其实就是在HDFS中!我们只需要找到要导出数据的HDFS目录,不就可以直接通过get命令导出了吗?命令:
hdfs dfs -get /user/hadoop/file localfile;
那么,如何找到Hive在HDFS上的存储位置呢?我们找到Hive的安装目录,会有一个hive-site.xml文件,里面有一个设置参数hive.metastore.warehouse.dir,这个参数的值就是Hive存储在HDFS上的路径位置,默认应该是/user/hive/warehouse下,这其实也就是Hive内部表的存储位置。
进一步理解上述这个路径:我们打开Hive,执行show databases后,可以看到很多张表,比如其中有一个表叫movie,那么这张表在HDFS上的存储路径就为user/hive/warehouse/movie.db。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号